Salut, Habr. Je voudrais parler d'une des approches pour résoudre le problème de la diarisation des locuteurs et montrer comment cette méthode peut être implémentée en python. Afin de ne pas effrayer le lecteur, je ne donnerai pas de formules mathématiques complexes (en partie parce que je ne suis pas moi-même un vrai soudeur), mais j'essaierai de tout expliquer dans un langage simple et de tout dire de telle manière qu'un développeur qui n'a jamais rencontré le machine learning auparavant l'a compris.
En me préparant à écrire cet article, j'ai choisi entre deux options: pour ceux qui connaissent déjà la Data Science et ceux qui se contentent de bien programmer. Au final, j'ai choisi la deuxième option, décidant que ce serait une bonne démonstration des capacités de DS.
Énoncé du problème
Comme nous le
dit Wikipedia, la diarisation est le processus de division d'un flux audio entrant en segments homogènes selon que le flux audio appartient à l'un ou à l'autre haut-parleur. En d'autres termes, le dossier doit être divisé en morceaux et numéroté: une personne parle à ces endroits et une autre à ces endroits. Du point de vue de l'apprentissage automatique, les tâches de ce type appartiennent à la classe d'apprentissage sans enseignant et sont appelées clustering. Vous pouvez lire sur les méthodes de clustering qui existent
ici ou
ici , par exemple, mais je ne parlerai que de celles qui nous sont utiles - il s'agit d'un modèle de mélange gaussien et d'un clustering spectral. Mais à leur sujet un peu plus tard.
Commençons par le tout début.
Préparation de l'environnement
SpoilerJe ne savais pas trop si je devais quitter cette section - je ne voulais pas transformer l'article en un très tutoriel. Mais à la fin je l'ai laissé. Celui qui n'en a pas besoin sautera, et pour ceux qui feront tout à partir de zéro, cette étape facilitera le démarrage.
De manière générale, en plus de R, python est le langage principal pour résoudre les problèmes de Data Science, et si vous n'avez pas encore essayé de le programmer, alors je recommande fortement de le faire car python vous permet de faire beaucoup de choses avec élégance, littéralement en quelques lignes (à propos, il y a même un tel mème).
Il existe deux branches de python développées séparément - les versions 2 et 3. Dans mes exemples, j'ai utilisé la version 3.6, mais si vous le souhaitez, elles peuvent facilement être portées vers la version 2.7. Il est pratique de déployer l'une de ces branches avec le programme d'installation d'
Anaconda , en installant lequel vous recevrez immédiatement un shell interactif pour le développement - IPython.
En plus de l'environnement de développement lui-même, des bibliothèques supplémentaires seront nécessaires: librosa (pour travailler avec l'audio et extraire les attributs), webrtcvad (pour la segmentation) et pickle (pour écrire des modèles entraînés dans un fichier). Tous sont installés par une simple commande dans Anaconda Prompt.
pip install [library]
Extraction de fonctionnalités
Commençons par l'extraction des fonctionnalités - des données avec lesquelles les modèles d'apprentissage automatique fonctionneront. En principe, le signal sonore lui-même est déjà une donnée, à savoir un tableau ordonné de valeurs d'amplitude sonore, auquel est ajouté un en-tête contenant le nombre de canaux, la fréquence d'échantillonnage et d'autres informations. Mais nous ne serons pas en mesure d'analyser ces données directement, car elles ne contiennent pas de telles choses, en regardant lesquelles, notre modèle peut dire - oui, ces pièces appartiennent à la même personne.
Dans les tâches de traitement de la parole, il existe plusieurs approches pour extraire des fonctionnalités. L'un d'eux est d'obtenir des coefficients cepstraux de fréquence de Mel. Ils ont
déjà été écrits ici, donc je ne vous le rappelle que légèrement.
Le signal d'origine est découpé en trames d'une durée de 16 à 40 ms. Ensuite, en appliquant une fenêtre de
Hamming au cadre, ils font une transformée de Fourier rapide et obtiennent la densité spectrale de puissance. Ensuite, avec un «peigne» spécial de filtres disposés uniformément sur l'échelle de craie, un spectrogramme de craie est réalisé, auquel une transformée en cosinus discrète (DCT) est appliquée - un algorithme de compression de données largement utilisé. Les coefficients ainsi obtenus sont une sorte de caractéristique compressée de la trame, et puisque les filtres que nous avons utilisés étaient situés à l'échelle de
craie , les coefficients portent plus d'informations dans le domaine de perception de l'oreille humaine. En règle générale, 13 à 25 MFCC par trame sont utilisés. Étant donné qu'en plus du spectre lui-même, la personnalité de la voix est formée par la vitesse et l'accélération, MFCC est combiné avec les première et deuxième dérivées.
En général, MFCC est l'option la plus courante pour travailler avec la parole, mais en plus d'eux, il existe d'autres signes - LPC (Linear Predictive Coding) et PLP (Perceptual Linear Prediction), et parfois vous pouvez également trouver LFCC, où au lieu de l'échelle de craie, linéaire est utilisé.
Voyons comment extraire MFCC en python.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
Comme vous pouvez le voir, cela se fait vraiment en quelques lignes. Passons maintenant au premier algorithme de clustering.
Modèle de mélange gaussien
Un modèle d'un mélange de distributions gaussiennes suggère que nos données sont un mélange de distributions gaussiennes multidimensionnelles avec certains paramètres.
Si vous le souhaitez, vous pouvez facilement trouver une description détaillée du modèle et comment fonctionne l'
algorithme EM qui forme ce modèle, mais j'ai promis de ne pas ennuyer avec des formules complexes et donc je vais montrer de beaux exemples de
cet article.
Nous allons générer quatre clusters et les dessiner.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
Nous allons créer un modèle, nous entraîner sur nos données et dessiner à nouveau les points, mais en tenant compte du modèle prévu d'appartenance au cluster.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
Le modèle a bien géré les données artificielles. En principe, en régulant le nombre de composants du mélange et le type de matrice de covariance (le nombre de degrés de liberté des Gaussiens), des données assez compliquées peuvent être décrites.

Ainsi, nous savons comment paramétrer les données et sommes capables de former un modèle d'un mélange de distributions gaussiennes. Maintenant, on pourrait essayer de faire un regroupement sur le front - la formation de GMM sur le MFCC extraite du dialogue. Et, probablement, dans un certain dialogue sphérique-vide idéal, dans lequel chaque locuteur s'intégrera dans son gaussien, nous obtiendrons un bon résultat. Il est clair qu'en réalité, cela ne se produira jamais. En fait, avec l'aide de GMM, ils ne modélisent pas un dialogue, mais chaque personne dans un dialogue - c'est-à-dire qu'ils imaginent que la voix de chaque locuteur dans les signes extraits est décrite par son propre ensemble de gaussiens.
Pour résumer, nous arrivons lentement au sujet principal.
Segmentation
Traditionnellement, le processus de diarisation se compose de trois blocs consécutifs - détection vocale (Voice Activity Detection), segmentation et clustering (il existe des modèles dans lesquels les deux dernières étapes sont combinées, voir
LIA E-HMM ).
Dans la première étape, la parole est séparée de divers types de bruit. L'algorithme VAD détermine si le morceau du fichier audio qui lui est soumis est un discours, ou par exemple, il sonne une sirène ou quelqu'un éternue. Il est clair que pour qu'un tel algorithme soit de haute qualité, une formation avec un enseignant est nécessaire. Et cela signifie à son tour que vous devez baliser les données - en d'autres termes, créer une base de données avec des enregistrements de parole et toutes sortes de bruits. Nous le ferons paresseusement - prenez un
VAD prêt à l'emploi, qui ne fonctionne pas parfaitement, mais pour les débutants, nous en avons assez.
Le deuxième bloc coupe les données vocales en segments avec un locuteur actif. L'approche classique à cet égard est l'algorithme pour déterminer le changement de locuteur sur la base du critère d'information bayésien -
BIC . L'essence de cette méthode est la suivante - une fenêtre coulissante parcourt les enregistrements audio et à chaque point du passage, ils répondent à la question: "Comment les données de cet endroit sont-elles mieux décrites - une distribution ou deux?" Pour répondre à cette question, le paramètre est calculé
, en fonction du signe dont la décision est prise de changer de locuteur. Le problème est que cette méthode ne fonctionnera pas très bien en cas de changements de haut-parleur fréquents, et même en présence de bruit (qui sont très caractéristiques pour l'enregistrement d'une conversation téléphonique).
Une petite explicationDans l'original, j'ai travaillé avec des enregistrements téléphoniques d'un centre d'appels d'une durée moyenne d'environ 4 minutes. Pour des raisons évidentes, je ne peux pas poster ces notes, donc pour la démonstration j'ai pris
une interview d'une station de radio. Dans le cas d'un long entretien, cette méthode donnerait probablement un résultat acceptable, mais elle n'a pas fonctionné sur mes données.
Dans les conditions où les annonceurs ne s'interrompent pas et que leurs voix ne se chevauchent pas, le VAD que nous utiliserons fera plus ou moins face à la tâche de segmentation, donc les deux premières étapes ressembleront à ceci.
En réalité, les gens parleront certainement en même temps. De plus, le VAD à certains endroits a fait une erreur en raison du fait que le disque n'est pas en direct, mais est un collage dans lequel les pauses sont supprimées. Vous pouvez essayer de répéter la découpe en segments, augmentant l'agressivité du VAD de 2 à 3.
GMM-UBM
Nous avons maintenant des segments séparés et nous avons décidé de modéliser chaque haut-parleur à l'aide de GMM. Nous extrayons les signes du segment et sur ces données nous formons le modèle. Faisons-le sur chaque segment et comparons les modèles résultants entre eux. Il est légitime de s'attendre à ce que les modèles formés sur des segments appartenant à la même personne soient quelque peu similaires. Mais ici, nous sommes confrontés au problème suivant: en extrayant des signes d'un fichier audio d'une seconde de long avec une fréquence d'échantillonnage de 8000 Hz avec une taille de fenêtre de 10 ms, nous obtenons un ensemble de 800 vecteurs MFCC. Notre modèle ne pourra pas apprendre de telles données, car elles sont négligeables. Même si ce n'est pas une seconde, mais dix, les données ne seront toujours pas suffisantes. Et ici, le modèle d'arrière-plan universel (UBM) vient à la rescousse, il est également appelé indépendant du locuteur. L'idée est la suivante. Nous formerons GMM sur un grand échantillon de données (dans notre cas, il s'agit d'un enregistrement d'interview complet) et nous obtiendrons un modèle acoustique d'un locuteur généralisé (ce sera notre UBM). Et puis, en utilisant un algorithme d'adaptation spécial (à ce sujet ci-dessous), nous «adapterons» ce modèle aux caractéristiques extraites de chaque segment. Cette approche est largement utilisée non seulement pour la diarisation, mais aussi dans les systèmes de reconnaissance vocale. Pour reconnaître une personne par la voix, vous devez d'abord former un modèle sur elle et sans UBM, vous devriez avoir plusieurs heures d'enregistrement du discours de cette personne.
De chaque GMM adapté, on extrait le vecteur des coefficients de cisaillement
(c'est aussi une attente médiane ou mat., si vous voulez) et, sur la base des données sur ces vecteurs de tous les segments, nous ferons un clustering (ci-dessous, il sera clair pourquoi il s'agit du vecteur de décalage).
Adaptation de la carte
La méthode par laquelle nous personnaliserons l'UBM pour chaque segment est appelée adaptation maximale a posteriori. En général, l'algorithme est le suivant. Premièrement, la probabilité postérieure est calculée sur les données d'adaptation et
des statistiques suffisantes pour le poids, la médiane et la variance de chaque gaussien. Ensuite, les statistiques obtenues sont combinées avec les paramètres UBM et les paramètres du modèle adapté sont obtenus. Dans notre cas, nous n'adapterons que les médianes, sans affecter le reste des paramètres. Malgré le fait que j'ai promis de ne pas approfondir les mathématiques, je citerai après tout trois formules, car l'adaptation MAP est le point clé de cet article.
Ici
- probabilité postérieure,
- statistiques suffisantes pour
,
- médiane du modèle adapté,
- coefficient d'adaptation,
- facteur de conformité.
Si tout cela semble insensé et provoque le découragement - ne désespérez pas. En effet, pour comprendre le fonctionnement de l'algorithme, il n'est pas nécessaire de se plonger dans ces formules; son fonctionnement peut être facilement démontré par l'exemple suivant:
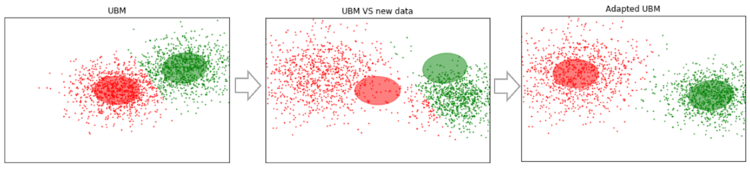
Supposons que nous ayons des données suffisamment volumineuses et que nous avons formé UBM sur celles-ci (image de gauche, UBM est un mélange à deux composantes de distributions gaussiennes). De nouvelles données apparaissent qui ne rentrent pas dans notre modèle (figure au milieu). En utilisant cet algorithme, nous déplacerons les centres des Gaussiens pour qu'ils se trouvent sur les nouvelles données (figure à droite). En appliquant cet algorithme aux données expérimentales, nous nous attendons à ce que sur les segments avec le même locuteur, les Gaussiens se déplacent dans une direction, formant ainsi des grappes. C'est pourquoi nous utiliserons des données de cisaillement pour regrouper les segments
.
Alors, faisons l'adaptation MAP pour chaque segment. (Pour référence: en plus de l'adaptation MAP, la méthode MLLR - Régression linéaire par maximum de vraisemblance et certaines de ses modifications sont largement utilisées. Ils essaient également de combiner ces deux méthodes.)
SV = []
Maintenant que pour chaque segment, nous avons des données sur
, nous passons enfin à la dernière étape.
Regroupement spectral
Le regroupement spectral est brièvement décrit dans l'article, un lien auquel j'ai donné au tout début. L'algorithme construit un graphe complet, où les sommets sont nos données et les bords entre eux sont une mesure de similitude. Dans les tâches de reconnaissance vocale, une métrique de cosinus est utilisée comme telle mesure, car elle prend en compte l'angle entre les vecteurs, en ignorant leur amplitude (qui ne transporte pas d'informations sur le locuteur). En construisant le graphique, les vecteurs propres de la matrice de Kirchhoff sont calculés (qui est essentiellement une représentation du graphique résultant) puis une méthode de regroupement standard est utilisée, par exemple, la méthode des k-moyennes. Tout tient dans deux lignes de code
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
Conclusions et plans futurs
L'algorithme décrit a été testé avec différents paramètres:
- Numéro MFCC: 7, 13, 20
- MFCC en combinaison avec LPC
- Type et nombre de mélanges dans GMM: complet [8, 16, 32], diag [8, 16, 32, 64, 256]
- Méthodes d'adaptation UBM: MAP (avec covariance_type = 'full') et MLLR (avec covariance_type = 'diag')
En conséquence, les paramètres sont restés subjectivement optimaux: MFCC 13, GMM covariance_type = 'full' n_components = 16.
Malheureusement, je n'ai pas eu la patience (j'ai commencé à écrire cet article il y a plus d'un mois) pour baliser les segments reçus et calculer le DER (Diariztion Error Rate). Subjectivement, j'évalue le fonctionnement de l'algorithme comme «en principe, pas mal, mais loin d'être idéal». En regroupant les vecteurs obtenus à partir des cent premiers segments (avec un passage MAP), puis en sélectionnant ceux où l'intervieweur dit (fille, elle parle beaucoup moins que l'invité là-bas), le regroupement donne une liste
![[1, 2, 25, 26, 46, 48, 49, 61, 85, 86] $](https://habrastorage.org/getpro/habr/formulas/b5f/5b8/c96/b5f5b8c962e564d107227d8156c32384.svg)
c'est 100% touché. Dans le même temps, les segments où les deux haut-parleurs sont présents (par exemple, 14) abandonnent, mais cela peut déjà être attribué à l'erreur VAD. De plus, de tels segments commencent à être pris en compte avec une augmentation du nombre de passes MAP. Un point important. L'interview avec laquelle nous avons travaillé est plus ou moins "propre". Si divers inserts musicaux, bruits et autres choses non verbales sont ajoutés, le regroupement commence à boiter. Par conséquent, il est prévu d'essayer de former notre propre VAD (car webrtcvad, par exemple, ne sépare pas la musique de la parole).
Étant donné que j'avais initialement travaillé avec une conversation téléphonique, je n'avais pas besoin d'estimer le nombre de locuteurs. Mais le nombre de locuteurs n'est pas toujours prédéterminé, même s'il s'agit d'une interview. Par exemple, dans
cette interview au milieu, il y a une annonce superposée à la musique et exprimée par deux personnes supplémentaires. Par conséquent, il serait intéressant d'essayer la méthode d'estimation du nombre de locuteurs spécifiée dans le premier article de la section de la liste de références (basée sur une analyse des valeurs propres de la matrice de Laplace normalisée).
Les références
En plus des documents situés sur les liens dans le texte et les ordinateurs portables Jupyter, les sources suivantes ont été utilisées pour préparer cet article:
- Diarisation des haut-parleurs à l'aide du superviseur GMM et des algorithmes de réduction avancés. Nurit spingarn
- Méthodes d'extraction des fonctionnalités LPC, PLP et MFCC dans la reconnaissance vocale. Namrata dave
- Évaluation MAP pour les observations de mélange gaussien à plusieurs variables des chaînes de Markov. Jean-Luc Gauvain et Chin-Hui Lee
- Sur l'analyse de regroupement spectral et un algorithme. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Reconnaissance du locuteur à l'aide d'un modèle d'arrière-plan universel sur la base de données YOHO. Alexandre Majetniak
J'ajouterai également quelques projets de diarisation:
- Extension de diarisation Sidekit et s4d. Une bibliothèque python pour travailler avec la parole. Malheureusement, la documentation est pauvre.
- Bob et ses différentes parties telles que bob.bio , bob.learn.em - une bibliothèque python pour le traitement du signal et l'utilisation de données biométriques. Windows n'est pas pris en charge.
- LIUM est une solution clé en main écrite en Java.
Tout le code est affiché sur le
github . Pour plus de commodité, j'ai fabriqué plusieurs ordinateurs portables Jupyter avec une démonstration de certaines choses - MFCC, GMM, MAP Adaptation and Diarization. Ce dernier est le processus principal. Dans le référentiel se trouvent également des fichiers de cornichons avec certains modèles pré-formés et l'interview elle-même.