SDSM-15. À propos de la QoS. Maintenant, avec la possibilité de
tirer des demandes .
Et nous sommes donc arrivés au sujet de la QoS.
Savez-vous pourquoi seulement maintenant et pourquoi ce sera l'article de clôture de l'ensemble du cours SDSM? Parce que la QoS est inhabituellement complexe. La chose la plus difficile qui était avant dans le cycle.
Ce n'est pas une sorte d'archiveur magique qui comprime intelligemment le trafic à la volée et pousse votre gigabit dans une liaison montante de cent mégabits. La QoS consiste à sacrifier quelque chose d'inutile, en poussant le non comestible dans le cadre du permis.
La QoS est tellement enchevêtrée dans l'aura du chamanisme et de l'inaccessibilité que tous les jeunes (et pas seulement) ingénieurs essaient d'ignorer soigneusement son existence, estimant qu'il suffit de jeter des problèmes avec de l'argent et d'élargir les liens à l'infini. Certes, jusqu'à ce qu'ils réalisent qu'avec cette approche, l'échec les attendra inévitablement. Soit l'entreprise commencera à poser des questions inconfortables, soit il y aura beaucoup de problèmes qui ne sont presque pas liés à la largeur du canal, mais dépendent directement de l'efficacité de son utilisation. Oui, la VoIP agite activement un stylo dans les coulisses et le trafic de multidiffusion vous caresse malicieusement dans le dos.
Par conséquent, réalisons simplement que la QoS est obligatoire, vous devrez le savoir d'une manière ou d'une autre, et pour une raison quelconque, ne commencez pas maintenant, dans une atmosphère détendue.

Table des matières
1.
Qu'est-ce qui détermine la QoS?2.
Trois modèles de QoS- Meilleurs effets
- Services intégrés
- Services différenciés
3.
Mécanismes DiffServ4.
Classification et étiquetage- Agrégation de comportements
- Multi-domaines
- Basé sur l'interface
5.
Files d'attente6.
Évitement de la congestion- Chute de queue et chute de tête
- Rouge
- Wred
7.
Gestion de la congestion- Premier entré, premier sorti
- File d'attente prioritaire
- File d'attente équitable
- Tournoi à la ronde
8.
Limite de vitesse- Façonner
- Police
- Seau qui fuit et seau à jetons
9.
Implémentation matérielle de QoS
Avant que le lecteur ne plonge dans ce trou, je vais y définir trois paramètres:
- Tous les problèmes ne peuvent pas être résolus en élargissant la bande.
- QoS n'étend pas la bande.
- QoS sur la gestion des ressources limitées.
1. Qu'est-ce qui détermine la QoS?
L'entreprise s'attend à ce que la pile réseau remplisse très bien sa fonction simple: fournir un flux binaire d'un hôte à un autre: sans perte et dans un délai prévisible.
À partir de cette courte phrase, toutes les métriques de qualité du réseau peuvent être dérivées:
Ces trois caractéristiques déterminent la
qualité du réseau quelle que soit sa nature: paquet, canal, IP, MPLS, radio,
pigeons .
Perte
Cette métrique vous indique combien de paquets envoyés par la source ont atteint la destination.
La cause de la perte peut être un problème d'interface / câble, une congestion du réseau, des erreurs de bit qui bloquent les règles ACL.
Ce qu'il faut faire en cas de perte est décidé par l'application. Il peut les ignorer, comme dans le cas d'une conversation téléphonique, où un paquet en retard n'est plus nécessaire, ou le renvoyer - c'est ce que TCP fait pour garantir une livraison précise des données source.

Comment gérer les pertes, si elles sont inévitables, dans le chapitre Gestion de la congestion.
Comment profiter des pertes dans le chapitre Prévention de la congestion.
Retards
C'est le temps que les données doivent passer de la source à la destination.

Le retard cumulé se compose des éléments suivants.
- Délai de sérialisation - le temps qu'il faut à un nœud pour décomposer un paquet en bits et établir une liaison avec le nœud suivant. Elle est déterminée par la vitesse de l'interface. Ainsi, par exemple, le transfert d'un paquet de 1500 octets de taille via une interface de 100 Mb / s prendra 0,0001 s, et pour 56 Kb / s - 0,2 s.
- Le délai de propagation est le résultat de la fameuse limitation de la vitesse de propagation des ondes électromagnétiques. La physique ne vous permet pas de vous rendre de New York à Tomsk à la surface de la planète plus rapidement qu'en 30 ms (en fait, environ 70 ms).
- Les retards introduits par la QoS sont la langueur des paquets dans les files d'attente ( Queuing Delay ) et les conséquences de la mise en forme ( Shaping Delay ). Nous en parlerons beaucoup aujourd'hui dans le chapitre Contrôle de vitesse.
- Retard dans le traitement des paquets ( délai de traitement ) - le temps de décider quoi faire avec le paquet: recherche, ACL, NAT, DPI - et le livrer de l'interface d'entrée à la sortie. Mais le jour où Juniper a séparé le contrôle et le plan de données dans son M40, les retards de traitement pourraient être négligés.
Les retards ne sont pas si mauvais pour les applications où il n'y a pas lieu de se précipiter: partage de fichiers, surf, VoD, stations de radio Internet, etc. Inversement, ils sont critiques pour les interactifs: 200 ms est déjà désagréable à l'oreille lors d'une conversation téléphonique.
Un terme lié au retard qui n'est pas synonyme de
RTT (
Round Trip Time ) est l'aller-retour. Lors du ping et du traçage, vous voyez exactement RTT, et non un délai unidirectionnel, bien que les valeurs aient une corrélation.
Jitter
La différence de délais entre la livraison de paquets consécutifs est appelée gigue.
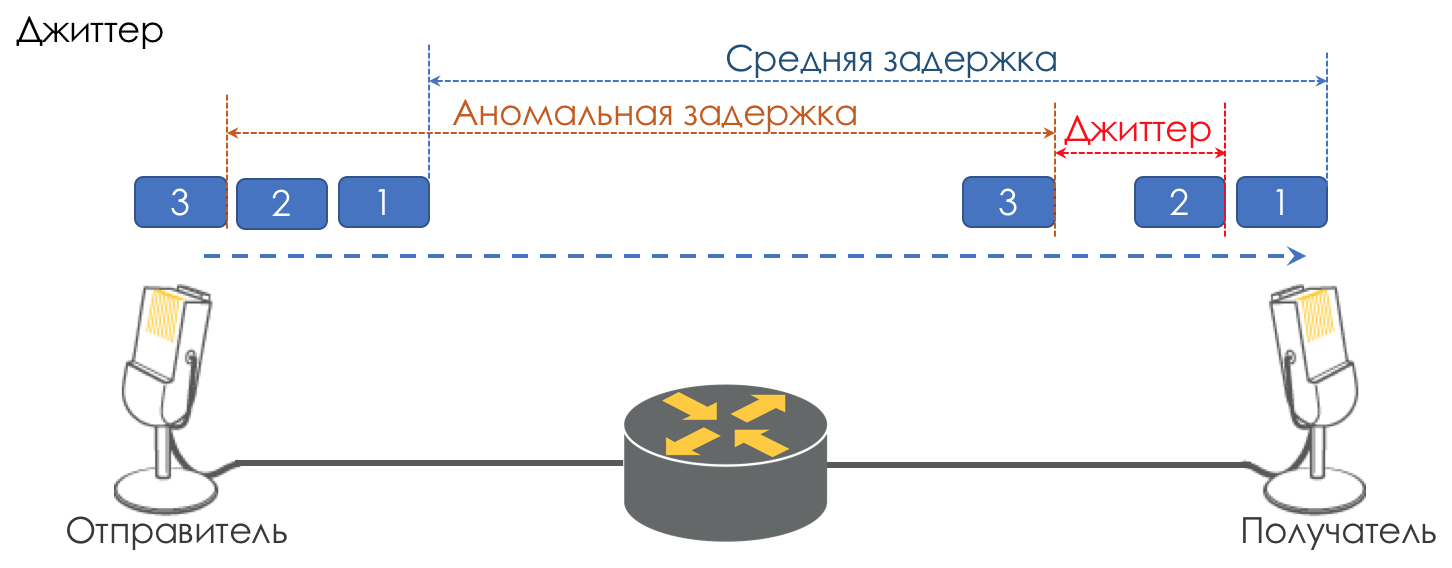
Comme la latence, la gigue n'a pas d'importance pour de nombreuses applications. Et même, il semblerait, quelle est la différence - le colis a été livré, alors quoi de plus?
Cependant, pour les services interactifs, c'est important.
Prenons la même téléphonie comme exemple. En fait, il s'agit d'une numérisation de signaux analogiques avec une division en blocs de données séparés. La sortie est un flux de paquets assez uniforme. Du côté de la réception, il y a un petit tampon d'une taille fixe dans lequel les paquets qui arrivent séquentiellement s'insèrent. Pour restaurer le signal analogique, un certain nombre d'entre eux est nécessaire. Dans des conditions de retards flottants, le prochain bloc de données peut ne pas arriver à l'heure, ce qui équivaut à une perte, et le signal ne peut pas être restauré.
La plus grande contribution à la variabilité des retards est apportée par la seule QoS. C'est aussi beaucoup et fastidieux dans les mêmes chapitres Speed Limit.
Ce sont les trois principales caractéristiques de la qualité du réseau, mais il y en a deux autres qui jouent également un rôle important.
Livraison aléatoire
Un certain nombre d'applications, telles que la téléphonie,
NAS ,
CES, sont extrêmement sensibles à la livraison aléatoire de paquets lorsqu'ils arrivent chez le destinataire dans le mauvais ordre dans lequel ils ont été envoyés. Cela peut entraîner une perte de connectivité, des erreurs, des dommages au système de fichiers.
Bien que la livraison aléatoire ne soit pas une fonction QoS formelle, elle fait définitivement référence à la qualité du réseau.
Même avec TCP tolérant ce type de problème, des ACK et des retransmissions en double se produisent.

Bande passante
Il ne se distingue pas comme une mesure de la qualité du réseau, car en fait son inconvénient se traduit par les trois ci-dessus. Cependant, dans nos réalités, quand il devrait être garanti pour certaines applications ou, au contraire, il devrait être limité par contrat, par exemple, MPLS TE le réserve tout au long du LSP, il convient de le mentionner, au moins comme une métrique faible.
Les mécanismes de contrôle de la vitesse seront abordés dans les chapitres Limite de vitesse.
Pourquoi les spécifications peuvent-elles mal tourner?
Ainsi, nous commençons avec une idée très primitive qu'un périphérique réseau (qu'il s'agisse d'un commutateur, d'un routeur, d'un pare-feu, peu importe) n'est qu'un autre morceau de tuyau appelé canal de communication, comme un fil de cuivre ou un câble optique.

Ensuite, tous les paquets transitent dans le même ordre dans lequel ils sont arrivés et ne subissent aucun retard supplémentaire - il n'y a nulle part où s'attarder.
Mais en fait, chaque routeur restaure les bits et les paquets du signal, fait quelque chose avec eux (nous n'y pensons pas encore) puis reconvertit les paquets en signal.
Un délai de sérialisation apparaît. Mais en général, ce n'est pas effrayant car c'est constant. Pas effrayant tant que la largeur de l'interface de sortie est supérieure à l'entrée.
Par exemple, à l'entrée de l'appareil se trouve un port gigabit et à la sortie une ligne de relais radio de 620 Mb / s connectée au même port gigabit?
Personne n'interdira les balles via le trafic gigabit de liaison formellement gigabit.
Il n'y a rien à faire - 380 Mb / s se déverseront sur le sol.
Les voici: des pertes.
Mais en même temps, j'aimerais beaucoup que la pire partie soit perdue - une vidéo de YouTube, et la conversation téléphonique du directeur exécutif avec le directeur de l'usine n'a pas interrompu ni même coassé.
J'aimerais que la voix ait une ligne dédiée.
Ou il y a cinq interfaces d'entrée, mais une sortie, et en même temps, cinq nœuds ont commencé à essayer d'injecter du trafic vers un destinataire.
Ajoutez une pincée de théorie VoIP (un article sur lequel personne n'a écrit) - il est très sensible aux retards et à leurs variations.
Si pour un flux TCP de vidéo à partir de YouTube (au moment de la rédaction de l'article
QUIC - cela reste encore une expérience), les retards, même en quelques secondes, sont totalement sans valeur en raison de la mise en mémoire tampon, alors le directeur après la première conversation de ce type avec le Kamchatka appellera le chef du service technique.
Autrefois, lorsque l'auteur du cycle faisait toujours ses devoirs le soir, le problème était particulièrement aigu. Les connexions par modem avaient une
vitesse de 56k .
Et lorsqu'un paquet de 1,5 K est entré dans une telle connexion, il a occupé toute la ligne pendant 200 ms. Personne d'autre ne pouvait passer en ce moment. Une voix? Non, je n'ai pas entendu.
Par conséquent, la question MTU est si importante - le paquet ne devrait pas occuper l'interface trop longtemps. Plus la vitesse est faible, plus le MTU est bas.
Les voici - des retards.
Maintenant, la chaîne est gratuite et le délai est faible, après une seconde, quelqu'un a commencé à télécharger un gros fichier et les délais ont augmenté. Le voici - la gigue.
Ainsi, il est nécessaire que les paquets vocaux volent à travers le tuyau avec des délais minimaux, et YouTube attendra.
Les 620 Mb / s disponibles doivent être utilisés pour la voix, la vidéo et pour les clients B2B achetant des VPN. J'aimerais qu'un trafic n'oppose pas l'autre, nous avons donc besoin d'une garantie de bande.
Toutes les caractéristiques ci-dessus sont universelles en ce qui concerne la nature du réseau. Cependant, il existe trois approches différentes de leur fourniture.
2. Trois modèles de QoS
- Meilleur effort - aucune garantie de qualité. Tous sont égaux.
- IntServ est une garantie de qualité pour chaque flux. Réserver des ressources de la source à la destination.
- DiffServ - Il n'y a pas de réservation. Chaque nœud détermine lui-même comment garantir la bonne qualité.
Meilleur effort (BE)
Aucune garantie.L'approche la plus simple pour implémenter la QoS, à partir de laquelle les réseaux IP ont commencé et est toujours pratiquée à ce jour - parfois parce qu'elle est suffisante, mais le plus souvent parce que personne n'a pensé à la QoS.
Soit dit en passant, lorsque vous envoyez du trafic vers Internet, il y sera traité comme BestEffort. Par conséquent, via un VPN déployé sur Internet (par opposition à un VPN fourni par le fournisseur), le trafic important, comme une conversation téléphonique, peut ne pas être très confiant.
Dans le cas de BE, toutes les catégories de trafic sont égales, aucune préférence n'est donnée à aucune. En conséquence, il n'y a aucune garantie de retard / gigue ou bande.
Cette approche a un nom quelque peu contre-intuitif - Best Effort, que le nouveau venu induit en erreur avec le mot «best».
Cependant, l'expression «je ferai de mon mieux» signifie que l'orateur essaiera de faire tout ce qui peut, mais ne garantit rien.
Rien n'est requis pour implémenter BE - c'est le comportement par défaut. La fabrication est bon marché, le personnel n'a pas besoin de connaissances spécifiques approfondies, la qualité de service dans ce cas ne peut pas être personnalisée.
Cependant, cette simplicité et cette statique ne conduisent pas au fait que l'approche Best Effort n'est utilisée nulle part. Il trouve une application dans les réseaux à large bande passante et sans congestion et rafales.
Par exemple, sur les lignes transcontinentales ou dans les réseaux de certains centres de données où il n'y a pas de sursouscription.
En d'autres termes, dans les réseaux sans congestion et où il n'est pas nécessaire de se rapporter à un trafic (par exemple, la téléphonie) d'une manière spéciale, BE est tout à fait approprié.
Interv.
Réservation préalable des ressources pour le flux de la source à la destination.Les pères des réseaux MIT, Xerox et ISI ont décidé d'ajouter l'élément de prévisibilité à l'Internet aléatoire grandissant, tout en maintenant son opérabilité et sa flexibilité.
Ainsi, en 1994, l'idée d'IntServ est née en réponse à la croissance rapide du trafic en temps réel et au développement de la multidiffusion. Il a ensuite été réduit à IS.
Le nom reflète la volonté du même réseau de fournir simultanément des services pour les types de trafic en temps réel et non en temps réel, offrant le droit prioritaire d'utiliser les ressources par la réservation de la bande. La possibilité de réutiliser le groupe sur lequel tout le monde gagne de l'argent, et grâce à laquelle la prise de vue IP, a été préservée.
La mission de sauvegarde a été attribuée au protocole RSVP, qui pour
chaque flux réserve une bande sur
chaque périphérique réseau.
En gros, avant de configurer une session Single Rate Three Color MarkerP ou de commencer l'échange de données, les hôtes finaux envoient le chemin RSVP avec la bande passante requise. Et si les deux ont renvoyé RSVP Resv - ils peuvent commencer à communiquer. En même temps, s'il n'y a pas de ressources disponibles, RSVP renvoie une erreur et les hôtes ne peuvent pas communiquer ou suivre BE.
Laissons maintenant les lecteurs les plus courageux imaginer qu'une chaîne sera signalée à l'avance pour
n'importe quel flux sur Internet aujourd'hui. Étant donné que cela nécessite des coûts de processeur et de mémoire non nuls à
chaque nœud de transit, retarde l'interaction réelle pendant un certain temps, il devient clair pourquoi IntServ s'est avéré être une idée pratiquement morte - une évolutivité nulle.
Dans un sens, l'incarnation moderne d'IntServ est MPLS TE avec une version d'étiquetage adaptée de RSVP - RSVP TE. Bien qu'ici, bien sûr, pas de bout en bout et non par flux.
IntServ est décrit dans
RFC 1633 .
Le document est, en principe, curieux d'évaluer à quel point vous pouvez être naïf dans les prévisions.
Diffserv
DiffServ est compliqué.Lorsqu'il est devenu clair à la fin des années 90 que l'approche IP IntServ de bout en bout a échoué, l'IETF a convoqué le groupe de travail sur les services différenciés en 1997, qui a élaboré les exigences suivantes pour le nouveau modèle de QoS:
- Pas de signalisation (Adjos, RSVP!).
- Basé sur une classification de trafic agrégée, au lieu de se concentrer sur les flux, les clients, etc.
- Il dispose d'un ensemble d'actions limité et déterministe pour le traitement du trafic de données des classes.
En conséquence, le
RFC 2474 (
Définition du champ des services différenciés (champ DS) dans les en-têtes IPv4 et IPv6 ) et le
RFC 2475 (
Une architecture pour les services différenciés ) sont nés en 1998.
Et plus loin, nous ne parlerons que de DiffServ.
Il convient de noter que le nom DiffServ n'est pas l'antithèse d'IntServ. Cela signifie que nous différencions les services fournis par diverses applications, ou plutôt leur trafic, en d'autres termes, nous partageons / différencions ces types de trafic.
IntServ fait de même - il distingue les types de trafic BE et en temps réel, transmis sur le même réseau. Les deux: et IntServ et DiffServ - font référence aux façons de différencier les services.
3. Mécanismes DiffServ
Qu'est-ce que DiffServ et pourquoi bat-il IntServ?
Si c'est très simple, le trafic est divisé en classes. Un package à l'entrée de chaque nœud est classé et un ensemble d'outils lui est appliqué, qui traite les packages de différentes classes de différentes manières, leur fournissant ainsi un niveau de service différent.
Mais ce ne
sera tout simplement
pas .
Au cœur de DiffServ se trouve le concept IP IP
PHB parfaitement assaisonné
- Comportement par bond . Chaque nœud sur le chemin de trafic prend indépendamment une décision sur la façon de se comporter par rapport au paquet entrant, en fonction de ses en-têtes.
Les actions du routeur de paquets seront appelées le modèle de comportement. Le nombre de ces modèles est déterministe et limité. Sur différents appareils, les modèles de comportement par rapport au même trafic
peuvent différer, ils sont donc par saut.
Les concepts de comportement et de PHB que j'utiliserai dans l'article comme synonymes.Il y a une légère confusion. PHB est, d'une part, le concept général de comportement indépendant de chaque nœud, et d'autre part, un modèle spécifique sur un nœud particulier. Avec cela, nous allons le découvrir.

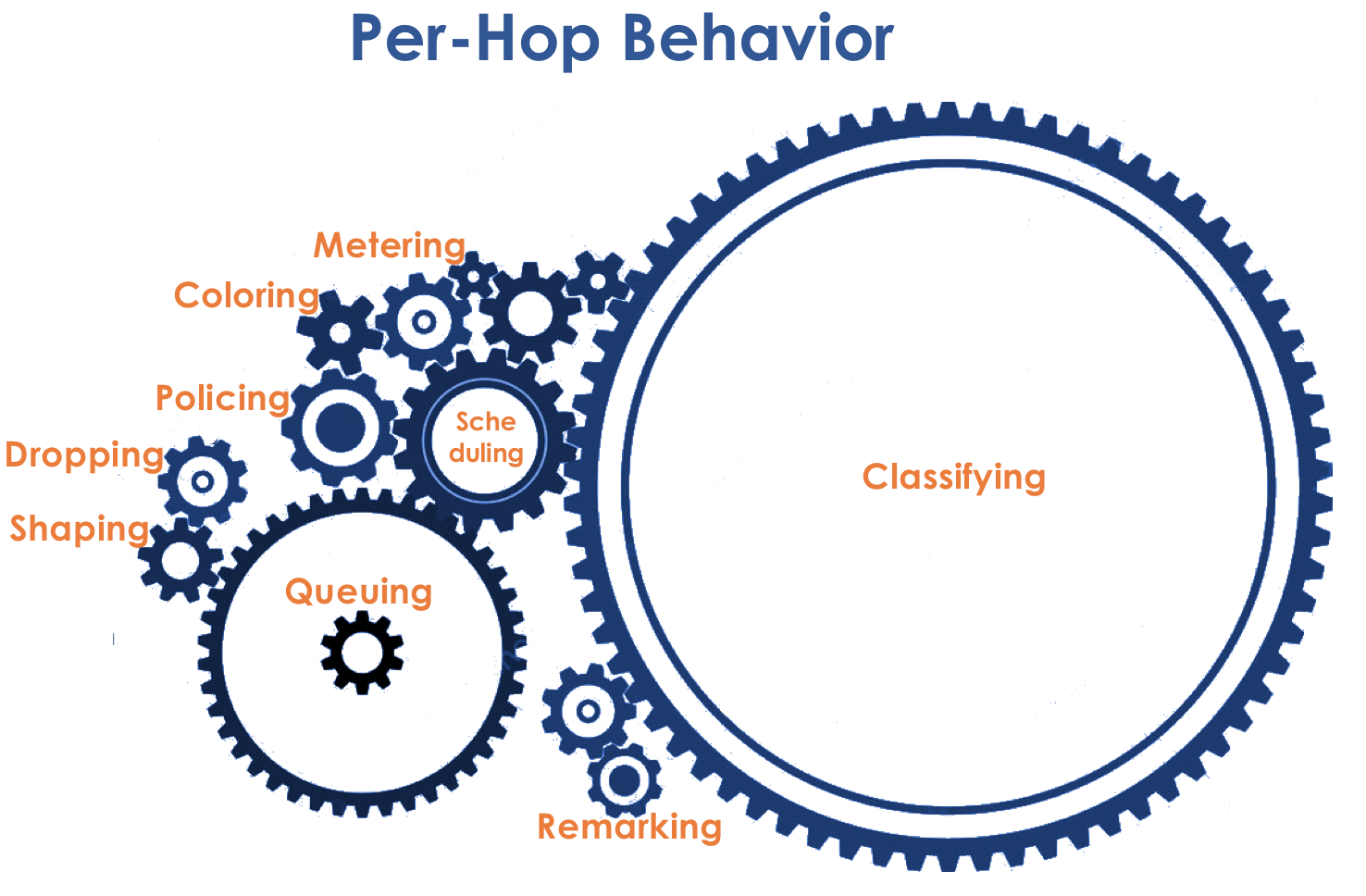
Le modèle de comportement est déterminé par un ensemble d'outils et leurs paramètres: maintien de l'ordre, suppression, mise en file d'attente, planification, mise en forme.
En utilisant les modèles de comportement disponibles, le réseau peut fournir différentes classes de service (
classe de service ).
C'est-à-dire que différentes catégories de trafic peuvent recevoir différents niveaux de service sur le réseau en leur appliquant différents PHB.
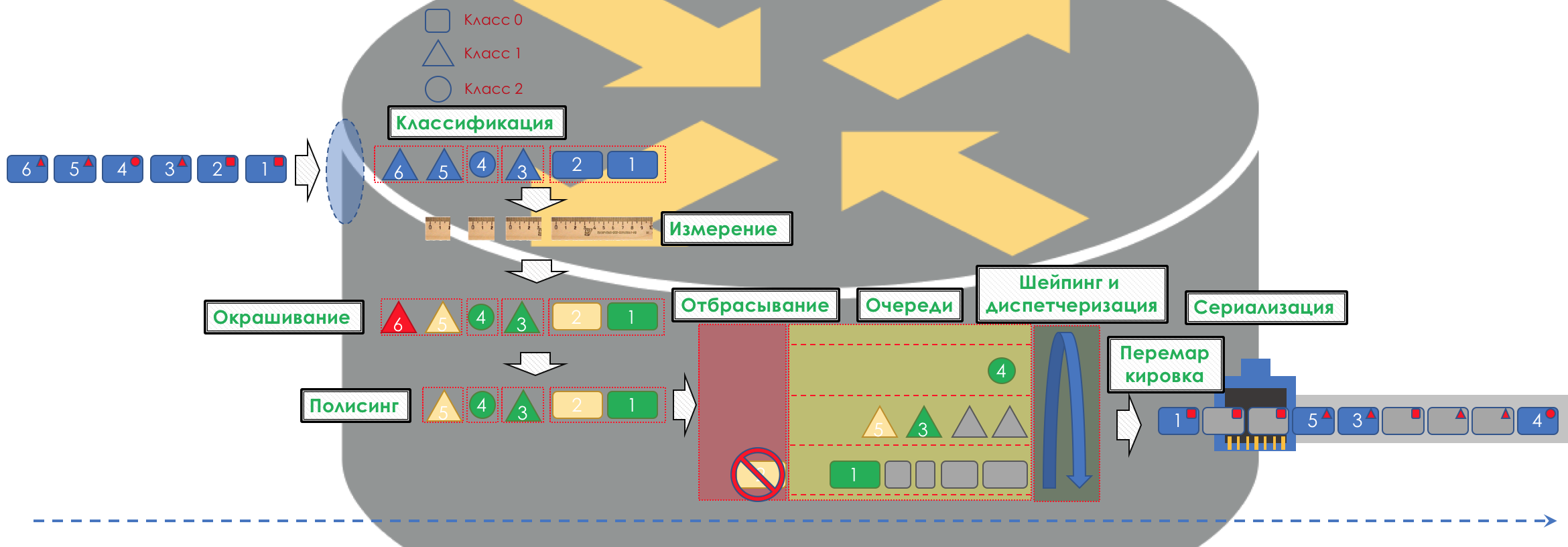
En conséquence, tout d'abord, vous devez déterminer à quelle classe de trafic de service se réfère -
Classification .
Chaque nœud classe indépendamment les paquets entrants.

Après la classification, une mesure se produit (
mesure ) - combien de bits / octets de trafic de cette classe sont arrivés au routeur.
Sur la base des résultats, les emballages peuvent être peints (
coloration ): vert (dans la limite établie), jaune (hors de la limite), rouge (complètement séduit la côte).
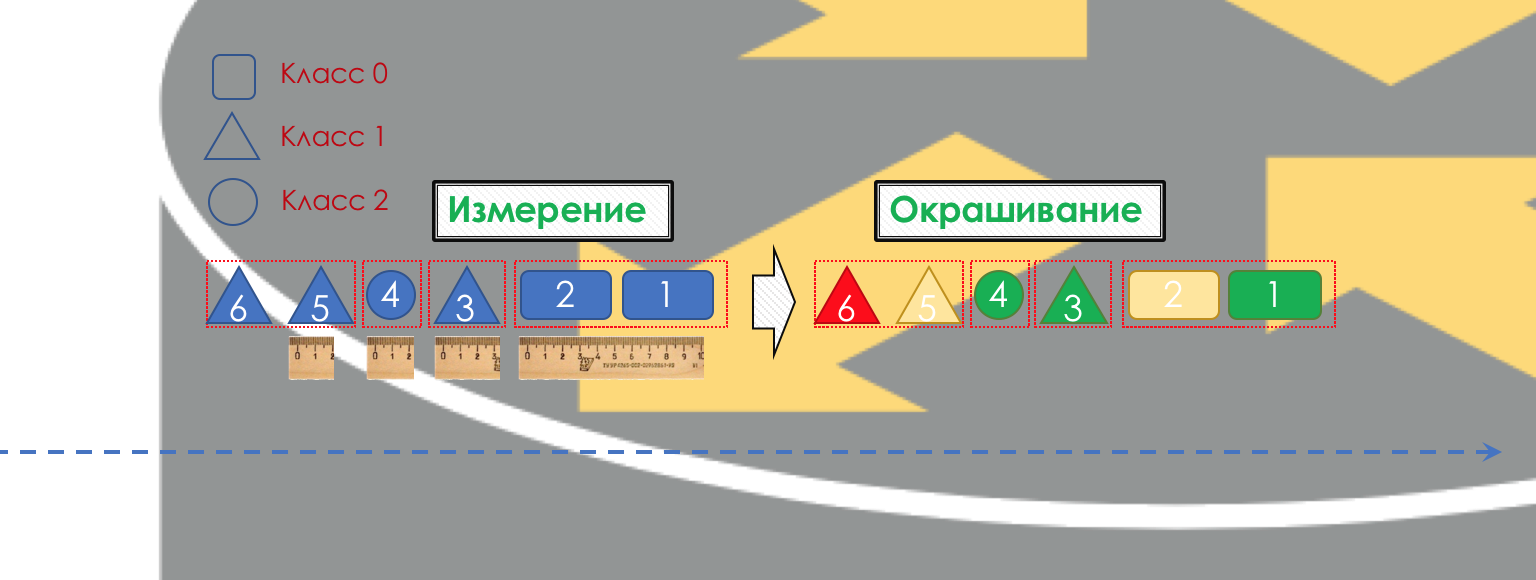
Si nécessaire, la
police a lieu (désolé pour un tel calque, il y a une meilleure option - écrivez, je vais changer). Un polisseur basé sur la couleur d'un paquet attribue une action au paquet - transmettre, éliminer ou re-marquer.
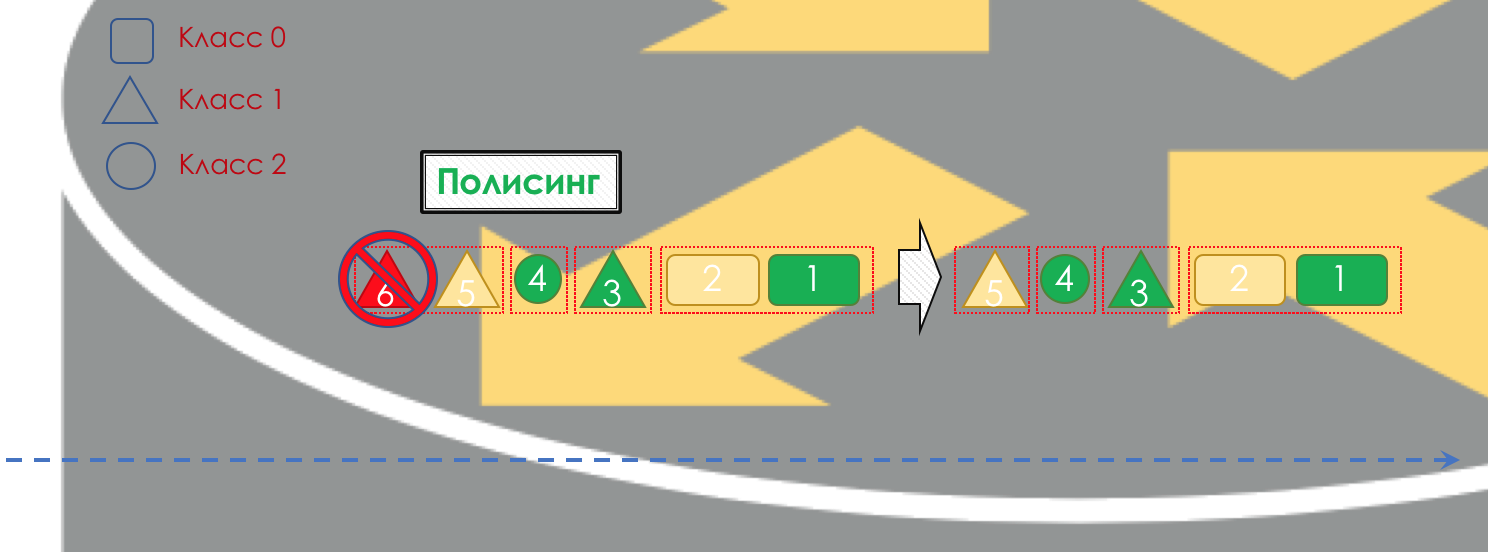
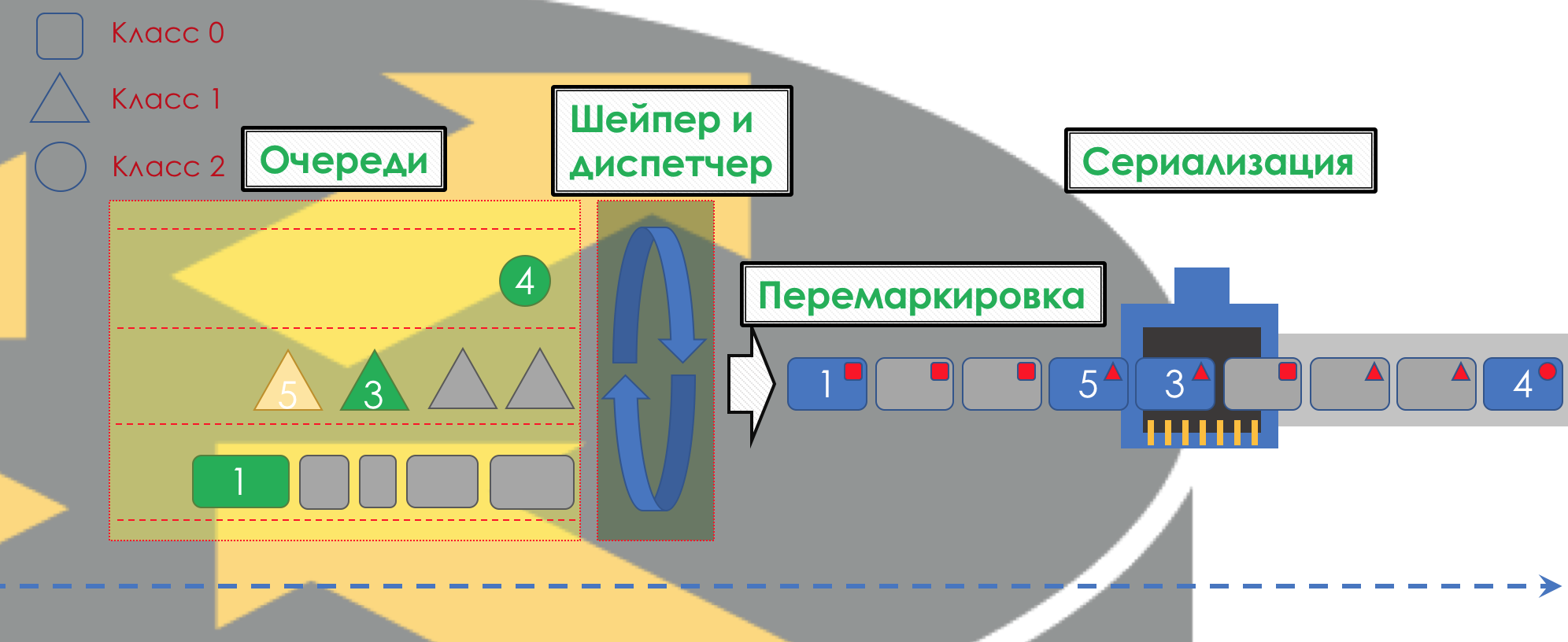
Après cela, le paquet devrait tomber dans l'une des files d'attente (
file d'attente ). Une file d'attente distincte est allouée pour chaque classe de service, ce qui permet de les différencier à l'aide de PHB différents.
Mais avant même que le paquet n'entre dans la file d'attente, il peut être supprimé (
Dropper ) si la file d'attente est pleine.
S'il est vert, il passera, s'il est jaune, il sera probablement rejeté si la ligne est pleine et si le rouge est un kamikaze sûr. Conditionnellement, la probabilité de chute dépend de la couleur du paquet et de la plénitude de la file d'attente où il va se rendre.
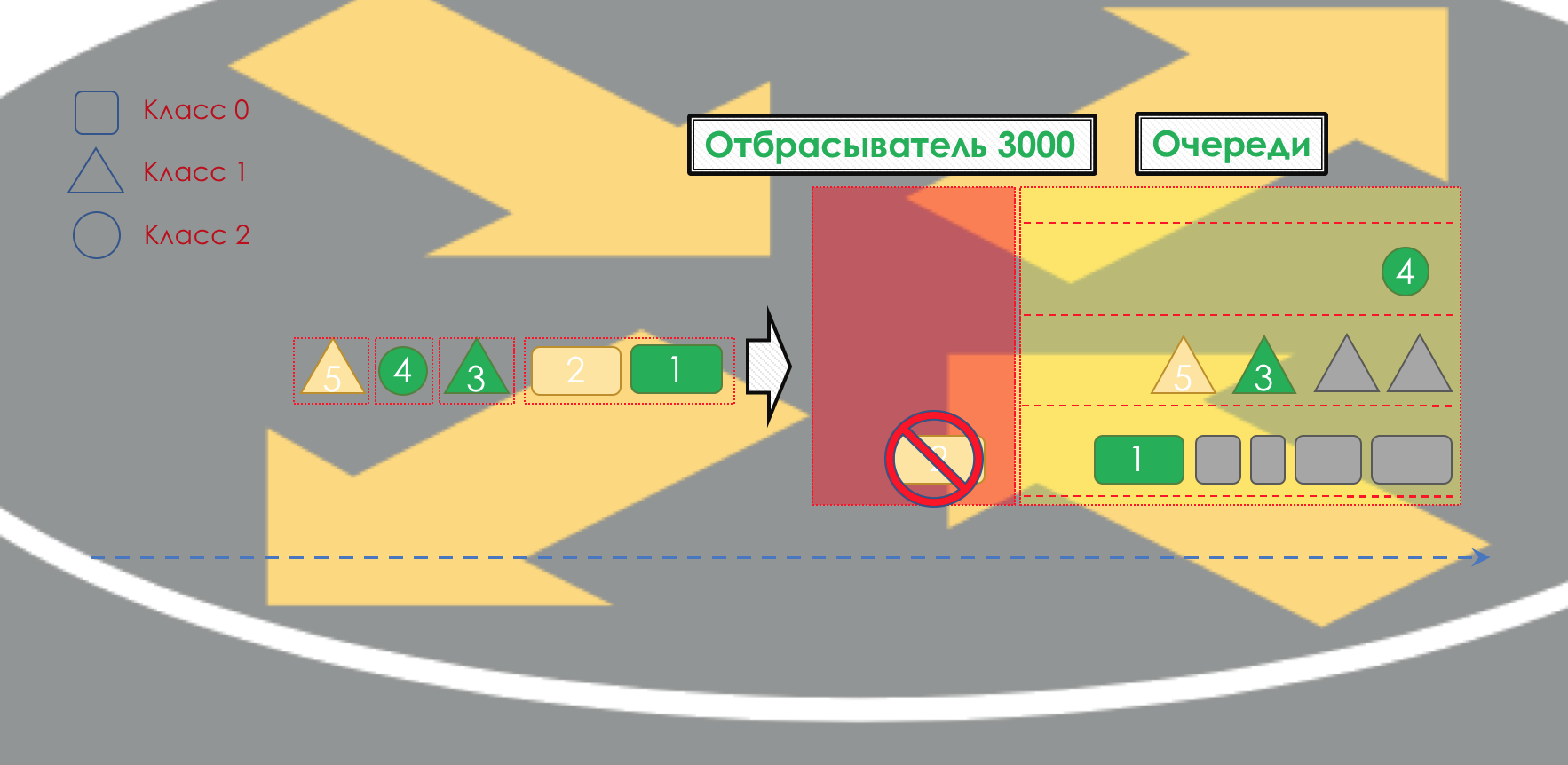
À la sortie de la file d'attente, un
Shaper fonctionne, dont la tâche est très similaire à la tâche du polyser - pour limiter le trafic à une valeur donnée.
Vous pouvez configurer des shapers arbitraires pour des files d'attente individuelles, ou même au sein de files d'attente.
Sur la différence entre un shaper et un polyser dans le chapitre Speed Limit.
Toutes les files d'attente devraient finalement fusionner en une seule interface de sortie.
Rappelez-vous la situation lorsque sur la route 8 voies fusionnent en 3. Sans contrôleur de circulation, cela se transforme en chaos. La séparation à son tour n'aurait pas de sens si nous avions la même sortie que l'entrée.
Par conséquent, il existe un répartiteur spécial (
Scheduler ), qui supprime cycliquement les paquets de différentes files d'attente et les envoie à l'interface (
Scheduling ).
En fait, une combinaison d'un ensemble de files d'attente et d'un répartiteur est le mécanisme de QoS le plus important qui vous permet d'appliquer différentes règles à différentes classes de trafic, l'une offrant une large bande passante, l'autre une faible latence, le troisième manque de pertes.
Ensuite, les paquets vont déjà à l'interface, où les paquets sont convertis en un flux binaire - sérialisation (
sérialisation ) puis le signal d'environnement.
Dans DiffServ, le comportement de chaque nœud est indépendant des autres; il n'y a aucun protocole de signalisation qui indiquerait quelle politique de QoS se trouve sur le réseau. Dans le même temps, au sein du réseau, je souhaite que le trafic soit géré de la même manière. Si un seul nœud se comporte différemment, l'intégralité de la politique de QoS est perdue.
Pour cela, d'une part, sur tous les routeurs, les mêmes classes et PHB sont configurés pour eux, et d'autre part, le
Marquage du paquet est utilisé - son appartenance à une classe particulière est enregistrée dans l'en-tête (IP, MPLS, 802.1q).
Et la beauté de DiffServ est que le nœud suivant peut s'appuyer sur cette étiquette pour la classification.
Une telle zone de confiance, dans laquelle les mêmes règles de classification du trafic et les mêmes comportements s'appliquent, est appelée le domaine
DiffServ (
DiffServ-Domain ).

Ainsi, à l'entrée du domaine DiffServ, nous pouvons classer un package basé sur 5-Tuple ou une interface, le marquer (
Remark / Rewrite ) selon les règles du domaine, et d'autres nœuds feront confiance à ce marquage et ne feront pas de classification complexe.
Autrement dit, il n'y a pas de signalisation explicite dans DiffServ, mais le nœud peut indiquer à tous les éléments suivants quelle classe ce paquet doit être fourni, en attendant qu'il soit approuvé.
Aux jonctions entre les domaines DiffServ, vous devez négocier (ou non) des politiques de QoS.
L'image entière ressemblera à ceci:
Pour que ce soit clair, je vais donner un analogue de la vie réelle.
Vol en avion (pas Victoire).
Il existe trois classes de services (CoS): Économie, Affaires, Première.
Lors de l'achat d'un billet, la classification a lieu - le passager reçoit une certaine classe de service en fonction du prix.
À l'aéroport, il y a un marquage (Remarque) - un billet est émis indiquant la classe.
Il existe deux comportements (PHB): Best Effort et Premium.
Il existe des mécanismes qui mettent en œuvre des comportements: une salle d'attente commune ou un salon VIP, un minibus ou un bus partagé, de grands sièges confortables ou des rangées étroites, le nombre de passagers par agent de bord, la possibilité de commander de l'alcool.
Selon la classe, des modèles de comportement sont attribués - à l'économie Best Effort, à Business - Premium Basic et à First - Premium SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HYPER-MEGA-MULTI-ALPHA-META-EXTRA-UBER-PREFIX!
En même temps, deux primes diffèrent en ce que, dans l'une, elles donnent un verre de demi-sucré, et dans l'autre, elles ont un Bacardi illimité.
Puis, à l'arrivée à l'aéroport, tout le monde passe par une porte. Ceux qui ont essayé d'apporter des armes avec eux ou qui n'ont pas de ticket ne sont pas autorisés (Drop). Les affaires et l'économie entrent dans des salles d'attente et des transports différents (Queuing). D'abord, ils ont laissé la First Class à bord, puis les affaires, puis l'économie (la planification), puis ils ont tous volé vers leur destination avec un seul avion (interface).
Dans le même exemple, un vol en avion est un retard de propagation, l'atterrissage est un retard de sérialisation, l'attente d'un avion dans les couloirs est en file d'attente et le contrôle des passeports est en cours de traitement. Notez qu'ici, le délai de traitement est généralement négligeable en termes de temps total.
Le prochain aéroport peut traiter les passagers d'une manière complètement différente - son PHB est différent. Mais en même temps, si le passager ne change pas de compagnie aérienne, l'attitude envers lui ne changera probablement pas, car une entreprise est un domaine DiffServ.
Comme vous l'avez peut-être remarqué, DiffServ est extrêmement (ou infiniment) complexe. Mais nous analyserons tout ce qui est décrit ci-dessus. Dans le même temps, dans l'article je n'entrerai pas dans les nuances de l'implémentation physique (elles peuvent différer même sur deux cartes du même routeur), je ne parlerai pas de HQoS et MPLS DS-TE.
Le seuil pour entrer dans le cercle des ingénieurs qui comprennent la technologie de QoS est beaucoup plus élevé que pour les protocoles de routage, MPLS ou, pardonnez-moi, Radya, STP.
Malgré cela, DiffServ a gagné la reconnaissance et la mise en œuvre sur les réseaux du monde entier, car, comme on dit, très évolutif.
Dans le reste de cet article, je n'analyserai que DiffServ.
Ci-dessous, nous analyserons tous les outils et processus indiqués dans l'illustration.
Au cours de l'élargissement du sujet, je montrerai certaines choses dans la pratique.
Nous travaillerons avec un tel réseau:
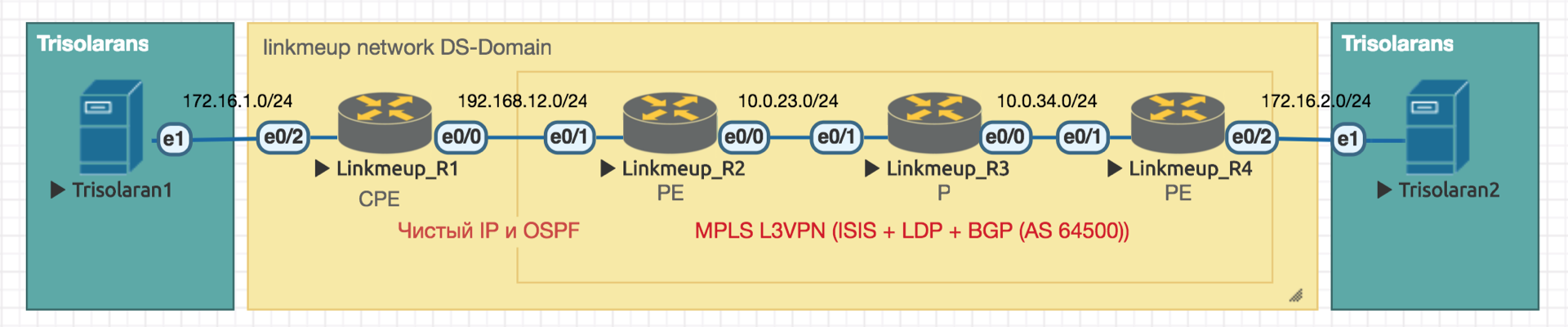
Trisolarans est un client fournisseur de liens avec deux points de connexion.
La zone jaune est le domaine DiffServ du réseau linkmeup, où une seule politique QoS est en vigueur.
Linkmeup_R1 est un appareil CPE géré par le fournisseur, et donc dans une zone de confiance. OSPF est soulevé avec lui et l'interaction a lieu via une IP propre.
Au cœur du réseau se trouvent MPLS + LDP + MP-BGP avec L3VPN, étiré de Linkmeup_R2 à Linkmeup_R4.
Je ferai tous les autres commentaires nécessaires.
Le fichier de configuration initial .
4. Classification et étiquetage
Au sein de son réseau, l'administrateur définit les classes de service auxquelles il peut fournir du trafic.
Par conséquent, la première chose que fait chaque nœud lorsqu'il reçoit un paquet est de le classer.
Il existe trois façons:
- Agrégat de comportement ( BA )
Faites simplement confiance à l'étiquette de package existante dans son en-tête. Par exemple, le champ IP DSCP.
Il est appelé ainsi car sous la même étiquette dans le champ DSCP, diverses catégories de trafic sont agrégées qui attendent le même comportement par rapport à elles-mêmes. Par exemple, toutes les sessions SIP seront regroupées en une seule classe.
Le nombre de classes de service possibles, et donc les modèles de comportement, est limité. En conséquence, il est impossible pour chaque catégorie (ou plus encore pour le flux) de séparer une classe distincte - il est nécessaire de l'agréger. - Basé sur l'interface
Tout ce qui vient à une interface particulière doit être placé dans une classe de trafic. Par exemple, nous savons avec certitude que le serveur de base de données est connecté à ce port et rien de plus. Et dans un autre poste de travail des employés. - MultiField ( MF )
Analysez les champs d'en-tête de paquet - adresses IP, ports, adresses MAC. De manière générale, des champs arbitraires.
Par exemple, tout le trafic qui va vers le sous-réseau 10.127.721.0/24 sur le port 5000 doit être marqué comme trafic, nécessitant conditionnellement la 5e classe de service.
L'administrateur détermine l'ensemble des classes de service que le réseau peut fournir et leur mappe une valeur numérique.
A l'entrée du domaine DS, nous ne faisons confiance à personne, le classement s'effectue donc de la deuxième ou troisième manière: en fonction des adresses, protocoles ou interfaces, la classe de service et la valeur numérique correspondante sont déterminées.
À la sortie du premier nœud, ce chiffre est codé dans le champ DSCP de l'en-tête IP (ou un autre champ de la classe de trafic: classe de trafic MPLS, classe de trafic IPv6, Ethernet 802.1p) - une remarque se produit.
Il est habituel de faire confiance à cet étiquetage à l'intérieur du domaine DS, par conséquent, les nœuds de transit utilisent la première méthode de classification (BA) - la plus simple. Aucune analyse de cap compliquée, il suffit de regarder le nombre enregistré.
À la jonction de deux domaines, vous pouvez classer en fonction d'une interface ou MF, comme je l'ai décrit ci-dessus, ou vous pouvez faire confiance au marquage BA avec des réserves.
Par exemple, faites confiance à toutes les valeurs à l'exception de 6 et 7 et réaffectez 6 et 7 à 5.
Cette situation est possible lorsque le fournisseur connecte une entité juridique qui a sa propre politique d'étiquetage. Le fournisseur n'a pas d'objection à l'enregistrer, mais ne souhaite pas que le trafic tombe dans la classe dans laquelle il reçoit les paquets de protocole réseau.
Agrégation de comportements
BA utilise une classification très simple - je vois un nombre - je comprends la classe.
Alors quel est le chiffre? Et dans quel domaine est-il enregistré?
- Classe de trafic IPv6
- Classe de trafic MPLS
- Ethernet 802.1p
La classification est principalement basée sur l'en-tête de commutation.
J'appelle un en-tête de navettage sur la base duquel l'appareil détermine où envoyer le paquet afin qu'il se rapproche du destinataire.Autrement dit, si un paquet IP arrive sur le routeur, l'en-tête IP et le champ DSCP sont analysés. Si MPLS arrive, il est analysé - MPLS Traffic Class.
Si un paquet Ethernet + VLAN + MPLS + IP est arrivé à un commutateur L2 normal, alors 802.1p sera analysé (bien que cela puisse être modifié).
IPv4 TOS
Le champ QoS nous accompagne exactement autant que l'IP. Le champ TOS à huit bits - Type de service - était censé porter la priorité du paquet.
Même avant l'avènement de DiffServ, la
RFC 791 (
INTERNET PROTOCOL ) décrivait le domaine comme ceci:
Priorité IP (IPP) + DTR + 00.
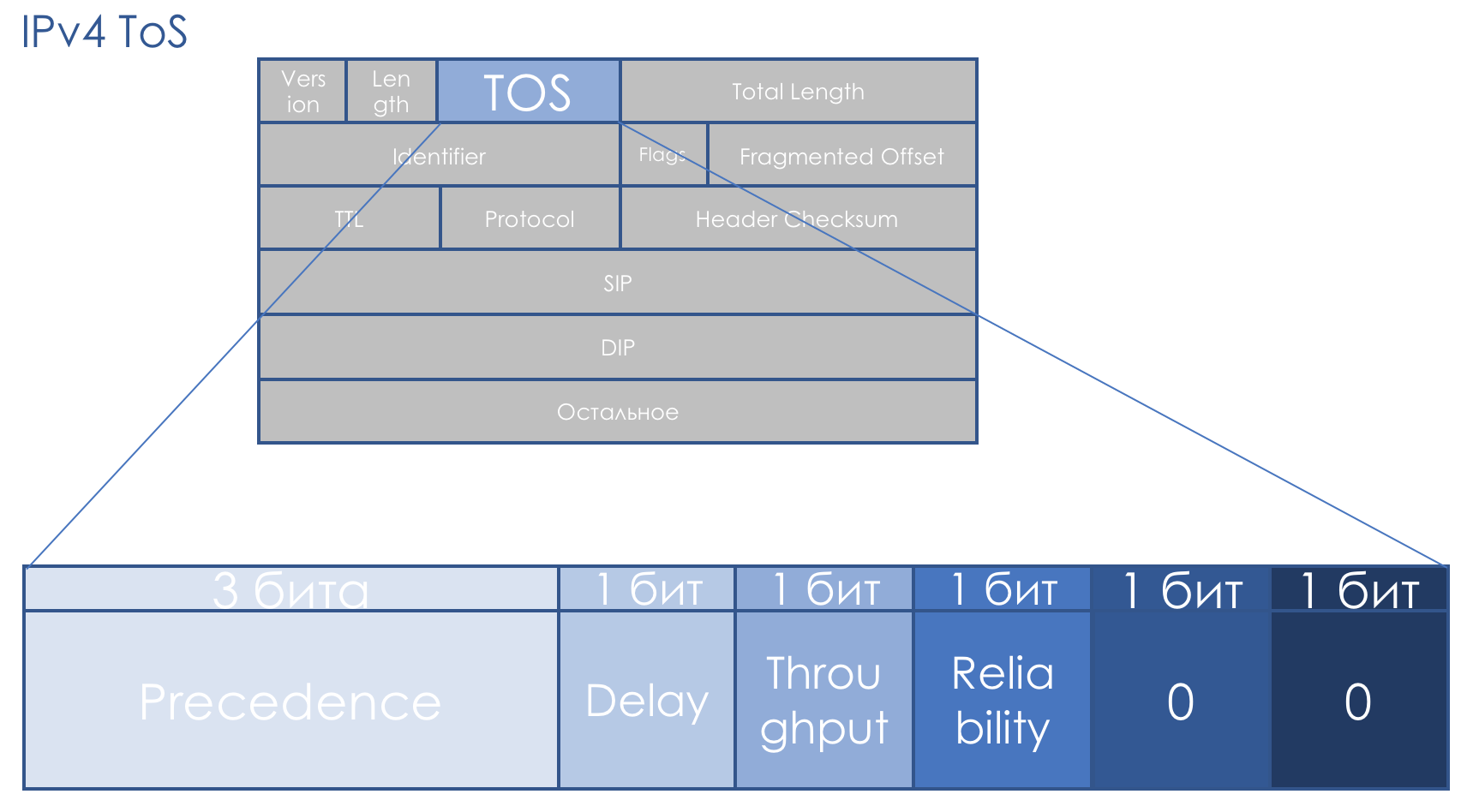
Autrement dit, la priorité du package va, puis les bits d'exactitude au délai, au débit, à la fiabilité (0 - sans exigences, 1 - avec exigences).
Les deux derniers bits doivent être nuls.
La priorité a déterminé les valeurs suivantes ...111 - Contrôle du réseau
110 - Contrôle interréseau
101 - CRITIQUE / ECP
100 - Contournement du flash
011 - Flash
010 - Immédiat
001 - Priorité
000 - Routine
Plus tard dans la
RFC 1349 (
Type de service dans Internet Protocol Suite ), le champ TOS a été légèrement redéfini:
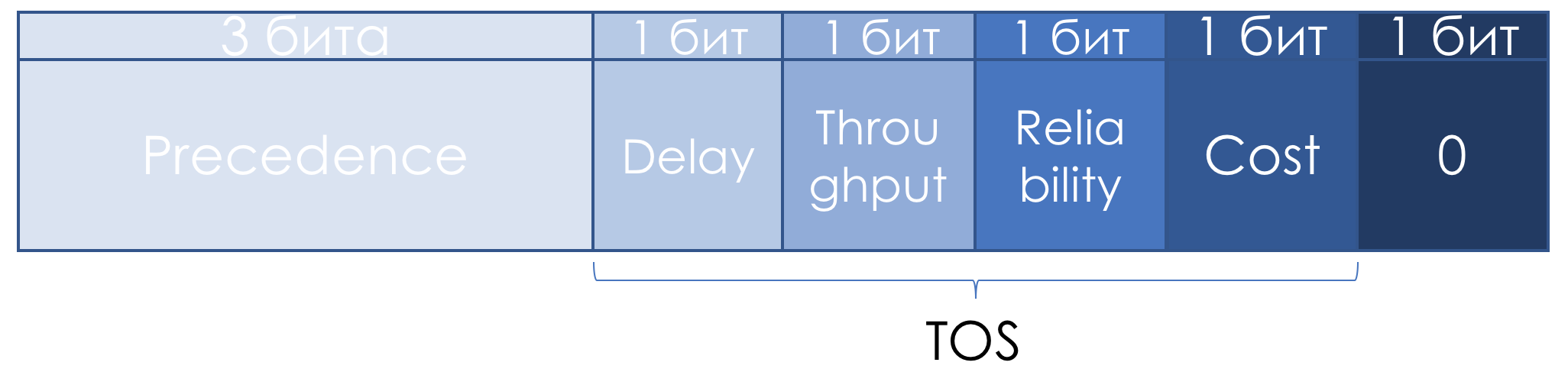
Les trois bits de gauche sont restés IP Precedence, les quatre suivants se sont transformés en TOS après avoir ajouté le bit Cost.
Voici comment lire les unités dans ces bits TOS:
- D - «minimiser le délai»,
- T - "maximiser le débit",
- R - "maximiser la fiabilité",
- C - «minimiser les coûts».
Les descriptions floues n'ont pas contribué à la popularité de cette approche.
Il n'y avait pas d'approche systématique de la QoS tout au long du chemin, il n'y avait pas de recommandations claires sur la façon d'utiliser le champ prioritaire, la description des bits de retard, de débit et de fiabilité était extrêmement vague.
Par conséquent, dans le contexte de DiffServ, le champ TOS a de nouveau été redéfini dans la
RFC 2474 (
Définition du champ Services différenciés (champ DS) dans les en-têtes IPv4 et IPv6 ):

Au lieu des bits IPP et DTRC, le champ DSCP à six bits -
Point de code des services différenciés a été introduit, les deux bits de droite n'ont pas été utilisés.
À partir de ce moment, c'est le champ DSCP qui aurait dû devenir le marquage principal de DiffServ: une certaine valeur (code) y est écrite, qui, dans le domaine DS, caractérise la classe de service spécifique requise par le package et sa priorité de suppression. C'est le même chiffre.
L'administrateur peut utiliser les 6 bits de DSCP comme bon lui semble, partageant jusqu'à un maximum de 64 classes de service.
Cependant, dans un souci de compatibilité avec la priorité IP, ils ont conservé le rôle de sélecteur de classe pour les trois premiers bits.
Autrement dit, comme dans IPP, 3 bits de sélecteur de classe vous permettent de définir 8 classes.

Cependant, ce n'est rien de plus qu'un arrangement que, dans les limites de son domaine DS, l'administrateur peut facilement ignorer et utiliser les 6 bits à sa discrétion.
De plus, je note également que selon les recommandations de l'IETF, plus la valeur enregistrée dans le CS est élevée, plus ce trafic vers le service est exigeant.
Mais cela ne doit pas être considéré comme une vérité indéniable.
Si les trois premiers bits définissent la classe de trafic, les trois suivants sont utilisés pour indiquer la priorité de suppression de paquets (priorité de suppression ou
priorité de perte de paquets - PLP ).
Huit classes - est-ce beaucoup ou peu? À première vue, ce n'est pas suffisant - après tout, il y a tellement de trafic différent sur le réseau que l'on veut distinguer chaque protocole par classe. Cependant, il s'avère que huit suffisent pour tous les scénarios possibles.
Pour chaque classe, vous devez définir un PHB qui le gérera différemment des autres classes.
Et avec une augmentation du diviseur, le dividende (ressource) n'augmente pas.
Je ne parle pas délibérément des valeurs exactes de la classe de trafic qu'ils décrivent, car il n'y a pas de normes et vous pouvez les utiliser officiellement à votre discrétion. Ci-dessous, je vous dirai quelles classes et leurs valeurs correspondantes sont recommandées.
Bits ECN ...Le champ ECN à deux bits n'apparaissait que dans la
RFC 3168 (
Explicit Congestion Notification ). Le champ a été défini dans le bon but d'informer explicitement les hôtes finaux que quelqu'un rencontrait de la congestion en cours de route.
Par exemple, lorsque les paquets sont retardés pendant longtemps dans les files d'attente du routeur et les remplissent, par exemple, de 85%, il modifie la valeur ECN, indiquant à l'hôte final ce qui doit être plus lent - quelque chose comme Pause Frames on Ethernet.
Dans ce cas, l'expéditeur doit réduire le débit de transmission et réduire la charge sur le nœud souffrant.
En même temps, théoriquement, la prise en charge de ce champ par tous les nœuds de transit n'est pas requise. Autrement dit, l'utilisation d'ECN ne rompt pas le réseau qui ne le prend pas en charge.
Le but est bon, mais avant application dans la vie ECN n'est pas particulièrement trouvé. De nos jours, les méga et hyperscales regardent ces deux bits avec un
nouvel intérêt .
ECN est l'un des mécanismes d'évitement de la congestion décrits ci-dessous.
Pratique de classification DSCP
Ça ne fait pas mal un peu de pratique.
Le schéma est le même.
Pour commencer, envoyez simplement une demande ICMP:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Linkmeup_R1. E0 / 0. pcapng
pcapngEt maintenant avec la valeur DSCP définie.
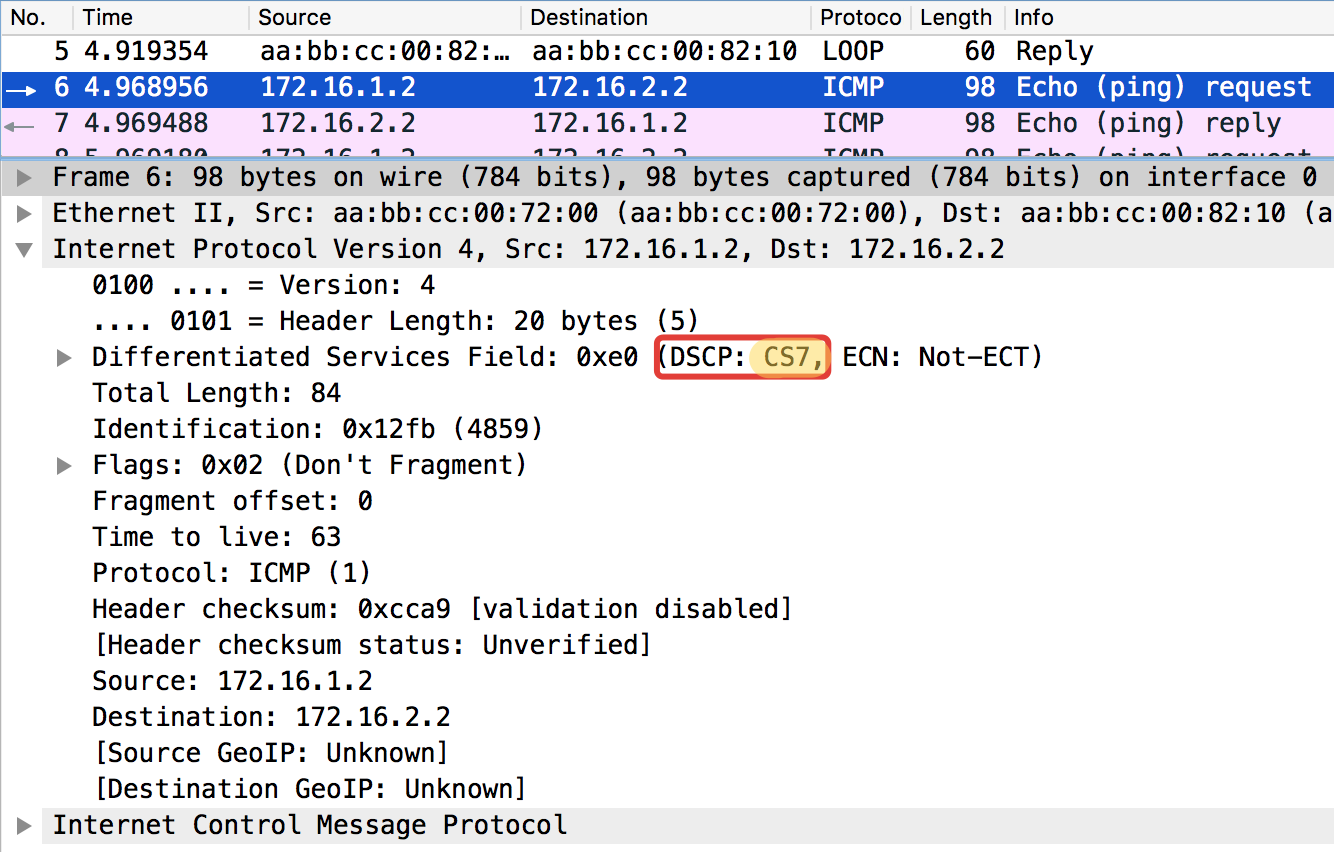
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
La valeur 184 est la représentation décimale du binaire 10111000. Parmi ceux-ci, les 6 premiers bits sont 101110, c'est-à-dire décimal 46, et c'est la classe EF.
Tableau des valeurs TOS standard pour un popingushki pratique ...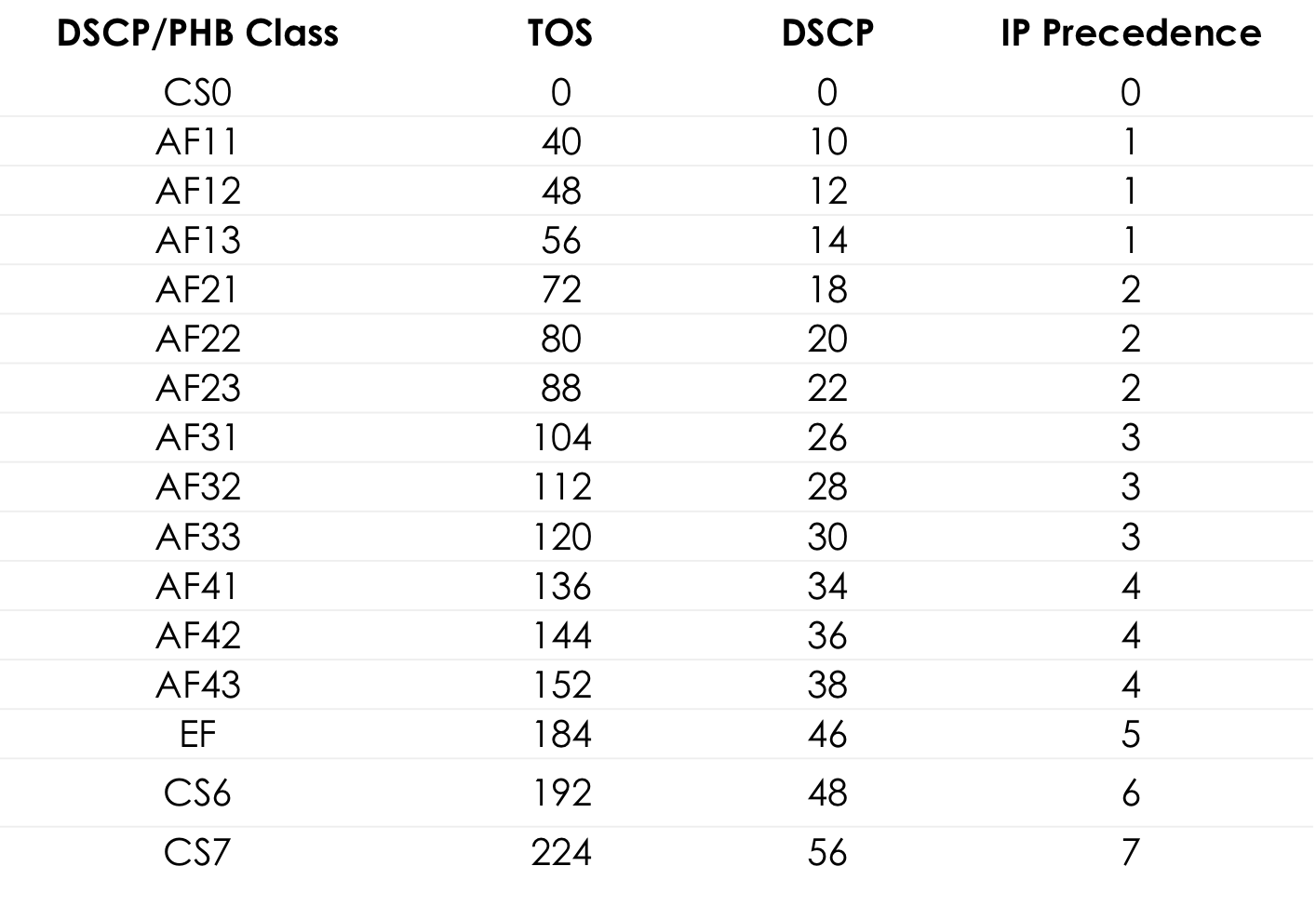 Plus de détails
Plus de détailsCi-dessous dans le texte du chapitre de la
recommandation de l'
IETF, je vais vous dire d'où viennent ces numéros et noms.
Linkmeup_R2. E0 / 0 pcapng
pcapngRemarque curieuse: la destination de pingushka dans la réponse ICMP Echo définit la même valeur de classe que dans Echo Request. C'est logique - si l'expéditeur a envoyé un paquet avec un certain niveau d'importance, il veut évidemment le recevoir en retour.
Linkmeup_R2. E0 / 0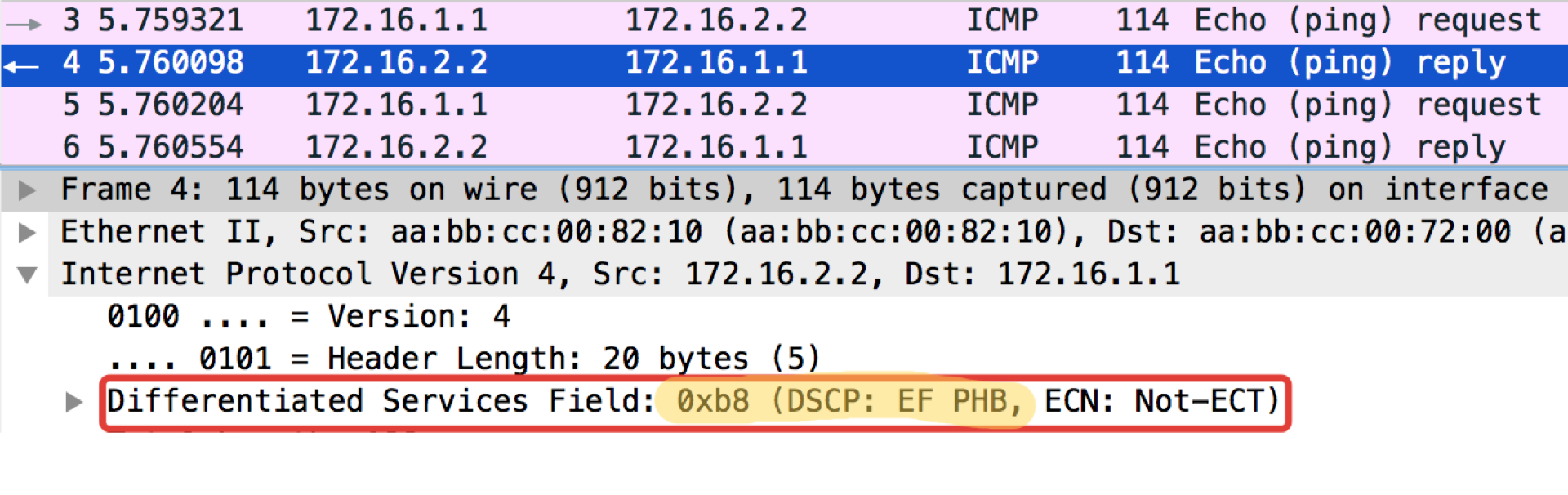 Fichier de configuration de la classification DSCP.
Fichier de configuration de la classification DSCP.Classe de trafic IPv6
IPv6 n'est pas très différent en termes de QoS que IPv4. Le champ de huit bits, appelé classe de trafic, est également divisé en deux parties. Les 6 premiers bits - DSCP - jouent exactement le même rôle.

Oui, Flow Label est apparu. Ils disent qu'il pourrait être utilisé pour une différenciation supplémentaire des classes. Mais cette idée n'a pas encore été appliquée dans la vie.
Classe de trafic MPLS
Le concept de DiffServ était axé sur les réseaux IP avec routage d'en-tête IP. C'est juste de la malchance - après 3 ans, ils ont publié la
RFC 3031 (
Multiprotocol Label Switching Architecture ). Et MPLS a commencé à reprendre les fournisseurs de réseau.
DiffServ n'a pas pu lui être étendu.
Par une heureuse coïncidence, un champ EXP de trois bits a été placé dans MPLS pour tout cas expérimental. Et malgré le fait qu'il y a longtemps dans la
RFC 5462 (le
champ «EXP» renommé en champ «Traffic Class» ) est devenu officiellement le champ Traffic Class, par inertie, il est appelé IExPi.
Il y a un problème: sa longueur est de trois bits, ce qui limite le nombre de valeurs possibles à 9. Ce n'est pas seulement petit, c'est 3 ordres binaires de moins que DSCP.

Étant donné que la classe de trafic MPLS est souvent héritée du paquet IP DSCP, nous avons l'archivage avec perte. Ou ... Non, vous ne voulez pas savoir ça ...
L-LSP . Utilise une combinaison de classe de trafic + valeur d'étiquette.
Généralement, la situation est étrange - MPLS a été conçu comme une aide IP pour une prise de décision rapide - le label MPLS est instantanément détecté dans CAM par Full Match, au lieu du traditionnel Longest Prefix Match. Autrement dit, ils connaissaient IP et participaient au changement, mais ne prévoyaient pas de champ de priorité normal.
En fait, nous avons déjà vu ci-dessus que seuls les trois premiers bits de DSCP sont utilisés pour déterminer la classe de trafic, et les trois autres bits sont Drop Precedence (ou PLP - Packet Loss Priority).
Par conséquent, en termes de classes de service, nous avons toujours une correspondance 1: 1, ne perdant que des informations sur Drop Precedence.
Dans le cas de MPLS, la classification comme dans IP peut être basée sur l'interface, MF, IP DSCP ou Traffic Class MPLS.
L'étiquetage signifie écrire une valeur dans le champ Classe de trafic de l'en-tête MPLS.
Un paquet peut contenir plusieurs en-têtes MPLS. Aux fins de DiffServ, seul le haut est utilisé.
Il existe trois scénarios de re-marquage différents lors du déplacement d'un paquet d'un segment IP pur à un autre via le domaine MPLS: (ce n'est qu'un extrait de l'
article ).
- Mode uniforme
- Mode tuyau
- Mode tuyau court
Modes de fonctionnement ...Mode uniforme
Il s'agit d'un modèle plat de bout en bout.
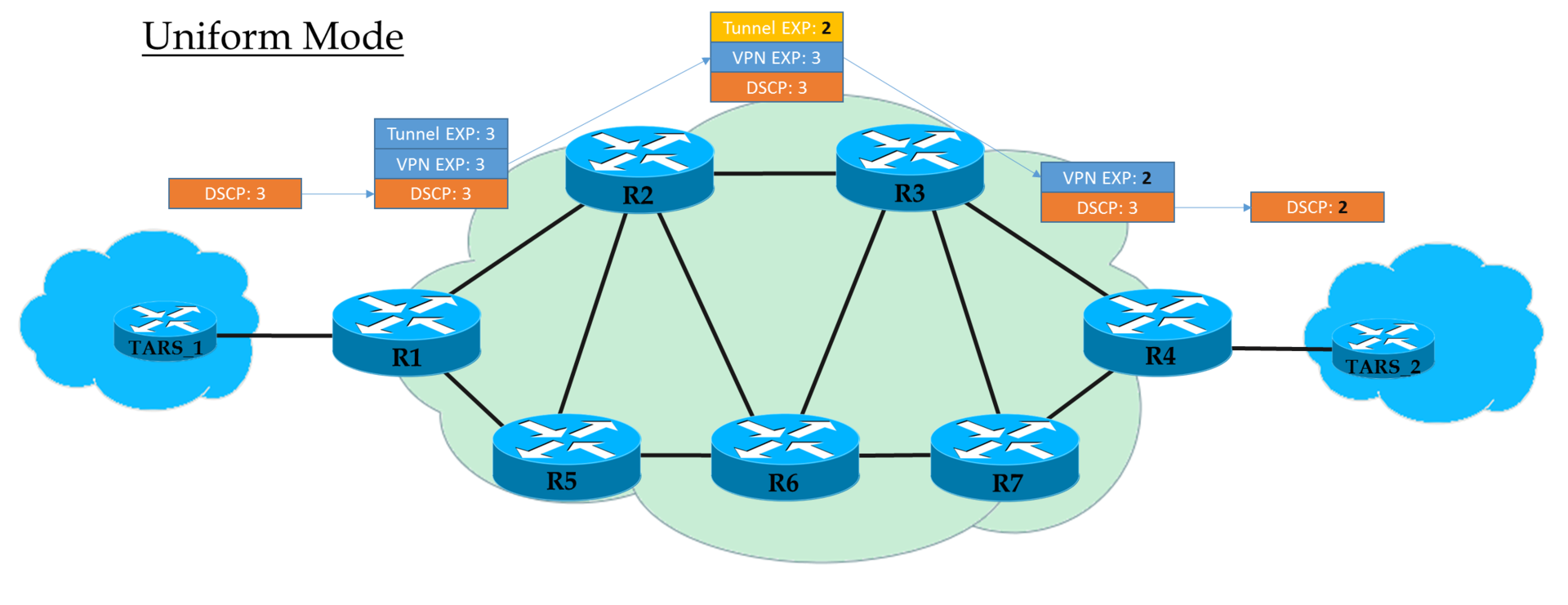
Chez Ingress PE, nous faisons confiance à IP DSCP et copions (à
proprement parler, affichons, mais pour simplifier, nous dirons «copier» ) sa valeur dans MPLS EXP (tunnel et en-têtes VPN). À la sortie d'Ingress PE, le paquet est déjà traité conformément à la valeur du champ EXP de l'en-tête MPLS supérieur.
Chaque transit P traite également des paquets en fonction de l'EXP supérieur. Mais en même temps, il peut le changer si l'opérateur le veut.
L'avant-dernier nœud supprime l'étiquette de transport (PHP) et copie la valeur EXP dans l'en-tête VPN. Peu importe ce qui se trouvait là - en mode uniforme, la copie a lieu.
Egress PE, en supprimant l'étiquette VPN, copie également la valeur EXP dans IP DSCP, même si quelque chose d'autre y est écrit.
Autrement dit, si quelque part au milieu la valeur de l'étiquette EXP dans l'en-tête du tunnel a changé, alors cette modification sera héritée par le paquet IP.
Mode tuyau
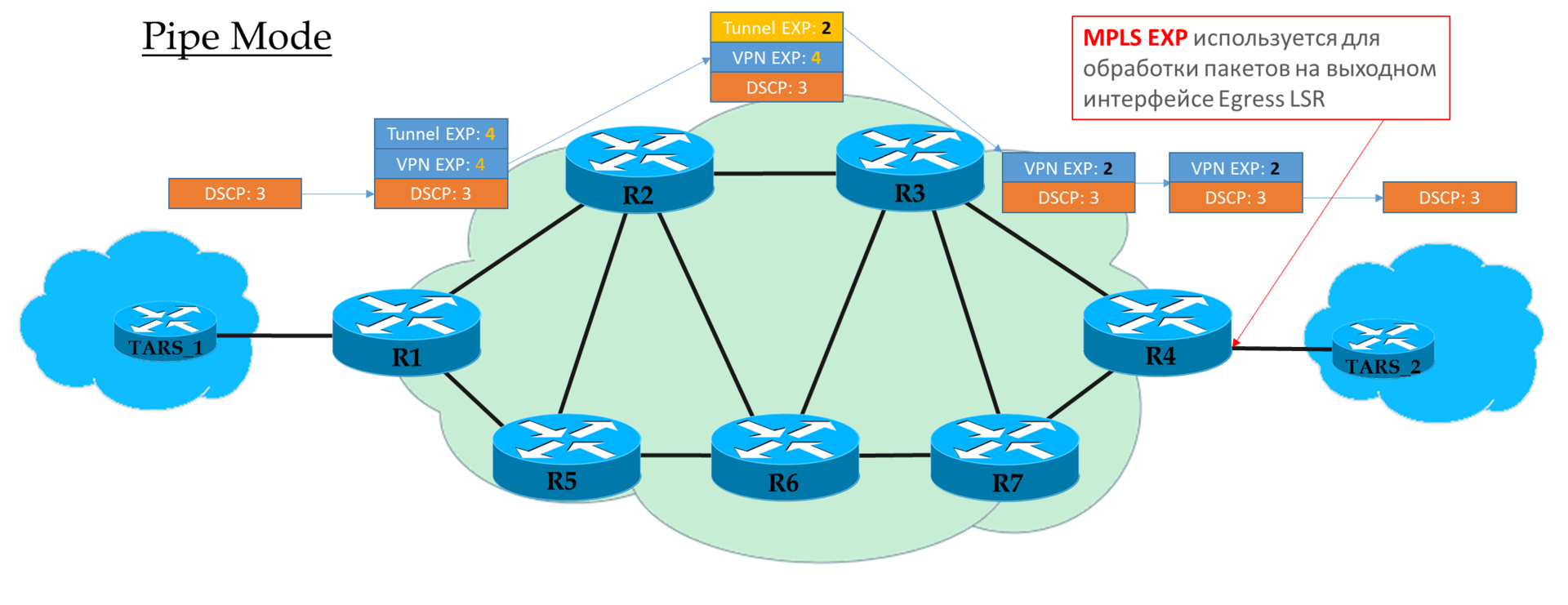
Si sur Ingress PE, nous avons décidé de ne pas faire confiance à la valeur DSCP, la valeur EXP souhaitée par l'opérateur est insérée dans les en-têtes MPLS.
Mais il est acceptable de copier ceux qui étaient dans DSCP. Par exemple, vous pouvez redéfinir les valeurs - copiez tout jusqu'à EF et mappez CS6 et CS7 à EF.
Chaque transit P ne regarde que l'EXP de l'en-tête MPLS supérieur.
L'avant-dernier nœud supprime l'étiquette de transport (PHP) et
copie la valeur EXP dans l'en-tête VPN.
Egress PE traite d'abord le paquet en fonction du champ EXP dans l'en-tête MPLS, puis le supprime uniquement,
sans copier la valeur dans DSCP.
Autrement dit, indépendamment de ce qui est arrivé au champ EXP dans les en-têtes MPLS, l'IP DSCP reste inchangé.
Un tel scénario peut être utilisé lorsque l'opérateur a son propre domaine Diff-Serv et qu'il ne veut pas que le trafic client l'influence d'une manière ou d'une autre.
Mode tuyau court
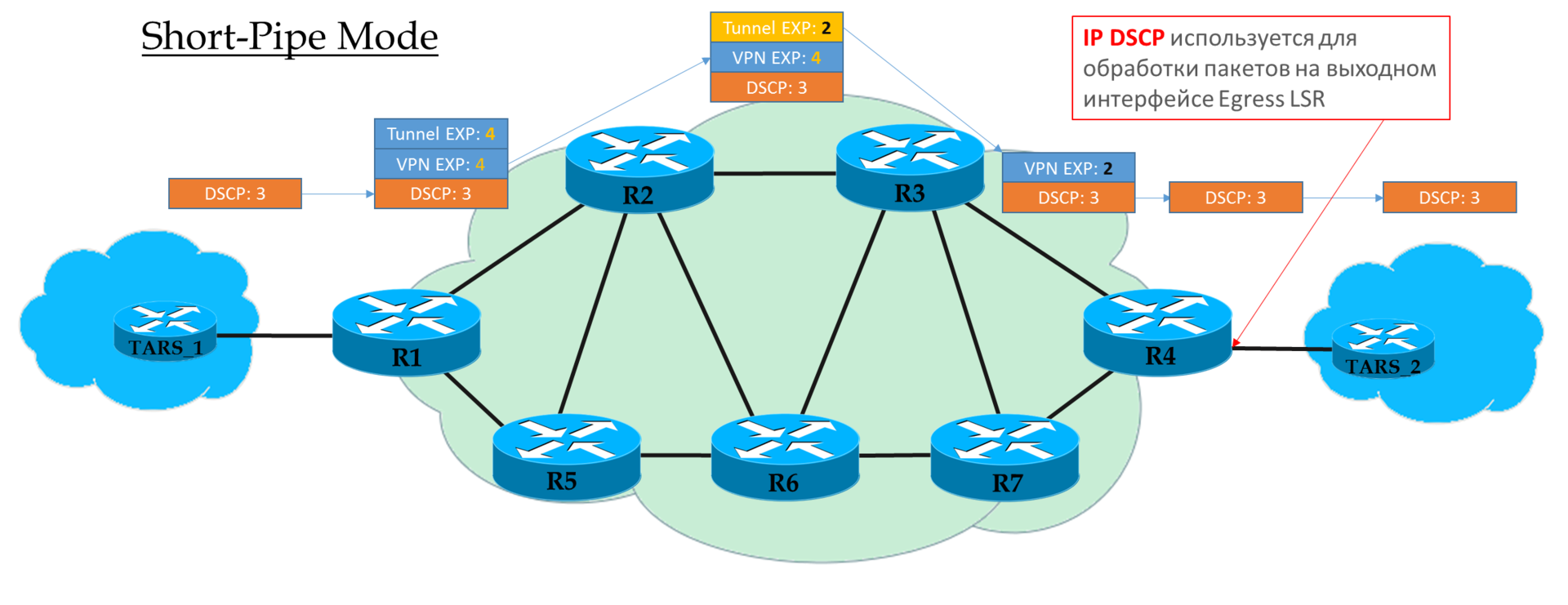
Vous pouvez considérer ce mode comme une variante du mode Pipe. La seule différence est qu'à la sortie du réseau MPLS, le paquet est traité conformément à son champ IP DSCP, et non à MPLS EXP.
Cela signifie que la priorité du paquet à la sortie est déterminée par le client, pas par l'opérateur.
Ingress PE ne fait pas confiance aux paquets entrants IP DSCP
Transit Ps regarde dans le champ EXP de l'en-tête supérieur.
L'avant-dernier P supprime l'étiquette de transport et copie la valeur dans l'étiquette VPN.
Egress PE supprime d'abord l'étiquette MPLS, puis traite le paquet dans les files d'attente.
Explication de
cisco .
Pratique de classification MPLS Traffic Class
Le schéma est le même:
Le fichier de configuration est le même.Dans le diagramme de réseau Linkmeup, il y a une transition de IP à MPLS à Linkmeup_R2.
Voyons ce qui se passe avec le marquage lors du ping
ping de l'IP 172.16.2.2 source 172.16.1.1 tos 184 .
Linkmeup_R2. E0 / 0. pcapng
pcapngAinsi, nous voyons que l'étiquette EF d'origine dans IP DSCP a été transformée en la valeur 5 du champ EXP MPLS (c'est aussi la classe de trafic, rappelez-vous ceci) à la fois de l'en-tête VPN et de l'en-tête de transport.
Nous assistons ici au mode de fonctionnement uniforme.
Ethernet 802.1p
L'absence de champ prioritaire dans 802.3 (Ethernet) s'explique par le fait qu'Ethernet était initialement prévu exclusivement comme une solution pour le segment LAN. Pour un argent modeste, vous pouvez obtenir une bande passante excessive, et la liaison montante sera toujours un goulot d'étranglement - il n'y a rien à craindre de prioriser.
Cependant, il est vite devenu clair que l'attractivité financière d'Ethernet + IP porte ce bundle aux niveaux de la dorsale et du WAN. Et la cohabitation dans un segment LAN de torrents et de téléphonie doit être résolue.
Heureusement, 802.1q (VLAN) est arrivé à temps pour cela, dans lequel un champ 3 bits (à nouveau) a été alloué pour les priorités.
Dans le plan DiffServ, ce champ vous permet de définir les 8 mêmes classes de trafic.
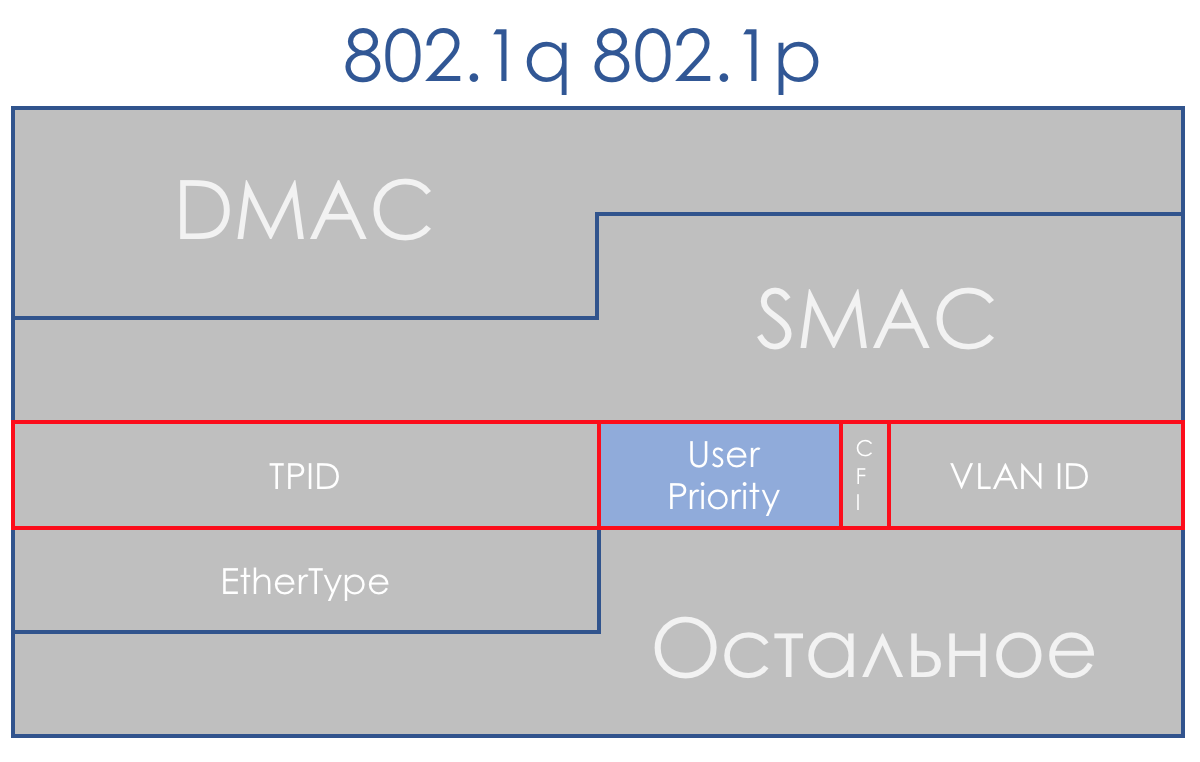
Lors de la réception d'un paquet, le périphérique réseau du domaine DS prend dans la plupart des cas en compte l'en-tête qu'il utilise pour la commutation:
- Commutateur Ethernet - 802.1p
- Noeud MPLS - Classe de trafic MPLS
- Routeur IP - IP DSCP
Bien que ce comportement puisse être modifié: classification basée sur l'interface et multi-champs. Et vous pouvez parfois même explicitement dire dans le champ CoS quel en-tête regarder.
Basé sur l'interface
C'est le moyen le plus simple de classer les packages sur le front. Tout ce qui est versé dans l'interface spécifiée est marqué d'une certaine classe.
Dans certains cas, cette granularité est suffisante, donc basée sur l'interface est utilisée dans la vie.
Pratique de classification basée sur l'interface
Le schéma est le même:
La configuration des politiques de QoS dans l'équipement de la plupart des fournisseurs est divisée en étapes.
- Tout d'abord, un classificateur est défini:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
Tout ce qui vient à l'interface Ethernet0 / 2.
- Ensuite, une stratégie est créée dans laquelle le classificateur et l'action nécessaire sont associés.
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
Si le paquet rencontre le classificateur TRISOLARANS_INTERFACE_CM, écrivez CS7 dans le champ DSCP.
Ici, je devance moi-même en utilisant l'obscur CS7, puis EF, AF. Vous trouverez ci-dessous des informations sur ces abréviations et accords acceptés. En attendant, il suffit de savoir que ce sont des classes différentes avec des niveaux de service différents.
- Et la dernière étape consiste à appliquer la stratégie à l'interface:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
Ici, le classificateur est un peu redondant, ce qui vérifiera que le paquet est arrivé à l'interface e0 / 2, où nous appliquons ensuite la politique. On pourrait écrire n'importe quel match:
class-map match-all TRISOLARANS_INTERFACE_CM match any
Cependant, la politique peut réellement être appliquée sur vlanif ou sur l'interface de sortie, donc c'est possible.
Exécutez le ping habituel sur 172.16.2.2 (Trisolaran2) avec Trisolaran1:
Et dans le vidage entre Linkmeup_R1 et Linkmeup_R2, nous verrons ce qui suit:
 pcapngClassification basée sur l'interface du fichier de configuration.
pcapngClassification basée sur l'interface du fichier de configuration.Multi-domaines
Le type de classification le plus courant à l'entrée du domaine DS. Nous ne faisons pas confiance à l'étiquetage existant, et sur la base des en-têtes de package, nous attribuons une classe.
Il s'agit souvent d'un moyen «d'activer» la qualité de service, dans le cas où les expéditeurs ne marquent pas.
Un outil assez flexible, mais en même temps lourd - vous devez créer des règles difficiles pour chaque classe. Par conséquent, dans le domaine DS, BA est plus pertinent.
Pratique de classification MF
Le schéma est le même:
À partir des exemples pratiques ci-dessus, on peut voir que les périphériques réseau approuvent par défaut l'étiquetage des paquets entrants.
C'est bien à l'intérieur du domaine DS, mais pas acceptable au point d'entrée.
Et maintenant, ne faisons pas confiance aveuglément? Sur
Linkmeup_R2, ICMP sera étiqueté comme EF (par exemple uniquement), TCP comme AF12, et tout le reste est CS0.
Ce sera la classification MF (Multi-Field).
- La procédure est la même, mais maintenant nous allons faire correspondre les ACL qui décrochaient les catégories de trafic nécessaires, donc nous les créons d'abord.
Sur Linkmeup_R2:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- Ensuite, nous définissons les classificateurs:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- Et maintenant nous définissons les règles du remarking en politique:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- Et nous suspendons la politique sur l'interface. En entrée, respectivement, car la décision doit être prise à l'entrée du réseau.
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
Test ICMP de l'hôte final Trisolaran1. Nous ne spécifions pas sciemment la classe - la valeur par défaut est 0.
J'ai déjà supprimé la stratégie avec Linkmeup_R1, donc le trafic vient avec le marquage CS0, pas CS7.
Voici deux vidages à proximité, avec Linkmeup_R1 et Linkmeup_R2:
Linkmeup_R1. E0 / 0.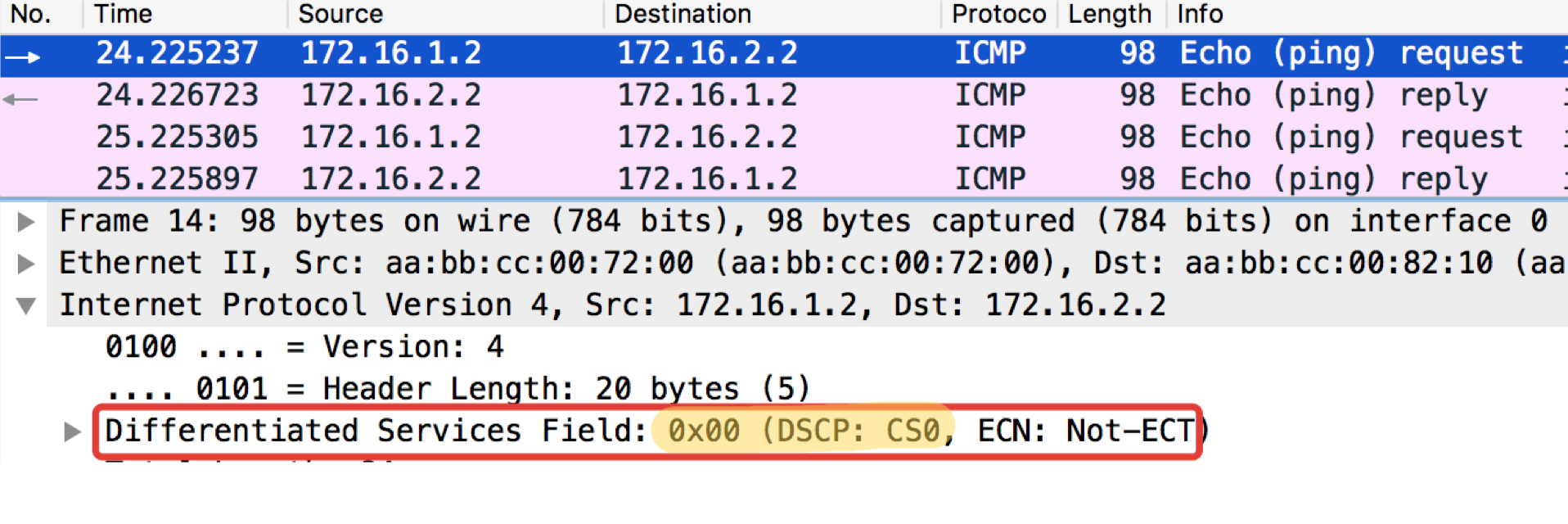 pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.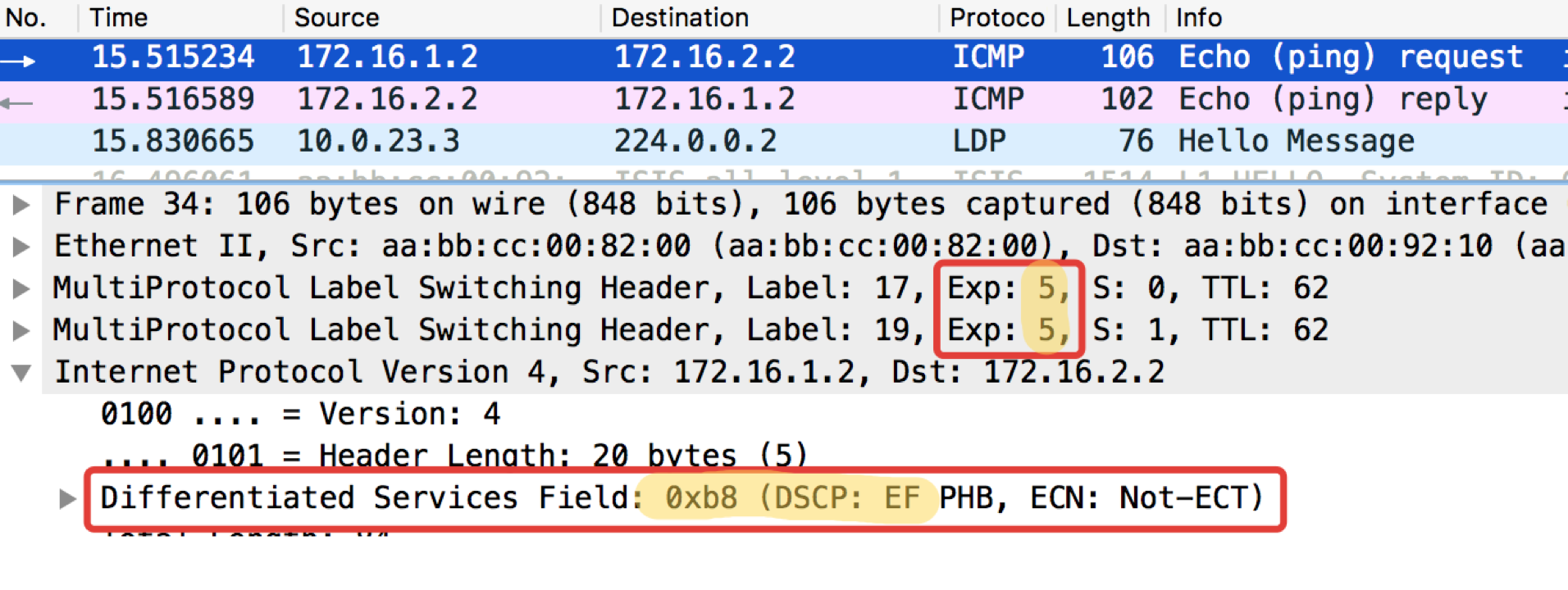 pcapng
pcapngOn peut voir qu'après les classificateurs et le réétiquetage sur Linkmeup_R2 sur les paquets ICMP, non seulement DSCP est devenu EF, mais MPLS Traffic Class est devenu égal à 5.
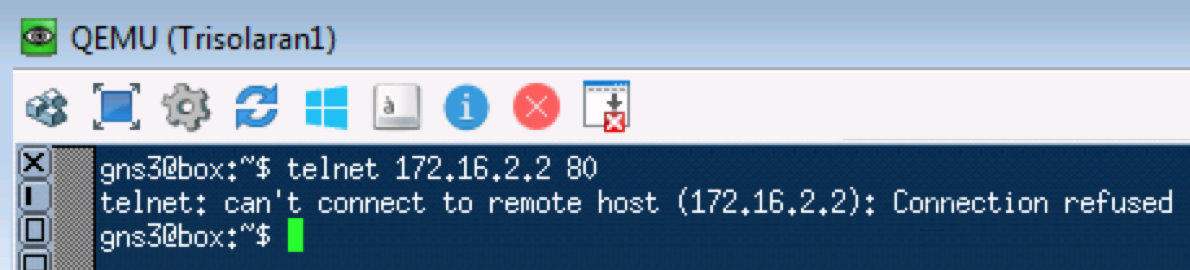
Un test similaire avec telnet 172.16.2.2. 80 - vérifiez donc TCP:
 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0. pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.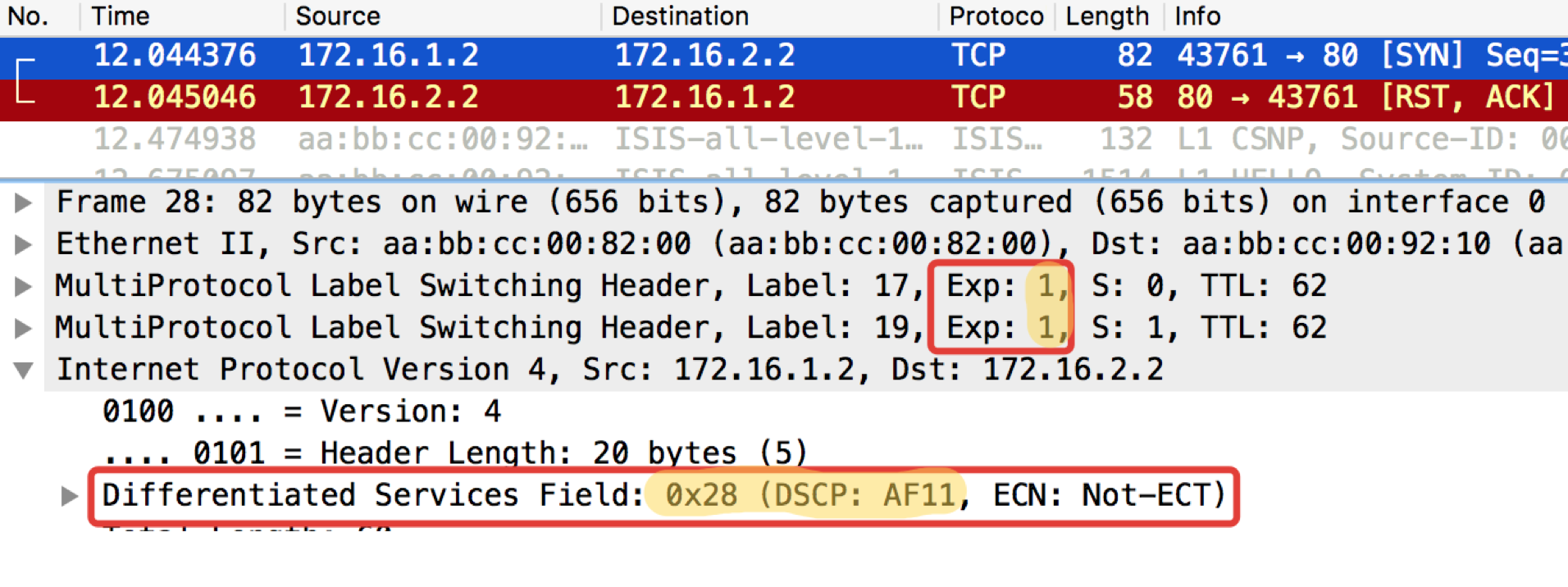 pcapng
pcapngLIRE - À quoi et à quoi s'attendre. TCP est transmis comme AF11.
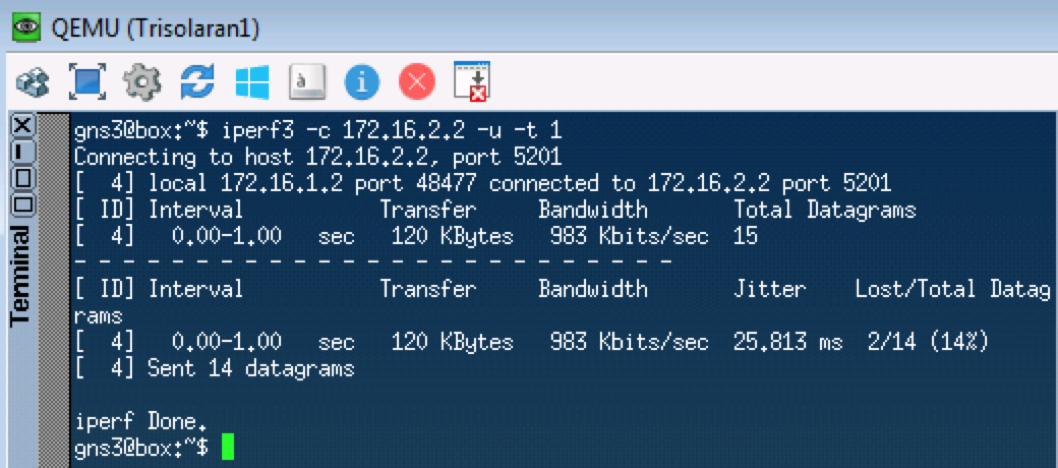
Le prochain test testera UDP, qui devrait aller à CS0 selon nos classificateurs. Nous utiliserons iperf pour cela (apportez-le à Linux Tiny Core via les applications). Sur le côté distant
iperf3 -s - démarrez le serveur, sur le
iperf3 local
-c -u -t1 - client (
-c ), protocole UDP (
-u ), testez 1 seconde (
-t1 ).
 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0. pcapngLinkmeup_R2. E0 / 0
pcapngLinkmeup_R2. E0 / 0 pcapng
pcapngDésormais, tout ce qui arrive à cette interface sera classé selon les règles configurées.
Marquage à l'intérieur de l'appareil
Encore une fois: à l'entrée de la classification du domaine DS peut se produire MF, Interface-based ou BA.
Entre les nœuds du domaine DS, le paquet dans l'en-tête porte un signe sur la classe de service requise et est classé par BA.
Quelle que soit la méthode de classification, après celle-ci, le package se voit attribuer une classe interne au sein de l'appareil, en fonction de laquelle il est traité. L'en-tête est supprimé et le paquet nu (non) se déplace vers la sortie.
Et à la sortie, la classe interne est convertie dans le champ CoS du nouvel en-tête.
C'est-à-dire, rubrique 1 ⇒ Classification ⇒ Classe de service interne ⇒ Rubrique 2.
Dans certains cas, vous devez afficher le champ d'en-tête d'un protocole dans le champ d'en-tête d'un autre, par exemple, DSCP dans la classe de trafic.
Cela se produit uniquement via le marquage interne intermédiaire.
Par exemple, En-tête DSCP ⇒ Classification ⇒ Classe de service interne ⇒ En-tête de classe de trafic.
Formellement, les classes internes peuvent être appelées comme vous le souhaitez, ou simplement numérotées, et elles ne disposent que d'une certaine file d'attente.
À la profondeur à laquelle nous plongeons dans cet article, peu importe comment ils sont appelés, il est important qu'un modèle de comportement spécifique soit associé à des valeurs spécifiques des champs QoS.
Si nous parlons d'implémentations QoS spécifiques, le nombre de classes de service que le périphérique peut fournir n'est pas supérieur au nombre de files d'attente disponibles. Il y en a souvent huit (soit sous l'influence d'IPP, soit parfois par accord non écrit). Cependant, selon le fournisseur, le périphérique, la carte, ils peuvent être plus ou moins.
Autrement dit, s'il y a 4 files d'attente, les classes de service n'ont tout simplement pas de sens d'en faire plus de quatre.
Parlons de cela plus en détail dans le chapitre matériel.
Si vous voulez toujours vraiment un peu de spécificité ...Les tableaux ci-dessous peuvent sembler pratiques à première vue quant à la relation entre les champs QoS et les classes internes, mais ils sont quelque peu trompeurs lors de l'appel des noms de classes PHB. Pourtant, PHB est le type de modèle de comportement attribué au trafic d'une certaine classe, dont le nom, en gros, est arbitraire.
Par conséquent, reportez-vous aux tableaux ci-dessous avec une part de scepticisme (donc, sous le spoiler).
Sur l'exemple de Huawei . Ici, Service-Class est la classe très interne du package.
Autrement dit, si BA est classé à l'entrée, les valeurs DSCP seront traduites en valeurs de classe de service et de couleur correspondantes.

Il convient de prêter attention au fait que de nombreuses valeurs DSCP ne sont pas utilisées et que les paquets avec de tels marquages sont en fait traités comme BE.
Voici un tableau de correspondance en arrière qui montre quelles valeurs DSCP seront définies pour le trafic lorsque la sortie est re-marquée.

Notez que seul AF a une gradation de couleur. BE, EF, CS6, CS7 - tout simplement vert.
Il s'agit d'un tableau de conversion des champs IPP, MPLS Traffic Class et 802.1p Ethernet en classes de service internes.

Et de retour.

Notez que toute information sur la priorité de suppression est généralement perdue ici.
Il doit être répété - ce n'est qu'un exemple spécifique de correspondances par défaut d'un fournisseur sélectionné
au hasard . Pour d'autres, cela peut être différent. Les administrateurs peuvent configurer des classes de services et des PHB complètement différentes sur leur réseau.
En termes de PHB, il n'y a absolument aucune différence ce qui est utilisé pour la classification - DSCP, Traffic Class, 802.1p.
À l'intérieur de l'appareil, ils se transforment en classes de trafic définies par l'administrateur réseau.
Autrement dit, tous ces marquages sont un moyen de dire aux voisins quelle classe de service ils doivent attribuer à ce package. C'est à peu près comme la communauté BGP, qui ne signifie rien en soi, jusqu'à ce que la politique d'interprétation soit définie sur le réseau.
Recommandations de l'IETF (catégories de trafic, classes de service et comportements)
Les normes ne normalisent pas du tout quelles classes de service particulières devraient exister, comment les classer et les étiqueter, et quel PHB leur appliquer.
Ceci est à la merci des fournisseurs et des administrateurs réseau.
Nous n'avons que 3 bits - nous utilisons comme nous voulons.
C'est bien:
- Chaque morceau de fer (fournisseur) choisit indépendamment les mécanismes à utiliser pour PHB - pas de signalisation, pas de problèmes de compatibilité.
- L'administrateur de chaque réseau peut répartir le trafic de manière flexible entre différentes classes, choisir les classes elles-mêmes et le PHB correspondant.
C'est mauvais:
- Aux limites des domaines DS, des problèmes de conversion se posent.
- Dans des conditions de totale liberté d'action - certains sont dans la forêt, certains sont des démons.
Par conséquent, l'IETF en 2006 a publié un manuel de formation sur la façon d'aborder la différenciation des services:
RFC 4594 (
directives de configuration pour les classes de service DiffServ ).
Ce qui suit est un bref résumé de ce RFC.
Modèles de comportement (PHB)
DF - Transfert par défautEnvoi standard.Si un modèle de trafic n'est pas spécifiquement affecté à un modèle de comportement, il sera traité à l'aide du transfert par défaut.
C'est le meilleur effort - l'appareil fera tout son possible, mais ne garantit rien. Des baisses, des désordres, des retards imprévisibles et une gigue flottante sont possibles, mais ce n'est pas exact.
Ce modèle convient aux applications peu exigeantes, telles que les téléchargements de courrier ou de fichiers.
Soit dit en passant, il y a du PHB et encore moins défini -
Un effort moindre.
AF - Transfert assuréEnvoi garanti.Il s'agit d'un BE amélioré. Certaines garanties apparaissent ici, par exemple, les bandes. Des baisses et des retards flottants sont toujours possibles, mais dans une bien moindre mesure.
Le modèle convient au multimédia: streaming, vidéoconférence, jeux en ligne.
RFC 2597 (
groupe PHB de transfert assuré ).
EF - Expédition accéléréeEnvoi d'urgence.Toutes les ressources et priorités se précipitent ici. C'est un modèle pour les applications qui n'ont pas besoin de pertes, de courts délais, d'une gigue stable, mais elles ne sont pas gourmandes pour la bande. Comme, par exemple, la téléphonie ou un service d'émulation de fil (CES - Circuit Emulation Service).
Les pertes, les désordres et les retards flottants dans EF sont extrêmement improbables.
RFC 3246 (
un PHB de transfert accéléré ).
CS - Sélecteur de classeIl s'agit de comportements conçus pour maintenir la compatibilité descendante avec la priorité IP dans les réseaux capables de DS.
Les classes suivantes existent dans IPP: CS0, CS1, CS2, CS3, CS4, CS5, CS6, CS7.
Pas toujours pour chacun d'eux il y a un PHB séparé, généralement il y en a deux ou trois, et les autres sont simplement traduits dans la classe DSCP la plus proche et obtiennent le PHB correspondant.
Ainsi, par exemple, un paquet étiqueté CS 011000 peut être classé comme 011010.
Parmi les CS, seuls CS6, CS7, qui sont recommandés pour NCP - Network Control Protocol et nécessitent un PHB distinct, sont sûrement conservés dans l'équipement.
Comme EF, PHB CS6.7 est conçu pour les classes qui ont des exigences de latence et de perte très élevées, mais sont quelque peu tolérantes à la discrimination de bande.
La tâche de PHB pour CS6.7 est de fournir un niveau de service qui élimine les chutes et les retards, même en cas de surcharge extrême de l'interface, de la puce et des files d'attente.
Il est important de comprendre que le PHB est un concept abstrait - et en fait, il est mis en œuvre par le biais de mécanismes disponibles sur un équipement réel.
Ainsi, le même PHB défini dans le domaine DS peut différer sur Juniper et Huawei.
De plus, un seul PHB n'est pas un ensemble statique d'actions; par exemple, un PHB AF peut se composer de plusieurs options qui diffèrent par le niveau de garanties (bande, retards acceptables).
Classes de service
L'IETF a pris en charge les administrateurs et identifié les principales catégories d'applications et leurs classes de service.
Je ne serai pas verbeux ici, insérez simplement quelques plaques de cette directive RFC.Catégories d'application: Exigences pour les caractéristiques du réseau:
Exigences pour les caractéristiques du réseau: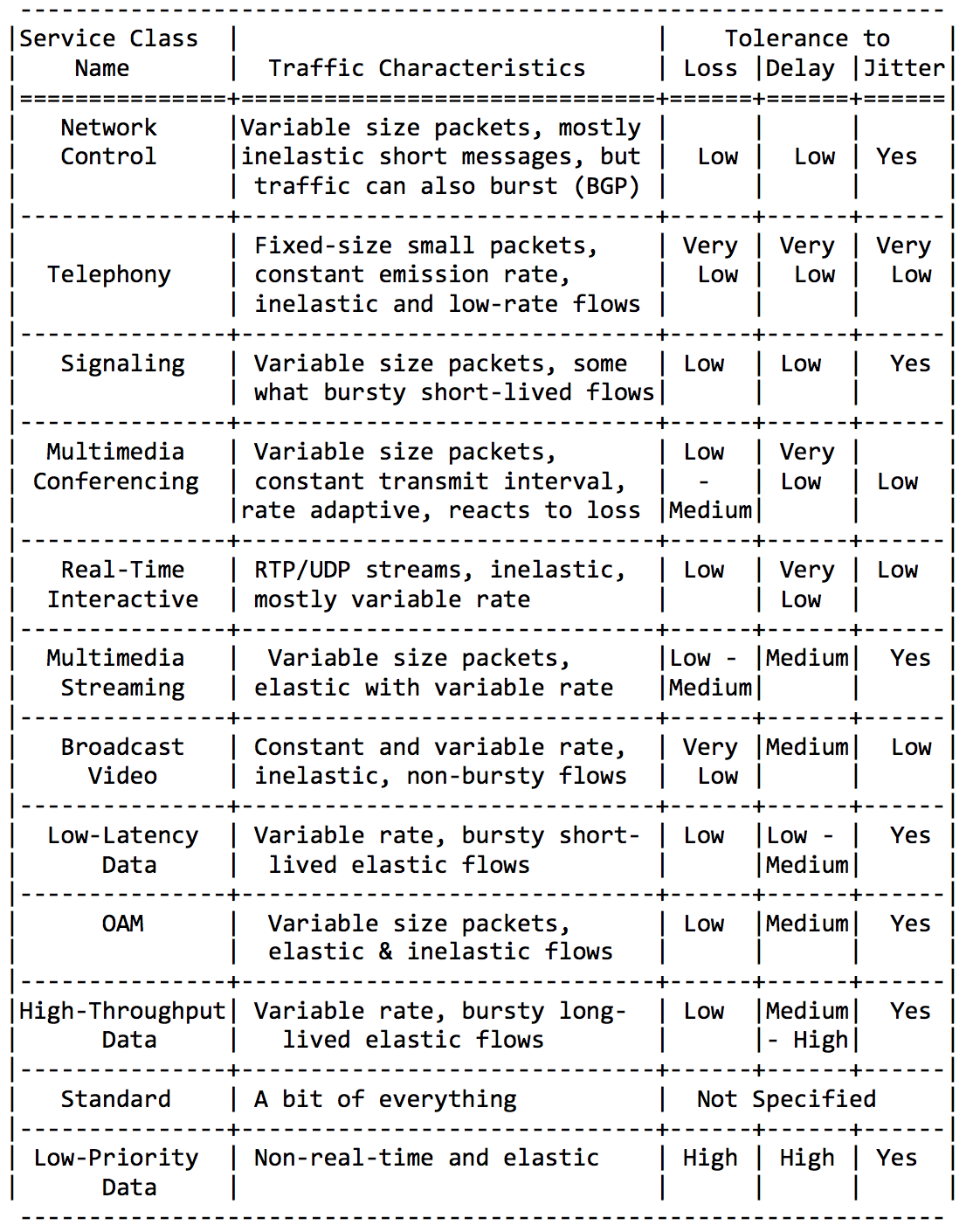 Et enfin, les noms de classe recommandés et les valeurs DSCP correspondantes:
Et enfin, les noms de classe recommandés et les valeurs DSCP correspondantes: En combinant les classes ci-dessus de différentes manières (pour tenir dans les 8 disponibles), vous pouvez obtenir des solutions QoS pour différents réseaux.Le plus courant est peut-être celui-ci: la
En combinant les classes ci-dessus de différentes manières (pour tenir dans les 8 disponibles), vous pouvez obtenir des solutions QoS pour différents réseaux.Le plus courant est peut-être celui-ci: la classe DF (ou BE) marque un trafic absolument peu exigeant - il reçoit une attention résiduelle.PHB AF dessert les classes AF1, AF2, AF3, AF4. Ils ont tous besoin de fournir une voie, au détriment des retards et des pertes. Les pertes sont contrôlées par les bits Drop Precedence, c'est pourquoi ils sont appelés AFxy, où x est la classe de service et y est Drop Precedence.EF a besoin d'une sorte de garantie de bande minimale, mais plus important encore - une garantie de retards, de gigue et de perte.CS6, CS7 nécessitent encore moins de bande passante, car il s'agit d'un filet de packages de services dans lesquels des rafales sont toujours possibles (BGP Update, par exemple), mais les pertes et les retards sont inacceptables - à quoi sert BFD avec un minuteur de 10 ms si Hello se bloque dans Files d'attente de 100 ms?Autrement dit, 4 classes sur 8 disponibles ont été données sous AF.Et malgré le fait qu'ils le font habituellement, je répète que ce ne sont que des recommandations, et rien n'empêche trois classes de votre domaine DS d'attribuer EF et seulement deux à AF.
classe DF (ou BE) marque un trafic absolument peu exigeant - il reçoit une attention résiduelle.PHB AF dessert les classes AF1, AF2, AF3, AF4. Ils ont tous besoin de fournir une voie, au détriment des retards et des pertes. Les pertes sont contrôlées par les bits Drop Precedence, c'est pourquoi ils sont appelés AFxy, où x est la classe de service et y est Drop Precedence.EF a besoin d'une sorte de garantie de bande minimale, mais plus important encore - une garantie de retards, de gigue et de perte.CS6, CS7 nécessitent encore moins de bande passante, car il s'agit d'un filet de packages de services dans lesquels des rafales sont toujours possibles (BGP Update, par exemple), mais les pertes et les retards sont inacceptables - à quoi sert BFD avec un minuteur de 10 ms si Hello se bloque dans Files d'attente de 100 ms?Autrement dit, 4 classes sur 8 disponibles ont été données sous AF.Et malgré le fait qu'ils le font habituellement, je répète que ce ne sont que des recommandations, et rien n'empêche trois classes de votre domaine DS d'attribuer EF et seulement deux à AF.
Résumé de la classification
A l'entrée d'un nœud, un package est classé en fonction d'une interface, MF, ou de son étiquetage (BA).L'étiquetage est la valeur des champs DSCP dans IPv4, la classe de trafic dans IPv6 et dans MPLS ou 802.1p dans 802.1q.Il existe 8 classes de service qui regroupent différentes catégories de trafic. Chaque classe se voit attribuer son propre PHB, satisfaisant aux exigences de la classe.Selon les recommandations de l'IETF, les classes de service suivantes sont distinguées: CS1, CS0, AF11, AF12, AF13, AF21, CS2, AF22, AF23, CS3, AF31, AF32, AF33, CS4, AF41, AF42, AF43, CS5, EF, CS6, CS7 en importance croissante du trafic.Parmi eux, vous pouvez choisir une combinaison de 8, qui peuvent en fait être encodés dans des champs CoS.La combinaison la plus courante: CS0, AF1, AF2, AF3, AF4, EF, CS6, CS7 avec 3 dégradés de couleurs pour AF.Chaque classe se voit attribuer un PHB, dont il existe 3 - Transfert par défaut, Transfert assuré, Transfert accéléré dans un ordre croissant de gravité. Un peu à côté est le sélecteur de classe PHB. Chaque PHB peut varier selon les paramètres de l'outil, mais plus à ce sujet plus tard.
Sur un réseau déchargé, la QoS n'est pas nécessaire, ont-ils déclaré. Tous les problèmes de QoS sont résolus en développant les liens, ont-ils déclaré. Avec Ethernet et DWDM, nous ne rencontrons jamais de congestion de ligne, ont-ils déclaré.Ce sont ceux qui ne comprennent pas ce qu'est la QoS.Mais la réalité frappe VPN sur ILV.- Pas partout, il y a de l'optique. RRL est notre réalité. Parfois, au moment de l'accident (et pas seulement) dans la liaison radio étroite veut explorer tout le trafic réseau.
- Les explosions de trafic sont notre réalité. Les rafales de trafic à court terme se mettent facilement en file d'attente, forçant à supprimer les paquets très nécessaires.
- La téléphonie, la visioconférence, les jeux en ligne sont notre réalité. Si la file d'attente est au moins quelque peu occupée, les retards commencent à danser.
Dans ma pratique, il y avait des exemples où la téléphonie se transformait en code Morse sur un réseau chargé à 40% au maximum. Le simple re-marquage dans EF a résolu momentanément le problème.
Il est temps de gérer des outils qui vous permettent de fournir différents services à différentes classes.
Outils PHB
Il n'y a en fait que trois groupes d'outils QoS qui manipulent activement les packages:- Évitement de la congestion - que faire pour ne pas être mauvais.
- Gestion de la congestion - que faire quand c'est déjà mauvais.
- Rate Limiting - comment ne pas mettre plus sur le réseau qu'il ne devrait l'être, et ne pas libérer autant qu'ils ne peuvent pas accepter.
Mais tous, dans l'ensemble, seraient inutiles sans la file d'attente.5. Files d'attente
Dans le parc d'attractions, vous ne pouvez pas donner la priorité à quelqu'un si vous n'organisez pas de file d'attente séparée pour ceux qui ont payé plus.Même situation dans les réseaux.Si tout le trafic est dans une file d'attente, vous ne pourrez pas extraire les paquets importants de son milieu pour leur donner la priorité.C'est pourquoi, après classification, les paquets sont placés dans la file d'attente correspondant à cette classe.Et puis une file d'attente (avec des données vocales) se déplacera rapidement, mais avec une bande limitée, une autre plus lente (streaming), mais avec une large bande, et certaines ressources iront selon le principe résiduel.Mais dans les limites de chaque file d'attente distincte, la même règle s'applique - vous ne pouvez pas extraire un paquet du milieu - uniquement de sa tête.Chaque file d'attente a une certaine longueur limitée. D'une part, cela est dicté par des limitations matérielles, et d'autre part, cela n'a aucun sens de garder les paquets dans la file d'attente trop longtemps. Un paquet VoIP n'est pas nécessaire s'il est retardé de 200 ms. TCP demandera le transfert, conditionnellement, après l'expiration du RTT (configuré dans sysctl). Par conséquent, l'abandon n'est pas toujours mauvais.Les développeurs et les concepteurs d'équipements réseau doivent trouver un compromis entre les tentatives de sauvegarde du package le plus longtemps possible et, au contraire, d'éviter le gaspillage de bande passante, en essayant de fournir le package qui n'est plus nécessaire.Dans une situation normale, lorsque l'interface / la puce n'est pas surchargée, l'utilisation du tampon est proche de zéro. Ils absorbent des éclats à court terme, mais cela ne provoque pas leur remplissage prolongé.S'il y a plus de trafic que la puce de commutation ou l'interface de sortie ne peut en gérer, les files d'attente commencent à se remplir. Et une utilisation chronique supérieure à 20-30% est déjà une situation à laquelle il faut remédier.
6. Évitement de la congestion
Dans la vie de n'importe quel routeur, il arrive un moment où la file d'attente est pleine. Où mettre le paquet, s'il n'y a vraiment nulle part où le mettre - c'est tout, le tampon est terminé, il ne sera pas là, même s'il est beau à regarder, même si vous payez un supplément.Il y a deux façons: soit de jeter ce paquet, soit celles qui ont déjà marqué le tour.Si ceux-ci sont déjà dans la file d'attente, considérez ce qui manque.Et si celui-ci, alors considérez qu'il n'est pas venu.Ces deux approches sont appelées Tail Drop et Head Drop .Chute de queue et chute de tête
Tail Drop - le mécanisme de gestion de file d'attente le plus simple - élimine tous les nouveaux paquets qui ne rentrent pas dans le tampon. Head Drop supprime les paquets mis en file d'attente depuis très longtemps. Il vaut mieux les jeter que de les sauver, car ils sont très probablement inutiles. Mais les paquets les plus pertinents arrivés à la fin de la file d'attente auront plus de chances d'arriver à temps. De plus, Head Drop vous permet de ne pas charger le réseau avec des packages inutiles. Naturellement, les packages les plus anciens sont ceux qui sont en tête de file d'attente, d'où le nom de l'approche.
Head Drop supprime les paquets mis en file d'attente depuis très longtemps. Il vaut mieux les jeter que de les sauver, car ils sont très probablement inutiles. Mais les paquets les plus pertinents arrivés à la fin de la file d'attente auront plus de chances d'arriver à temps. De plus, Head Drop vous permet de ne pas charger le réseau avec des packages inutiles. Naturellement, les packages les plus anciens sont ceux qui sont en tête de file d'attente, d'où le nom de l'approche. Head Drop présente un autre avantage non évident: si vous supprimez le paquet au début de la file d'attente, le destinataire sera rapidement informé de l'encombrement du réseau et informera l'expéditeur. Dans le cas de Tail Drop, les informations sur le paquet abandonné atteindront, peut-être, des centaines de millisecondes plus tard - jusqu'à ce qu'elles parviennent de la queue de la ligne à sa tête.Les deux mécanismes fonctionnent tour à tour avec différenciation. Autrement dit, il n'est pas nécessaire que la totalité du tampon soit pleine. Si la deuxième file d'attente est vide, et celle du zéro aux globes oculaires, alors seuls les paquets du zéro seront rejetés.
Head Drop présente un autre avantage non évident: si vous supprimez le paquet au début de la file d'attente, le destinataire sera rapidement informé de l'encombrement du réseau et informera l'expéditeur. Dans le cas de Tail Drop, les informations sur le paquet abandonné atteindront, peut-être, des centaines de millisecondes plus tard - jusqu'à ce qu'elles parviennent de la queue de la ligne à sa tête.Les deux mécanismes fonctionnent tour à tour avec différenciation. Autrement dit, il n'est pas nécessaire que la totalité du tampon soit pleine. Si la deuxième file d'attente est vide, et celle du zéro aux globes oculaires, alors seuls les paquets du zéro seront rejetés. Tail Drop et Head Drop peuvent fonctionner simultanément.
Tail Drop et Head Drop peuvent fonctionner simultanément.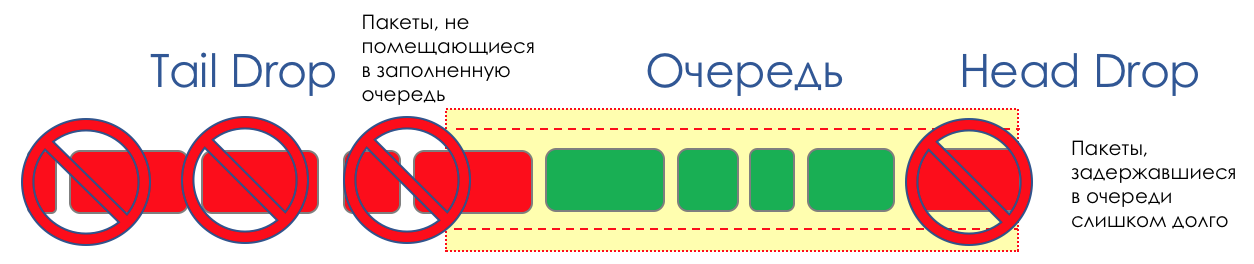
La chute de la queue et de la tête est un «front» pour éviter la congestion. Vous pouvez même dire - c'est son absence.Nous ne faisons rien tant que la file d'attente n'est pas pleine à 100%. Et après cela, nous commençons à éliminer tous les paquets nouvellement arrivés (ou retardés pendant longtemps).Si vous n'avez rien à faire pour atteindre l'objectif, quelque part il y a une nuance.Et cette nuance est TCP.Rappelez-vous ( plus profondément et extrêmement profondément ) comment TCP fonctionne - nous parlons d'implémentations modernes.Il existe une fenêtre coulissante (fenêtre coulissante ou rwnd - fenêtre annoncée du destinataire), que le destinataire contrôle, indiquant à l'expéditeur le montant qui peut être envoyé.Et il y a une fenêtre de surcharge ( CWND - Congestion Window), qui répond aux problèmes de réseau et est contrôlé par l'expéditeur.Le processus de transfert de données commence par un démarrage lent (démarrage lent ) avec une augmentation exponentielle de CWND. Avec chaque segment confirmé, 1 taille MSS est ajoutée au CWND, c'est-à-dire qu'il double en un temps égal à RTT (données là-bas, retour ACK) (Discours sur Reno / NewReno).Par exemple, la croissance exponentielle continue jusqu'à une valeur appelée ssthreshold (seuil de démarrage lent), qui est spécifiée dans la configuration TCP sur l'hôte.Commence ensuite le linéaireune augmentation de 1 / CWND pour chaque segment confirmé jusqu'à ce qu'il repose sur RWND ou que les pertes commencent (la perte est confirmée par une confirmation répétée (ACK dupliqué) ou aucune confirmation du tout).Dès qu'une perte de segment est détectée, TCP Backoff se produit - TCP réduit considérablement la fenêtre, réduisant en fait la vitesse d'envoi - et le mécanisme de récupération rapide démarre :
la croissance exponentielle continue jusqu'à une valeur appelée ssthreshold (seuil de démarrage lent), qui est spécifiée dans la configuration TCP sur l'hôte.Commence ensuite le linéaireune augmentation de 1 / CWND pour chaque segment confirmé jusqu'à ce qu'il repose sur RWND ou que les pertes commencent (la perte est confirmée par une confirmation répétée (ACK dupliqué) ou aucune confirmation du tout).Dès qu'une perte de segment est détectée, TCP Backoff se produit - TCP réduit considérablement la fenêtre, réduisant en fait la vitesse d'envoi - et le mécanisme de récupération rapide démarre :- envoyer des segments perdus (Retransmission rapide),
- la fenêtre est doublée,
- La valeur ssthreshold devient également égale à la moitié de la fenêtre atteinte,
- la croissance linéaire recommence jusqu'à la première perte,
- Répétez.
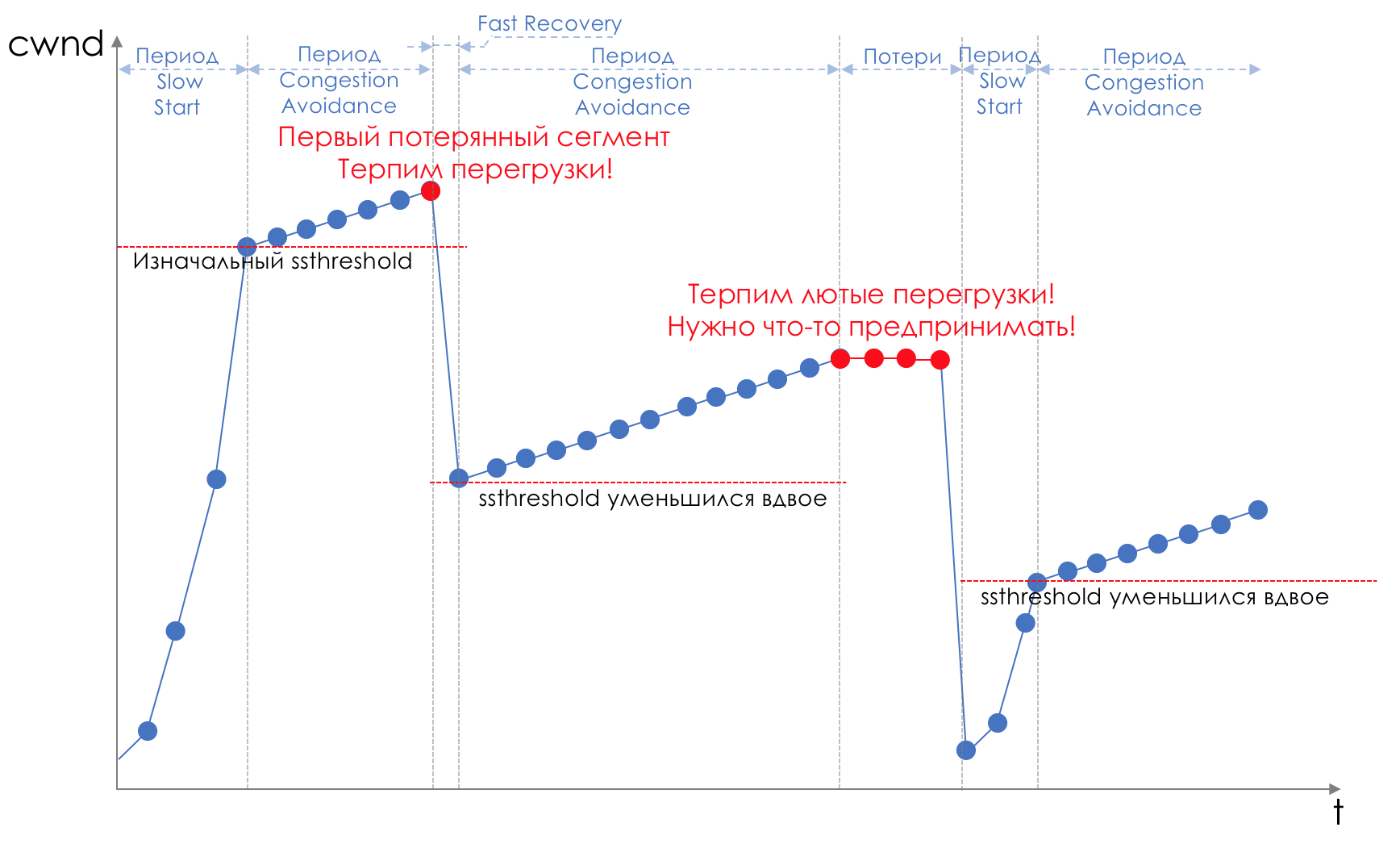 La perte peut signifier soit l'effondrement complet d'un segment de réseau, puis considérer qu'il est perdu, ou une congestion sur la ligne (lire le dépassement de tampon et rejeter un segment de cette session).Il s'agit de la méthode TCP permettant de maximiser l'utilisation de la bande passante disponible et de gérer la congestion. Et c'est assez efficace.Mais à quoi mène Tail Drop?
La perte peut signifier soit l'effondrement complet d'un segment de réseau, puis considérer qu'il est perdu, ou une congestion sur la ligne (lire le dépassement de tampon et rejeter un segment de cette session).Il s'agit de la méthode TCP permettant de maximiser l'utilisation de la bande passante disponible et de gérer la congestion. Et c'est assez efficace.Mais à quoi mène Tail Drop?- Disons que via un routeur se trouve le chemin de milliers de sessions TCP. À un moment donné, le trafic de session a atteint 1,1 Gb / s, la vitesse de l'interface de sortie - 1 Gb / s.
- Le trafic est plus rapide que les feuilles, les tampons sont remplis vsklyan .
- Tail Drop est activé jusqu'à ce que le répartiteur retire quelques paquets de la file d'attente.
- Dans le même temps, des dizaines ou des centaines de sessions enregistrent des pertes et passent à Fast Recovery (ou même Slow Start).
- , , Tail Drop .
- TCP- , .
- .
- Fast Recovery/Slow Start.
- .
En savoir plus sur les modifications apportées aux mécanismes TCP dans RFC 2001 ( démarrage lent TCP, évitement de congestion, retransmission rapide et algorithmes de récupération rapide ).Il s'agit d'une illustration typique d'une situation appelée Global TCP Synchronization : Global car de nombreuses sessions établies via ce nœud souffrent.Synchronisation , car ils souffrent en même temps. Et la situation se répétera jusqu'à ce qu'il y ait une surcharge.TCP - car UDP, qui ne dispose pas de mécanismes de contrôle de congestion, n'est pas affecté par celui-ci.Rien de mal ne se serait produit dans cette situation si elle n'avait pas causé l'utilisation sous-optimale de la bande - les écarts entre les dents de scie - l'argent gaspillé.Le deuxième problème est TCP Starvation - TCP depletion. Alors que TCP ralentit pour réduire la charge (ne soyons pas rusés - tout d'abord, afin de transmettre sûrement nos données), UDP, toute cette souffrance morale en général par le datagramme - en envoie le plus possible.Ainsi, la quantité de trafic TCP est réduite et UDP augmente (éventuellement), le prochain cycle de perte - récupération rapide se produit à un seuil inférieur. UDP prend de la place. La quantité totale de trafic TCP diminue.Comment résoudre le problème, il vaut mieux l'éviter. Essayons de réduire la charge avant qu'elle ne remplisse la file d'attente à l'aide du Fast Recovery / Slow Start, qui était juste contre nous.
Global car de nombreuses sessions établies via ce nœud souffrent.Synchronisation , car ils souffrent en même temps. Et la situation se répétera jusqu'à ce qu'il y ait une surcharge.TCP - car UDP, qui ne dispose pas de mécanismes de contrôle de congestion, n'est pas affecté par celui-ci.Rien de mal ne se serait produit dans cette situation si elle n'avait pas causé l'utilisation sous-optimale de la bande - les écarts entre les dents de scie - l'argent gaspillé.Le deuxième problème est TCP Starvation - TCP depletion. Alors que TCP ralentit pour réduire la charge (ne soyons pas rusés - tout d'abord, afin de transmettre sûrement nos données), UDP, toute cette souffrance morale en général par le datagramme - en envoie le plus possible.Ainsi, la quantité de trafic TCP est réduite et UDP augmente (éventuellement), le prochain cycle de perte - récupération rapide se produit à un seuil inférieur. UDP prend de la place. La quantité totale de trafic TCP diminue.Comment résoudre le problème, il vaut mieux l'éviter. Essayons de réduire la charge avant qu'elle ne remplisse la file d'attente à l'aide du Fast Recovery / Slow Start, qui était juste contre nous.ROUGE - Détection précoce aléatoire
Mais que se passe-t-il si nous prenons et enduisons des gouttes sur une partie du tampon?Relativement parlant, commencez à supprimer des paquets aléatoires lorsque la file d'attente est pleine à 80%, forçant certaines sessions TCP à réduire la fenêtre et, par conséquent, la vitesse.Et si la file d'attente est pleine à 90%, nous commençons à supprimer aléatoirement 50% des paquets.90% - la probabilité augmente jusqu'à Tail Drop (100% des nouveaux paquets sont rejetés).Les mécanismes qui implémentent une telle gestion de file d'attente sont appelés AQM - Adaptive (or Active) Queue Management,c'est ainsi que RED fonctionne .Détection précoce - correction d'une surcharge potentielle;Aléatoire - éliminer les paquets au hasard.Parfois, ils décodent RED (à mon avis, sémantiquement plus correctement), comme Random Early Discard.Graphiquement, cela ressemble à ceci: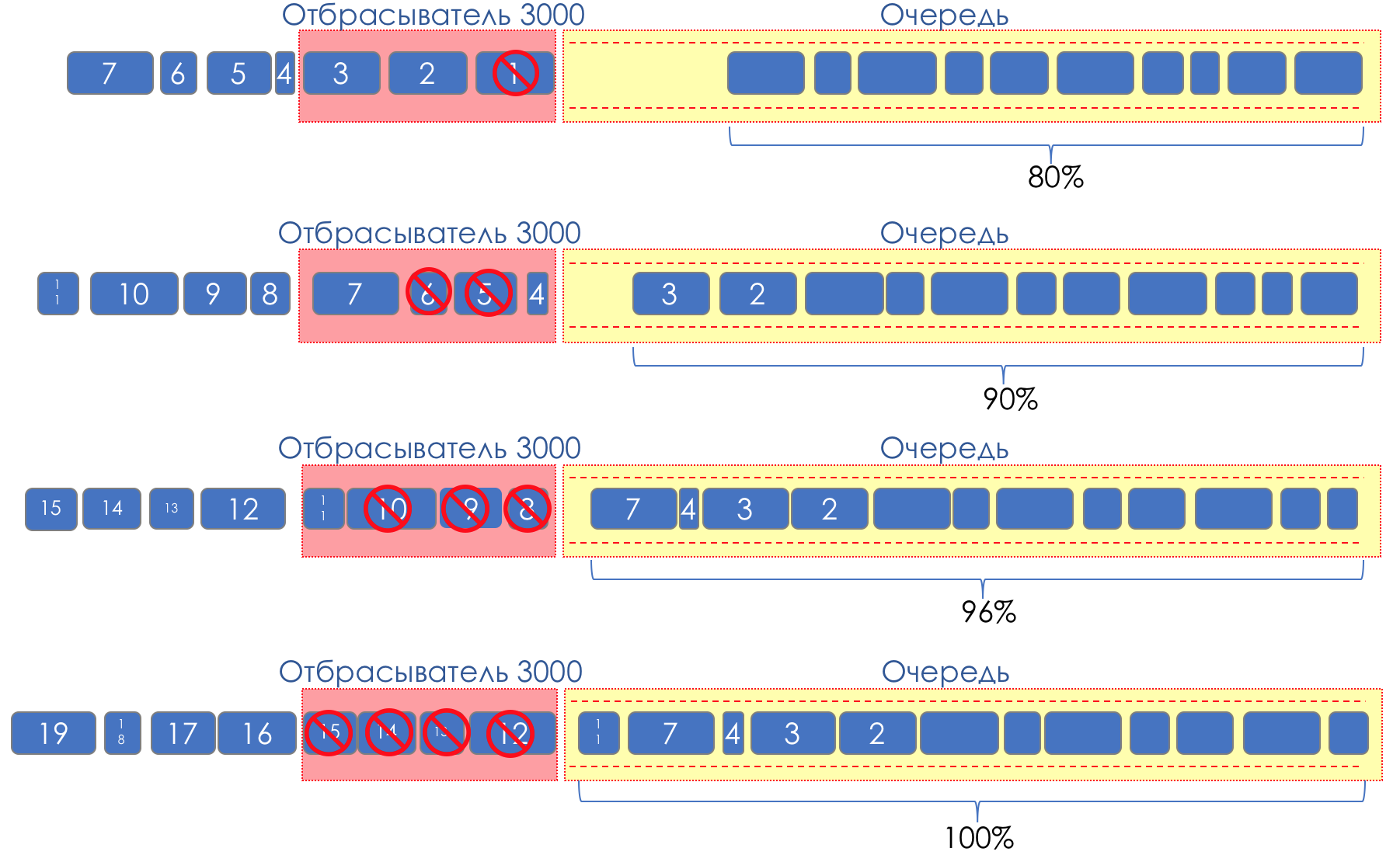
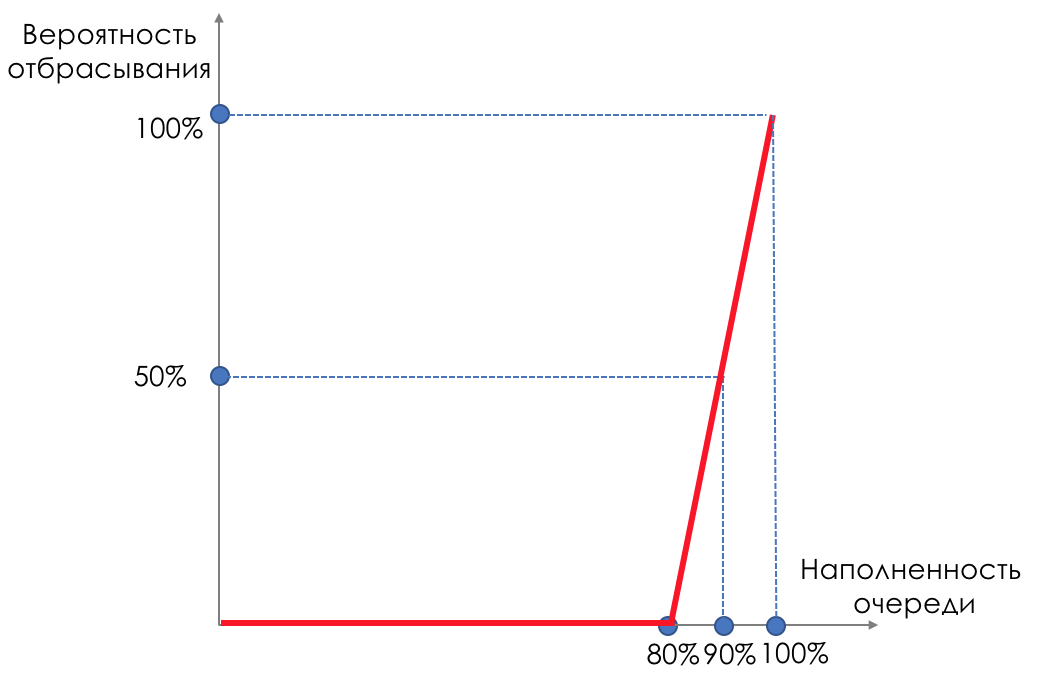 Tant que le tampon n'est pas rempli à 80%, les paquets ne sont pas du tout rejetés - la probabilité est de 0%.De 80 à 100 paquets commencent à être rejetés et plus le remplissage de la file d'attente est élevé.Le pourcentage passe donc de 0 à 30.Un effet secondaire de RED est que les sessions TCP agressives sont plus susceptibles de ralentir, simplement parce qu'il y a beaucoup de paquets et qu'ils sont plus susceptibles d'être abandonnés.L'inefficacité de l'utilisation de la bande ROUGE se résout en émoussant une partie beaucoup plus petite des séances sans provoquer un rabattement aussi grave entre les dents.Exactement pour la même raison, UDP ne peut pas tout occuper.
Tant que le tampon n'est pas rempli à 80%, les paquets ne sont pas du tout rejetés - la probabilité est de 0%.De 80 à 100 paquets commencent à être rejetés et plus le remplissage de la file d'attente est élevé.Le pourcentage passe donc de 0 à 30.Un effet secondaire de RED est que les sessions TCP agressives sont plus susceptibles de ralentir, simplement parce qu'il y a beaucoup de paquets et qu'ils sont plus susceptibles d'être abandonnés.L'inefficacité de l'utilisation de la bande ROUGE se résout en émoussant une partie beaucoup plus petite des séances sans provoquer un rabattement aussi grave entre les dents.Exactement pour la même raison, UDP ne peut pas tout occuper.WRED - Détection précoce aléatoire pondérée
Mais à l'audience de tous, probablement, toujours WRED . Le lecteur astucieux de linkmeup a déjà suggéré qu'il s'agit du même ROUGE, mais pondéré à tour de rôle. Et il n'avait pas tout à fait raison.RED opère dans la même file d'attente. Cela n'a aucun sens de revenir sur EF si le BE est plein. Par conséquent, le pesage à son tour n'apportera rien.Ici, Drop Precedence fonctionne.Et dans la même file d'attente, les paquets avec une priorité de suppression différente auront des courbes différentes. Plus la priorité est basse, plus il est probable qu'elle soit critiquée. Il y a trois courbes ici:rouge - moins de trafic prioritaire (en termes de baisse), jaune - plus, vert - maximum.Le trafic rouge commence à être rejeté lorsque le tampon est plein à 20%, de 20 à 40 il descend à 20%, puis à Tail Drop.Le jaune commence plus tard - de 30 à 50, il est défaussé jusqu'à 10%, puis - Tail Drop.Le vert est le moins sensible: de 50 à 100, il croît en douceur à 5%. Vient ensuite Tail Drop.Dans le cas du DSCP, ce pourrait être AF11, AF12 et AF13, respectivement vert, jaune et rouge.
Il y a trois courbes ici:rouge - moins de trafic prioritaire (en termes de baisse), jaune - plus, vert - maximum.Le trafic rouge commence à être rejeté lorsque le tampon est plein à 20%, de 20 à 40 il descend à 20%, puis à Tail Drop.Le jaune commence plus tard - de 30 à 50, il est défaussé jusqu'à 10%, puis - Tail Drop.Le vert est le moins sensible: de 50 à 100, il croît en douceur à 5%. Vient ensuite Tail Drop.Dans le cas du DSCP, ce pourrait être AF11, AF12 et AF13, respectivement vert, jaune et rouge. Il est très important ici qu'il fonctionne avec TCP et qu'il ne s'applique absolument pas à UDP.Ou une application utilisant UDP ignore les pertes, comme dans le cas de la téléphonie ou du streaming vidéo, et cela affecte négativement ce que l'utilisateur voit.Ou l'application elle-même contrôle la livraison et vous demande de renvoyer le même package. Cependant, il n'est pas nécessaire de demander à la source d'abaisser le débit de transmission. Et au lieu de réduire la charge, une augmentation est due aux retransmissions.C'est pourquoi seul Tail Drop est utilisé pour EF.Pour CS6, CS7, Tail Drop est également utilisé, car aucune vitesse élevée n'est supposée et WRED ne résoudra rien.Pour AF, WRED est appliqué. AFxy, où x est la classe du service, c'est-à-dire la file d'attente dans laquelle il tombe, et y est la priorité de suppression - la même couleur.Pour BE, la décision est prise en fonction du trafic en vigueur dans cette file d'attente.Au sein d'un même routeur, un étiquetage interne spécial des paquets est utilisé, différent de celui qui porte les en-têtes. Par conséquent, MPLS et 802.1q, où il n'est pas possible de coder la priorité de suppression, peuvent être traités dans des files d'attente avec différentes priorités de suppression.Par exemple, un paquet MPLS est arrivé à un nœud, il ne porte pas d'étiquetage Drop Precedence, cependant, selon les résultats du polissage, il s'est avéré être jaune et peut être jeté avant d'être placé dans la file d'attente (ce qui peut être déterminé par le champ Classe de trafic).Il convient de rappeler que tout cet arc-en-ciel n'existe qu'à l'intérieur du nœud. Il n'y a pas de concept de couleur dans la ligne entre voisins.Bien qu'il soit possible, bien sûr, de coder la couleur dans la partie Drop Precedence de DSCP.
Il est très important ici qu'il fonctionne avec TCP et qu'il ne s'applique absolument pas à UDP.Ou une application utilisant UDP ignore les pertes, comme dans le cas de la téléphonie ou du streaming vidéo, et cela affecte négativement ce que l'utilisateur voit.Ou l'application elle-même contrôle la livraison et vous demande de renvoyer le même package. Cependant, il n'est pas nécessaire de demander à la source d'abaisser le débit de transmission. Et au lieu de réduire la charge, une augmentation est due aux retransmissions.C'est pourquoi seul Tail Drop est utilisé pour EF.Pour CS6, CS7, Tail Drop est également utilisé, car aucune vitesse élevée n'est supposée et WRED ne résoudra rien.Pour AF, WRED est appliqué. AFxy, où x est la classe du service, c'est-à-dire la file d'attente dans laquelle il tombe, et y est la priorité de suppression - la même couleur.Pour BE, la décision est prise en fonction du trafic en vigueur dans cette file d'attente.Au sein d'un même routeur, un étiquetage interne spécial des paquets est utilisé, différent de celui qui porte les en-têtes. Par conséquent, MPLS et 802.1q, où il n'est pas possible de coder la priorité de suppression, peuvent être traités dans des files d'attente avec différentes priorités de suppression.Par exemple, un paquet MPLS est arrivé à un nœud, il ne porte pas d'étiquetage Drop Precedence, cependant, selon les résultats du polissage, il s'est avéré être jaune et peut être jeté avant d'être placé dans la file d'attente (ce qui peut être déterminé par le champ Classe de trafic).Il convient de rappeler que tout cet arc-en-ciel n'existe qu'à l'intérieur du nœud. Il n'y a pas de concept de couleur dans la ligne entre voisins.Bien qu'il soit possible, bien sûr, de coder la couleur dans la partie Drop Precedence de DSCP.Les gouttes peuvent également apparaître dans un réseau non chargé, où il semblerait qu'aucun débordement de file d'attente ne devrait se produire. Comment?
La raison peut en être de courtes rafales - des rafales - de trafic. L'exemple le plus simple - 5 applications en même temps ont décidé de transférer le trafic vers un hôte final.
Un exemple est plus compliqué - l'expéditeur est connecté via l'interface 10 Gb / s et le récepteur est de 1 Gb / s. L'environnement lui-même vous permet de créer des packages plus rapidement sur l'expéditeur. Le contrôle de flux Ethernet du récepteur demande à l'hôte le plus proche de ralentir et les paquets commencent à s'accumuler dans les tampons.
Eh bien, que faire quand tout empire?7. Gestion de la congestion
Lorsque tout va mal, la priorité de traitement doit être donnée à un trafic plus important. L'importance de chaque colis est déterminée au stade de la classification.Mais qu'est-ce qui est mauvais?Tous les tampons ne doivent pas être obstrués pour que les applications commencent à rencontrer des problèmes.L'exemple le plus simple est les paquets vocaux, qui se rassemblent autour de grands paquets de gros paquets d'une application téléchargeant un fichier.Cela augmentera le délai, ruinera la gigue et provoquera éventuellement des chutes.Autrement dit, nous avons des problèmes à fournir des services de qualité en l'absence de congestion réelle.Ce problème est conçu pour résoudre le mécanisme de gestion de la congestion.Le trafic des différentes applications est divisé en files d'attente, comme nous l'avons vu plus haut.Mais seulement en conséquence, tout devrait à nouveau fusionner en une seule interface. La sérialisation se produit toujours de manière séquentielle.Comment différentes files d'attente parviennent-elles à fournir différents niveaux de services?Supprimez les paquets de différentes files d'attente de différentes manières.Le répartiteur s'y est engagé.Nous considérerons aujourd'hui la majorité des répartiteurs, en commençant par le plus simple:- FIFO - une seule ligne, tout en BE, C - injustice.
- PQ - la route des oligarques, les laquais cèdent la place.
- FQ - tous sont égaux.
- DWRR - tous sont égaux, mais certains sont plus égaux.
FIFO - Premier entré, premier sorti
Le cas le plus simple, en fait l'absence de QoS, est que tout le trafic est traité de la même manière - dans une file d'attente.Les paquets quittent la file d'attente exactement dans l'ordre dans lequel ils sont arrivés, d'où le nom: première entrée - première et gauche .FIFO n'est ni un répartiteur au sens plein du terme, ni un mécanisme DiffServ en général, car il ne sépare pas réellement les classes.Si la file d'attente commence à se remplir, les retards et la gigue commencent à augmenter, vous ne pouvez pas les gérer, car vous ne pouvez pas extraire un paquet important du milieu de la file d'attente.Des sessions TCP agressives avec une taille de paquet de 1 500 octets peuvent occuper toute la file d'attente, ce qui fait souffrir les petits paquets vocaux.Dans FIFO, toutes les classes fusionnent dans CS0. Cependant, malgré toutes ces lacunes, c'est ainsi que fonctionne Internet aujourd'hui.La plupart des fournisseurs FIFO sont désormais le répartiteur par défaut avec une file d'attente pour tout le trafic de transit et une autre pour les paquets de service générés localement.C'est simple, c'est extrêmement bon marché. Si les canaux sont larges et qu'il y a peu de trafic, tout va bien.La quintessence de l'idée que la QoS - pour les pauvres - élargit la bande, et les clients seront satisfaits, et votre salaire augmentera de plusieurs fois.Ce n'est que de cette façon que l'équipement de réseau fonctionnait autrefois.Mais très vite, le monde a été confronté au fait que cela ne fonctionnerait tout simplement pas.Avec la tendance aux réseaux convergents, il est devenu clair que les différents types de trafic (service, voix, multimédia, navigation sur Internet, partage de fichiers) ont des exigences de réseau fondamentalement différentes.FIFO ne suffisait pas, ils ont donc créé plusieurs files d'attente et commencé à produire des schémas de planification du trafic.Cependant, FIFO ne quitte jamais nos vies: à l'intérieur de chacune des files d'attente, les paquets sont toujours traités selon le principe FIFO.
Cependant, malgré toutes ces lacunes, c'est ainsi que fonctionne Internet aujourd'hui.La plupart des fournisseurs FIFO sont désormais le répartiteur par défaut avec une file d'attente pour tout le trafic de transit et une autre pour les paquets de service générés localement.C'est simple, c'est extrêmement bon marché. Si les canaux sont larges et qu'il y a peu de trafic, tout va bien.La quintessence de l'idée que la QoS - pour les pauvres - élargit la bande, et les clients seront satisfaits, et votre salaire augmentera de plusieurs fois.Ce n'est que de cette façon que l'équipement de réseau fonctionnait autrefois.Mais très vite, le monde a été confronté au fait que cela ne fonctionnerait tout simplement pas.Avec la tendance aux réseaux convergents, il est devenu clair que les différents types de trafic (service, voix, multimédia, navigation sur Internet, partage de fichiers) ont des exigences de réseau fondamentalement différentes.FIFO ne suffisait pas, ils ont donc créé plusieurs files d'attente et commencé à produire des schémas de planification du trafic.Cependant, FIFO ne quitte jamais nos vies: à l'intérieur de chacune des files d'attente, les paquets sont toujours traités selon le principe FIFO.PQ - Mise en file d'attente prioritaire
Le deuxième mécanisme le plus compliqué et la tentative de division du service en classes est une file d'attente prioritaire .Le trafic est désormais disposé dans plusieurs files d'attente en fonction de sa priorité de classe (par exemple, bien que pas nécessairement, le même BE, AF1-4, EF, CS6-7). Le répartiteur parcourt une file d'attente après l'autre.Tout d'abord, il ignore tous les paquets de la file d'attente de priorité la plus élevée, puis de moins, puis de moins. Et donc en cercle.
Le répartiteur ne commence pas à récupérer les paquets de faible priorité tant que la file d'attente de haute priorité n'est pas vide. Si, au moment du traitement des paquets de faible priorité, un paquet arrive dans une file d'attente de priorité plus élevée, le répartiteur y bascule et ce n'est qu'après avoir été vidé qu'il revient aux autres.
Si, au moment du traitement des paquets de faible priorité, un paquet arrive dans une file d'attente de priorité plus élevée, le répartiteur y bascule et ce n'est qu'après avoir été vidé qu'il revient aux autres. PQ fonctionne presque aussi bien que FIFO.Il est idéal pour des types de trafic tels que les paquets de protocole et la voix, où les retards sont critiques et le volume total n'est pas très élevé.Eh bien, vous devez admettre, vous ne devriez pas garder BFD Bonjour, car plusieurs gros morceaux vidéo de YouTube sont venus?Mais là réside le manque de PQ - si la file d'attente prioritaire est chargée de trafic, le répartiteur ne basculera jamais du tout vers les autres.Et si un docteur maléfique, à la recherche de méthodes de conquête du monde, décide de marquer tout son trafic crapuleux avec la plus haute marque noire, tous les autres attendront consciencieusement et seront ensuite jetés.Il n'est pas non plus nécessaire de parler d'une voie garantie pour chaque ligne.Les files d'attente de haute priorité peuvent être réduites par la vitesse du trafic qui y est traité. Ensuite, d'autres ne mourront pas de faim. Cependant, contrôler cela n'est pas facile.
PQ fonctionne presque aussi bien que FIFO.Il est idéal pour des types de trafic tels que les paquets de protocole et la voix, où les retards sont critiques et le volume total n'est pas très élevé.Eh bien, vous devez admettre, vous ne devriez pas garder BFD Bonjour, car plusieurs gros morceaux vidéo de YouTube sont venus?Mais là réside le manque de PQ - si la file d'attente prioritaire est chargée de trafic, le répartiteur ne basculera jamais du tout vers les autres.Et si un docteur maléfique, à la recherche de méthodes de conquête du monde, décide de marquer tout son trafic crapuleux avec la plus haute marque noire, tous les autres attendront consciencieusement et seront ensuite jetés.Il n'est pas non plus nécessaire de parler d'une voie garantie pour chaque ligne.Les files d'attente de haute priorité peuvent être réduites par la vitesse du trafic qui y est traité. Ensuite, d'autres ne mourront pas de faim. Cependant, contrôler cela n'est pas facile.
Les mécanismes suivants parcourent tour à tour toutes les files d'attente, en leur prélevant une certaine quantité de données, offrant ainsi des conditions plus honnêtes. Mais ils le font différemment.FQ-Fair Queuing
Le prochain candidat au rôle de répartiteur idéal est celui des mécanismes de file d'attente équitables .FQ - Fair Queuing
Son histoire a commencé en 1985, lorsque John Nagle a suggéré de créer une file d'attente pour chaque flux de données. En esprit, cela est proche de l'approche IntServ et s'explique facilement par le fait que l'idée de classes de service, comme DiffServ, n'existait pas à l'époque.FQ a extrait la même quantité de données de chaque file d'attente dans l'ordre.L'honnêteté réside dans le fait que le répartiteur ne fonctionne pas avec le nombre de paquets, mais avec le nombre de bits pouvant être transmis depuis chaque file d'attente.Un flux TCP agressif ne peut donc pas inonder l'interface, et tout le monde bénéficie de l'égalité des chances.En théorie. FQ n'a jamais été implémenté dans la pratique comme mécanisme de répartition des files d'attente dans les équipements réseau.Il y a trois inconvénients:La première - évidente - c'est très coûteux - pour démarrer une file d'attente pour chaque flux, compter le poids de chaque paquet et toujours se soucier des bits à sauter et de la taille du paquet.La seconde - moins évidente - tous les threads bénéficient de chances égales en termes de bande passante. Et si je veux inégale?Le troisième - non évident - l'honnêteté FQ est absolue: tout le monde a des retards égaux, mais il y a des threads qui sont plus importants que le retard que le groupe.Par exemple, parmi 256 flux, il y en a des vocaux, ce qui signifie que chacun d'eux n'atteindra que 256 threads.Et que faire avec eux n'est pas clair. Ici, vous pouvez voir qu'en raison de la grande taille du paquet dans la 3ème étape, au cours des deux premiers cycles, nous avons traité un paquet des deux premiers.La description des mécanismes bit à bit de Round Robin et GPS dépasse déjà le cadre de cet article, et je renvoie le lecteur à une étude indépendante .
Ici, vous pouvez voir qu'en raison de la grande taille du paquet dans la 3ème étape, au cours des deux premiers cycles, nous avons traité un paquet des deux premiers.La description des mécanismes bit à bit de Round Robin et GPS dépasse déjà le cadre de cet article, et je renvoie le lecteur à une étude indépendante .WFQ - File d'attente équitable pondérée
Les deuxième et partiellement troisième failles du FQ ont tenté de fermer le WFQ, publié en 1989.Chaque file d'attente était dotée d'un poids et, par conséquent, du droit de donner du trafic en multiples de poids pour un cycle.Le poids a été calculé sur la base de deux paramètres: toujours pertinent, puis la priorité IP et la longueur du paquet.Dans le contexte de WFQ, plus il y a de poids, pire c'est.Par conséquent, plus la priorité IP est élevée, plus le poids du paquet est faible.Plus la taille de l'emballage est petite, plus son poids est petit.Ainsi, les petits paquets à haute priorité obtiennent le plus de ressources, tandis que les géants à faible priorité attendent.Dans l'illustration ci-dessous, les paquets ont reçu des poids tels qu'au premier un paquet de la première file d'attente est ignoré, puis deux du deuxième, à nouveau de la première et seulement ensuite le troisième est traité. Ainsi, par exemple, cela pourrait se produire si la taille des paquets dans la deuxième étape est relativement petite. À propos de la dure ingénierie de WFQ, avec son temps de fin de paquet, son temps virtuel et le théorème de la perruque, vous pouvez lire dans un document couleur curieux .Cependant, cela n'a pas résolu les premier et troisième problèmes. L'approche basée sur les flux était tout aussi gênante, et les flux qui nécessitaient de courts délais et une gigue stable ne les recevaient pas.Cependant, cela n'a pas empêché WFQ d'être utilisé dans certains appareils Cisco (pour la plupart anciens). Il y avait jusqu'à 256 files d'attente dans lesquelles les threads étaient placés en fonction du hachage de leurs en-têtes. Un compromis entre le paradigme Flow-Based et des ressources limitées.
À propos de la dure ingénierie de WFQ, avec son temps de fin de paquet, son temps virtuel et le théorème de la perruque, vous pouvez lire dans un document couleur curieux .Cependant, cela n'a pas résolu les premier et troisième problèmes. L'approche basée sur les flux était tout aussi gênante, et les flux qui nécessitaient de courts délais et une gigue stable ne les recevaient pas.Cependant, cela n'a pas empêché WFQ d'être utilisé dans certains appareils Cisco (pour la plupart anciens). Il y avait jusqu'à 256 files d'attente dans lesquelles les threads étaient placés en fonction du hachage de leurs en-têtes. Un compromis entre le paradigme Flow-Based et des ressources limitées.CBWFQ - WFQ basé sur les classes
CBWFQ a fait l'approche du problème de complexité avec l'avènement de DiffServ. Behavior Aggregate a classé toutes les catégories de trafic en 8 classes et, par conséquent, les files d'attente. Cela lui a donné un nom et a considérablement simplifié les files d'attente.Le poids dans CBWFQ a acquis une signification différente. Le poids a été attribué aux classes (pas aux threads) manuellement dans la configuration à la demande de l'administrateur, car le champ DSCP était déjà utilisé pour la classification.Autrement dit, DSCP a déterminé la file d'attente à mettre en place et le poids configuré - combien de voies sont disponibles pour cette file d'attente.Plus important encore, cela a indirectement rendu la vie un peu plus facile et les flux à faible latence, qui étaient maintenant regroupés dans une (deux-trois- ...) files d'attente et recevaient leurs points forts beaucoup plus souvent. La vie est devenue meilleure, mais toujours pas bonne - il n'y a aucune garantie - en général, à WFQ tout est toujours égal en termes de retards.Et la nécessité d'une surveillance constante de la taille des paquets, de leur fragmentation et de leur défragmentation, n'a pas disparu.CBWFQ + LLQ - File d'attente à faible latence
L'approche finale, point culminant d'une approche bit par bit, est l'union de CBWFQ avec PQ.L'une des files d'attente devient la soi-disant LLQ (file d'attente à faible latence), et tandis que toutes les autres files d'attente sont traitées par le gestionnaire CBWFQ, le gestionnaire PQ s'exécute entre les LLQ et les autres.Autrement dit, alors qu'il y a des paquets dans LLQ, les files d'attente restantes attendent, leurs délais augmentent. Dès que les paquets dans LLQ se sont épuisés, nous sommes allés traiter le reste. Des paquets sont apparus dans LLQ - ils ont oublié le reste, y sont retournés.FIFO fonctionne également à l'intérieur de LLQ, vous ne devez donc pas tout pousser sans y arriver, augmentant l'utilisation du tampon et le retard en même temps.Néanmoins, pour que les files d'attente non prioritaires ne meurent pas de faim, il convient de définir une limite de bande passante dans LLQ. Ainsi, les moutons sont pleins et les loups sont en sécurité.
Ainsi, les moutons sont pleins et les loups sont en sécurité.RR - Round-Robin
Main dans la main avec FQ marcha et RR .L'un était honnête, mais pas simple. L'autre est tout à fait le contraire. RR a parcouru les files d'attente, en extrayant un nombre égal de paquets. L'approche est plus primitive que FQ, et donc malhonnête par rapport aux différents flux. Des sources agressives pourraient facilement inonder la bande de paquets de 1 500 octets.Cependant, il était très simple à implémenter - vous n'avez pas besoin de connaître la taille du paquet dans la file d'attente, de le fragmenter, puis de le récupérer.Cependant, son injustice dans l'attribution de la bande a bloqué son chemin vers le monde - dans le monde des réseaux, le Round-Robin pur n'a pas été mis en œuvre.
RR a parcouru les files d'attente, en extrayant un nombre égal de paquets. L'approche est plus primitive que FQ, et donc malhonnête par rapport aux différents flux. Des sources agressives pourraient facilement inonder la bande de paquets de 1 500 octets.Cependant, il était très simple à implémenter - vous n'avez pas besoin de connaître la taille du paquet dans la file d'attente, de le fragmenter, puis de le récupérer.Cependant, son injustice dans l'attribution de la bande a bloqué son chemin vers le monde - dans le monde des réseaux, le Round-Robin pur n'a pas été mis en œuvre.WRR - Round Robin pondéré
Le même sort est avec WRR, qui a ajouté du poids aux files d'attente en fonction de la priorité IP. Dans WRR, pas un nombre égal de paquets a été retiré, mais un multiple du poids de la file d'attente.Il serait possible de donner plus de poids aux files d'attente avec des paquets plus petits, mais cela n'était pas possible de manière dynamique.
DWRR - Round Robin pondéré en fonction du déficit
Et tout à coup, une approche extrêmement curieuse en 1995 a été proposée par M. Shreedhar et G. Varghese.Chaque ligne a une ligne de crédit distincte en bits.Lors du passage de la file d'attente, autant de packages sont émis qu'il y a suffisamment de crédit.La taille du colis en tête de file d'attente est déduite du montant du prêt.Si la différence est supérieure à zéro, ce paquet est supprimé et le suivant est vérifié. Donc, jusqu'à ce que la différence soit inférieure à zéro.Si même le premier colis n'a pas assez de crédit, enfin, hélas, les coulées de boue, il reste dans la file d'attente.Avant le prochain passage, le crédit de chaque ligne est augmenté d'un certain montant, appelé quantum .Pour différentes files d'attente, le quantum est différent - plus la bande que vous devez donner est grande, plus le quantum est grand.Ainsi, toutes les files d'attente reçoivent une bande passante garantie, quelle que soit la taille des paquets qu'elle contient.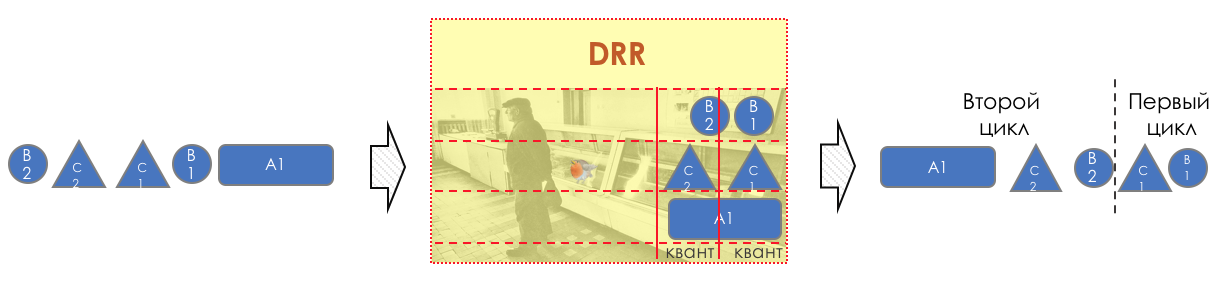 D'après l'explication ci-dessus, il ne serait pas clair pour moi comment cela fonctionne.
D'après l'explication ci-dessus, il ne serait pas clair pour moi comment cela fonctionne.Trouvons les étapes ...:
- DRR ( W),
- 4 ,
- 0- 500 ,
- 1- — 1000,
- 2- 1500,
- 3- 4000,
- — 1600 .

1
1. 0, 1600 ()
0- . :
— (1600 — 500 = 1100).
— — (1100 — 500 = 600).
— — (600 — 500 = 100).
— (100 — 500 = -400). .
— 100 .
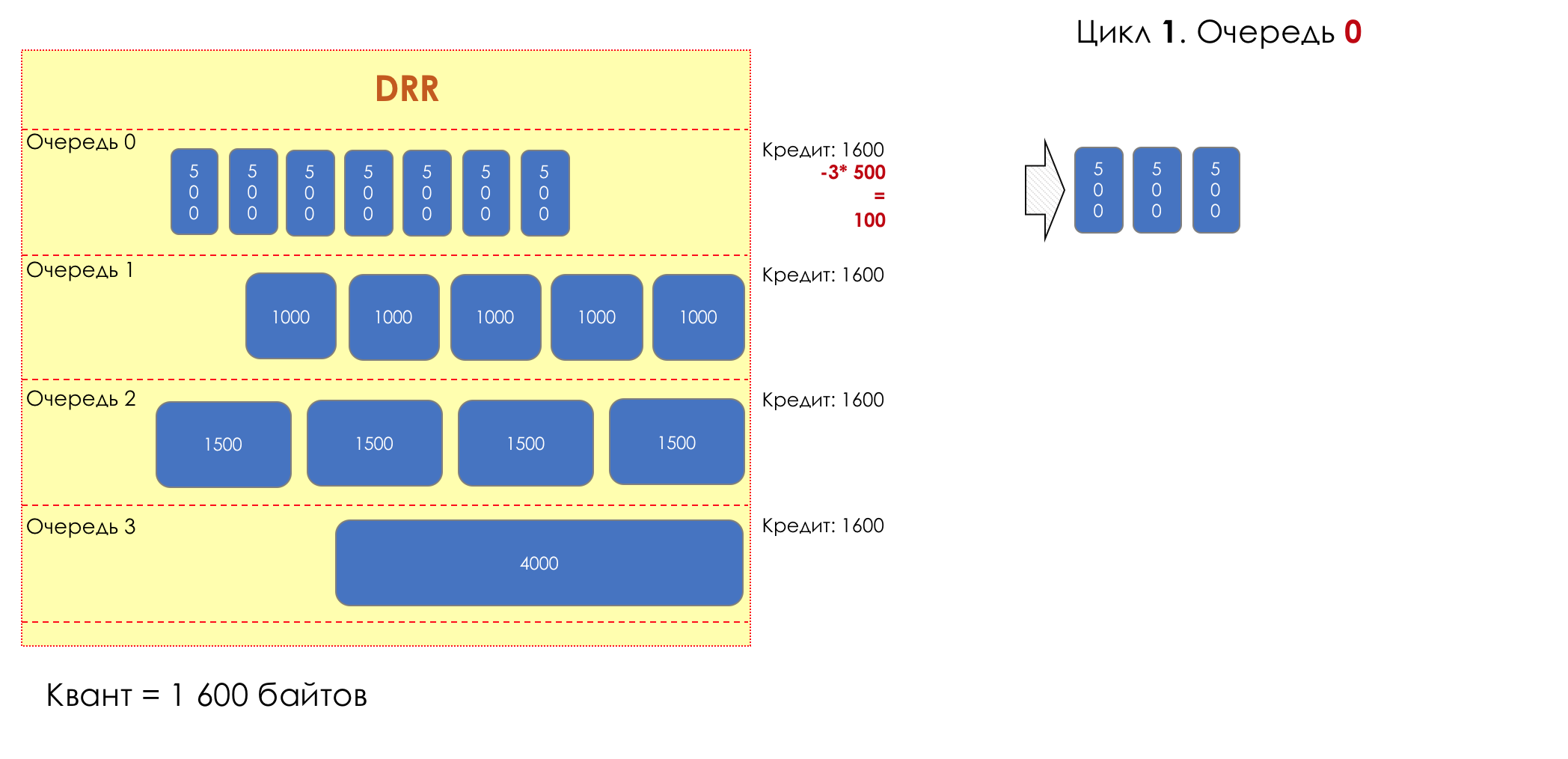 1. 1
1. 1— (1600 — 1000 = 600).
(600 — 1000 = -400). .
— 600 .
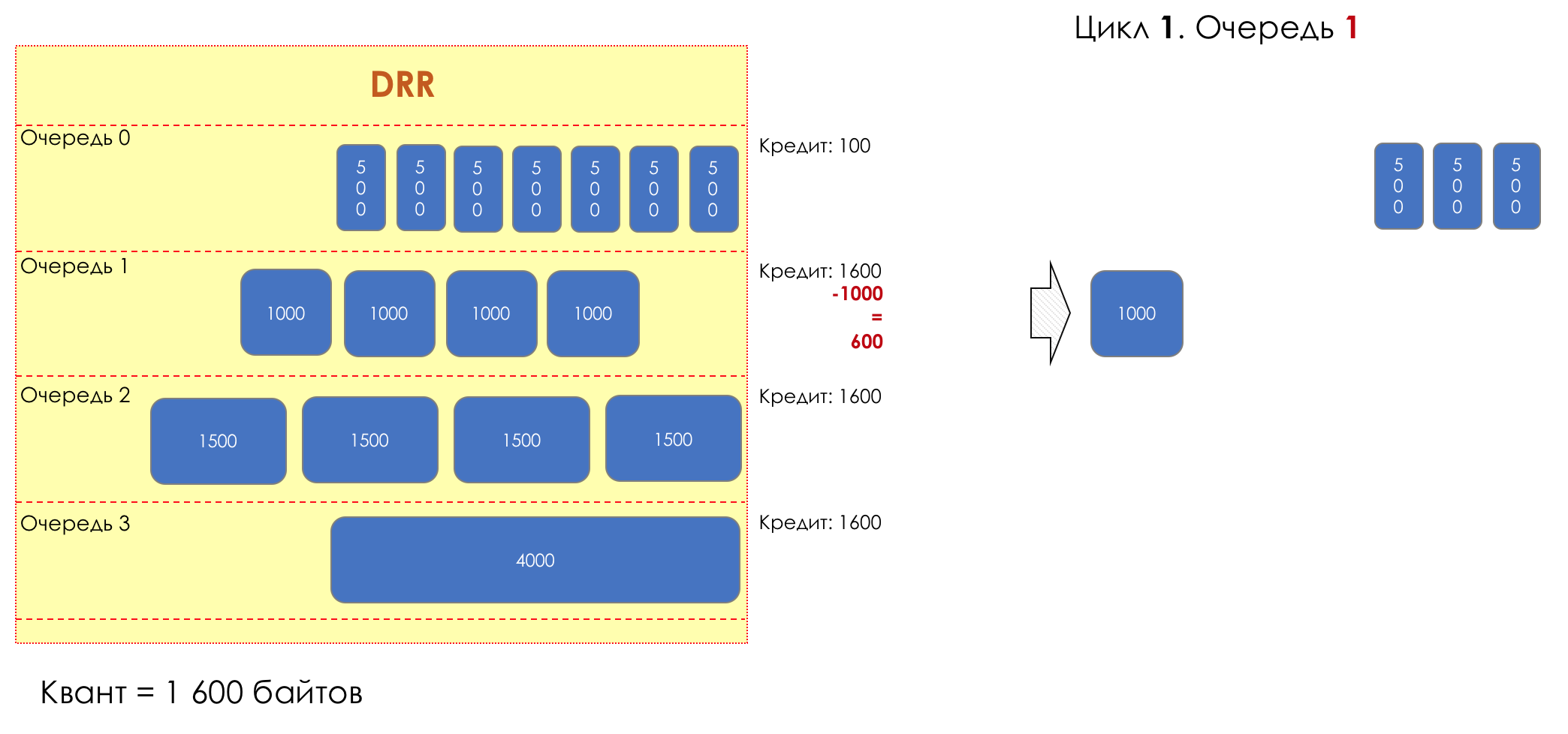 1. 2
1. 2— (1600 — 1500 = 100).
(100 — 1000 = -900). .
— 100 .
 1. 3
1. 3. (1600 — 4000 = -2400).
.
— 1600 .
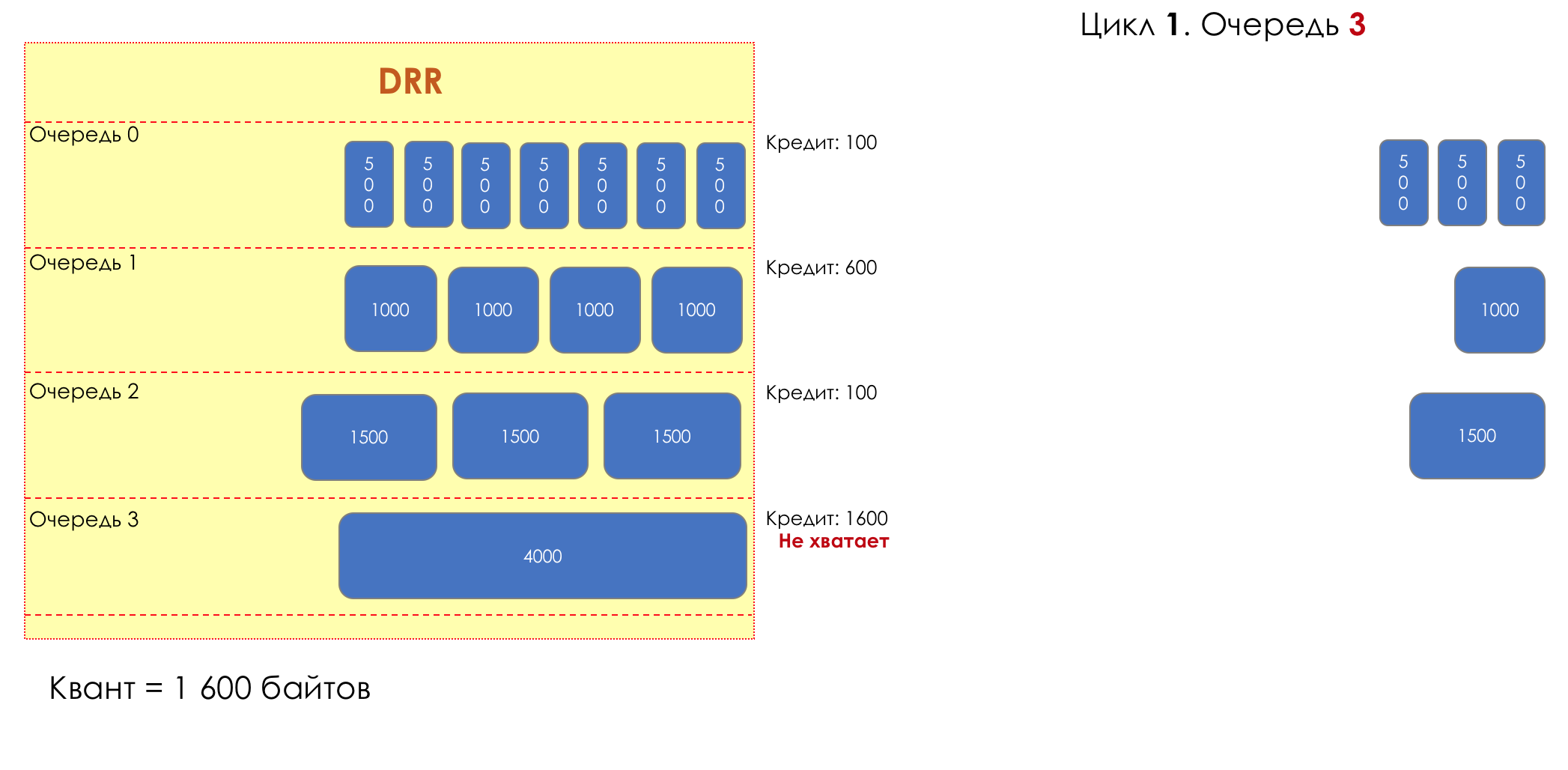
, :
- 0 — 1500
- 1 — 1000
- 2 — 1500
- 3 — 0
:
- 0 — 100
- 1 — 600
- 2 — 100
- 3 — 1600
2
— 1600 .
2. 01700 (100 + 1600).
— (1700 — 3*500 = 200).
.
— 200 .
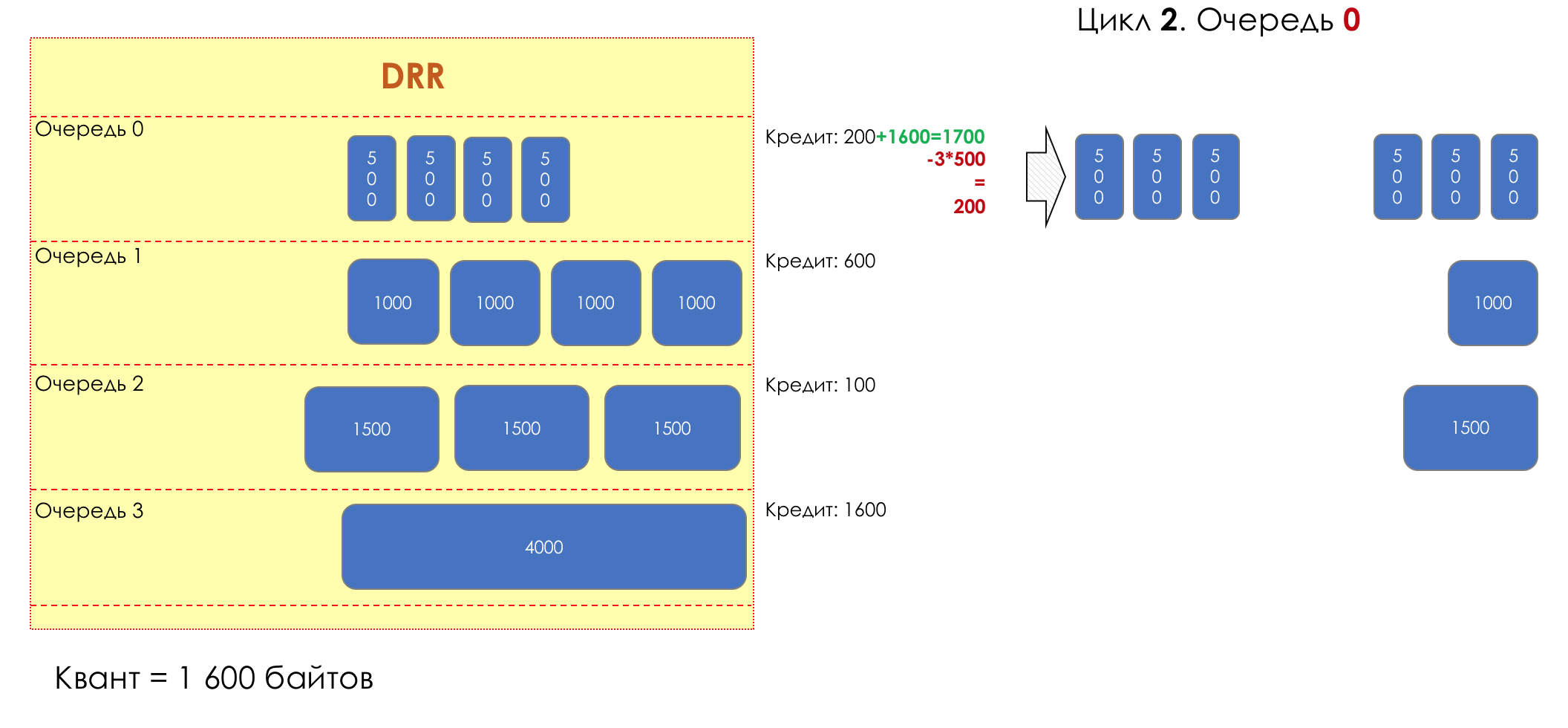 2. 1
2. 12200 (600 + 1600).
— (2200 — 2*1000 = 200).
.
— 200 .
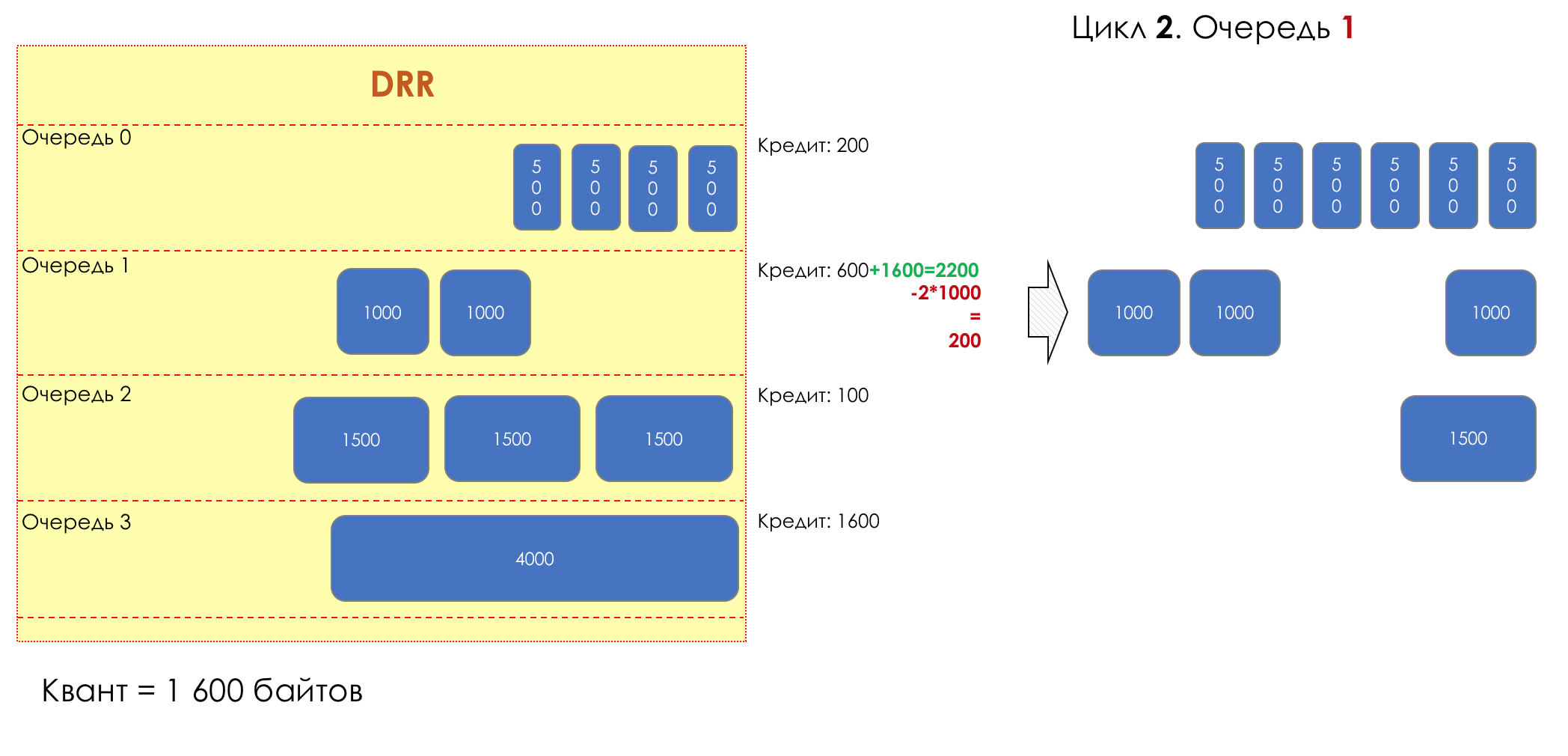 2. 2
2. 21700 (100 + 1600).
— (2200 — 1500 = 200).
— .
— 200 .
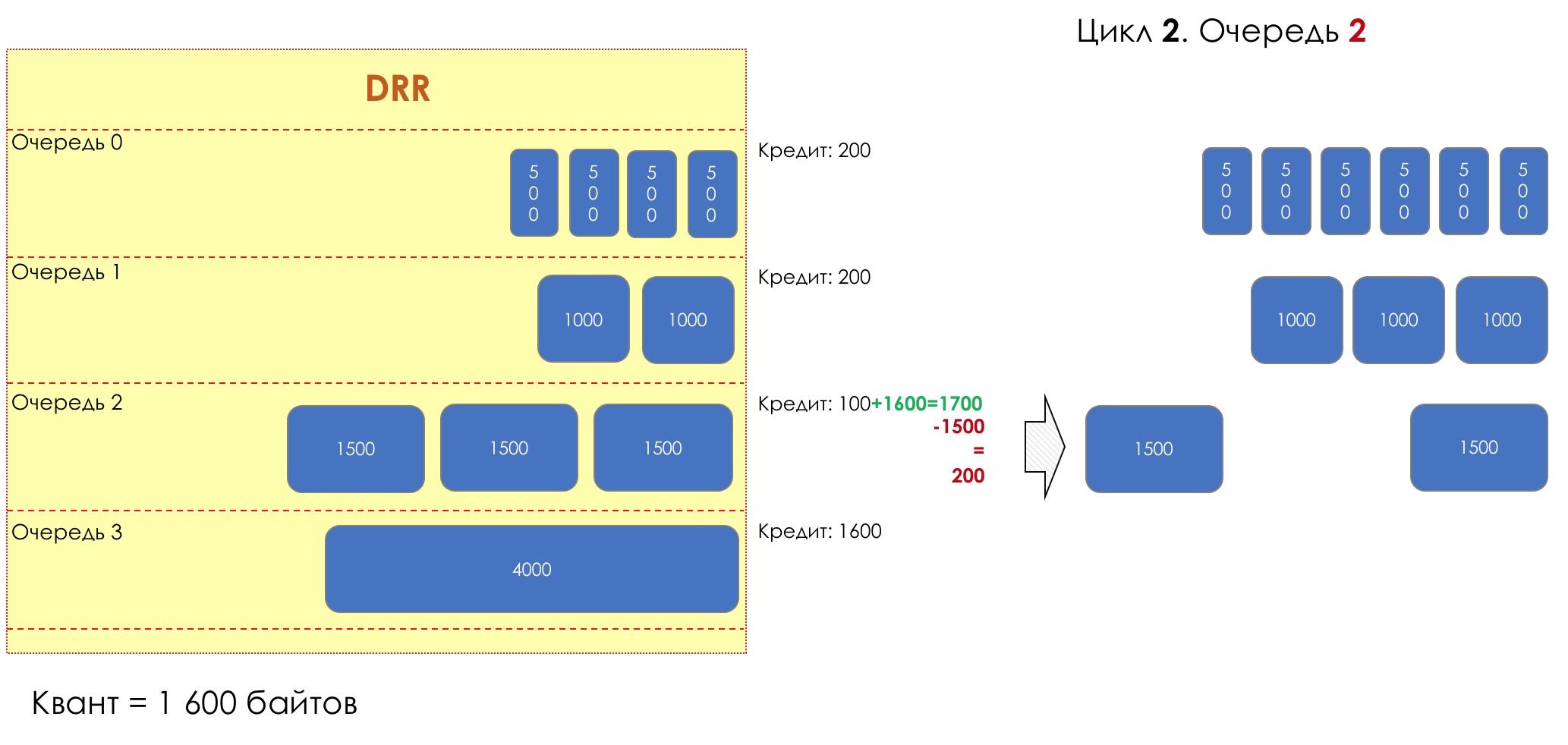 2. 3
2. 33200 (1600 + 1600).
(3200 — 4000 = -800)
— 3200 .
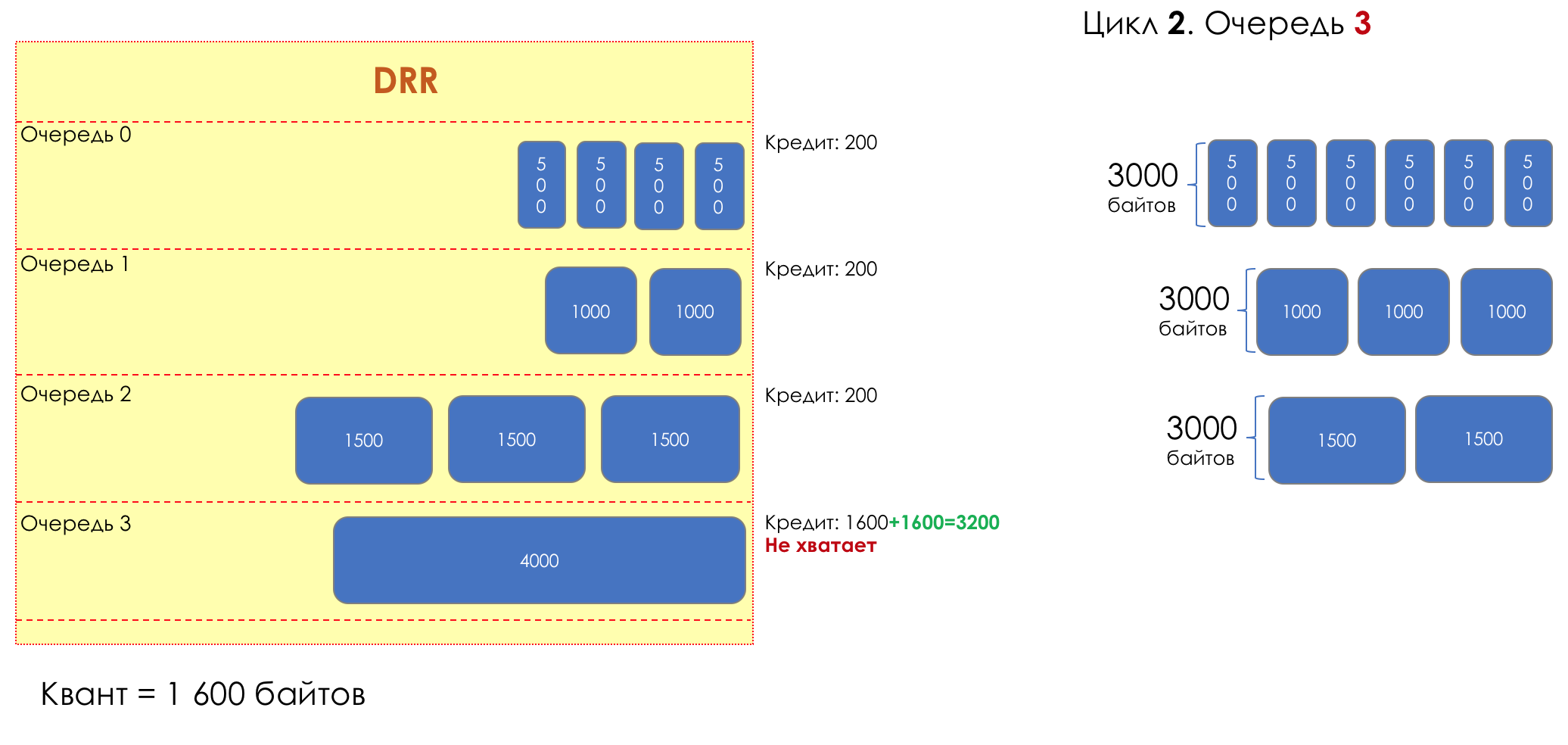
, :
- 0 — 3000
- 1 — 3000
- 2 — 3000
- 3 — 0
:
- 0 — 200
- 1 — 200
- 2 — 200
- 3 — 3200
3
— 1600 .
3. 01800 (200 + 1600).
— (1800 — 3*500 = 300).
.
— 300 .
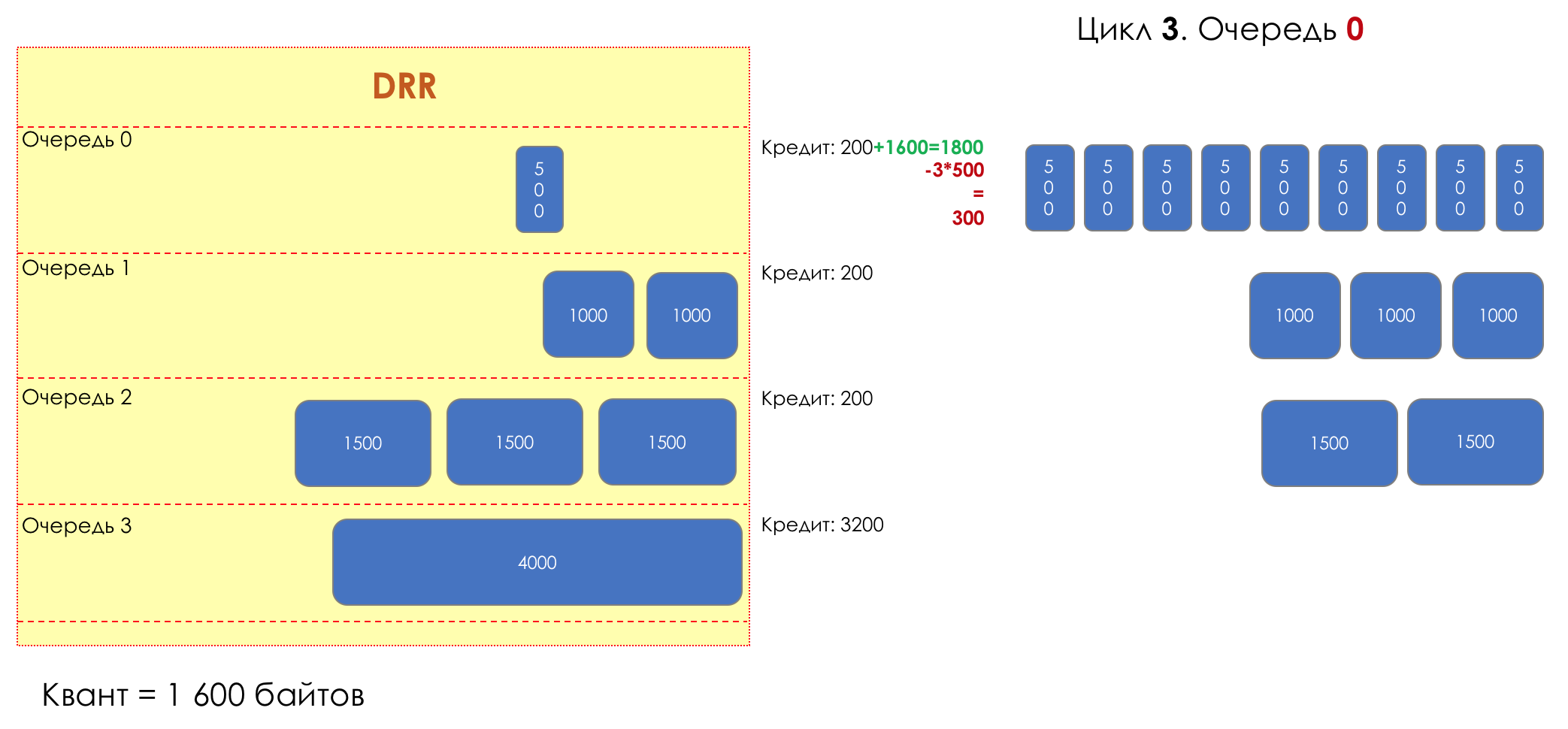 3. 1
3. 11800 (200 + 1600).
— (1800 — 1000 = 800).
— 800 .
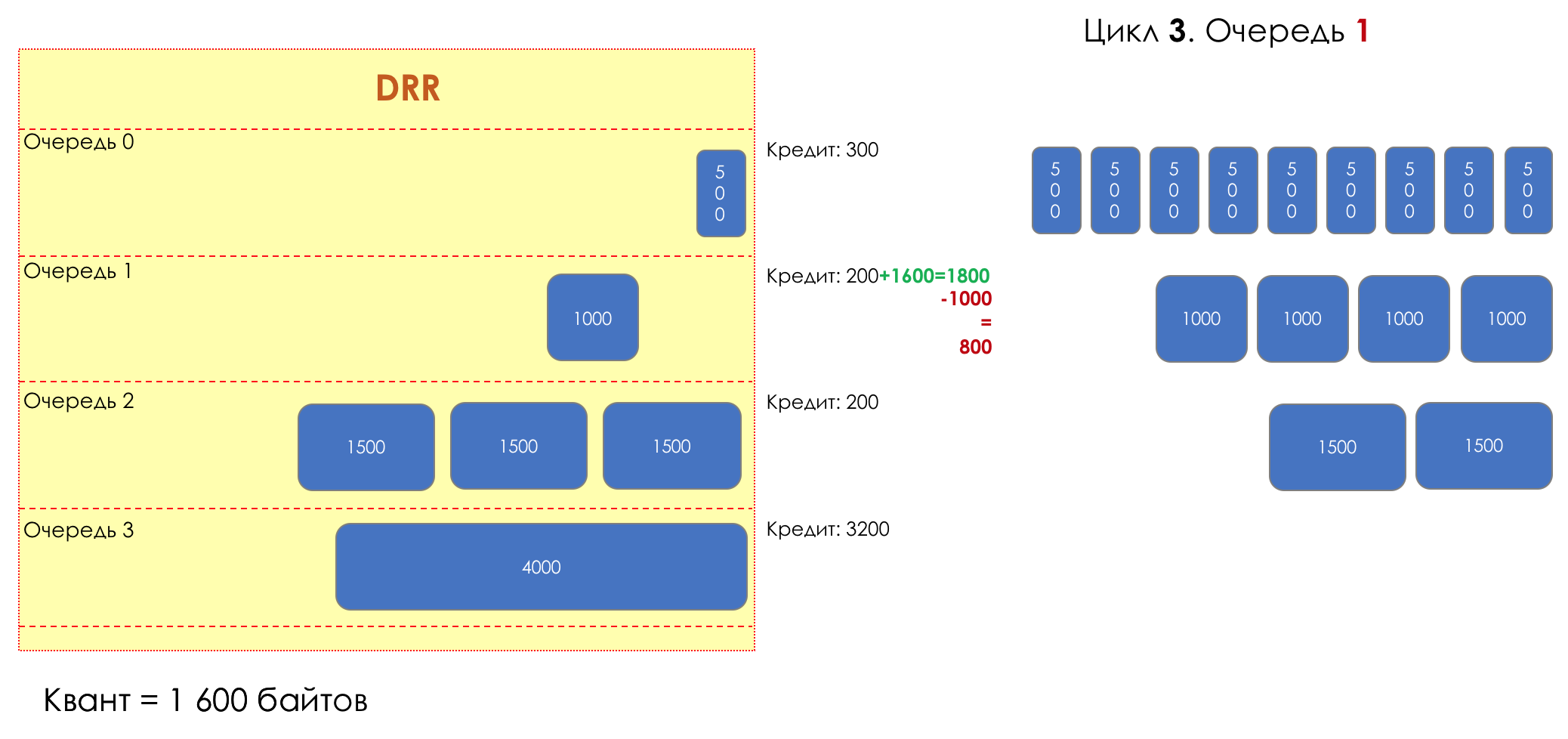 3. 2
3. 21800 (200 + 1600).
— (1800 — 1500 = 300).
— 300 .
 3. 3
3. 33- !
4800 (3200 + 1600).
— (4800 — 4000 = 800).
— 800 .
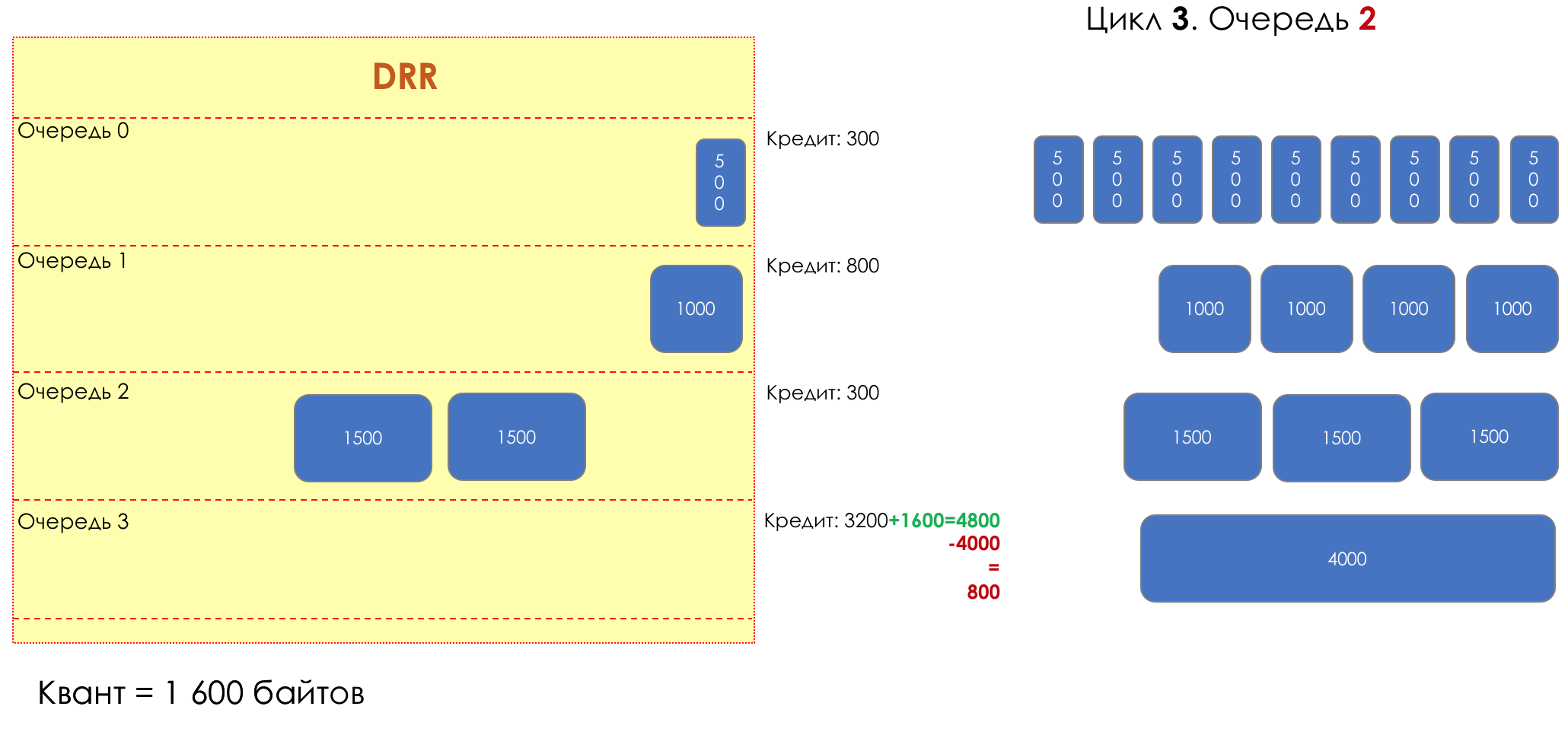
, :
- 0 — 4500
- 1 — 4000
- 2 — 4500
- 3 — 4000
:
- 0 — 300
- 1 — 800
- 2 — 300
- 3 — 800
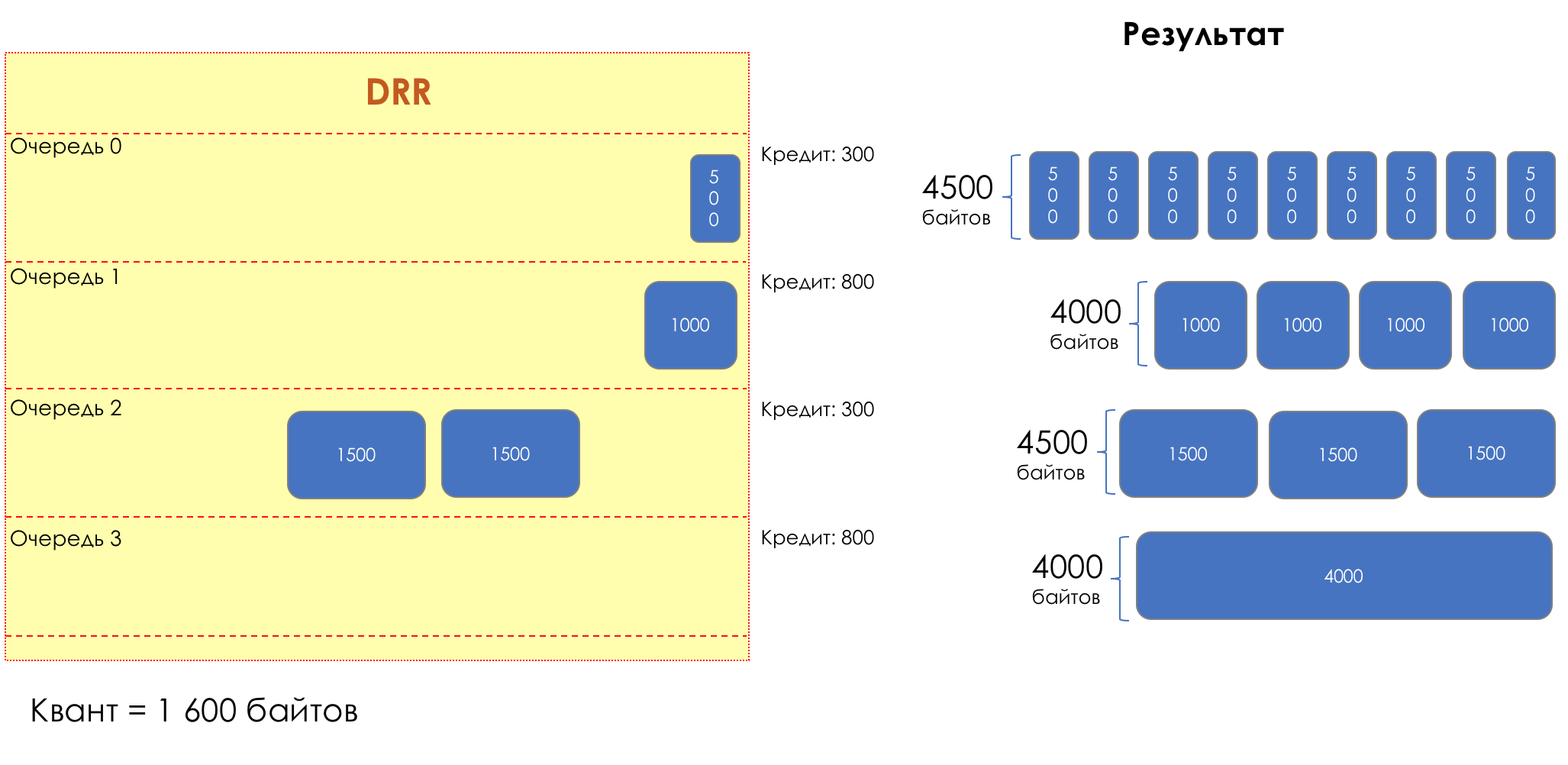
DRR. .
, .
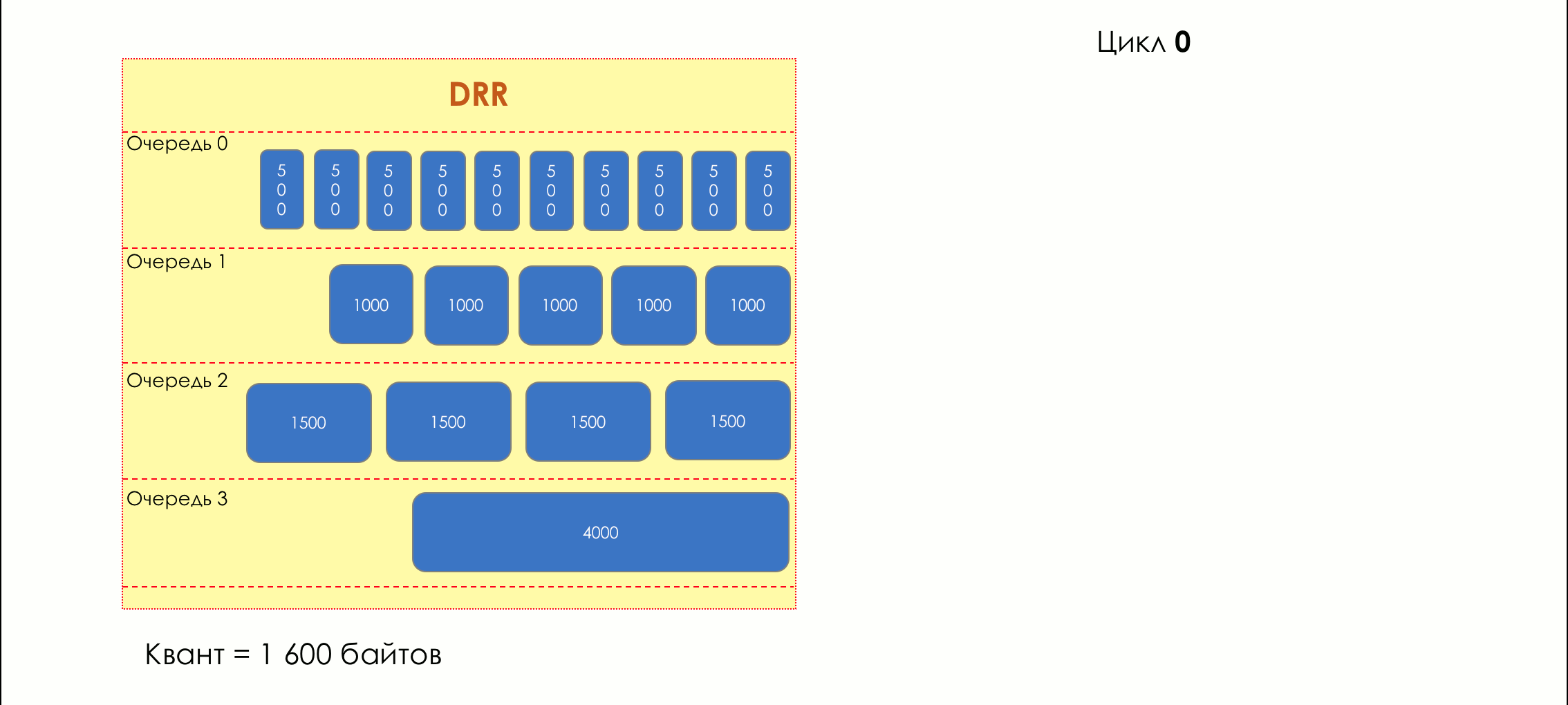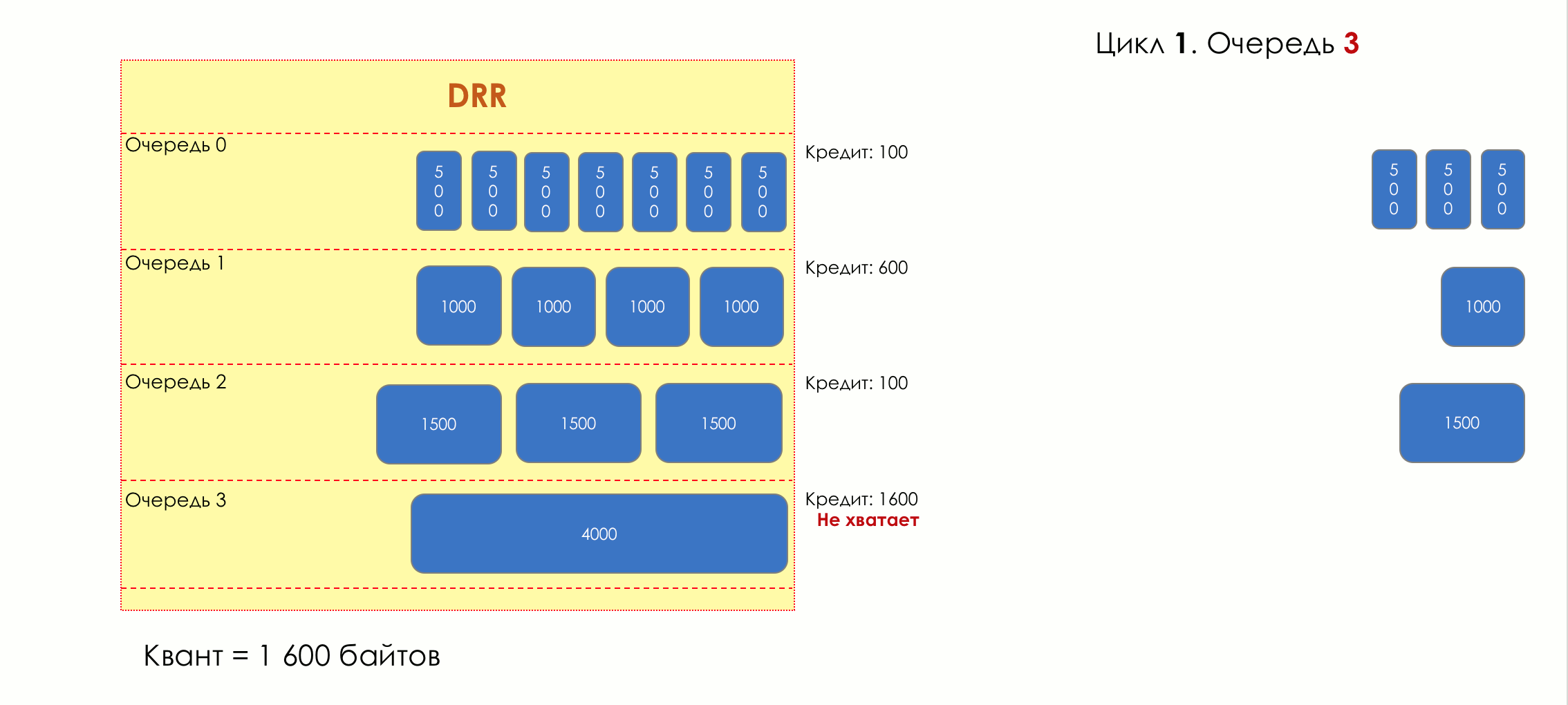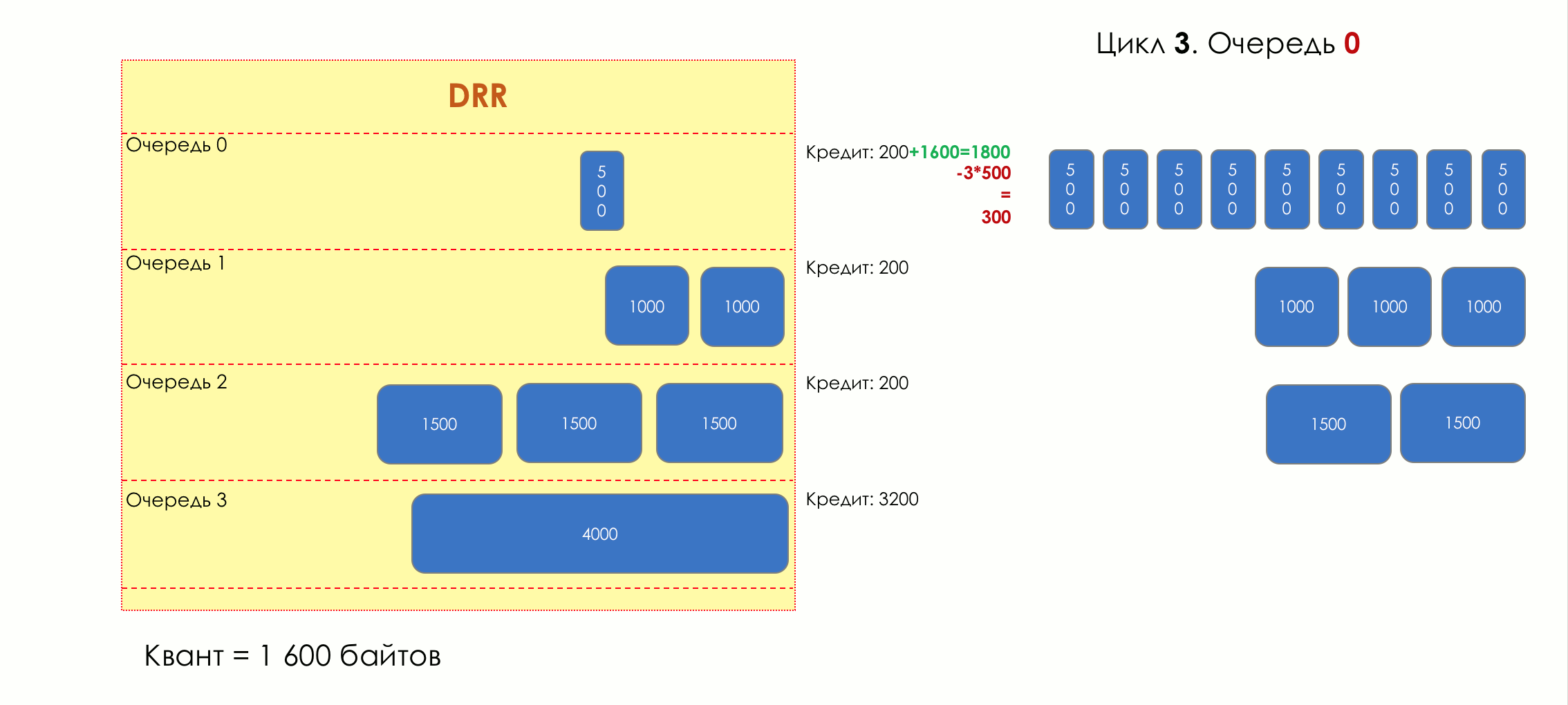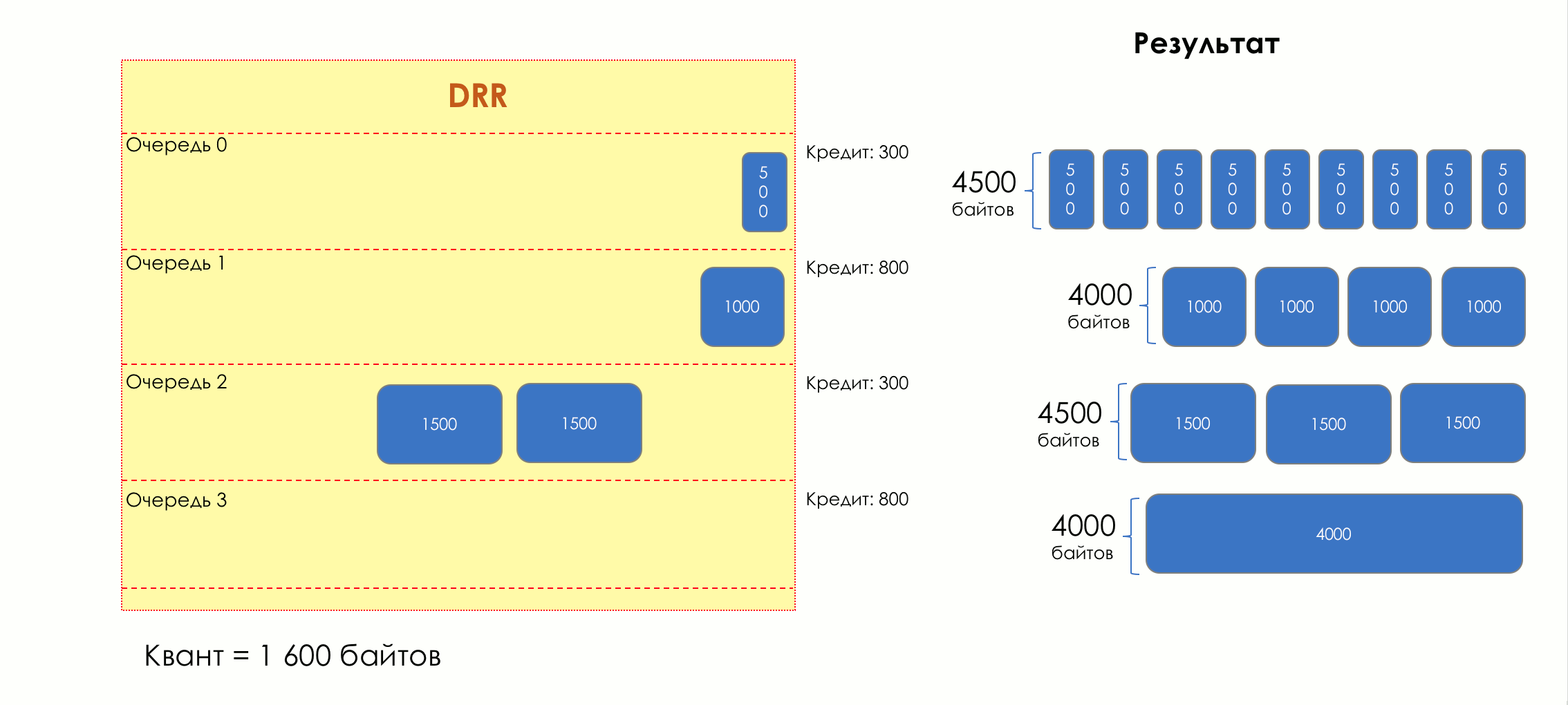
DWRR DRR , , , .
DRR, — , .
: , . .
Avec DWRR, la question demeure avec la garantie des retards et de la gigue - le poids ne le résout en aucune façon.Théoriquement, vous pouvez faire la même chose qu'avec CB-WFQ, en ajoutant LLQ.Cependant, ce n'est qu'un des scénarios possibles de la popularité croissante d'aujourd'hui.PB-DWRR - DWRR à priorité
En fait, le courant dominant aujourd'hui devient PB-DWRR - Round Based Weighted Deficit Weighted Round Robin.C'est le même vieux DWRR maléfique, dans lequel une autre file d'attente est ajoutée - priorité, dans laquelle les paquets sont traités avec une priorité plus élevée. Cela ne signifie pas qu'elle se voit attribuer une bande plus grande, mais que les colis en seront retirés plus souvent.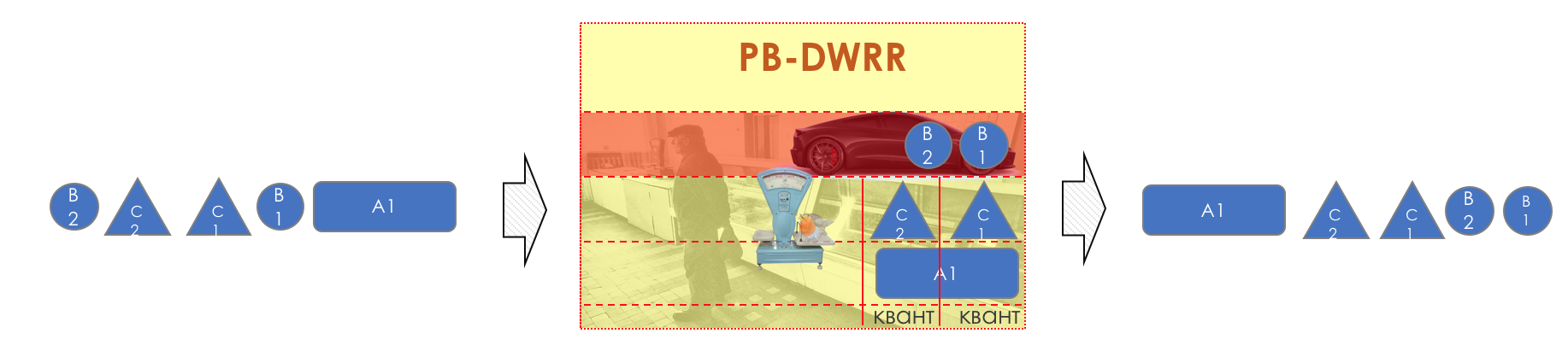 Il existe plusieurs approches pour mettre en œuvre le PB-DWRR. Dans certains d'entre eux, comme dans PQ, tout paquet arrivant dans la file d'attente prioritaire est immédiatement supprimé. Dans d'autres, il est accessible à chaque fois que le répartiteur se déplace entre les files d'attente. Troisièmement, un crédit et un quantum sont introduits pour cela, de sorte que la file d'attente prioritaire ne peut pas comprimer la bande entière.Bien sûr, nous ne les analyserons pas.
Il existe plusieurs approches pour mettre en œuvre le PB-DWRR. Dans certains d'entre eux, comme dans PQ, tout paquet arrivant dans la file d'attente prioritaire est immédiatement supprimé. Dans d'autres, il est accessible à chaque fois que le répartiteur se déplace entre les files d'attente. Troisièmement, un crédit et un quantum sont introduits pour cela, de sorte que la file d'attente prioritaire ne peut pas comprimer la bande entière.Bien sûr, nous ne les analyserons pas.Un bref résumé sur les mécanismes de répartition
Depuis des décennies, l'humanité essaie de résoudre le problème le plus difficile d'assurer le bon niveau de service et une distribution équitable de la bande. Les files d'attente étaient l'outil principal; la seule question était de savoir comment obtenir les paquets des files d'attente, en essayant de les pousser dans une seule interface.A partir du FIFO, il a inventé le PQ - la voix a pu coexister avec le surf, mais il n'était pas question de garantir le groupe.Plusieurs monstrueux FQ, WFQ sont apparus, qui ont fonctionné sinon par flux, puis presque comme ça. CB-WFQ est venu dans la société de classe, mais cela n'a pas été plus facile.Comme alternative, il a développé RR. Il est devenu un WRR, puis un DWRR.Et dans les profondeurs de chacun des répartiteurs habite FIFO.Cependant, comme vous pouvez le voir, il n'y a pas de répartiteur universel qui gère toutes les classes selon leurs besoins. C'est toujours une combinaison de répartiteurs, dont l'un résout le problème de garantir les retards, la gigue et l'absence de pertes, et l'autre alloue une bande.CBWFQ + LLQ ou PB-WDRR ou WDRR + PQ.Sur un équipement réel, vous pouvez spécifier les files d'attente à traiter avec quel répartiteur.CBWFQ, WDRR et leurs dérivés sont les favoris d'aujourd'hui.PQ, FQ, WFQ, RR, WRR - nous ne pleurons pas et ne nous souvenons pas (à moins, bien sûr, que nous nous préparions pour CCIE Clipper).
Ainsi, les répartiteurs sont en mesure de garantir la vitesse, mais comment la limiter par le haut?8. Limite de vitesse
La nécessité de limiter la vitesse du trafic à première vue est évidente - ne laissez pas le client sortir de sa bande conformément à l'accord.Oui Mais pas seulement ça.
Supposons qu'il existe une plage RRL d'une largeur de 620 Mb / s connectée via un port 1 Gb / s. Si vous y tirez tout le gigabit, puis quelque part sur le RRL, qui, très probablement, n'a aucune idée des files d'attente et de la qualité de service, des baisses monstrueuses de nature aléatoire commenceront, sans lien avec les véritables priorités du trafic.Cependant, si vous activez la mise en forme jusqu'à 600 Mb / s sur le routeur, EF, CS6, CS7 ne seront pas supprimés du tout, et dans BE, AFx, la bande et les gouttes seront distribuées en fonction de leurs poids. Le RRL atteindra 600 Mb / s et nous obtiendrons une image prévisible.Un autre exemple est le contrôle d'admission. Par exemple, deux opérateurs ont accepté de se faire mutuellement confiance, à l'exception de CS7 - si quelque chose arrivait dans CS7 - à jeter. Pour CS6 et EF - donnez une file d'attente séparée avec une garantie de retard et aucune perte.Mais, que se passe-t-il si le partenaire rusé a commencé à verser des torrents dans ces lignes? Au revoir la téléphonie. Et les protocoles s'effondreront très probablement.Il est logique dans ce cas de s'entendre avec un partenaire sur la bande. Tout ce qui rentre dans le contrat est ignoré. Ce qui ne convient pas - jeter ou transférer dans une autre file d'attente - BE, par exemple. Ainsi, nous protégeons notre réseau et nos services.Il existe deux approches fondamentalement différentes pour limiter la vitesse: le polissage et la mise en forme. Ils résolvent un problème, mais de différentes manières.Considérez la différence en utilisant un exemple d'un tel profil de trafic:
Police de la circulation
Le maintien de l'ordre limite la vitesse en supprimant le trafic excessif.Tout ce qui dépasse la valeur réglée, le polyser coupe et jette. Ce qui est coupé est oublié. L'image montre que le paquet rouge n'est pas dans le trafic après le polyser.Et voici à quoi ressemblera le profil sélectionné après le polyser: en
Ce qui est coupé est oublié. L'image montre que le paquet rouge n'est pas dans le trafic après le polyser.Et voici à quoi ressemblera le profil sélectionné après le polyser: en raison de la gravité des mesures prises, cela s'appelle Hard Policing .Cependant, il existe d'autres actions possibles.Le policier travaille généralement avec un compteur de trafic. Le mètre colore les sacs, vous vous en souvenez, en vert, jaune ou rouge.Et sur la base de cette couleur déjà, le polyser peut ne pas jeter le paquet, mais le placer dans une autre classe. Ce sont des mesures douces - police douce .Il peut être appliqué à la fois au trafic entrant et au trafic sortant.Une caractéristique distinctive du polyser est la capacité d'absorber les rafales de trafic et de déterminer la vitesse maximale autorisée grâce au mécanisme Token Bucket.Autrement dit, tout ce qui n'est pas au-dessus de la valeur définie n'est pas coupé - il est permis d'aller un peu au-delà - les courtes rafales ou les petits excès de la bande allouée sont ignorés.Le nom «Police» est dicté par le rapport assez strict de l'outil au trafic excessif - rejet ou rétrogradation vers une classe inférieure.
raison de la gravité des mesures prises, cela s'appelle Hard Policing .Cependant, il existe d'autres actions possibles.Le policier travaille généralement avec un compteur de trafic. Le mètre colore les sacs, vous vous en souvenez, en vert, jaune ou rouge.Et sur la base de cette couleur déjà, le polyser peut ne pas jeter le paquet, mais le placer dans une autre classe. Ce sont des mesures douces - police douce .Il peut être appliqué à la fois au trafic entrant et au trafic sortant.Une caractéristique distinctive du polyser est la capacité d'absorber les rafales de trafic et de déterminer la vitesse maximale autorisée grâce au mécanisme Token Bucket.Autrement dit, tout ce qui n'est pas au-dessus de la valeur définie n'est pas coupé - il est permis d'aller un peu au-delà - les courtes rafales ou les petits excès de la bande allouée sont ignorés.Le nom «Police» est dicté par le rapport assez strict de l'outil au trafic excessif - rejet ou rétrogradation vers une classe inférieure.Mise en forme du trafic
La mise en forme limite la vitesse en tamponnant le trafic excédentaire.Tout le trafic entrant passe par le tampon. Un shaper supprime les paquets de ce tampon à une vitesse constante.Si le taux d'arrivée des paquets vers le tampon est inférieur à la sortie, ils ne sont pas retardés dans le tampon - ils volent de part en part.Et si le taux d'arrivée est supérieur à la sortie, ils commencent à s'accumuler.La vitesse de sortie est toujours la même.Ainsi, des rafales de trafic sont ajoutées au tampon et seront envoyées lorsqu'elles atteindront la file d'attente.Par conséquent, avec la planification dans les files d'attente, la mise en forme est le deuxième outil qui contribue au retard total .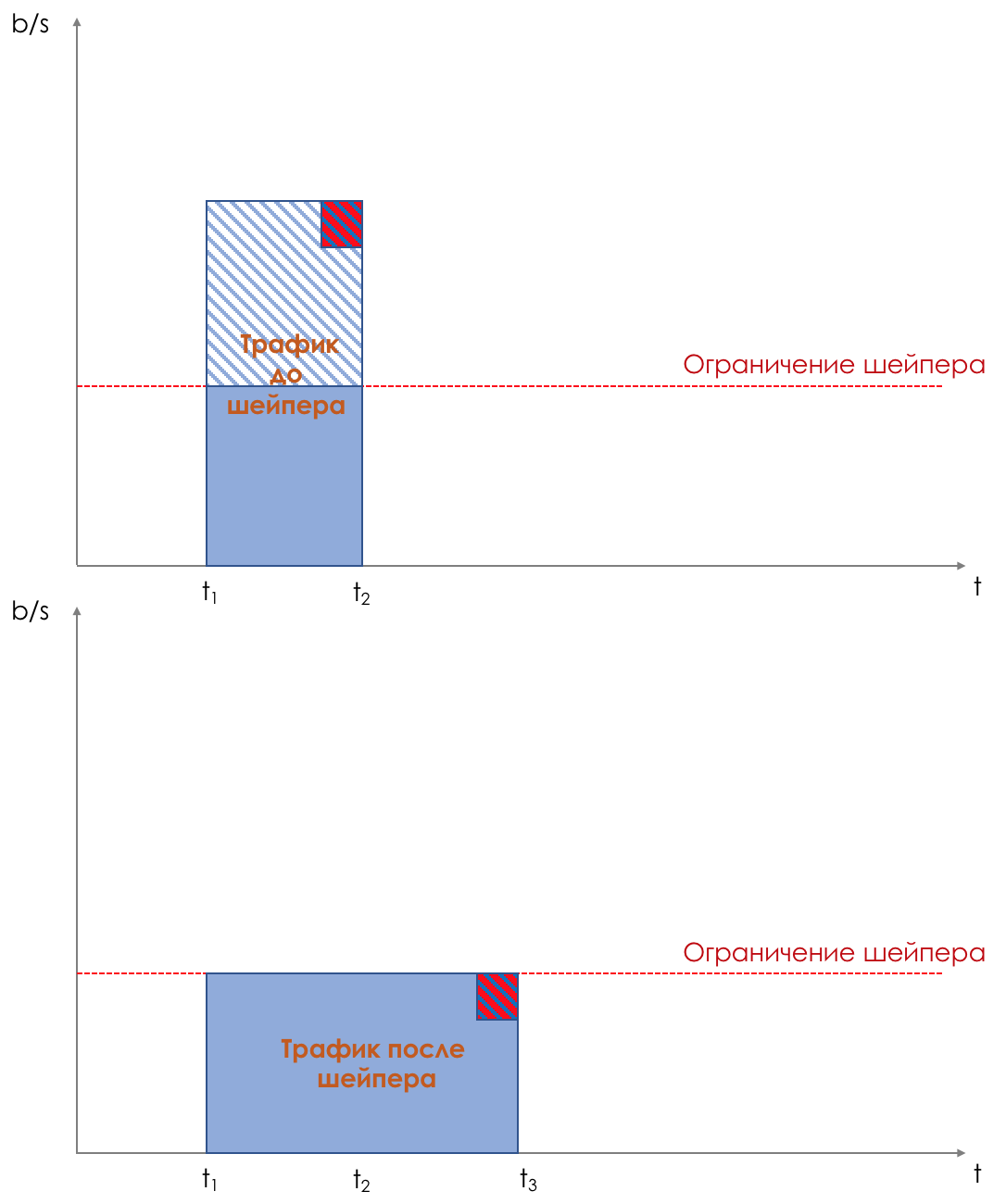 L'illustration montre clairement comment le paquet arrivant au moment t2 du tampon arrive au moment t3 en sortie. t3-t2 est le retard introduit par le shaper.Shaper est généralement appliqué au trafic sortant.Voici à quoi ressemble le profil du shaper.
L'illustration montre clairement comment le paquet arrivant au moment t2 du tampon arrive au moment t3 en sortie. t3-t2 est le retard introduit par le shaper.Shaper est généralement appliqué au trafic sortant.Voici à quoi ressemble le profil du shaper.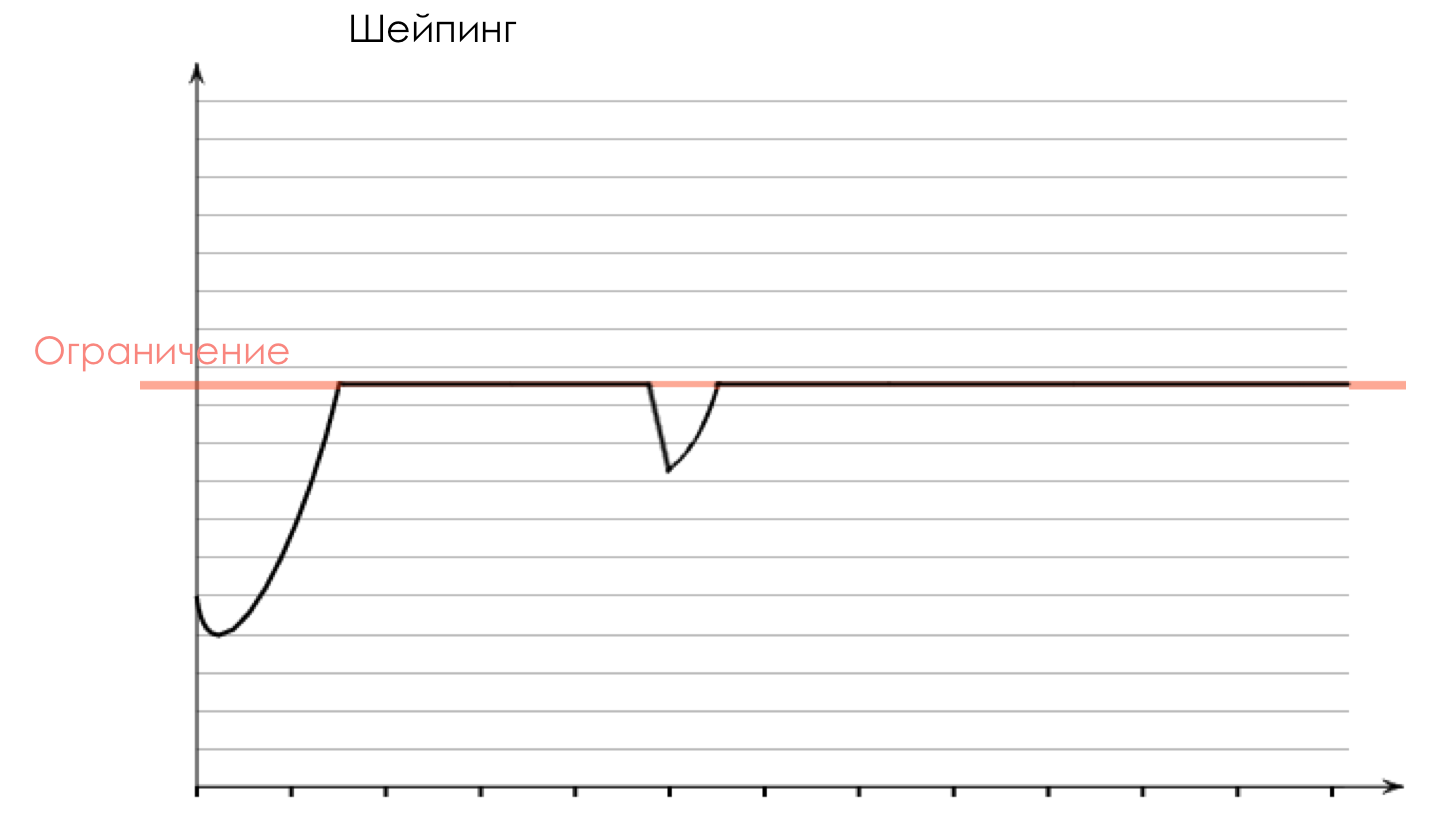 Le nom «Shaping» indique que l'outil donne une forme au profil de trafic, le lissant.Le principal avantage de cette approche est l'utilisation optimale de la bande existante - au lieu de laisser tomber un trafic excessif, nous la reportons.L'inconvénient principal est un délai imprévisible - lorsque le tampon est plein, les paquets y languissent pendant longtemps. Par conséquent, la mise en forme ne convient pas à tous les types de trafic.La mise en forme utilise le mécanisme Leaky Bucket.
Le nom «Shaping» indique que l'outil donne une forme au profil de trafic, le lissant.Le principal avantage de cette approche est l'utilisation optimale de la bande existante - au lieu de laisser tomber un trafic excessif, nous la reportons.L'inconvénient principal est un délai imprévisible - lorsque le tampon est plein, les paquets y languissent pendant longtemps. Par conséquent, la mise en forme ne convient pas à tous les types de trafic.La mise en forme utilise le mécanisme Leaky Bucket.Façonner contre polir
Le travail du polyser est similaire à un couteau qui, se déplaçant le long de la surface de l'huile, coupe le côté tranchant du tubercule.Le travail d'un shaper est similaire à un rouleau, qui lisse les tubercules, les répartissant uniformément sur la surface.Shaper essaie de ne pas laisser tomber les paquets pendant qu'ils sont mis en mémoire tampon au prix d'un retard accru.Le polisseur n'introduit pas de retards, mais jette plus facilement les paquets.Les applications insensibles aux retards, mais pour lesquelles la perte n'est pas souhaitable, doivent être limitées à un shaper.Pour ceux pour qui un paquet tardif est identique à un paquet perdu, il est préférable de le déposer immédiatement - puis de le polir.Un shaper n'affecte pas les en-têtes de paquets et leur sort en dehors du nœud, tandis qu'après le polissage, le périphérique peut reclasser la classe dans l'en-tête. Par exemple, à l'entrée, le paquet avait la classe AF11, la mesure l'a peint en jaune à l'intérieur de l'appareil, à la sortie, il a re-marqué sa classe sur AF12 - sur le nœud suivant, il aura une probabilité plus élevée de tomber.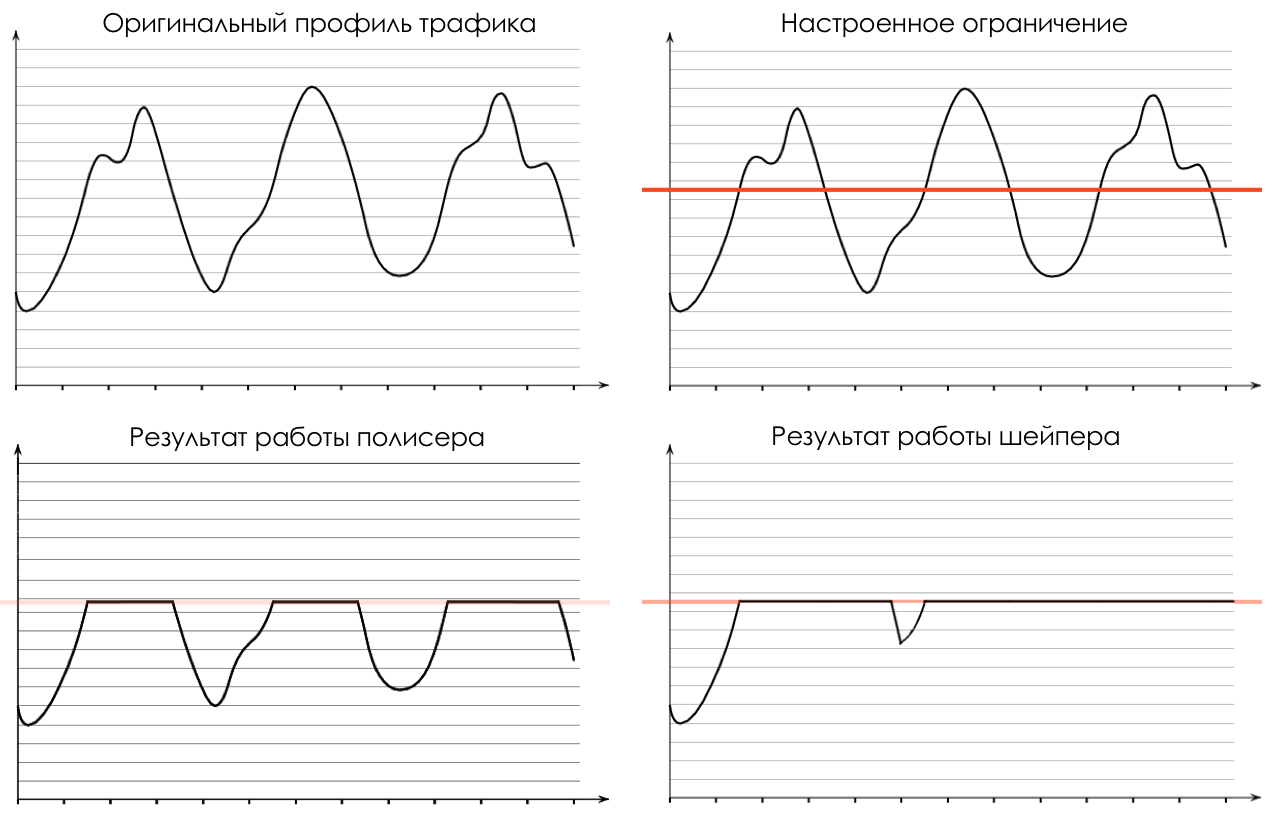
Pratiquer le polissage et le façonnage
Le schéma est le même:fichier de configuration. Nousobservons cette image sans appliquer de restrictions: Nous procéderons comme suit:
Nous procéderons comme suit:- Sur l'interface d'entrée Linkmeup_R2 (e0 / 1), nous allons configurer le polissage - ce sera le contrôle d'entrée. Selon l'accord, nous donnons 10 Mb / s.
- Sur l'interface de sortie Linkmeup_R4 (e0 / 2), configurez la mise en forme à 20 Mb / s.
Commençons par le shaper sur Linkmeup_R4 .Faites correspondre tout: class-map match-all TRISOLARANS_ALL_CM match any
Forme jusqu'à 20 Mo / s: policy-map TRISOLARANS_SHAPING class TRISOLARANS_ALL_CM shape average 20000000
Appliquer à l'interface de sortie: interface Ethernet0/2 service-policy output TRISOLARANS_SHAPING
Tout ce qui doit sortir (sortir) de l'interface Ethernet0 / 2, forme jusqu'à 20 Mb / s.Fichier de configuration du Shaper.Et voici le résultat: il se révèle une ligne assez plate de débit total et de graphiques déchirés pour chaque flux individuel.Le fait est que nous limitons le shaper au groupe général. Cependant, selon la plate-forme, les flux individuels peuvent également être configurés individuellement, gagnant ainsi des opportunités égales.
il se révèle une ligne assez plate de débit total et de graphiques déchirés pour chaque flux individuel.Le fait est que nous limitons le shaper au groupe général. Cependant, selon la plate-forme, les flux individuels peuvent également être configurés individuellement, gagnant ainsi des opportunités égales.
Configurez maintenant le polissage sur Linkmeup_R2.Nous ajouterons un polyser à la politique existante. policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_TCP_CM police cir 10000000 bc 1875000 conform-action transmit exceed-action drop
La politique a déjà été appliquée à l'interface: interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
Ici, nous indiquons la vitesse moyenne autorisée CIR (10 Mo / s) et la rafale autorisée Bc (1 875 000 octets, environ 14,6 Mo).Plus tard, expliquant comment fonctionne le polyser, je vous dirai ce que sont le CIR et le Bc et comment déterminer ces valeurs.Fichier de configuration du polyser.Cette image est observée avec polysing. Des changements soudains du niveau de vitesse sont immédiatement apparents:
Mais une image aussi intéressante est obtenue si nous rendons la taille de rafale autorisée trop petite, par exemple 10 000 octets. police cir 10000000 bc 10000 conform-action transmit exceed-action drop
 La vitesse globale a immédiatement chuté à environ 2 Mo / s.Attention au réglage des rafales :)Table de test.
La vitesse globale a immédiatement chuté à environ 2 Mo / s.Attention au réglage des rafales :)Table de test.
Seau qui fuit et seau à jetons
Cela semble simple et clair. Mais comment cela fonctionne-t-il dans la pratique et est-il implémenté dans le matériel?Un exemple.La limite de 400 Mb / s est-elle beaucoup (ou un peu)? En moyenne, un client n'en utilise que 320. Mais parfois, il passe à 410 pendant 5 minutes. Et parfois jusqu'à 460 par minute. Et parfois jusqu'à 500 pendant une demi-seconde.Comme le peut dire le lien du fournisseur contractuel - 400 et c'est tout! Si vous en voulez plus, connectez-vous au tarif de 1Gb / s + 27 chaînes anime.Et nous pouvons augmenter la fidélité des clients si cela n'interfère pas avec les autres en autorisant de telles surtensions.Comment autoriser 460 Mb / s pour seulement une minute, et non 30 ou pour toujours?Comment autoriser 500 Mb / s, si la bande est gratuite, et pousser à 400, si d'autres consommateurs sont apparus?Maintenant, faites une pause, versez un seau de fort.Commençons par le mécanisme plus simple utilisé par le shaper - un seau qui fuit.Algorithme de seau qui fuit
Leaky Bucket est un seau qui fuit. Nous avons un seau avec un trou d'une taille donnée en bas. Les sacs sont versés / versés dans ce seau par le haut. Et d'en bas, ils coulent à un débit constant.Lorsque le seau est plein, de nouveaux paquets commencent à être jetés.La taille du trou est déterminée par la limite de vitesse spécifiée, qui pour Leaky Bucket est mesurée en bits par seconde.Le volume du godet, sa plénitude et sa vitesse de sortie déterminent le retard introduit par le shaper.Pour plus de commodité, le volume du godet est généralement mesuré en ms ou μs.En termes d'implémentation, Leaky Bucket est un tampon régulier basé sur SD-RAM.Même si la mise en forme n'est pas explicitement configurée, en présence de rafales qui ne passent pas dans l'interface, les paquets sont temporairement mis en mémoire tampon et transmis lorsque l'interface est libérée. Cela façonne également.Le seau qui fuit est utilisé uniquement pour le façonnage et ne convient pas au polissage.
Nous avons un seau avec un trou d'une taille donnée en bas. Les sacs sont versés / versés dans ce seau par le haut. Et d'en bas, ils coulent à un débit constant.Lorsque le seau est plein, de nouveaux paquets commencent à être jetés.La taille du trou est déterminée par la limite de vitesse spécifiée, qui pour Leaky Bucket est mesurée en bits par seconde.Le volume du godet, sa plénitude et sa vitesse de sortie déterminent le retard introduit par le shaper.Pour plus de commodité, le volume du godet est généralement mesuré en ms ou μs.En termes d'implémentation, Leaky Bucket est un tampon régulier basé sur SD-RAM.Même si la mise en forme n'est pas explicitement configurée, en présence de rafales qui ne passent pas dans l'interface, les paquets sont temporairement mis en mémoire tampon et transmis lorsque l'interface est libérée. Cela façonne également.Le seau qui fuit est utilisé uniquement pour le façonnage et ne convient pas au polissage.Algorithme de seau à jetons
Beaucoup de gens pensent que le seau à jetons et le seau qui fuit sont la même chose. Seul Einstein se trompait beaucoup plus, ajoutant une constante cosmologique.Les puces de commutation ne comprennent pas vraiment l'heure, elles aggravent encore le nombre de bits qu'elles ont transmis par unité de temps. Leur travail consiste à battre.Est-ce que le bit approchant est 400 000 000 bits par seconde, ou déjà 400 000 001? Les développeurs d'ASIC avaient un défi d'ingénierie non trivial.Il était divisé en deux sous-tâches:
Les développeurs d'ASIC avaient un défi d'ingénierie non trivial.Il était divisé en deux sous-tâches:- Limitant réellement la vitesse en jetant les paquets inutiles sur la base d'une condition très simple. Effectué sur les puces de commutation.
- Créer cette condition simple, qui traite d'une puce plus complexe (plus spécialisée), en gardant une trace du temps.
L'algorithme qui résout le deuxième problème est appelé le seau à jetons. Son idée est élégante et simple (non).La tâche de Token Bucket est de faire passer le trafic s'il relève de la restriction et de le rejeter / peindre en rouge sinon.Il est important d'autoriser les rafales de trafic, car cela est normal.Et si dans Leaky Bucket les rafales étaient tamponnées, le Token Bucket ne met rien en mémoire tampon.Tarif unique - Marquage bicolore
Pour l'instant, ne faites pas attention au nom =)Nous avons un seau dans lequel les pièces tombent à vitesse constante - 400 mégamonets par seconde, par exemple.Le volume du seau est de 600 millions de pièces. Autrement dit, il est rempli en une seconde et demie.A proximité se trouvent deux tapis roulants: l'un livre les colis, le second enlève.Pour arriver au convoyeur, le colis doit payer.Pour cela, il prend des pièces dans un seau en fonction de sa taille. En gros - combien de bits - tant de pièces.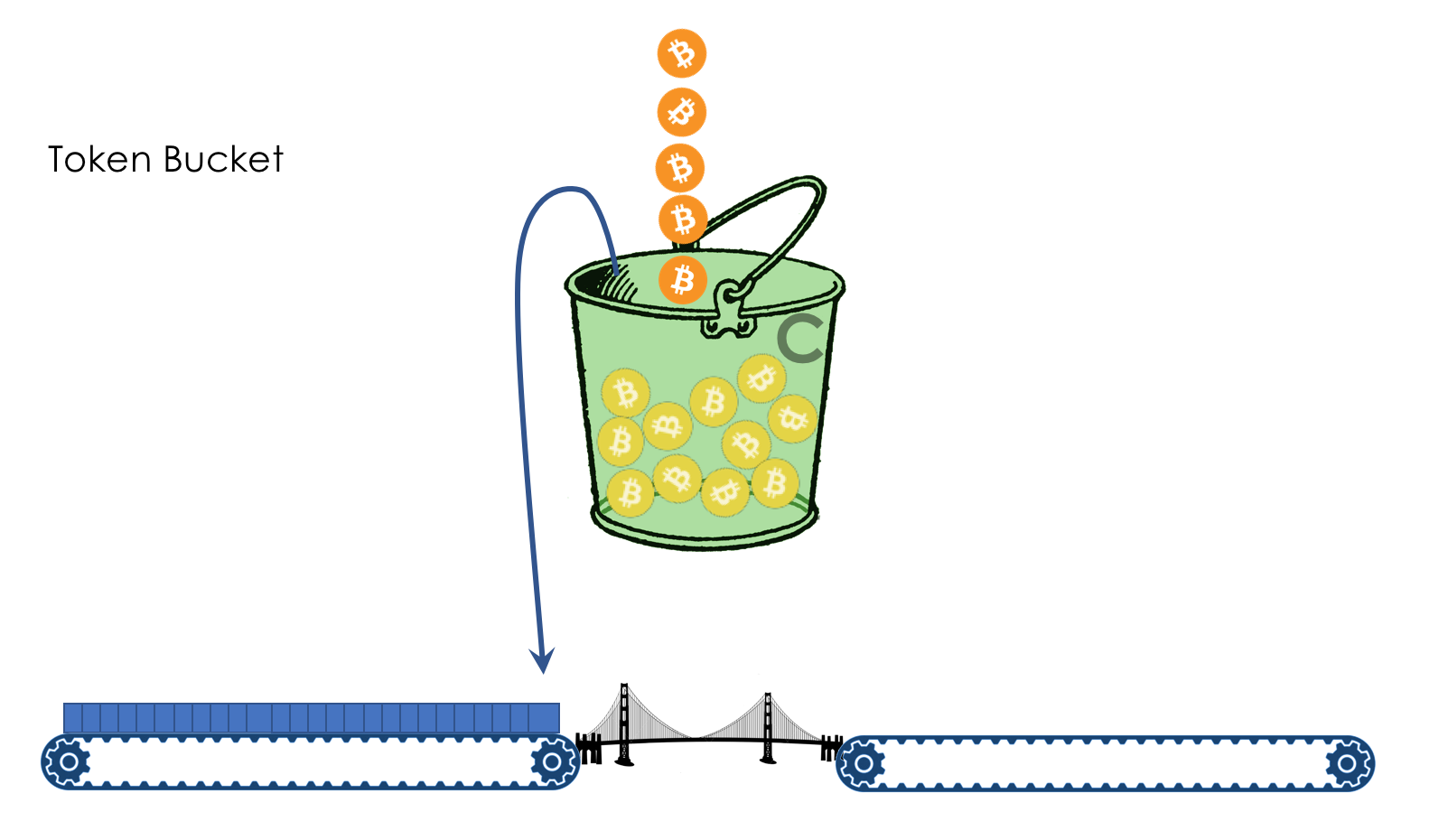
 Si le seau est vide et qu'il n'y a pas assez de pièces dans le sac, il est peint en rouge et jeté. Hélas, Selyava. Dans ce cas, les pièces ne sont pas retirées du seau.
Si le seau est vide et qu'il n'y a pas assez de pièces dans le sac, il est peint en rouge et jeté. Hélas, Selyava. Dans ce cas, les pièces ne sont pas retirées du seau.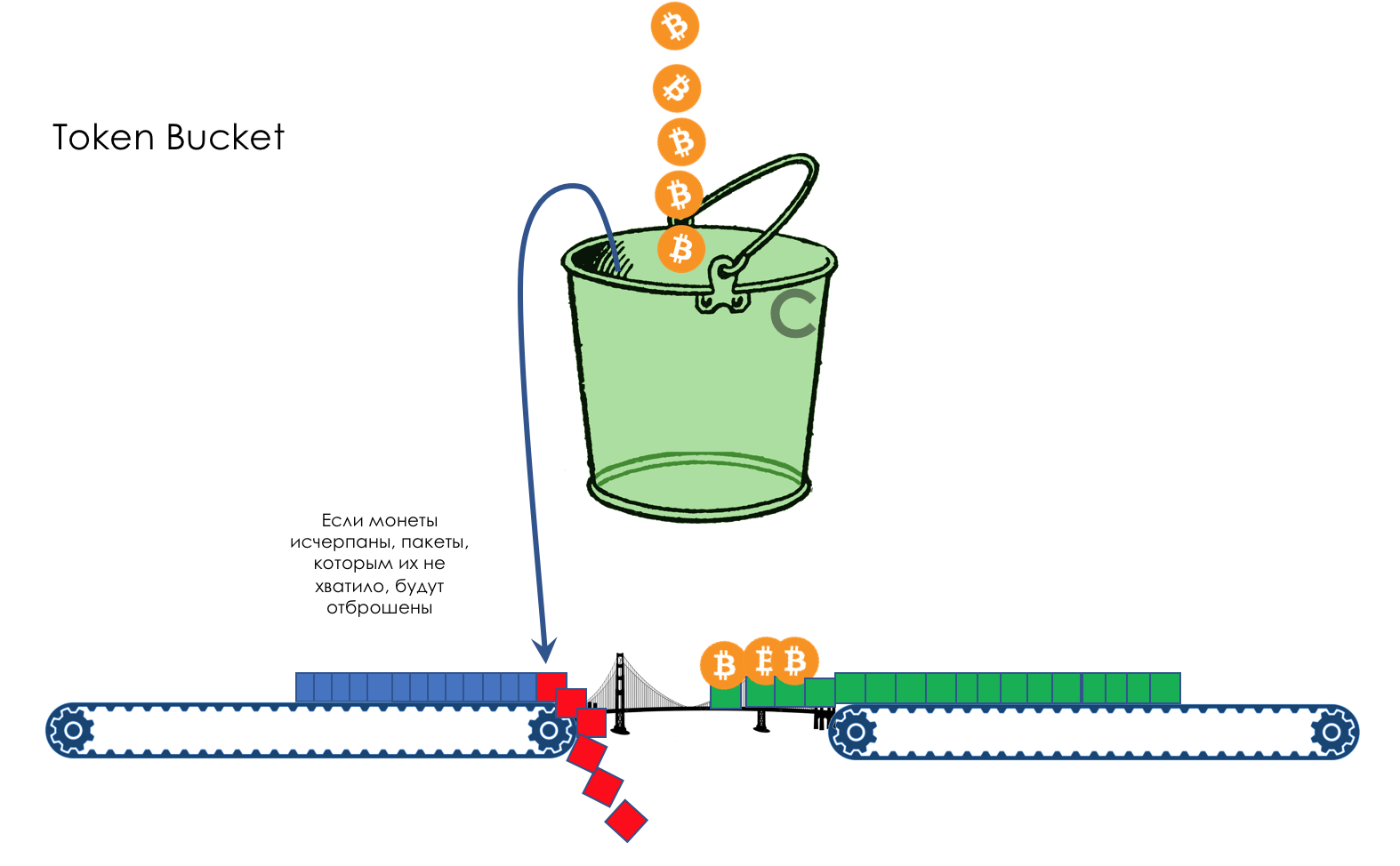 Le prochain paquet de pièces peut déjà être suffisant - premièrement, le paquet peut être plus petit et, deuxièmement, il attaque plus de pièces pendant ce temps.Si le seau est déjà plein, toutes les nouvelles pièces seront jetées.
Le prochain paquet de pièces peut déjà être suffisant - premièrement, le paquet peut être plus petit et, deuxièmement, il attaque plus de pièces pendant ce temps.Si le seau est déjà plein, toutes les nouvelles pièces seront jetées.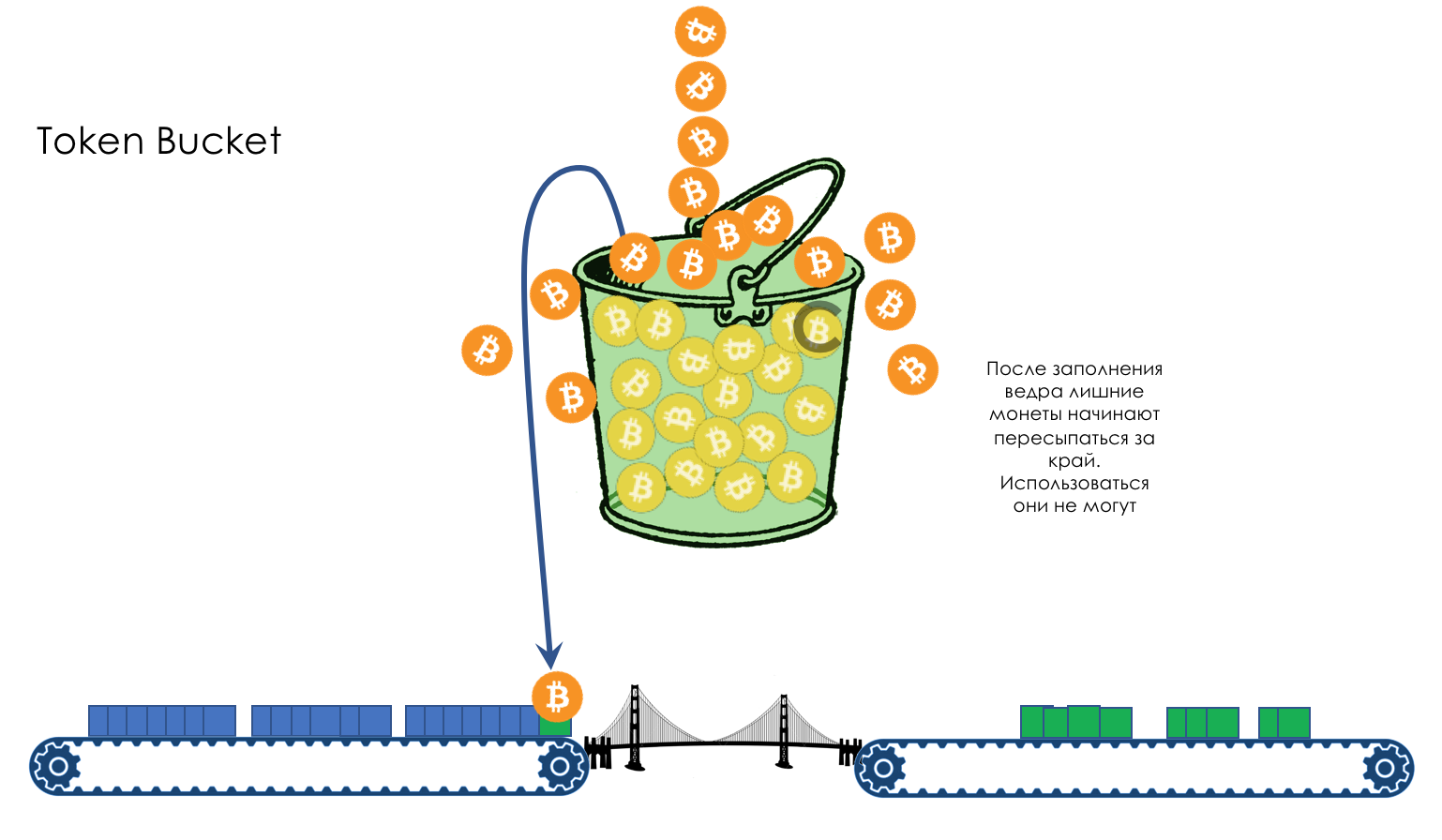 Tout dépend du taux d'arrivée des paquets et de leur taille.S'il est stable ou inférieur à 400 Mo par seconde, il y aura toujours suffisamment de pièces.S'il est supérieur, certains des paquets seront perdus.
Tout dépend du taux d'arrivée des paquets et de leur taille.S'il est stable ou inférieur à 400 Mo par seconde, il y aura toujours suffisamment de pièces.S'il est supérieur, certains des paquets seront perdus.Un exemple plus précis avec des gifs, comme nous aimons tous.
- Il y a un seau d'une capacité de 2500 octets. Au départ, il contient 550 jetons.
Il y a trois paquets de 1000 octets sur le pipeline qui veulent être envoyés à l'interface.
À chaque intervalle de temps, 500 octets tombent dans le compartiment (500 * 8 = 4000 bits / intervalle de temps - limite de polyser). - 500 . . 1000 , 1050 — . . 1000 .
50 . - 500 — 550. — 1000 — .
, . - 500 — 1050. — 1000 — .
, .
2500 , 2500 — . MTU , , , 1,5-2 .
:
CBS = CIR ( )*1,5 ()/8 ( )
, (Bc), , (1 875 000 ) . (10 000 ), , MTU, .
Pourquoi un volume de godet? Le train de bits n'est pas toujours uniforme, c'est évident. Une limite de 400 Mb / s n'est pas une asymptote - le trafic peut la traverser. Le volume des pièces stockées permet aux petites rafales de survoler sans être jetées, mais conserve la vitesse moyenne à 400 Mo / s.Par exemple, un flux stable de 399 Mb / s en 600 secondes permettra au godet de se remplir à ras bord.De plus, le trafic peut atteindre 1000Mb / s et rester à ce niveau pendant 1 seconde - 600 Mm (Megamonet) de stock et 400 Mm / s de bande garantie.Ou, le trafic peut aller jusqu'à 410 Mb / s et le rester pendant 60 secondes.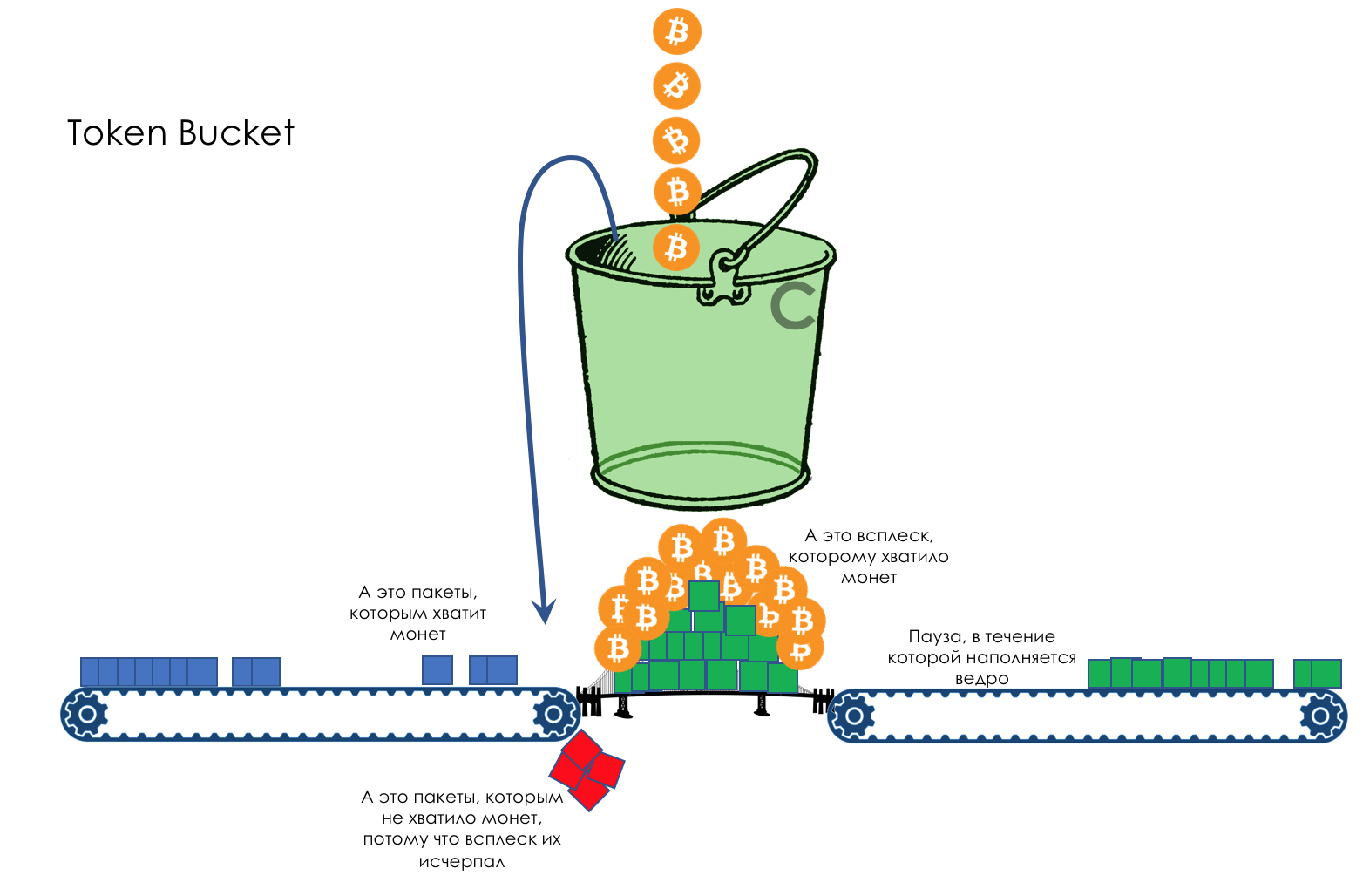 Autrement dit, la fourniture de pièces vous permet d'aller légèrement au-delà de la restriction pendant une longue période ou de lancer une surtension courte mais élevée.Passons maintenant à la terminologie.Le taux de réception des pièces dans le seau - CIR - Taux d'Information Engagé (Vitesse moyenne garantie). Mesuré en bits par seconde.Le nombre de pièces pouvant être stockées dans le seau - CBS - Committed Burst Size . Taille de rafale maximale autorisée. Mesuré en octets. Parfois, comme vous l'avez peut-être remarqué, cela s'appelle Bc .Tc - Le nombre de pièces (Token) dans le compartiment C (CBS) pour le moment.
Autrement dit, la fourniture de pièces vous permet d'aller légèrement au-delà de la restriction pendant une longue période ou de lancer une surtension courte mais élevée.Passons maintenant à la terminologie.Le taux de réception des pièces dans le seau - CIR - Taux d'Information Engagé (Vitesse moyenne garantie). Mesuré en bits par seconde.Le nombre de pièces pouvant être stockées dans le seau - CBS - Committed Burst Size . Taille de rafale maximale autorisée. Mesuré en octets. Parfois, comme vous l'avez peut-être remarqué, cela s'appelle Bc .Tc - Le nombre de pièces (Token) dans le compartiment C (CBS) pour le moment.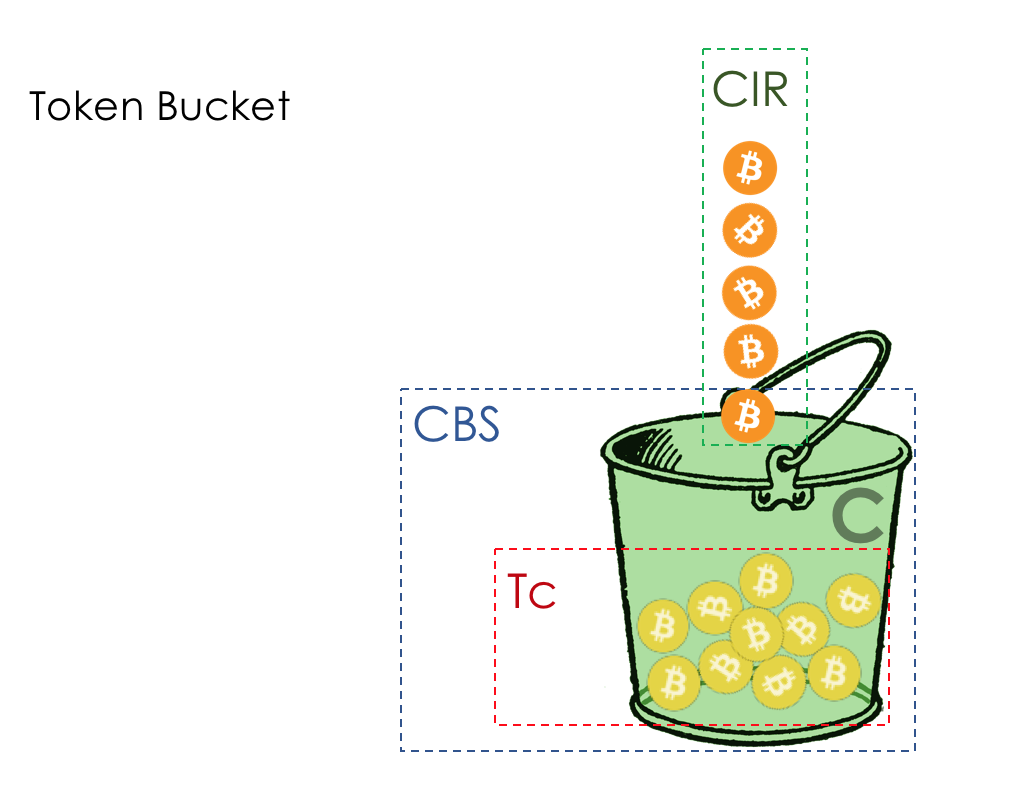
" Tc ", , RFC 2697 ( A Single Rate Three Color Marker ).
Tc, , .
.
, , Token Bucket, TDM (Time-Division Multiplexing) — .
— , , .
CIR . .
, — , — , — .
, .
( Cisco) Tc , — Bc . Bc = CIR*Tc .
Tc Bc .
C'est le scénario le plus simple. Il est appelé Single Rate - Two Color .Le taux unique signifie qu'il n'y a qu'une seule vitesse moyenne autorisée et deux couleurs - que vous pouvez colorer le trafic dans l'une des deux couleurs: vert ou rouge.- Si le nombre de pièces (bits) disponibles dans le compartiment C est supérieur au nombre de bits qui doivent être ignorés pour le moment, le paquet est coloré en vert - une faible probabilité de chute à l'avenir. Les pièces sont retirées du seau.
- Sinon, l'emballage est peint en rouge - une forte probabilité de chute (ou, plus souvent, une chute momentanée). Pièces de monnaie seaux ainsi C est retiré .
Utilisé pour le polissage dans PHB CS et EF, où une accélération n'est pas attendue, mais si cela se produit, il est préférable de le jeter immédiatement.De plus, nous considérerons plus difficile: Taux unique - Trois couleurs.Tarif unique - Marquage tricolore
L'inconvénient du schéma précédent est qu'il n'y a que deux couleurs. Et si nous ne voulons pas tout laisser tomber au-dessus de la vitesse moyenne autorisée, mais que nous voulons être encore plus fidèles?TCM-sr ( taux unique - les trois plus la couleur de marquage ) entre dans le deuxième seau - E . A cette époque, les pièces ne sont pas placés dans un seau rempli de C , sont versés dans E . EBS est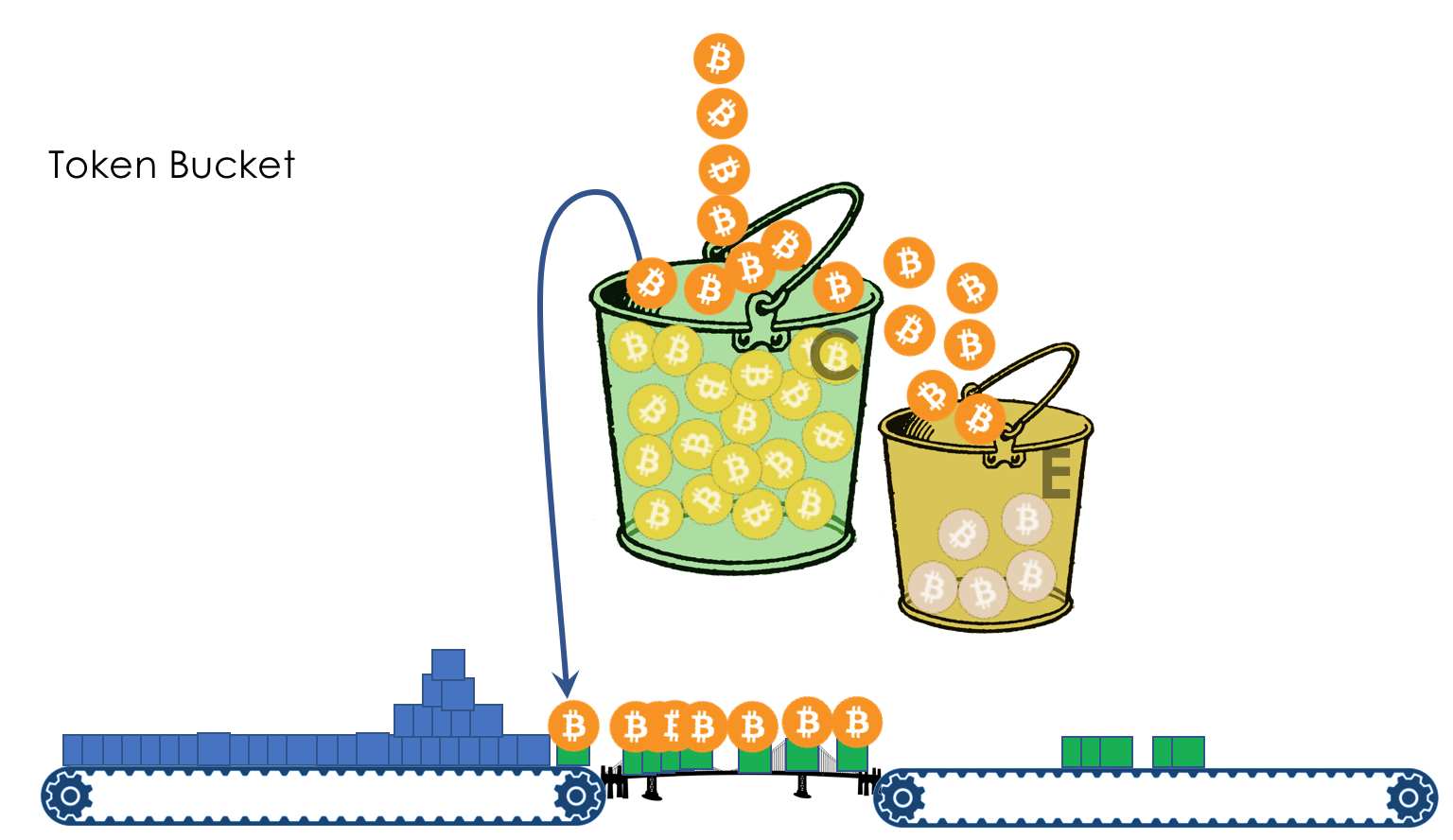 ajouté à CIR et CBS - Excess Burst Size - Taille de rafale autorisée pendant les pics. Te - le nombre de pièces dans un seau E .
ajouté à CIR et CBS - Excess Burst Size - Taille de rafale autorisée pendant les pics. Te - le nombre de pièces dans un seau E . Disons qu'un paquet de taille B est arrivé le long du pipeline.
Disons qu'un paquet de taille B est arrivé le long du pipeline. Alors
- C , . C B (: Tc — B).
- C , E . , ( ), E B .

- E , , .

Notez que pour un package spécifique, Tc et Te ne sont pas cumulatifs .Autrement dit, un paquet de 8000 octets de taille ne passera pas, même s'il y a 3000 pièces dans le seau C et dans E - 7000 pièces . En C ce n'est pas suffisant, en E ce n'est pas suffisant - nous mettons une marque rouge - shuruy d'ici.Il s'agit d'un design très élégant. Tout le trafic qui tombe dans la restriction CIR + CBS moyenne (l'auteur sait qu'il est impossible d'ajouter des bits / s et des octets si directement) - passe au vert. Aux heures de pointe, lorsque le client n'a plus de pièces dans le compartiment C , il a encore du stock de Te dans le compartiment E accumulé pendant les temps d'arrêt .Autrement dit, vous pouvez sauter un peu plus, mais en cas de congestion, ils sont plus susceptibles d'être jetés.sr-TCM est décrit dans la RFC 2697 .Utilisé pour le polissage dans PHB AF.Eh bien, le dernier système est le plus flexible et donc le plus complexe - deux taux - trois couleurs.Deux taux - trois couleurs de marquage
Le modèle Tr-TCM est né de l'idée que ce n'est pas au détriment des autres utilisateurs et types de trafic, pourquoi ne pas donner au client des opportunités un peu plus agréables, ou mieux vendre.Disons-lui qu'il est garanti 400 Mb / s, et s'il y a des ressources libres, alors 500. Êtes-vous prêt à payer 30 roubles de plus?Un autre seau P est ajouté .De cette façon:
CIR - vitesse moyenne garantie.CBS a la même taille d'éclaboussure autorisée (volume de compartiment C ).PIR - Peak Information Rate - vitesse moyenne maximale.EBS - taille de rafale autorisée pendant les pics (Bucket Volume P ).Contrairement à sr-TCM, dans tr-TCM, les pièces sont désormais livrées indépendamment aux deux compartiments. En C - avec la vitesse du CIR, en P - PIR.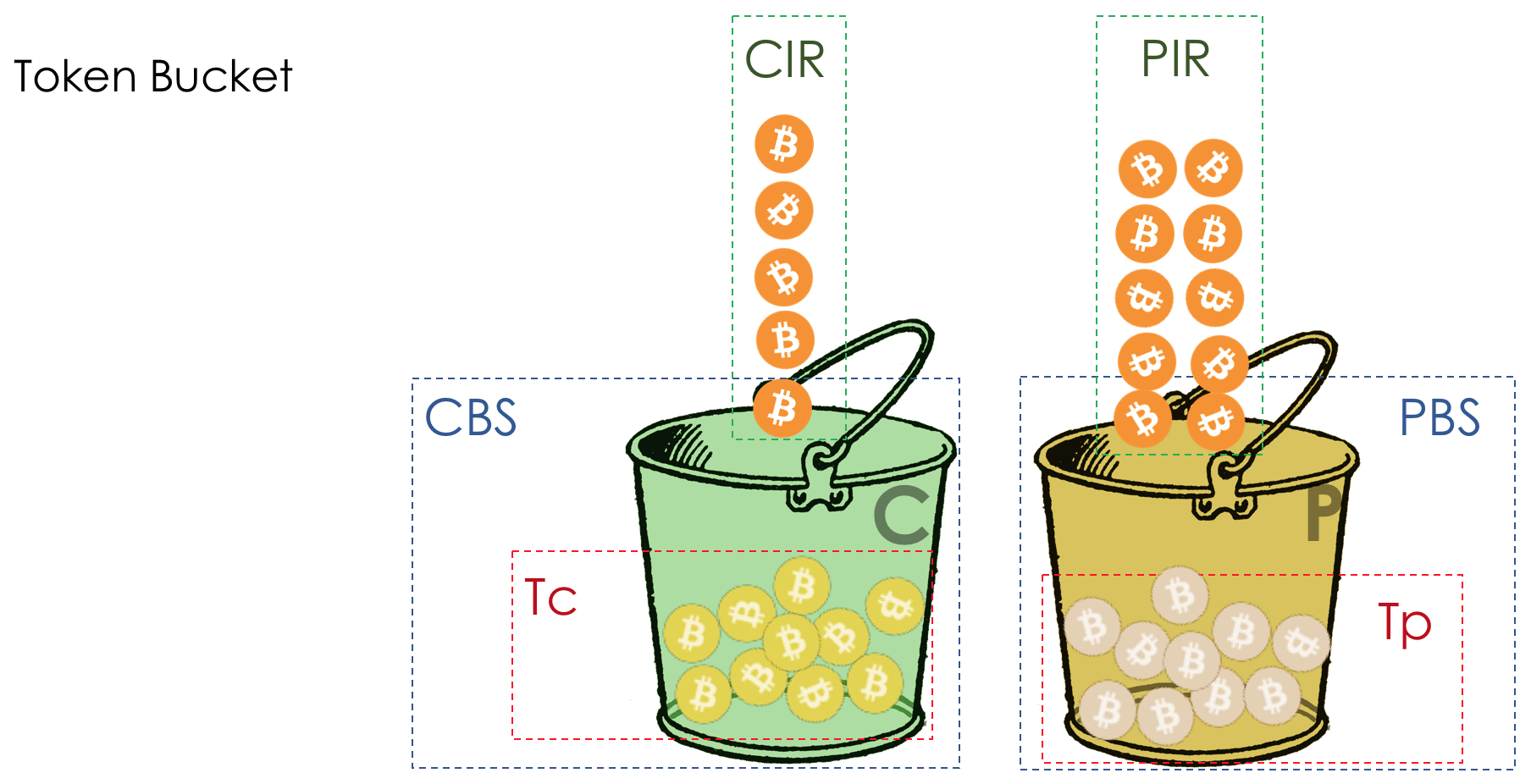 Quelles sont les règles?Un paquet de taille B octets arrive .
Quelles sont les règles?Un paquet de taille B octets arrive .- S'il n'y a pas assez de pièces dans le seau P , le paquet est marqué en rouge. Les pièces ne sont pas retirées . Sinon:
- C — , P B . Sinon:
- B .
 Autrement dit, les règles de tr-TCM sont différentes.Tant que le trafic reste dans la vitesse garantie, les pièces sont retirées des deux compartiments. Grâce à cela, lorsque les pièces s'épuisent dans le seau C , elles resteront dans P , mais juste assez pour ne pas dépasser le PIR (si elles n'étaient retirées que de C , alors P se remplirait plus et donnerait une vitesse beaucoup plus élevée).En conséquence, si elle est supérieure à la garantie, mais inférieure au pic, les pièces ne sont retirées que de P , car en C il n'y a déjà rien.tr-TCM surveille non seulement les rafales, mais également une vitesse de pointe constante.tr-TCM est décrit dans la RFC 2698 .Également utilisé pour le polissage en PHB AF.
Autrement dit, les règles de tr-TCM sont différentes.Tant que le trafic reste dans la vitesse garantie, les pièces sont retirées des deux compartiments. Grâce à cela, lorsque les pièces s'épuisent dans le seau C , elles resteront dans P , mais juste assez pour ne pas dépasser le PIR (si elles n'étaient retirées que de C , alors P se remplirait plus et donnerait une vitesse beaucoup plus élevée).En conséquence, si elle est supérieure à la garantie, mais inférieure au pic, les pièces ne sont retirées que de P , car en C il n'y a déjà rien.tr-TCM surveille non seulement les rafales, mais également une vitesse de pointe constante.tr-TCM est décrit dans la RFC 2698 .Également utilisé pour le polissage en PHB AF.
Résumé de la limite de vitesse
Alors que la mise en forme diffère le trafic lorsqu'il est dépassé, le polissage le rejette.La mise en forme n'est pas adaptée aux applications sensibles à la latence et à la gigue.Pour implémenter le polissage dans le matériel, l'algorithme Token Bucket est utilisé, pour la mise en forme - Leaky Bucket.Le seau à jetons peut être:- Avec un seau - Tarif unique - Marquage bicolore. Permet des rafales valides.
- Avec deux godets - Taux unique - Marquage tricolore (sr-TCM). L'excédent du godet C (CBS) est versé dans le godet E. Permet des surtensions autorisées et redondantes.
- Avec deux seaux - Deux taux - Marquage tricolore (tr-TCM). Les godets C et P (PBS) se régénèrent indépendamment à différentes vitesses. Permet une vitesse de pointe et des rafales autorisées et excessives.
sr-TCM se concentre sur la quantité de trafic au-delà de la limite. tr-TCM - à la vitesse à laquelle il arrive.Le polissage peut être utilisé à l'entrée et à la sortie de l'appareil. La mise en forme se fait principalement à la sortie.Pour PHB CS et EF, le marquage bicolore à taux unique est utilisé.Pour AF, sr-TCM ou tr-TCM.Pour une meilleure compréhension, je recommande de se référer à la RFC originale ou de lire ici .Token Bucket . , , , , .
, — , . , , , — .
, . — . .
Ci-dessus, j'ai décrit tous les mécanismes de base de la QoS, sinon approfondir la QoS hiérarchique. Un système sophistiqué avec de nombreuses pièces mobiles.Tout allait bien (non?) Sonné jusqu'à présent, mais que se passe-t-il sous le panneau externe vanille du routeur?Au fil des ans, les fournisseurs ont ajouté de plus en plus de contours, développé des puces sophistiquées, élargi les tampons, d'une part, pour suivre le volume croissant du trafic et de ses nouvelles catégories, et d'autre part, pour résoudre les problèmes croissants causés par le premier paragraphe.La course en cours. Les paquets ne doivent pas être perdus si le concurrent ne les perd pas. Vous ne pouvez pas refuser la fonctionnalité si un adversaire se tient à ses côtés sous les portes du client.Ida dans l'antre de la propriété!9. Implémentation matérielle de QoS
Dans ce chapitre, j'entreprends la tâche ingrate. Si vous le décrivez le plus simplement possible, il y aura toujours ceux qui disent que tout n'est pas ainsi en réalité.Si vous le décrivez tel quel, le lecteur laissera tomber l'article car il se transformera en dessin sous-marin, plus précisément, des dessins de trois bateaux avec des crayons de couleurs différentes sur une seule feuille.En général, je ferai une mise en garde qu'en réalité tout n'est pas le même qu'en réalité, et j'irai selon la version d'une simple présentation.Pardonnez-moi mon collègue perfectionniste.Qu'est-ce qui contrôle le comportement du nœud et déclenche les mécanismes appropriés par rapport au package? La priorité qu'il porte dans l'une des rubriques? Oui et non. Comme mentionné ci-dessus, au sein d'un périphérique réseau, l'en-tête de commutation standard cesse généralement d'exister.
Comme mentionné ci-dessus, au sein d'un périphérique réseau, l'en-tête de commutation standard cesse généralement d'exister. Dès qu'un paquet arrive sur la puce de commutation, les en-têtes en sont supprimés et envoyés pour analyse, et la charge utile languit dans une sorte de tampon temporaire.Sur la base des en-têtes, une classification (BA ou MF) a lieu et une décision est prise concernant la redirection.Après un moment, un en-tête interne avec des métadonnées sur le package est suspendu sur le package.Ces métadonnées contiennent de nombreuses informations importantes - l'adresse de l'expéditeur et du destinataire, la puce de sortie, le numéro de série de la cellule, s'il y a eu fragmentation du paquet et le marquage de classe (CoS) et la priorité de suppression sont obligatoires. Marquage uniquement au format interne - il peut coïncider avec le DSCP ou non.En principe, à l'intérieur de la boîte, vous pouvez définir une longueur de marquage arbitraire sans être lié aux normes et définir des actions très flexibles avec le package.Chez Cisco, le marquage interne est appelé QoS Group, chez Juniper - Forwarding Class, Huawei n'a pas décidé: quelque part il appelle les priorités internes, quelque part les priorités locales, quelque part la classe de service et quelque part juste CoS. Ajoutez des noms pour d'autres fournisseurs dans les commentaires - j'ajouterai.Ce marquage interne est attribué en fonction de la classification effectuée par le nœud.Il est important que, sauf indication contraire, l'étiquetage interne ne fonctionne qu'à l'intérieur du nœud, mais n'apparaisse pas sur l'étiquette dans les en-têtes du paquet qui sera envoyé à partir du nœud - il restera le même.Cependant, à l'entrée du domaine DS après la classification, il y a généralement un nouveau marquage dans une certaine classe de service acceptée dans ce réseau. Ensuite, l'étiquetage interne est converti en la valeur acceptée pour cette classe sur le réseau et est enregistré dans l'en-tête du paquet envoyé.L'étiquetage interne CoS et Drop Precedence définit le comportement uniquement au sein d'un nœud donné et n'est pas explicitement transmis aux voisins, à l'exception du ré-étiquetage des en-têtes.CoS et Drop Precedence définissent le PHB, ses mécanismes et paramètres: prévention des encombrements, gestion des encombrements, ordonnancement et réétiquetage.
Dès qu'un paquet arrive sur la puce de commutation, les en-têtes en sont supprimés et envoyés pour analyse, et la charge utile languit dans une sorte de tampon temporaire.Sur la base des en-têtes, une classification (BA ou MF) a lieu et une décision est prise concernant la redirection.Après un moment, un en-tête interne avec des métadonnées sur le package est suspendu sur le package.Ces métadonnées contiennent de nombreuses informations importantes - l'adresse de l'expéditeur et du destinataire, la puce de sortie, le numéro de série de la cellule, s'il y a eu fragmentation du paquet et le marquage de classe (CoS) et la priorité de suppression sont obligatoires. Marquage uniquement au format interne - il peut coïncider avec le DSCP ou non.En principe, à l'intérieur de la boîte, vous pouvez définir une longueur de marquage arbitraire sans être lié aux normes et définir des actions très flexibles avec le package.Chez Cisco, le marquage interne est appelé QoS Group, chez Juniper - Forwarding Class, Huawei n'a pas décidé: quelque part il appelle les priorités internes, quelque part les priorités locales, quelque part la classe de service et quelque part juste CoS. Ajoutez des noms pour d'autres fournisseurs dans les commentaires - j'ajouterai.Ce marquage interne est attribué en fonction de la classification effectuée par le nœud.Il est important que, sauf indication contraire, l'étiquetage interne ne fonctionne qu'à l'intérieur du nœud, mais n'apparaisse pas sur l'étiquette dans les en-têtes du paquet qui sera envoyé à partir du nœud - il restera le même.Cependant, à l'entrée du domaine DS après la classification, il y a généralement un nouveau marquage dans une certaine classe de service acceptée dans ce réseau. Ensuite, l'étiquetage interne est converti en la valeur acceptée pour cette classe sur le réseau et est enregistré dans l'en-tête du paquet envoyé.L'étiquetage interne CoS et Drop Precedence définit le comportement uniquement au sein d'un nœud donné et n'est pas explicitement transmis aux voisins, à l'exception du ré-étiquetage des en-têtes.CoS et Drop Precedence définissent le PHB, ses mécanismes et paramètres: prévention des encombrements, gestion des encombrements, ordonnancement et réétiquetage.
Quels cercles les paquets passent-ils entre les interfaces d'entrée et de sortie? J'ai passé en revue dans un article précédent . En fait, cela s'est avéré imprévu, car à un moment donné, il est devenu évident que sans comprendre l'architecture, il était prématuré de parler de QoS.Cependant, répétons.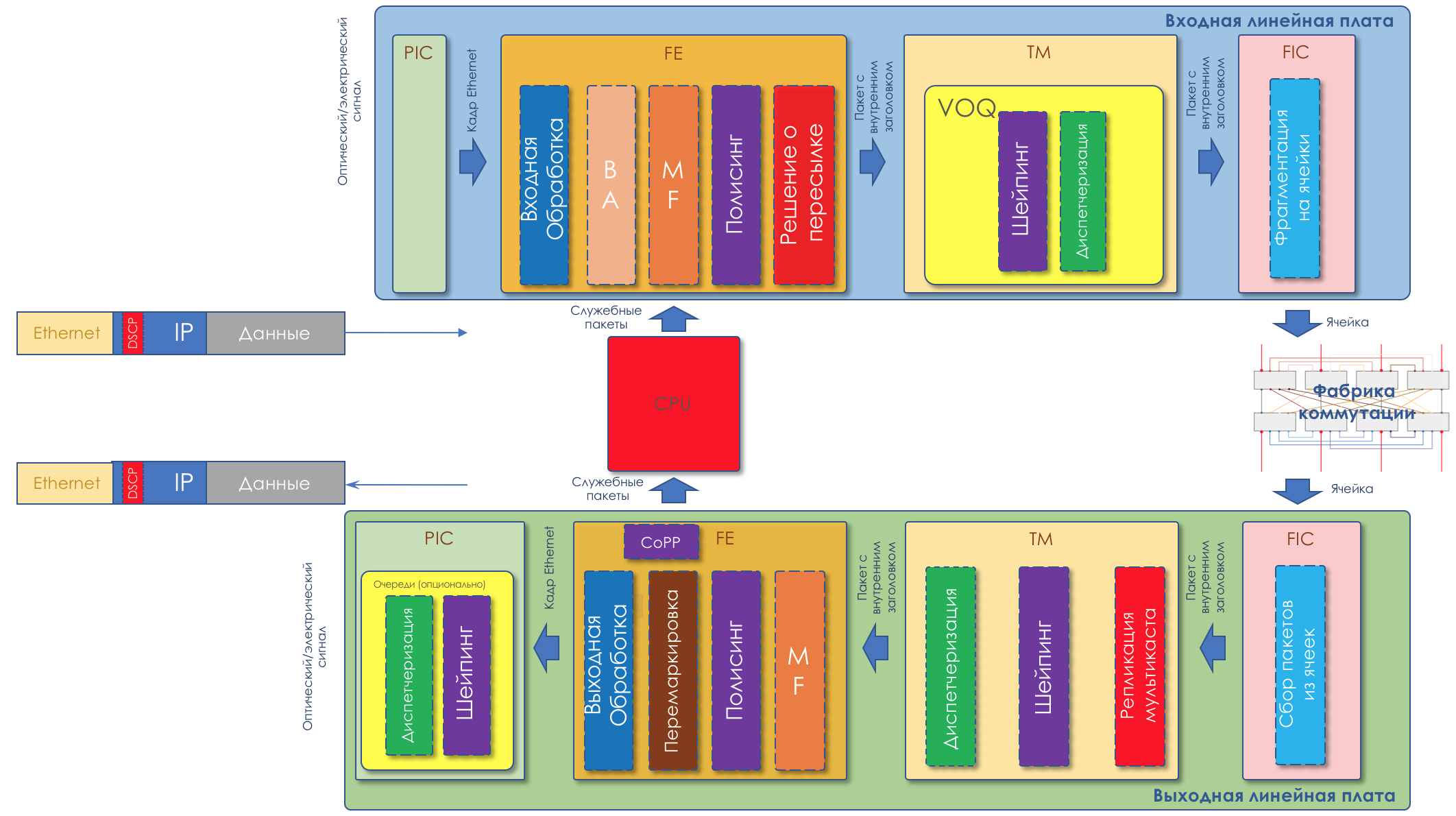
- Le signal frappe l'interface d'entrée physique et sa puce (PIC). Un flux de bits en découle, puis un paquet avec tous les en-têtes.
- À côté de la puce de commutation d'entrée (FE), où les en-têtes sont séparés du corps du paquet. La classification se produit et il est déterminé où le paquet doit être envoyé plus loin.
- À côté de la file d'attente d'entrée (TM / VOQ). Déjà ici, les packages sont disposés dans différentes files d'attente en fonction de leur classe.
- Suite à l'usine de commutation (le cas échéant).
- À côté de la file d'attente de sortie (TM).
- (FE), .
- (, ) (PIC).
Dans ce cas, le routeur doit résoudre une équation complexe.Développez tout en classes, offrez à quelqu'un une large bande, quelqu'un à faible latence, quelqu'un n'assure aucune perte.Et en même temps, ayez le temps de sauter tout le trafic si possible.De plus, vous devez faire du façonnage, éventuellement du polissage. Si une surcharge se produit soudainement, faites-y face.Et cela ne compte pas les recherches, le traitement ACL, le comptage des statistiques.Part peu enviable. Mais les robots injectent, pas un homme.En fait, il n'y a que deux endroits où les mécanismes QoS fonctionnent - une puce de commutation et une puce / file d'attente de gestion du trafic.Dans le même temps, des opérations sur la puce de commutation nécessitent une analyse ou des actions avec des en-têtes.- Classification
- Polissage
- Réétiquetage
TM s'occupe du reste. Fondamentalement, ce sont des opérations de routine avec un algorithme prédéfini et des paramètres personnalisés:- Prévention de la congestion
- Gestion de la congestion
- Façonner
TM est un tampon intelligent, généralement basé sur SD-RAM.Il est intelligent parce que, a) programmable, b) il peut faire toutes sortes de choses délicates avec des files d'attente.Il est souvent distribué - des puces SD-RAM sont situées sur chaque carte d'interface, et ensemble, elles sont combinées en VOQ (Virtual Output Queue), ce qui résout le problème de blocage de la tête de ligne.Le fait est que si la puce de commutation ou l'interface de sortie est obstruée, ils demandent à la puce d'entrée de ralentir et de ne pas envoyer de trafic pendant un certain temps. S'il n'y a qu'une seule file d'attente dans toutes les directions, il est très décevant que toutes les autres souffrent d'une seule interface de sortie. Il s'agit du Head of Line Blocking.VOQ, sur la carte d'interface d'entrée, crée plusieurs files d'attente de sortie virtuelles pour chaque interface de sortie existante.De plus, ces lignes dans des équipements modernes prennent en compte l'étiquetage de l'emballage.À propos de VOQ est décrit suffisamment en détail dans une série de notes ici .Soit dit en passant, ils sont vraiment placés dans la file d'attente, ils sont promus, ce ne sont pas les paquets eux-mêmes qui sont saisis, etc., mais uniquement les enregistrements les concernant. Cela n'a aucun sens de faire autant de gestes avec de grands tableaux de bits. Pendant que la QoS se moque des enregistrements, les paquets sont parfaitement dans leur mémoire et sont récupérés à partir de là à l'adresse.VOQ est une file d'attente logicielle (le terme anglais Software Queue est plus précis). Après cela, juste avant l'interface, il y a aussi une file d'attente matérielle, qui fonctionne toujours strictement selon FIFO. Il est presque impossible de contrôler aucun de ses paramètres (par exemple, Cisco vous permet de configurer uniquement la profondeur avec la commande tx-ring-limit).Juste entre les files d'attente logicielles et matérielles, vous pouvez exécuter des répartiteurs arbitraires. C'est dans la file d'attente du programme que fonctionnent Head / Tail-drop et AQM, le polissage et le façonnage.La taille de la file d'attente matérielle est très petite (unités de paquets), car le répartiteur fait tout le travail d'empilement du débit de ligne.Malheureusement, ici, vous pouvez faire de nombreuses réservations, et en fait tout biffer avec un stylo rouge et dire "le vendeur X ne le fait pas".
Je voudrais faire une dernière remarque sur les packages de services. Ils sont traités différemment des paquets d'utilisateurs de transit.Étant générés localement, leur conformité aux règles ACL et aux limites de vitesse n'est pas vérifiée.Les paquets de l'extérieur destinés au processeur de la puce de commutation de sortie tombent dans d'autres files d'attente - vers le processeur - en fonction du type de protocole.Par exemple, BFD a la priorité la plus élevée, OSPF peut attendre plus longtemps et ICMP n'a généralement pas peur de tomber. C'est-à-dire que plus le paquet est important pour que le réseau fonctionne, plus sa classe de service est élevée lors de l'envoi vers le CPU. C'est pourquoi il est normal de voir des retards variables sur le transit hop dans le ping ou le traçage - ICMP n'est pas un trafic prioritaire pour le CPU.De plus, des paquets de protocole sont appliquésCoPP - Control Plane Protection (ou Policing) - limitation de vitesse pour éviter une utilisation élevée du processeur - encore une fois, de meilleures baisses prévisibles dans les files d'attente à faible priorité avant le début des problèmes.CoPP aidera à la fois à partir d'un DoS ciblé et d'un comportement anormal du réseau (par exemple, des boucles) lorsqu'un volume de trafic de diffusion commence à arriver sur l'appareil.
Liens utiles
- Le meilleur livre sur la théorie et la philosophie de la QoS: QS-Enabled Networks: Tools and Foundations .
Certains extraits peuvent être lus ici , mais je recommanderais de le lire de et vers, de ne pas échanger. - QoS Huawei: Special Edition QoS(v6.0) . PHB .
- sr-TCM tr-TCM : Understanding Single-Rate and Dual-Rate Traffic Policing .
- VOQ: What is VOQ and why you should care?
- QoS MPLS: MPLS and Quality of Service .
- QoS Juniper: Juniper CoS notes .
- QoS TCP UDP. : The TCP/IP Guide
- , , : TCP .
- , FQ: Queuing and Scheduling .
, , An Introduction to Computer Networks , , Introduction, . .
- WFQ , , , , , : Weighted Fair Queueing: a packetized approximation for FFS/GP.
- Il y a aussi le mécanisme LFI, que je n'ai pas abordé, car il est difficile dans nos réalités d'interfaces de cent gigaoctets également, mais il pourrait être intéressant de se familiariser: fragmentation de lien et entrelacement .
Et bien sûr, la suite RFC ... Conclusion
Cette version a eu de nombreux critiques.Je vous remercie
Alexander Fatin ( LoxmatiyMamont ) pour un mot d'introduction et de précieux conseils sur l'expressivité et la clarté du texte.Alexander Clipper (@ metallicat20) pour sa revue par les pairs.Alexander Klimenko (@ v00lk) pour les critiques sévères et les changements les plus massifs de ces derniers jours.Andrey Glazkov (@glazgoo) pour des commentaires sur la structure, la terminologie et les virgules.Artyom Chernobay pour KDPV.Anton Klochkov (@NAT_GTX) pour les contacts avec Miran.Miran (miran.ru) pour avoir organisé un serveur avec Eva et diffusé. Traditionnellement, ma famille, qui, cette fois, a le moins souffert en raison de son absence près des moments les plus difficiles.