Préface
Tout a commencé il y a plus de 2 ans, et je suis passé à la 4e année de la spécialité "Business Informatics" de l'Université d'État des systèmes de contrôle et de la radioélectronique de Tomsk (TUSUR). Il ne restait pas beaucoup de temps avant la fin de l'université et la perspective d'écrire un diplôme se profilait déjà sous nos yeux. L'idée d'acheter une œuvre finie n'a pas été envisagée. Je voulais vraiment faire quelque chose moi-même. Il y avait beaucoup d'options pour les sujets des projets de diplôme: à la fois des projets de configuration pour automatiser les besoins de production de l'entreprise et le projet pour la mise en œuvre de la gestion de documents à lui seul pour 3 unités territoriales et plus de 500 utilisateurs actifs et l'introduction de l'EDI. Bref, tout était dans ma tête, mais rien de tout cela ne m'a inspiré. Et c'était l'essentiel.
A cette époque, je travaillais dans une entreprise réputée et pour les affaires, j'ai rencontré un programmeur sympa et généralement une bonne personne Andrei Shcheglov (Salut Andrei!) Et en quelque sorte = lors d'une conversation, il m'a demandé si j'avais entendu quelque chose sur OneScript et Langage de script Gherkin. À laquelle j'ai reçu une réponse que non, je n'ai pas entendu. Naturellement, la soirée google / Yandex et la nuit blanche ont conduit à l'idée que le voici - le monde de l'inconnu. Mais l'idée que cela pourrait faire l'objet d'une thèse n'est pas encore apparue. Le cercle de tâches de routine était le travail habituel dans le configurateur 1C par tâche, comme vous le comprenez avec les tests manuels et ne vous permettait pas de vous immerger complètement dans une nouvelle approche dans le monde 1C.
Concepts inconnus
La première difficulté que j'ai rencontrée était une quantité incroyable de terminologies et d'outils différents dont je n'avais pas entendu parler du tout - car à ce moment j'étais un "odnosnik typique" (à ce moment, l'holivar commence ...) Surtout ne connaissant aucun autre langage de programmation, et En outre, les méthodologies de la grande informatique ne m'étaient pas du tout familières, j'ai dû passer d'un sujet à l'autre pour remplir au moins en quelque sorte mon glossaire.
Presque au même moment, moi (nous - et mes collègues) avons été confrontés à un problème assez spécifique. Ils ont pris le module logiciel de l'entrepreneur, vérifié les copies. Tout semble fonctionner. Mais comme il y avait beaucoup de travail, ils ont signé un acte de travail terminé et l'ont jeté dans le productif. Tout a été bon pendant six mois, jusqu'à ce que les données de ce sous-système ne dépassent pas la limite autorisée. Et des choses très étranges ont commencé à se produire. La réalisation d'un document à partir du module a commencé à se produire pendant 5 à 10 minutes, un tas d'erreurs est apparu, etc. Voir le code du programme était horrible (ne demandez pas pourquoi cela n'a pas été fait avant d'accepter ...). Le nombre de cycles imbriqués était juste au-delà du raisonnable. La seule demande dans le quatrième cycle et l'appel en 4 points étaient des bagatelles, itérant sur tous les documents précédents pour remplir le document actuel, un copier-coller 10 fois du même bloc et bien plus encore.
Exemple d'imbrication:

Duplication de champs dans la mise en page:

De plus, pour remplir ces champs, une copie-copie de 14 fois .
Début de cycle:

Et jusqu'à ce que la variable FF atteigne 15:

Eh bien, et un tas d'autres œuvres d'art tout aussi uniques.
Du coup, je me suis souvenu que pour OneScript il y avait une bibliothèque simple pour calculer la "cyclomaticité" du module (1) (la complexité d'un module ou d'une méthode). Trouvé, calculé. J'ai obtenu une valeur de 163 unités, avec une valeur valide de pas plus de 10. Et je suis arrivé à la conclusion que le test d'acceptation du code de programme devrait être obligatoire et qu'il devrait être automatique et continu. Ensuite, j'ai découvert l'inspection continue - et comme cela s'est avéré en 2006, IBM a fait (2) une publication sur ce sujet.
Encore plus. De nombreuses personnes travaillant dans de grandes entreprises ont probablement rencontré le problème du déploiement d'une copie de la base de travail sur la machine locale du développeur. Lorsque cette base pèse 5 à 10 gigaoctets - ce n'est pas un problème, et lorsqu'elle pèse presque un téraoctet uniquement en sauvegarde, c'est déjà sérieux. En conséquence, il a fallu 5-6 heures de temps de travail pour déployer une nouvelle copie. Quand j'en ai eu marre, j'ai commencé à utiliser un très bon outil 1C-Deploy-and-CopyDB (Anton merci!) Puis j'ai réalisé que l'automatisation était cool.
En outre, il y avait d'autres tâches, par exemple, la mise à jour régulière de la base principale et distribuée du stockage la nuit, les tests de formulaire, les tests de scénario, etc. Une partie de cela a été réalisée, mais d'autres non.
Mais tout cela n'était nécessaire qu'à moi. Lors de la recherche de personnes partageant les mêmes idées dans sa ville, il a pratiquement échoué. Ils ne sont pas là. Bien que terriblement étrange, car les problèmes sont typiques. À ce moment-là, je savais déjà que je voulais écrire ma thèse sur ce sujet. Mais je ne savais pas quoi écrire. Par conséquent, j'ai dû rejoindre la communauté non seulement en lisant, mais au moins en écrivant et en posant des questions. Les principaux endroits où vous pouvez poser des questions étaient
Projets Github:
• https://github.com/silverbulleters/add
• https://github.com/oscript-library/opm
• https://github.com/EvilBeaver/OneScript
• https://github.com/silverbulleters/vanessa-runner/
Forum XDD:
• Section 1Script
• section de test
• section d'automatisation des processus
Eh bien et comme moyen de communication rapide - groupes de profils à Gitter
La collecte de matériel a commencé. Comme le destin l'aurait voulu, j'ai réussi à contacter Alexey Lustin alexey-lustin (Salut Alexey!) Et à parler de mon idée de diplôme sur le forum XDD. À laquelle j'ai été surpris d'entendre des commentaires d'approbation et même une invitation à subir une pratique de pré-graduation chez Silver Bullet. C'était déjà une victoire. Pendant plusieurs heures, nous avons proposé le sujet et le contenu du diplôme. Nous fixons des tâches pour les travaux pratiques. J'ai obtenu le chef du projet de diplôme de la société - Arthur Ayukhanov (Arthur salut!) Comment le jeune Padawan a eu accès au cours vidéo de l'ingénieur de publication et la possibilité d'obtenir Nikita Gryzlov (Salut Nikita!) Illimitéement avec ses questions, pour lesquelles il est très reconnaissant.
En résumé:
Le sujet du diplôme est «Gestion automatisée du cycle de vie des systèmes d'information - ingénierie système et logicielle des solutions sur la plateforme 1C: Entreprise dans des conditions d'amélioration continue de la qualité du processus de production».

L'objectif du travail de qualification final (WRC) est d'identifier la relation entre les outils logiciels et une description du processus métier du circuit DevOps dans la zone 1C.
La justification théorique du projet était la norme pour l'amélioration continue de la qualité de service à partir d'ITIL 3.0, et l'objet pratique était la construction d'une boucle d'intégration continue pour la nouvelle solution d'application que nous avons développée - le compte personnel du client. Pour ce faire, le serveur source GitLab et la boucle de génération Jenkins ont été déployés. Les tests ont été exécutés sur un serveur dédié (Windows Slave). La configuration a été déchargée du référentiel 1C à l'aide de la bibliothèque Gitsync , version 3.0
(actuellement situé dans la branche develop) déjà avec les réalisations d'Alexei Khorev (Lech hello!) avec une fréquence de 30 minutes dans la branche develop. La raison du choix de cette version particulière était la possibilité de se connecter au référentiel via le protocole tcp, qui, malheureusement, ne supportait pas GitSync 2.x typique à l'époque. Si des modifications ont été enregistrées dans GitLab, l'exécution de la boucle d'intégration continue a été automatiquement lancée.
Étant donné que le budget de l'événement était nul et que la possibilité de créer un contrôle de qualité complet du code de programme sans acheter de module pour SonarQube était impossible, une vérification de la syntaxe 1C standard a été utilisée comme solution simplifiée. Bien qu'un déchargement unique ait néanmoins été effectué, les résultats ont été obtenus et analysés. Des vérifications supplémentaires de la cyclicité et de la présence de code réutilisable ont également été utilisées.
Au stade du test de la fonctionnalité, 2 frameworks Vanessa-Behavior et XUnitFor1C ont été utilisés dans leur version combinée appelée Vanessa Automation Driven Development (Vanessa ADD). Le premier a été utilisé pour commencer à tester le comportement attendu, le second a vérifié l'ouverture des formulaires (test de fumée). La réussite de la boucle d'intégration continue a généré des rapports générés automatiquement.
Selon les résultats du test, l'ingénieur de publication a pris la décision de fusionner les branches de développement et de master et a lancé (déjà manuellement) la troisième tâche - la publication des modifications de la base de données productive. La base de données productive n'est pas connectée au référentiel et est complètement fermée aux modifications manuelles. La mise à jour s'effectue uniquement à la livraison et en mode automatique.
Pour décrire le processus opérationnel du circuit, un diagramme IDEF0 a été formé, composé de 4 blocs consécutifs qui forment le passage du circuit. Une erreur qui se produit lors du passage à l'une des étapes interrompt le processus d'assemblage avec une notification à l'ingénieur de version et transfère le contrôle au 5e bloc du processus d'assemblage, où les rapports sont générés au format ALLURE, JUNIT et, bien sûr, cucumber.json.
Description du modèle IDEF0
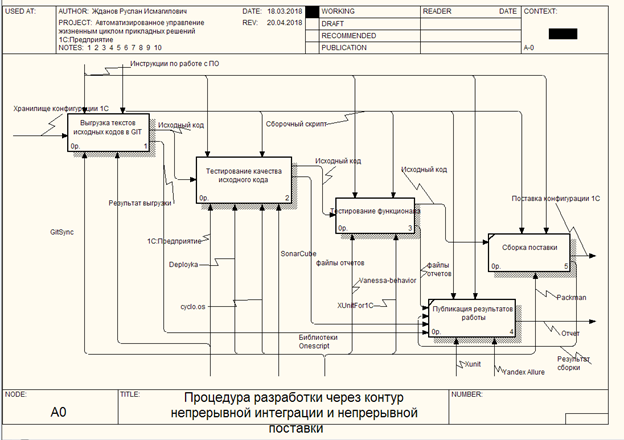
Le processus de "déchargement du code source dans GIT"
Données d'entrée: - Référentiel de configuration
Sortie (Sortie): - Code source
Contrôle: instructions pour travailler avec le logiciel, script d'assemblage
Mécanisme: 1C: Enterprise, Gitsync .
Une condition préalable à l'existence du contour est la présence de fichiers source. À partir de la version 8.3.6 de la plateforme, 1C offrait la possibilité de télécharger des codes source de configuration dans des fichiers. Il est à noter que ce processus peut avoir plusieurs options, selon les spécificités de développement du service informatique. Dans la version actuelle, pour simplifier le processus de transition des employés vers la nouvelle méthodologie, l'intégration avec le processus de développement actuel via le référentiel de configuration et l'utilisation du configurateur 1C a été effectuée.
Au stade du processus «Déchargement des sources dans GIT», le fichier, base d'informations de service 1C sera créé; il était connecté au magasin de configuration sous le compte de service; toutes les modifications sont reçues au moment actuel (ou au dernier commit dans le référentiel); les codes sources ont été déchargés dans le répertoire d'assembly; engagé dans le système de stockage de version GIT; les modifications sont envoyées au serveur source GitLab
Le processus de «tester la qualité du code source»
Données d'entrée: - Code source
Sortie (Sortie): - Code source
Contrôle: instructions pour travailler avec le logiciel, script d'assemblage
Mécanisme: 1C: Enterprise, Deployka , SonarQube , Cyclo.os - (malheureusement il n'y a pas de lien)
Au début de ce processus, le code source est stocké dans le référentiel GitLab. À l'aide du script de contrôle (assemblage), il est reçu dans le répertoire d'assemblage. Au moyen de la plateforme 1C: Enterprise, basée sur ces codes sources, une base d'informations de service est déployée. Une analyse des erreurs est effectuée à l'aide des outils de la plateforme. Si au cours de l'analyse, des erreurs de code de programme sont détectées qui ne permettent pas d'assembler la configuration, le processus sera interrompu. Le but de cette étape est d'éliminer le temps perdu à analyser le code de programme d'une configuration inopérante.
Après vérification des erreurs, le calcul de la complexité cyclomatique du code de programme est lancé. Une augmentation de ce coefficient affecte considérablement le débogage et l'analyse du code de programme. La valeur maximale autorisée est 10. En cas de dépassement, une exception est levée et le code est renvoyé pour révision.
La dernière étape de l'analyse de la qualité du code du programme consiste à vérifier la conformité aux normes de développement. À ces fins, le schéma proposé utilise le service SonarQube et le module de support de syntaxe 1C développé par lui à partir de Silver Bullet. Sur la base des résultats de l'analyse, le système calcule la valeur de la dette technique pour chaque employé qui a publié le code de programme.
Processus de test fonctionnel
Données d'entrée: - Code source
Sortie (Sortie): - Code source
Contrôle: instructions pour travailler avec le logiciel, script d'assemblage
Mécanisme: 1C: Enterprise, Vanessa-Behavior, XunitFor1C .
Au cours du processus de développement, des situations peuvent se produire et de nouvelles fonctionnalités peuvent perturber le fonctionnement des sous-systèmes existants. Cela peut se manifester à la fois dans la formation d'exceptions et dans la conclusion du résultat non attendu. À ces fins, le comportement attendu du système est testé.
Plusieurs méthodes de développement et de test sont applicables pour ce circuit: TDD (Test Driven Development) et BDD (Behavior Driven Development)
Au moment de la rédaction de WRC, le framework Vanessa-bahavior était utilisé pour effectuer des tests en utilisant la méthodologie BDD et le XunitFor1C pour TDD. Ils sont actuellement fusionnés sous un seul produit Vanessa-ADD. La prise en charge des développeurs pour les produits plus anciens a été interrompue. Les résultats des tests sont transmis aux fichiers de rapport Yandex Allure et Xunit.
Processus «Assemblage de livraison»
Données d'entrée: - Code source
Données de sortie: - Livraison de la configuration
Contrôle: instructions pour travailler avec le logiciel, script d'assemblage
Mécanisme: 1C: Enterprise, packman .
Dans ce processus, la livraison finale de la livraison de configuration pour le déploiement sur le système cible se produit. Le code source vérifié se trouve dans la branche develop du référentiel de code source GitLab. Pour former une livraison, il est nécessaire que les modifications de la branche develop apparaissent dans la branche master . Cette action peut se produire à la fois manuellement et automatiquement et est réglementée par les exigences du service informatique utilisant la boucle CI / CD. Après la fusion des succursales, le processus d'assemblage de la livraison terminée démarre. Pour ce faire, encore une fois, dans le répertoire d'assemblage, sur la base des sources existantes, une base d'informations de service est créée puis, à l'aide des outils de la plateforme 1C: Enterprise, une livraison de configuration est générée et archivée. La livraison de la configuration est le produit final du processus d'assemblage et est livrée au client via des canaux de communication établis ou est installée directement dans un système d'information productif.
Processus de publication des résultats
Données d'entrée: - Décharger le résultat, rapporter les fichiers
Données de sortie: - Rapport
Contrôle: instructions pour travailler avec le logiciel, script d'assemblage
Mécanisme: Yandex Allure , Xunit .
Lors de l'exécution des étapes du processus, les outils de test créent des fichiers de rapport dans certains formats en tant que sous-produit. La tâche de ce processus est de regrouper, transformer et publier pour la commodité de l'analyse des données. Dans le cas où une exception est générée à un certain stade de l'assemblage et avec les paramètres nécessaires, le système doit automatiquement informer l'administrateur de la boucle des problèmes. Cette étape est effectuée dans le post-traitement du processus d'assemblage et doit être effectuée indépendamment des résultats des processus précédents.
Pour les commentaires, en plus de la liste de diffusion, l'intégration avec le responsable de l'entreprise Slack a été utilisée, où tous les messages d'information ont été envoyés concernant l'état de la construction, l'apparition de nouveaux commits, la formation de sauvegardes, ainsi que la surveillance du fonctionnement des services liés au circuit DevOps et de 1C à ensemble.
Les résultats de mon projet ont été la protection du WRC à la fin du mois de mai de cette année avec le résultat «excellent». De plus, les informations méthodologiques sur la formation du contour ont été mises à jour.

Conclusions générales:
- L'effet économique n'est possible qu'à long terme. L'expérience a montré que lorsque le projet de mise en œuvre de pratiques d'ingénierie est lancé, une baisse de la productivité du développement de 20 à 30% par rapport au niveau actuel est enregistrée. Cette période est temporaire et, en règle générale, les performances retrouvent leurs valeurs initiales après trois à quatre mois de fonctionnement. La baisse des performances est principalement due au fait que le développeur doit s'habituer aux nouvelles exigences de développement: écriture de scripts, tests et création de documentation technique.
- La stabilité d'un système d'information productif a considérablement augmenté en raison des tests du code du programme. Le fonctionnement garanti des sous-systèmes critiques est assuré par la couverture des tests de scénario. De ce fait, les risques de l'entreprise dans un domaine critique - l'interaction opérationnelle avec les clients ont été réduits.
- L'exclusion de correctifs dynamiques sur une base d'informations productive a permis de planifier le développement de manière plus constructive et d'empêcher le code logiciel de contourner la boucle de test.
- Coûts de main-d'œuvre réduits pour l'entretien de la base d'informations grâce à l'automatisation du circuit d'assemblage.
- L'utilisation des commentaires via Slack a permis de surveiller et de résoudre en ligne les problèmes de cycle de vie du système. Selon les critiques de l'équipe, l'utilisation d'un messager est plus pratique que l'envoi de courrier (bien qu'il soit également présent).
- L'utilisation de l'inspection de code continue automatisée (inspection continue) pour la conformité aux normes de développement (SonarQube) oblige les développeurs à accroître indépendamment leurs compétences, et la réparation de la dette technique identifiée directement pendant le développement d'un module logiciel est beaucoup plus rapide, car vous n'avez pas à passer du temps à restaurer le contexte de la tâche.
- L'activation de la fonctionnalité de documentation automatique et la génération d'instructions vidéo peuvent réduire le nombre de demandes des utilisateurs.
- Au cours du projet, un processus commercial a été formé qui décrit le cycle de vie du développement et des tests des solutions d'application 1C, ce qui a à son tour influencé la formation d'un projet pour la mise en œuvre de pratiques d'ingénierie . , 1.
, . 90% .
, :
- , " 1. - , , ( 5 ).
- “ 1”. . ( , " ". ).
- CICD 1 , 5.5.0 .
, , 1 , DevOps. , — DevOps 1 .
, DevOps 1. ?