Le succès des projets d'apprentissage automatique est généralement associé non seulement à la capacité d'utiliser différentes bibliothèques, mais aussi à une compréhension de la région d'où proviennent les données. Une excellente illustration de cette thèse a été la solution proposée par l'équipe d'Alexei Kayuchenko, Sergey Belov, Alexander Drobotov et Alexey Smirnov dans le cadre du concours PIK Digital Day. Ils ont pris la deuxième place et après quelques semaines, ils ont parlé de leur participation et des modèles construits lors de la prochaine
formation Yandex ML .
Alexey Kayuchenko:
- Bonjour! Nous parlerons du concours PIK Digital Day auquel nous avons participé. Un peu sur l'équipe. Nous étions quatre. Tous avec un fond complètement différent, de différents domaines. En fait, nous nous sommes rencontrés en finale. L'équipe s'est formée juste un jour avant la finale. Je parlerai du déroulement du concours, de l'organisation du travail. Ensuite, Seryozha sortira, il parlera des données, et Sasha parlera de la soumission, du déroulement final du travail et de la façon dont nous avons évolué dans le classement.

En bref sur la compétition. La tâche était très appliquée. PIC a organisé ce concours en fournissant des données sur les ventes d'appartements. En tant qu'ensemble de données de formation, il y avait une histoire avec des attributs pendant 2 ans et demi à Moscou et dans la région de Moscou. Le concours comportait deux étapes. C'était une étape en ligne, où chacun des participants a individuellement essayé de créer son propre modèle, et l'étape hors ligne, pas si longue, n'était que d'un jour du matin au soir. Il a frappé les leaders de la scène en ligne.
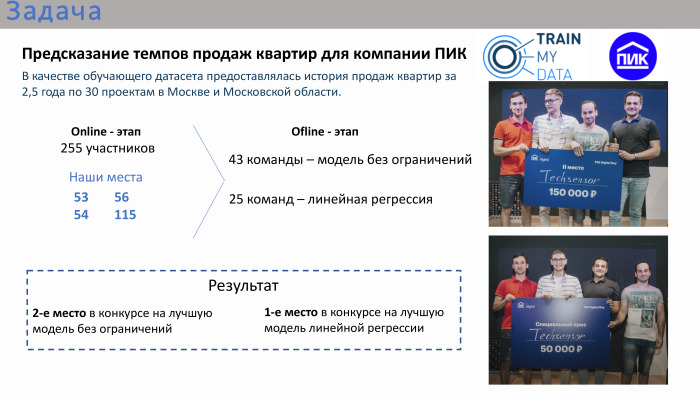
Selon les résultats de la compétition en ligne, nos places ne figuraient même pas dans le top 10, ni même dans le top 20. Nous y étions dans des endroits 50+. À la toute fin, c'est-à-dire la phase hors ligne, il y avait 43 équipes. Il y avait beaucoup d'équipes composées d'une seule personne, même s'il était possible de s'unir. Environ un tiers des équipes comptaient plus d'une personne. Il y a eu deux compétitions lors de la finale. Le premier concours est un modèle sans restrictions. Il était possible d'utiliser n'importe quel algorithme: apprentissage profond, apprentissage automatique. En parallèle, un concours a été organisé pour la meilleure solution de régression linéaire. L'organisateur a estimé que la régression linéaire était également assez appliquée, car le concours lui-même était très appliqué dans son ensemble. Autrement dit, la tâche a été posée - il était nécessaire de prédire le volume des ventes d'appartements, ayant des données historiques pour les 2,5 années précédentes avec des attributs.
Notre équipe a pris la deuxième place dans la compétition pour le meilleur modèle sans restrictions et la première place dans la compétition pour la meilleure régression. Double prix.

Je peux dire au sujet du déroulement général de l'organisation que la finale a été très stressante, assez stressante. Par exemple, notre décision gagnante a été téléchargée seulement deux minutes avant l'arrêt du match. La décision précédente nous plaçait, à mon avis, en quatrième ou cinquième place. Autrement dit, nous avons travaillé jusqu'à la fin, sans se détendre. Le PIC a très bien tout organisé. Il y avait de telles tables, il y avait même une véranda pour qu'on puisse s'asseoir dans la rue, respirer l'air frais. Nourriture, café, tout était fourni. La photo montre que tout le monde était assis dans ses groupes, travaillant.
Sergey en dira plus sur les données.
Sergey Belov:
- Merci. PIC nous a fourni plusieurs fichiers de données. Les deux principaux sont train.csv et test.csv, dans lesquels il y avait environ 50 fonctionnalités générées par le PIC lui-même. Le train était composé d'environ 10 000 lignes, test - de 2 000.
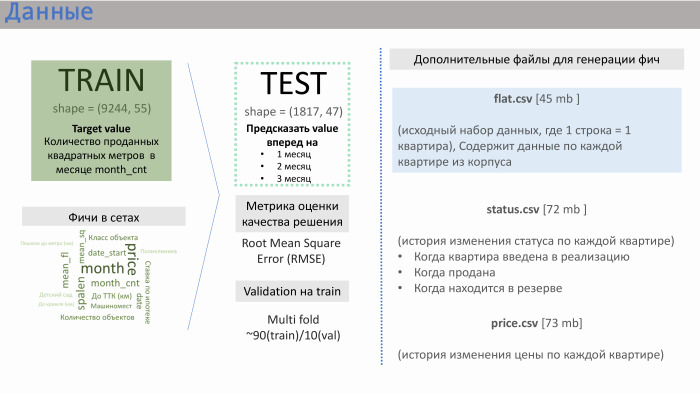
Qu'est-ce que la chaîne a fourni? Il contenait des données sur les ventes. Autrement dit, en tant que valeur (dans ce cas, objectif), nous avons réalisé des ventes au mètre carré d'appartements en moyenne sur un immeuble particulier. Il y avait environ 10 000 lignes de ce type. Les caractéristiques des ensembles que le PIK lui-même a générés sont montrées sur la diapositive avec la signification approximative que nous avons obtenue.
J'ai été aidé ici par mon expérience dans des sociétés de développement. Des caractéristiques telles que la distance de l'appartement au Kremlin ou à l'anneau de transport, le nombre de places de parking - elles n'affectent pas considérablement les ventes. L'influence est exercée par la classe de l'objet, la dormance et, surtout, le nombre d'appartements dans la mise en œuvre à l'heure actuelle. PIC n'a pas généré cette fonctionnalité, mais ils nous ont fourni trois fichiers supplémentaires: flat.csv, status.csv et price.csv. Et nous avons décidé de jeter un œil à flat.csv, car il n'y avait que des données sur le nombre d'appartements, leur statut.
Et si l'on se demande ce qui a servi à la réussite de notre décision, alors c'est un vrai travail d'équipe. Dès le début de ce concours, nous avons travaillé de manière très harmonieuse. Nous avons immédiatement discuté quelque part dans environ 20 minutes de ce que nous ferons. Nous sommes arrivés à la conclusion générale que la première chose dont vous avez besoin pour travailler avec des données est parce que tout scientifique des données comprend qu'il y a beaucoup de données dans les données et souvent la victoire est due à une fonctionnalité que l'équipe a générée. Après avoir travaillé avec les données, nous avons principalement utilisé divers modèles. Nous avons décidé de voir quel résultat nos caractéristiques donnent dans chacun de ces modèles, puis nous nous sommes concentrés sur le modèle illimité et le modèle de régression linéaire.
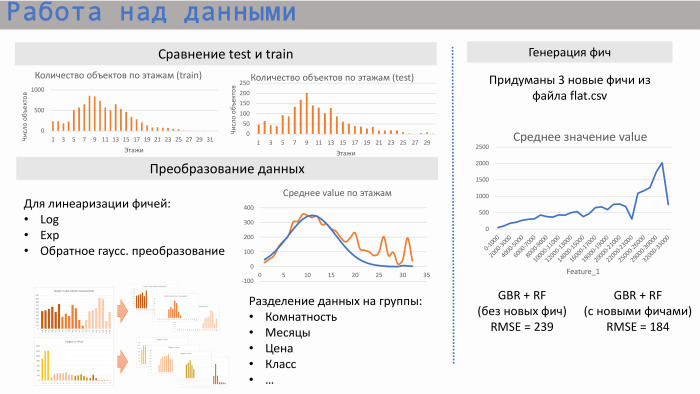
Nous avons commencé à travailler avec des données. Tout d'abord, nous avons examiné la relation entre les tests de trains, c'est-à-dire les intersections des zones de ces données. Oui, ils se croisent: dans le nombre d'appartements, dans la dormance, et dans un certain nombre moyen d'étages.
Plus loin pour la régression linéaire, nous avons commencé à effectuer certaines transformations. C'est comme les logarithmes standard d'un exposant. Par exemple, dans le cas de l'étage intermédiaire, il s'agit de la transformation gaussienne inverse pour la linéarisation. Nous avons également remarqué qu'il est parfois préférable de séparer les données en groupes. Si nous prenons, par exemple, la distance de l'appartement au métro ou à sa chambre, alors il y a des marchés légèrement différents, et il vaut mieux se diviser, faire des modèles différents pour chacun de ces groupes.
Nous avons généré trois fonctionnalités à partir du fichier flat.csv. L'un d'eux est présenté ici. On peut voir qu'elle a une assez bonne relation linéaire, outre cette subsidence. Quelle était cette fonctionnalité? Il correspond au nombre d'appartements en cours de réalisation. Et cette fonctionnalité fonctionne très bien à des valeurs faibles. Autrement dit, il ne peut y avoir plus d'appartements vendus que le montant de la vente. Mais dans ces fichiers, en fait, un certain facteur humain a été établi, car ils sont souvent compilés par des humains. Nous y avons vu directement des points qui ont été éliminés de cette zone, car ils étaient un peu obstrués.
Exemple de scikit-learn. Un modèle de GBR et Random Forest sans caractéristiques a donné RMSE 239, et avec ces trois caractéristiques - 184.
Sasha parlera des modèles que nous avons utilisés.
Alexander Drobotov:
- Quelques mots sur notre approche. Comme les gars l'ont dit, nous sommes tous différents, nous venons de différents domaines, d'une éducation différente. Et nous avions différentes approches. Au stade final, Lesha a davantage utilisé XGBoost de Yandex (très probablement, je veux dire CatBoost - ndlr), Seryozha - la bibliothèque scikit-learn, I - LightGBM et la régression linéaire.

Les modèles XGBoost, la régression linéaire et Prophet sont les trois options qui nous ont montré le meilleur score. Pour la régression linéaire, nous avons mélangé deux modèles et pour la compétition générale, XGBoost, et nous avons ajouté une petite régression linéaire.

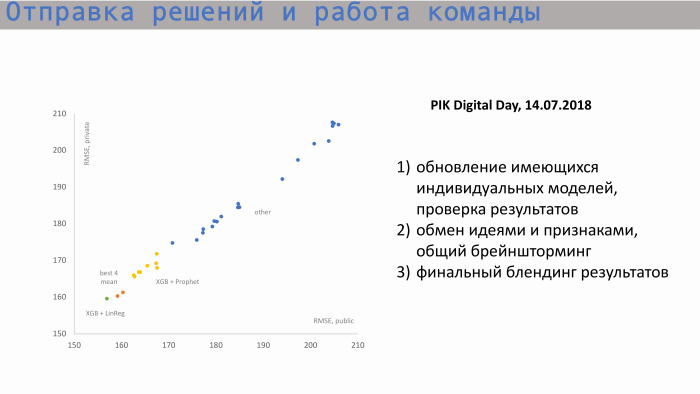
Voici le processus d'envoi des décisions et du travail d'équipe. Dans le graphique de gauche, l'axe X est public RMSE, la valeur métrique et l'axe Y est le score privé, RMSE. Nous sommes partis de ces positions. Voici des modèles individuels de chacun des participants. Ensuite, après avoir échangé des idées et créé de nouvelles fonctionnalités, nous avons commencé à approcher notre meilleur score. Nos valeurs pour les modèles individuels étaient approximativement les mêmes. Le meilleur modèle individuel est XGBoost et Prophet. Prophète a créé une prévision des ventes cumulées. Il y avait un signe tel que le carré de départ. Autrement dit, nous savions combien d'appartements nous avons au total, nous avons compris quelle valeur historique et quelle valeur incrémentale cherchait à obtenir la valeur totale. Prophet a fait une prévision pour l'avenir, a émis des valeurs au cours des périodes suivantes et les a soumises à XGBoost.
Le mélange de notre meilleur score individuel se situe quelque part par ici, ces deux points orange. Mais ce score n'était pas suffisant pour que nous arrivions au sommet.
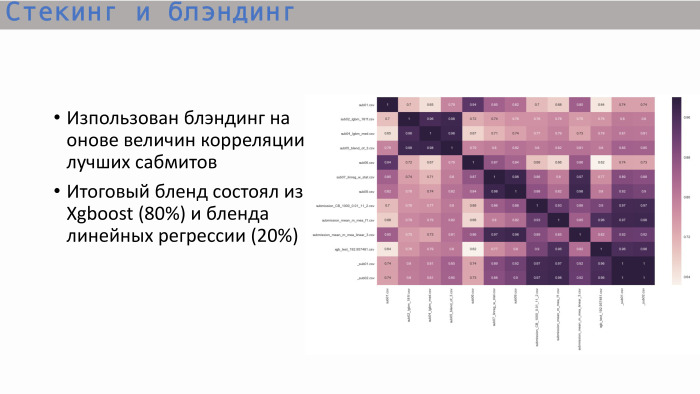
Après avoir étudié la matrice de corrélation habituelle des meilleures soumissions, nous avons vu ce qui suit: les arbres - et c'est logique - ont montré une corrélation proche de l'unité, et le meilleur arbre a donné XGBoost. Il montre une corrélation moins élevée avec la régression linéaire. Nous avons décidé de mélanger ces deux options dans un rapport de 8 à 2. C'est ainsi que nous avons obtenu la meilleure solution finale.
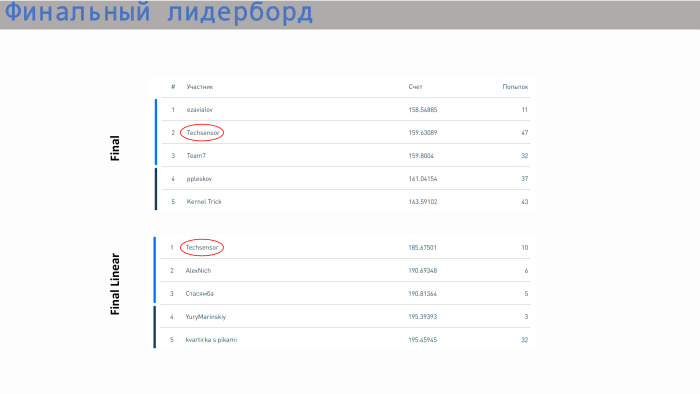
Ceci est un classement avec des résultats. Notre équipe a pris la deuxième place dans les modèles illimités et la première place dans les modèles linéaires. Quant au score - ici toutes les valeurs sont assez proches. La différence n'est pas très grande. Une régression linéaire fait déjà un pas dans la zone 5. Nous avons tout, merci!