
L'une des principales conférences Data Science de l'année a commencé à Londres aujourd'hui. Je vais essayer de parler rapidement de ce qui était intéressant à entendre.
Le début s'est révélé nerveux: le même matin, une réunion de masse des Témoins de Jéhovah a été organisée dans le même centre, donc ce n'était pas facile de trouver le bureau d'enregistrement du KDD, et quand je l'ai finalement trouvé, la ligne faisait 150-200 mètres de long. Néanmoins, après environ 20 minutes d'attente, il a reçu un badge convoité et est allé à une classe de maître.
Confidentialité dans l'analyse des données
Le premier atelier était consacré au maintien de la confidentialité dans l'analyse des données. Au début, j'étais en retard, mais, apparemment, je n'ai pas perdu grand-chose - ils ont parlé de l'importance de la confidentialité et de la façon dont les attaquants peuvent faire un mauvais usage des informations privées divulguées. Soit dit en passant, des gens très respectables de Google, LinkedIn et Apple le disent. À la suite de la classe de maître a laissé une impression très positive, les diapositives sont toutes disponibles
ici .
Il s'avère que le concept de
confidentialité différentielle existe depuis longtemps, dont l'idée est d'ajouter du bruit qui rend difficile l'établissement de vraies valeurs individuelles, mais conserve la possibilité de restaurer des distributions communes. En fait, il y a deux paramètres:
e - la difficulté de divulguer les données et
d - la distorsion des réponses.
Le concept original suggère qu'il existe une sorte de lien intermédiaire entre l'analyste et les données - le «Curateur», c'est lui qui traite toutes les demandes et génère des réponses pour que le bruit masque les données privées. En réalité, le modèle de confidentialité différentielle locale est souvent utilisé, dans lequel les données utilisateur restent sur l'appareil de l'utilisateur (par exemple, un téléphone mobile ou un PC), cependant, lors de la réponse aux demandes des développeurs, l'application envoie un paquet de données à partir de l'appareil personnel qui ne permet pas de savoir quoi exactement Cet utilisateur particulier a répondu. Cependant, lorsque vous combinez les réponses d'un grand nombre d'utilisateurs, vous pouvez restaurer l'image globale avec une grande précision.
Un bon exemple est l'enquête «Avez-vous eu un avortement»? Si vous menez une enquête "sur le front", alors personne ne dira la vérité. Mais si vous organisez l'enquête comme suit: «jetez une pièce, s'il y a un aigle, puis lancez-le à nouveau et dites« oui »à l'aigle, mais« non »aux queues, sinon répondez à la vérité», il est facile de rétablir la vraie distribution tout en préservant la vie privée individuelle. Le développement de cette idée a été la mécanique de collecte de statistiques sensibles
Google RAPPOR (RAndomized Privacy-Preserving Ordinal Report), qui a été utilisé pour collecter des données sur l'utilisation de Chrome et de ses fourchettes.
Immédiatement après la sortie de Chrome en open source, un assez grand nombre de personnes sont apparues qui souhaitaient créer leur propre navigateur avec une page d'accueil remplacée, un moteur de recherche, leurs propres dés publicitaires, etc. Naturellement, les utilisateurs et Google n'étaient pas enthousiastes à ce sujet. D'autres actions sont généralement compréhensibles: pour découvrir les substitutions les plus courantes et écraser administrativement, mais l'inattendu est sorti ... La politique de confidentialité de Chrome n'a pas permis à Google de prendre et de collecter des informations sur la configuration de la page d'accueil et du moteur de recherche de l'utilisateur :(
Pour surmonter cette limitation et créé RAPPOR, qui fonctionne comme suit:
- Les données de la page d'accueil sont enregistrées dans un petit filtre Bloom d'environ 128 bits.
- Un bruit blanc permanent est ajouté à ce filtre de floraison. Permanent = la même chose pour cet utilisateur, sans économiser le bruit, plusieurs demandes pourraient révéler des données utilisateur.
- En plus du bruit constant, le bruit individuel généré pour chaque requête est superposé.
- Le vecteur binaire résultant est envoyé à Google, où le décryptage de l'image globale commence.
- Tout d'abord, par des méthodes statistiques, nous soustrayons l'effet du bruit de l'image globale.
- Ensuite, nous construisons des vecteurs de bits candidats (les sites / moteurs de recherche les plus populaires en principe).
- En utilisant les vecteurs obtenus comme base, nous construisons une régression linéaire pour reconstruire l'image.
- Combinez la régression linéaire avec LASSO pour supprimer les candidats non pertinents.
Schématiquement, la construction du filtre ressemble à ceci:

L'expérience de la mise en œuvre de RAPPOR s'est avérée très positive et le nombre de statistiques privées collectées avec son aide augmente rapidement. Parmi les principaux facteurs de succès, les auteurs ont identifié:
- Simplicité et clarté du modèle.
- Ouverture et documentation du code.
- La présence sur les graphiques finaux des limites des erreurs.
Cependant, cette approche a une limitation importante: il est nécessaire d'avoir des listes de réponses candidates pour le décryptage (c'est pourquoi O - Ordinal). Quand Apple a commencé à collecter des statistiques sur les mots et les emoji utilisés dans les messages texte, il est devenu clair que cette approche n'était pas bonne. En conséquence, lors de la conférence WDC-2016, l'une des principales nouvelles fonctionnalités annoncées sur iOS était l'ajout d'une confidentialité différentielle. Une combinaison d'une structure d'esquisse avec un bruit supplémentaire a également été utilisée comme base, mais de nombreux problèmes techniques ont dû être résolus:
- Le client (téléphone) devrait être en mesure de construire et de stocker cette réponse dans un délai raisonnable.
- En outre, cette réponse doit être emballée dans un message réseau de taille limitée.
- Du côté d'Apple, tout cela devrait être regroupable dans un délai raisonnable.
En conséquence, nous avons trouvé un schéma utilisant
count-min-sketch pour encoder les mots, puis nous avons sélectionné au hasard la réponse d'une seule des fonctions de hachage (mais en fixant le choix pour la paire utilisateur / mot), le vecteur a été converti en utilisant la
transformation de Hadamard et envoyé au serveur uniquement un «bit» significatif pour la fonction de hachage sélectionnée.
Pour restaurer le résultat sur le serveur, il a également fallu revoir les hypothèses candidates. Mais, il s'est avéré qu'avec une grande taille de dictionnaire, c'est trop compliqué même pour un cluster. Il était en quelque sorte nécessaire de sélectionner de manière heuristique les domaines de recherche les plus prometteurs. L'expérience avec l'utilisation de bigrammes comme points de départ, à partir de laquelle vous pouvez ensuite assembler la mosaïque, n'a pas été réussie - tous les bigrammes étaient à peu près tout aussi populaires. L'approche de hachage bigram + mot a résolu le problème, mais a conduit à une violation de la vie privée. En conséquence, nous nous sommes installés sur des arbres de préfixe: des statistiques ont été collectées sur les premières parties du mot puis sur le mot entier.
Cependant, une analyse de l'algorithme de confidentialité utilisé par Apple par la communauté des chercheurs a montré que la confidentialité peut toujours
être compromise par des statistiques à long terme.
LinkedIn était dans une situation plus difficile avec son étude de la répartition des salaires des utilisateurs. Le fait est que la confidentialité différentielle fonctionne bien lorsque nous avons un très grand nombre de mesures, sinon il n'est pas possible de soustraire le bruit de manière fiable. Dans l'enquête sur les salaires, le nombre de rapports est limité et LinkedIn a décidé d'emprunter une voie différente: combiner des outils techniques de cryptographie et de cybersécurité avec le concept de
k-anonymat : les données utilisateur sont considérées comme suffisamment déguisées si vous les soumettez dans un paquet contenant k réponses avec les mêmes attributs d'entrée (par exemple, lieu et profession) qui ne diffèrent que par la variable cible (salaire).
En conséquence, un convoyeur complexe a été construit dans lequel différents services se transmettent des données, se chiffrant constamment afin qu'une seule machine ne puisse pas les ouvrir complètement. Par conséquent, les utilisateurs sont divisés par attributs en cohortes, et lorsque la cohorte atteint la taille minimale, ses statistiques sont transmises à HDFS pour analyse.
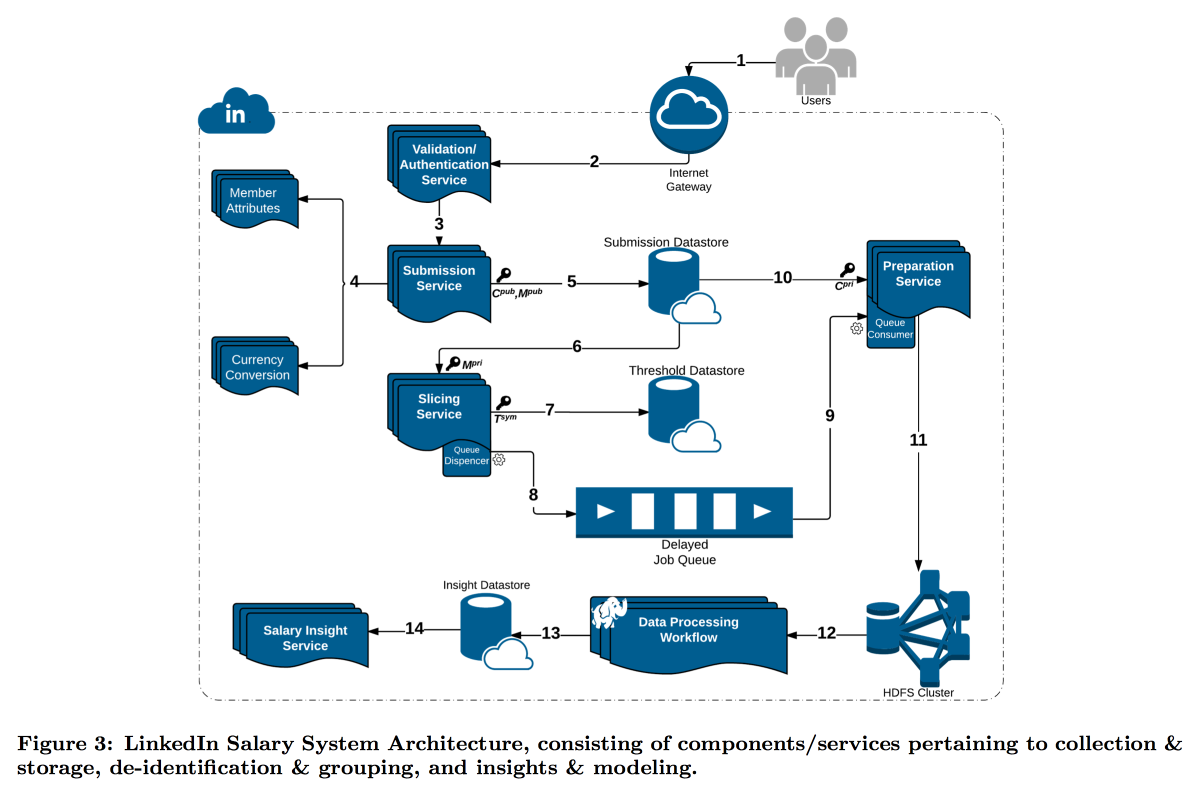
L'horodatage mérite une attention particulière: il doit également être anonymisé, sinon vous pouvez trouver la réponse qui est le journal des appels. Mais je ne veux pas prendre complètement le temps, car il est intéressant de suivre la dynamique. En conséquence, nous avons décidé d'ajouter un horodatage aux attributs par lesquels la cohorte est construite et d'en faire la moyenne.
Le résultat est une fonctionnalité premium intéressante et quelques questions ouvertes intéressantes:
Le RGPD suggère que, sur demande, nous devrions être en mesure de supprimer toutes les données des utilisateurs, mais nous avons essayé de les masquer afin que nous ne puissions plus maintenant trouver de quelles données il s'agit. Disposant de données sur un grand nombre de tranches / cohortes différentes, vous pouvez isoler les correspondances et étendre la liste des attributs ouverts
Cette approche fonctionne pour les données volumineuses, mais ne fonctionne pas avec les données continues. La pratique montre que simplement échantillonner des données n'est pas une bonne idée, mais Microsoft lors du NIPS2017 a
proposé une solution sur la façon de travailler avec. Malheureusement, les détails n'ont pas eu le temps de divulguer.
Analyse de grands graphes
Le deuxième atelier sur l'analyse des grands graphiques a commencé dans l'après-midi. Malgré le fait qu'il était également dirigé par les gars de Google et qu'il y avait plus d'attentes de lui, il l'aimait beaucoup moins - ils parlaient de leurs technologies fermées, puis tombaient dans le banalisme et la philosophie générale, puis plongeaient dans des détails sauvages, sans même avoir le temps de formuler la tâche. Néanmoins, j'ai pu saisir certains aspects intéressants. Les diapositives peuvent être trouvées
ici .
Tout d'abord, j'ai aimé le schéma appelé
clustering ego-network , je pense qu'il est possible de construire des solutions intéressantes sur sa base. L'idée est très simple:
- Nous considérons le graphique local du point de vue d'un utilisateur spécifique, MAIS moins lui-même.
- Nous regroupons ce graphique.
- Ensuite, nous «clonons» le haut de notre utilisateur, en ajoutant une instance à chaque cluster et sans les connecter les uns aux autres par des bords.
Dans un graphique transformé similaire, de nombreux problèmes sont résolus plus facilement et les algorithmes de classement fonctionnent plus proprement. Par exemple, il est beaucoup plus facile de partitionner un tel graphique de manière équilibrée, et lors du classement dans la recommandation d'amis, les nœuds de pont sont beaucoup moins bruyants. C'est pour cette tâche que les recommandations des amis d'ENC ont été examinées / promues.
Mais en général, ENC n'était qu'un exemple, chez Google, un département entier est engagé dans le développement d'algorithmes sur des graphiques et les fournit à d'autres départements sous forme de bibliothèque. La fonctionnalité déclarée de la bibliothèque est impressionnante: une bibliothèque de rêve pour SNA, mais tout est fermé. Dans le meilleur des cas, des blocs individuels peuvent être essayés de se reproduire par des articles. On prétend que la bibliothèque a des centaines d'implémentations à l'intérieur de Google, y compris sur des graphiques avec plus d'un billion d'arêtes.
Ensuite, il y a eu environ 20 minutes de promotion du modèle MapReduce, comme si nous ne savions pas à quel point c'était cool. Après quoi, les gars ont montré que de nombreux problèmes complexes peuvent être résolus (approximativement) en utilisant le modèle Randomized Composable Core Sets. L'idée principale est que les données sur les bords sont dispersées au hasard dans N nœuds, là, elles sont tirées en mémoire et le problème est résolu localement, après quoi les résultats de la solution sont transférés à la machine centrale et agrégés. On fait valoir que de cette façon, vous pouvez obtenir à bon marché de bonnes approximations pour de nombreux problèmes: composants de connectivité, forêt couvrant minimum, correspondance maximale, couverture maximale, etc. Dans certains cas, en même temps, mapper et réduire résolvent le même problème, mais ils peuvent être légèrement différents. Un bon exemple de la façon de nommer intelligemment une solution simple pour que les gens y croient.
Puis il y a eu une conversation sur ce que j'allais faire ici: le partitionnement graphique équilibré. C'est-à-dire comment couper un graphique en N parties de sorte que les parties soient de taille approximativement égale et que le nombre de liaisons à l'intérieur des parties soit significativement supérieur au nombre de liaisons externes. Si vous êtes en mesure de bien résoudre un tel problème, de nombreux algorithmes deviennent plus faciles et même les tests A / B peuvent être exécutés plus efficacement, avec compensation de l'effet viral. Mais l'histoire un peu déçue, tout ressemblait à un «plan gnome»: attribuer des numéros basés sur un clustering affine hiérarchique, déplacer, ajouter un déséquilibre. Pas de détails. À ce sujet sur KDD, il y aura un rapport séparé d'eux plus tard, je vais essayer d'y aller. De plus, il y a un
article de blog .
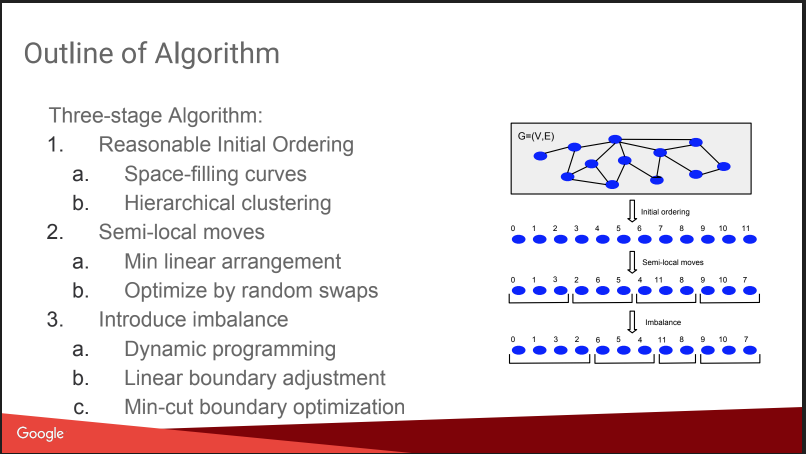
Néanmoins, ils ont donné une comparaison avec certains concurrents, certains d'entre eux sont ouverts:
Spinner ,
UB13 de FB,
Fennel de Microsoft,
Metis . Vous pouvez aussi les regarder.
Ensuite, nous avons parlé un peu des détails techniques. Ils utilisent plusieurs paradigmes pour travailler avec des graphiques:
- MapReduce au sommet de Flume. Je ne savais pas que c'était possible - Flume n'est pas beaucoup écrit sur Internet pour la collecte, mais pas pour l'analyse des données. Je pense que c'est une perversion intra-google. UPD: J'ai découvert que c'est vraiment un produit Google interne, cela n'a rien à voir avec Apache Flume, il y a un ersatz dans le cloud appelé dataflow
- Table de hachage distribuée MapReduce +. Ils disent que cela aide à réduire considérablement le nombre de tours MP, mais sur Internet il n'y a pas beaucoup écrit sur cette technique, par exemple ici
- Pregel - ils disent qu'il mourra bientôt.
- La transmission de messages asynchrone est la plus cool, la plus rapide et la plus prometteuse.
L'idée d'ASYMP est très similaire à Pregel:
- les nœuds sont distribués, gardent leur état et peuvent envoyer un message aux voisins;
- une file d'attente est construite sur la machine avec des priorités, ce qu'il faut envoyer (l'ordre peut différer de l'ordre d'addition);
- après avoir reçu un message, le nœud peut ou non changer d'état, lors du changement, nous envoyons un message aux voisins;
- terminer lorsque toutes les files d'attente sont vides.
Par exemple, lors de la recherche de composants connectés, nous initialisons tous les sommets avec des poids aléatoires U [0,1], après quoi nous commençons à nous envoyer au moins des voisins. En conséquence, ayant reçu leur minimum des voisins, nous recherchons un minimum pour eux, etc., jusqu'à ce que le minimum soit stabilisé. Ils notent un point important pour l'optimisation: réduire les messages d'un nœud (c'est le tour), ne laissant que le dernier. Ils parlent également de la facilité avec laquelle il est possible de récupérer après une défaillance tout en conservant l'état des nœuds.
Ils disent qu'ils construisent des algorithmes très rapides sans problèmes, il semble que ce soit vrai - le concept est simple et rationnel. Il y a des
publications .
En conséquence, la conclusion se suggère: il est triste de raconter des histoires sur les technologies fermées, mais certaines parties utiles peuvent être saisies.