Plus récemment, nous avons déjà
parlé de la nécessité de remplacer Equals et GetHashCode lors de la programmation en C #. Aujourd'hui, nous allons traiter des paramètres de performance des méthodes asynchrones. Rejoignez-nous maintenant!

Dans les deux derniers articles du blog msdn, nous avons examiné la
structure interne des méthodes asynchrones en C # et
les points d'extension que le compilateur C # fournit pour contrôler le comportement des méthodes asynchrones.
Sur la base des informations du premier article, le compilateur effectue de nombreuses transformations pour rendre la programmation asynchrone aussi similaire à synchrone que possible. Pour ce faire, il crée une instance de la machine d'état, la transmet au générateur de la méthode asynchrone, qui appelle l'objet attendant pour la tâche, etc. Bien sûr, une telle logique a un prix, mais combien cela nous coûte-t-il?
Jusqu'à l'apparition de la bibliothèque TPL, les opérations asynchrones n'étaient pas utilisées en si grande quantité, par conséquent, les coûts n'étaient pas élevés. Mais aujourd'hui, même une application relativement simple peut effectuer des centaines, voire des milliers, d'opérations asynchrones par seconde. La bibliothèque de tâches parallèles TPL a été créée avec une telle charge de travail à l'esprit, mais il n'y a pas de magie ici et vous devez payer pour tout.
Pour estimer les coûts des méthodes asynchrones, nous utiliserons un exemple légèrement modifié du premier article.
public class StockPrices { private const int Count = 100; private List<(string name, decimal price)> _stockPricesCache;
La classe
StockPrices en
StockPrices les cours des actions à partir d'une source externe et vous permet de les demander via l'API. La principale différence avec l'exemple du premier article est le passage d'un dictionnaire à une liste de prix. Afin d'estimer les coûts des différentes méthodes asynchrones par rapport aux méthodes synchrones, l'opération elle-même doit faire un certain travail, dans notre cas, c'est une recherche linéaire des cours boursiers.
La méthode
GetPricesFromCache intentionnellement construite autour d'une boucle simple pour éviter l'allocation de ressources.
Comparaison des méthodes synchrones et des méthodes asynchrones basées sur les tâches
Dans le premier test de performances, nous comparons la méthode asynchrone qui appelle la méthode d'initialisation asynchrone (
GetStockPriceForAsync ), la méthode synchrone qui appelle la méthode d'initialisation asynchrone (
GetStockPriceFor ) et la méthode synchrone qui appelle la méthode d'initialisation synchrone.
private readonly StockPrices _stockPrices = new StockPrices(); public SyncVsAsyncBenchmark() {
Les résultats sont présentés ci-dessous:

Déjà à ce stade, nous avons reçu des données assez intéressantes:
- La méthode asynchrone est assez rapide.
GetPricesForAsync s'exécute de manière synchrone dans ce test et est environ 15% (*) plus lent que la méthode purement synchrone. - La méthode
GetPricesFor synchrone, qui appelle la méthode asynchrone InitializeMapIfNeededAsync , a des coûts encore plus bas, mais le plus surprenant, elle n'alloue pas de ressources du tout (dans la colonne allouée du tableau ci-dessus, elle coûte 0 pour GetPricesDirectlyFromCache et GetStockPriceFor ).
(*) Bien sûr, on ne peut pas dire que les coûts d'exécution synchrone de la méthode asynchrone sont de 15% pour tous les cas possibles. Cette valeur dépend directement de la charge de travail effectuée par la méthode. La différence entre les frais généraux d'une invocation pure d'une méthode asynchrone (qui ne fait rien) et d'une méthode synchrone (qui ne fait rien) sera énorme. L'idée de ce test comparatif est de montrer que les coûts de la méthode asynchrone, qui effectue un travail relativement faible, sont relativement faibles.Comment se fait-il que lorsque vous appelez
InitializeMapIfNeededAsync , les ressources ne soient pas allouées du tout? Dans le premier article de cette série, j'ai mentionné qu'une méthode asynchrone devait allouer au moins un objet dans l'en-tête géré - l'instance de tâche elle-même. Discutons ce point plus en détail.
Optimisation n ° 1: mise en cache des instances de tâche lorsque cela est possible
La réponse à la question ci-dessus est très simple:
AsyncMethodBuilder utilise une instance de la tâche pour chaque opération asynchrone terminée avec succès . La méthode asynchrone
AsyncMethodBuilder par
Task utilise
AsyncMethodBuilder avec la logique suivante dans la méthode
SetResult :
La méthode
SetResult appelée uniquement pour les méthodes asynchrones terminées avec succès et un
résultat réussi pour chaque méthode basée sur les Task peut être librement utilisé ensemble . Nous pouvons même retracer ce comportement avec le test suivant:
[Test] public void AsyncVoidBuilderCachesResultingTask() { var t1 = Foo(); var t2 = Foo(); Assert.AreSame(t1, t2); async Task Foo() { } }
Mais ce n'est pas la seule optimisation possible.
AsyncTaskMethodBuilder<T> optimise le travail d'une manière similaire: il met en cache les tâches pour
Task<bool> et certains autres types simples. Par exemple, il met en cache toutes les valeurs par défaut pour un groupe de types entiers et utilise un cache spécial pour la
Task<int> , en plaçant des valeurs de la plage [-1; 9] (pour plus de détails, voir
AsyncTaskMethodBuilder<T>.GetTaskForResult() ).
Ceci est confirmé par le test suivant:
[Test] public void AsyncTaskBuilderCachesResultingTask() {
Ne vous fiez pas trop à un tel comportement , mais il est toujours agréable de se rendre compte que les créateurs du langage et de la plateforme font tout leur possible pour augmenter la productivité de toutes les manières disponibles. La mise en cache des tâches est une méthode d'optimisation populaire qui est également utilisée dans d'autres domaines. Par exemple, une nouvelle implémentation de
Socket dans le référentiel
corefx repo utilise largement cette méthode et applique
les tâches mises en cache dans la mesure du possible.
Optimisation n ° 2: utilisation de ValueTask
La méthode d'optimisation décrite ci-dessus ne fonctionne que dans quelques cas. Par conséquent, au lieu de cela, nous pouvons utiliser
ValueTask<T> (**), un type spécial de valeur similaire à la tâche; il n'allouera pas de ressources si la méthode s'exécute de manière synchrone.
ValueTask<T> est une combinaison distincte de
T et
Task<T> : si la "valeur-tâche" est terminée, alors la valeur de base sera utilisée. Si l'allocation de base n'a pas encore été épuisée, des ressources seront allouées à la tâche.
Ce type spécial permet d'éviter un provisionnement de segment de mémoire excessif lors de l'exécution d'une opération de manière synchrone. Pour utiliser
ValueTask<T> , vous devez modifier le type de retour pour
GetStockPriceForAsync : au lieu de
Task<decimal> spécifier
ValueTask<decimal> :
public async ValueTask<decimal> GetStockPriceForAsync(string companyId) { await InitializeMapIfNeededAsync(); return DoGetPriceFromCache(companyId); }
Nous pouvons maintenant évaluer la différence à l'aide d'un test comparatif supplémentaire:
[Benchmark] public decimal GetStockPriceWithValueTaskAsync_Await() { return _stockPricesThatYield.GetStockPriceValueTaskForAsync("MSFT").GetAwaiter().GetResult(); }
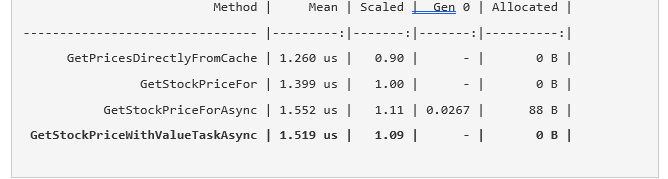
Comme vous pouvez le voir, la version avec
ValueTask n'est que légèrement plus rapide que la version avec Task. La principale différence est que l'allocation de segments de mémoire est empêchée. Dans une minute, nous discuterons de la faisabilité d'une telle transition, mais avant cela, je voudrais parler d'une optimisation délicate.
Optimisation n ° 3: abandonner les méthodes asynchrones dans un chemin commun
Si vous utilisez très souvent une méthode asynchrone et souhaitez réduire les coûts encore plus, je vous suggère l'optimisation suivante: supprimez le modificateur async, puis vérifiez l'état de la tâche à l'intérieur de la méthode et effectuez l'opération entière de manière synchrone, abandonnant complètement les approches asynchrones.
Ça a l'air compliqué? Prenons un exemple.
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized(string companyId) { var task = InitializeMapIfNeededAsync();
Dans ce cas, le modificateur
async n'est pas utilisé dans la méthode
GetStockPriceWithValueTaskAsync_Optimized , donc lorsqu'il reçoit une tâche de la méthode
InitializeMapIfNeededAsync , il vérifie son état d'exécution. Si la tâche est terminée, la méthode utilise simplement
DoGetPriceFromCache pour obtenir immédiatement le résultat. Si la tâche d'initialisation est toujours en cours, la méthode appelle une fonction locale et attend les résultats.
L'utilisation d'une fonction locale n'est pas la seule, mais l'un des moyens les plus simples. Mais il y a une mise en garde. Lors de l'implémentation la plus naturelle, la fonction locale recevra un état externe (variable locale et argument):
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized2(string companyId) {
Mais, malheureusement, en raison d'
une erreur de compilation, ce code générera une fermeture, même si la méthode est exécutée dans le chemin commun. Voici à quoi ressemble cette méthode de l'intérieur:
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized(string companyId) { var closure = new __DisplayClass0_0() { __this = this, companyId = companyId, task = InitializeMapIfNeededAsync() }; if (closure.task.IsCompleted) { return ... }
Comme indiqué dans l'article
Dissection des fonctions locales en C # , le compilateur utilise une instance commune de fermeture pour toutes les variables et arguments locaux dans une zone spécifique. Par conséquent, il y a un certain sens dans une telle génération de code, mais cela rend toute la lutte avec l'allocation de tas inutile.
CONSEIL . Une telle optimisation est une chose très insidieuse. Les avantages sont négligeables et même si vous écrivez la fonction locale d'origine
correcte , vous pouvez accidentellement obtenir un état externe qui provoque l'allocation du tas. Vous pouvez toujours recourir à l'optimisation si vous travaillez avec une bibliothèque couramment utilisée (par exemple, BCL) dans une méthode qui sera certainement utilisée sur une section de code chargée.
Coûts associés à l'attente d'une tâche
Pour le moment, nous n'avons considéré qu'un seul cas spécifique: la surcharge d'une méthode asynchrone qui s'exécute de manière synchrone. Cela se fait exprès. Plus la méthode asynchrone est petite, plus les coûts de ses performances globales sont visibles. En règle générale, les méthodes asynchrones plus détaillées s'exécutent de manière synchrone et effectuent une charge de travail plus petite. Et nous les appelons généralement plus souvent.
Mais il faut être conscient des coûts du mécanisme asynchrone lorsque la méthode «attend» l'achèvement d'une tâche en suspens. Pour estimer ces coûts, nous apporterons des modifications à
InitializeMapIfNeededAsync et appellerons
Task.Yield() même lorsque le cache est initialisé:
private async Task InitializeMapIfNeededAsync() { if (_stockPricesCache != null) { await Task.Yield(); return; }
Nous ajoutons les méthodes suivantes à notre package de référence pour les tests comparatifs:
[Benchmark] public decimal GetStockPriceFor_Await() { return _stockPricesThatYield.GetStockPriceFor("MSFT"); } [Benchmark] public decimal GetStockPriceForAsync_Await() { return _stockPricesThatYield.GetStockPriceForAsync("MSFT").GetAwaiter().GetResult(); } [Benchmark] public decimal GetStockPriceWithValueTaskAsync_Await() { return _stockPricesThatYield.GetStockPriceValueTaskForAsync("MSFT").GetAwaiter().GetResult(); }

Comme vous pouvez le voir, la différence est palpable - à la fois en termes de vitesse et en termes d'utilisation de la mémoire. Expliquez brièvement les résultats.
- Chaque opération d'attente pour une tâche inachevée prend environ 4 microsecondes et alloue près de 300 octets (**) pour chaque appel. C'est pourquoi GetStockPriceFor s'exécute presque deux fois plus vite que GetStockPriceForAsync et alloue moins de mémoire.
- Une méthode asynchrone basée sur ValueTask prend un peu plus de temps que la variante avec Task, lorsque cette méthode n'est pas exécutée de manière synchrone. Une machine d'état d'une méthode basée sur ValueTask <T> doit stocker plus de données qu'une machine d'état d'une méthode basée sur Task <T>.
(**) Cela dépend de la plateforme (x64 ou x86) et d'un certain nombre de variables et d'arguments locaux de la méthode asynchrone.Performances de la méthode asynchrone 101
- Si la méthode asynchrone s'exécute de manière synchrone, la surcharge est assez petite.
- Si la méthode asynchrone est exécutée de manière synchrone, la surcharge de mémoire suivante se produit: pour les méthodes de tâche asynchrone, il n'y a pas de surcharge et pour les méthodes de tâche async <T>, le dépassement est de 88 octets par opération (pour les plates-formes x64).
- ValueTask <T> élimine la surcharge susmentionnée pour les méthodes asynchrones exécutées de manière synchrone.
- Lorsqu'une méthode asynchrone basée sur ValueTask <T> est exécutée de manière synchrone, cela prend un peu moins de temps que la méthode avec Task <T>, sinon il y a de légères différences en faveur de la deuxième option.
- La surcharge de performances pour les méthodes asynchrones en attente de terminer une tâche inachevée est nettement plus élevée (environ 300 octets par opération pour les plates-formes x64).
Bien sûr, les mesures sont notre tout. Si vous voyez qu'une opération asynchrone cause des problèmes de performances, vous pouvez basculer de la
Task<T> vers
ValueTask<T> , mettre en cache la tâche ou rendre le chemin d'exécution global synchrone, si possible. Vous pouvez également essayer d'agréger vos opérations asynchrones. Cela permettra d'améliorer les performances, de simplifier le débogage et l'analyse de code en général.
Tous les petits morceaux de code ne doivent pas être asynchrones.