Démonstration de l'utilisation d'outils open source tels que Packer et Terraform pour apporter en permanence des modifications d'infrastructure aux environnements cloud préférés des utilisateurs.
Le matériel était basé sur une présentation de Paul Stack lors de notre conférence d'automne
DevOops 2017. Paul est un développeur d'infrastructure qui travaillait chez HashiCorp et a participé au développement d'outils utilisés par des millions de personnes (par exemple, Terraform). Il s'exprime souvent lors de conférences et transmet des pratiques à l'avant-garde des implémentations CI / CD, les principes de la bonne organisation de la partie opérations, et est capable d'expliquer clairement pourquoi les administrateurs le font. Le reste de l'article est raconté à la première personne.
Commençons donc tout de suite par quelques constatations clés.
Le serveur de longue durée est nul

J'ai précédemment travaillé dans une organisation où nous avons déployé Windows Server 2003 en 2008, et aujourd'hui, ils sont toujours en production. Et une telle entreprise n'est pas seule. À l'aide du bureau à distance sur ces serveurs, ils installent le logiciel manuellement, téléchargeant des fichiers binaires depuis Internet. C'est une très mauvaise idée, car les serveurs ne sont pas typiques. Vous ne pouvez pas garantir que la même chose se produit en production que dans votre environnement de développement, dans l'environnement intermédiaire, dans l'environnement QA.
Infrastructure immuable
En 2013, un article est paru sur le blog de Chad Foiler intitulé «Jetez vos serveurs et gravez votre code: infrastructure immuable et composants jetables» (Chad Foiler
« Déposez
vos serveurs et gravez votre code: infrastructure immuable et composants jetables» ). Il s'agit principalement d'une conversation selon laquelle une infrastructure immuable est la voie à suivre. Nous avons créé l'infrastructure et si nous devons la changer, nous créons une nouvelle infrastructure. Cette approche est très courante dans le cloud, car ici, elle est rapide et bon marché. Si vous avez des centres de données physiques, c'est un peu plus compliqué. De toute évidence, si vous exécutez la virtualisation du centre de données, les choses deviennent plus faciles. Cependant, si vous démarrez toujours des serveurs physiques à chaque fois, il faut un peu plus de temps pour en entrer un nouveau que pour en modifier un existant.
Infrastructure jetable
Selon les programmeurs fonctionnels, «immuable» est en fait le mauvais terme pour désigner ce phénomène. Parce que pour être vraiment immuable, votre infrastructure a besoin d'un système de fichiers en lecture seule: aucun fichier ne sera écrit localement, personne ne pourra utiliser SSH ou RDP, etc. Ainsi, il semble qu'en fait l'infrastructure ne soit pas immuable.
La terminologie a été discutée sur Twitter pendant six ou même huit jours par plusieurs personnes. En fin de compte, ils ont convenu qu'une «infrastructure ponctuelle» est une formulation plus appropriée. Lorsque le cycle de vie d'une «infrastructure ponctuelle» prend fin, il peut être facilement détruit. Vous n'avez pas besoin de vous y accrocher.
Je vais faire une analogie. Les vaches d'élevage ne sont généralement pas considérées comme des animaux de compagnie.

Lorsque vous avez du bétail à la ferme, vous ne leur donnez pas de noms individuels. Chaque individu a un numéro et une étiquette. Il en va de même pour les serveurs. Si vous avez toujours créé des serveurs manuellement en production en 2006, ils ont des noms importants, par exemple, «Base de données SQL sur la production 01». Et ils ont une signification très spécifique. Et si l'un des serveurs tombe en panne, l'enfer commence.
Si l'un des animaux du troupeau meurt, l'agriculteur en achète simplement un nouveau. Il s'agit de «l'infrastructure ponctuelle».
Livraison continue
Alors, comment combinez-vous cela avec la livraison continue?
Tout ce dont je parle maintenant existe depuis un certain temps. J'essaie simplement de combiner les idées de développement d'infrastructure et de développement logiciel.
Les développeurs de logiciels se sont depuis longtemps engagés à fournir et à intégrer en permanence. Par exemple, Martin Fowler a écrit sur l'intégration continue sur son blog au début des années 2000. Jez Humble a longtemps promu la livraison continue.
Si vous regardez de plus près, rien n'est créé spécifiquement pour le code source du logiciel. Il existe une définition standard de Wikipédia:
la livraison continue est un ensemble de pratiques et de principes visant à créer, tester et publier des logiciels le plus rapidement possible .
La définition ne signifie pas les applications Web ou les API, il s'agit de logiciels en général. La création d'un logiciel de puzzle nécessite de nombreuses pièces de puzzle. De cette façon, vous pouvez pratiquer la livraison continue du code d'infrastructure de la même manière.
Le développement de l'infrastructure et des applications sont des directions assez proches. Et les personnes qui écrivent du code d'application écrivent également du code d'infrastructure (et vice versa). Ces mondes commencent à s'unir. Il n'y a plus une telle séparation et les pièges spécifiques de chacun des mondes.
Principes et pratiques de livraison continue
La livraison continue a un certain nombre de principes:
- Le processus de lancement / déploiement du logiciel doit être reproductible et fiable.
- Automatisez tout!
- Si une procédure est difficile ou douloureuse, faites-la plus souvent.
- Gardez tout sous contrôle de source.
- Terminé - signifie «non publié».
- Intégrez le travail à la qualité!
- Tout le monde est responsable du processus de publication.
- Augmentez la continuité.
Mais plus important encore, la livraison continue a quatre pratiques. Prenez-les et transférez-les directement dans l'infrastructure:
- Créez des fichiers binaires une seule fois. Créez votre serveur une fois. Ici, nous parlons de «jetabilité» depuis le tout début.
- Utilisez le même mécanisme de déploiement dans chaque environnement. Ne pratiquez pas différents déploiements en développement et en production. Vous devez utiliser le même chemin dans chaque environnement. C'est très important.
- Testez votre déploiement. J'ai créé de nombreuses applications. J'ai créé beaucoup de problèmes car je n'ai pas suivi le mécanisme de déploiement. Vous devez toujours vérifier ce qui se passe. Et je ne dis pas que vous devriez passer cinq ou six heures sur un test à grande échelle. Assez "test de fumée". Vous avez un élément clé du système qui, comme vous le savez, vous permet, à vous et à votre entreprise, de gagner de l'argent. Ne soyez pas trop paresseux pour commencer les tests. Sinon, il peut y avoir des interruptions qui coûteront de l'argent à votre entreprise.
- Et enfin, la chose la plus importante. Si quelque chose se casse, arrêtez-vous et réparez-le immédiatement! Vous ne pouvez pas laisser le problème s'aggraver et empirer de plus en plus. Vous devez le réparer. C'est vraiment important.
Quelqu'un a-t-il lu le livre
Livraison continue ?

Je suis sûr que vos entreprises vous en paieront une copie que vous pourrez transférer au sein de l'équipe. Je ne dis pas que vous devriez vous asseoir et passer une journée libre à le lire. Si vous le faites, vous voudrez probablement quitter l'informatique. Mais je recommande de maîtriser périodiquement de petits morceaux du livre, de les digérer et de réfléchir à la façon de les transférer dans votre environnement, votre culture et votre processus. Un petit morceau à la fois. Parce que l'approvisionnement continu est une conversation sur l'amélioration continue. Ce n'est pas seulement de s'asseoir au bureau avec des collègues et le patron et d'entamer une conversation avec la question: «Comment allons-nous mettre en œuvre la livraison continue?», Puis écrivez 10 choses au tableau et après 10 jours, comprenez que vous l'avez mise en œuvre. Cela prend beaucoup de temps, provoque beaucoup de protestations, car avec l'introduction des changements de culture.
Aujourd'hui, nous utiliserons deux outils: Terraform et Packer (les deux sont des développements Hashicorp). Une autre discussion portera sur les raisons pour lesquelles nous devrions utiliser Terraform et comment l'intégrer dans notre environnement. Ce n'est pas par hasard que je parle de ces deux outils. Jusqu'à récemment, j'ai également travaillé chez Hashicorp. Mais même après avoir quitté Hashicorp, je continue de contribuer au code de ces outils, car je les trouve réellement très utiles.
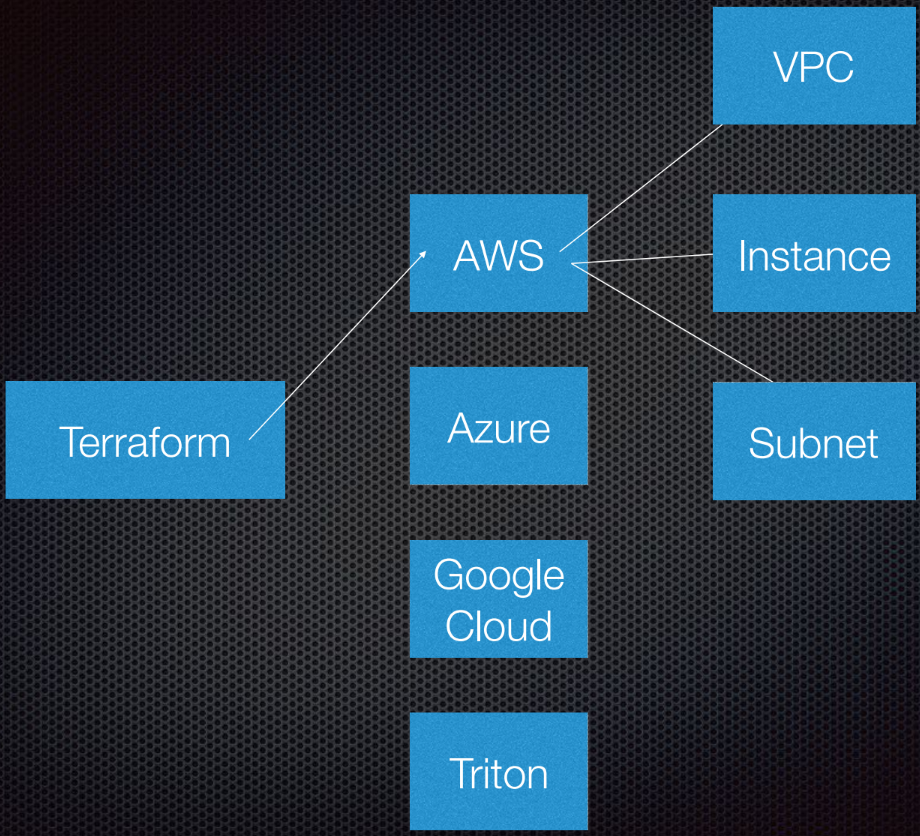
Terraform prend en charge l'interaction avec les fournisseurs. Les fournisseurs sont les clouds, les services Saas, etc.
Au sein de chaque fournisseur de services cloud, il existe plusieurs ressources, telles qu'un sous-réseau, un VPC, un équilibreur de charge, etc. En utilisant DSL (langage spécifique au domaine), vous indiquez à Terraform à quoi ressemblera votre infrastructure.
Terraform utilise la théorie des graphes.

Vous connaissez probablement la théorie des graphes. Les nœuds font partie de notre infrastructure, tels qu'un équilibreur de charge, un sous-réseau ou un VPC. Les nervures sont les relations entre ces systèmes. C'est tout ce que je considère personnellement nécessaire de savoir sur la théorie des graphes pour utiliser Terraform. Nous laissons le reste aux experts.

Terraform utilise en fait un graphe orienté car il connaît non seulement les relations, mais aussi leur ordre: que A (supposons que A est un VPC) doit être défini sur B, qui est un sous-réseau. Et B doit être créé avant C (instance), car il existe une procédure prescrite pour créer des abstractions dans Amazon ou tout autre cloud.
Plus d'informations sur ce sujet sont disponibles sur
YouTube par Paul Hinze, qui est toujours directeur de l'infrastructure chez Hashicorp. Par référence - une grande conversation sur l'infrastructure et la théorie des graphes.
Pratique
Écrire un code est bien mieux que discuter d'une théorie.
J'ai précédemment créé AMI (Amazon Machine Images). J'utilise Packer pour les créer et je vais vous montrer comment le faire.
AMI est une instance d'un serveur virtuel sur Amazon, elle est prédéfinie (en termes de configuration, d'applications, etc.) et est créée à partir d'une image. J'adore pouvoir créer de nouvelles AMI. Essentiellement, les AMI sont mes conteneurs Docker.
Donc, j'ai AMI, ils ont une pièce d'identité. En allant à l'interface Amazon, nous voyons que nous n'avons qu'une seule AMI et rien de plus:

Je peux vous montrer ce qu'il y a dans cette AMI. Tout est très simple.
J'ai un modèle de fichier JSON:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] }
Nous avons des variables que nous transmettons, et Packer a une liste de soi-disant constructeurs pour différents domaines; il y en a beaucoup. Builder utilise une source AMI spéciale, à laquelle je transmets un identifiant AMI. Je lui donne le nom d'utilisateur et le mot de passe SSH, et indique également s'il a besoin d'une adresse IP publique pour que les gens puissent y accéder de l'extérieur. Dans notre cas, cela n'a pas vraiment d'importance, car il s'agit d'une instance AWS pour Packer.
Nous avons également défini le nom et les balises AMI.
Vous n'êtes pas obligé d'analyser ce code. Il n'est là que pour vous montrer comment il travaille. La partie la plus importante ici est la version. Cela deviendra pertinent plus tard lorsque nous entrerons dans Terraform.
Une fois que le générateur a appelé l'instance, les agents de provisionnement y sont lancés. En fait, j'installe NCP et nginx pour vous montrer ce que je peux faire ici. Je copie des fichiers et j'installe simplement la configuration de nginx. Tout est très simple. Ensuite, j'active nginx pour qu'il démarre au démarrage de l'instance.
Donc, j'ai un serveur d'applications et ça marche. Je peux l'utiliser à l'avenir. Cependant, je vérifie toujours mes modèles Packer. Parce que c'est une configuration JSON où vous pouvez rencontrer des problèmes.
Pour ce faire, j'exécute la commande:
make validate
J'obtiens la réponse que le modèle Packer a été vérifié avec succès:
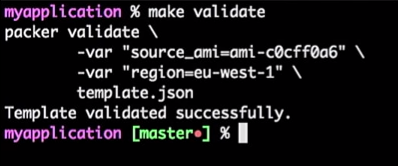
Ceci est juste une commande, donc je peux le connecter à l'outil CI (n'importe qui). En fait, ce sera un processus: si le développeur modifie le modèle, la demande d'extraction est générée, l'outil CI vérifie la demande, effectue l'équivalent de la vérification du modèle et publie le modèle en cas de vérification réussie. Tout cela peut être combiné dans le "Master".
Nous obtenons un flux pour les modèles AMI - il vous suffit d'augmenter la version.
Supposons que le développeur ait créé une nouvelle version d'AMI.
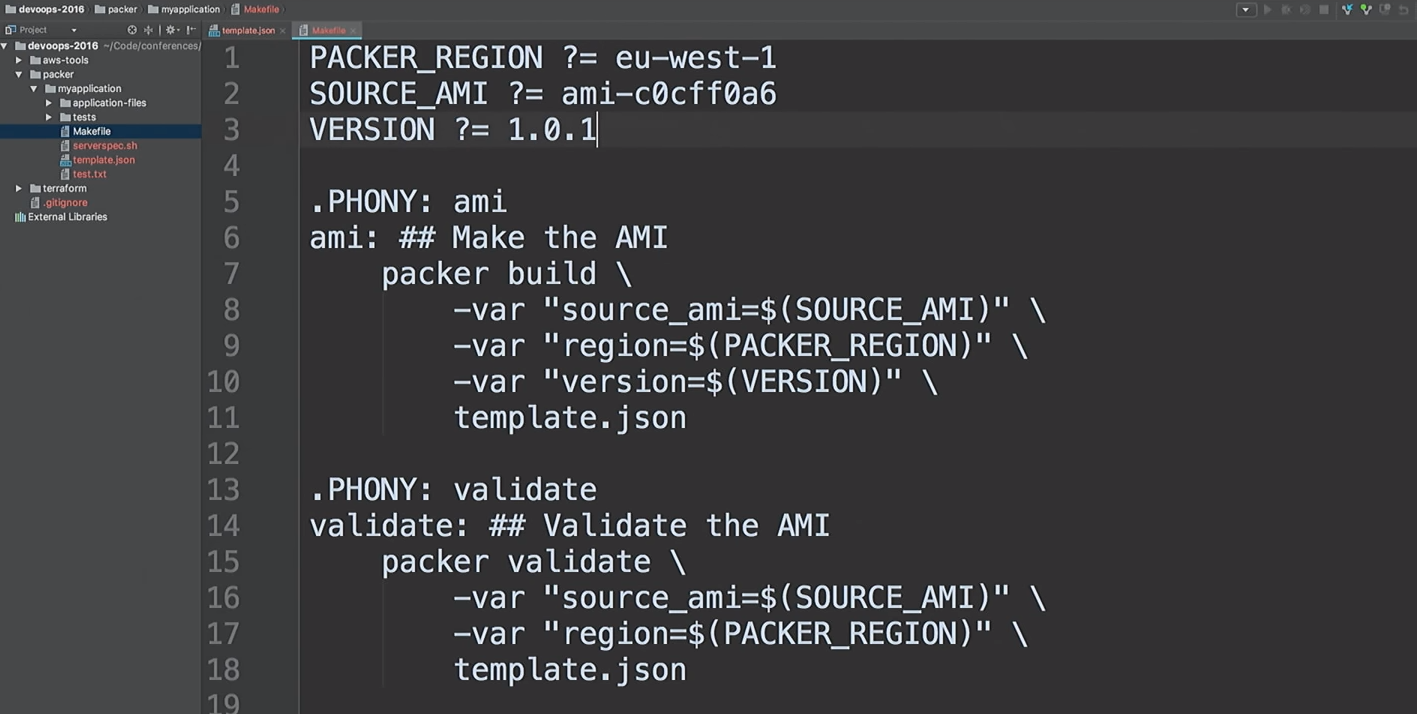
Je vais juste corriger la version dans les fichiers de 1.0.0 à 1.0.1 pour vous montrer la différence:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html>
Je reviendrai sur la ligne de commande et commencerai la création d'AMI.
Je n'aime pas diriger les mêmes équipes. J'aime créer rapidement AMI, donc j'utilise des makefiles. Jetons un coup d'oeil avec
cat dans mon makefile:
cat Makefile

Ceci est mon makefile. J'ai même fourni de l'aide: je tape
make et je clique sur l'onglet, et ça me montre toute la cible.

Nous allons donc créer une nouvelle version AMI 1.0.1.
make ami

Revenons à Terraform.
J'insiste sur le fait qu'il ne s'agit pas d'un code de production. Ceci est une démonstration. Il existe des moyens de faire mieux la même chose.
J'utilise des modules Terraform partout. Comme je ne travaille plus sur Hashicorp, je peux donc exprimer mon opinion sur les modules. Pour moi, les modules sont au niveau de l'encapsulation. Par exemple, j'aime encapsuler tout ce qui concerne le VPC: réseaux, sous-réseaux, tables de routage, etc.
Que se passe-t-il à l'intérieur? Les développeurs qui travaillent avec cela peuvent ne pas s'en soucier. Ils doivent avoir une compréhension de base du fonctionnement du cloud, de ce qu'est un VPC. Mais il n'est pas nécessaire de se plonger dans les détails. Seules les personnes qui ont vraiment besoin de changer un module doivent le comprendre.
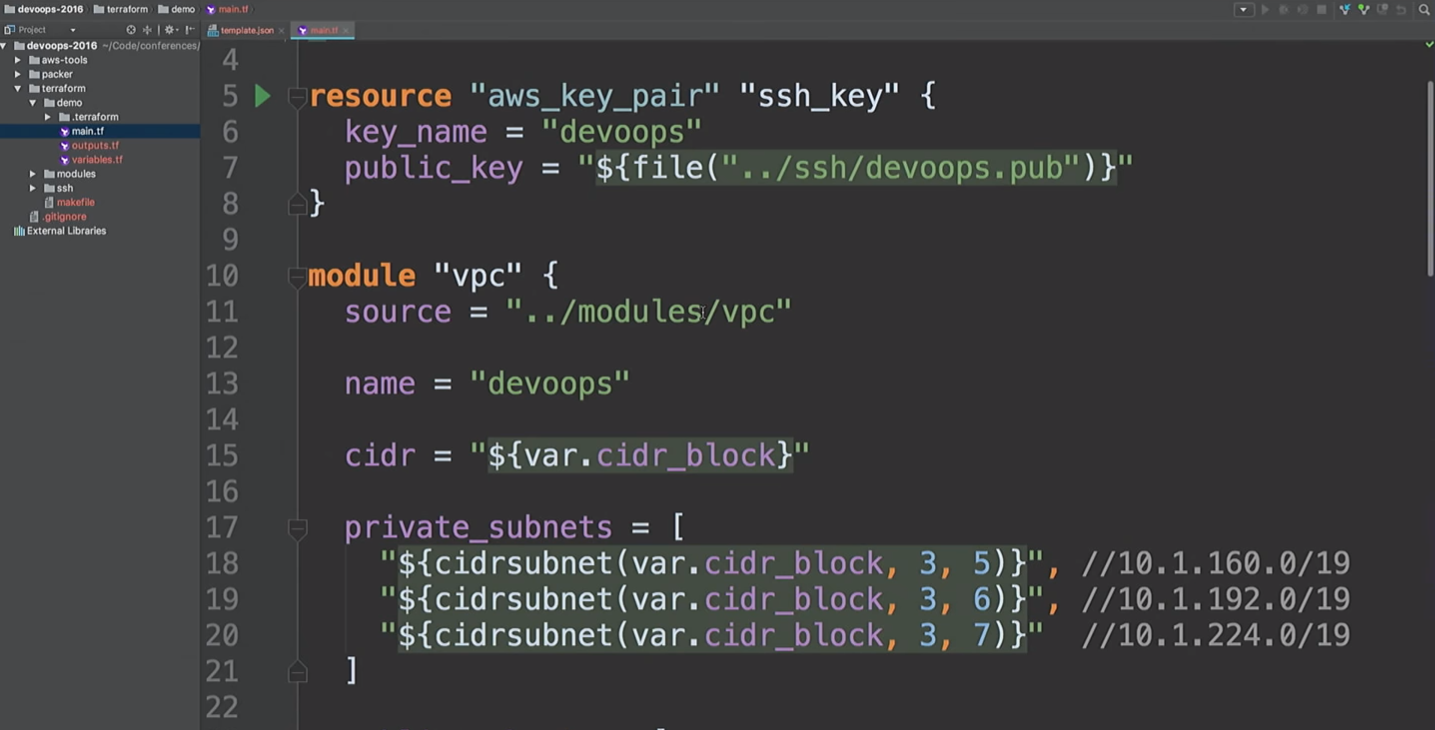

Ici, je vais créer une ressource AWS et un module VPC. Que se passe-t-il ici? Prenez
cidr_block niveau
cidr_block et créez trois sous-réseaux privés et trois sous-réseaux publics. Voici une liste des zones de disponibilité. Mais nous ne savons pas quelles sont ces zones d'accessibilité.

Nous allons créer un VPN. N'utilisez simplement pas ce module VPN. C'est openVPN, qui crée une instance AWS qui n'a pas de certificat. Il utilise uniquement l'adresse IP publique et n'est mentionné ici que pour vous montrer que nous pouvons nous connecter au VPN. Il existe des outils plus pratiques pour créer un VPN. Il m'a fallu environ 20 minutes et deux bières pour écrire la mienne.
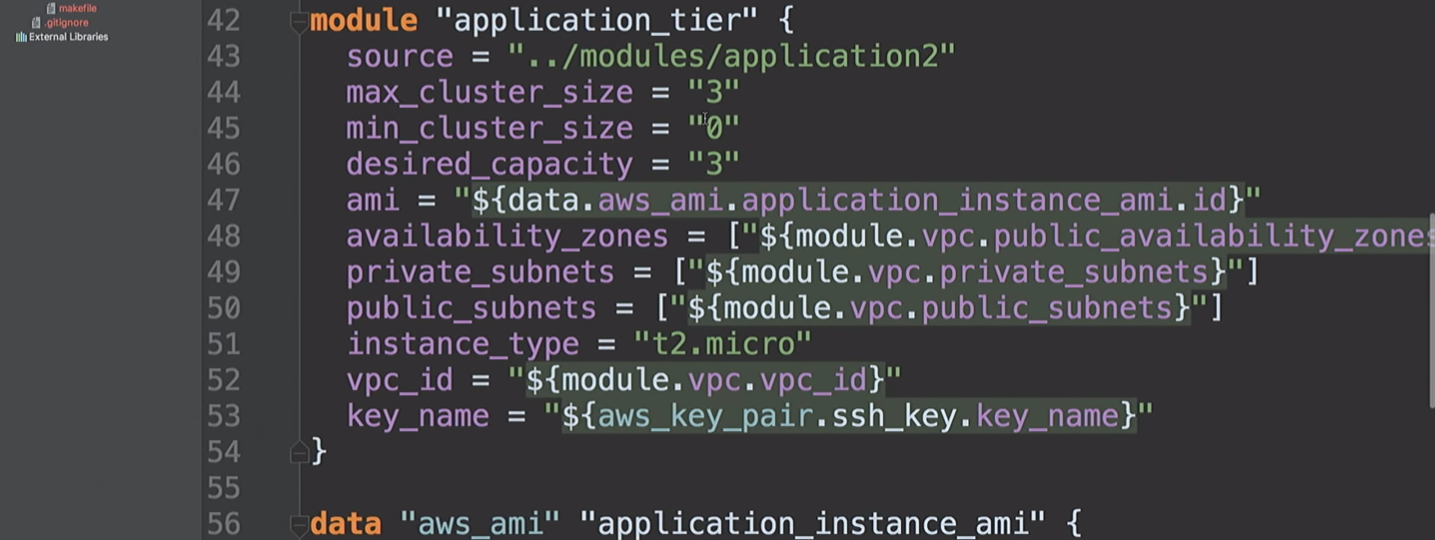


Ensuite, nous créons un
application_tier , qui est un groupe de mise à l'échelle automatique - un équilibreur de charge. Certaines configurations de démarrage sont basées sur AMI-ID, et combinent plusieurs sous-réseaux et zones de disponibilité, et utilisent également une clé SSH.
Revenons à cela dans une seconde.
J'ai déjà mentionné les zones de disponibilité. Ils diffèrent pour différents comptes AWS. Mon compte aux États-Unis dans l'Est peut avoir accès aux zones A, B et D. Votre compte AWS peut avoir accès à B, C et E. Ainsi, en fixant ces valeurs dans le code, nous rencontrerons des problèmes. Chez Hashicorp, nous avons suggéré de créer de telles sources de données afin de demander à Amazon ce qui était disponible pour nous. Sous le capot, nous demandons une description des zones de disponibilité, puis renvoyons une liste de toutes les zones pour votre compte. Grâce à cela, nous pouvons utiliser des sources de données pour AMI.
Nous arrivons maintenant au bas de ma démonstration. J'ai créé un groupe de mise à l'échelle automatique dans lequel trois instances sont en cours d'exécution. Par défaut, ils ont tous la version 1.0.0.
Lorsque nous déploierons la nouvelle version d'AMI, je recommencerai la configuration Terraform, cela changera la configuration de lancement, et le nouveau service recevra la prochaine version du code, etc. Et nous pouvons la contrôler.

Nous voyons que Packer est terminé et nous avons une nouvelle AMI.
Je retourne sur Amazon, rafraîchis la page et vois une deuxième AMI.

Revenons à Terraform.
À partir de la version 0.10, Terraform a divisé les fournisseurs en référentiels distincts. Et la commande
init terraform obtient une copie du fournisseur nécessaire à l'exécution.

Fournisseurs chargés. Nous sommes prêts à aller de l'avant.
Ensuite, nous devons exécuter
terraform get - charger les modules nécessaires. Ils sont maintenant sur ma machine locale. Terraform récupérera donc tous les modules localement. En général, les modules peuvent être stockés dans leurs propres référentiels sur GitHub ou ailleurs. C'est pourquoi j'ai parlé du module VPC. Vous pouvez donner à l'équipe du réseau un accès pour effectuer des modifications. Et c'est l'API pour l'équipe de développement pour travailler avec eux. Vraiment utile.
L'étape suivante consiste à créer un graphique.
Commencez avec
terraform plan

Terraform prendra l'état local actuel et le comparera avec le compte AWS, indiquant les différences. Dans notre cas, il créera 35 nouvelles ressources.
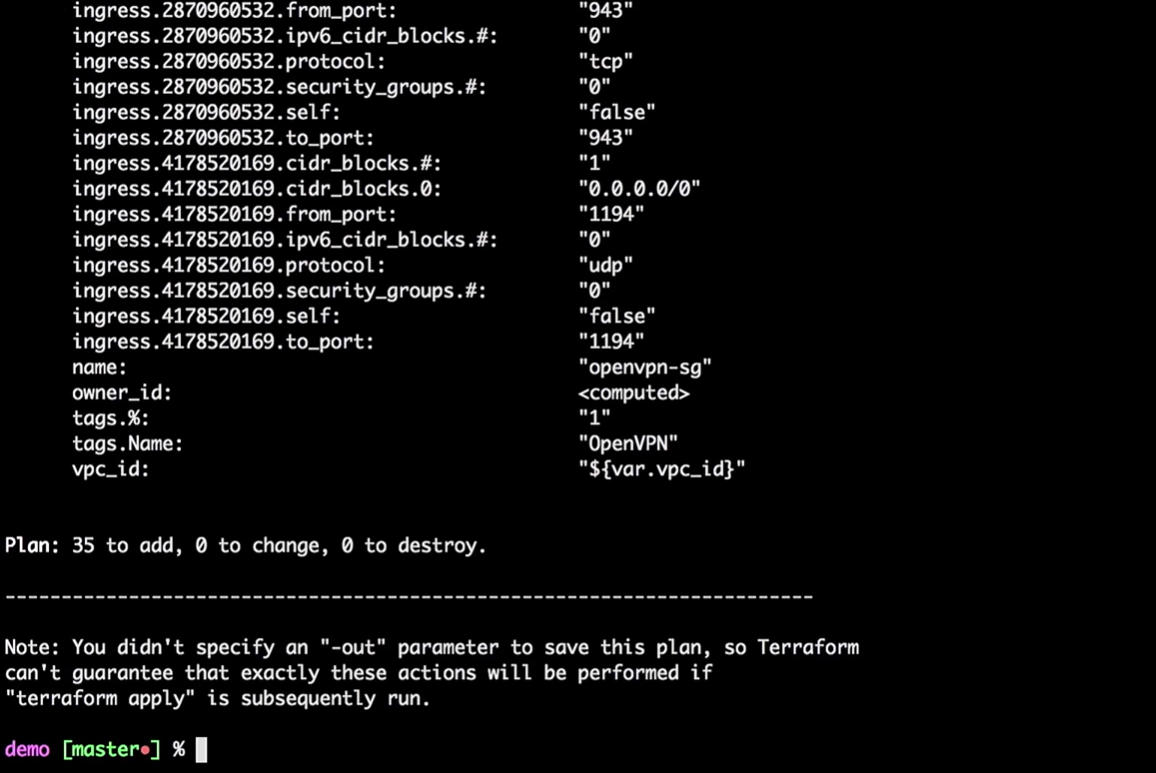
Maintenant, nous appliquons les modifications:
terraform apply
Vous n'avez pas à faire tout cela depuis la machine locale. Ce ne sont que des commandes, passant des variables à Terraform. Vous pouvez porter ce processus sur les outils CI.
Si vous souhaitez le déplacer vers CI, vous devez utiliser l'état distant. J'aimerais que tous ceux qui utilisent Terraform travaillent avec un état distant. Veuillez ne pas utiliser l'état local.
Un de mes amis a noté que même après toutes ces années de travail avec Terraform, il découvre encore quelque chose de nouveau. Par exemple, si vous créez une instance AWS, vous devez lui fournir un mot de passe et il peut l'enregistrer dans votre état. Lorsque j'ai travaillé chez Hashicorp, nous avons supposé qu'il y aurait un processus collaboratif qui changerait ce mot de passe. Par conséquent, n'essayez pas de tout stocker localement. Et puis, vous pouvez mettre tout cela dans les outils CI.
Donc, l'infrastructure est créée pour moi.

Terraform peut construire un graphique:
terraform graph
Comme je l'ai dit, il construit un arbre. En fait, cela vous donne la possibilité d'évaluer ce qui se passe dans votre infrastructure. Il vous montrera la relation entre toutes les différentes parties - tous les nœuds et les bords. Puisque les connexions ont des directions, nous parlons d'un graphe orienté.
Le graphique sera une liste JSON qui peut être enregistrée dans un fichier PNG ou DOC.
Revenons à Terraform. Nous créons vraiment un groupe de mise à l'échelle automatique.

Le groupe de mise à l'échelle automatique a une capacité de 3.

Une question intéressante: pouvons-nous utiliser Vault pour gérer les secrets dans Terraform? Hélas, non. Il n'y a pas de source de données Vault pour lire les secrets dans Terraform. Il existe d'autres façons, telles que les variables d'environnement. Avec leur aide, vous n'avez pas besoin d'entrer de secrets dans le code; vous pouvez les lire en tant que variables d'environnement.
Nous avons donc quelques infrastructures:
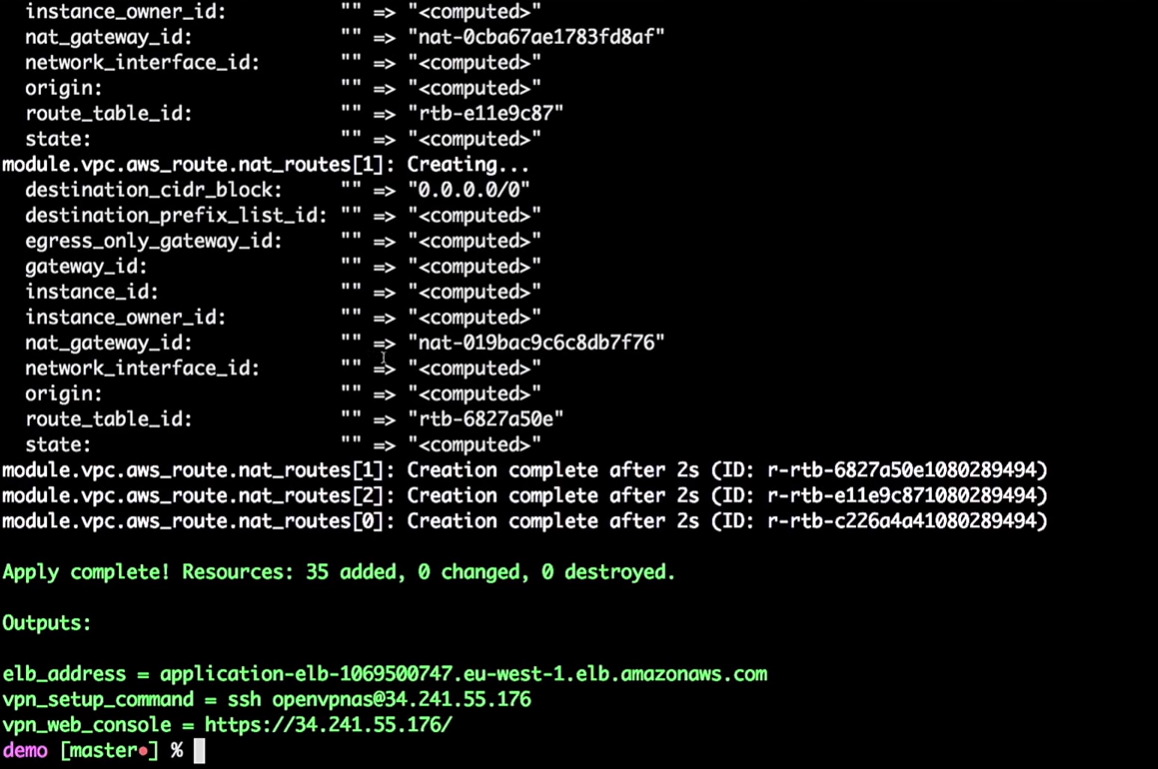
J'entre dans mon VPN très secret (ne craquez pas mes VPN).
La chose la plus importante ici est que nous avons trois instances de la demande. Certes, j'aurais dû noter quelle version de l'application s'exécute sur eux. C'est très important.
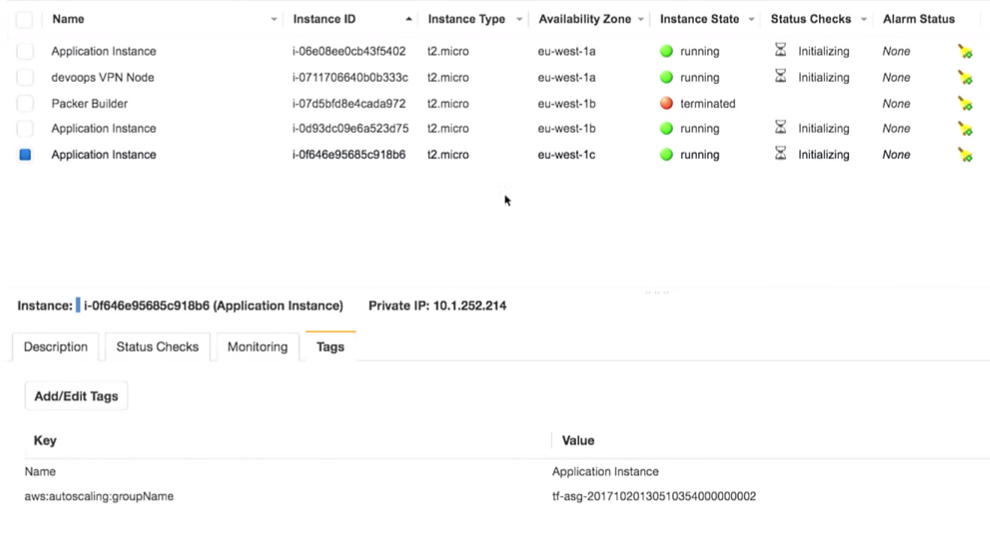
Tout est vraiment derrière le VPN:

Si je prends ceci (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) et le colle dans la barre d'adresse du navigateur, j'obtiens ce qui suit:

Permettez-moi de vous rappeler que je suis connecté à un VPN. Si je me déconnecte, l'adresse spécifiée ne sera pas disponible.
Nous voyons la version 1.0.0. Et peu importe combien nous actualisons la page, nous obtenons 1.0.0.
Que se passe-t-il si je change la version 1.0.0 en 1.0.1 dans le code?
filter { name = "tag:Version" values = ["1.0.1"] }
De toute évidence, les outils CI vous assureront de créer la bonne version.
Je ne note aucune mise à jour manuelle! Nous sommes imparfaits, nous faisons des erreurs et nous pouvons mettre la version 1.0.6 au lieu de 1.0.1 lors de la mise à jour manuelle.
filter { name = "tag:Version" values = ["1.0.6"] }
Mais passons à notre version (1.0.1).
terraform plan
Terraform met à jour l'état:
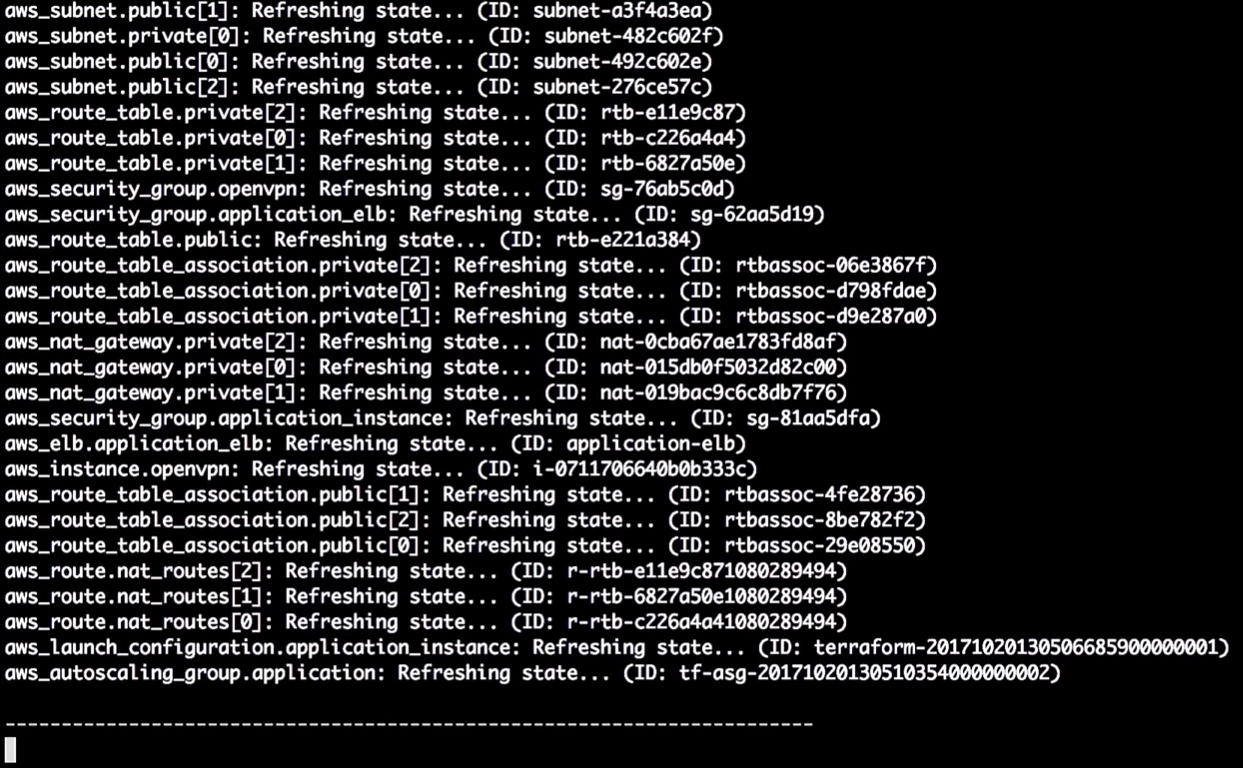

Donc, en ce moment, il me dit qu'il va changer la version dans la configuration de lancement. En raison de la modification de l'identifiant, il forcera un redémarrage de la configuration et le groupe de mise à l'échelle automatique changera (cela est nécessaire pour activer la nouvelle configuration de lancement).
Cela ne change pas les instances en cours d'exécution. C'est vraiment important. Vous pouvez suivre ce processus et le tester sans modifier les instances en production.
Remarque: vous devez toujours créer une nouvelle configuration de lancement avant de détruire l'ancienne, sinon il y aura une erreur.
Appliquons les changements:
terraform apply
Revenons maintenant à AWS. Lorsque toutes les modifications sont appliquées, nous passons au groupe de mise à l'échelle automatique.
Passons à la configuration AWS. Nous voyons qu'il y a trois instances avec une configuration de lancement. Ce sont les mêmes.
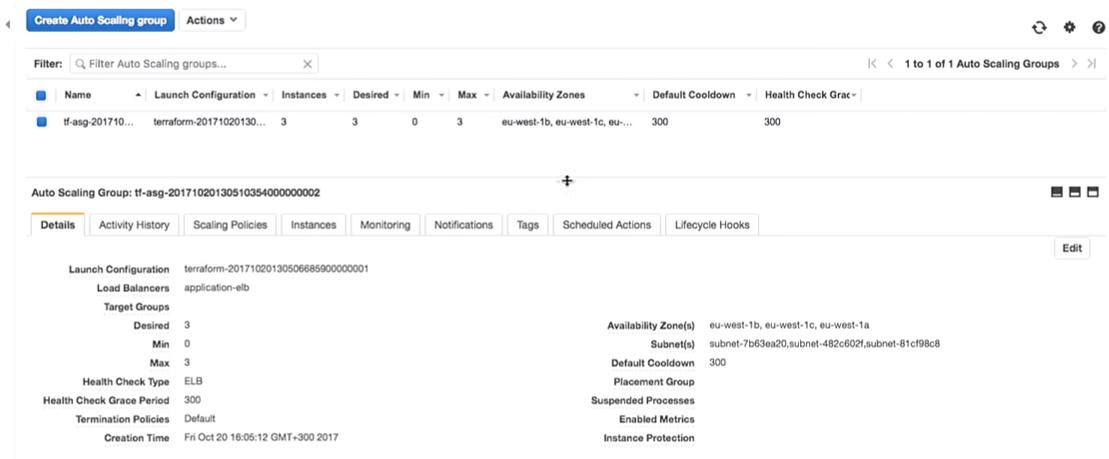
Amazon garantit que si nous voulons exécuter trois instances du service, elles seront effectivement lancées. C'est pourquoi nous leur payons de l'argent.
Passons aux expériences.
Une nouvelle configuration de lancement a été créée. Par conséquent, si je supprime l'une des instances, les autres ne seront pas endommagées. C'est important. Cependant, si vous utilisez directement les instances, tout en modifiant les données utilisateur, cela détruira les instances "actives". Veuillez ne pas le faire.
Supprimez donc l'une des instances:

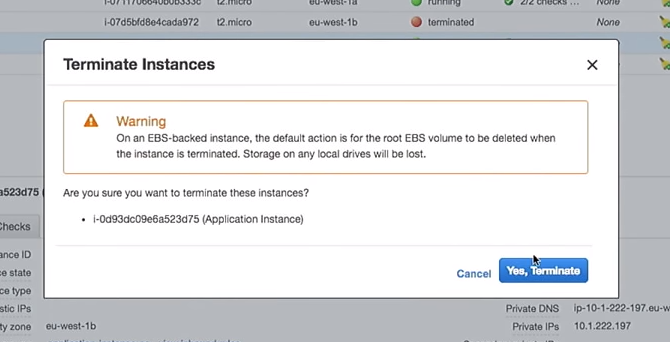
Que se passera-t-il dans le groupe de mise à l'échelle automatique lors de sa fermeture? Une nouvelle instance apparaîtra à sa place.
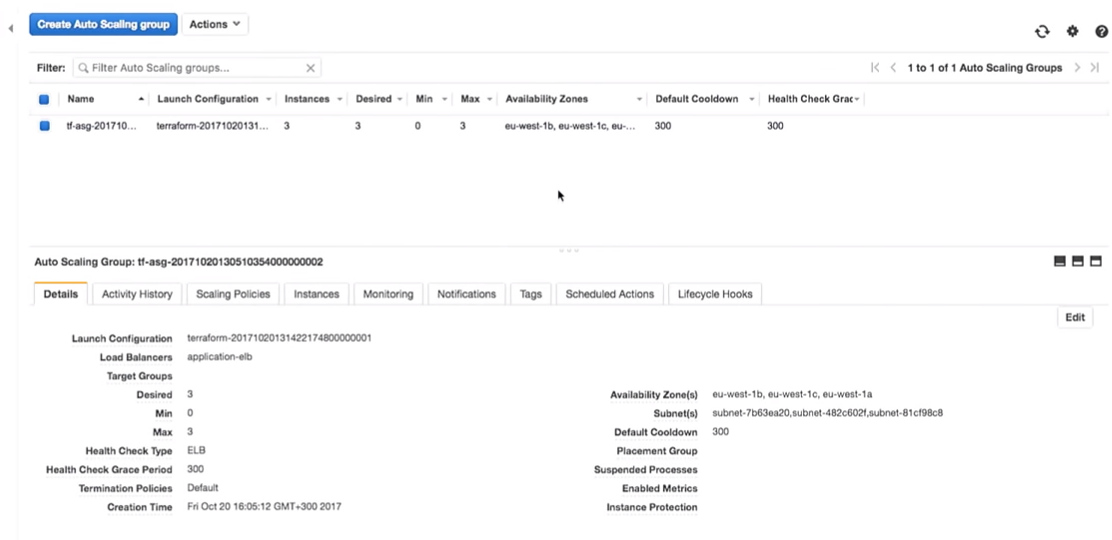
Ici, vous vous trouvez dans une situation intéressante. L'instance sera lancée avec la nouvelle configuration. Autrement dit, dans le système, vous pouvez avoir plusieurs images différentes (avec différentes configurations). Parfois, il vaut mieux ne pas supprimer immédiatement l'ancienne configuration de démarrage afin de se connecter au besoin.
Ici, tout devient encore plus intéressant. Pourquoi ne pas le faire avec des scripts et des outils CI, et non manuellement, comme je le montre? Il existe des outils qui peuvent le faire, tels que les excellents outils AWS-missing-sur GitHub.

Et que fait cet outil? Il s'agit d'un script bash qui parcourt toutes les instances de l'équilibreur de charge, les détruit une à la fois, garantissant la création de nouvelles à leur place.
Si j'ai perdu une de mes instances avec la version 1.0.0 et qu'une nouvelle est apparue - 1.1.1, je voudrais tuer tous les 1.0.0, tout transférer vers la nouvelle version. Parce que j'avance toujours. Permettez-moi de vous rappeler que je n'aime pas quand le serveur d'applications vit longtemps.
Dans l'un des projets, tous les sept jours, j'avais un script de contrôle qui détruisait toutes les instances de mon compte. Le serveur n'avait donc pas plus de sept jours. Une autre chose (ma préférée) est de marquer les serveurs comme "tachés" en utilisant SSH dans une boîte et de les détruire toutes les heures en utilisant un script - nous ne voulons pas que les gens le fassent manuellement.
De tels scripts de contrôle vous permettent d'avoir toujours la dernière version avec des bogues corrigés et des mises à jour de sécurité.
Vous pouvez utiliser le script simplement en exécutant:
aws-ha-relesae.sh -a my-scaling-group
-a est votre groupe de mise à l'échelle automatique. Le script passera par toutes les instances de votre groupe de mise à l'échelle automatique et le remplacera. Vous pouvez l'exécuter non seulement manuellement, mais également à partir de l'outil CI.
Vous pouvez le faire en QA ou en production. Vous pouvez le faire même dans votre compte AWS local. Vous faites ce que vous voulez, en utilisant à chaque fois le même mécanisme.
Retour sur Amazon. Nous avons une nouvelle instance:

Après avoir mis à jour la page dans le navigateur, où nous avons précédemment vu la version 1.0.0, nous obtenons:

La chose intéressante est que depuis que nous avons créé le script de création AMI, nous pouvons tester la création d'AMI.
Il existe d'excellents outils, tels que ServerScript ou Serverspec.
Serverspec vous permet de créer des spécifications de style Ruby pour tester l'apparence de votre serveur d'applications. Par exemple, ci-dessous, je donne un test qui vérifie que nginx est installé sur le serveur.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end
Nginx doit être installé et exécuté sur le serveur et à l'écoute sur le port 80. Vous pouvez dire que l'utilisateur X doit être disponible sur le serveur. Et vous pouvez mettre tous ces tests à leur place. Ainsi, lorsque vous créez une AMI, l'outil CI peut vérifier si cette AMI est adaptée à un objectif donné. Vous saurez qu'AMI est prêt pour la production.
Au lieu d'une conclusion
Mary Poppendieck est probablement l'une des femmes les plus incroyables dont j'ai jamais entendu parler. À un moment donné, elle a expliqué comment le développement de logiciels lean s'est développé au fil des ans. Et comment elle était associée à 3M dans les années 60, lorsque l'entreprise était vraiment engagée dans le développement Lean.
Et elle a posé la question: combien de temps faut-il à votre organisation pour déployer les modifications associées à une ligne de code? Pouvez-vous rendre ce processus fiable et reproductible?
En règle générale, cette question concernait toujours le code du logiciel. Combien de temps me faudra-t-il pour corriger une erreur dans cette application lors du déploiement en production? Mais il n'y a aucune raison pour laquelle nous ne pouvons pas utiliser la même question pour les infrastructures ou les bases de données.
J'ai travaillé pour une entreprise appelée OpenTable. Dans ce document, nous avons appelé cela la durée du cycle. Et dans OpenTable, elle avait sept semaines. Et c'est relativement bon. Je connais des entreprises qui mettent des mois à envoyer un code en production. Chez OpenTable, nous avons revu le processus pendant quatre ans. Cela a pris beaucoup de temps, car l'organisation est grande - 200 personnes. Et nous avons réduit le temps de cycle à trois minutes. Cela a été possible grâce aux mesures de l'effet de nos transformations.
Maintenant, tout est scripté. Nous avons tellement d'outils et d'exemples, il y a GitHub. Par conséquent, prenez des idées de conférences comme DevOops, mettez-les en œuvre dans votre organisation. N'essayez pas de tout mettre en œuvre. Prenez une toute petite chose et vendez-la. Montrez quelqu'un. L'impact d'un petit changement peut être mesuré, mesuré et passer à autre chose!
Paul Stack arrivera à Saint-Pétersbourg à la conférence DevOops 2018 avec un rapport «Tests de systèmes durables avec le Chaos» . Paul parlera de la méthodologie Chaos Engineering et montrera comment utiliser cette méthodologie sur des projets réels.