Il n'y a pas si longtemps, dans le centre de données dans lequel nous louons des serveurs, un autre mini-incident s'est produit. En conséquence, il n'y a eu aucune conséquence grave pour notre service; selon les métriques disponibles, nous avons pu comprendre ce qui se passait en une minute. Et puis j'ai imaginé comment je devrais me creuser la tête s'il ne manquait que 2 mesures simples. Sous la coupe, une petite histoire en images.
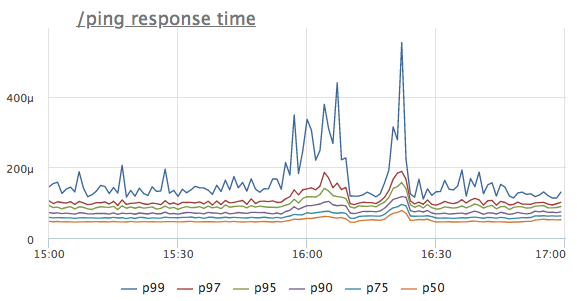
Imaginez que nous ayons vu une anomalie dans la chronologie de réponse d'un certain service. Pour simplifier, nous prenons le gestionnaire / ping, qui n'accède ni à la base de données ni aux services voisins, mais renvoie simplement '200 OK' (il est nécessaire pour les équilibreurs de charge et k8 pour le service de vérification de l'état)

Quelle est la première pensée? C'est vrai, le service n'a pas assez de ressources, probablement le CPU! Nous regardons la consommation du processeur:
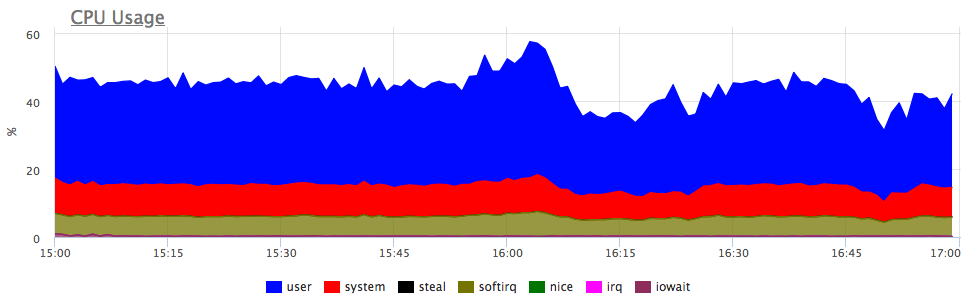
Oui, il y a des rafales similaires. Ensuite, nous regardons la consommation des services sur le serveur:
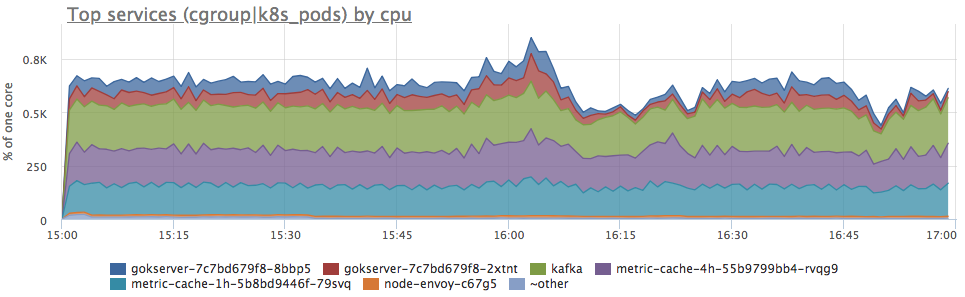
On voit que la consommation de proca a augmenté proportionnellement pour tous les services. Vous ne pouvez rien dire de plus explicite: vous pouvez aller voir si le profil de charge a changé (puisque tous les composants sont connectés et une augmentation des demandes d'entrée peut en fait entraîner une augmentation proportionnelle de la consommation de ressources) ou comprendre ce qu'est devenu les ressources du serveur.
Bien sûr, j'ai essayé de préserver l'intrigue du mieux que je pouvais, mais au début de l'article, vous avez probablement déjà deviné que le serveur avait simplement réduit le nombre de ticks de processeur disponibles. Dans dmesg, cela ressemble à ceci:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
En gros, nous avons réduit la fréquence en raison de la surchauffe du processeur. Nous regardons la température:
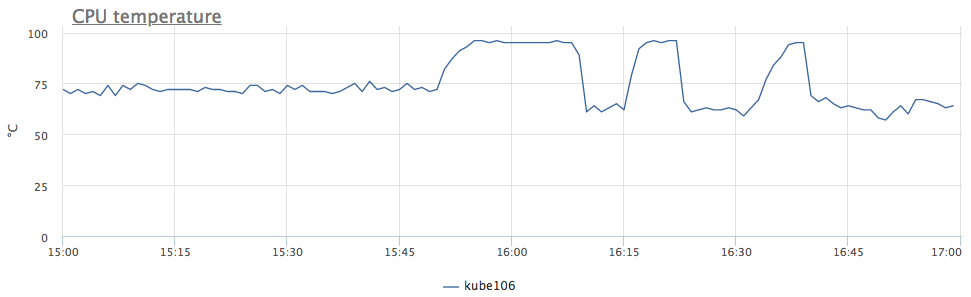
maintenant tout est clair. Comme nous avons immédiatement eu un comportement similaire sur 6 serveurs, nous nous sommes rendu compte que le problème se trouvait dans le DC, et pas dans tout, mais seulement dans certaines rangées de racks.
Mais revenons aux mesures. Nous voulons potentiellement savoir si les serveurs surchaufferont à l'avenir, mais ce n'est pas une raison pour ajouter un graphique des températures du processeur à tous les tableaux de bord et le vérifier à chaque fois.
Habituellement, des déclencheurs sont utilisés pour suivre certaines mesures afin d'optimiser le processus. Mais quel seuil dois-je choisir pour un déclencheur en fonction de la température du processeur?
C'est à cause de la difficulté de choisir un bon seuil pour le déclencheur, de nombreux ingénieurs rêvent d'un détecteur d'anomalie, qui sans réglages se retrouvera, je ne sais pas quoi :)La première pensée est de fixer la température seuil à laquelle notre service a commencé à avoir des problèmes. Et si vous n'avez jamais eu de surchauffe? Bien sûr, vous pouvez consulter mon emploi du temps et décider par vous-même que 95 ° C est ce dont vous avez besoin, mais réfléchissons un peu plus.
Le problème avec nous n'est pas à cause des degrés, mais parce que la fréquence a diminué! Gardons une trace du nombre de ces événements.
Sous Linux, cela peut être supprimé de sysfs:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Pour être honnête, nous n'affichons même cette statistique nulle part, nous n'avons un déclencheur automatique pour tous les clients qui se déclenche lorsque le seuil "> 10 événements / seconde" est atteint. Selon nos statistiques, il n'y a pratiquement pas de faux positifs à ce seuil.
Oui, ce déclencheur fonctionne rarement, mais lorsque cela se produit, cela rend la vie très facile!
Chez okmeter.io, la plupart du temps, nous sommes engagés dans le développement de notre base de données d'auto-déclencheurs, ce qui permet à nos clients de trouver plus facilement les problèmes qui leur sont inconnus.