Bonjour à tous!
Aujourd'hui, nous allons parler de l'expérience de l'un de nos projets DevOps. Nous avons décidé d'implémenter une nouvelle application pour Linux en utilisant .Net Core sur une architecture de microservice.
Nous prévoyons que le projet se développera activement et qu'il y aura de plus en plus d'utilisateurs. Par conséquent, il doit être facilement évolutif en termes de fonctionnalités et de performances.
Nous avons besoin d'un système tolérant aux pannes - si l'un des blocs de fonctionnalités ne fonctionne pas, le reste devrait fonctionner. Nous voulons également assurer une intégration continue, y compris le déploiement de la solution sur les serveurs du client.
Par conséquent, nous avons utilisé les technologies suivantes:
- .Net Core pour la mise en œuvre de microservices. Notre projet a utilisé la version 2.0,
- Kubernetes pour l'orchestration de microservices,
- Docker pour la création d'images de microservices,
- bus d'intégration Rabbit MQ et Mass Transit,
- Elasticsearch et Kibana pour l'exploitation forestière,
- TFS pour implémenter le pipeline CI / CD.
Cet article partagera les détails de notre solution.

Ceci est une transcription de notre discours lors de la réunion .NET, voici un
lien vers la vidéo du discours.
Notre défi commercial
Notre client est une entreprise fédérale où il y a des marchandiseurs - ce sont des gens qui sont responsables de la façon dont les marchandises sont présentées dans les magasins. Et il y a des superviseurs - ce sont les leaders des marchandiseurs.
L'entreprise a un processus de formation et d'évaluation du travail des marchandiseurs par des superviseurs, qui devait être automatisé.
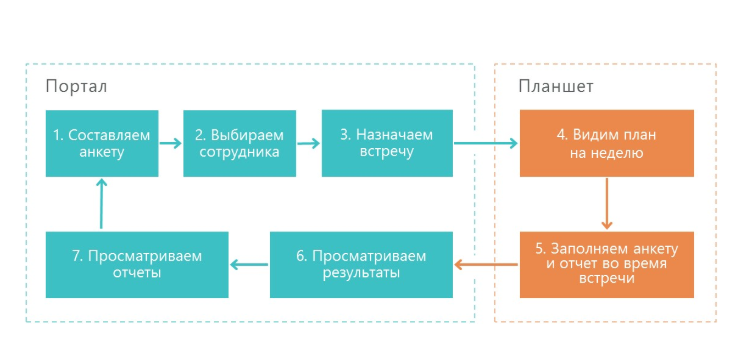
Voici comment fonctionne notre solution:
1. Le superviseur établit un questionnaire - c'est une liste de contrôle de ce que vous devez vérifier dans le travail du marchandiseur.
2. Ensuite, le superviseur sélectionne l'employé dont le travail sera vérifié. La date de l'interrogatoire est attribuée.
3. Ensuite, l'activité est envoyée à l'appareil mobile du superviseur.
4. Ensuite, le questionnaire est rempli et envoyé au portail.
5. Le portail génère des résultats et divers rapports.
Les microservices nous aideront à résoudre trois problèmes:
1. À l'avenir, nous voulons étendre facilement la fonctionnalité, car il existe de nombreux processus commerciaux similaires dans l'entreprise.
2. Nous voulons que la solution soit tolérante aux pannes. Si une partie cesse de fonctionner, la solution pourra restaurer son travail d'elle-même et la défaillance d'une partie n'affectera pas considérablement le fonctionnement de la solution dans son ensemble.
3. L'entreprise pour laquelle nous mettons en œuvre la solution a de nombreuses succursales. En conséquence, le nombre d'utilisateurs de la solution est en constante augmentation. Par conséquent, je voulais que cela n'affecte pas les performances.
En conséquence, nous avons décidé d'utiliser des microservices sur ce projet, ce qui a nécessité un certain nombre de décisions non triviales.
Quelles technologies ont aidé à mettre en œuvre cette solution:
• Docker simplifie la distribution de la distribution de la solution. La distribution dans notre cas est un ensemble d'images de microservices
• Comme il existe de nombreux microservices dans notre solution, nous devons les gérer. Pour cela, nous utilisons Kubernetes.
• Nous implémentons des microservices en utilisant .Net Core.
• Afin de mettre à jour rapidement la solution chez le client, nous devons mettre en œuvre une intégration et une livraison continues pratiques.
Voici notre ensemble complet de technologies:
• .Net Core que nous utilisons pour créer des microservices,
• Microservice est emballé dans une image Docker,
• L'intégration continue et la livraison continue sont mises en œuvre à l'aide de TFS,
• L’extrémité avant est implémentée en angulaire,
• Pour la surveillance et la journalisation, nous utilisons Elasticsearch et Kibana,
• RabbitMQ et MassTransit sont utilisés comme bus d'intégration.
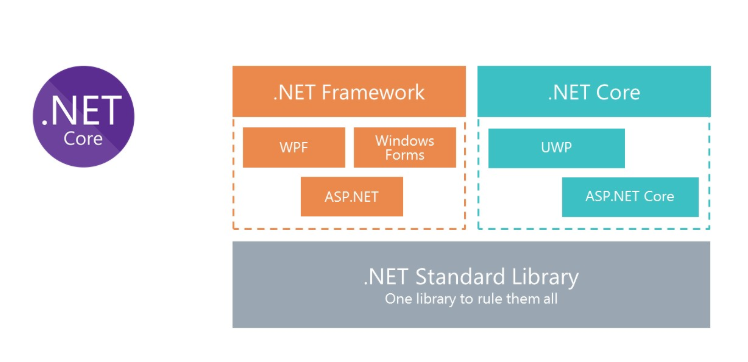
Solutions .NET Core pour Linux
Nous savons tous ce qu'est le framework .Net classique. Le principal inconvénient de la plate-forme est qu'elle n'est pas multiplateforme. Par conséquent, nous ne pouvons pas exécuter de solutions sur le .Net Framework pour Linux dans Docker.
Pour fournir la possibilité d'utiliser C # dans Docker, Microsoft a repensé le .Net Framework et créé .Net Core. Et pour utiliser les mêmes bibliothèques, Microsoft a créé la spécification de bibliothèque standard .Net. Les assemblys .Net Standart Library peuvent être utilisés à la fois dans .Net Framework et .Net Core.
Kubernetes - pour l'orchestration de microservices
Kubernetes est utilisé pour gérer et regrouper les conteneurs Docker. Voici les principaux avantages de Kubernetes dont nous avons profité:
- offre la possibilité de configurer facilement l'environnement des microservices,
- simplifie la gestion environnementale (Dev, QA, Stage),
- Prêt à l'emploi offre la possibilité de répliquer les microservices et l'équilibrage de charge sur les répliques.
Architecture de la solution
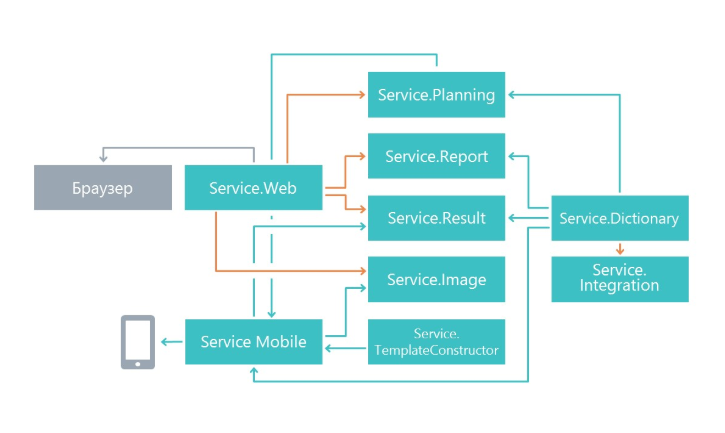
Au début des travaux, nous nous sommes demandé comment diviser la fonctionnalité en microservices. La division a été faite sur le principe d'une responsabilité unique, mais à un niveau supérieur. Sa tâche principale est d'apporter des modifications à un service en affectant le moins possible les autres microservices. En conséquence, dans notre cas, les microservices ont commencé à effectuer un domaine de fonctionnalité distinct.
En conséquence, nous sommes apparus des services qui sont engagés dans la planification de questionnaires, un microservice pour afficher les résultats, un microservice pour travailler avec une application mobile et d'autres microservices.
Options d'interaction avec des clients externes
Microsoft dans son livre sur les microservices, «
.NET Microservices. .NET Container Application Architecture »propose trois implémentations possibles d'interaction avec des microservices. Nous avons examiné les trois et choisi la plus appropriée.
• Service API Gateway
L'API de service Gateway est une implémentation de façade pour les demandes des utilisateurs pour d'autres services. Le problème avec la solution est que si la façade ne fonctionne pas, alors toute la solution cessera de fonctionner. Ils ont décidé d'abandonner cette approche pour la tolérance aux pannes.
• API Gateway avec Azure API Management
Microsoft offre la possibilité d'utiliser une façade cloud dans Azure. Mais cette solution ne convenait pas, car nous allions déployer la solution non pas dans le cloud, mais sur les serveurs du client.
• Communication directe client-microservice
En conséquence, il nous reste la dernière option - l'interaction directe de l'utilisateur avec les microservices. Nous l'avons choisi.
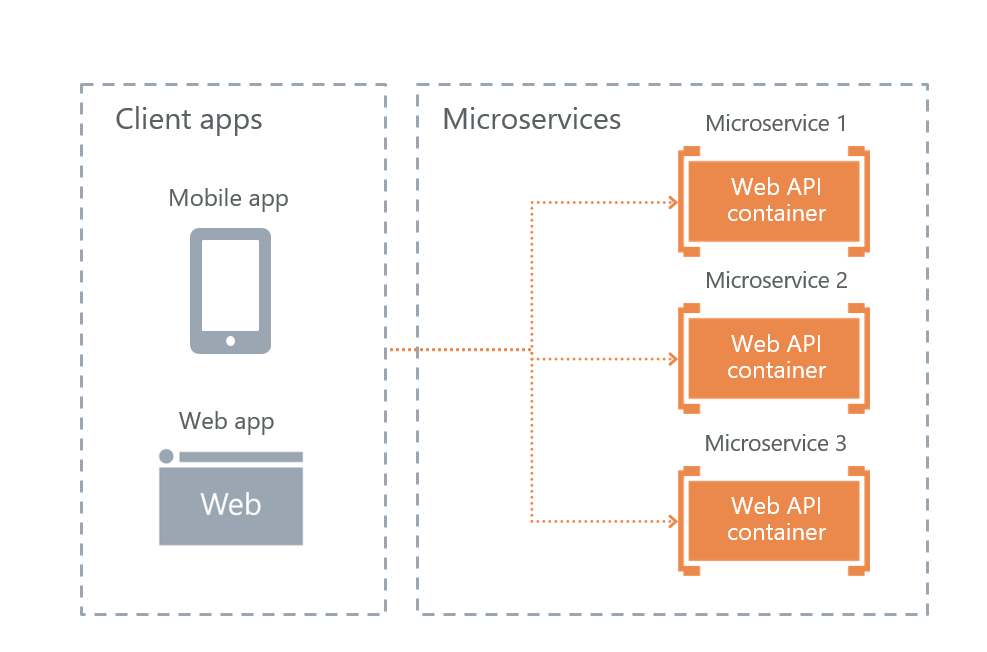
Son plus en tolérance aux pannes. L'inconvénient est qu'une partie de la fonctionnalité devra être reproduite sur chaque service séparément. Par exemple, il était nécessaire de configurer l'autorisation séparément sur chaque microservice auquel les utilisateurs ont accès.
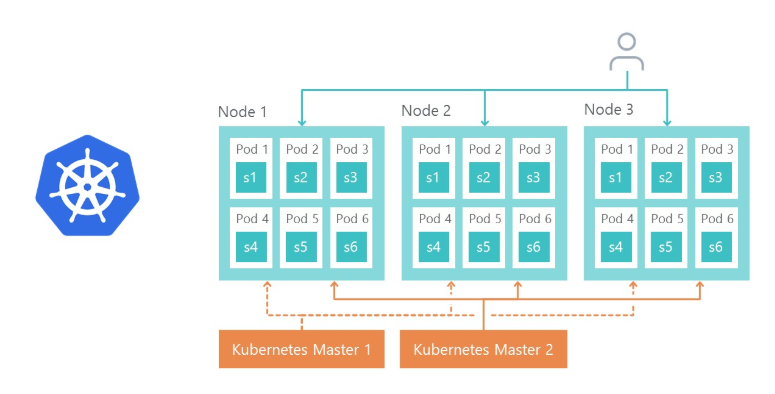
Bien sûr, la question se pose de savoir comment nous allons équilibrer la charge et comment la tolérance aux pannes est mise en œuvre. Tout est simple ici - Ingress Controller Kubernetes le fait.

Le nœud 1, le nœud 2 et le nœud 3 sont des répliques du même microservice. Si l'une des répliques échoue, l'équilibreur de charge redirigera automatiquement la charge vers d'autres microservices.
Architecture physique
Voici comment nous avons organisé notre infrastructure de solutions:
• Chaque microservice a sa propre base de données (s'il en a bien sûr besoin), les autres services n'accèdent pas à la base de données d'un autre microservice.
• Les microservices communiquent entre eux uniquement via le bus RabbitMQ + Mass Transit, ainsi qu'en utilisant des requêtes HTTP.
• Chaque service a sa propre responsabilité clairement définie.
• Pour la journalisation, nous utilisons Elasticsearch et Kibana et la bibliothèque pour travailler avec
Serilog .
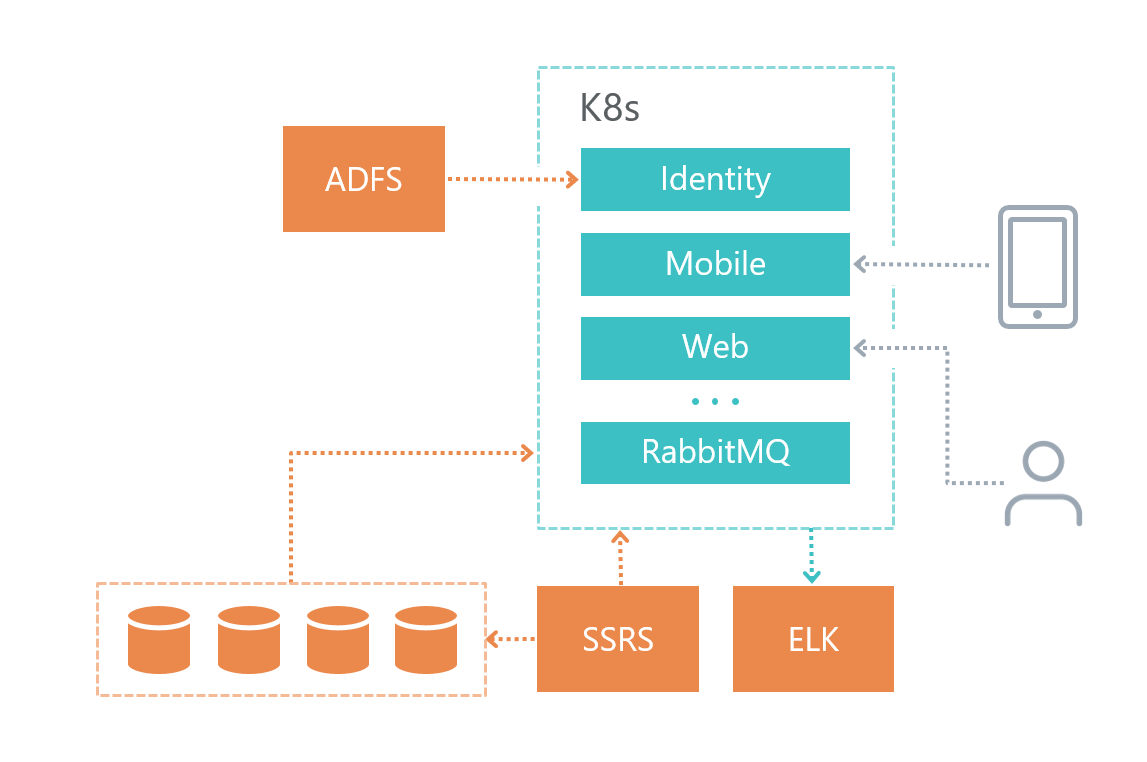
Le service de base de données a été déployé sur une machine virtuelle distincte et non dans Kubernetes, car Microsoft DBMS ne recommande pas d'utiliser Docker sur les environnements de produit.
Le service de journalisation a également été déployé sur une machine virtuelle distincte pour des raisons de tolérance aux pannes - si nous avons des problèmes avec Kubernetes, alors nous pouvons comprendre quel est le problème.
Déploiement: comment nous avons organisé les environnements de développement et de produits
Notre infrastructure dispose de 3 espaces de noms à Kubernetes. Les trois environnements accèdent à un service de base de données et à un service de journalisation. Et, bien sûr, chaque environnement regarde sa propre base de données.
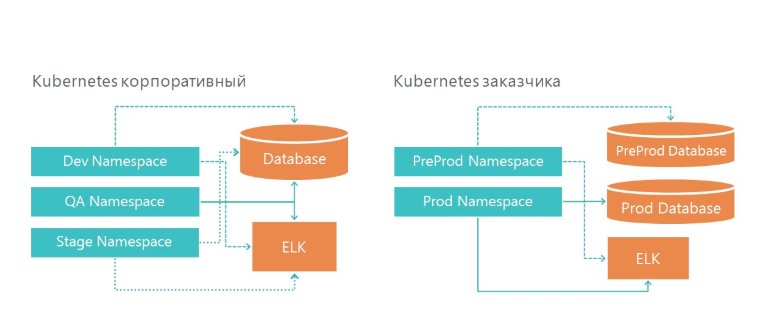
Sur l'infrastructure du client, nous avons également deux environnements: la pré-production et la production. À la production, nous avons des serveurs de base de données séparés pour la pré-vente et l'environnement du produit. Pour la journalisation, nous avons alloué un serveur ELK sur notre infrastructure et sur l'infrastructure du client.
Comment déployer 5 environnements avec 10 microservices chacun?
En moyenne, nous avons 10 services par projet et trois environnements: QA, DEV, Stage, sur lesquels environ 30 microservices sont déployés au total. Et ce n'est que sur l'infrastructure de développement! Ajoutez 2 environnements supplémentaires sur l'infrastructure du client et nous bénéficions de 50 microservices.
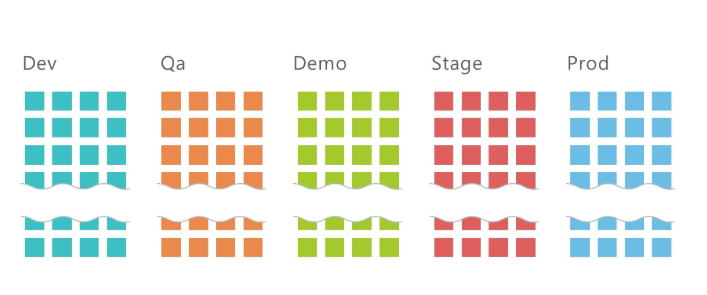
Il est clair qu'un tel nombre de services doit en quelque sorte être géré. Kubernetes nous y aide.
Pour déployer un microservice, vous devez
• Développez secret,
• Déployer le déploiement,
• Étendre le service.
À propos de l'écriture secrète ci-dessous.
Le déploiement est une instruction pour Kubernetes, sur la base de laquelle il lancera le conteneur Docker de notre microservice. Voici la commande sur laquelle le déploiement est déployé:
kubectl apply -f .\(yaml deployment-) --namespace=DEV apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Ce fichier décrit comment le déploiement est appelé (imtob-etr-it-dictionary-api), quelle image il doit utiliser pour l'exécution, ainsi que d'autres paramètres. Dans la section secrète, nous allons personnaliser notre environnement.
Après avoir déployé le déploiement, nous devons déployer le service, si nécessaire.
Les services sont nécessaires lorsque l'accès au microservice de l'extérieur est nécessaire. Par exemple, lorsque vous souhaitez qu'un utilisateur ou un autre microservice puisse effectuer une demande Get vers un autre microservice.
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV apiVersion: v1 kind: Service metadata: name: imtob-etr-it-dictionary-api-services spec: ports: - name: http port: 80 targetPort: 80 protocol: TCP selector: name: imtob-etr-it-dictionary-api
Habituellement, la description du service est petite. On y voit le nom du service, comment y accéder et le numéro de port.
Par conséquent, pour déployer l'environnement, nous avons besoin
• un ensemble de fichiers avec des secrets pour tous les microservices,
• un ensemble de fichiers avec le déploiement de tous les microservices,
• un ensemble de fichiers avec les services de tous les microservices.
Nous stockons tous ces scripts dans le référentiel git.
Pour déployer la solution, nous avons obtenu un ensemble de trois types de scripts:
• dossier avec secrets - ce sont des configurations pour chaque environnement,
• dossier avec déploiement pour tous les microservices,
• dossier avec services pour certains microservices,
dans chacune - une dizaine d'équipes, une pour chaque microservice. Pour plus de commodité, nous avons créé une page avec des scripts dans Confluence, qui nous aide à déployer rapidement un nouvel environnement.
Voici un script de déploiement de déploiement (il existe des ensembles similaires pour secret et pour service):
Script de déploiementkubectl applique -f. \ imtob-etr-it-image-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-mobile-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-planning-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-result-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-web.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-report-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-template-constructor-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-dictionary-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-integration-api.yml --namespace = DEV
kubectl applique -f. \ imtob-etr-it-identity-api.yml --namespace = DEV
Implémentation CI / CD
Chaque service est dans son propre dossier, et nous avons un dossier avec des composants communs.
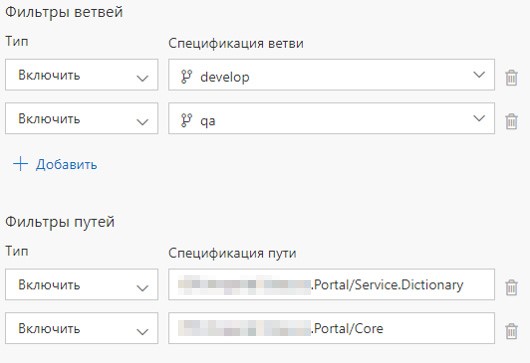
Il existe également une définition de build et une définition de version pour chaque microservice. Nous avons configuré le lancement de Build Definion lors de la validation sur le service approprié ou lors de la validation dans le dossier approprié. Si le contenu du dossier avec les composants communs est mis à jour, tous les microservices sont déployés.
Quels sont les avantages d'une telle organisation Build?
1. La solution est dans un référentiel git,
2. Lors du changement de plusieurs microservices, l'assemblage démarre en parallèle avec les agents d'assemblage libres,
3. Chaque définition de build présente un script simple à partir de la création de l'image et de son insertion dans le registre Nexus.
Définition de version et définition de version
Comment déployer un agent VSTS, nous l'avons décrit précédemment
dans cet article .
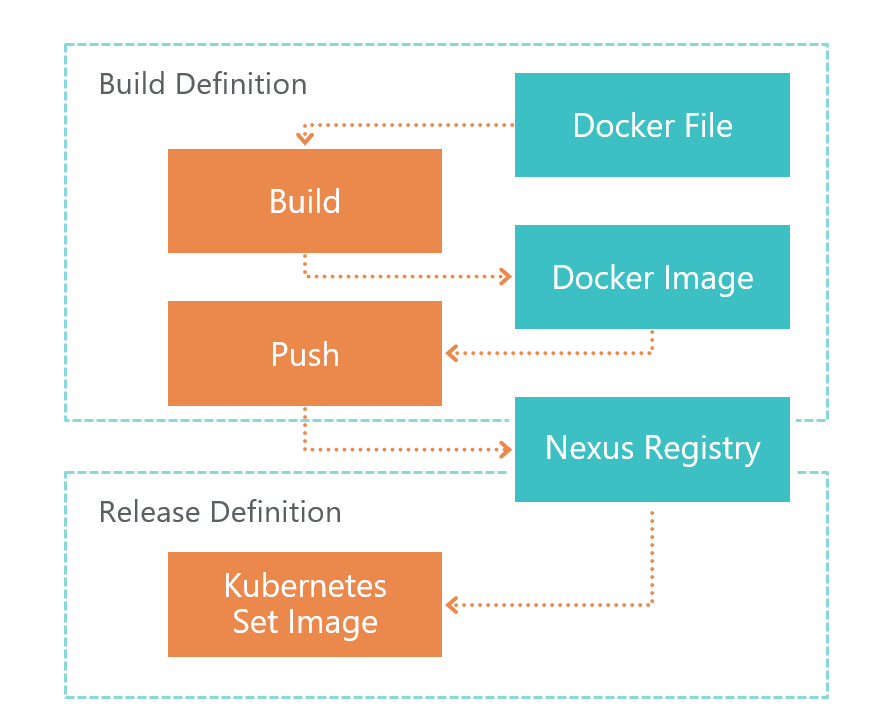
Vient d'abord la définition de construction. À la commande TFS VSTS, l'agent lance la génération Dockerfile. En conséquence, nous obtenons l'image d'un microservice. Cette image est enregistrée localement sur l'environnement où l'agent VSTS s'exécute.
Après la génération, Push est lancé, qui envoie l'image que nous avons reçue à l'étape précédente au registre Nexus. Maintenant, il peut être utilisé en externe. Le registre Nexus est une sorte de Nuget, non seulement pour les bibliothèques, mais pour les images Docker et plus encore.
Une fois l'image prête et accessible de l'extérieur, vous devez la déployer. Pour cela, nous avons la définition de version. Tout est simple ici - nous exécutons la commande set image:
kubectl set image deployment/imtob-etr-it-dictionary-api imtob-etr-it-dictionary-api=nexus3.company.ru:18085/etr-it-dictionary-api:$(Build.BuildId)Après cela, il mettra à jour l'image du microservice souhaité et lancera un nouveau conteneur. En conséquence, notre service a été mis à jour.
Comparons maintenant la construction avec et sans Dockerfile.
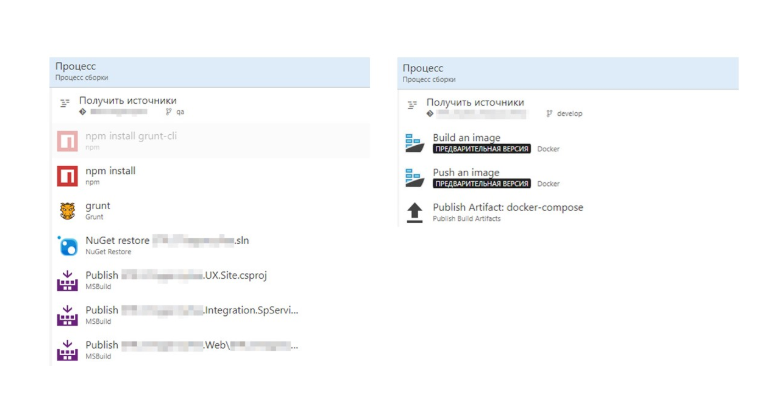
Sans Dockerfile, nous obtenons beaucoup d'étapes, qui ont beaucoup de spécificités .Net. Sur la droite, nous voyons une construction d'image Docker. Tout est devenu beaucoup plus facile.
L'ensemble du processus de construction de l'image est décrit dans le Dockerfile. Cet assembly peut être débogué localement.

Total: nous avons obtenu un CI / CD simple et transparent
1. Séparation du développement et du déploiement. L'assemblage est décrit dans Dockerfile et repose sur les épaules du développeur.
2. Lors de la configuration de CI / CD, vous n'avez pas besoin de connaître les détails et les caractéristiques de l'assemblage - le travail se fait uniquement avec le Dockerfile.
3. Nous mettons à jour uniquement les microservices modifiés.
Ensuite, vous devez configurer RabbitMQ dans le K8S: nous avons écrit un
article séparé à ce sujet.
Réglage de l'environnement
D'une manière ou d'une autre, nous devons configurer des microservices. La partie principale de l'environnement est configurée dans le fichier de configuration racine Appsettings.json. Ce fichier contient des paramètres indépendants de l'environnement.
Ces paramètres qui dépendent de l'environnement sont stockés dans le dossier secrets du fichier appsettings.secret.json. Nous avons adopté l'approche décrite dans l'article
Gestion des paramètres de l'application ASP.NET Core sur Kubernetes .
var configuration = new ConfigurationBuilder() .AddJsonFile($"appsettings.json", true) .AddJsonFile("secrets/appsettings.secrets.json", optional: true) .Build();
Le fichier appsettings.secrets.json contient les paramètres des index Elastic Search et la chaîne de connexion à la base de données.
{ "Serilog": { "WriteTo": [ { "Name": "Elasticsearch", "Args": { "nodeUris": "http://192.168.150.114:9200", "indexFormat": "dev.etr.it.ifield.api.dictionary-{0:yyyy.MM.dd}", "templateName": "dev.etr.it.ifield.api.dictionary", "typeName": "dev.etr.it.ifield.api.dictionary.event" } } ] }, "ConnectionStrings": { "DictionaryDbContext": "Server=192.168.154.162;Database=DEV.ETR.IT.iField.Dictionary;User Id=it_user;Password=PASSWORD;" } }
Ajouter un fichier de configuration à Kubernetes
Pour ajouter ce fichier, vous devez le déployer dans le conteneur Docker. Cela se fait dans le fichier de déploiement de Kubernetis. Le déploiement décrit dans quel dossier le fichier secret c doit être créé et à quel secret il est nécessaire d'associer le fichier.
apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Vous pouvez créer un secret dans Kubernetes à l'aide de l'utilitaire kubectl. Nous voyons ici le nom du secret et le chemin d'accès au fichier. Nous indiquons également le nom de l'environnement pour lequel nous créons un secret.
kubectl create secret generic secret-appsettings-dictionary
--from-file=./Dictionary/appsettings.secrets.json --namespace=DEMOConclusions
Inconvénients de l'approche choisie
1. Seuil d'entrée élevé. Si vous réalisez un tel projet pour la première fois, il y aura beaucoup de nouvelles informations.
2. Microservices → conception plus complexe. Il est nécessaire d'appliquer de nombreuses solutions non évidentes car nous n'avons pas une solution monolithique, mais une solution microservice.
3. Tout n'est pas implémenté pour Docker. Tout ne peut pas être exécuté dans une architecture de microservice. Par exemple, alors que SSRS n'est pas dans Docker.
Avantages d'une approche auto-testée
1. L'infrastructure comme code
La description de l'infrastructure est stockée dans le contrôle de code source. Au moment du déploiement, vous n'avez pas besoin d'adapter l'environnement.
2. Mise à l'échelle à la fois au niveau des fonctionnalités et au niveau des performances hors de la boîte.
3. Les microservices sont bien isolés
Il n'y a pratiquement pas de parties critiques, dont la défaillance conduit à l'inopérabilité du système dans son ensemble.
4. Livraison rapide des modifications
Seuls les microservices dans lesquels il y a eu des mises à jour sont mis à jour. Si vous ne tenez pas compte du temps de coordination et d'autres éléments liés au facteur humain, la mise à jour d'un microservice s'effectue en 2 minutes ou moins.
Conclusions pour nous
1. Sur .NET Core, vous pouvez et devez mettre en œuvre des solutions industrielles.
2. K8S a vraiment simplifié la vie, simplifié la mise à jour des environnements, facilité la configuration des services.
3. TFS peut être utilisé pour implémenter CI / CD pour Linux.