Bonjour chers collègues.
Nous espérons commencer la traduction d'un petit
livre , mais vraiment
basique, sur la mise en œuvre des capacités de l'IA en Python avant la fin août.

M. Gift n'a peut-être pas besoin de publicité supplémentaire (pour les curieux - le
profil du maître sur GitHub):

L'article qui est proposé aujourd'hui parlera brièvement de la bibliothèque Ray, développée à l'Université de Californie (Berkeley) et mentionnée dans le livre de Peter par petite. Nous espérons qu'en tant que teaser précoce - ce dont vous avez besoin. Bienvenue sous chat
Avec le développement d'algorithmes et de techniques d'apprentissage automatique, de plus en plus d'applications d'apprentissage automatique doivent être exécutées sur de nombreuses machines à la fois, et elles ne peuvent pas se passer de simultanéité. Cependant, l'infrastructure pour effectuer l'apprentissage automatique sur des clusters est toujours formée de manière situationnelle. Maintenant, il existe déjà de bonnes solutions (par exemple, des serveurs de paramètres ou la recherche d'hyperparamètres) et des systèmes distribués de haute qualité (par exemple, Spark ou Hadoop), créés à l'origine pour ne pas travailler avec l'IA, mais les praticiens créent souvent l'infrastructure pour leurs propres systèmes distribués à partir de zéro. Beaucoup d'efforts supplémentaires sont consacrés à cela.
À titre d'exemple, considérons un algorithme conceptuellement simple, disons, des
stratégies évolutives pour l'apprentissage par renforcement . Sur le pseudo-code, cet algorithme tient sur une dizaine de lignes, et son implémentation en Python est légèrement plus importante. Cependant, l'utilisation efficace de cet algorithme sur une machine ou un cluster plus gros nécessite une ingénierie logicielle beaucoup plus sophistiquée. Dans la mise en œuvre de cet algorithme par les auteurs de cet article - des milliers de lignes de code, il est nécessaire de déterminer les protocoles de communication, les stratégies de sérialisation et de désérialisation des messages, ainsi que diverses méthodes de traitement des données.
L'un des objectifs de
Ray est d'aider un praticien à transformer un prototype d'algorithme qui s'exécute sur un ordinateur portable en une application distribuée hautes performances qui fonctionne efficacement sur un cluster (ou sur une seule machine multicœur) en ajoutant relativement peu de lignes de code. En termes de performances, un tel cadre devrait avoir tous les avantages d'un système optimisé manuellement et ne pas obliger l'utilisateur à penser à la planification, au transfert de données et aux pannes de machine.
Framework AI gratuitLien avec d'autres cadres d'apprentissage en profondeur : Ray est entièrement compatible avec les cadres d'apprentissage en profondeur tels que TensorFlow, PyTorch et MXNet, donc dans de nombreuses applications, il est tout à fait naturel d'utiliser un ou plusieurs autres cadres d'apprentissage en profondeur avec Ray (par exemple, dans nos bibliothèques d'apprentissage renforcées activement appliquer TensorFlow et PyTorch).
Communication avec d'autres systèmes distribués : Aujourd'hui, de nombreux systèmes distribués populaires sont utilisés, cependant, la plupart d'entre eux ont été conçus sans prendre en compte les tâches associées à l'IA, ils n'ont donc pas les performances requises pour prendre en charge l'IA et ne disposent pas d'une API pour exprimer les aspects appliqués de l'IA. Dans les systèmes distribués modernes, il n'y a pas (nécessaire, selon le système) de telles fonctionnalités nécessaires:
- Prise en charge des tâches au niveau de la milliseconde et prise en charge de millions de tâches par seconde
- Parallélisme imbriqué (parallélisation de tâches au sein de tâches, par exemple, simulations parallèles lors de la recherche d'hyperparamètres) (voir la figure suivante)
- Dépendances arbitraires entre les tâches, dynamiquement pendant l'exécution (par exemple, ne pas avoir à attendre, s'adapter au rythme des travailleurs lents)
- Tâches qui opèrent sur un état variable partagé (par exemple, les poids dans les réseaux de neurones ou un simulateur)
- Prise en charge de ressources hétérogènes (CPU, GPU, etc.)
 Un exemple simple de concurrence imbriquée. Dans notre application, deux expériences sont effectuées en parallèle (chacune d'elles est une tâche à long terme), et dans chaque expérience plusieurs processus parallèles sont simulés (chaque processus est également une tâche).
Un exemple simple de concurrence imbriquée. Dans notre application, deux expériences sont effectuées en parallèle (chacune d'elles est une tâche à long terme), et dans chaque expérience plusieurs processus parallèles sont simulés (chaque processus est également une tâche).Il existe deux façons principales d'utiliser Ray: via ses API de bas niveau et via des bibliothèques de haut niveau. Les bibliothèques de haut niveau sont construites au-dessus des API de bas niveau. Ceux-ci incluent actuellement
Ray RLlib (une bibliothèque évolutive pour l'apprentissage par renforcement) et
Ray.tune , une bibliothèque efficace pour la recherche distribuée d'hyperparamètres.
API Ray Low LevelLe but de l'API Ray est de fournir une expression naturelle des modèles de calcul et des applications les plus courants, sans être limité à des modèles fixes tels que MapReduce.
Graphes de tâches dynamiquesLa primitive de base dans l'application (tâche) Ray est un graphe de tâche dynamique. Il est très différent du graphe de calcul dans TensorFlow. Alors que dans TensorFlow un graphe de calcul représente un réseau de neurones et est exécuté plusieurs fois dans chaque application distincte, dans Ray le graphe de tâches correspond à l'application entière et n'est exécuté qu'une seule fois. Le graphique des tâches n'est pas connu à l'avance. Il est construit dynamiquement pendant que l'application est en cours d'exécution et l'exécution d'une tâche peut déclencher l'exécution de nombreuses autres tâches.
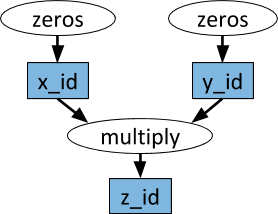 Un exemple de graphe de calcul. Dans les ovales blancs, les tâches sont représentées et dans les rectangles bleus - les objets. Les flèches indiquent que certaines tâches dépendent d'objets, tandis que d'autres créent des objets.
Un exemple de graphe de calcul. Dans les ovales blancs, les tâches sont représentées et dans les rectangles bleus - les objets. Les flèches indiquent que certaines tâches dépendent d'objets, tandis que d'autres créent des objets.Les fonctions arbitraires Python peuvent être exécutées en tant que tâches et, dans n'importe quel ordre, elles peuvent dépendre de la sortie d'autres tâches. Voir l'exemple ci-dessous.
ActeursÀ l'aide des seules fonctions distantes et de la gestion des tâches ci-dessus, il est impossible d'obtenir que plusieurs tâches fonctionnent simultanément sur le même état mutable partagé. Un tel problème avec l'apprentissage automatique se pose dans différents contextes, où l'état du simulateur, les poids dans le réseau neuronal ou quelque chose de complètement différent peuvent être partagés. L'abstraction d'acteur est utilisée dans Ray pour encapsuler un état mutable partagé entre de nombreuses tâches. Voici un exemple illustratif montrant comment procéder avec le simulateur Atari.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
Pour toute sa simplicité, l'acteur est très souple d'utilisation. Par exemple, un simulateur ou une stratégie de réseau de neurones peut être encapsulé dans un acteur, il peut également être utilisé pour une formation distribuée (comme avec un serveur de paramètres) ou pour fournir des stratégies dans une application «en direct».
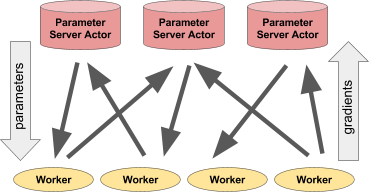 Gauche: L'acteur donne des prévisions / actions à un certain nombre de processus clients. À droite: de nombreux acteurs du serveur de paramètres effectuent une formation distribuée pour de nombreux flux de travail.Exemple de serveur de paramètres
Gauche: L'acteur donne des prévisions / actions à un certain nombre de processus clients. À droite: de nombreux acteurs du serveur de paramètres effectuent une formation distribuée pour de nombreux flux de travail.Exemple de serveur de paramètresLe serveur de paramètres peut être implémenté en tant qu'acteur Ray comme suit:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
Voici un
exemple plus complet .
Pour instancier un serveur de paramètres, nous le faisons.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
Pour créer quatre travailleurs de longue durée, extrayant et mettant constamment à jour les paramètres, nous allons le faire.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
Bibliothèques Ray High LevelRay RLlib est une bibliothèque d'apprentissage de renforcement évolutive conçue pour être utilisée sur plusieurs machines. Il peut être activé à l'aide des scripts de formation fournis à titre d'exemple, ainsi que via l'API Pytho. Actuellement, il comprend des implémentations d'algorithmes:
- A3C
- Dqn
- Stratégies évolutives
- PPO
Des travaux sont en cours sur la mise en œuvre d'autres algorithmes. RLlib est entièrement compatible avec
OpenAI gym .
Ray.tune est une bibliothèque efficace pour la recherche distribuée d'hyperparamètres. Il fournit une API Python pour l'apprentissage en profondeur, l'apprentissage par renforcement et d'autres tâches qui nécessitent beaucoup de puissance de traitement. Voici un exemple illustratif de ce type:
from ray.tune import register_trainable, grid_search, run_experiments
Les résultats actuels peuvent être visualisés dynamiquement à l'aide d'outils spéciaux, par exemple, Tensorboard et VisKit de rllab (ou lire directement les journaux JSON). Ray.tune prend en charge la recherche dans la grille, la recherche aléatoire et des algorithmes d'arrêt précoce plus triviaux comme HyperBand.
Plus sur Ray