 Le code du projet est disponible dans le référentiel.
Le code du projet est disponible dans le référentiel.Présentation
Quand j'ai lu les descriptions de l'apparence des personnages dans les livres, j'ai toujours été intéressé par leur apparence dans la vie. Il est tout à fait possible d'imaginer une personne dans son ensemble, mais la description des détails les plus visibles est une tâche difficile, et les résultats varient d'une personne à l'autre. Plusieurs fois, je ne pouvais rien imaginer d'autre qu'un visage très flou du personnage jusqu'à la fin du travail. Ce n'est que lorsque le livre est transformé en film que le visage flou se remplit de détails. Par exemple, je ne pourrais jamais imaginer à quoi ressemble le visage de Rachel dans le livre "
Girl on the Train ". Mais quand le film est sorti, j'ai pu faire correspondre le visage d'Emily Blunt avec le personnage de Rachel. Certes, les personnes impliquées dans la sélection des acteurs prennent beaucoup de temps pour représenter correctement les personnages du script.
Ce problème m'a inspiré et m'a motivé à trouver une solution. Après cela, j'ai commencé à étudier la littérature sur l'apprentissage profond à la recherche de quelque chose de similaire. Heureusement, il y a eu pas mal d'études sur la synthèse d'images à partir de texte. Voici certains de ceux sur lesquels j'ai bâti:
[les
projets utilisent des réseaux contradictoires génératifs, GSS (Generative adversarial network, GAN) / env. perev. ]
Après avoir étudié la littérature, j'ai choisi une architecture qui a été simplifiée par rapport à StackGAN ++ et qui résout assez bien mon problème. Dans les sections suivantes, je vais expliquer comment j'ai résolu ce problème et partager les résultats préliminaires. Je décrirai également certains des détails de la programmation et de la formation sur lesquels j'ai passé beaucoup de temps.
Analyse des données
Sans aucun doute, l'aspect le plus important du travail est les données utilisées pour former le modèle. Comme l'a dit le professeur Andrew Eun dans ses cours deeplearning.ai: «Dans le domaine de l'apprentissage automatique, ce n'est pas celui qui a le meilleur algorithme, mais celui qui a les meilleures données.» C'est ainsi qu'a commencé ma recherche d'un ensemble de données sur les visages avec de bonnes, riches et diverses descriptions textuelles. Je suis tombé sur différents ensembles de données - soit des visages, soit des visages avec des noms, soit des visages avec une description de la couleur et de la forme des yeux. Mais il n'y en avait pas dont j'avais besoin. Ma dernière option était d'utiliser
un premier projet - générer une description des données structurelles dans un langage naturel. Mais une telle option ajouterait du bruit supplémentaire à un ensemble de données déjà assez bruyant.
Le temps a passé et à un moment donné, un nouveau projet
Face2Text est apparu . Il s'agissait d'une collection d'une base de données de descriptions textuelles détaillées de personnes. Je remercie les auteurs du projet pour l'ensemble de données fourni.
L'ensemble de données contenait des descriptions textuelles de 400 images sélectionnées au hasard dans la base de données LFW (faces étiquetées). Les descriptions ont été nettoyées pour éliminer les caractéristiques ambiguës et mineures. Certaines descriptions contenaient non seulement des informations sur les visages, mais également des conclusions tirées sur la base des images - par exemple, «la personne sur la photo est probablement un criminel». Tous ces facteurs, ainsi que la petite taille de l'ensemble de données, ont conduit au fait que mon projet jusqu'à présent ne démontre que des preuves de l'opérabilité de l'architecture. Par la suite, ce modèle peut être adapté à un ensemble de données plus grand et plus diversifié.
L'architecture
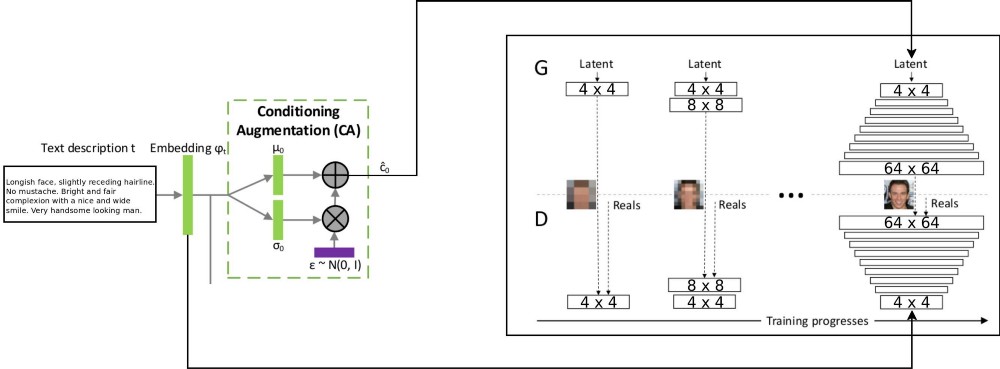
L'architecture du projet T2F combine deux architectures stackGAN pour l'encodage de texte incrémenté conditionnellement, et ProGAN (
croissance GSS progressive ) pour la synthèse d'images de visage. L'architecture stackgan ++ originale utilisait plusieurs GSS avec différentes résolutions spatiales, et j'ai décidé que c'était une approche trop sérieuse pour toute tâche de distribution de correspondance. Mais ProGAN n'utilise qu'un seul GSS, progressivement entraîné à des résolutions toujours plus détaillées. J'ai décidé de combiner ces deux approches.
Il y a une explication du flux de données: les descriptions de texte sont encodées dans le vecteur final par intégration dans le réseau LSTM (Embedding) (psy_t) (voir schéma). Ensuite, l'incorporation est transmise via le bloc d'augmentation de conditionnement (une couche linéaire) pour obtenir la partie texte du vecteur propre (en utilisant la technique de reparamétrisation VAE) pour le GSS en entrée. La deuxième partie du vecteur propre est le bruit gaussien aléatoire. Le vecteur propre résultant est envoyé au générateur GSS, et l'incorporation est envoyée à la dernière couche discriminante pour une distribution conditionnelle de la correspondance. La formation des processus GSS se déroule exactement comme dans l'article sur ProGAN - en couches, avec une augmentation de la résolution spatiale. Une nouvelle couche est introduite à l'aide de la technique de fondu pour éviter d'effacer les résultats d'apprentissage précédents.
Mise en œuvre et autres détails
L'application a été écrite en python en utilisant le framework PyTorch. J'avais l'habitude de travailler avec des packages tensorflow et keras, mais maintenant je voulais essayer PyTorch. J'ai aimé utiliser le débogueur python intégré pour travailler avec l'architecture réseau - tout cela grâce à la stratégie d'exécution précoce. Tensorflow a également récemment activé le mode d'exécution impatient. Cependant, je ne veux pas juger quel cadre est le meilleur, je veux juste souligner que le code de ce projet a été écrit en utilisant PyTorch.
Plusieurs parties du projet me semblent réutilisables, notamment ProGAN. Par conséquent, j'ai écrit un code séparé pour eux en tant
qu'extension du module PyTorch, et il peut également être utilisé sur d'autres ensembles de données. Il suffit d'indiquer la profondeur et la taille des caractéristiques de l'ESG. GSS peut être formé progressivement pour tout ensemble de données.
Détails de la formation
J'ai formé plusieurs versions du réseau en utilisant différents hyperparamètres. Les détails du travail sont les suivants:
- Le discriminateur n'a pas d'opérations par lot ou par couche, donc la perte de WGAN-GP peut croître de façon explosive. J'ai utilisé une pénalité de dérive avec lambda égale à 0,001.
- Pour contrôler votre propre diversité, obtenue à partir du texte encodé, il est nécessaire d'utiliser la distance Kullback - Leibler dans les pertes du générateur.
- Pour que les images résultantes correspondent mieux à la distribution de texte entrante, il est préférable d'utiliser la version WGAN du discriminateur (Matching-Aware) correspondant.
- Le temps de fondu pour les niveaux supérieurs doit dépasser le temps de fondu pour les niveaux inférieurs. J'ai utilisé 85% comme valeur de fondu lors de l'entraînement.
- J'ai trouvé que les exemples de résolution supérieure (32 x 32 et 64 x 64) produisent plus de bruit de fond que les exemples de résolution inférieure. Je pense que cela est dû au manque de données.
- Pendant un entraînement progressif, il est préférable de passer plus de temps sur des résolutions plus basses et de réduire le temps passé à travailler avec des résolutions plus élevées.
La vidéo montre le laps de temps du générateur. La vidéo est compilée à partir d'images de différentes résolutions spatiales obtenues lors de la formation du GSS.
Conclusion
Selon les résultats préliminaires, on peut juger que le projet T2F est réalisable et a des applications intéressantes. Supposons qu'il puisse être utilisé pour composer des photobots. Ou pour les cas où il faut booster l'imagination. Je continuerai à travailler sur la mise à l'échelle de ce projet sur des ensembles de données tels que Flicker8K, les légendes Coco, etc.
La croissance progressive de l'ESG est une technologie phénoménale pour une formation GSS plus rapide et plus stable. Il peut être combiné avec diverses technologies modernes mentionnées dans d'autres articles. GSS peut être utilisé dans différents domaines de MO.