Bonjour, Habr! Je m'appelle Sergey Prutskikh, je suis en charge de la direction de suivi de Sberbank-Technology. L'objectif principal de notre organisation est le développement et le test de produits logiciels pour Sberbank. Pour cela, la société dispose d'une grande infrastructure informatique - 15 000 serveurs sont répartis dans environ 1 500 environnements de test, qui sont liés à plus de 500 systèmes automatisés. Au total, environ 10 000 spécialistes travaillent avec eux.
En 2015, nous avons commencé à créer un service de surveillance centralisé. De plus, tout se limitait non seulement à la mise en œuvre. Il a fallu élaborer de nombreux règlements, instructions, ainsi que les relations entre les unités de Sbertech dans le cadre du suivi. Dans cet article, je vais vous expliquer en détail comment nous avons choisi la plate-forme, sur quels principes nous avons tout créé et avec quoi nous nous sommes retrouvés.

Les principaux objectifs et idéologie du projet
Voici les objectifs que nous avons poursuivis dans le cadre du projet:
- Obtenir des données fiables sur la taille et la composition de l'infrastructure informatique;
- Optimisation de l'utilisation des installations informatiques;
- Réduire les coûts de support et d'exploitation de l'infrastructure informatique des environnements de développement et de test;
- Prise en charge de l'infrastructure informatique prête pour le développement et les tests;
- Informer rapidement les spécialistes des problèmes dans le travail des environnements de test;
- L'audit de conformité des environnements de test et des AFM industriels n'est pas une tâche très courante pour nous;
- Collecte de données pour les rapports sur les résultats des tests, fournissant la mesure des paramètres critiques à toutes les étapes des tests.
Pour l'avenir, je peux dire que tous les objectifs à un degré ou à un autre ont déjà été atteints à ce jour. Et certains problèmes connexes, la surveillance ont également aidé à résoudre.
En plus des objectifs, nous avons formulé des principes, une idéologie, auxquels nous avons adhéré tout au long du projet:
- La satisfaction des utilisateurs est l'un des principaux indicateurs du suivi. Lors de la conférence ITSMf 2017, j'ai parlé de la surveillance de l'infrastructure informatique, et le cinquième N'EST PAS dans ce rapport: "NE FORCEZ PAS vos employés à travailler avec le système de surveillance." Il s'agit de motiver, pas d'obliger. Ceci est réalisé grâce à des KPI correctement construits. Au début du service, ces KPI peuvent ne pas encore apparaître. Néanmoins, il est très important dès les premiers jours de surveillance de commencer à bénéficier aux clients potentiels.
- Temps minimum de raffinement. Pour cela, nous utilisons des éléments Agiles. Ils aident à fournir de nouvelles fonctionnalités le plus rapidement possible et à recevoir les commentaires des clients.
- L'ouverture du système, à la fois pour les améliorations, qui se traduit par la création d'un seul backlog, les demandes auxquelles tout employé peut écrire, et en termes de fourniture d'informations - notre service vous permet d'obtenir des informations sur la configuration de surveillance, qui, en règle générale, est cachée.
- Haut degré d'intégration dans le travail quotidien. Notre priorité est de mettre en œuvre quotidiennement les fonctionnalités dont les utilisateurs ont besoin. Cela a contribué en peu de temps à populariser le service de surveillance au sein de l'entreprise.
Le choix du système de surveillance
Dans presque tous les projets auxquels j'ai participé, tôt ou tard, un tableau est apparu comparant les fonctionnalités de divers systèmes, dans lesquels un système particulier avait un avantage évident.
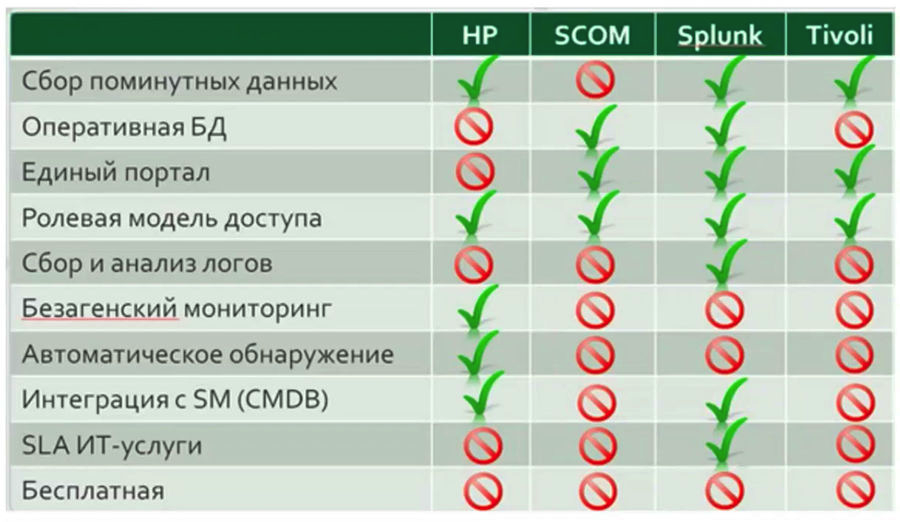
À mon avis, une telle analyse comparative
ne peut être effectuée avant le début immédiat de la collaboration avec le service de surveillance, et plus encore, il ne vaut pas la peine de prendre une décision sur le choix de l'une ou l'autre solution sur la base de cette analyse. Tant que le système de votre entreprise ne fonctionne pas pendant au moins une courte période, il est impossible de juger sans ambiguïté quelles fonctions spécifiques de votre entreprise seront demandées. Ces tableaux peuvent vous aider si vous souhaitez changer le système de surveillance pour une raison quelconque.
Comparaison avec d'autres installations Zabbix
Vous pouvez beaucoup parler de la façon de comparer la taille de plusieurs installations de systèmes de surveillance, mais toutes les caractéristiques sélectionnées pour cela, à mon avis, sont assez subjectives. Afin que vous ayez une idée plus précise de la taille de notre installation, j'ai décidé de donner des exemples de services similaires dans d'autres entreprises, dont les représentants de Zabbix ont parlé lors de la conférence Highload.
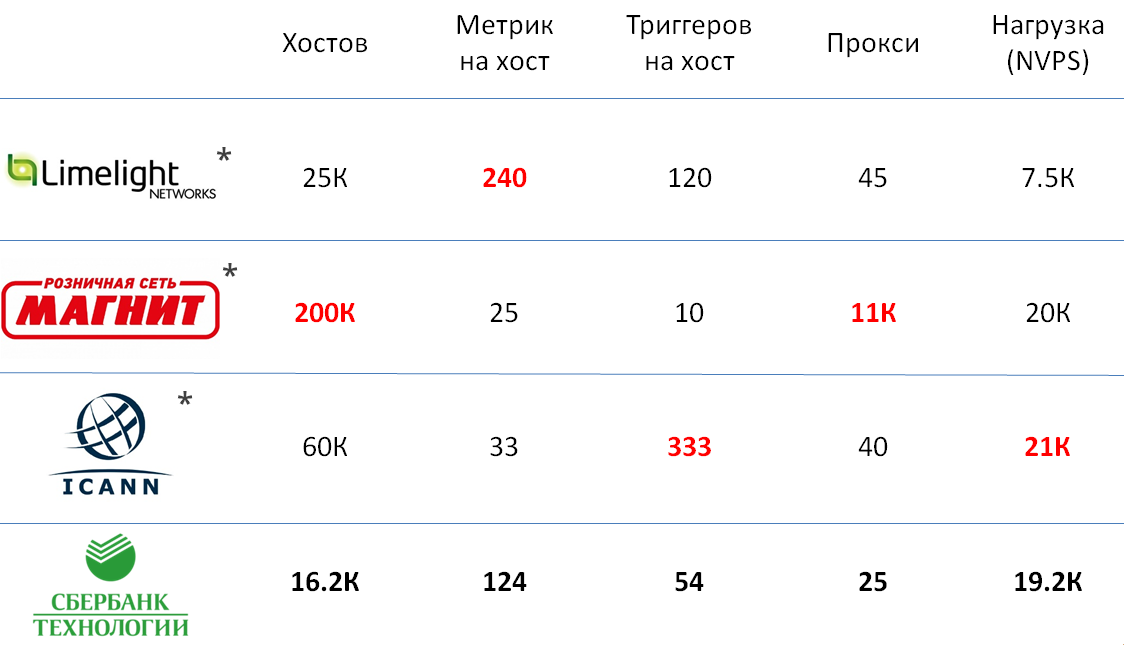
Comme vous pouvez le voir, l'instance Zabbix dans Sbertech n'est pas beaucoup inférieure aux plus grandes installations, et en termes de charge totale, elle est à égalité avec elles.
Avantages de Zabbix
Au second semestre 2017, nous avons mené un pilote Zabbix pour surveiller l'infrastructure PROM. Nous avons ensuite formulé un certain nombre de critères qualitatifs que nous attribuons aux avantages absolus de Zabbix:
- Open source Possibilités illimitées de traitement et de personnalisation.
- Ouverture du mécanisme et source de collecte des métriques. Dans les solutions d'entreprise commerciale, de nombreuses mesures sont incompréhensibles - divers réseaux de zombies, fuites de mémoire, que même le support technique du fournisseur ne peut souvent pas expliquer. Zabbix n'a pas un tel problème - vous pouvez toujours dire clairement comment il collecte certaines métriques. Ainsi, la crédibilité du système par les administrateurs système augmente.
- Facilité de mise à l'échelle relative - principalement en raison de l'introduction de serveurs proxy supplémentaires, auxquels vous pouvez transférer une partie de la charge. Si vous atteignez la limite de performance d'une instance, il est possible d'augmenter la seconde et de combiner les deux sous un système de visualisation (Grafana).
- API cool - à mon avis, c'est l'un des principaux avantages de Zabbix. Une API de haute qualité, bien développée et compréhensible ouvre d'énormes possibilités d'intégration avec les systèmes connexes, l'automatisation, etc.
- La surveillance des objets dynamiques est une bagatelle, mais agréable. Dans Zabbix, cette surveillance est simple et intuitive, vous permettant d'obtenir de bons résultats très rapidement. Les objets dynamiques sont tous les objets qui apparaissent et disparaissent sur les serveurs au cours de leur durée de vie: systèmes de fichiers, interfaces réseau et autres. Par conséquent, il est nécessaire d'automatiser la définition et la suppression de ces objets de la surveillance.
- Un nombre relativement faible de composants. Dans les solutions commerciales, chaque composant est un sous-système distinct avec sa propre base, qui doit être installé séparément. Et Zabbix est un système unique, dans lequel toutes les méthodes de surveillance sont concentrées à la fois: agent, sans agent, réseau et autres - seulement 14 types.
- Visualisation des données avec Grafana. L'intégration avec Grafana permet de construire des graphiques et de créer des tableaux de bord vraiment pratiques.
- Disponibilité du suivi de la disponibilité des services informatiques. Zabbix dispose d'un sous-système intégré qui peut calculer la disponibilité des services informatiques pour une utilisation future dans SLA.
- La flexibilité de créer des métriques et leurs valeurs de seuil. Ici, Zabbix a amplement l'occasion de configurer des mesures de surveillance complexes:
- Tout d'abord, c'est la création de métriques calculées : sur la base de plusieurs métriques simples, une complexe est calculée.
- le prétraitement de la valeur des métriques est disponible - c'est, par exemple, lorsque vous chargez un grand tableau de données dans Zabbix, puis, avant de mettre une métrique spécifique dans la base de données, Zabbix analyse le tableau et extrait exactement les données que vous souhaitez enregistrer en tant que métrique .
- métriques principales. Il est possible de collecter un tableau de données sur un objet dans une enquête dans une grande métrique, puis de l'utiliser comme source de données pour d'autres métriques. Cela vous permet de réduire le nombre de requêtes et de synchroniser la collecte de toutes les métriques dans le temps.
- Possibilité de surveillance interne. Zabbix, en tant que produit open source, a des problèmes de performances. Cependant, un système de surveillance interne bien pensé permet de résoudre rapidement ces problèmes.
Inconvénients de Zabbix
En toute honnêteté, je ne peux m'empêcher de mentionner les principaux, à mon avis, les lacunes de Zabbix. Vous pouvez également en faire une liste décente:
- Faible degré d'automatisation du backend. Je ferai une réservation que je n'ai pas eu l'occasion d'expérimenter avec toutes les variantes du SGBD. Notre entreprise utilise le SGBD Oracle comme backend Zabbix. Les opérations de masse peuvent prendre plus d'une heure - par exemple, la mise à jour ou la modification des mesures, qui est liée à un grand nombre d'objets (15 000 nœuds de réseau).
- Manque d'outils de gestion des agents de surveillance intégrés. Ces produits sont disponibles dans des produits commerciaux. Zabbix ne l'a pas encore. Il n'y a même pas de mise à jour de la boîte à outils pour les agents. Bien sûr, tout peut être fait indépendamment, mais il serait préférable de sortir ces fonctionnalités de la boîte.
- Jusqu'à présent, faible élaboration du suivi de la disponibilité des services informatiques. C'est formidable qu'il y ait un suivi, mais il doit être développé davantage. Désormais, il n'est plus possible de restreindre l'accès des utilisateurs à des parties individuelles du modèle de ressource de service (ci-après CPM). Si l'arborescence CPM est grande, l'interface Web commence à ralentir. Et les possibilités de personnalisation du calcul de disponibilité dans ce sous-système sont encore faibles.
- Longues mises à jour. La dernière mise à jour de la base de données nous a pris environ huit heures. À ce moment, le service de surveillance n'était pas disponible. Alternativement, vous pouvez demander des scripts de support et mettre à jour séparément.
- La modeste fonctionnalité du sous-système de visualisation intégré. Grafana résout ce problème, mais la visualisation intégrée laisse beaucoup à désirer.
- Surveillance intégrée du SGBD (ODBC). Le fait est qu'une telle surveillance ouvre une connexion distincte pour Zabbix chaque fois que la métrique est interrogée. Et si votre base de données est volumineuse (avec un grand nombre de mesures collectées), le pool de connexions peut devenir saturé et la base de données cessera de répondre, y compris pour les systèmes cibles. Zabbix dispose d'un outil de surveillance alternatif (par exemple, DBforBIX), mais sa configuration pour un grand nombre d'objets est une tâche assez laborieuse. De plus, pour cela, vous devez écrire une automatisation distincte.
- Manque de flexibilité des stocks pour l'infrastructure informatique. D'une part, c'est bien de l'avoir. D'un autre côté, il ressemble à un onglet distinct pour tout objet de surveillance sur lequel il existe un ensemble de champs d'inventaire avec des noms codés en dur. Pour changer quelque chose, vous devez entrer dans le code source du frontend. Il est également impossible de modifier le nombre de ces champs et tailles - il y a un risque de casser quelque chose lors de la prochaine mise à jour.
- Manque d'automatisation pour la construction de cartes réseau. À titre de comparaison, nous pouvons citer HP OpenView Network Node Manager, qui est parfaitement capable de créer des cartes de topologie de réseau en mode automatique. Zabbix devra tout construire manuellement. Peut-être, pour cette raison, cette fonctionnalité n'est pratiquement pas demandée parmi nous.
- Manque de flexibilité dans le modèle de rôle. Zabbix ne fournit que quatre rôles d'utilisateur avec des capacités fixes. En outre, il n'y a aucun moyen de restreindre l'accès des utilisateurs à l'API Zabbix. Autrement dit, si l'utilisateur a accès au frontend, il a automatiquement accès à l'API. Pour nous, cela a conduit au fait que les utilisateurs avec des demandes incompétentes ont sérieusement chargé le système. De plus, il n'y a aucun moyen de donner à l'utilisateur un accès, par exemple, pour lire des métriques sans accès, pour modifier les paramètres de l'objet de surveillance.
Architecture du système
Maintenant, quelques mots sur les indicateurs quantitatifs et l'architecture de notre système.
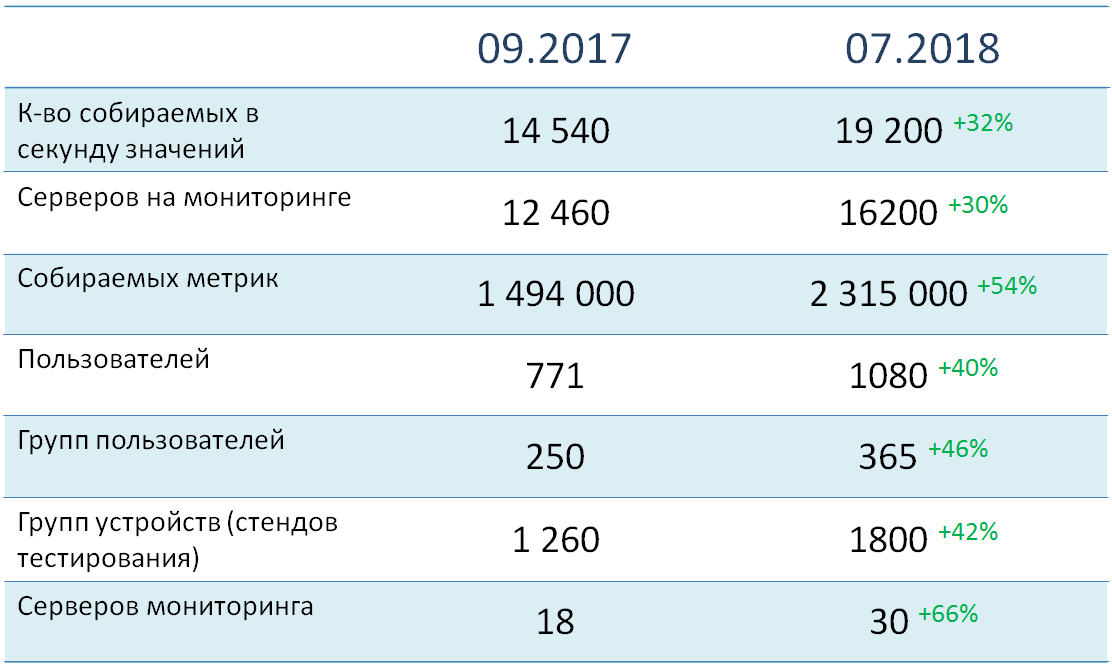
À l'heure actuelle, plus de 16 000 objets (principalement des serveurs) sont sous surveillance, à partir desquels près de deux millions et demi de mesures sont collectées au total. Leur charge totale sur le système est d'environ 19 000 valeurs par seconde. Tous les objets de surveillance sont répartis sur plus de 1800 groupes d'appareils, dont la grande majorité correspond à des environnements de test spécifiques. Actuellement, plus de 1000 utilisateurs sont enregistrés dans le système, qui sont divisés en 365 groupes fonctionnels.
Comme vous pouvez le voir, nous accordons beaucoup d'attention à la distribution des appareils et des utilisateurs en groupes. Cela vous permet d'augmenter considérablement la précision des alertes de notre service.
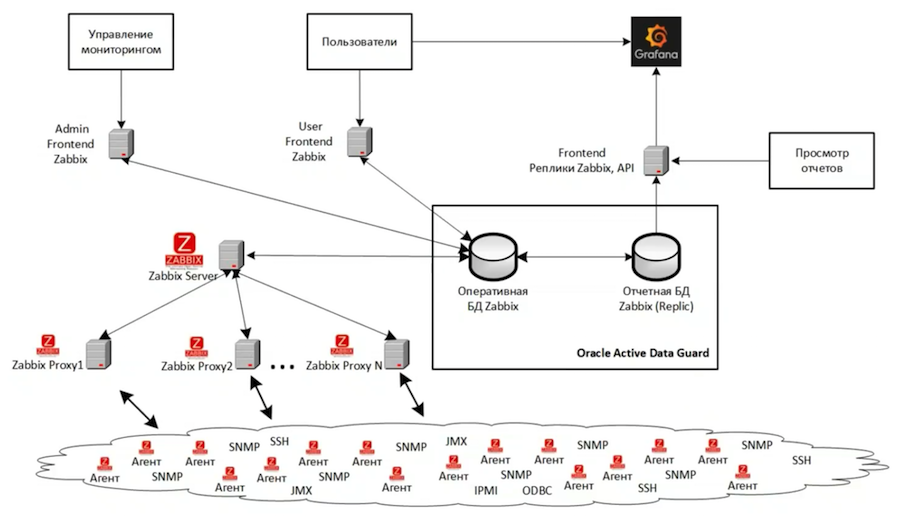
Au total, nous avons trois instances Zabbix. Le diagramme montre l'architecture du plus grand d'entre eux, qui surveille la principale infrastructure informatique de développement et de test. Une autre instance supervise l'infrastructure de surveillance. Et la troisième instance est utilisée avec nous pour le développement et le test de nouveaux outils de surveillance. La structure entière de l'instance principale est virtualisée sur la base de VMWare. En général, si possible, il est préférable de ne pas utiliser de système de virtualisation, car il est beaucoup plus difficile de rechercher et de résoudre les problèmes de performances dans le cas d'une infrastructure virtuelle.
Le backend est basé sur Oracle Active Data Guard et se compose de deux bases de données - la principale et la réplique. Nous avons trois fronts:
- Pour les tâches administratives - il est configuré pour effectuer des opérations lourdes, complexes et à long terme qui chargent fortement le serveur;
- Personnalisé - avec des réglages plus stricts qui ne permettent pas aux utilisateurs de surcharger trop le système de surveillance principal;
- Pour les rapports, il examine la réplique et a été adapté pour interagir avec des bases de données en lecture seule. Grafana y est connecté, offrant une visualisation de haute qualité des données de surveillance.
Caractéristiques d'implémentation
Dans cette histoire, j'ai décidé de ne pas me concentrer sur les fonctionnalités de base qui sont implémentées dans presque toutes les surveillances - correction des plantages, collecte d'informations sur les performances ou la disponibilité des systèmes informatiques. Je vais me concentrer sur les caractéristiques distinctives de notre service.
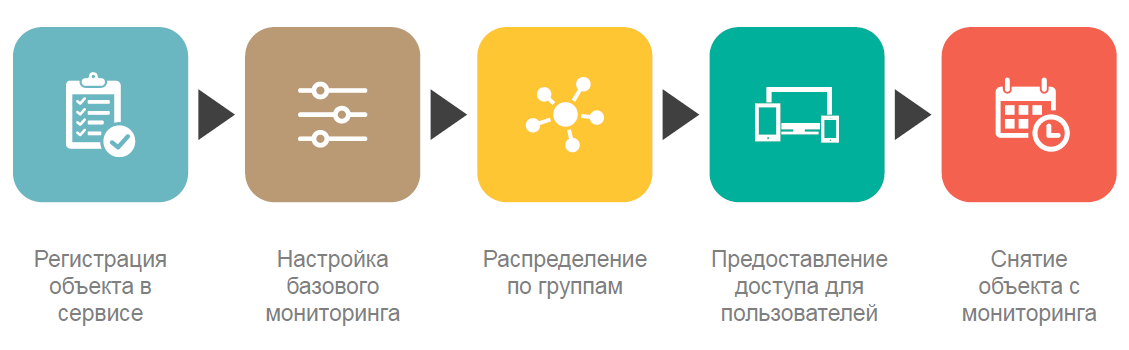
Ces fonctionnalités incluent principalement un degré élevé d'automatisation des tâches typiques. Nous ne passons pratiquement pas de temps à configurer des serveurs pour la surveillance, à fournir un accès aux résultats de la surveillance, mais nous nous concentrons principalement sur le développement du service et l'ajout de nouvelles fonctionnalités non standard. Plus de 200 scripts d'automatisation développés à partir du moment où le service de surveillance a été mis à l'essai nous aident grandement à cet égard.
Mais avant d'enregistrer l'agent dans Zabbix, il doit encore être installé. Comme je l'ai écrit ci-dessus, l'un des inconvénients de Zabbix est le manque d'outils de gestion des agents de surveillance. Par conséquent, pour installer des agents, nous avons organisé un travail distinct dans le cadre de nos processus DevOps. La figure ci-dessous montre le schéma d'installation de l'agent.
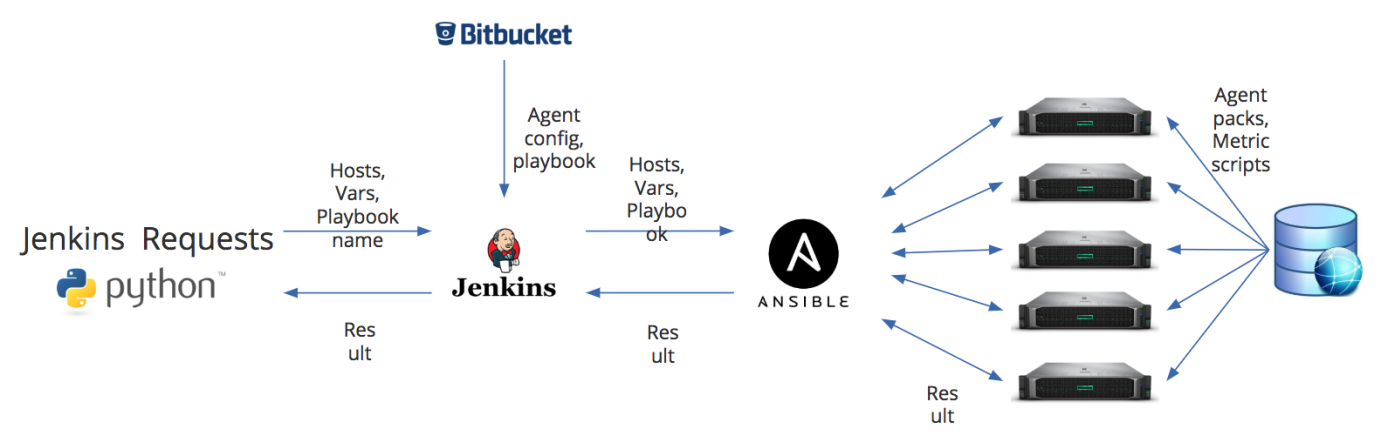
Nous avons deux points d'entrée principaux. Il s'agit soit d'un script Python - via l'API REST, il transmet au job Jenkins des informations sur les hôtes sur lesquels vous souhaitez installer ou mettre à jour l'agent, une liste de variables supplémentaires, ainsi que le nom du playbook que vous devez exécuter sur Ansible. Ou les données par défaut peuvent provenir de Bitbucket. Mais dans Jenkins, ils peuvent être complètement remplacés en fonction des variables que nous avons passées. Et cela nous aide, par exemple, à mettre à jour des agents surveillés par différents serveurs proxy. La particularité de notre processus est que la configuration de l'agent Zabbix se forme presque à la volée.
Rapports
Déjà au début du projet, il est devenu clair que les outils de reporting standard fournis par les outils Zabbix ne nous permettraient pas de répondre à tous nos besoins. À cet égard, sur la base de l'architecture de microservices, un sous-système de rapport distinct a été mis en œuvre, ce qui élargit considérablement les capacités des rapports de surveillance de base. Nous avons maintenant plus de vingt rapports en service. Voici quelques exemples ainsi que les objectifs qui sont mis en œuvre:

Alertes
Tout au long du travail du service, les alertes email ont évolué. Voici à quoi ils ressemblent en ce moment:
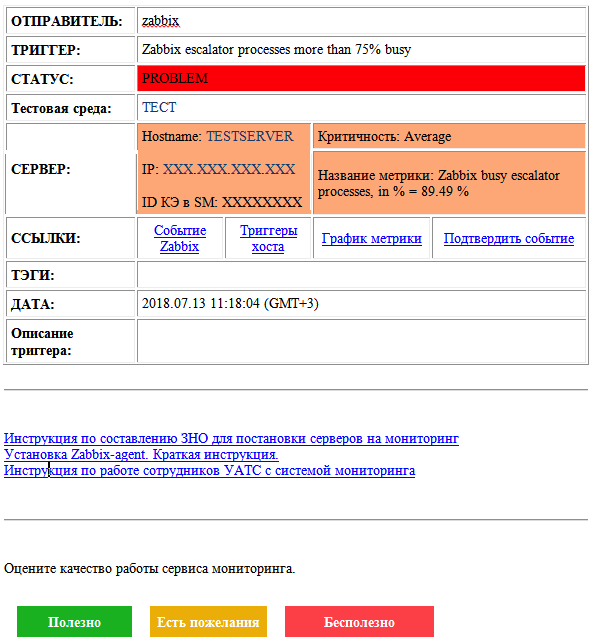
Il y a des informations sur le problème et son état, ainsi que sur l'objet de surveillance. Il y a des liens vers des mesures et des événements connexes, un champ pour décrire le problème, des liens vers des instructions et un formulaire de rétroaction. Pour les accidents plus critiques, nous avons bien sûr également une distribution SMS.
Ces alertes informatives nous ont permis de minimiser la communication de la plupart de nos utilisateurs avec Zabbix lui-même. Il suffit de recevoir cette liste de diffusion. Nous avons bien regroupé les utilisateurs - il y a 365 groupes pour 1080 personnes. Par conséquent, le bulletin d'information s'avère assez pointillé - et, par conséquent, pas ennuyeux. Beaucoup de nos utilisateurs ont presque oublié que nous avons, en fait, Zabbix - ils utilisent la newsletter Grafana et le système de visualisation.
Intégration avec les processus de gestion
Le projet consistait initialement à surveiller l'intégration avec certains de nos processus de gestion de l'infrastructure informatique. Si le service de surveillance a enregistré un accident, vous pouvez créer un ticket pour celui-ci - pour les équipes qui travaillent davantage avec Jira. Pour les services, il est possible de créer des incidents dans HP Service Manager:

Basée sur Zabbix, une méthodologie d'optimisation de l'utilisation de l'infrastructure informatique a également été développée et automatisée. Trois paramètres principaux sont optimisés: la quantité de CPU, de RAM et de disques durs. Cette technique fonctionne sur la base d'une moyenne mobile et d'un percentile à 90%. Sur la base de cette technique, tout objet ou serveur appartient à l'une des trois catégories: sous-chargé, chargé de manière optimale, surchargé.
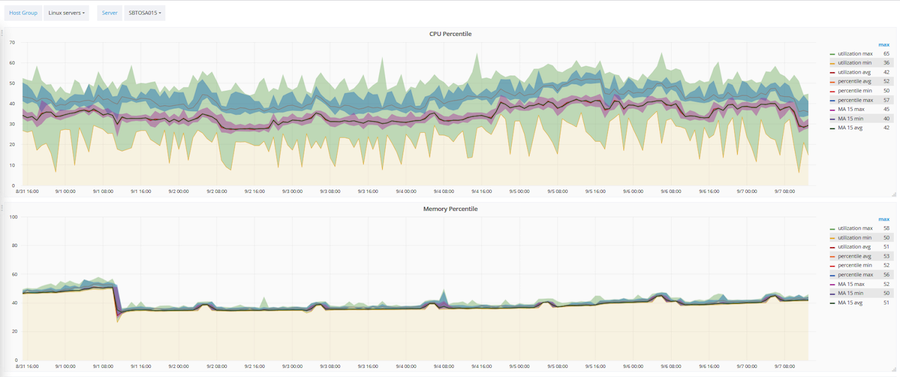
Ce qui précède montre comment cette technique est appliquée à un serveur spécifique. Le couloir rose est la valeur de la moyenne mobile. Large couloir vert - données brutes. Et le bleu est un percentile à 90%.
L'intégration à la base de données de configuration a permis d'automatiser la plupart des tâches associées à la fourniture d'accès et à la création d'un modèle de service-ressource. , . , , , .
Zabbix . , .
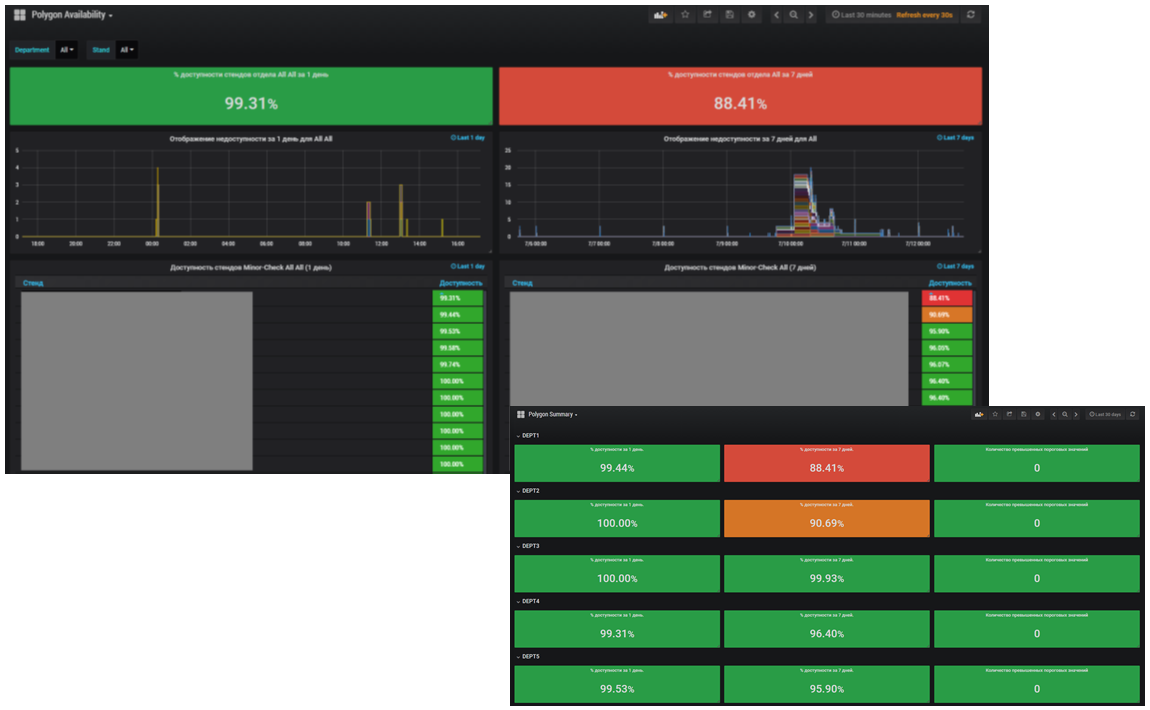
, . , . .
, . 2017 :
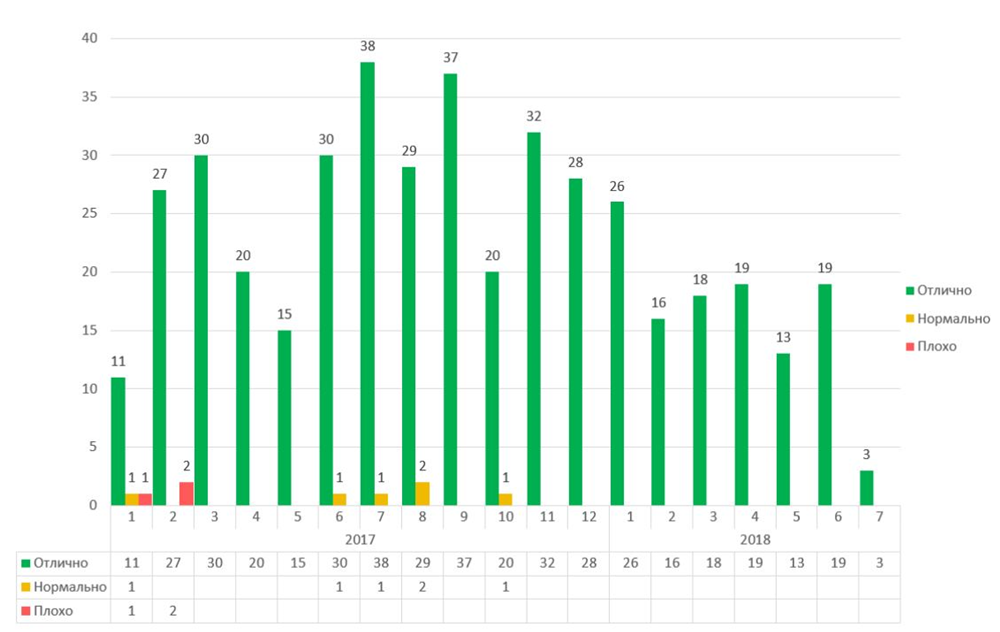
2017 .
, :
, . 70% . , , , .
2016 . . , , .
2016 . - , . . ,
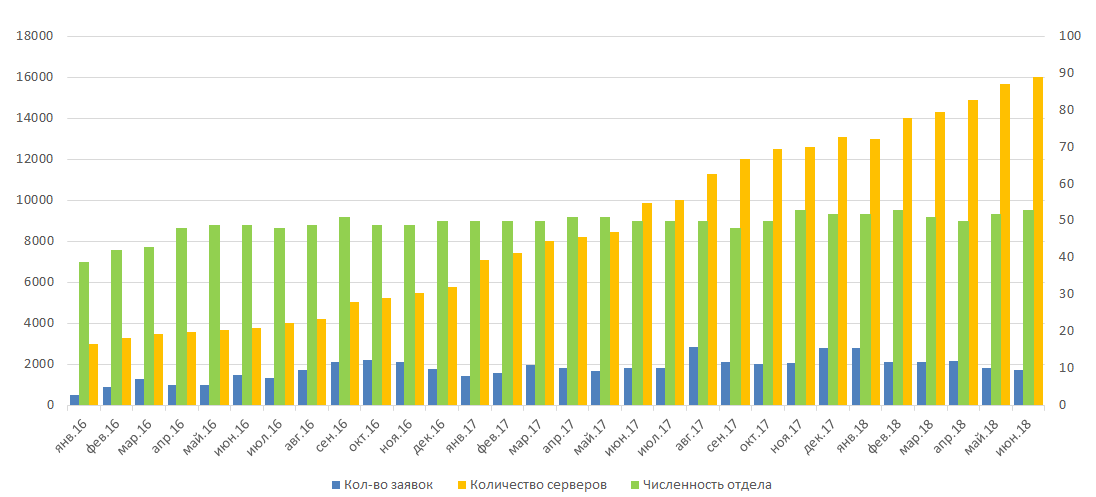
2016 , : 600 CPU, 7,5 50 .