Bonjour à tous! Cette fois, je veux écrire comment j'ai réussi à gagner la compétition
Mini AI Cup 2 . Comme dans mon
dernier article , il n'y aura pratiquement aucun détail de mise en œuvre. Cette fois, la tâche était moins volumineuse, mais il y avait néanmoins beaucoup de nuances et de petites choses qui affectaient le comportement du bot. En conséquence, même après près de trois semaines de travail actif sur le bot, il y avait encore des idées sur la façon d'améliorer la stratégie.
Sous la coupe, beaucoup de gifs et de trafic.
Les persévérants le découvriront, les autres s'enfuiront avec horreur (d'après les commentaires sur la brève partie compressée).Ceux qui sont trop paresseux pour lire beaucoup peuvent aller à l'avant-dernier spoiler de l'article pour voir une brève description concise de l'algorithme , puis vous pouvez commencer à lire depuis le début .Lien vers la source
sur le github .
Sélection d'outils
Comme la dernière fois, il m'a fallu beaucoup de temps pour réfléchir par où commencer. Le choix s'est fait, entre autres, entre deux langages: Java, familier pour moi, et déjà assez oublié des jours étudiants C ++. Mais comme dès le début il me semblait que le principal obstacle à l'écriture d'un bon bot ne serait pas tant la vitesse de développement que la productivité de la solution finale, le choix s'est néanmoins porté en C ++.
Après l'expérience réussie d'utiliser mon propre visualiseur pour déboguer le bot lors des compétitions précédentes, je ne voulais pas m'en passer cette fois aussi. Mais le visualiseur que j'ai écrit moi-même sur Qt pour
CodeWars ne ressemblait pas à une solution idéale pour moi, et j'ai décidé d'utiliser
ce visualiseur. Il a également été réalisé sous CodeWars, mais n'a pas nécessité de traitement sérieux pour être utilisé dans ce concours. La relative simplicité de connexion et la commodité d'invoquer le rendu n'importe où dans le code jouaient en sa faveur.
Comme auparavant, je voulais vraiment déboguer n'importe quel tick du jeu - la possibilité d'exécuter une stratégie à un moment arbitraire du jeu testé. Étant donné que le visualiseur de plug-in n'a pas pu résoudre ce problème, à l'aide de la paire #ifdef (dans laquelle j'ai également encapsulé les morceaux de code responsables du rendu), j'ai ajouté à chaque tick l'enregistrement de la classe Context, qui contenait toutes les valeurs nécessaires des variables de la tick précédente. À la base, la solution était similaire à celle que j'utilisais dans Code Wizards, mais cette fois, l'approche n'était pas si spontanée. Après avoir simulé l'intégralité du jeu, il vous a été demandé de saisir le numéro du tick du jeu, qui doit être redémarré. Des informations sur l'état des variables avant ce tick ont été prises dans le tableau, ainsi que la ligne reçue par la stratégie d'entrée, ce qui m'a permis de jouer les mouvements de ma stratégie dans n'importe quel ordre nécessaire.
Commencer
Le jour de l'ouverture des règles, je ne suis pas passé et le premier soir j'ai regardé ce qui nous attend. Il n'a pas hésité à s'indigner du format d'entrée json (oui, c'est pratique, mais certains participants commencent à apprendre de nouveaux PJ anciens ou oubliés depuis longtemps dans de telles compétitions, et commencer par l'analyse json n'est pas le plus agréable), a examiné l'étrange formule de mouvement et a commencé à former le cadre de l'avenir stratégies (pour comprendre l'article à l'avenir, il est utile de lire les
règles ). Pendant 2 jours, j'ai écrit un tas de cours comme Ejection, Virus, Player et autres, lisant json, connectant une bibliothèque à fichier unique pour la journalisation ... Et le soir de l'ouverture d'un bac à sable non classé, j'avais déjà une stratégie qui était presque identique en principe au C ++, mais significativement, un code beaucoup plus grand.
Et puis ... j'ai commencé à trouver des options, comment les développer. Réflexions à l'époque:
- La recherche des états du monde ne peut être réduite à ces valeurs qui peuvent dominer le minimax et les modifications;
- Les champs potentiels sont bons, mais ils répondent mal à la question de savoir comment le monde changera les n tics suivants;
- La génétique et des algorithmes similaires fonctionneront, mais seulement 20 ms sont donnés par coup, et la profondeur de calcul serait souhaitable, à première vue, plus que les sensations ne peuvent être traitées en utilisant le GA. Oui, et vous pouvez jouer avec la sélection des paramètres de mutation «avec bonheur pour toujours».
J'ai définitivement décidé une chose: nous devons faire une simulation du monde. Après tout, les calculs approximatifs peuvent-ils «battre» un calcul froid et précis? De telles considérations, bien sûr, m'ont incité à examiner le code qui était censé être responsable de la simulation du monde sur le serveur, car cette fois il a été mis dans le domaine public avec les règles. Après tout, il n'y a rien de mieux que du code qui devrait décrire avec précision les règles du monde?
J'ai donc pensé exactement jusqu'à ce que je commence à étudier le code qui était censé tester nos bots sur le serveur et localement. Initialement, en termes de compréhensibilité et d'exactitude du code, tout n'était pas très bon, et les organisateurs, avec les participants, ont commencé à le traiter activement. Pendant le test bêta (capture quelques jours après), les changements dans le moteur de jeu ont été très graves, et beaucoup n'ont commencé à participer qu'au moment où le moteur de test ne se stabilise pas. Mais au final, à mon avis, ils ont attendu un moteur qui fonctionne bien pour un jeu très adapté au format compétition. Je n'ai pas non plus commencé à mettre en œuvre d'approches sérieuses jusqu'à ce que le coureur local se stabilise, et pendant la première semaine, rien de plus sensé n'a été fait dans mon bot, à l'exception du visualiseur vissé.
La veille du premier week-end du télégramme, les organisateurs ont créé un groupe distinct dans lequel il était supposé que les gens seraient en mesure d'aider à corriger et à améliorer le coureur local. J'ai également participé aux travaux sur le moteur du monde. Après des discussions dans ce chat, en tant que test, j'ai fait 2 demandes de tirage aux paramètres régionaux du coureur: ajuster la formule
alimentaire (et de petits changements dans l'ordre de manger) aux règles, et fusionner plusieurs parties en une seule agaric tout en
maintenant l'inertie et le centre de masse ). Ensuite, j'ai commencé à réfléchir à la façon d'insérer une physique de collision saine dans ce code, car la physique présente dans le monde du jeu à cette époque fonctionnait très illogiquement. Les collisions entre les deux agarics n'étant pas décrites dans le règlement, j'ai demandé aux organisateurs des critères selon lesquels ma mise en place d'une telle logique serait acceptable. La réponse était la suivante: les agarics dans une collision devraient être «mous» (c'est-à-dire qu'ils pourraient se heurter un peu), tandis que la logique d'une collision avec les murs ne devrait pas être touchée (c'est-à-dire que les murs devraient simplement arrêter les agarics, mais pas les repousser). Et ma prochaine
demande de traction a été une sérieuse altération de la physique.
Avant et après altération de la physiqueCette physique de collision était: Et elle le devint après les mises à jour:
Et elle le devint après les mises à jour:
Je voudrais également souligner
cette demande de tirage, qui a considérablement réduit le code déroutant avec l'analyse d'état et un grand nombre de bogues trouvés (et potentiels) en quelque chose de beaucoup plus intelligible.
Écrire une simulation
Après avoir apporté le code des paramètres régionaux du coureur sous une forme saine, j'ai progressivement commencé à transférer le code de simulation mondiale des paramètres régionaux du coureur vers mon bot. Tout d'abord, c'était bien sûr un code pour simuler le mouvement des agarics, et en même temps un code pour calculer la physique des collisions. Il a fallu quelques soirées pour sauver le code repensé des bogues de réécriture (le transfert logique n'a pas été fait du tout en copiant le code) et des estimations approximatives de la profondeur des calculs.
La fonction de notation pour chaque tick à ce moment était +1 pour la nourriture que je mange et -1 pour la nourriture mangée par l'ennemi, ainsi que des valeurs légèrement plus élevées pour manger les agarics les uns des autres. Dans les constantes pour manger d'autres agarics, il y avait initialement une différence entre manger mon adversaire, mon adversaire (et, bien sûr, une très grosse amende pour avoir mangé ma dernière agarika par l'adversaire), ainsi que deux adversaires différents l'un de l'autre (après quelques jours le dernier coefficient est devenu 0). De plus, la vitesse totale pour tous les ticks précédents de la simulation, chaque tick a été multipliée par 1 + 1e-5 pour encourager mon bot à effectuer des actions plus utiles au moins un peu plus tôt, et à la fin de la simulation, la vitesse du dernier tick a été ajoutée en bonus, également très petite . Pour simuler le mouvement des agarics, des points ont été sélectionnés sur le bord de la carte avec un pas de 15 degrés par rapport aux coordonnées arithmétiques moyennes de tous mes agarics, et un point a été sélectionné lors de la simulation du mouvement auquel la fonction d'estimation a pris la plus grande valeur. Et déjà avec une simulation aussi primitive et une évaluation simple à l'époque, le bot s'est en toute confiance retranché dans le top 10.
Démonstration de points, la commande de mouvement à laquelle l'algorithme a simulé à l'origine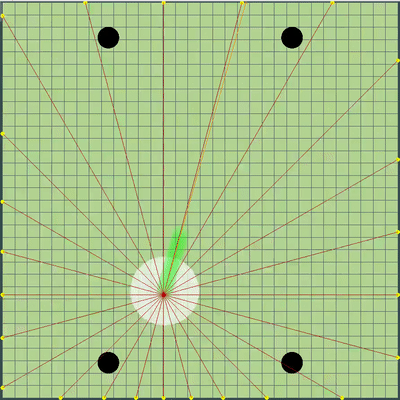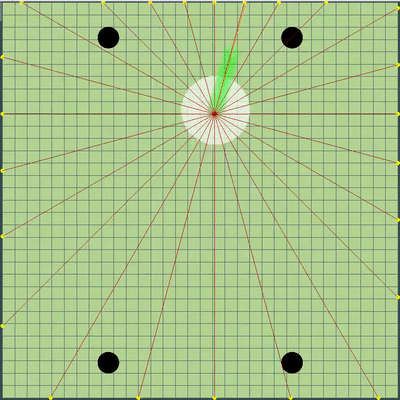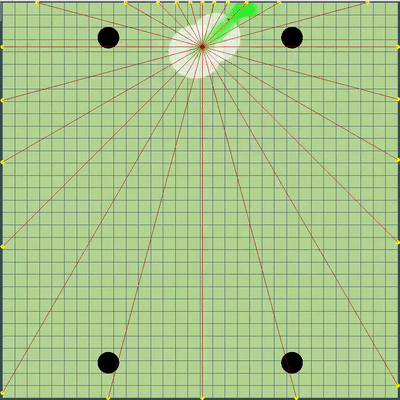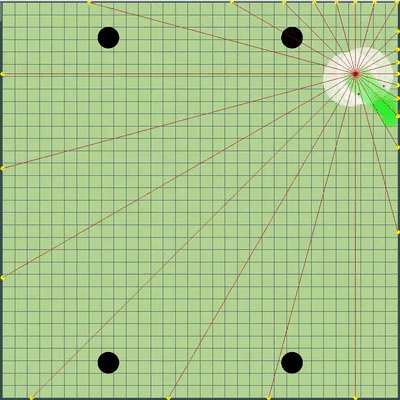 Points, dont l'ordre de mouvement a été donné lors de différentes simulations. Si vous regardez de très près - la commande finale donnée est parfois décalée par rapport aux points recherchés, mais ce sont les conséquences de modifications futures.
Points, dont l'ordre de mouvement a été donné lors de différentes simulations. Si vous regardez de très près - la commande finale donnée est parfois décalée par rapport aux points recherchés, mais ce sont les conséquences de modifications futures. Au cours de la soirée de vendredi et samedi, une simulation de fusion d'agarics, une simulation de «sape» sur les virus, et de deviner le TTF de l'adversaire a été ajoutée. Le TTF de l'adversaire était une valeur calculée assez intéressante, et il était possible de comprendre à quel point l'adversaire a fait une scission ou atteint le virus uniquement en saisissant le moment du vol incontrôlé, qui pourrait durer à partir d'un très petit nombre de tiques avec une grande viscosité et jusqu'au vol à travers toute la carte. Étant donné que les collisions agariques pouvaient entraîner un léger excès de leur vitesse maximale, pour calculer le TTF de l'adversaire, j'ai vérifié que sa vitesse en deux ticks d'affilée correspond vraiment à la vitesse à laquelle vous pouvez obtenir deux ticks d'affilée en vol libre (en vol libre, les agarics volaient strictement en ligne droite et avec ralentissement de chaque tique strictement égal à la viscosité). Cela a presque complètement éliminé la possibilité de faux positifs. De plus, lors du test de cette logique, j'ai remarqué qu'un TTF plus grand correspond toujours à un identifiant plus grand de l'agaric (dont j'ai été plus tard convaincu lors du transfert du code d'
explosion sur le virus et du
traitement de la division ), ce qui valait également la peine d'être utilisé.
Après avoir examiné les divisions constantes dans le top 3 (ce qui leur a permis de collecter de la nourriture de manière significative sur la carte), comme test, j'ai ajouté une commande de division permanente au bot s'il n'y avait pas d'ennemi dans le rayon de visibilité, et dimanche matin, j'ai trouvé mon bot sur la deuxième ligne de la note. Gérer une poignée de petites agarics a considérablement augmenté le classement, mais les perdre était beaucoup plus facile si vous tombez sur un adversaire. Et comme la peur d'être mangée par mes agarics était très conditionnelle (la peine était seulement pour manger dans une simulation, mais pas pour approcher un adversaire qui pouvait manger), la première chose a été ajoutée une pénalité pour traverser avec un adversaire qui pouvait manger. Et cette même évaluation a fonctionné comme un bonus pour chasser un adversaire. Après avoir vérifié la consommation du processeur avec ma stratégie, j'ai décidé d'ajouter un tour de simulation supplémentaire lorsque le fractionnement a été effectué lors du premier tick (cette logique, bien sûr, a également dû être transférée vers mon code à partir des paramètres régionaux du runner), puis la simulation s'est déroulée exactement comme avant. . Ce type de logique n'était pas très approprié pour "tirer" sur l'ennemi (bien que parfois par accident, il se fendait à un moment très approprié), mais il était très bon pour collecter de la nourriture plus rapidement, ce que faisait tout le haut à ce moment-là. De telles modifications nous ont permis d'entrer la semaine prochaine sur la première ligne de la notation, bien que la marge ne soit pas significative.
À cette époque, cela suffisait, la «colonne vertébrale» de la stratégie était élaborée, la stratégie semblait assez primitive et extensible. Mais ce que j'ai vraiment remarqué, c'est la consommation du processeur et la stabilité globale du code. Par conséquent, les soirées de la prochaine partie de la semaine de travail ont été principalement consacrées à l'amélioration de la précision des simulations (ce que le visualiseur a beaucoup aidé), à la stabilisation du code (valgrind) et à certaines optimisations de la vitesse de travail.
Allons de l'avant
Ma prochaine stratégie envoyée, qui a montré un résultat nettement meilleur et devançait les adversaires (à l'époque), contenait deux changements importants: ajouter un champ potentiel pour collecter de la nourriture et doubler le nombre de simulations s'il y a un adversaire avec un TTF inconnu à proximité.
Le champ potentiel de collecte de nourriture dans la première version était assez simple et son essence était de se souvenir de la nourriture qui avait disparu de la zone de visibilité, réduisant le potentiel dans les endroits près du bot ennemi et mettant à zéro dans ma zone de visibilité (avec restauration ultérieure tous les n tiques conformément aux règles). Cela semblait être une amélioration utile, mais dans la pratique, à mon avis subjectif, la différence était soit faible, soit complètement absente. Par exemple, sur des cartes à forte inertie et vitesse, le bot sautait souvent la nourriture et tentait ensuite d'y revenir, tout en perdant beaucoup de vitesse. Cependant, s'il décidait de maintenir la vitesse et ignorait simplement la nourriture sautée, il mangerait beaucoup plus.
Champ potentiel de collecte de nourriture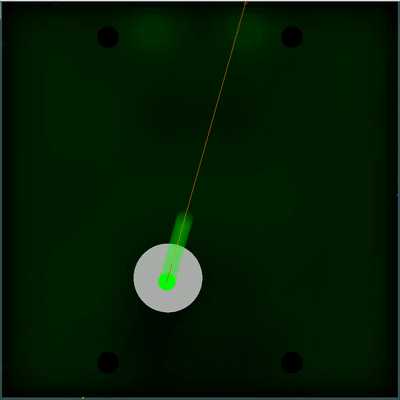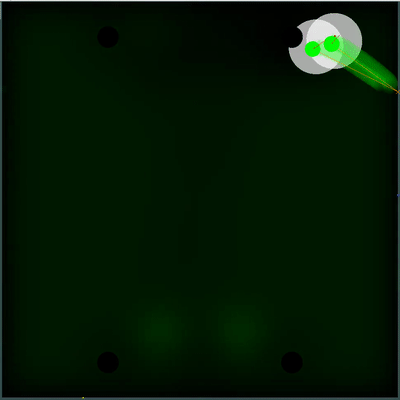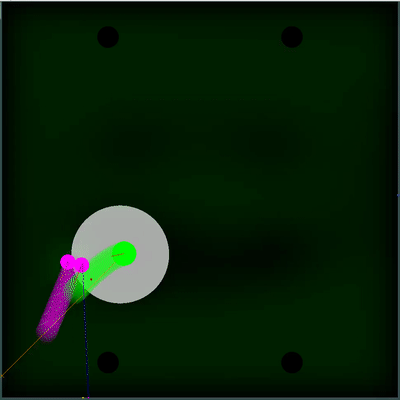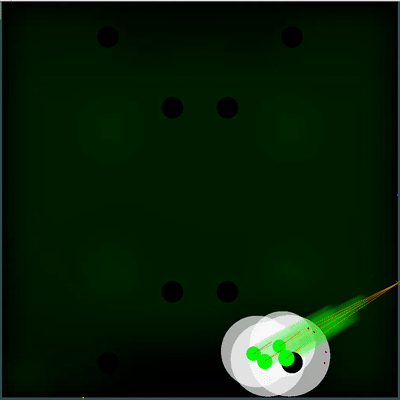 Vous pouvez faire attention à la façon dont tous les 40 ticks le champ devient un peu plus lumineux. Toutes les 40 graduations, le champ est mis à jour en fonction de la façon dont la nourriture est ajoutée sur la carte, et la probabilité d'apparition de nourriture est uniformément «étalée» à travers le champ. Si sur cette tique, nous voyons qu'il y a de la nourriture que nous verrions sur la tique précédente - la probabilité d'apparition de cet aliment n'est pas "étalée" avec le reste, mais est fixée par des points spécifiques (la nourriture apparaît toutes les 40 tiques de manière strictement symétrique).
Vous pouvez faire attention à la façon dont tous les 40 ticks le champ devient un peu plus lumineux. Toutes les 40 graduations, le champ est mis à jour en fonction de la façon dont la nourriture est ajoutée sur la carte, et la probabilité d'apparition de nourriture est uniformément «étalée» à travers le champ. Si sur cette tique, nous voyons qu'il y a de la nourriture que nous verrions sur la tique précédente - la probabilité d'apparition de cet aliment n'est pas "étalée" avec le reste, mais est fixée par des points spécifiques (la nourriture apparaît toutes les 40 tiques de manière strictement symétrique). Un utilitaire subjectif complètement différent s'est avéré être une double simulation de l'ennemi avec différents TTF - le minimum et le maximum possible (au cas où je ne connais pas le TTF pour tous les agarics visibles sur la carte). Et si plus tôt mon robot pensait que le tas d'agarics ennemi deviendrait un tout et se déplacerait lentement, alors maintenant il a choisi le pire des deux scénarios et ne risque pas d'être proche de l'ennemi, dont il sait moins qu'il ne voudrait.
Après avoir obtenu un avantage significatif, j'ai essayé de l'augmenter en ajoutant une définition du point auquel l'adversaire donne l'ordre à ses agarics de se déplacer, et bien que ce point ait été calculé dans la plupart des cas assez précisément, cela seul n'a pas amélioré les résultats du bot. Selon mes observations, cela est devenu encore pire que le cas lorsque les agarics de l'adversaire se sont simplement déplacés dans la même direction et à la même vitesse que si l'adversaire n'avait rien fait, de sorte que ces modifications ont été enregistrées dans une branche de guitare séparée jusqu'à des temps meilleurs.
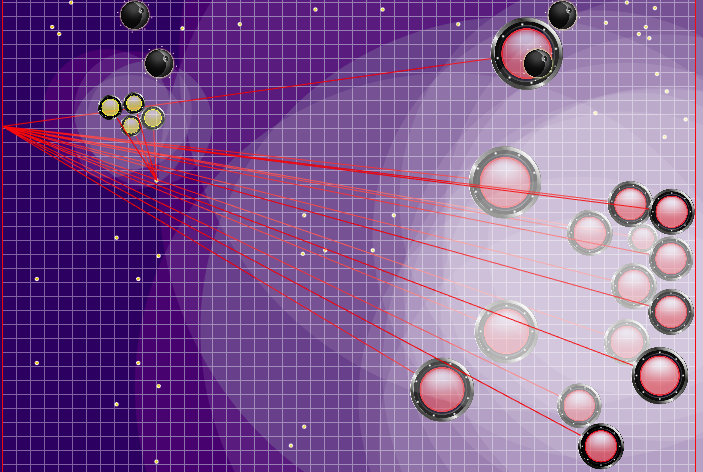
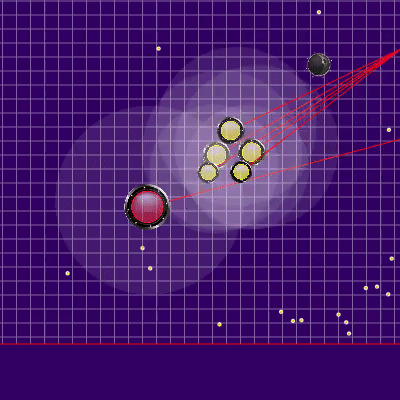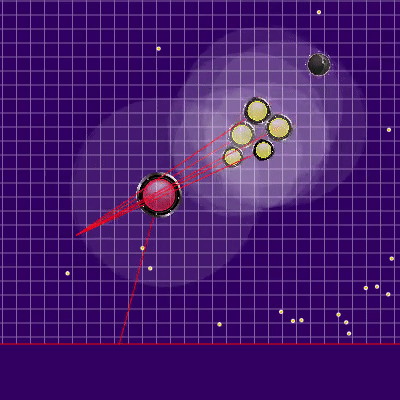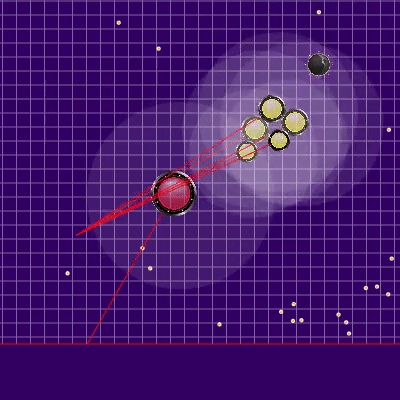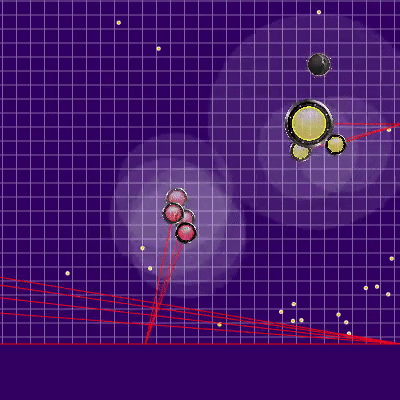
La définition de l'équipe adverse qui a été utilisée plus tard Les rayons des agarics de l'adversaire montrent l'équipe présumée que l'adversaire a donnée à leurs agarics lors du tick précédent. Les rayons bleus sont la direction exacte dans laquelle l'agarik a changé de direction au dernier tick. Le noir est l'intention. Il n'a été possible de déterminer plus précisément la direction de l'équipe que si la gélose était complètement dans la zone de notre visibilité (il a été possible de calculer l'effet des collisions sur le changement de sa vitesse). L'intersection des rayons est l'équipe prévue de l'adversaire. Gif réalisé sur la base du jeu aicups.ru/session/200710 , environ 3 000 ticks.
Les rayons des agarics de l'adversaire montrent l'équipe présumée que l'adversaire a donnée à leurs agarics lors du tick précédent. Les rayons bleus sont la direction exacte dans laquelle l'agarik a changé de direction au dernier tick. Le noir est l'intention. Il n'a été possible de déterminer plus précisément la direction de l'équipe que si la gélose était complètement dans la zone de notre visibilité (il a été possible de calculer l'effet des collisions sur le changement de sa vitesse). L'intersection des rayons est l'équipe prévue de l'adversaire. Gif réalisé sur la base du jeu aicups.ru/session/200710 , environ 3 000 ticks. Il y a également eu des tentatives de transfert de la fonction d'évaluation à l'évaluation de la masse gagnée, des tentatives de changement de la fonction d'évaluation du danger de l'adversaire ... Mais encore une fois, tous ces changements de sentiments se sont encore aggravés. La seule chose qui était utile pour évaluer le danger d'être proche de l'ennemi était une autre optimisation des performances ainsi que l'extension de cette estimation à un rayon beaucoup plus grand que le rayon d'intersection avec l'ennemi (essentiellement toute la carte, mais avec une diminution quadratique, si légèrement simplifiée - faisant une présence dans cinq rayons ou plus de l'adversaire dans la région de 1/25 du danger maximum d'être mangé). Le dernier changement également imprévu a conduit au fait que mes agariks ont eu très peur d'approcher un ennemi beaucoup plus grand, ainsi que dans le cas de leurs tailles très supérieures étaient plus enclins à se diriger vers l'adversaire. Ainsi, il s'est avéré être un remplacement réussi et peu gourmand en ressources du code prévu pour l'avenir, qui était censé être responsable de la peur d'une attaque d'un adversaire par scission (et un peu d'aide pour une telle attaque pour moi plus tard).
Après de longues et relativement vaines tentatives d’améliorer quelque chose, je suis de nouveau revenu à prédire la direction du mouvement de l’adversaire. J'ai décidé de l'essayer si ce n'est pas seulement pour remplacer les rivaux factices, puis faites comme je l'ai fait avec l'option TTF minimum et maximum - simulez deux fois et choisissez la meilleure. Mais pour cela, le CPU pourrait ne pas être suffisant, et dans de nombreux jeux de mon bot, ils pourraient simplement se déconnecter du système en raison d'un appétit insatiable. Par conséquent, avant de mettre en œuvre cette option, j'ai ajouté une définition approximative du temps passé et, si les limites étaient dépassées, j'ai commencé à réduire le nombre de mouvements de simulation. En ajoutant une double simulation de l'ennemi pour le cas où je connais l'endroit où il se dirige, j'ai de nouveau reçu une augmentation assez sérieuse dans la plupart des paramètres de jeu, à l'exception des plus gourmandes en ressources (avec une grande inertie / faible vitesse / faible viscosité), ce qui en raison d'une forte diminution de la profondeur Les simulations pourraient même s'aggraver un peu.
Avant le début des parties de 25 000 ticks, deux autres améliorations utiles ont été apportées: la pénalité pour terminer la simulation loin du centre de la carte, ainsi que pour se souvenir de la position précédente de l'adversaire s'il quittait la ligne de vue (ainsi que pour simuler son mouvement à ce moment-là). , . CPU , . . . , (, ) “” , .
Exemple de champ de danger à la fin d'un virage dans un coin et de tiques gâchées ,
, , . , .
, . , . De plus, des points de simulation de mouvement ont été ajoutés aux points sur le bord de la carte: à chaque agarik de rivaux et dans un rayon de la coordonnée moyenne arithmétique de mon agariki tous les 45 degrés. Le rayon a été réglé sur distance moyenne des coordonnées arithmétiques moyennes de mes agarics.Nouveaux points de simulation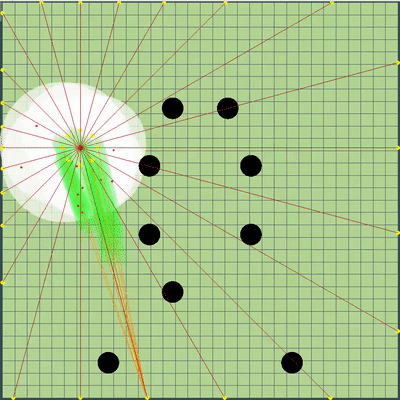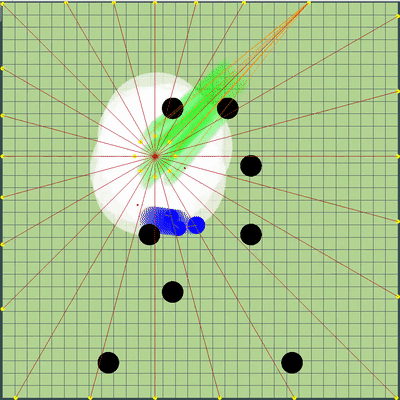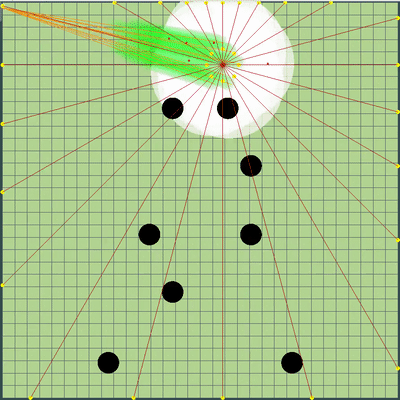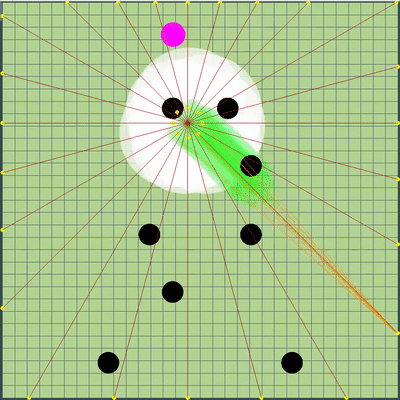 . «» , . .
. «» , . . Préparation finale
Au moment de l'ouverture des matchs pour 25 000 ticks et du passage à la finale, j'avais une solide marge, mais je n'avais pas l'intention de me détendre.Avec les nouveaux jeux 25k, la nouvelle est arrivée: les matchs de la finale auront également une longueur de 25k, et la limite de temps de la stratégie pour les ticks est devenue un peu plus longue. Après avoir évalué le temps que ma stratégie passe sur le jeu dans les nouvelles conditions, j'ai décidé d'ajouter une autre version de la simulation: on fait tout comme d'habitude, mais pendant la simulation on the go n do split. Cela, entre autres, a nécessité l'utilisation de la simulation trouvée à l'étape précédente, mais avec un décalage de 1 mouvement (par exemple, si nous avons constaté que le fractionnement de 7 ticks de l'actuel, alors le coup suivant, nous répétons la même chose, mais nous ferons déjà la division au 6ème coup). Cela a considérablement ajouté des attaques agressives contre ses rivaux, mais a mangé un peu plus de temps de stratégie.Il aurait dû y avoir une description concise de l'algorithme:
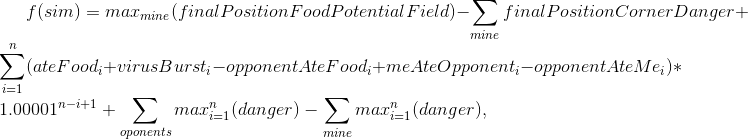
- f — , ;
- sim — ( , , TTF , );
- finalPositionFoodPotentialField — , , ;
- finalPositionCornerDanger — . , ;
- n — , . 10 50 ;
- ateFood — i;
- virusBurst — i;
- opponentAteFood — i;
- meAteOpponent — ;
- opponentAteMe — ;
- mine/opponents — . C'est-à-dire — ;
- danger — , , .
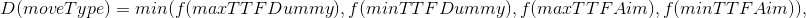
- moveType — , ;
- max/min TTF — , TTF ( TTF );
- dummy/aim — Dummy ( , ).
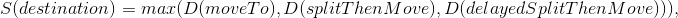
- destination — , ;
- moveTo — , n “ ” ;
- splitThenMove — split ;
- delayedSplitThenMove — , split .
1 . C'est-à-dire splitThenMove moveTo, delayedSplitThenMove 7 6 , 6 5 .. , — 7 . .
destination :
- 15 ( — ). 24 ;
- , ( );
- :
- “” , ;
- 8 . .
destination , .
Tous les perfectionnements ultérieurs étaient exclusivement liés à l'efficacité des simulations en cas de manque de TL: optimisation de la séquence de déconnexion de certaines parties de la logique en fonction du CPU consommé. Dans la plupart des jeux, cela n'était pas censé changer quoi que ce soit, mais trouver quelque chose de plus correct ne fonctionnait pas.Points finaux en finale. 808 2424 , . .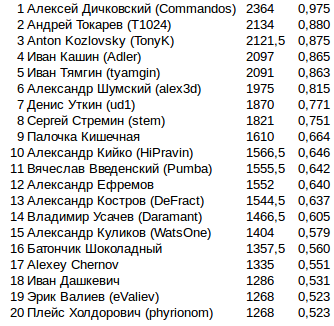
Au lieu d'une conclusion
En général, le début de cette compétition s'est avéré plutôt huilé, mais dans les premières semaines et demie, la tâche a été ramenée à une forme assez jouable avec l'aide des participants. Au départ, la tâche était très variable et choisir la bonne approche pour la résoudre ne semblait pas être une tâche triviale. Il était encore plus intéressant de trouver des moyens d'améliorer l'algorithme sans dépasser les limites de la consommation du processeur. Un grand merci aux organisateurs pour le concours et pour la mise en place des codes sources du monde pour l'accès libre. Ces derniers, bien sûr, leur ont énormément ajouté des problèmes au départ, mais ont grandement facilité (sinon pour dire, ce qui a permis en principe) la compréhension par les participants du dispositif du simulateur mondial. Un merci spécial pour l'opportunité de choisir un prix! Le prix est donc ressorti beaucoup plus utile :-) Pourquoi ai-je besoin d'un autre MacBook?