
Aujourd'hui au KDD 2018 est une journée de séminaire - avec une grande conférence qui commence demain, plusieurs groupes ont réuni des auditeurs sur certains sujets spécifiques. Été à deux de ces fêtes.
Analyse des séries chronologiques
Le matin, je voulais aller à un séminaire sur l'analyse des
graphes , mais il a été détenu pendant 45 minutes, alors je suis passé au suivant, sur l'analyse des séries chronologiques. Soudain, un
professeur blond de Californie ouvre le séminaire sur le thème «Intelligence artificielle en médecine». Étrange, car pour cela, il y a une piste séparée dans la pièce voisine. Ensuite, il s'avère qu'elle a plusieurs étudiants diplômés qui parleront de séries chronologiques ici. Mais, en fait, au point.
Intelligence artificielle en médecine
Les erreurs médicales sont à l'origine de 10% des décès aux USA, c'est l'une des trois principales causes de décès dans le pays. Le problème est qu'il n'y a pas assez de médecins; ceux qui sont surchargés et les ordinateurs sont plus susceptibles de créer des problèmes pour les médecins qu'ils ne peuvent en résoudre, du moins les médecins le font. Cependant, la plupart des données ne sont pas vraiment utilisées pour la prise de décision. Tout cela doit être combattu. Par exemple, une bactérie,
Clostridium difficile, est très virulente et résistante aux médicaments. Au cours de la dernière année, elle a infligé 4 milliards de dollars de dommages. Essayons d'évaluer le risque d'infection en fonction de la série chronologique des dossiers médicaux. Contrairement aux travaux précédents, nous prenons beaucoup de signes (vecteur 10k pour chaque jour) et construirons des modèles individuels pour chaque hôpital (à bien des égards, apparemment, une mesure nécessaire, car tous les hôpitaux ont leur propre ensemble de données). En conséquence, nous obtenons une précision d'environ 0,82 AUC avec un pronostic de risque CDI après 5 jours.
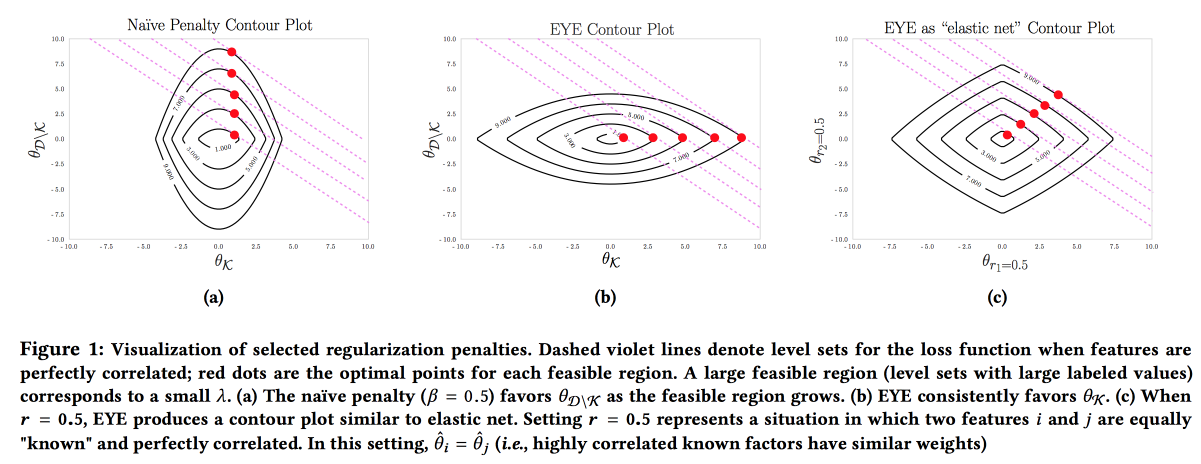
Il est important que le modèle soit précis, interprétable et robuste; nous devons montrer ce que nous pouvons faire pour prévenir la maladie. Un tel modèle peut être construit en utilisant activement les connaissances du domaine. C'est le désir d'interprétabilité qui réduit souvent le nombre de fonctionnalités et conduit à la création de modèles simples. Mais même un modèle simple avec un grand espace de fonctionnalités perd son interprétabilité, et l'utilisation de la régularisation L1 conduit souvent au fait que le modèle sélectionne au hasard l'une des fonctionnalités colinéaires. En conséquence, les médecins ne croient pas au modèle, malgré une bonne ASC. Les auteurs proposent d'utiliser un autre type de régularisation
EYE (expert yield assessment). Étant donné qu'il existe des données connues sur l'effet sur le résultat, il s'avère que le modèle se concentre sur les fonctionnalités nécessaires. Cela donne de bons résultats, même si l'expert a foiré, d'ailleurs, en comparant la qualité avec des régularisations standard, vous pouvez évaluer dans quelle mesure l'expert a raison.
Ensuite, nous procédons à l'analyse des séries chronologiques. Il s'avère que pour améliorer la qualité en eux, il est important de rechercher des invariants (en fait - conduire à une forme canonique). Dans un
article récent, un groupe de professeurs a proposé une approche basée sur deux réseaux convolutionnels. Le premier, Sequence Transformer, apporte la série à une forme canonique, et le second, Sequence Decoder, résout le problème de classification.
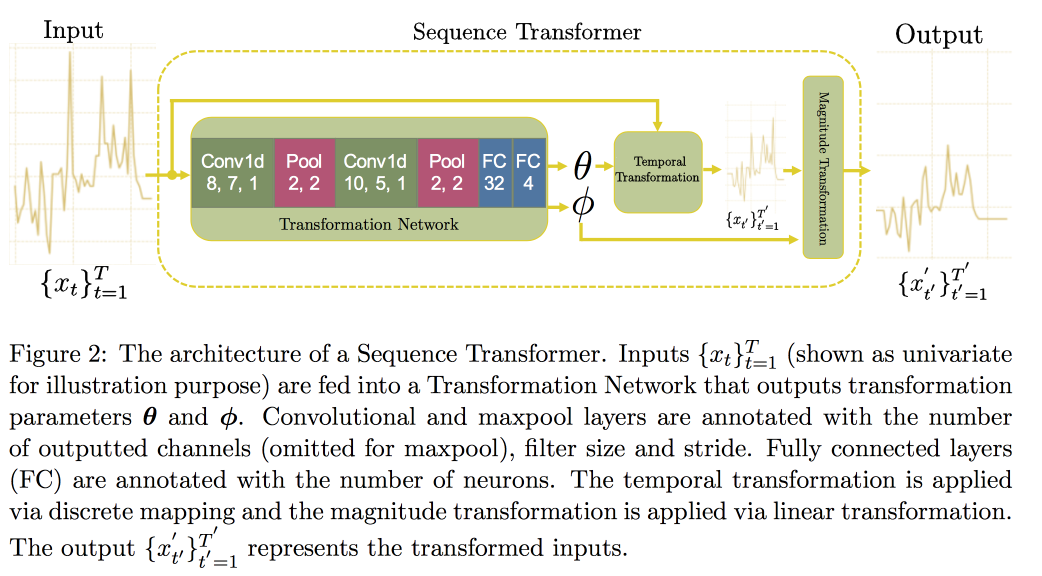
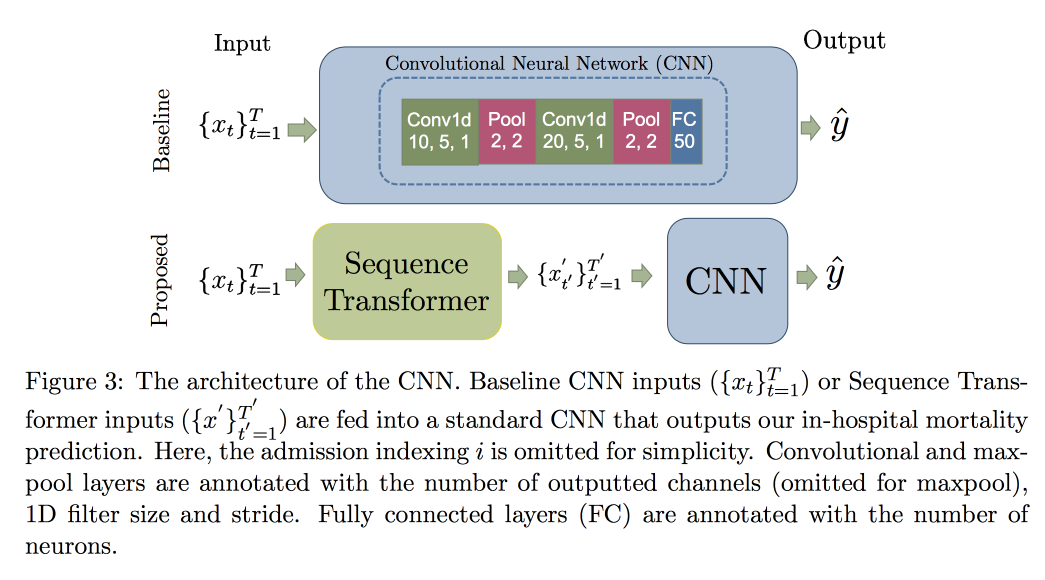
L'utilisation de CNN, plutôt que de RNN, s'explique par le fait qu'ils fonctionnent avec des lignes de longueur fixe. Vérifié sur l'
ensemble de données MIMIC, a tenté de prédire la mort à l'hôpital dans les 48 heures. Le résultat a été une amélioration de 0,02 AUC par rapport au CNN ordinaire avec des couches supplémentaires, mais les intervalles de confiance se chevauchent.
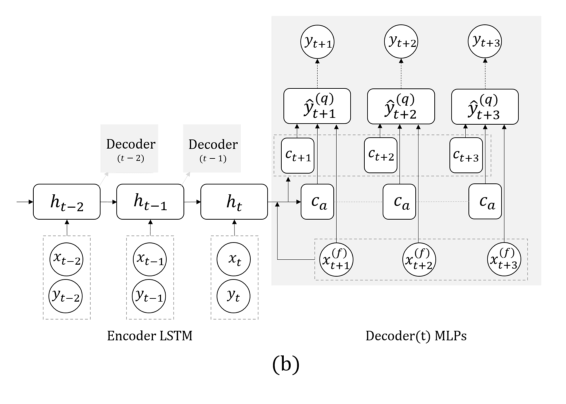
Maintenant, une autre tâche: nous allons prévoir uniquement sur la base de la série réelle, sans signaux externes (qui ont mangé, etc.). Ici, l'équipe a proposé de remplacer le RNN pour prédire quelques pas en avant par une grille à plusieurs sorties, sans récursivité entre elles. L'explication de cette solution est qu'une erreur ne s'accumule pas pendant la récursivité. Combinez cette technique avec la précédente (recherche d'invariants). Immédiatement après la présentation du professeur, le post-doctorant a parlé en détail de ce modèle, nous terminons donc ici, notant seulement que lors de la validation, il est important de regarder non seulement l'erreur générale, mais aussi l'erreur de classification des cas dangereux de glucose trop élevé ou trop bas.
J'ai posé une question sur la rétroaction du modèle: bien qu'il s'agisse d'une question ouverte et douloureuse, ils disent que nous devrions essayer de comprendre quels changements dans la distribution des symptômes se produisent en raison du fait de l'intervention et quels sont les changements naturels causés par des facteurs externes. En fait, la présence de tels changements complique grandement la situation: il est impossible de recycler le modèle, car la qualité se dégrade, le mélange au hasard (ne pas traiter quelqu'un et vérifier s'il va mourir) n'est pas éthique, mais apprendre des données où tout le monde a été traité selon la recommandation du modèle est garanti biais ...
Exemple de génération de chemin
Un exemple de la façon de ne pas faire de présentations: très rapide, difficile à entendre et à saisir l'idée est presque impossible. L'œuvre elle-même est disponible
ici .
Les gars développent leur résultat de prévision précédent plusieurs pas en avant. Il y a deux idées principales dans le travail précédent: au lieu de RNN, utilisez un réseau avec plusieurs sorties pour différents points dans le temps, et au lieu de nombres spécifiques, nous essayons de prédire les distributions et d'évaluer les quantiles. Tout cela s'appelle
MQ-RNN / CNN (Multi-Horizont prevision Quantile regression).
Cette fois, nous avons essayé d'affiner les prévisions en utilisant le post-traitement. Considéré deux approches. Dans le cadre du premier, nous essayons de «calibrer» la distribution du réseau neuronal à l'aide de données postérieures et d'apprendre la matrice de covariance des sorties et des observations, ce que l'on appelle le rétrécissement de la covariance. La méthode est assez simple et fonctionne, mais j'en veux plus. La deuxième approche consistait à utiliser des modèles génératifs pour construire un «échantillon de chemin»: ils utilisent l'approche générative pour la prévision (GAN, VAE). De bons résultats, mais instables, ont été obtenus avec l'aide de
WaveNet, développé pour la
génération de sons.
Représentation graphique des réseaux structurés
Un travail intéressant sur le transfert de "connaissance du domaine" dans le réseau neuronal. Ils ont montré sur l'exemple de prédire le niveau de criminalité dans l'espace (par régions urbaines) et dans le temps (par jours et heures). La principale difficulté: de fortes données rares et la présence d'événements locaux rares. En conséquence, de nombreuses méthodes ne fonctionnent pas bien, en moyenne, il s'avère toujours possible de deviner quotidiennement, mais pas pour des zones et des heures spécifiques. Essayons de combiner une structure de haut niveau et des micro-motifs dans un réseau neuronal.
Nous construisons un graphique de communication à l'aide des codes postaux et déterminons l'influence de l'un sur l'autre à l'aide du
processus multivarié de Hawkes . Ensuite, sur la base du graphique obtenu, nous construisons la topologie du réseau neuronal, reliant les blocs des régions de la ville avec un crime qui a montré une corrélation.
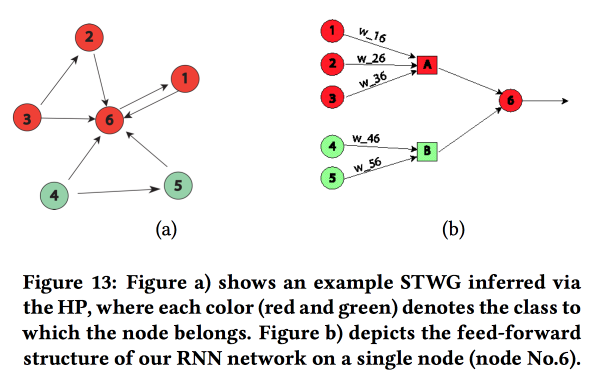
Nous avons comparé cette approche avec deux autres: la formation sur une grille pour un district ou sur une grille pour un groupe de régions avec un taux de criminalité similaire, a montré une augmentation de la précision. Pour chaque région, un LSTM à deux couches avec deux couches entièrement connectées est introduit.
En plus des délits, ils ont également montré des exemples de travaux sur la prévision du trafic. Ici, le graphique de construction d'un réseau est déjà pris géographiquement par kNN. On ne sait pas exactement dans quelle mesure leurs résultats peuvent être comparés à d'autres (ils ont librement modifié les métriques dans l'analyse), mais en général, l'heuristique de construction d'un réseau semble adéquate.
Approche non paramétrique pour la prévision d'ensemble
Les ensembles sont un sujet très populaire, mais comment obtenir le résultat de prévisions individuelles n'est pas toujours évident. Dans leur travail, les auteurs proposent une
nouvelle approche .
Souvent, les ensembles simples fonctionnent bien, encore mieux. que le nouveau
modèle bayésien faisant la moyenne et la moyenne-NN. La régression n'est pas non plus mauvaise, mais donne souvent des résultats étranges en termes de choix de pondérations (par exemple, cela donnera à certaines prévisions un poids négatif, etc.). En fait, la raison en est souvent le fait que la méthode d'agrégation utilise certaines hypothèses sur la façon dont l'erreur de prévision est distribuée (par exemple, selon Gauss ou normale), mais lorsqu'elle est utilisée, ils oublient de vérifier cette hypothèse. Les auteurs ont tenté de proposer une approche sans hypothèses.
Nous considérons deux processus aléatoires: le Processus de génération de données (DGP) modélise la réalité et peut dépendre du temps, et le Processus de génération de prévisions (FGP) modélise la construction de prévisions (il y en a beaucoup - un pour chaque membre de l'ensemble). La différence entre ces deux processus est également un processus aléatoire, que nous allons essayer d'analyser.
- Nous collectons des données historiques et construisons la densité de distribution d'erreur pour les prédicteurs à l'aide de l' estimation de la densité du noyau.
- Ensuite, nous construisons une prévision et la transformons en variable aléatoire en ajoutant l'erreur construite.
- Ensuite, nous résolvons le problème de la maximisation de la probabilité.
La méthode résultante est presque similaire à EMOS (Ensemble Model Output Statistics) avec une erreur gaussienne et bien mieux avec une méthode non gaussienne. Souvent en réalité, par exemple (
Wikipedia Page Traffic Dataset ) est une erreur non gaussienne.
LSTM imbriqué: modélisation de la taxonomie et de la dynamique temporelle dans un réseau social géolocalisé
Le travail est soumis par des auteurs de Google. Nous essayons de prévoir la prochaine vérification utilisateur. en utilisant son histoire des chekins récents et des métadonnées de lieux, tout d'abord, leur relation avec les tags / catégories. Les catégories sont à trois niveaux, nous utilisons les deux niveaux supérieurs: la catégorie parent décrit l'intention de l'utilisateur (par exemple, le désir de manger) et la catégorie enfant décrit les préférences de l'utilisateur (par exemple, l'utilisateur aime la nourriture espagnole). La catégorie subsidiaire du prochain chèque devrait être montrée pour obtenir plus de revenus de la publicité en ligne.
Nous utilisons deux LSTM imbriqués: le supérieur, comme d'habitude, selon la séquence de vérifications, et le niché - selon les transitions dans l'arbre des catégories du parent à l'enfant.
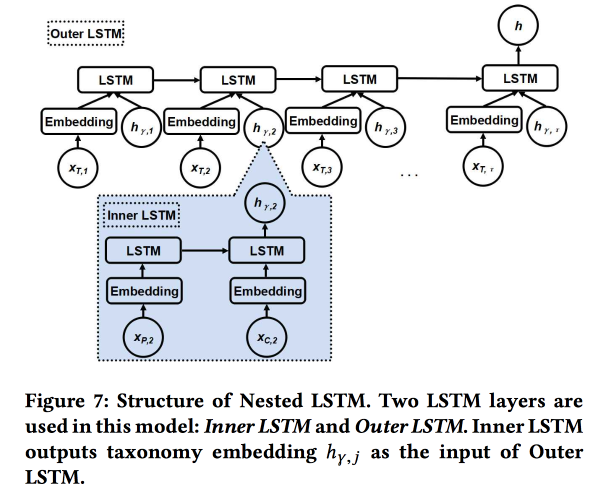
Il s'avère 5 à 7% meilleur par rapport à un LSTM simple avec des intégrations de catégorie brute. De plus, nous avons montré que les jonctions de transition LSTM dans l'arborescence de catégories sont plus belles que les simples et sont mieux regroupées.
Identifier les changements dans l'espace sémantique évolutif
Discours assez gai du
professeur chinois . L'essentiel est d'essayer de comprendre comment les mots changent leur sens.
Maintenant, tout le monde réussit à former des incorporations de mots, elles fonctionnent bien, mais être formé à des moments différents ne peut pas être comparé - vous devez faire des alliances.
- Vous pouvez prendre l'ancien pour l'initialisation, mais cela ne donne aucune garantie.
- Vous pouvez apprendre la fonction de transformation pour le regroupement, mais cela ne fonctionne pas toujours, car les dimensions ne sont pas toujours partagées également.
- Et vous pouvez utiliser un espace topologique et non vectoriel!
En fin de compte, l'essence de la solution: nous construisons un graphique knNN dans les voisins du mot à différentes périodes pour évaluer le changement de sens, et essayons de comprendre s'il y a un changement significatif. Pour cela, nous utilisons le modèle
Bayesian Surprise . En fait, nous regardons la
divergence KL de la distribution d'une hypothèse (antérieure) et d'une hypothèse soumise à observations (postérieure) - c'est une surprise. Avec les mots et les graphiques CNN, nous utilisons Dirichlet basé sur les fréquences des voisins dans le passé comme une distribution a priori et le comparons avec le multinomial réel de l'histoire récente. Total:
- Nous avons coupé l'histoire.
- Nous construisons des encastrements (LINE avec conservation de l'initialisation).
- Nous considérons KNN sur les embeds.
- Appréciez la surprise.
Nous validons en prenant deux mots aléatoires avec la même fréquence, et nous nous échangeons - l'augmentation de la qualité par surprise est de 80%. Ensuite, nous prenons 21 mots avec des dérives de sens connues et voyons si nous pouvons les trouver automatiquement. Les sources ouvertes n'ont pas encore de description détaillée de cette approche, mais
il y en a une au SIGIR 2018 .
AdKDD & TargetAd
Après le déjeuner, je suis passé à un séminaire sur la publicité en ligne. Il y a beaucoup plus de conférenciers de l'industrie et tout le monde réfléchit à la façon de gagner plus d'argent.
Technologie publicitaire sur Airbnb
En tant que grande entreprise avec une grande équipe DS, AirBnB investit beaucoup pour se promouvoir correctement et ses offres internes sur des sites externes. L'un des développeurs a parlé un peu des défis.
Commençons par la publicité dans un moteur de recherche: lors de la recherche d'hôtels sur Google, les deux premières pages sont de la publicité :(. Mais souvent, l'utilisateur ne comprend même pas cela, car la publicité est très pertinente. Schéma standard: nous faisons correspondre les demandes de publicité par mots clés et nous obtenons la signification du motif / motif ( ville, bon marché ou luxe, etc.)
Une fois les candidats sélectionnés, nous organisons une vente aux enchères entre eux (maintenant le
deuxième prix généralisé est utilisé partout). Lors de la participation à l'enchère, l'objectif est de maximiser l'effet sur un budget fixe, en utilisant un modèle avec une combinaison de la probabilité d'un clic et du revenu: Enchère = P (clic | requête de recherche) * valeur de réservation. Un point important: ne dépensez pas tout votre argent trop rapidement, alors ajoutez Spacer pacer.
AirBnB dispose d'un système puissant pour les tests A / B, mais il ne peut pas être appliqué ici, car il contrôle la plupart du processus Google. Là, ils ont promis d'ajouter plus d'outils aux annonceurs, les grands acteurs sont vraiment impatients.
Problème distinct: contact des utilisateurs avec la publicité à plusieurs endroits. Nous voyageons en moyenne deux fois par an, le cycle de préparation d'un voyage et de réservation est très long (des semaines voire des mois), il y a plusieurs canaux où nous pouvons joindre l'utilisateur, et nous devons diviser le budget par canal. Ce sujet est très douloureux, il existe des méthodes simples (linéairement, soigneusement, par le dernier clic ou par les résultats du
test de soulèvement ). AirBnB a essayé deux nouvelles approches: basées sur les modèles Markov et
le modèle Shapley .
Avec le modèle de Markov, tout est plus ou moins clair: on construit une chaîne discrète, dont les nœuds correspondent aux points de contact avec la publicité, il y a aussi un nœud à convertir. Selon les données, nous sélectionnons des poids pour les transitions, donnons plus de budget aux nœuds où la probabilité de transition est plus grande. Je leur ai posé une question: pourquoi utiliser une simple chaîne de Markov, alors qu'il est plus logique d'utiliser MDP; Ils ont dit qu'ils travaillaient sur ce sujet.
C'est plus intéressant avec Shapley: en fait, il s'agit d'un schéma connu depuis longtemps pour évaluer l'effet additif, dans lequel différentes combinaisons d'effets sont prises en compte, l'effet de chacun d'eux est évalué, puis un certain agrégat pour chaque effet individuel est déterminé. La difficulté est qu'il peut y avoir synergie entre les effets (moins souvent antagonisme), et le résultat de la somme n'est pas égal à la somme des résultats. En général, une théorie assez intéressante et belle, je
vous conseille de lire .
Dans le cas d'AirBnB, l'application du modèle Shapley ressemble à ceci:
- Nous avons dans les exemples de données observés avec différentes combinaisons d'effets et le résultat réel.
- Remplissez les lacunes dans les données (toutes les combinaisons ne sont pas présentées) en utilisant ML.
- Nous calculons le prêt pour chaque type d'impact Shapley.
Microsoft: repousser les limites de {AI}
Un peu plus à ce sujet. comme Microsoft est engagé dans la publicité, maintenant du côté du site, principalement Bing. Un peu d'abattage:
- Le marché publicitaire connaît une croissance très rapide (exponentielle).
- La publicité sur une page se cannibalise, vous devez analyser la page entière.
- La conversion sur certaines pages est plus élevée, malgré le fait que le CTP soit pire.
Il existe environ 70 modèles dans le moteur de publicité Bing, 2000 expériences hors ligne, 400 en ligne. Un changement important dans la plateforme chaque semaine. En général, ils travaillent sans relâche. Quels sont les changements dans la plateforme:
- Le mythe d'une métrique: cela ne fonctionne pas de cette façon, les métriques se développent et se font concurrence.
- Nous avons repensé le système de publicité correspondant aux demandes de NLP à DL, qui est calculé sur FPGA.
- Ils utilisent des modèles fédéraux et des bandits contextuels: les modèles internes produisent la probabilité et l'incertitude, le bandit d'en haut prend une décision. Elle a beaucoup parlé des bandits, ils sont habitués à lancer des modèles et à lancer à vitesse de croisière, ils contournent le fait que souvent l'amélioration du modèle entraîne une baisse des revenus :(
- Il est très important d'évaluer l'incertitude (enfin, oui, sans cela, vous ne pouvez pas construire un bandit).
- Pour les petits annonceurs, l'institution de publicité via des bandits ne fonctionne pas, il y a peu de statistiques, il faut faire des modèles séparés pour un démarrage à froid.
- Il est important de surveiller les performances sur différentes cohortes d'utilisateurs, ils disposent d'un système automatique de découpage en fonction des résultats de l'expérience.
Nous avons parlé un peu de l'analyse des sorties. Les hypothèses des vendeurs sur les causes de la sortie ne sont pas toujours vraies, vous devez creuser plus profondément. Pour ce faire, vous devez construire des modèles interprétables (ou un modèle spécial pour expliquer les prévisions) et réfléchir beaucoup. Et puis faites les expériences. Mais il est toujours difficile de faire des expériences avec le flux sortant, ils recommandent d'utiliser des statistiques de second ordre et
un article de Google .
Ils utilisent également une chose telle que Commercial Knowledge Graph, qui décrit le domaine: marques, produits, etc. Le graphique est construit de manière entièrement automatique, sans supervision. Les marques sont marquées par des catégories, c'est important, car en général, il n'est pas toujours possible de superviser sans isoler la marque dans son ensemble, mais au sein d'un certain sujet de catégorie, le signal est plus fort. Malheureusement, je n'ai pas trouvé d'œuvres ouvertes par leur méthode.
Annonces Google
Le même mec qui a parlé hier des chefs d'accusation raconte que tout est tout aussi triste et arrogant. J'ai marché sur plusieurs sujets.
Première partie: Répartition robuste des annonces stochastiques. Nous avons des nœuds budgétés (annonces) et des nœuds en ligne (utilisateurs), et il y a également des pondérations entre eux. Vous devez maintenant choisir quelles publicités afficher le nouveau nœud. Vous pouvez le faire avec gourmandise (toujours avec un poids maximum), mais nous courons alors le risque d'élaborer un budget prématurément et d'obtenir une solution inefficace (la limite théorique est de 1/2 de l'optimum). Vous pouvez traiter cela de différentes manières, en fait, nous avons ici un conflit traditionnel entre le revenu et le bien-être.
Lors du choix de la méthode d'allocation, on peut supposer un ordre d'apparition aléatoire des nœuds en ligne conformément à une certaine distribution, mais dans la pratique, il peut également y avoir un ordre contradictoire (c'est-à-dire avec des éléments ayant un effet opposé). Les méthodes dans ces cas sont différentes, elles fournissent des liens vers leurs derniers articles:
1 et
2 .
Deuxième partie: apprentissage sensible à la perception / tarification robuste. Maintenant, nous essayons de résoudre le problème du choix du prix de réservation pour augmenter les revenus des sites publicitaires. Nous considérons également l'utilisation d'autres enchères telles que
Myerson ,
BINTAC , le retour à l'enchère du premier prix en cas de contact avec la réservation. Ils n'entrent pas dans les détails, ils envoient à
leur article .
Troisième partie: Regroupement en ligne. Encore une fois, nous résolvons le problème de l'augmentation des revenus, mais maintenant nous allons de l'autre côté. Si vous pouviez acheter des annonces en vrac (regroupement hors ligne), dans de nombreuses situations, vous pouvez proposer une solution plus optimale. Mais vous ne pouvez pas le faire dans une vente aux enchères en ligne, vous devez créer des modèles complexes avec de la mémoire et dans des conditions difficiles, RTB ne le pousse pas.
Puis un modèle magique apparaît, où toute la mémoire est réduite à un chiffre (compte bancaire), mais le temps presse et le haut-parleur commence à parcourir frénétiquement les diapositives. , ,
.
Deep Policy optimization by Alibaba
«sponsored search». RL, — .
.
offline- , , online-, .
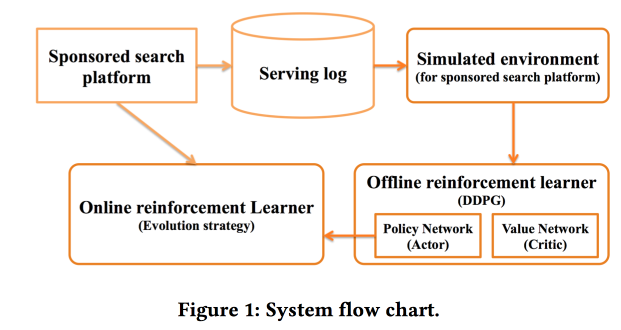
CTR ,
DDPG .
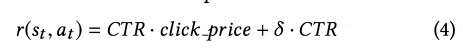
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
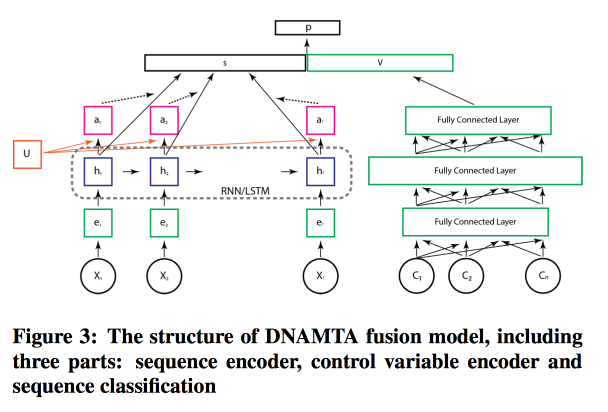
, attention- .
Conclusion
Ensuite, il y a eu une séance d'ouverture de pathos avec une vidéo IMAX dans la meilleure tradition des remorques à succès, un grand merci à tous ceux qui ont contribué à tout organiser - un record de KDD à tous égards (y compris un parrainage de 1,2 million de dollars), des mots de départ de Lord Bytes (ministre de l'Innovation) Royaume-Uni) et une session d'affiches pour laquelle il n'y a plus de force. Nous devons nous préparer pour demain.