On pense que le développement prend environ 10% du temps, et le débogage prend 90%. Peut-être que cette déclaration est exagérée, mais tout développeur conviendra que le débogage est un processus extrêmement gourmand en ressources, en particulier dans les grands systèmes multithreads.
Ainsi, l'optimisation et la systématisation du processus de débogage peuvent apporter des avantages significatifs sous forme d'heures de travail économisées, augmentant la vitesse de résolution des problèmes et, finalement, augmentant la fidélité de vos utilisateurs.
 Sergey Shchegrikovich
Sergey Shchegrikovich (dotmailer) à la conférence
DotNext 2018 Piter a suggéré de considérer le débogage comme un processus qui peut être décrit et optimisé. Si vous n'avez toujours pas de plan clair pour trouver des bugs - sous la vidéo et le texte de la transcription du rapport de Sergey.
(Et à la fin de l'article, nous avons ajouté
l' attrait de
John Skeet à tous les affiliés, assurez-vous de regarder)
Mon objectif est de répondre à la question: comment corriger efficacement les bugs et quel devrait être le focus. Je pense que la réponse à cette question est un processus. Le processus de débogage, qui consiste en des règles très simples, et vous les connaissez bien, mais vous l'utilisez probablement sans le savoir. Par conséquent, ma tâche est de les systématiser et de montrer comment devenir plus efficaces à l'aide d'un exemple.
Nous développerons un langage commun pour la communication pendant le débogage, et nous verrons également un chemin direct pour trouver les principaux problèmes. Sur mes exemples, je montrerai ce qui s'est passé en raison d'une violation de ces règles.
Utilitaires de débogage
Bien sûr, tout débogage n'est pas possible sans les utilitaires de débogage. Mes favoris sont:
- Windbg , qui, en plus du débogueur lui-même, possède de riches fonctionnalités pour étudier les vidages de mémoire. Un vidage de mémoire est une tranche de l'état d'un processus. Vous y trouverez la valeur des champs d'objets, des piles d'appels, mais, malheureusement, le vidage de la mémoire est statique.
- PerfView est un profileur écrit sur la technologie ETW .
- Sysinternals est un utilitaire écrit par Mark Russinovich , qui vous permet de creuser un peu plus loin dans l'appareil du système d'exploitation.
Service en baisse
Commençons par un exemple de ma vie dans lequel je montrerai comment la nature non systématique du processus de débogage conduit à l'inefficacité.
Cela est probablement arrivé à tout le monde, lorsque vous venez dans une nouvelle entreprise dans une nouvelle équipe pour un nouveau projet, puis dès le premier jour, vous voulez faire des avantages irréparables. C'était donc avec moi. À cette époque, nous avions un service qui recevait du HTML pour l'entrée et des images de sortie pour la sortie.
Le service a été écrit sous .Net 3.0 et c'était il y a très longtemps. Ce service avait une petite fonctionnalité - il s'est écrasé. Tombait souvent, environ une fois toutes les deux à trois heures. Nous avons corrigé ces propriétés de redémarrage élégamment définies dans les propriétés du service après la chute.
Le service n'était pas essentiel pour nous et nous pouvions y survivre. Mais j'ai rejoint le projet et la première chose que j'ai décidé de faire a été de le réparer.
Où vont les développeurs .NET si quelque chose ne fonctionne pas? Ils vont à EventViewer. Mais là je n'ai rien trouvé d'autre que le record que le service est tombé. Il n'y avait aucun message sur l'erreur native, ni une pile d'appels.
Il existe un outil qui a fait ses preuves pour ce qu'il faut faire ensuite - nous enveloppons l'ensemble
main dans
try-catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); }
L'idée est simple:
try-catch fonctionnera, cela nous dérangera, nous le lirons et réparerons le service. Nous compilons, déployons en production, le service plante, il n'y a pas d'erreur. Ajoutez une autre
catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); }
Nous répétons le processus: le service plante, il n'y a pas d'erreur dans les logs. La dernière chose qui peut aider est
finally , ce qui est toujours appelé.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); } finally { LogEndOfExecution(); }
Nous compilons, déployons, le service plante, il n'y a pas d'erreur. Trois jours s'écoulent derrière ce processus, maintenant des pensées viennent déjà que nous devons enfin commencer à penser et à faire autre chose. Vous pouvez faire beaucoup de choses: essayez de reproduire l'erreur sur la machine locale, regardez les vidages de mémoire, etc. Cela semblait encore deux jours et je vais corriger ce bug ...
Deux semaines se sont écoulées.
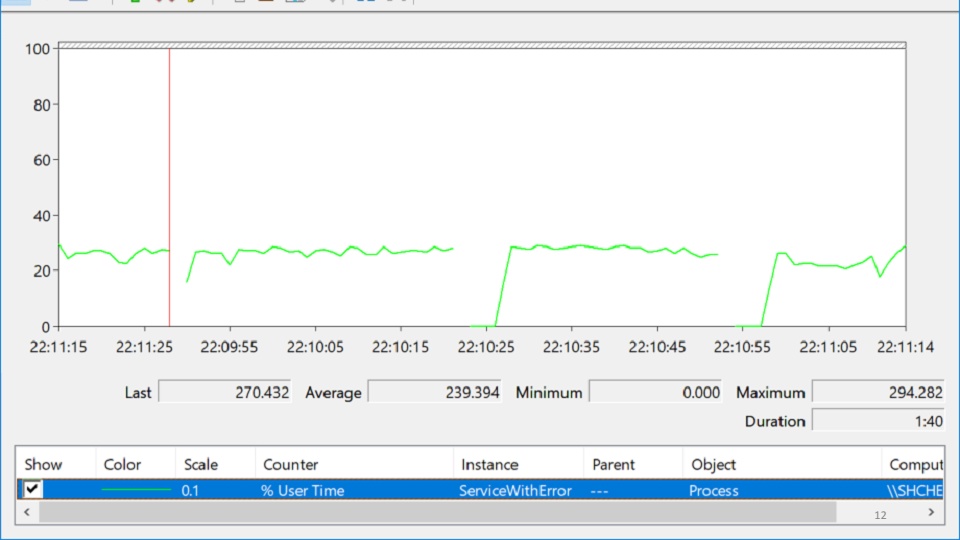
J'ai regardé dans PerformanceMonitor, où j'ai vu un service qui se bloque, puis monte, puis retombe. Cette condition est appelée
désespoir et ressemble à ceci:
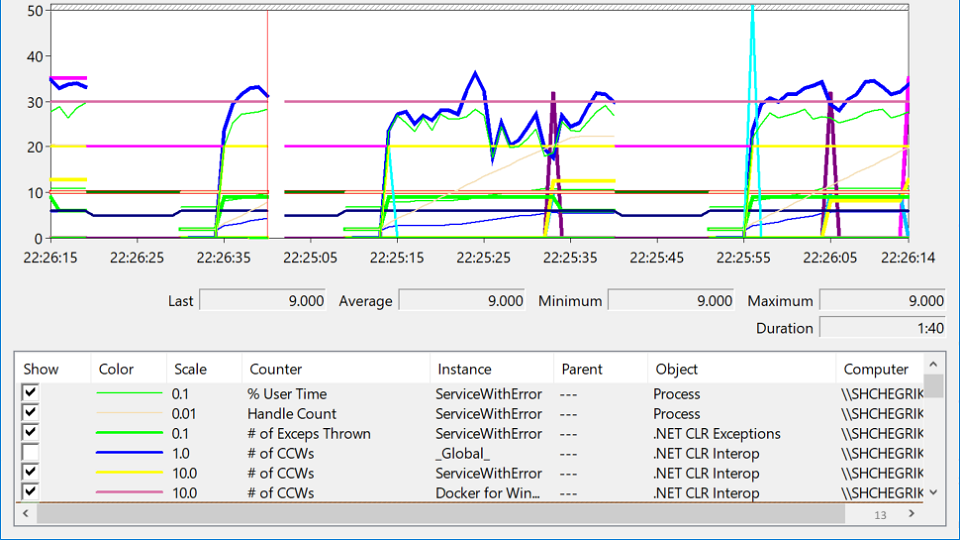
Dans cette variété d'étiquettes, essayez-vous de découvrir où se situe réellement le problème? Après plusieurs heures de méditation, le problème apparaît soudain:
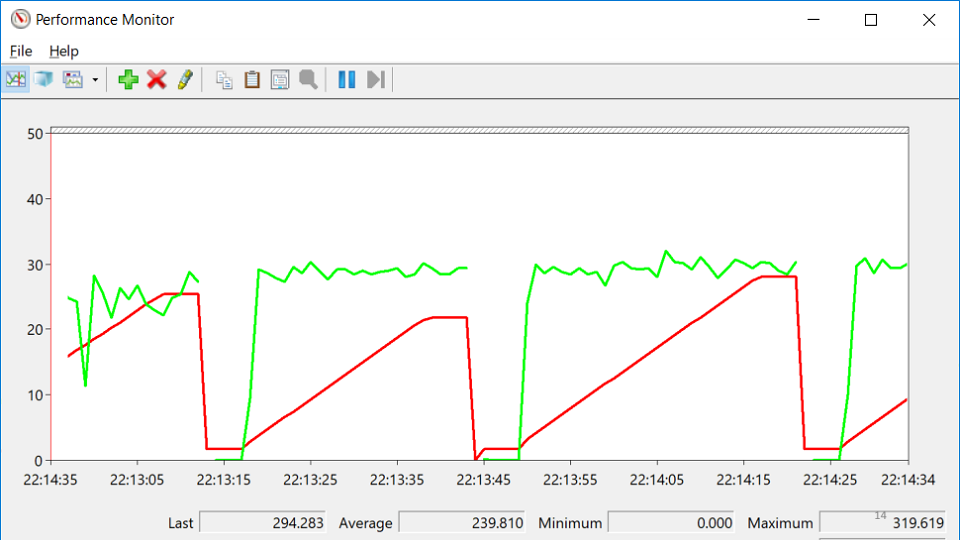
La ligne rouge est le nombre de descripteurs natifs dont le processus est propriétaire. Un handle natif est une référence à une ressource de système d'exploitation: fichier, registre, clé de registre, mutex, etc. Pour une étrange combinaison de circonstances, la baisse de la croissance du nombre de poignées coïncide avec les moments où le service a chuté. Cela conduit à l'idée qu'il y a quelque part une fuite de poignées.
Nous prenons un vidage de mémoire, l'ouvrons dans WinDbg. Nous commençons à exécuter des commandes. Essayons de voir la file d'attente de finalisation des objets qui devraient être libérés par l'application.
0:000> !FinalizeQueue
À la toute fin de la liste, j'ai trouvé un navigateur Web.
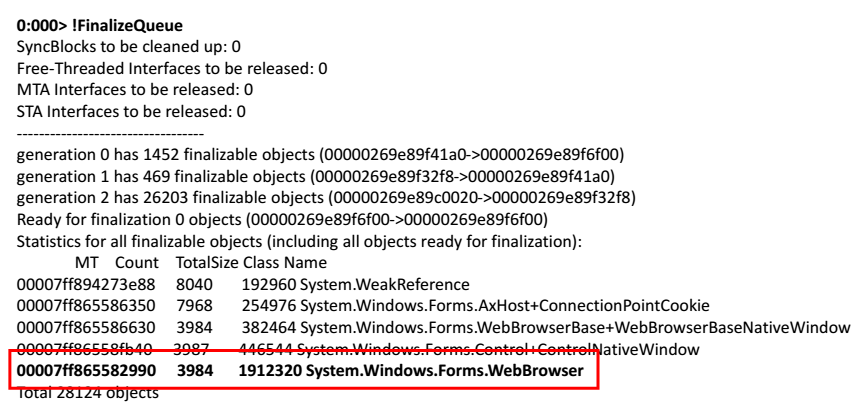
La solution est simple - prenez WebBrowser et appelez en
dispose :
private void Process() { using (var webBrowser = new WebBrowser()) {
Les conclusions de cette histoire peuvent être tirées comme suit: deux semaines, c'est trop long et trop long pour trouver une disposition non invitée; que nous avons trouvé une solution au problème - la chance, puisqu'il n'y avait pas d'approche spécifique, il n'y avait pas de nature systématique.
Après cela, j'avais une question: comment faire ses débuts efficacement et que faire?
Pour ce faire, vous devez connaître seulement trois choses:
- Règles de débogage
- Algorithme de recherche d'erreurs.
- Techniques de débogage proactives.
Règles de débogage
- Répétez l'erreur.
- Si vous n'avez pas corrigé l'erreur, elle n'est pas corrigée.
- Comprenez le système.
- Vérifiez la fiche.
- Divisez et conquérez.
- Rafraîchissez-vous.
- Ceci est votre bug.
- Cinq pourquoi.
Ce sont des règles assez claires qui se décrivent.
Répétez l'erreur. Une règle très simple, car si vous ne pouvez pas vous tromper, il n'y a rien à corriger. Mais il existe différents cas, en particulier pour les bogues dans un environnement multi-thread. Nous avons en quelque sorte eu une erreur qui n'apparaissait que sur les processeurs Itanium et uniquement sur les serveurs de production. Par conséquent, la première tâche du processus de débogage consiste à trouver une configuration du banc de test sur laquelle l'erreur serait reproduite.
Si vous n'avez pas corrigé l'erreur, elle n'est pas corrigée. Cela arrive parfois: un bug tracker contient un bug qui est apparu il y a six mois, personne ne l'a vu depuis longtemps, et on souhaite simplement le fermer. Mais en ce moment, nous manquons la chance de savoir, la chance de comprendre comment notre système fonctionne et ce qui lui arrive vraiment. Par conséquent, tout bug est une nouvelle opportunité d'apprendre quelque chose, d'en savoir plus sur votre système.
Comprenez le système. Brian Kernighan a dit un jour que si nous étions si intelligents pour écrire ce système, alors nous devons être doublement intelligents pour le lancer.
Un petit exemple de la règle. Notre suivi dessine des graphiques:
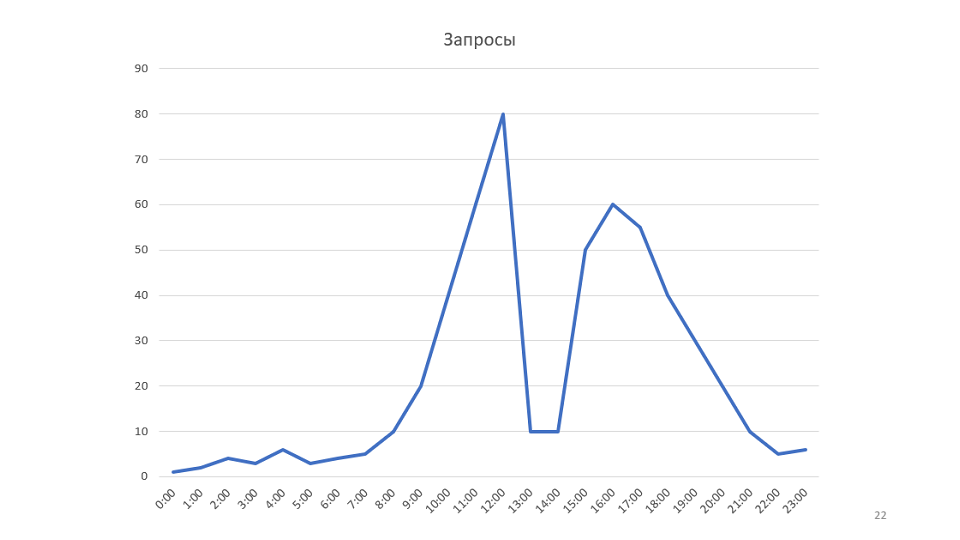
Il s'agit d'un graphique du nombre de demandes traitées par notre service. Après l'avoir regardé, nous avons eu l'idée qu'il serait possible d'augmenter la vitesse du service. Dans ce cas, le planning augmente, il peut être possible de réduire le nombre de serveurs.
L'optimisation des performances Web se fait simplement: nous prenons PerfView, l'exécutons sur la machine de production, il supprime la trace dans les 3-4 minutes, nous prenons cette trace sur la machine locale et commençons à l'étudier.
L'une des statistiques que PerfView affiche est le garbage collector.
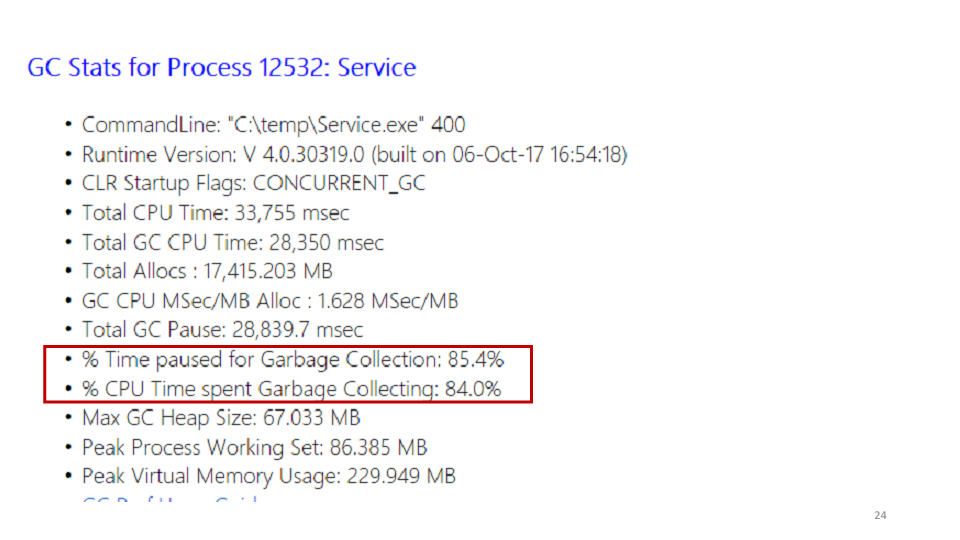
En regardant ces statistiques, nous avons vu que le service passe 85% de son temps à ramasser les ordures. Vous pouvez voir dans PerfView exactement où ce temps est passé.
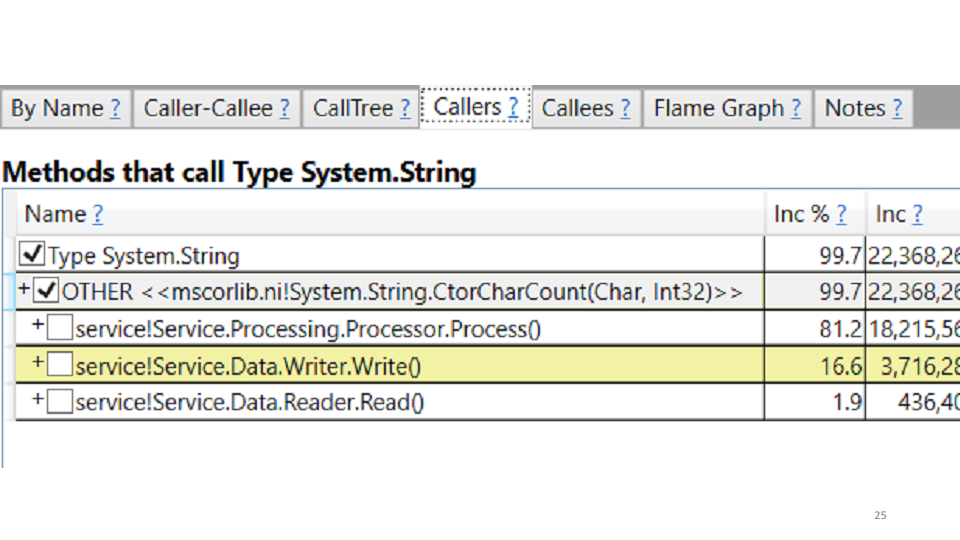
Dans notre cas, cela crée des chaînes. La correction elle-même se suggère: nous remplaçons toutes les chaînes par StringBuilders. Localement, nous obtenons une augmentation de productivité de 20 à 30%. Déployer en production, voir les résultats par rapport à l'ancien planning:
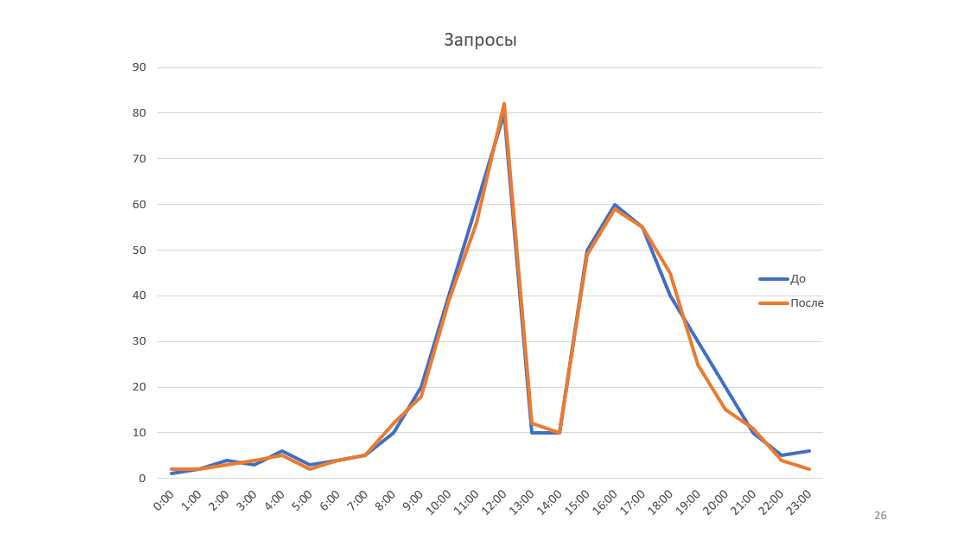
La règle «Comprendre le système» ne consiste pas seulement à comprendre comment les interactions se déroulent dans votre système, comment les messages passent, mais à essayer de modéliser votre système.
Dans l'exemple, le graphique montre la bande passante. Mais si vous regardez l'ensemble du système du point de vue de la théorie des files d'attente, il s'avère que le débit de notre système dépend d'un seul paramètre - la vitesse d'arrivée de nouveaux messages. En fait, le système ne contenait tout simplement pas plus de 80 messages à la fois, il n'y a donc aucun moyen d'optimiser ce calendrier.
Vérifiez la fiche. Si vous ouvrez la documentation d'un appareil électroménager, elle y sera définitivement inscrite: si l'appareil ne fonctionne pas, vérifiez que la fiche est insérée dans la prise. Après plusieurs heures dans le débogueur, je me retrouve souvent à penser que je devais juste recompiler ou simplement récupérer la dernière version.
La règle «vérifier la fiche» concerne les faits et les données. Le débogage ne commence pas par l'exécution de WinDbg ou PerfView sur les machines de production, il commence par la vérification des faits et des données. Si le service ne répond pas, il se peut qu'il ne fonctionne tout simplement pas.
Divisez et conquérez. C'est la première et probablement la seule règle qui inclut le débogage en tant que processus. Il s'agit d'hypothèses, de leur promotion et de leur test.
Un de nos services n'a pas voulu s'arrêter.
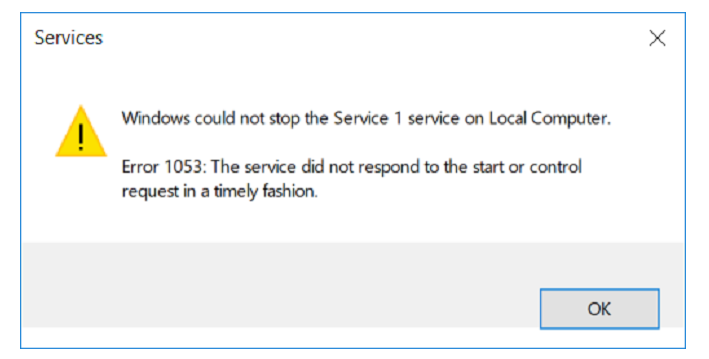
Nous faisons une hypothèse: il y a peut-être un cycle dans le projet qui traite quelque chose à l'infini.
Vous pouvez tester l'hypothèse de différentes manières, une option consiste à effectuer un vidage de la mémoire. Nous retirons les piles d'appels du vidage et de tous les threads en utilisant la commande
~*e!ClrStack . Nous commençons à regarder et à voir trois flux.
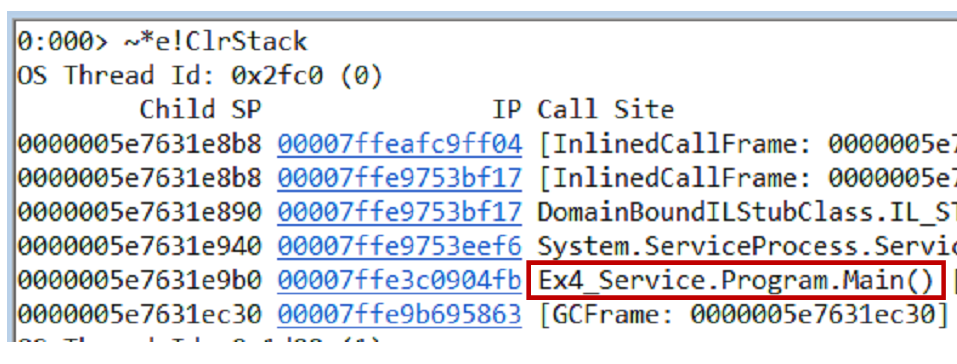
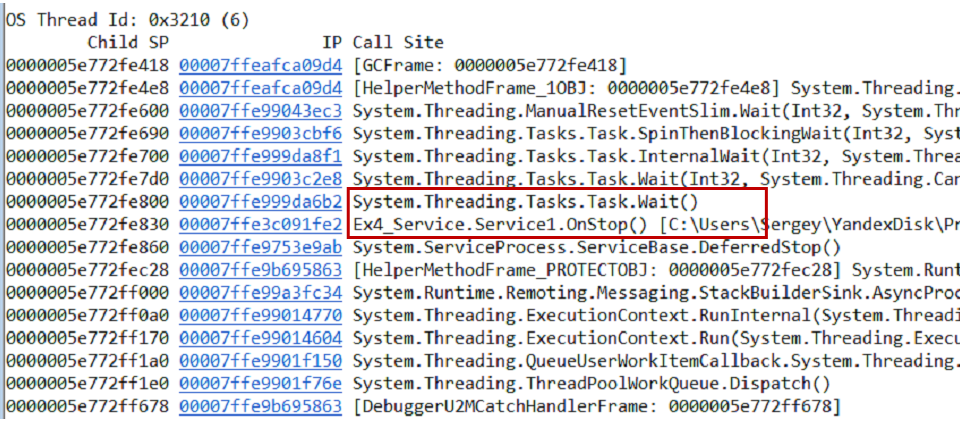
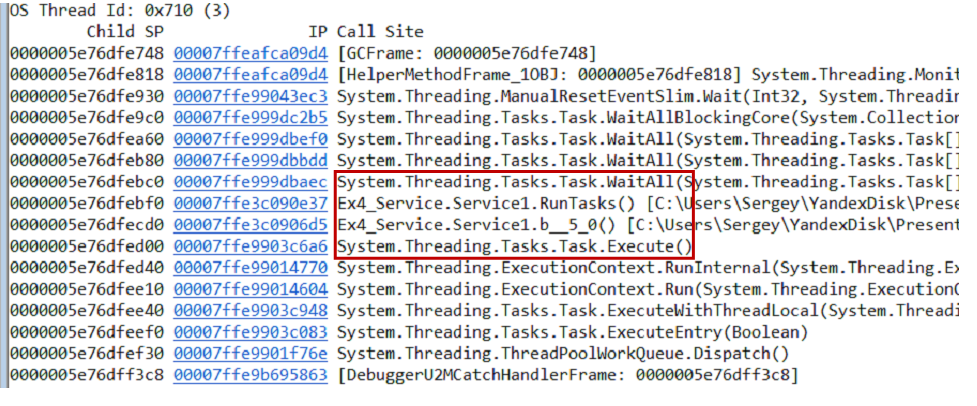
Le premier thread est dans Main, le second est dans le gestionnaire
OnStop() et le troisième thread attendait certaines tâches internes. Ainsi, notre hypothèse n'est pas justifiée. Il n'y a pas de boucle, tous les threads attendent quelque chose. Impasse probablement.
Notre service fonctionne comme suit. Il y a deux tâches - l'initialisation et le travail. L'initialisation ouvre une connexion à la base de données, le travailleur commence à traiter les données. La communication entre eux s'effectue via un indicateur commun, qui est implémenté à l'aide de
TaskCompletionSource .
Nous faisons la deuxième hypothèse: nous avons peut-être une impasse d'une tâche pour la seconde. Pour vérifier cela, vous pouvez voir chaque tâche séparément via WinDbg.
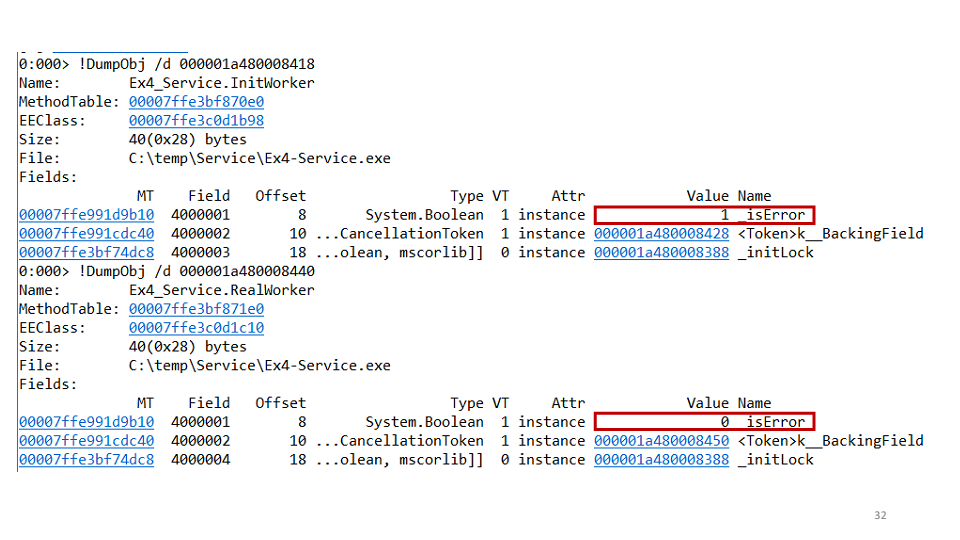
Il s'avère que l'une des tâches est tombée, et la seconde non. Dans le projet, nous avons vu le code suivant:
await openAsync(); _initLock.SetResult(true);
Cela signifie que la tâche d'initialisation ouvre la connexion et définit ensuite
TaskCompletionSource sur true. Mais que faire si une exception tombe ici? Ensuite, nous n'avons pas le temps de définir
SetResult sur true, donc le correctif de ce bogue était le suivant:
try { await openAsync(); _initLock.SetResult(true); } catch(Exception ex) { _initLock.SetException(ex); }
Dans cet exemple, nous proposons deux hypothèses: la boucle infinie et l'impasse. La règle "diviser pour mieux régner" permet de localiser l'erreur. Des approximations successives résolvent de tels problèmes.
La chose la plus importante dans cette règle est les hypothèses, car au fil du temps, elles se transforment en modèles. Et selon l'hypothèse, nous utilisons différentes actions.
Rafraîchissez-vous. Cette règle est que vous avez juste besoin de vous lever de la table et de marcher, de boire de l'eau, du jus ou du café, de faire n'importe quoi, mais le plus important est de vous distraire de votre problème.
Il existe une très bonne méthode appelée canard. Selon la méthode, il faut parler du problème du
canard . Vous pouvez utiliser un collègue comme
canard . De plus, il n'a pas à répondre, il suffit d'écouter et d'accepter. Et souvent, après la première discussion du problème, vous trouvez vous-même une solution.
Ceci est votre bug. Je vais parler de cette règle par un exemple.
Il y avait un problème dans une
AccessViolationException . En regardant dans la pile d'appels, j'ai vu que cela s'est produit lorsque nous avons généré la requête LinqToSql à l'intérieur du client sql.

De ce bug, il était clair que quelque part l'intégrité de la mémoire est violée. Heureusement, à cette époque, nous utilisions déjà un système de gestion du changement. En conséquence, après quelques heures, il est devenu clair ce qui s'est passé: nous avons installé .Net 4.5.2 sur nos machines de production.
En conséquence, nous envoyons le bogue à Microsoft, ils l'examinent, nous communiquons avec eux, ils corrigent le bogue dans .Net 4.6.1.
Pour moi, cela s'est traduit par 11 mois de travail avec le support Microsoft, bien sûr, pas tous les jours, mais il a fallu 11 mois depuis le début pour corriger. De plus, nous leur avons envoyé des dizaines de gigaoctets de vidages mémoire, nous avons mis des centaines d'assemblys privés pour rattraper cette erreur. Et pendant tout ce temps, nous n'avons pas pu dire à nos clients que Microsoft était à blâmer, pas nous. Par conséquent, le bug est toujours le vôtre.
Cinq pourquoi. Dans notre entreprise, nous utilisons Elastic. L'élastique est bon pour l'agrégation de journaux.
Vous venez travailler le matin et les mensonges élastiques.
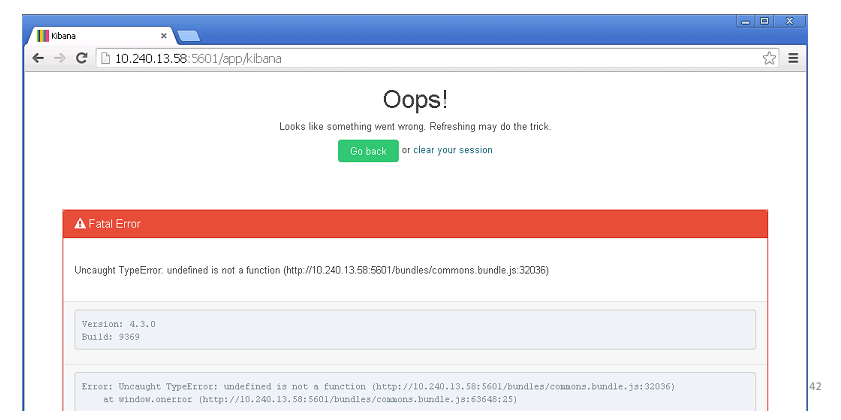
La première question est pourquoi est élastique? Presque immédiatement, il est devenu clair - les nœuds principaux sont tombés. Ils coordonnent le travail de l'ensemble du cluster et lorsqu'ils tombent, l'ensemble du cluster cesse de répondre. Pourquoi ne se sont-ils pas levés? Peut-être qu'il devrait y avoir un démarrage automatique? Après avoir recherché la réponse, nous avons constaté que la version du plugin ne correspond pas. Pourquoi les nœuds principaux sont-ils tombés? Ils ont été tués par OOM Killer. C'est une telle chose sur les machines Linux, qui en cas de manque de mémoire ferme les processus inutiles. Pourquoi n'y a-t-il pas assez de mémoire? Parce que le processus de mise à jour a commencé, ce qui découle des journaux système. Pourquoi cela a-t-il fonctionné avant, mais pas maintenant? Et comme nous avions ajouté de nouveaux nœuds une semaine plus tôt, les nœuds maîtres avaient donc besoin de plus de mémoire pour stocker les index et les configurations de cluster.
Les questions "pourquoi?" aider à trouver la racine du problème. Dans l'exemple, nous pourrions désactiver le bon chemin plusieurs fois, mais le correctif complet ressemble à ceci: mettre à jour le plug-in, lancer les services, augmenter la mémoire et prendre une note pour l'avenir, que la prochaine fois, lors de l'ajout de nouveaux nœuds au cluster, vous devez vous assurer que la mémoire sur Master est suffisante Noeuds
L'application de ces règles vous permet de révéler des problèmes réels, de vous concentrer sur la résolution de ces problèmes et aide à communiquer. Mais ce serait encore mieux si ces règles formaient un système. Et il existe un tel système, il s'appelle l'algorithme de débogage.
Algorithme de débogage
Pour la première fois, j'ai lu à propos de l'algorithme de débogage dans le livre John Robbins Debugging applications. Il décrit le processus de débogage comme suit:
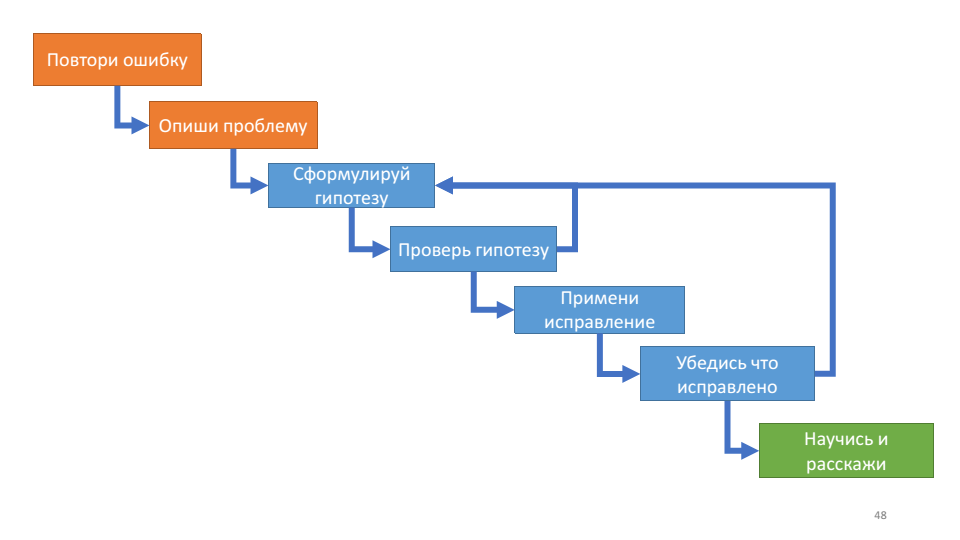
Cet algorithme est utile pour sa boucle interne - travaillant avec une hypothèse.
A chaque tour de cycle, nous pouvons nous vérifier: en savons-nous plus sur le système ou non? Si nous émettons des hypothèses, vérifiez, elles ne fonctionnent pas, nous n’apprenons rien de nouveau sur le fonctionnement du système, alors il est probablement temps de se rafraîchir. Deux questions actuelles à ce stade: quelles hypothèses avez-vous testées et quelle hypothèse testez-vous maintenant.
Cet algorithme s'accorde très bien avec les règles de débogage dont nous avons parlé plus haut: répétez l'erreur - c'est votre bogue, décrivez le problème - comprenez le système, formulez une hypothèse - divisez et conquérez, testez l'hypothèse - vérifiez la fiche, assurez-vous qu'elle est corrigée - cinq pourquoi.
J'ai un bon exemple pour cet algorithme. Une exception est tombée sur l'un de nos services Web.
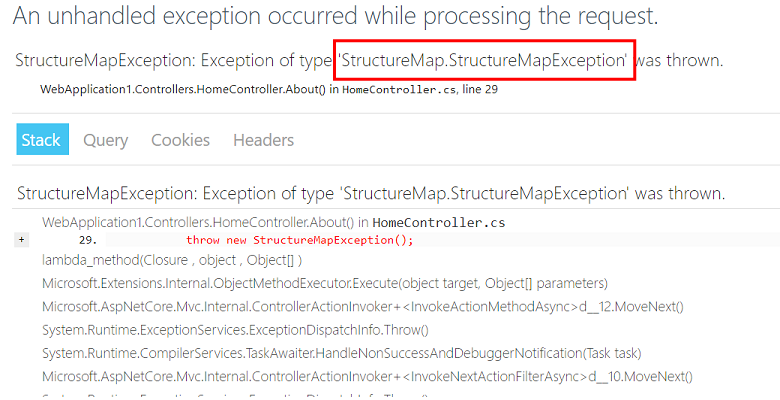
Notre première pensée n'est pas notre problème. Mais selon les règles, c'est toujours notre problème.
Tout d'abord, répétez l'erreur. Pour chaque millier de demandes, il existe environ une
StructureMapException , afin que nous puissions reproduire le problème.
Deuxièmement, nous essayons de décrire le problème: si l'utilisateur fait une demande http pour notre service au moment où StructureMap essaie de créer une nouvelle dépendance, alors une exception se produit.
Troisièmement, nous émettons l'hypothèse que StructureMap est un wrapper et qu'il y a quelque chose à l'intérieur qui lève une exception interne. Nous testons l'hypothèse à l'aide de procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
Il s'avère que l'intérieur est une
NullReferenceException .
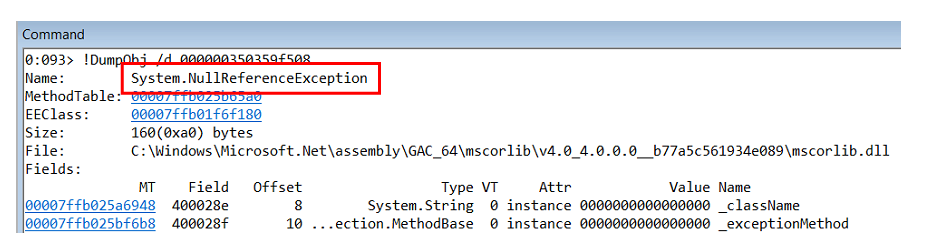
En étudiant la pile d'appels de cette exception, nous comprenons qu'elle se produit à l'intérieur du générateur d'objet dans le StructureMap lui-même.
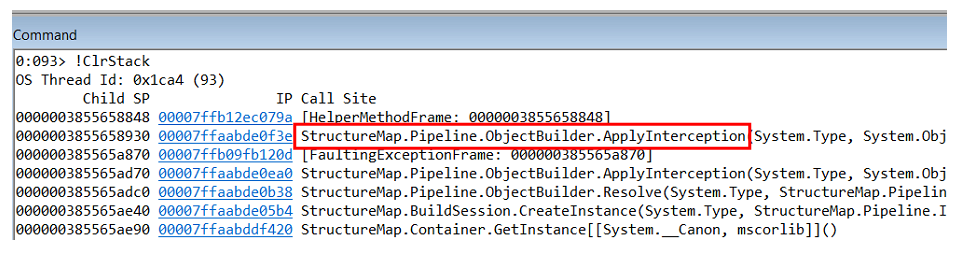
Mais
NullReferenceException n'est pas le problème lui-même, mais la conséquence. Vous devez comprendre où cela se produit et qui le génère.
Nous proposons l'hypothèse suivante: pour une raison quelconque, notre code retourne une dépendance nulle. Étant donné que dans .Net tous les objets en mémoire sont localisés un par un, si nous regardons les objets sur le tas qui se trouvent avant la
NullReferenceException , ils pointeront probablement vers le code qui a levé l'exception.
Dans WinDbg, il existe une commande - Liste des objets proches
!lno . Cela montre que l'objet qui nous intéresse est la fonction lambda, qui est utilisée dans le code suivant.
public CompoundInterceptor FindInterceptor(Type type) { CompoundInterceptop interceptor; if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { lock (_locker) { if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type)); interceptor = new CompoundInterceptor(interceptorArray); _analyzedInterceptors.Add(type, interceptor); } } } return interceptor; }
Dans ce code, nous vérifions d'abord si la valeur dans le
Dictionary _analyzedInterceptors dans
_analyzedInterceptors , si nous ne la trouvons pas, puis ajoutons une nouvelle valeur à l'intérieur du
lock .
En théorie, ce code ne peut jamais retourner null. Mais le problème ici est dans
_analyzedInterceptors , qui utilise un
Dictionary ordinaire dans un environnement multi-thread, pas un
ConcurrentDictionary .
La racine du problème a été trouvée, nous avons mis à jour la dernière version de StructureMap, déployée, vérifié que tout était corrigé. La dernière étape de notre algorithme est «apprendre et dire». Dans notre cas, il s'agissait d'une recherche dans le code de tous les
Dictionary utilisés dans le verrouillage et de vérifier que tous sont utilisés correctement.
Ainsi, l'algorithme de débogage est un algorithme intuitif qui fait gagner un temps considérable. Il se concentre sur l'hypothèse - et c'est la chose la plus importante dans le débogage.
Débogage proactif
À la base, le débogage proactif répond à la question «que se passe-t-il lorsqu'un bogue apparaît».
L'importance des techniques de débogage proactives peut être vue dans le diagramme du cycle de vie des bogues.
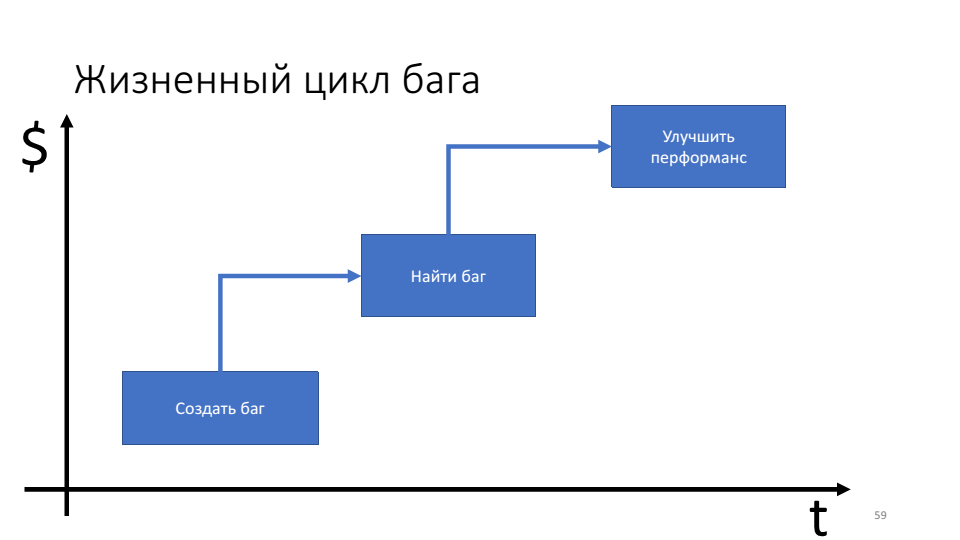
Le problème est que plus la durée de vie du bogue est longue, plus nous consacrons de ressources (temps) à celui-ci.
Les règles de débogage et l'algorithme de débogage nous concentrent sur le moment où le bogue est détecté et nous pouvons déterminer quoi faire ensuite. En fait, nous voulons changer notre focus au moment où le bogue a été créé. Je crois que nous devrions faire le produit minimum déboguable (MDP), c'est-à-dire un produit qui possède le minimum d'infrastructure nécessaire pour un débogage efficace en production.
MDP se compose de deux choses: la fonction fitness et la méthode USE.
Caractéristiques de remise en forme. Ils ont été popularisés par Neil Ford et co-auteurs dans le livre Building Evolutionary Architectures. À la base, les fonctions de fitness, selon les auteurs du livre, ressemblent à ceci: il existe une architecture d'application que nous pouvons couper sous différents angles, obtenant des propriétés architecturales telles que la
maintenabilité , les
performances , etc., et pour chaque section, nous devons écrire un test - fitness -fonction. Ainsi, une fonction de fitness est un test d'architecture.
Dans le cas de MDP, la fonction fitness est un test de débogage. Vous pouvez utiliser tout ce que vous voulez pour écrire de tels tests: NUnit, MSTest, etc. Mais, comme le débogage fonctionne souvent avec des outils externes, je vais démontrer l'utilisation de Pester (framework de test d'unité powershell) comme exemple. Son avantage ici est qu'il fonctionne bien avec la ligne de commande.
Par exemple, au sein de l'entreprise, nous convenons d'utiliser des bibliothèques spécifiques pour la journalisation; lors de la journalisation, nous utiliserons des modèles spécifiques; les caractères pdb doivent toujours être donnés au serveur de symboles. Ce seront les conventions que nous testerons dans nos tests.
Describe 'Debuggability' { It 'Contains line numbers in PDBs' { Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") ` | ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } ` | Where-Object { $_ -like "*Line nubmers: TRUE*" } ` | Should -Not –BeNullOrEmpty } }
Ce test vérifie que tous les caractères pdb ont été donnés au serveur de symboles et ont été donnés correctement, c'est-à-dire ceux qui contiennent des numéros de ligne à l'intérieur. Pour ce faire, nous prenons la version compilée de la production, trouvons tous les fichiers exe et dll, passons tous ces fichiers binaires via l'utilitaire syschk.exe, qui est inclus dans le package des outils de débogage pour Windows. L'utilitaire syschk.exe vérifie le binaire avec le serveur de symboles et, s'il y trouve un fichier pdb, imprime un rapport à ce sujet. Dans le rapport, nous recherchons la ligne «Numéros de ligne: VRAI». Et en finale on vérifie que le résultat n'est pas «nul ou vide».
Ces tests doivent être intégrés dans un pipeline de déploiement continu. Une fois les tests d'intégration et les tests unitaires réussis, les fonctions de mise en forme sont lancées.
Je vais montrer un autre exemple avec la vérification des bibliothèques nécessaires dans le code.
Describe 'Debuggability' { It 'Contains package for logging' { Get-ChildItem -Path . -Recurse -Name "packages.config" ` | ForEach-Object { Get-Content "$_" } ` | Where-Object { $_ -like "*nlog*" } ` | Should -Not –BeNullOrEmpty } }
Dans le test, nous prenons tous les fichiers packages.config et essayons d'y trouver les bibliothèques nlog. De même, nous pouvons vérifier que le champ id de corrélation est utilisé à l'intérieur du champ nlog.
UTILISEZ les méthodes. La dernière chose que MDP comprend est les mesures que vous devez collecter.
Je vais démontrer par l'exemple de la méthode USE, qui a été popularisée par Brendan Gregg.
L'idée est simple: s'il y a un problème dans le code, il suffit de prendre trois métriques: utilisation (saturation), saturation (erreurs), ce qui aidera à comprendre où est le problème.Certaines entreprises, par exemple Circonus (elles font du soft monitoring), construisent leurs tableaux de bord sous forme de métriques désignées.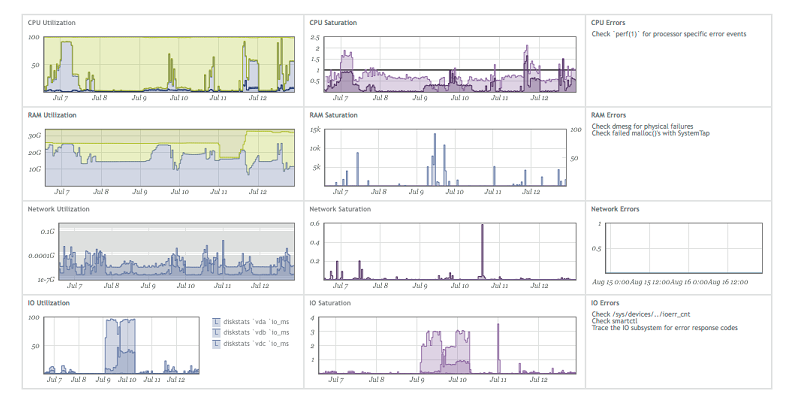 Si vous regardez en détail, par exemple, la mémoire, alors l'utilisation est la quantité de mémoire libre, la saturation est le nombre d'accès au disque, les erreurs sont toutes les erreurs qui sont apparues. Par conséquent, pour rendre les produits plus pratiques pour le débogage, vous devez collecter les métriques USE pour toutes les fonctionnalités et toutes les parties du sous-système.Si vous utilisez une fonctionnalité commerciale, vous pouvez très probablement y distinguer trois mesures:
Si vous regardez en détail, par exemple, la mémoire, alors l'utilisation est la quantité de mémoire libre, la saturation est le nombre d'accès au disque, les erreurs sont toutes les erreurs qui sont apparues. Par conséquent, pour rendre les produits plus pratiques pour le débogage, vous devez collecter les métriques USE pour toutes les fonctionnalités et toutes les parties du sous-système.Si vous utilisez une fonctionnalité commerciale, vous pouvez très probablement y distinguer trois mesures:- Utilisation - temps de traitement de la demande.
- La saturation est la longueur de la file d'attente.
- Erreurs - toutes situations exceptionnelles.
À titre d'exemple, regardons un graphique du nombre de demandes traitées par l'un de nos systèmes. Comme vous pouvez le constater, le service n'a pas traité les demandes au cours des trois dernières heures.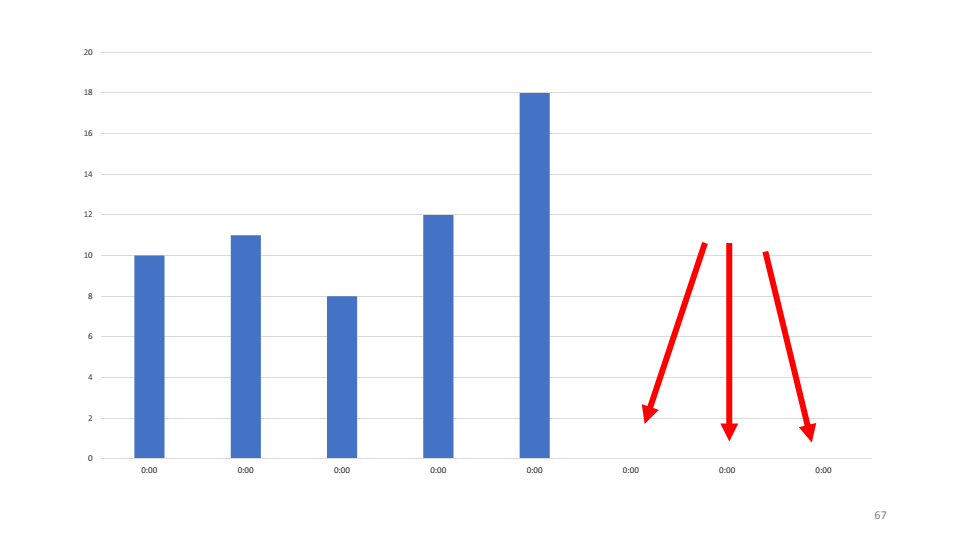 La première hypothèse que nous avons faite est que le service est tombé et que nous devons le redémarrer. Lors de la vérification, il s'avère que le service fonctionne, il utilise 4-5% du CPU.
La première hypothèse que nous avons faite est que le service est tombé et que nous devons le redémarrer. Lors de la vérification, il s'avère que le service fonctionne, il utilise 4-5% du CPU.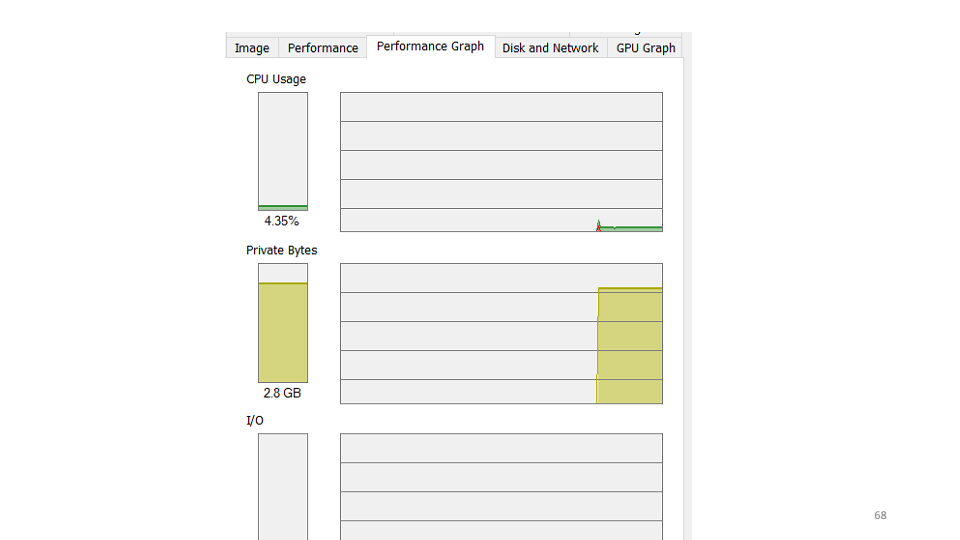 La deuxième hypothèse est qu'une erreur relève du service que nous ne voyons pas. Nous utiliserons l'utilitaire etrace.
La deuxième hypothèse est qu'une erreur relève du service que nous ne voyons pas. Nous utiliserons l'utilitaire etrace. etrace --kernel Process ^ --where ProcessName=Ex5-Service ^ --clr Exception
L'utilitaire vous permet de vous abonner aux événements ETW en temps réel et de les afficher à l'écran.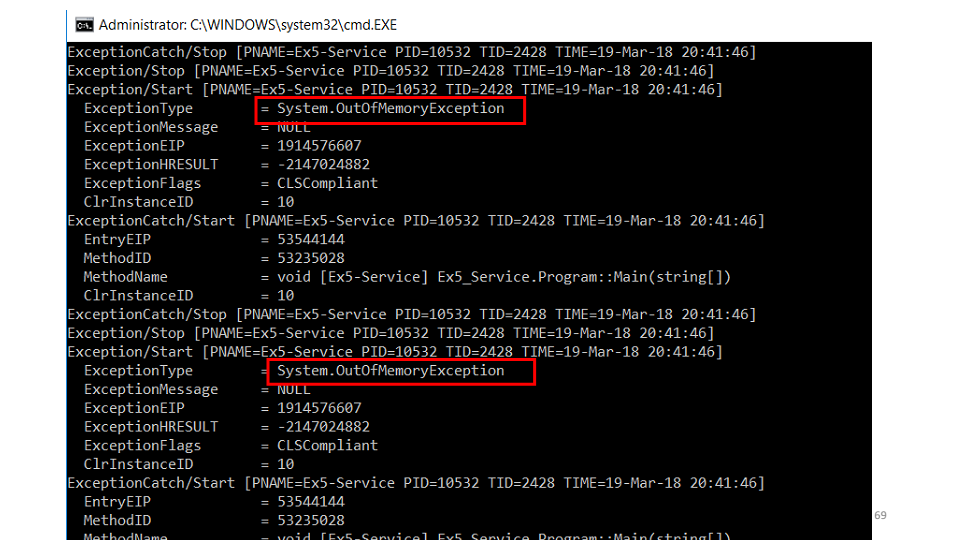 On voit que ça tombe
On voit que ça tombe OutOfMemoryException. Mais, la deuxième question, pourquoi n'est-elle pas dans les journaux? La réponse est rapide - nous l'interceptons, essayons de nettoyer la mémoire, attendons un peu et recommençons à travailler. while (ShouldContinue()) { try { Do(); } catch (OutOfMemoryException) { Thread.Sleep(100); GC.CollectionCount(2); GC.WaitForPendingFinalizers(); } }
L'hypothèse suivante est que quelqu'un mange toute la mémoire. Selon le vidage de la mémoire, la plupart des objets sont dans le cache. public class Cache { private static ConcurrentDictionary<int, String> _items = new ... private static DateTime _nextClearTime = DateTime.UtcNow; public String GetFromCache(int key) { if (_nextClearTime < DateTime.UtcNow) { _nextClearTime = DateTime.UtcNow.AddHours(1); _items.Clear(); } return _items[key]; } }
Le code montre que toutes les heures, le cache doit être effacé. Mais la mémoire n'était pas suffisante, ils n'ont même pas atteint le nettoyage. Regardons un exemple de la métrique de cache USE.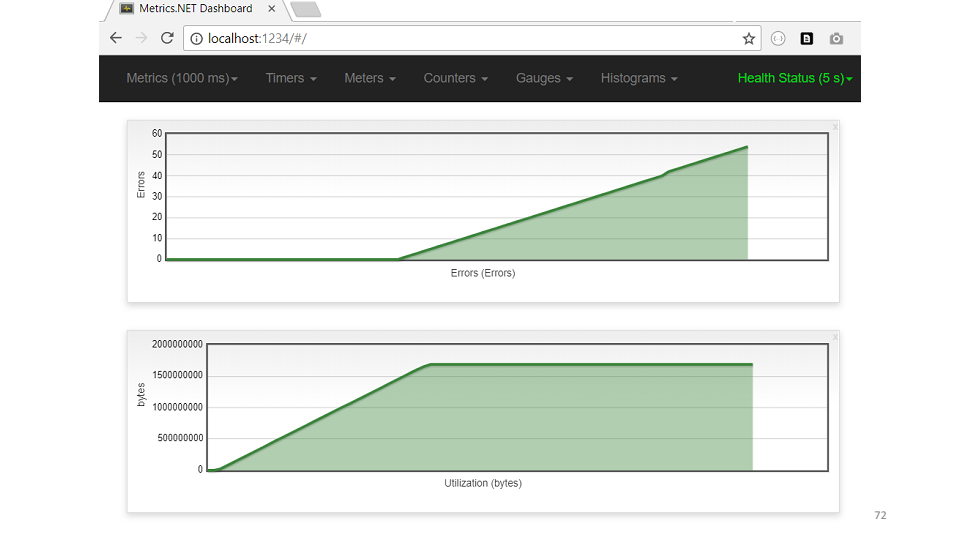 Selon le calendrier, il est immédiatement visible - la mémoire a augmenté, les erreurs ont immédiatement commencé.Donc, conclusions sur ce qu'est le débogage proactif.
Selon le calendrier, il est immédiatement visible - la mémoire a augmenté, les erreurs ont immédiatement commencé.Donc, conclusions sur ce qu'est le débogage proactif.- — . , , — . — , -. , .
- . ; Exception , , - .
- Minimum Debuggable Product — , .
, ?
- .
- .
- .
Cette fois, le sponsor de notre annonce est Jon Skeet. Même si vous n'allez pas à Moscou pour le nouveau DotNext , la vidéo vaut le détour (John a essayé dur).