Remarque perev. : L'auteur de l'article original, Nicolas Leiva, est un architecte de solutions Cisco qui a décidé de partager avec ses collègues, ingénieurs réseau, comment le réseau Kubernetes fonctionne de l'intérieur. Pour ce faire, il explore sa configuration la plus simple dans le cluster, en appliquant activement le bon sens, sa connaissance des réseaux et des utilitaires Linux / Kubernetes standard. Cela s'est avéré volumineux, mais très clair.
En plus du fait que le
guide Kubernetes The Hard Way de Kelsey Hightower fonctionne (
même sur AWS! ), J'ai aimé que le réseau soit maintenu propre et simple; et c'est une excellente occasion de comprendre le rôle, par exemple, de l'interface réseau de conteneurs (
CNI ). Cela dit, j'ajouterai que le réseau Kubernetes n'est pas vraiment très intuitif, surtout pour les débutants ... et n'oubliez pas non plus "qu'il n'y a
tout simplement pas de réseau de conteneurs".
Bien qu'il existe déjà de bons documents sur ce sujet (voir les liens
ici ), je n'ai pas pu trouver un tel exemple que je combinerais tout ce qui est nécessaire avec les conclusions des équipes que les ingénieurs de réseau aiment et détestent, démontrant ce qui se passe réellement dans les coulisses. Par conséquent, j'ai décidé de collecter des informations à partir de nombreuses sources - j'espère que cela vous aide et que vous comprenez mieux comment tout est connecté les uns aux autres. Cette connaissance est importante non seulement pour vous tester, mais aussi pour simplifier le processus de diagnostic des problèmes. Vous pouvez suivre l'exemple dans votre cluster de
Kubernetes The Hard Way : toutes les adresses IP et tous les paramètres sont extraits de là (à partir des validations de mai 2018, avant d'utiliser
les conteneurs Nabla ).
Et nous commencerons par la fin, lorsque nous aurons trois contrôleurs et trois nœuds de travail:
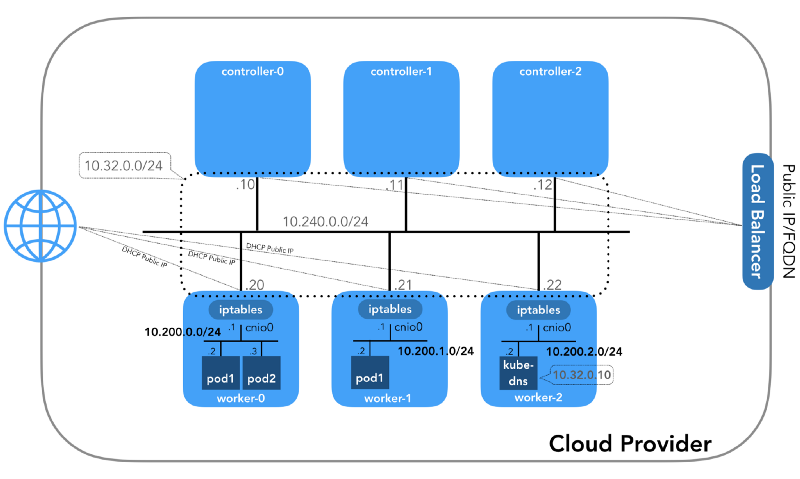
Vous remarquerez peut-être qu'il y a également au moins trois sous-réseaux privés ici! Un peu de patience, et ils seront tous pris en considération. N'oubliez pas que même si nous nous référons à des préfixes IP très spécifiques, ils sont simplement extraits de
Kubernetes The Hard Way , de sorte qu'ils n'ont qu'une signification locale, et vous êtes libre de choisir tout autre bloc d'adresses pour votre environnement conformément à la
RFC 1918 . Pour le cas d'IPv6, il y aura un article de blog séparé.
Réseau hôte (10.240.0.0/24)
Il s'agit d'un réseau interne dont tous les nœuds font partie. Défini par l'
--private-network-ip dans
GCP ou l'
--private-ip-address dans
AWS lors de l'allocation des ressources informatiques.
Initialisation des nœuds de contrôleur dans GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
Initialisation des nœuds de contrôleur dans AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
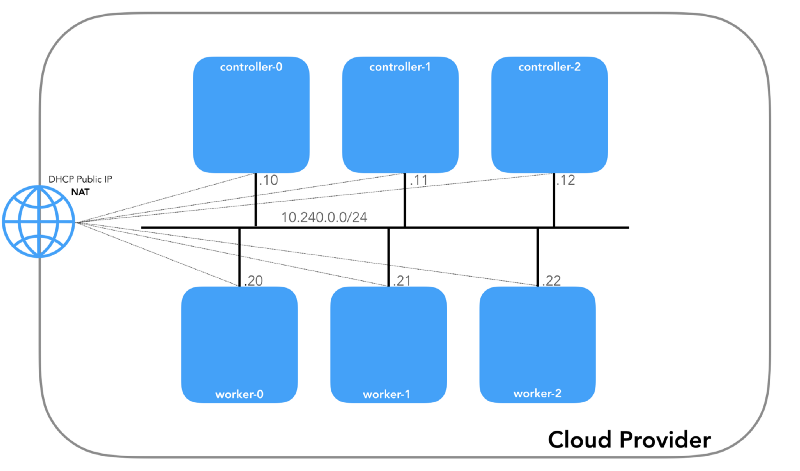
Chaque instance aura deux adresses IP: privée du réseau hôte (contrôleurs -
10.240.0.1${i}/24 , travailleurs -
10.240.0.2${i}/24 ) et publique, désignée par le fournisseur de cloud, dont nous parlerons plus tard comment se rendre à
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
Aws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
Tous les nœuds doivent pouvoir se pinguer si les
politiques de sécurité sont correctes (et si le
ping installé sur l'hôte).
Réseau de foyer (10.200.0.0/16)
Il s'agit du réseau dans lequel vivent les modules. Chaque nœud de travail utilise un sous-réseau de ce réseau. Dans notre cas,
POD_CIDR=10.200.${i}.0/24 pour le
worker-${i} .
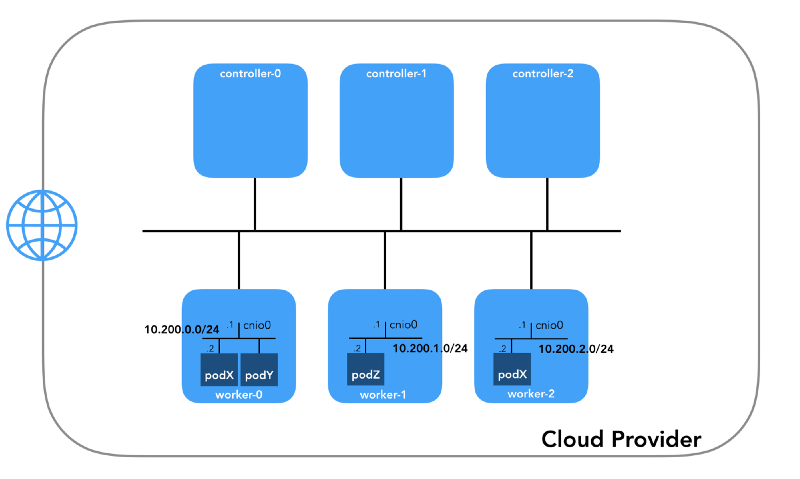
Pour comprendre comment tout est configuré, prenez du recul et examinez
le modèle de réseau Kubernetes , qui nécessite les éléments suivants:
- Tous les conteneurs peuvent communiquer avec tout autre conteneur sans utiliser NAT.
- Tous les nœuds peuvent communiquer avec tous les conteneurs (et vice versa) sans utiliser NAT.
- L'IP que le conteneur voit doit être la même que les autres le voient.
Tout cela peut être implémenté de plusieurs façons, et Kubernetes transmet la configuration réseau au
plugin CNI .
«Le plugin CNI est chargé d'ajouter une interface réseau à l' espace de noms réseau du conteneur (par exemple, une extrémité d'une paire de veth ) et d'apporter les modifications nécessaires sur l'hôte (par exemple, connecter la deuxième extrémité de veth à un pont). Il doit ensuite attribuer une interface IP et configurer les routes conformément à la section Gestion des adresses IP en appelant le plugin IPAM souhaité. » (à partir de la spécification de l'interface réseau du conteneur )
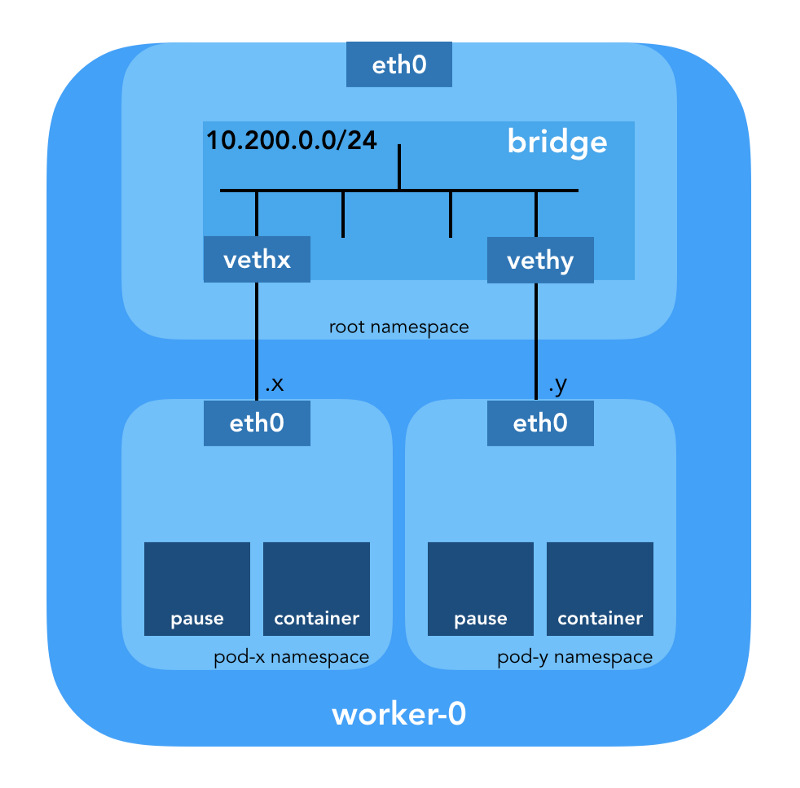
Espace de noms réseau
«L'espace de noms encapsule la ressource système globale dans une abstraction visible par les processus de cet espace de noms de telle sorte qu'ils aient leur propre instance isolée de la ressource globale. Les modifications de la ressource globale sont visibles pour les autres processus inclus dans cet espace de noms, mais pas pour les autres processus. » (à partir de la page de manuel des espaces de noms )
Linux fournit sept espaces de noms différents (
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS ). Les espaces de noms réseau (
CLONE_NEWNET ) définissent les ressources réseau disponibles pour le processus: «Chaque espace de noms réseau possède ses propres périphériques réseau, adresses IP, tables de routage IP,
/proc/net , numéros de port, etc.»
( de l'article « Espaces de noms en fonctionnement ») .
Périphériques Ethernet virtuels (Veth)
«Une paire de réseaux virtuels (veth) offre une abstraction sous la forme d'un« canal », qui peut être utilisé pour créer des tunnels entre des espaces de noms réseau ou pour créer un pont vers un périphérique réseau physique dans un autre espace réseau. Lorsque l'espace de noms est libéré, tous les périphériques Veth qu'il contient sont détruits. » (à partir de la page de manuel des espaces de noms réseau )
Descendez au sol et voyez comment tout cela se rapporte au cluster. Premièrement,
les plugins réseau de Kubernetes sont divers et les plugins CNI en font partie (
pourquoi pas CNM? ).
Kubelet sur chaque nœud indique au
runtime du conteneur le
plug-in réseau à utiliser. L'interface
CNI (Container Network Interface) se situe entre le runtime du conteneur et l'implémentation du réseau. Et déjà le plugin CNI met en place le réseau.
«Le plugin CNI est sélectionné en passant l' --network-plugin=cni ligne de commande --network-plugin=cni à Kubelet. Kubelet lit le fichier à partir de --cni-conf-dir (la valeur par défaut est /etc/cni/net.d ) et utilise la configuration CNI de ce fichier pour configurer le réseau pour chaque fichier. " (à partir des exigences du plugin réseau )
Les vrais fichiers binaires du plugin CNI sont dans
-- cni-bin-dir (la valeur par défaut est
/opt/cni/bin ).
Veuillez noter que les
kubelet.service appel de
kubelet.service incluent
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
Tout d'abord, Kubernetes crée un espace de noms réseau pour le foyer, avant même d'appeler des plugins. Ceci est mis en œuvre en utilisant le conteneur de
pause spécial, qui "sert de" conteneur parent "pour tous les conteneurs de foyer"
(à partir de l'article " Le conteneur de pause tout-puissant ") . Kubernetes exécute ensuite le plugin CNI pour attacher le conteneur de
pause au réseau. Tous les conteneurs de pod utilisent l'
netns ce conteneur de
pause .
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
La
configuration CNI utilisée indique l'utilisation du plugin de
bridge pour configurer le pont logiciel Linux (L2) dans l'espace de noms racine appelé
cnio0 (le
nom par défaut est
cni0 ), qui agit comme une passerelle (
"isGateway": true ).

Une paire de veth sera également configurée pour connecter le foyer au pont nouvellement créé:
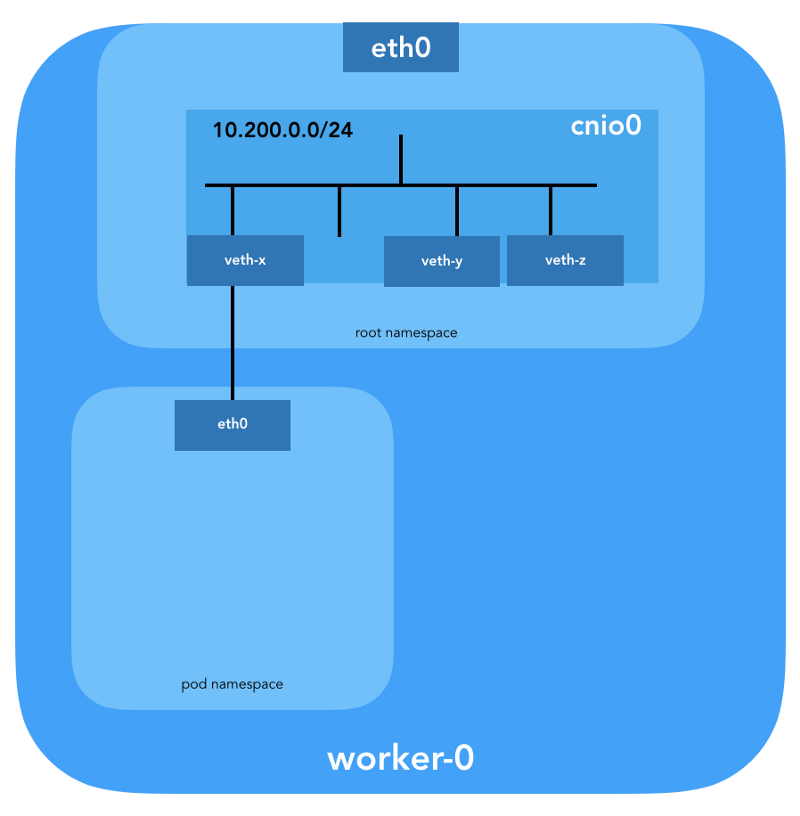
Pour attribuer des informations L3, telles que des adresses IP, le
plug -
in IPAM (
ipam ) est appelé. Dans ce cas, le type
host-local est utilisé, "qui stocke l'état localement sur le système de fichiers hôte, ce qui garantit l'unicité des adresses IP sur un hôte"
(d'après la host-local ) . Le plug-in IPAM renvoie ces informations au plug-in précédent (
bridge ), afin que toutes les routes spécifiées dans la configuration puissent être configurées (
"routes": [{"dst": "0.0.0.0/0"}] ). Si
gw pas spécifié, il
est extrait du sous-réseau . La route par défaut est également configurée dans l'espace de noms réseau du foyer, pointant vers le pont (qui est configuré comme le premier sous-réseau IP du foyer).
Et le dernier détail important: nous avons demandé le
"ipMasq": true (
"ipMasq": true ) pour le trafic provenant du réseau de foyer. Nous n'avons pas vraiment besoin de NAT ici, mais voici la configuration de
Kubernetes The Hard Way . Par conséquent, pour être complet, je dois mentionner que les entrées dans les
iptables plugin
bridge sont configurées pour cet exemple particulier. Tous les paquets du foyer, dont le destinataire ne se trouve pas dans la plage
224.0.0.0/4 ,
seront derrière NAT , ce qui ne répond pas tout à fait à l'exigence "tous les conteneurs peuvent communiquer avec tout autre conteneur sans utiliser NAT." Eh bien, nous prouverons pourquoi le NAT n'est pas nécessaire ...

Acheminement du foyer
Nous sommes maintenant prêts à personnaliser les pods. Examinons tous les espaces réseau des noms de l'un des nœuds de travail et analysons l'un d'eux après avoir créé le déploiement de
nginx partir d'ici . Nous utiliserons
lsns avec l'option
-t pour sélectionner le type d'espace de noms souhaité (c'est-à-dire
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
En utilisant l'option
-i pour
ls nous pouvons trouver leurs numéros d'inode:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Vous pouvez également répertorier tous les espaces de noms réseau à l'aide d'
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
Pour voir tous les processus en cours d'exécution dans l'espace réseau
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ), vous pouvez exécuter, par exemple, la commande suivante:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
On peut voir qu'en plus de faire une
pause dans ce pod, nous avons lancé
nginx . Le conteneur de
pause partage les espaces de noms
net et
ipc avec tous les autres conteneurs de pod. Rappelez-vous le PID de la
pause - 27255; nous y reviendrons.
Voyons maintenant ce que
kubectl raconte à propos de ce pod:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
Plus de détails:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
Nous voyons le nom du pod -
nginx-65899c769f-wxdx6 - et l'ID de l'un de ses conteneurs (
nginx ), mais rien n'a été dit à propos de la
pause . Creusez un nœud de travail plus profond pour faire correspondre toutes les données. N'oubliez pas que
Kubernetes The Hard Way n'utilise pas
Docker , donc pour plus de détails sur le conteneur, nous nous référons à l'utilitaire de console
containerd - ctr
(voir également l'article " Intégration de containerd avec Kubernetes, remplaçant Docker, prêt pour la production " - transfert environ ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
Connaissant l'
k8s.io containerd (
k8s.io ), vous pouvez obtenir l'ID du conteneur
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
... et
pause une
pause aussi:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
L'ID du conteneur
nginx terminant par
…983c7 correspond à ce que nous avons obtenu de
kubectl . Voyons si nous pouvons déterminer quel conteneur de
pause appartient au pod
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
N'oubliez pas que les processus avec les PID 27331 et 27355 s'exécutent dans l'espace de noms réseau
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ?
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... et:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
Nous savons maintenant avec certitude quels conteneurs s'exécutent dans ce module (
nginx-65899c769f-wxdx6 ) et l'espace de noms réseau (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - pause (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

Comment est-ce sous (
nginx-65899c769f-wxdx6 ) connecté au réseau? Nous utilisons le PID 27255 précédemment reçu de
pause pour exécuter des commandes dans son espace de noms réseau (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
À ces fins, nous utiliserons
nsenter avec l'option
-t qui définit le PID cible et
-n sans spécifier de fichier pour entrer dans l'espace de noms réseau du processus cible (27255). Voici ce que dira l'
ip link show :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... et
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Cela confirme que l'adresse IP obtenue précédemment via
kubectl get pod est configurée sur l'interface
eth0 . Cette interface fait partie d'une
paire de Veth , dont une extrémité se trouve dans le foyer et l'autre dans l'espace de noms racine. Pour découvrir l'interface de la seconde extrémité, nous utilisons
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
Nous voyons que
ifindex fête est 7. Vérifiez qu'il se trouve dans l'espace de noms racine. Cela peut être fait en utilisant
ip link :
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
Pour en être sûr enfin, voyons:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
Génial, maintenant tout est clair avec le lien virtuel. En utilisant
brctl voyons qui d'autre est connecté au pont Linux:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
Donc, l'image est la suivante:
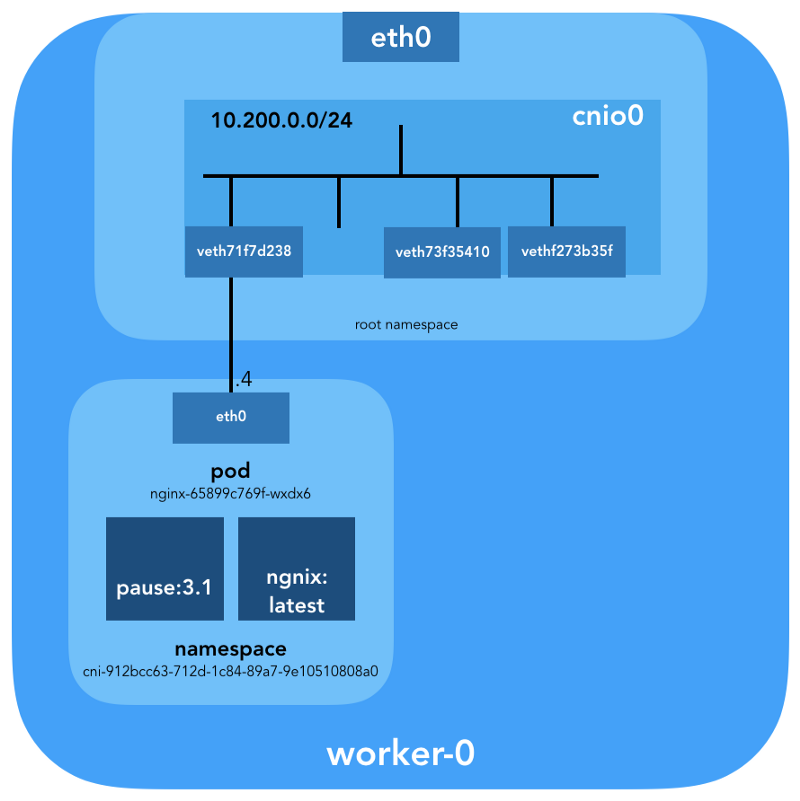
Vérification du routage
Comment transmettons-nous réellement le trafic? Regardons la table de routage dans le pod d'espace de noms de réseau:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
Au moins, nous savons comment accéder à l'espace de noms racine (
default via 10.200.0.1 ). Voyons maintenant la table de routage de l'hôte:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
Nous savons comment transmettre des paquets à un routeur VPC (VPC
a un routeur «implicite», qui a
généralement une deuxième adresse à partir de l'espace d'adressage IP principal du sous-réseau). Maintenant: le routeur VPC sait-il comment se rendre au réseau de chaque foyer? Non, il ne le fait pas, donc on suppose que les routes seront configurées par le plugin CNI ou
manuellement (comme dans le manuel). Apparemment, le
plugin AWS CNI fait exactement cela pour nous chez AWS. N'oubliez pas qu'il existe de
nombreux plugins CNI , et nous envisageons un exemple de
configuration réseau simple :
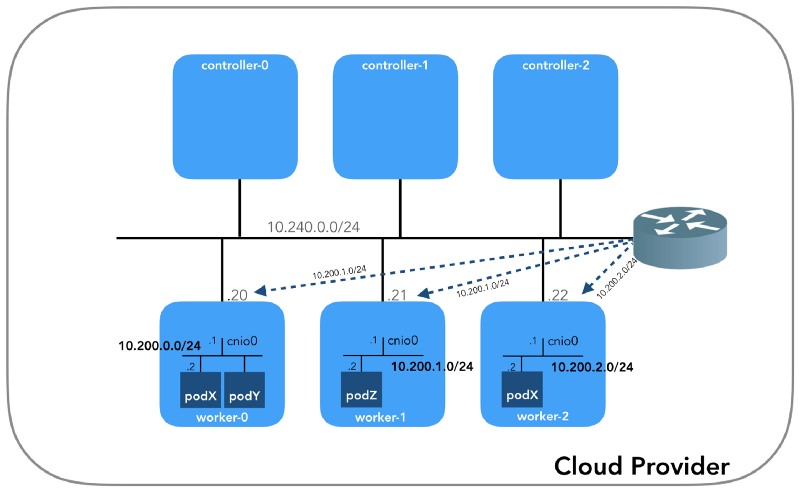
Immersion profonde dans NAT
kubectl create -f busybox.yaml créez deux conteneurs
busybox identiques avec Replication Controller:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
Nous obtenons:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
Les pings d'un conteneur à un autre doivent réussir:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
Pour comprendre le mouvement du trafic, vous pouvez regarder les paquets en utilisant
tcpdump ou
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
L'IP source du pod 10.200.0.21 est traduite en adresse IP de l'hôte 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
Dans iptables, vous pouvez voir que les nombres augmentent:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
D'un autre côté, si vous supprimez
"ipMasq": true de la configuration du plugin CNI, vous pouvez voir ce qui suit (cette opération est effectuée exclusivement à des fins éducatives - nous ne recommandons pas de changer la configuration sur un cluster de travail!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping doit toujours passer:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
Et dans ce cas - sans utiliser NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Nous avons donc vérifié que «tous les conteneurs peuvent communiquer avec n'importe quel autre conteneur sans utiliser NAT».
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Réseau de clusters (10.32.0.0/24)
Vous avez peut-être remarqué dans l'exemple de la
busybox que les adresses IP attribuées à la
busybox étaient différentes dans chaque cas. Et si nous voulions rendre ces conteneurs disponibles pour la communication d'autres foyers? On pourrait prendre les adresses IP actuelles du pod, mais elles changeront. Pour cette raison, vous devez configurer la ressource
Service , qui procurera des requêtes par proxy à de nombreux foyers de courte durée.
«Le service dans Kubernetes est une abstraction qui définit l'ensemble logique des foyers et les politiques par lesquelles ils sont accessibles.» (à partir de la documentation des services Kubernetes )
Il existe différentes façons de publier un service; le type par défaut est
ClusterIP , qui définit l'adresse IP à partir du bloc CIDR du cluster (c'est-à-dire accessible uniquement à partir du cluster). Un tel exemple est le module complémentaire de cluster DNS configuré dans Kubernetes The Hard Way.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl montre que le
Service souvient des points de terminaison et les traduit:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
Comment exactement? ..
iptables nouveau. Passons en revue les règles créées pour cet exemple. Leur liste complète peut être consultée avec la commande
iptables-save .
Dès que les paquets sont créés par le processus (
OUTPUT ) ou arrivent sur l'interface réseau (
PREROUTING ), ils passent par les chaînes
iptables suivantes:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
Les cibles suivantes correspondent aux paquets TCP envoyés au 53e port à 10.32.0.10 et sont transmises au destinataire 10.200.0.27 avec le 53e port:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
De même pour les paquets UDP (destinataire 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Il existe d'autres types de
Services dans Kubernetes. En particulier, Kubernetes The Hard Way
NodePort de
NodePort - voir
Smoke Test: Services .
kubectl expose deployment nginx --port 80 --type NodePort
NodePort publie le service sur l'adresse IP de chaque nœud, en le plaçant sur un port statique (il s'appelle
NodePort ).
NodePort est
NodePort accessible depuis l'extérieur du cluster. Vous pouvez vérifier le port dédié (dans ce cas - 31088) en utilisant
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Under est désormais disponible sur Internet sous le nom
http://${EXTERNAL_IP}:31088/ . Ici,
EXTERNAL_IP est l'adresse IP publique de
toute instance de travail . Dans cet exemple, j'ai utilisé l'adresse IP publique de
worker-0 . La demande est reçue par un hôte avec une adresse IP interne de 10.240.0.20 (le fournisseur de cloud est engagé dans le NAT public), cependant, le service est réellement démarré sur un autre hôte (
travailleur-1 , qui peut être vu par l'adresse IP du point final - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
Le paquet est envoyé de
travailleur-0 à
travailleur-1 , où il trouve son destinataire:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
Un tel circuit est-il idéal? Peut-être pas, mais ça marche. Dans ce cas, les règles programmées
iptables sont les suivantes:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
En d'autres termes, l'adresse du destinataire des paquets avec le port 31088 est diffusée le 10.200.1.18. Le port diffuse également, de 31088 à 80.
Nous n'avons pas
LoadBalancer un autre type de service -
LoadBalancer - qui rend le service accessible au public à l'aide d'un équilibreur de charge de fournisseur de cloud, mais l'article s'est déjà révélé volumineux.
Conclusion
Il peut sembler qu'il y a beaucoup d'informations, mais nous n'avons touché que la pointe de l'iceberg. À l'avenir, je vais parler d'IPv6, IPVS, eBPF et de quelques plugins CNI actuels intéressants.
PS du traducteur
Lisez aussi dans notre blog: