Dans la nouvelle version
unitaire de 2018, ils ont finalement officiellement ajouté le nouveau
système de composants d'entité, ou
ECS pour faire court, qui vous permet de travailler uniquement avec leurs données au lieu du travail habituel avec les composants d'objet.
Un système de tâches supplémentaire vous propose d'utiliser la puissance de calcul parallèle pour améliorer les performances de votre code.
Ensemble, ces deux nouveaux systèmes (
ECS et
Job System ) offrent un nouveau niveau de traitement des données.
Plus précisément, dans cet article, je n'analyserai pas l'ensemble du système
ECS , qui est actuellement disponible sous la forme d'un ensemble d'outils téléchargés séparément dans l'
unité , mais je ne considérerai que le système de tâches et comment il peut être utilisé en dehors du package
ECS .
Nouveau système
Initialement, l'
unité pouvait utiliser l'informatique multithread, mais tout cela devait être créé par le développeur lui-même, pour résoudre les problèmes lui-même et contourner les pièges. Et si auparavant, il était nécessaire de travailler directement avec des choses telles que la création de threads, la fermeture de threads, les pools, la synchronisation, maintenant tout ce travail tombait sur les épaules du moteur, et le développeur lui-même n'avait plus qu'à créer des tâches et les terminer.
Les tâches
Pour effectuer des calculs dans le nouveau système, il est nécessaire d'utiliser des tâches qui sont des objets composés de méthodes et de données pour le calcul.
Comme toutes les autres données du système
ECS , les tâches du
Job System sont également représentées comme des structures héritant de l'une des trois interfaces.
Ijob
L'interface de tâche la plus simple contenant une méthode
Execute qui ne prend rien sous forme de paramètres et ne renvoie rien.
La tâche elle-même ressemble à ceci:
Ijobpublic struct JobStruct : IJob { public void Execute() {} }
Dans la méthode
Execute , vous pouvez effectuer les calculs nécessaires.
IJobParallelFor
Une autre interface avec la même méthode
Execute , qui à son tour accepte déjà l'
index des paramètres numériques.
IJobParallelFor public struct JobStruct : IJobParallelFor { public void Execute(int index) {} }
Cette interface
IJobParallelFor , contrairement à l'interface
IJob , propose d'exécuter une tâche plusieurs fois et pas seulement de l'exécuter, mais de diviser cette exécution en blocs qui seront répartis entre les threads.
Pas clair Ne vous en faites pas, je vous en dirai plus.IJobParallelForTransform
Et la dernière interface spéciale, qui, comme son nom l'indique, est conçue pour fonctionner avec ces transformations de l'objet. Il contient également la méthode
Execute , avec l'
index des paramètres numériques et le paramètre
TransformAccess où se trouvent la position, la taille et la rotation de la transformation.
IJobParallelForTransform public struct JobStruct : IJobParallelForTransform { public void Execute(int index, TransformAccess transform) {} }
Étant donné que vous ne pouvez pas travailler avec des objets d'
unité directement dans la tâche, cette interface ne peut traiter les données de transformation qu'en tant que structure
TransformAccess distincte.
Terminé, maintenant que vous savez comment les structures de tâches sont créées, vous pouvez procéder à la pratique.
Achèvement de la tâche
Créons une tâche simple héritée de l'interface
IJob et
terminons-la . Pour cela, nous avons besoin d'un simple script
MonoBehaviour et de la structure de la tâche elle-même.
Testjob public class TestJob : MonoBehaviour { void Start() {} }
Déposez maintenant ce script sur un objet de la scène. Dans le même script (
TestJob ) ci-dessous, nous écrirons la structure de la tâche et n'oubliez pas d'importer les bibliothèques nécessaires.
Simplejob using Unity.Jobs; public struct SimpleJob : IJob { public void Execute() { Debug.Log("Hello parallel world!"); } }
Dans la méthode
Execute , par exemple, imprimez une ligne simple sur la console.
Passons maintenant à la méthode
Start du script
TestJob , où nous allons créer une instance de la tâche, puis l'exécuter.
Testjob public class TestJob : MonoBehaviour { void Start() { SimpleJob job = new SimpleJob(); job.Schedule().Complete(); } }
Si vous avez tout fait comme dans l'exemple, après avoir commencé le jeu, vous obtiendrez un message simple à la console comme dans l'image.

Ce qui se passe ici: après avoir appelé la méthode
Schedule , le planificateur place la tâche dans le handle et maintenant elle peut être terminée en appelant la méthode
Complete .
Il s'agit d'un exemple de tâche qui a simplement imprimé du texte sur la console. Pour qu'une tâche effectue des calculs parallèles, il est nécessaire de la remplir de données.
Données dans la tâche
Comme dans le système
ECS , dans les tâches, il n'y a pas d'accès aux objets d'
unité , vous ne pouvez pas mettre le
GameObject dans la tâche et y changer son nom. Tout ce que vous pouvez faire est de transférer certains paramètres d'objet distincts à la tâche, de modifier ces paramètres et, une fois la tâche terminée, de réappliquer ces modifications à l'objet.
Il existe plusieurs limitations aux données dans la tâche elle-même: premièrement, il doit s'agir de structures et, deuxièmement, il
ne doit
pas s'agir de types de données
convertibles , c'est-à-dire que vous ne pouvez pas transmettre le même
booléen ou la même
chaîne à la tâche.
Simplejob public struct SimpleJob : IJob { public float a, b; public void Execute() { float result = a + b; Debug.Log(result); } }
Et la condition principale: les données non enfermées dans un conteneur ne sont accessibles qu'à l'intérieur de la tâche!
Conteneurs
Lorsque vous travaillez avec l'informatique multithread, il est nécessaire d'échanger en quelque sorte des données entre les threads. Afin de pouvoir y transférer des données et les relire dans le système de tâches, il existe à ces fins des conteneurs. Ces conteneurs se présentent sous forme de structures ordinaires et je travaille sur le principe d'un pont par lequel les données élémentaires sont synchronisées entre les flux.
Il existe plusieurs types de conteneurs:
NativeArray . Le type de conteneur le plus simple et le plus utilisé est présenté comme un tableau simple avec une taille fixe.
NativeSlice . Un autre conteneur - un tableau, comme il ressort de la traduction, est conçu pour couper le NativeArray en morceaux.
Ce sont les deux principaux conteneurs disponibles sans connecter de système
ECS . Dans une version plus avancée, il existe plusieurs autres types de conteneurs.
NativeList . Il s'agit d'une liste régulière de données.
NativeHashMap . Un analogue d'un dictionnaire avec une clé et une valeur.
NativeMultiHashMap . Le même
NativeHashMap avec seulement quelques valeurs sous une seule clé.
NativeQueue Liste des files d'attente de données.
Puisque nous travaillons sans connecter de système
ECS , seuls
NativeArray et
NativeSlice sont à
notre disposition .
Avant de passer à la partie pratique, il est nécessaire d'analyser le point le plus important - la création d'instances.
Créer des conteneurs
Comme je l'ai dit précédemment, ces conteneurs représentent un pont sur lequel les données sont synchronisées entre les threads. Le système de tâches ouvre ce pont avant de commencer le travail et le ferme après son achèvement. Le processus d'ouverture est appelé «
allocation » (
Allocation ) ou
«allocation de mémoire» , le processus de fermeture est appelé «
libération des ressources » (
Dispose ).
C'est l'allocation qui détermine la durée pendant laquelle la tâche peut utiliser les données dans le conteneur - en d'autres termes, la durée pendant laquelle le pont sera ouvert.
Afin de mieux comprendre ces deux processus, jetons un œil à l'image ci-dessous.
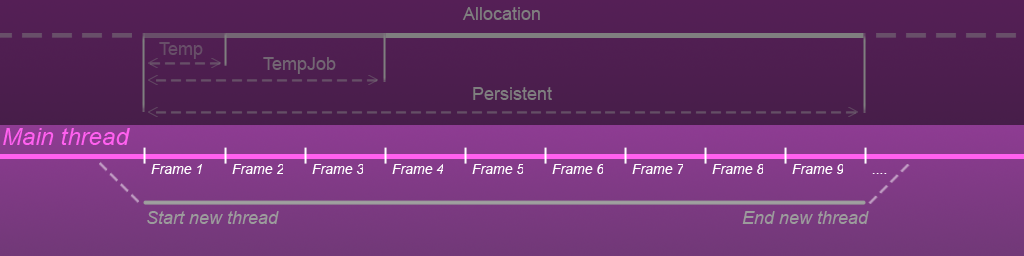
La partie inférieure montre le cycle de vie du thread principal (thread
principal ), qui est calculé en nombre d'images; dans la première image, nous créons un autre thread parallèle (
nouveau thread) qui existe pour un certain nombre d'images, puis se ferme en toute sécurité.
Dans le même
nouveau thread, la tâche avec le conteneur arrive.
Jetez maintenant un coup d'œil en haut de l'image.

L'
allocation de la barre blanche indique la durée de vie du conteneur. Dans le premier cadre, le conteneur est
alloué - le pont est ouvert jusqu'à ce que le conteneur n'existe pas, une fois tous les calculs de la tâche terminés, le conteneur est libéré de la mémoire et dans le 9e cadre, le pont est fermé.
Sur cette bande (
Allocation ), il y a également des segments temporels (
Temp ,
TempJob et
Presistent ), chacun de ce segment affiche la durée de vie estimée du conteneur.
Pourquoi ces segments sont-ils nécessaires!? Le fait est que l'exécution d'une tâche par durée peut être différente, nous pouvons les exécuter directement dans la même méthode que celle où nous l'avons créée, ou nous pouvons prolonger le temps d'exécution de la tâche si elle est assez compliquée, et ces segments montrent l'urgence et la durée pendant laquelle la tâche peut utiliser les données dans le récipient.
Si ce n'est toujours pas clair, j'analyserai chaque type d'allocation à l'aide d'un exemple.Nous pouvons maintenant passer à la partie pratique de la création de conteneurs, pour cela, nous revenons à la méthode
Start du script
TestJob et créons une nouvelle instance du conteneur
NativeArray et n'oubliez pas de connecter les bibliothèques nécessaires.
Temp
Testjob using Unity.Jobs; using Unity.Collections; public class TestJob : MonoBehaviour { void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); } }
Pour créer une nouvelle instance de conteneur, vous devez spécifier la taille et le type d'allocation dans son constructeur. Cet exemple utilise le type
Temp , car la tâche sera exécutée uniquement dans la méthode
Start .
Maintenant, initialisez la même variable de tableau exacte dans la structure de la tâche
SimpleJob .
Simplejob public struct SimpleJob : IJob { public NativeArray<int> array; public void Execute() {} }
C'est fait. Vous pouvez maintenant créer la tâche elle-même et lui passer une instance de tableau.
Commencer void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); SimpleJob job = new SimpleJob(); job.array = array; }
Pour exécuter la tâche cette fois, nous utiliserons son handle
JobHandle pour l'obtenir en appelant la même méthode
Schedule .
Commencer void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); SimpleJob job = new SimpleJob(); job.array = array; JobHandle handle = job.Schedule(); }
Vous pouvez maintenant appeler la méthode
Complete sur sa poignée et vérifier si la tâche est terminée pour afficher le texte dans la console.
Commencer void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); SimpleJob job = new SimpleJob(); job.array = array; JobHandle handle = job.Schedule(); handle.Complete(); if (handle.IsCompleted) print(" "); }
Si vous exécutez la tâche sous cette forme, après avoir démarré le jeu, vous obtiendrez une grosse erreur rouge indiquant que vous n'avez pas libéré le conteneur de tableau des ressources une fois la tâche terminée.
Quelque chose comme ça.

Pour éviter cela, appelez la méthode
Dispose sur le conteneur après avoir terminé la tâche.
Commencer void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); SimpleJob job = new SimpleJob(); job.array = array; JobHandle handle = job.Schedule(); handle.Complete(); if (handle.IsCompleted) print("Complete"); array.Dispose(); }
Ensuite, vous pouvez le redémarrer en toute sécurité.
Mais la tâche ne fait rien! - puis ajoutez-y quelques actions.
Simplejob public struct SimpleJob : IJob { public NativeArray<int> array; public void Execute() { for(int i = 0; i < array.Length; i++) { array[i] = i * i; } } }
Dans la méthode
Execute , je multiplie l'index de chaque élément du tableau par moi-même et l'écris dans le
tableau pour imprimer le résultat sur la console dans la méthode
Start .
Commencer void Start() { NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp); SimpleJob job = new SimpleJob(); job.array = array; JobHandle handle = job.Schedule(); handle.Complete(); if (handle.IsCompleted) print(job.array[job.array.Length - 1]); array.Dispose(); }
Quel sera le résultat dans la console si nous imprimons le dernier élément du tableau au carré?
C'est ainsi que vous pouvez créer des conteneurs, les placer dans des tâches et effectuer des actions dessus.
Il s'agit d'un exemple utilisant le type d'allocation
Temp , ce qui implique de terminer une tâche dans un cadre. Ce type est mieux utilisé lorsque vous devez effectuer rapidement des calculs sans charger le thread principal, mais vous devez être prudent si la tâche est trop compliquée ou s'il y en aura beaucoup, l'affaissement peut se produire, dans ce cas, il est préférable d'utiliser le type
TempJob, que
j'analyserai plus tard.
Tempjob
Dans cet exemple, je
modifierai légèrement
la structure de la tâche
SimpleJob et l'hériterai d'une autre interface
IJobParallelFor .
Simplejob public struct SimpleJob : IJobParallelFor { public NativeArray<Vector2> array; public void Execute(int index) {} }
De plus, comme la tâche durera plus d'une image, nous exécuterons et collecterons les résultats de la tâche dans différentes méthodes
Awake et
Start présentées sous la forme d'une coroutine. Pour ce faire, modifiez un peu l'apparence de la classe
TestJob .
Testjob public class TestJob : MonoBehaviour { private NativeArray<Vector2> array; private JobHandle handle; void Awake() {} IEnumerator Start() {} }
Dans la méthode
Awake , nous allons créer une tâche et un conteneur de vecteurs, et dans la méthode
Start , sortir les données reçues et libérer les ressources.
Éveillé void Awake() { this.array = new NativeArray<Vector2>(100, Allocator.TempJob); SimpleJob job = new SimpleJob(); job.array = this.array; }
Là encore, un conteneur de
tableau est créé avec le type d'allocation
TempJob , après quoi nous créons une tâche et obtenons son handle en appelant la méthode
Schedule avec des modifications mineures.
Éveillé void Awake() { this.array = new NativeArray<Vector2>(100, Allocator.TempJob); SimpleJob job = new SimpleJob(); job.array = this.array; this.handle = job.Schedule(100, 5) }
Le premier paramètre de la méthode
Schedule indique combien de fois la tâche sera exécutée, voici le même nombre que la taille du
tableau .
Le deuxième paramètre indique le nombre de blocs à partager la tâche.
Quels autres blocs?Auparavant, pour terminer une tâche, un thread appelait simplement la méthode
Execute une fois, maintenant il est nécessaire d'appeler cette méthode 100 fois, de sorte que le planificateur divise ces 100 fois de répétitions en blocs qu'il distribue entre les threads afin de ne pas charger de thread séparé. Dans l'exemple, une centaine de répétitions sera divisée en 5 blocs de 20 répétitions chacun, c'est-à-dire que le planificateur distribuera vraisemblablement ces 5 blocs en 5 threads, où chaque thread appellera 20 fois la méthode
Execute . En pratique, bien sûr, ce n'est pas un fait que le planificateur fera exactement cela, tout dépend de la charge de travail du système, donc peut-être que les 100 répétitions se produiront dans un seul thread.
Vous pouvez maintenant appeler la méthode
Complete sur le descripteur de tâche.
Éveillé void Awake() { this.array = new NativeArray<Vector2>(100, Allocator.TempJob); SimpleJob job = new SimpleJob(); job.array = this.array; this.handle = job.Schedule(100, 5); this.handle.Complete(); }
Dans la coroutine
Démarrer , nous vérifierons l'exécution de la tâche puis nous nettoierons le conteneur.
Commencer IEnumerator Start() { while(this.handle.isCompleted == false){ yield return new WaitForEndOfFrame(); } this.array.Dispose(); }
Passons maintenant aux actions de la tâche elle-même.
Simplejob public struct SimpleJob : IJobParallelFor { public NativeArray<Vector2> array; public void Execute(int index) { float x = index; float y = index; Vector2 vector = new Vector2(x * x, y * y / (y * 2)); this.array[index] = vector; } }
Après avoir terminé la tâche dans la méthode
Start , affichez tous les éléments du tableau dans la console.
Commencer IEnumerator Start() { while(this.handle.IsCompleted == false){ yield return new WaitForEndOfFrame(); } foreach(Vector2 vector in this.array) { print(vector); } this.array.Dispose(); }
Terminé, vous pouvez exécuter et regarder le résultat.
Pour comprendre la différence entre
IJob et
IJobParallelFor, jetez un œil aux images ci-dessous.
Par exemple, dans
IJob, vous
pouvez utiliser une boucle
for simple
pour effectuer plusieurs fois les calculs, mais dans tous les cas, un thread ne peut appeler la méthode
Execute qu'une seule fois pendant toute la durée de la tâche - c'est ainsi qu'une seule personne peut effectuer des centaines d'actions identiques dans une rangée.
 IJobParallelFor
IJobParallelFor propose non seulement d'exécuter plusieurs fois une tâche dans un thread, mais également de répartir ces répétitions entre d'autres threads.

En général, le type d'allocation
TempJob est parfait pour la plupart des tâches qui sont effectuées sur plusieurs trames.
Mais que se passe-t-il si vous devez stocker des données même après avoir terminé une tâche, et si après avoir reçu le résultat, vous n'avez pas besoin de les détruire immédiatement. Pour cela, il faut utiliser le type d'allocation
Persistant , ce qui implique la libération des ressources puis «
quand c'est nécessaire!» .
Persistant
Revenons à la classe
TestJob et changeons-la. Nous allons maintenant créer des tâches dans la méthode
OnEnable , vérifier leur exécution dans la méthode
Update et nettoyer les ressources dans la méthode
OnDisable .
Dans l'exemple, nous déplacerons l'objet dans la méthode
Update , pour calculer la trajectoire, nous utiliserons deux conteneurs vectoriels -
inputArray dans lequel nous mettrons la position actuelle et
outputArray d'où nous recevrons les résultats.
Testjob public class TestJob : MonoBehaviour { private NativeArray<Vector2> inputArray; private NativeArray<Vector2> outputArray; private JobHandle handle; void OnEnable() {} void Update() {} void OnDisable() {} }
Nous allons également
modifier légèrement
la structure de la tâche
SimpleJob en l'héritant de l'interface
IJob pour l'exécuter une fois.
Simplejob public struct SimpleJob : IJob { public void Execute() {} }
Dans la tâche elle-même, nous trahirons également deux conteneurs vectoriels, un vecteur position et un delta numérique, qui déplaceront l'objet vers la cible.
Simplejob public struct SimpleJob : IJob { [ReadOnly] public NativeArray<Vector2> inputArray; [WriteOnly] public NativeArray<Vector2> outputArray; public Vector2 position; public float delta; public void Execute() {} }
Les attributs
ReadOnly et
WriteOnly affichent les restrictions de flux sur les actions associées aux données à l'intérieur des conteneurs.
ReadOnly propose le flux uniquement pour lire les données du conteneur, l'attribut
WriteOnly , au contraire, permet au flux d'écrire uniquement des données dans le conteneur. Si vous devez effectuer ces deux actions à la fois avec un seul conteneur, vous n'avez pas du tout besoin de le marquer avec un attribut.
Passons à la méthode
OnEnable de la classe
TestJob où les conteneurs seront initialisés.
Onenable void OnEnable() { this.inputArray = new NativeArray<Vector2>(1, Allocator.Persistent); this.outputArray = new NativeArray<Vector2>(1, Allocator.Persistent); }
Les dimensions des conteneurs seront uniques car il n'est nécessaire de transmettre et de recevoir des paramètres qu'une seule fois. Le type d'allocation sera
Persistant .
Dans la méthode
OnDisable ,
nous libérerons les ressources des conteneurs.
Ondisable void OnDisable() { this.inputArray.Dispose(); this.outputArray.Dispose(); }
Créons une méthode
CreateJob distincte où nous allons créer une tâche avec son handle et là nous la remplirons de données.
CreateJob void CreateJob() { SimpleJob job = new SimpleJob(); job.delta = Time.deltaTime; Vector2 position = this.transform.position; job.position = position; Vector2 newPosition = position + Vector2.right; this.inputArray[0] = newPosition; job.inputArray = this.inputArray; job.outputArray = this.outputArray; this.handle = job.Schedule(); this.handle.Complete(); }
En fait, inputArray n'est pas vraiment nécessaire ici, car il est possible de transférer un vecteur de direction uniquement à la tâche, mais je pense qu'il sera préférable de comprendre pourquoi ces attributs ReadOnly et WriteOnly sont nécessaires.Dans la méthode
Update , nous vérifierons si la tâche est terminée, après quoi nous appliquons le résultat obtenu à la transformation d'objet et la réexécutons.
Mettre à jour void Update() { if (this.handle.IsCompleted) { Vector2 newPosition = this.outputArray[0]; this.transform.position = newPosition; CreateJob(); } }
Avant de commencer, nous
ajusterons légèrement la méthode
OnEnable afin que la tâche soit créée immédiatement après l'initialisation des conteneurs.
Onenable void OnEnable() { this.inputArray = new NativeArray<Vector2>(1, Allocator.Persistent); this.outputArray = new NativeArray<Vector2>(1, Allocator.Persistent); CreateJob(); }
Terminé, vous pouvez maintenant accéder à la tâche elle-même et effectuer les calculs nécessaires dans la méthode
Execute .
Exécuter public void Execute() { Vector2 newPosition = this.inputArray[0]; newPosition = Vector2.Lerp(this.position, newPosition, this.delta); this.outputArray[0] = newPosition; }
Pour voir le résultat du travail, vous pouvez lancer le script
TestJob sur un objet et lancer le jeu.
Par exemple, mon sprite se déplace progressivement vers la droite.
En général, le type d'allocation
Persistant est idéal pour les conteneurs réutilisables qui n'ont pas besoin d'être détruits et recréés à chaque fois.
Alors quel type utiliser!?Le type
Temp est mieux utilisé pour effectuer rapidement des calculs, mais si la tâche est trop complexe et trop importante, un jeu peut se produire.
Le type
TempJob est idéal pour travailler avec des objets
unitaires , vous pouvez donc modifier les paramètres des objets et les appliquer, par exemple, dans le cadre suivant.
Le type
Persistant peut être utilisé lorsque la vitesse n'est pas importante pour vous, mais vous avez juste besoin de calculer constamment une sorte de données sur le côté, par exemple, traiter des données sur un réseau ou le travail d'une IA.
Invalide et aucunIl existe deux autres types d'allocation Invalid et None , mais ils sont plus nécessaires pour le débogage et ne participent pas au travail.
Jobhandle
Séparément, il vaut la peine d'analyser les capacités du descripteur de tâche, car en plus de vérifier le processus d'exécution des tâches, ce petit descripteur peut toujours créer des réseaux entiers de tâches via des dépendances (bien que je préfère les appeler davantage files d'attente).
Par exemple, si vous devez effectuer deux tâches dans une certaine séquence, il vous suffit pour cela d'attacher le handle d'une tâche au handle d'une autre.
Cela ressemble à ceci.

Chaque poignée individuelle contient initialement sa propre tâche, mais lorsqu'elle est combinée, nous obtenons une nouvelle poignée avec deux tâches.
Commencer void Start() { Job jobA = new Job(); JobHandle handleA = jobA.Schedule(); Job jobB = new Job(); JobHandle handleB = jobB.Schedule(); JobHandle result = JobHandle.CombineDependecies(handleA, handleB); result.Complete(); }
Ou alors.
Commencer void Start() { JobHandle handle; for(int i = 0; i < 10; i++) { Job job = new Job(); handle = job.Schedule(handle); } handle.Complete(); }
La séquence d'exécution est enregistrée et le planificateur ne démarrera pas la tâche suivante tant qu'il ne sera pas convaincu de la précédente, mais il est important de se rappeler que la propriété de
handle IsCompleted attendra que toutes les tâches soient terminées.
Conclusion
Conteneurs
- Lorsque vous travaillez avec des données dans des conteneurs, n'oubliez pas qu'il s'agit de structures, donc tout écrasement de données dans le conteneur ne les modifie pas, mais les crée à nouveau.
- Que se passe-t-il si vous définissez le type d'allocation Temp et n'effacez pas les ressources une fois la tâche terminée? L'erreur.
- Puis-je créer mes propres conteneurs? Il est possible que les unités décrivent en détail le processus de création de conteneurs personnalisés ici, mais il vaut mieux réfléchir à quelques reprises: cela vaut-il la peine, peut-être qu'il y aura suffisamment de conteneurs ordinaires!?
La sécurité!
Données statiques.N'essayez pas d'utiliser des données statiques dans une tâche ( aléatoire et autres), tout accès aux données statiques violera la sécurité du système. En fait, pour le moment, vous pouvez accéder aux données statiques, mais uniquement si vous êtes sûr qu'elles ne changent pas pendant le travail - c'est-à-dire qu'elles sont complètement statiques et en lecture seule.Quand utiliser le système de tâches?Tous ces exemples qui sont donnés ici dans l'article ne sont que conditionnels et montrent comment travailler avec ce système, et non quand l'utiliser. Le système de tâches peut être utilisé sans ECS,vous devez comprendre que le système consomme également des ressources au travail et que pour une raison quelconque, écrire immédiatement des tâches, créer des tas de conteneurs est tout simplement inutile - tout va encore empirer. Par exemple, recalculer un tableau de 10000 éléments de taille ne sera pas correct - cela vous prendra plus de temps pour travailler avec le planificateur, mais recalculer tous les polygones d'une énorme terrane ou même le générer est la bonne solution, vous pouvez diviser la terrane en tâches et les traiter chacune dans un flux séparé.En général, si vous êtes constamment impliqué dans des calculs complexes dans des projets et recherchez constamment de nouvelles opportunités pour rendre ce processus moins gourmand en ressources, alors Job Systemc'est exactement ce dont vous avez besoin. Si vous travaillez constamment avec des calculs complexes inséparables des objets et que vous voulez que votre code fonctionne plus rapidement et soit pris en charge sur la plupart des plates-formes, ECS vous aidera certainement. Si vous créez des projets uniquement pour WebGL, ce n'est pas pour vous, pour le moment le Job System ne prend pas en charge le travail dans les navigateurs, bien que ce ne soit pas un problème pour les unitecs, mais pour les développeurs de navigateurs eux-mêmes.Source avec tous les exemples