
Aujourd'hui, enfin, le programme principal de la conférence a commencé. Le taux d'acceptation cette année n'était que de 8%, soit doit être le meilleur du meilleur du meilleur. Les flux appliqués et de recherche sont clairement séparés, et il existe plusieurs activités connexes distinctes. Les flux appliqués semblent plus intéressants, les rapports proviennent principalement de majors (Google, Amazon, Alibaba, etc.). Je vais vous parler des performances auxquelles j'ai réussi à assister.
Des données pour de bon
La journée a commencé par une présentation suffisamment longue pour que les données soient utiles et utilisées pour le bien. Un
professeur de l'Université de Californie prend la
parole (il convient de noter qu'il y a beaucoup de femmes au KDD, tant parmi les étudiants que parmi les locuteurs). Tout cela est exprimé dans l'abréviation FATES:
- Équité - aucun biais dans les prévisions du modèle, tout est neutre et tolérant.
- Responsabilité - il doit y avoir quelqu'un ou quelque chose responsable des décisions prises par la machine.
- Transparence - transparence et explicabilité des décisions.
- Éthique - lorsque vous travaillez avec des données, un accent particulier doit être mis sur l'éthique et la confidentialité.
- Sûreté et sécurité - le système doit être sûr (non dangereux) et protégé (résistant aux influences manipulatrices de l'extérieur)
Ce manifeste exprime malheureusement plutôt un désir et est faiblement corrélé à la réalité. Le modèle ne sera politiquement correct que si tous les signes en sont supprimés; la responsabilité de transférer à une personne spécifique est toujours très difficile; plus la DS évolue, plus il est difficile d'interpréter ce qui se passe à l'intérieur du modèle; sur l'éthique et la vie privée, il y avait quelques bons exemples le premier jour, mais sinon, les données sont souvent traitées assez librement.
Eh bien, on ne peut qu'admettre que les modèles modernes ne sont souvent pas sûrs (un pilote automatique peut abandonner une voiture avec un conducteur) et ne sont pas protégés (vous pouvez prendre des exemples qui cassent le travail d'un réseau de neurones sans même savoir comment fonctionne le réseau). Un travail récent intéressant de
DeepExplore : un système de recherche de vulnérabilités dans les réseaux de neurones génère, entre autres, des images qui font que le pilote automatique se dirige dans le mauvais sens.

Ce qui suit est une autre définition de la science des données comme «DS est l'étude de l'extraction des données de forme de valeur». En principe, assez bien. Au début du discours, l'orateur a spécifiquement mentionné que DS ne regarde souvent les données qu'au moment de l'analyse, alors que le cycle de vie complet est beaucoup plus large, et cela, entre autres, a été reflété dans la définition.
Eh bien, il y avait quelques exemples de travaux de laboratoire.
Encore une fois, nous analyserons la tâche d'évaluer l'influence de nombreux facteurs sur le résultat, mais pas à partir de la position de la publicité, mais en général. Il y a un
article non encore publié. Considérez, par exemple, la question de quels acteurs choisir pour le film afin de récolter un bon box-office. Nous analysons les listes d'acteurs des films les plus rentables et essayons de prédire la contribution de chacun des acteurs. Mais! Il existe des soi-disant
facteurs de confusion qui affectent l'efficacité d'un acteur (par exemple, Stallone ira bien dans un film d'action thrash, mais pas dans une comédie romantique). Pour choisir le bon, vous devez trouver tous les facteurs de confusion et les évaluer, mais nous ne serons jamais sûrs d'avoir trouvé tout le monde. En fait, l'article propose une nouvelle approche - déconfondeur. Au lieu de mettre en évidence des facteurs de confusion, nous introduisons explicitement des variables latentes et les évaluons dans un mode non supervisé, puis nous étudions le modèle basé sur eux. Tout cela semble assez étrange, car cela semble être une simple variante des intégrations, ce qui est nouveau n'est pas clair.
Quelques belles photos ont été montrées, des exemples de la façon dont dans leur université l'IA, etc., progresse.
Commerce électronique et profilage
Je suis allé à la section des applications sur le commerce. Au début, il y avait des rapports très intéressants, à la fin il y avait une certaine quantité de bouillie, mais d'abord les choses.
Nouvelle modélisation utilisateur et prédiction de désabonnement
Le
travail intéressant de Snapchat sur la prédiction des sorties. Les gars utilisent l'idée, que nous avons également couronnée de succès il y a environ 4 ans: avant de prédire le flux sortant, les utilisateurs doivent être divisés en grappes en fonction du type de comportement. Dans le même temps, l'espace vectoriel par les types d'actions qu'ils se sont révélés assez pauvres, sur seulement quelques types d'interactions (nous avons dû, en temps voulu, faire une sélection de signes afin de passer de trois cents à un an et demi), mais ils enrichissent l'espace de statistiques supplémentaires et le considèrent comme une série chronologique , par conséquent, les clusters sont obtenus non pas tant sur ce que font les utilisateurs, mais sur
la fréquence à laquelle ils le font.
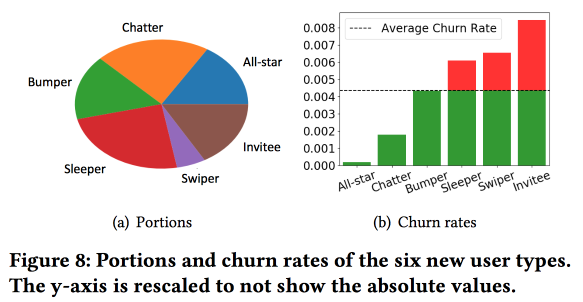
Une observation importante: le réseau a le «cœur» des utilisateurs les plus connectés et les plus actifs avec une taille de 1,7 million de personnes. Dans le même temps, le comportement et la rétention de l'utilisateur dépendent grandement de sa capacité à communiquer avec quelqu'un du «cœur».
Ensuite, nous commençons à construire un modèle. Prenons les nouveaux arrivants dans une quinzaine de jours (511 000), fonctionnalités simples et réseaux d'ego (taille et densité), et voyons s'ils sont associés au «noyau», etc. Nous alimentons le comportement des utilisateurs avec LSTM et obtenons une précision des prévisions de sortie légèrement supérieure à celle de logreg (de 7 à 8%). Mais alors le plaisir commence. Pour prendre en compte les spécificités des clusters individuels, nous allons former plusieurs LSTM en parallèle, et nous attacherons une couche d'attention sur le dessus. En conséquence, un tel schéma commence à fonctionner à la fois sur le clustering (lequel des LSTM a retenu l'attention) et sur les prévisions de sortie. Cela donne une autre augmentation de qualité de 5 à 7%, et logreg semble déjà pâle. Mais! En fait, il serait juste de le comparer avec un logreg segmenté formé séparément pour les clusters (qui peut être obtenu de manière plus simple).
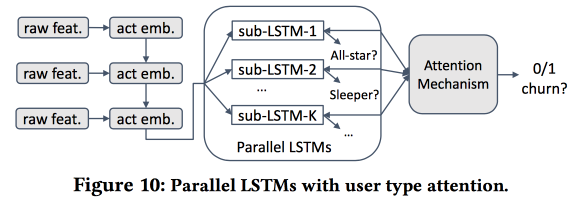
J'ai posé une question sur l'interprétabilité: après tout, les sorties sont souvent prévues non pas pour obtenir une prévision, mais pour comprendre quels facteurs l'influencent. L'orateur était clairement prêt pour cette question: pour cela, des clusters dédiés sont utilisés et analysés, que ceux où les prévisions de sorties sont plus élevées se distinguent des autres.
Représentation universelle des utilisateurs
Les gars d'Alibaba expliquent comment créer des associations d'utilisateurs. Il s'avère que le fait d'avoir de nombreuses soumissions d'utilisateurs est mauvais: beaucoup ne sont pas finalisés, les forces sont gaspillées. Ils ont réussi à faire une présentation universelle et à montrer que cela fonctionne mieux. Naturellement sur les réseaux de neurones. L'architecture est assez standard, déjà sous une forme ou une autre a été décrite à plusieurs reprises lors de la conférence. Les faits du comportement de l'utilisateur sont introduits dans l'entrée, nous les construisons, donnons tout à LSTM, accrochons une couche d'attention sur le dessus et à côté une grille supplémentaire pour les fonctionnalités statiques, couronnant avec une multitâche (en fait, plusieurs petites grilles pour une tâche spécifique) . Nous formons tout cela ensemble, la sortie avec attention sera l'intégration de l'utilisateur.
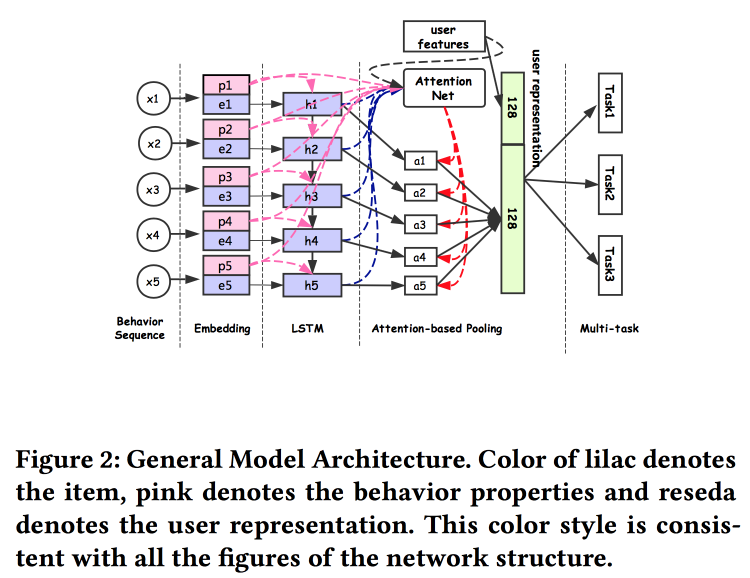
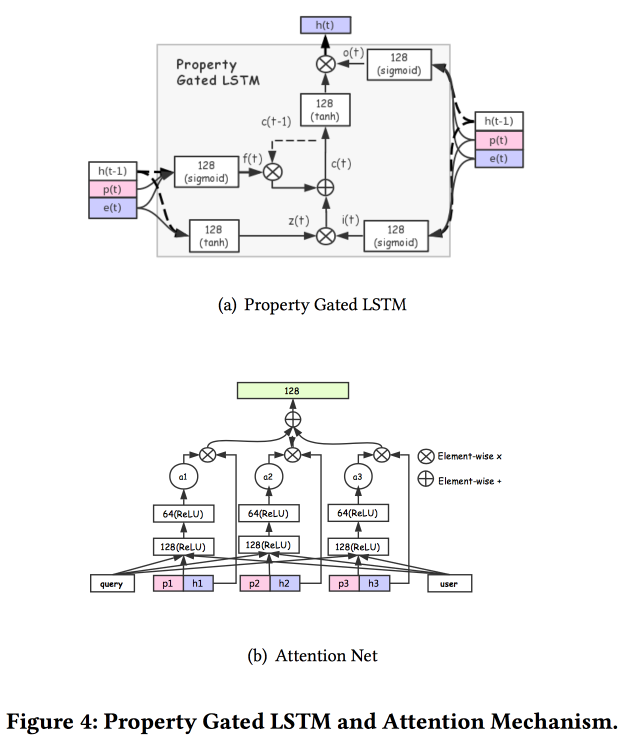
Il existe plusieurs ajouts plus complexes: en plus d'une simple attention, ils ajoutent un filet d'attention «en profondeur» et utilisent également une version modifiée de LSTM - propriété gated LSTM
Tâches sur lesquelles tout cela se déroule: prédiction CTR, prédiction de préférence de prix, apprentissage du classement, prédiction de mode selon la mode, prédiction de préférence de magasin. L'ensemble de données pour 10 jours comprend 6 * 10
9 exemples de formation.
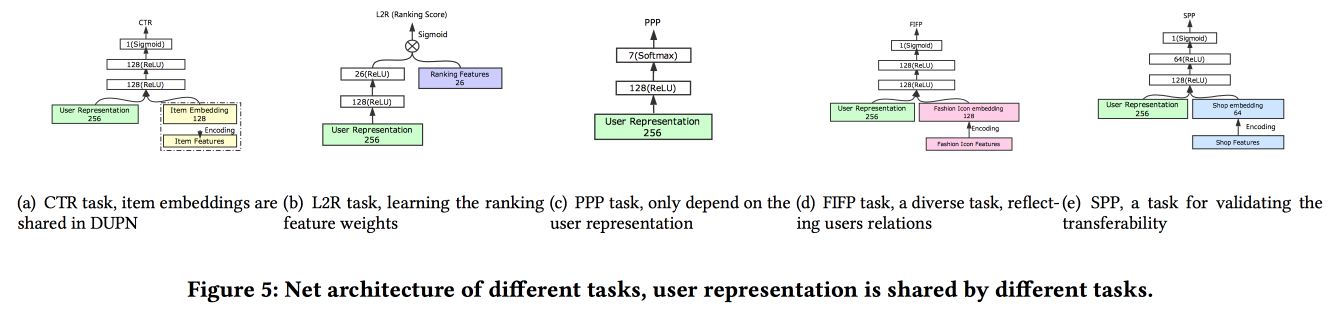
Puis il y avait une personne inattendue: ils entraînent tout cela sur TensorFlow, sur un cluster CPU de 2000 machines avec 15 cœurs chacune, il faut 4 jours pour compléter les données pendant 10 jours. Par conséquent, ils continuent de se recycler jour après jour (10 heures sur ce cluster). À propos du GPU / FPGA, je n'ai pas eu le temps de demander :(. L'ajout d'une nouvelle tâche se fait soit par le recyclage dans son ensemble, soit par le recyclage d'une grille peu profonde (réglage fin du réseau). Dans l'exécution pour l'inférence, ils stockent des représentations (sortie avec attention pour des utilisateurs spécifiques) et seules les têtes des grilles sont calculées pour le test A / B des tâches spécifiques a montré une augmentation de 2-3% pour divers indicateurs.
Prévision de retour de produit E-tail
Ils prédisent le retour des marchandises par l'utilisateur après l'achat, le
travail est présenté par IBM. Malheureusement, il n'y a pas de texte en libre accès jusqu'à présent. Le retour des marchandises est un problème grave d'une valeur de 200 milliards de dollars par an. Pour construire une prévision des retours, il utilise un modèle d'hypergraphe qui relie les produits et les paniers, en utilisant ce panier ils essaient de trouver les plus proches par hypergraphe, après quoi ils estiment la probabilité d'un retour. Pour éviter un retour, une boutique en ligne a de nombreuses possibilités, par exemple en offrant une remise pour retirer certains produits du panier.
Nous avons immédiatement constaté qu'il existe une différence significative entre les paniers avec doublons (par exemple, deux t-shirts identiques de tailles différentes) et sans, par conséquent, nous devons immédiatement construire des modèles différents pour ces deux cas.
L'algorithme général est appelé HyperGo:
- Nous construisons un hypergraphe pour représenter les achats et les retours avec des informations sur l'utilisateur, le produit, le panier.
- Ensuite, nous utilisons la coupe du graphique local basée sur une marche aléatoire pour obtenir des informations locales pour la prévision.
- Nous considérons séparément les paniers avec prises et sans prises.
- Nous utilisons des méthodes bayésiennes pour évaluer l'impact d'un produit individuel dans le panier.
Si l'on compare la qualité de la prévision de retour avec KNN pour les paniers, pondérée selon Jacquard KNN, rationnée par le nombre de doublons, on obtient une augmentation du résultat. Un lien vers GitHub a clignoté sur les diapositives, mais ils n'ont pas pu trouver leur source, et il n'y a pas de lien dans l'article.
OpenTag: Ouvrir l'extraction de la valeur d'attribut à partir des profils de produit
Travail assez intéressant d'Amazon. Défi: exploitez divers faits pour qu'Alexa réponde mieux aux questions. Ils disent à quel point tout est compliqué, les anciens systèmes ne savent pas comment travailler avec de nouveaux mots, nécessitent souvent un grand nombre de règles manuscrites et d'heuristiques, les résultats sont tels. Bien sûr, les réseaux de neurones avec l’architecture embarquée déjà intégrée d’attention au LSTM aideront à résoudre tous les problèmes, mais nous allons doubler le LSTM, et nous placerons également le
champ aléatoire conditionnel sur le dessus.

Nous allons résoudre le problème du balisage d'une séquence de mots. Les balises montreront où nous commençons et terminons les séquences de certains attributs (par exemple, le goût et la composition des aliments pour chiens), et LSTM essaiera de les prédire. Comme un chignon et une révérence vers Mechanical Turk, une formation active sur les modèles est utilisée. Pour sélectionner des exemples qui doivent être envoyés pour un balisage supplémentaire, utilisez l'heuristique "pour prendre ces exemples où les balises s'échangent le plus souvent entre les époques".
Apprentissage et transfert de la représentation des identifiants dans le commerce électronique
Dans leur
travail, les collègues d'Alibaba reviennent à nouveau sur la question de la construction des intégrations, cette fois en regardant non seulement les utilisateurs, mais les ID en principe: pour les produits, les marques, les catégories, les utilisateurs, etc. Les sessions d'interaction sont utilisées comme source de données et des attributs supplémentaires sont également pris en compte. Les Skipgrams sont utilisés comme algorithme principal.
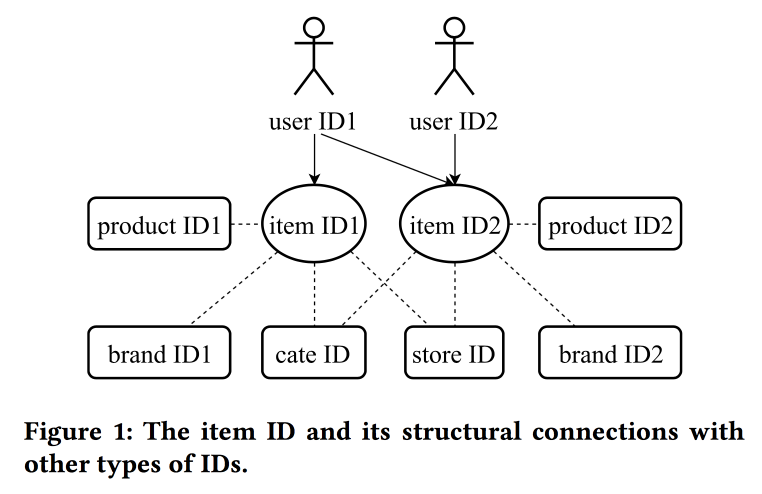
L'orateur a une prononciation très lourde avec un fort accent chinois, comprendre ce qui se passe est presque impossible. L'un des "trucs" du travail est la mécanique de transfert des représentations avec un manque d'information, par exemple, des éléments à l'utilisateur en passant par la moyenne (rapidement, vous n'avez pas besoin d'apprendre tout le modèle). À partir d'anciens éléments, vous pouvez en initialiser de nouveaux (apparemment par similitude de contenu), ainsi que transférer la vue de l'utilisateur d'un domaine (électronique) à un autre (vêtements).
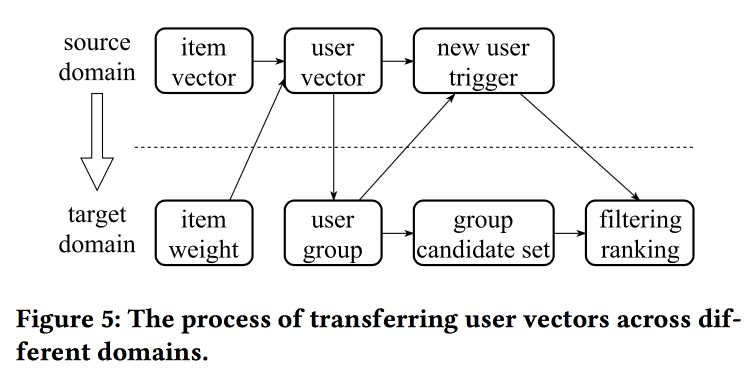
Dans l'ensemble, il n'est pas entièrement clair où la nouveauté est ici, apparemment, les détails doivent être creusés; en outre, il n'est pas clair comment cela se compare à l'histoire précédente sur les représentations unifiées des utilisateurs.
Sélection de paramètres en ligne pour les problèmes de classement basés sur le Web
Travail très intéressant d'amis sur LinkedIn. L'essence du travail est de sélectionner les paramètres optimaux du fonctionnement de l'algorithme en ligne, en tenant compte de plusieurs objectifs concurrents. En tant que portée, considérez la bande et essayez d'augmenter le nombre de sessions de certains types:
- Séance avec une certaine action virale (VA).
- Reprendre la session de soumission (JA).
- Interaction de contenu dans la session Feed (EFS).
La fonction de classement dans l'algorithme est une moyenne pondérée des prévisions de conversion pour ces trois objectifs. En fait, les poids sont ces paramètres que nous allons essayer d'optimiser en ligne. Initialement, ils formulent une tâche commerciale comme «maximiser le nombre de sessions de virus tout en maintenant les deux autres types au moins à un certain niveau», mais ensuite ils les transforment un peu pour faciliter l'optimisation.
Nous simulons les données avec un ensemble de distributions binomiales (l'utilisateur se convertira à l'objectif souhaité ou non, après avoir vu la bande avec certains paramètres), où la probabilité de succès avec les paramètres donnés est un
processus gaussien (le sien pour chaque type de conversion). Ensuite, nous utilisons l'
échantillonneur Thompson avec
des bandits "infiniment
robustes " pour sélectionner les paramètres optimaux (pas en ligne, mais hors ligne sur des données historiques, donc pendant une longue période). Ils donnent quelques conseils: utilisez des points en gras pour construire la grille initiale et assurez-vous d'ajouter un échantillonnage
epsilon gourmand (avec la probabilité que epsilon essaie un point aléatoire dans l'espace), sinon vous pouvez ignorer le maximum global.
Ils simulent la prise d'échantillons hors ligne une fois par heure (vous avez besoin de beaucoup d'échantillons), le résultat est une certaine distribution de paramètres optimaux. De plus, lorsqu'un utilisateur entre à partir de cette distribution, il prend des paramètres spécifiques pour construire la bande (il est important de le faire de manière cohérente avec la graine de l'ID utilisateur pour l'initialisation afin que la bande de l'utilisateur ne change pas radicalement).
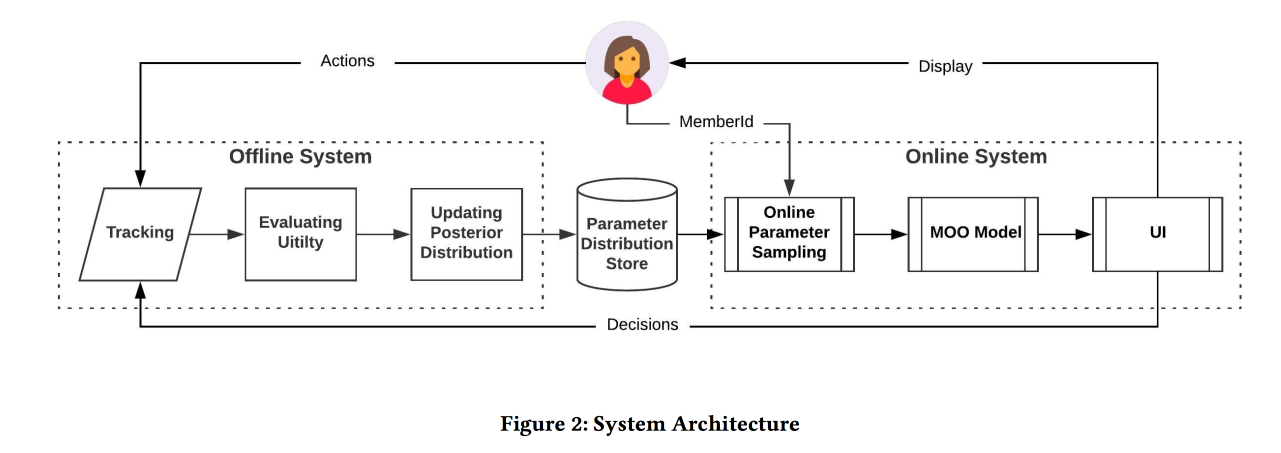
Selon les résultats de l'expérience A / B, ils ont reçu une augmentation de 12% des envois de curriculum vitae et des goûts de 3%. Partagez quelques observations:
- Il est plus facile d’échantillonner plus que d’essayer d’ajouter plus d’informations au modèle (par exemple, le jour de la semaine / de l’heure).
- Nous supposons l'indépendance des objectifs dans cette approche, mais il n'est pas clair si c'est le cas (plutôt, non). Cependant, l'approche fonctionne.
- Les entreprises doivent fixer des objectifs et des seuils.
- Il est important d'exclure une personne du processus et de la laisser faire quelque chose d'utile.
Optimisation en temps quasi réel de la notification basée sur l'activité
Un autre
travail de LinkedIn, cette fois sur la gestion des notifications. Nous avons des personnes, des événements, des canaux de distribution et des objectifs à long terme pour augmenter l'engagement des utilisateurs sans négativité significative sous la forme de plaintes et de désabonnement des push. La tâche est importante et difficile, et vous devez tout faire correctement: aux bonnes personnes au bon moment pour envoyer le bon contenu sur le bon canal et en bonne quantité.
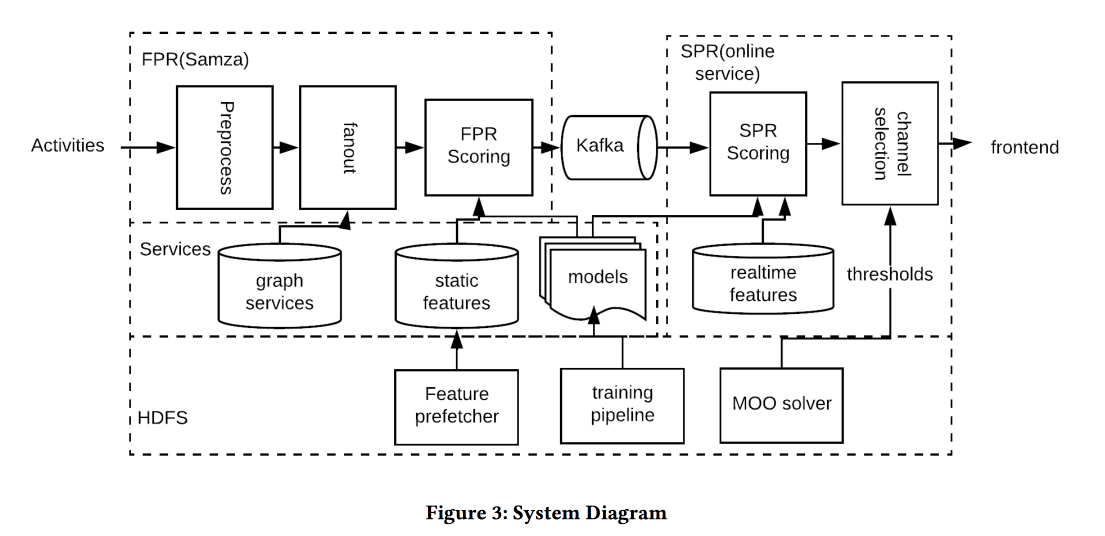
L'architecture du système dans l'image ci-dessus, l'essence de ce qui se passe est approximativement la suivante:
- Nous filtrons tout spam à l'entrée.
- Les bonnes personnes: un casque pour tous ceux qui sont fortement liés à l'auteur / au contenu, en équilibrant le seuil sur la force de la communication, en gérant la couverture et la pertinence.
- Le bon moment: envoyer immédiatement du contenu, pour lequel le temps est important (événements entre amis), le reste peut être conservé pour des chaînes moins dynamiques.
- Le bon contenu: utilisez logreg! Un modèle de prévision d'un clic sur un tas de signes est construit, séparément pour le cas où une personne est dans l'application et quand ce n'est pas le cas.
- Canal correct: nous fixons différents seuils de pertinence, les plus stricts pour la poussée, plus bas - si l'utilisateur est maintenant dans l'application, encore plus bas - pour le courrier (il contient toutes sortes de résumés / publicités).
- Volume correct: le modèle de circoncision par volume est en sortie, il regarde aussi la pertinence, il est recommandé de le faire individuellement (une bonne heuristique de seuil est un score minimum d'objets envoyés au cours des derniers jours)
Sur le test A / B a reçu une augmentation de quelques pour cent du nombre de sessions.
Personnalisation en temps réel à l'aide des incorporations pour le classement de recherche sur Airbnb
Et c'était le
meilleur papier d'application d'AirBnB. Objectif: optimiser l'émission de placements et de résultats de recherche similaires. Nous décidons par la construction d'incorporation d'emplacements et d'utilisateurs dans un même espace afin d'évaluer davantage la similitude. Il est important de se rappeler qu'il existe un historique à long terme (préférences de l'utilisateur) et à court terme (intention actuelle de l'utilisateur / session).
Sans plus tarder, nous utilisons pour créer des emplacements word2vec sur des séquences de clics dans les sessions de recherche (une session - un document). Mais nous faisons encore quelques modifications (KDD, après tout):
- Nous prenons la séance au cours de laquelle il y avait une réserve.
- Ce qui est finalement réservé, nous le tenons comme un contexte global pour tous les éléments de la session lors de la mise à jour w2v.
- Les négatifs en formation sont échantillonnés dans la même ville.

L'efficacité d'un tel modèle est vérifiée de trois manières standard:
- Vérifiez hors ligne: la vitesse à laquelle nous pouvons augmenter le bon hôtel dans la session de recherche.
- Test par des évaluateurs: construit un outil spécial pour visualiser les similaires.
- Test A / B: spoiler, CTR a considérablement augmenté, les réservations n'ont pas augmenté, mais maintenant elles se produisent plus tôt
Nous essayons de classer les résultats des résultats de recherche non seulement à l'avance, mais aussi de réorganiser (donc en temps réel) à la réception d'une réponse - un clic sur une phrase et en ignorer une autre. L'approche consiste à collecter les endroits cliqués et ignorés dans deux groupes, à trouver des incorporations dans chaque centroïde (il existe une formule spéciale), puis dans le classement, nous élevons comme des clics, abaissons comme des sauts.
Le test A / B a connu une augmentation des réservations, l'approche a résisté à l'épreuve du temps: il a été inventé il y a un an et demi et tourne toujours en production.
Et si vous avez besoin de chercher dans une autre ville? Vous ne pourrez pas établir de priorité par clics, il n'y a aucune information sur l'attitude des utilisateurs vis-à-vis des lieux dans ce règlement. Pour contourner ce problème, nous introduisons des «incorporations de contenu». Tout d'abord, nous allons créer un simple espace discret de panneaux (bon marché / cher, au centre / à la périphérie, etc.) de la taille d'environ 500 000 types (pour les lieux et les personnes). Ensuite, nous construisons des incorporations par type. Lors de l'apprentissage, n'oubliez pas d'ajouter un négatif clair sur les refus (lorsque le propriétaire du lieu n'a pas confirmé la réservation).
Représentation graphique des réseaux de neurones convolutifs pour les systèmes de recommandation à l'échelle Web
Travaillez sur Pinterest sur la recommandation d'épingles. Nous considérons les broches utilisateur du graphique bipartite et ajoutons des fonctionnalités réseau aux recommandations. Le graphique est très grand - 3 milliards de broches, 16 milliards d'interactions; les intégrations de graphiques classiques n'ont pas pu être faites. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
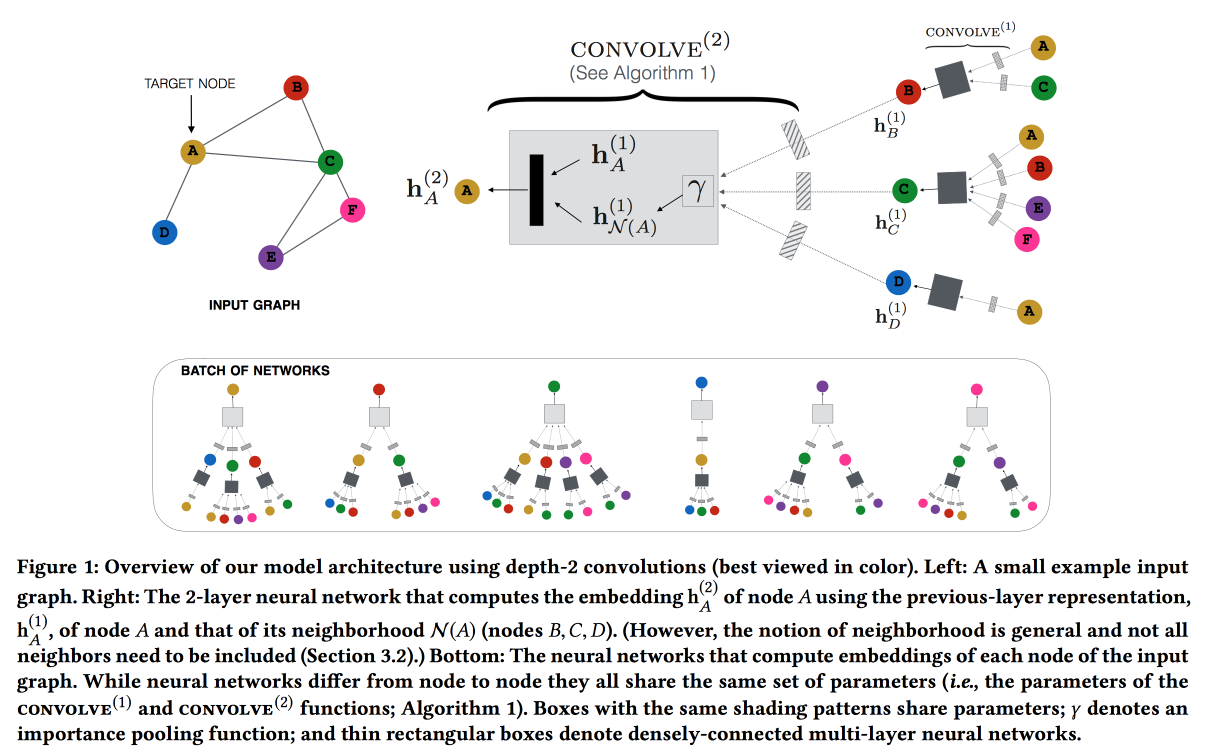
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
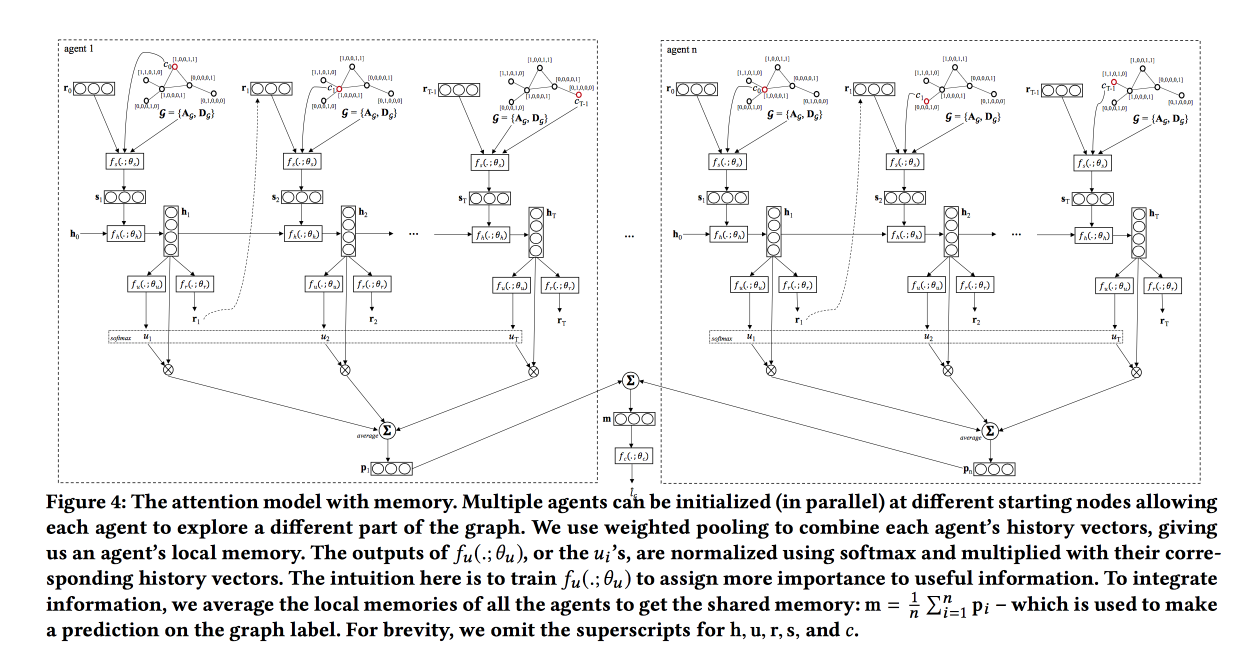
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
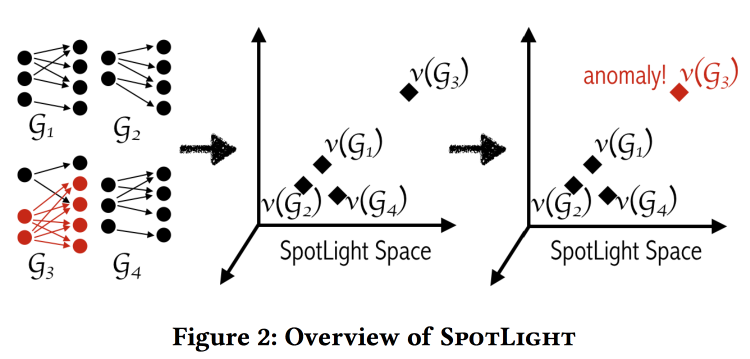
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . En fait. , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
Maintenant, les compagnies d'assurance ont du mal: en 2011, la discrimination fondée sur le sexe a finalement été interdite, maintenant le sexe ne peut pas être pris en compte dans les assurances (ce qui est sacrément difficile - même si vous masquez explicitement la fonction «sexe», le modèle est susceptible de l'approcher pour d'autres raisons). Cela a conduit à un effet intéressant au Royaume-Uni:- Les femmes conduisent avec plus de précision et sont moins susceptibles d'avoir des accidents, donc l'assurance leur était moins chère.
- Après le nivellement, le coût de l'assurance pour les femmes a augmenté et pour les hommes a diminué.
- Le marché fonctionne: en conséquence, il y a plus d'hommes et moins de femmes sur les routes.
- À mesure que la «précision» moyenne des conducteurs sur les routes diminuait, il y avait plus d'accidents.
- Après quoi, l'assurance, bien sûr, a commencé à augmenter ses prix.
- L'assurance voyage a commencé à laver encore plus les conducteurs soignés.
En conséquence, ils ont obtenu la «spirale de la mort».
Ce thème fait écho à la représentation d'ouverture de la journée. F - L'équité, c'est un château de nuages inaccessible. Les modèles ML apprennent à séparer les exemples (y compris les personnes) dans l'espace des attributs, ils ne peuvent donc pas être «justes» par définition.