
Les 18 et 19 août, Tele2 a organisé un hackathon de science des données. Ce hackathon se concentre sur l'analyse des dialogues de support technique dans les réseaux sociaux, accélérant et simplifiant les interactions avec les clients.
La tâche n'avait pas de métrique spécifique qui devait être optimisée; la tâche pouvait être inventée par vous-même. L'essentiel est d'améliorer le service. Le jury du concours était composé des directeurs de divers domaines de Tele2, ainsi que de Pavel Pleskov, la communauté des grands maîtres de Kaggle, célèbre dans la communauté Data Science.
Sous la coupe, l'histoire de l'équipe qui a pris la 1ère place.
Lorsqu'un collègue m'a invité à participer à ce hackathon, j'ai accepté assez rapidement.
Je m'intéressais au sujet de la PNL, et il y avait aussi des développements de réseaux neuronaux que je voulais tester dans la pratique.
Les organisateurs du Hackathon ont envoyé à l'avance de petits fragments d'ensembles de données qui ont donné une idée du type de données qui seraient disponibles lors de l'événement.
Les données se sont avérées plutôt sales, des trolls étrangers sont entrés dans les dialogues, il n'était pas toujours évident de savoir à quel type de question l'opérateur répond.
Il est devenu clair qu'il ne serait pas facile de mettre en œuvre l'idée dans les 24 heures allouées, j'ai donc pris un jour de congé et je l'ai consacré à la préparation du réseau neuronal que je voulais essayer. Cela nous a permis de ne pas perdre de temps de hackathon à rechercher des bugs, mais de nous concentrer sur les applications et les cas commerciaux.
Le bureau Tele2 est situé sur le territoire de la Nouvelle-Moscou dans le parc d'activités Rumyantsevo. Quant à moi, j'y arrive depuis un certain temps, mais le parc d'activités fait bonne impression (à l'exception des lignes électriques).
 Lignes électriques dans le contexte d'un centre d'affaires
Lignes électriques dans le contexte d'un centre d'affairesJuste à la station de métro, les organisateurs nous ont rencontrés, nous ont montré comment se rendre au bureau. Le bâtiment du centre d'affaires lui-même est occupé par de nombreuses entreprises, le bureau Tele2 est situé au 5ème étage. Les participants au Hackathon se sont vu attribuer un espace spécial à l'intérieur du bureau, il y avait une cuisine, un espace détente avec une PlayStation et des poufs. Particulièrement satisfait de la vitesse du wi-fi, aucun problème inhérent aux événements de masse n'a été observé.
 Petit déjeuner
Petit déjeunerL'ensemble de données réel fourni par Tele2 se composait de 3 gros fichiers CSV avec des dialogues de support technique: dialogues sur les réseaux sociaux, télégramme et email. Au total, plus de 4 millions de visites sont nécessaires pour former un réseau de neurones.
Qu'est-ce qu'un réseau neuronal?
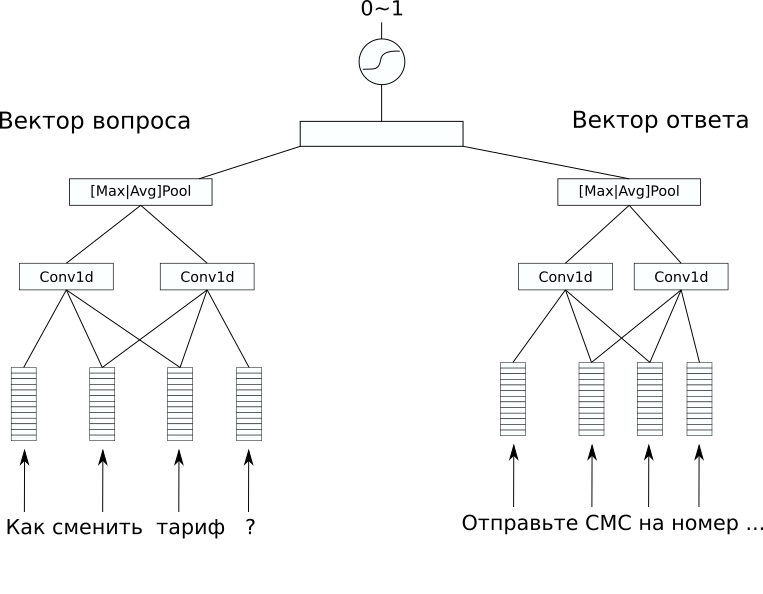 Architecture de réseau
Architecture de réseauDans l'ensemble de données, il n'y avait pas de balisage supplémentaire qu'il serait intéressant de prédire, mais je voulais résoudre un problème supervisé. Par conséquent, nous avons décidé d'essayer de prédire les réponses aux questions, afin qu'au moins un bot de chat simple à partir d'un tel modèle puisse être créé. Pour cela, nous avons choisi l'architecture CDSSM (Convolution Deep Semantic Similarity Model). Il s'agit de l'un des modèles de réseau neuronal simples pour comparer les textes par leur signification, qui a été initialement proposé par Microsoft pour classer les résultats de recherche Bing.
Son essence est la suivante: tout d'abord, chaque texte est converti en vecteur à l'aide d'une séquence de couches de convolution et de mise en commun.
Ensuite, les vecteurs résultants sont comparés d'une manière ou d'une autre. Dans notre problème, une couche linéaire supplémentaire combinant les deux vecteurs avec un sigmoïde comme fonction d'activation a donné un bon résultat. Les poids du réseau codant des phrases en vecteurs peuvent être les mêmes pour une paire de textes (ces réseaux sont appelés siamois) et peuvent différer.
Dans notre cas, la variante avec des poids différents a donné le meilleur résultat, car les textes de la question et de la réponse étaient significativement différents.
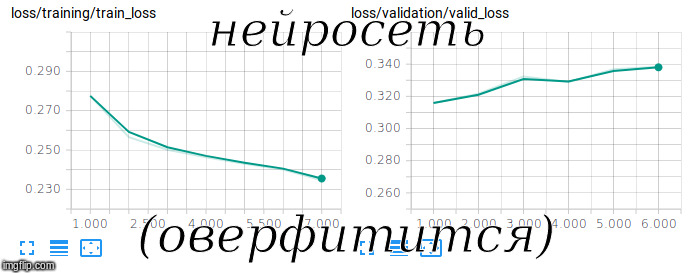 Essayer de former un réseau siamois
Essayer de former un réseau siamoisFastText avec RusVectōrēs a été utilisé comme
intégration pré-formée; il résiste aux fautes de frappe, que l'on retrouve souvent dans les questions des utilisateurs.
Pour former un tel modèle, il doit être formé non seulement sur des exemples positifs, mais aussi sur des exemples négatifs. Pour ce faire, nous avons ajouté des paires aléatoires de questions et réponses dans un rapport de 1 à 10 à l'ensemble de formation.
Pour évaluer la qualité sur un échantillon aussi déséquilibré, la métrique ROC-AUC a été utilisée. Après 3 heures de formation sur le GPU, nous avons réussi à atteindre une valeur de 0,92 dans cette métrique.
En utilisant ce modèle, il est possible de résoudre non seulement le problème direct - choisir la réponse appropriée à la question, mais aussi le contraire - pour trouver des erreurs d'opérateur, des réponses de mauvaise qualité et étranges aux questions des utilisateurs.
Nous avons réussi à trouver certaines de ces réponses dès le hackathon et à les inclure dans la présentation finale. Il me semble que cela a fait la plus grande impression sur le jury.
Une application intéressante peut également être trouvée dans la représentation vectorielle de textes que le réseau génère au cours de son travail.
En l'utilisant, vous pouvez rechercher des anomalies dans les questions et réponses par
diverses méthodes non supervisées .
En conséquence, notre décision a été bien prise tant d'un point de vue technique que d'un point de vue commercial. Les autres équipes ont essentiellement essayé de résoudre le problème de l'analyse des clés et de la modélisation thématique, notre solution a donc différé favorablement. En conséquence, nous avons pris la 1ère place, séparés satisfaits et fatigués.
 Sur la photo (de gauche à droite): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (auteur) et Shvetsov Egor
Sur la photo (de gauche à droite): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (auteur) et Shvetsov EgorQuoi d'autre à lire: