
De nombreuses personnes qui étudient l'apprentissage automatique connaissent le projet OpenAI, dont l'un des fondateurs est Elon Musk, et utilisent la plate-forme
OpenAI Gym pour former leurs modèles de réseau neuronal.
La salle de gym contient un vaste ensemble d'environnements, certains d'entre eux sont différents types de simulations physiques: les mouvements des animaux, des humains, des
robots . Ces simulations sont basées sur le moteur physique
MuJoCo , qui est gratuit à des fins éducatives et scientifiques.
Dans cet article, nous allons créer une simulation physique extrêmement simple similaire à l'environnement OpenAI Gym, mais basée sur le moteur de physique gratuit Bullet (
PyBullet ). Et créez également un agent pour travailler avec cet environnement.
PyBullet est un module python pour créer un environnement de simulation physique basé sur le moteur physique
Bullet Physics . Il, comme MuJoCo, est souvent utilisé comme stimulation de divers robots, qui sont intéressés par habr il y a
un article avec des exemples réels.
Il existe un très bon
QuickStartGuide pour PyBullet qui contient des liens vers des exemples sur la page source de
GitHub .
PyBullet vous permet de charger des modèles déjà créés au format URDF, SDF ou MJCF. Dans les sources, il y a une bibliothèque de
modèles dans ces formats, ainsi que des environnements complètement prêts à l'emploi de simulateurs de
vrais robots.Dans notre cas, nous créerons nous-mêmes l'environnement en utilisant PyBullet. L'interface d'environnement sera
similaire à l'interface d'OpenAI Gym. De cette façon, nous pouvons former nos agents à la fois dans notre environnement et dans l'environnement Gym.
Tout le code (iPython), ainsi que le fonctionnement du programme sont visibles dans
Google Colaboratory .
L'environnement
Notre environnement sera constitué d'une balle qui peut se déplacer le long de l'axe vertical dans une certaine plage de hauteurs. La balle a une masse et la gravité agit sur elle, et l'agent doit, en contrôlant la force verticale appliquée à la balle, la ramener à la cible. L'altitude cible change à chaque redémarrage de l'expérience.

La simulation est très simple et peut en fait être considérée comme une simulation de quelque élémentaire.
Pour travailler avec l'environnement, 3 méthodes sont utilisées:
reset (redémarrage de l'expérience et création de tous les objets de l'environnement),
étape (application de l'action sélectionnée et obtention de l'état résultant de l'environnement),
rendu (affichage visuel de l'environnement).
Lors de l'initialisation de l'environnement, il est nécessaire de connecter notre objet à la simulation physique. Il existe 2 options de connexion: avec une interface graphique (GUI) et sans (DIRECT) Dans notre cas, c'est DIRECT.
pb.connect(pb.DIRECT)
réinitialiser
Avec chaque nouvelle expérience, nous réinitialisons la simulation
pb.resetSimulation () et créons à nouveau tous les objets d'environnement.
Dans PyBullet, les objets ont 2 formes: une
forme de collision et une
forme visuelle . Le premier est utilisé par le moteur physique pour calculer les collisions d'objets et, pour accélérer le calcul de la physique, a généralement une forme plus simple qu'un objet réel. Le second est facultatif et n'est utilisé que lors de la formation de l'image de l'objet.
Les formulaires sont collectés dans un seul objet (corps) -
MultiBody . Un corps peut être constitué d'une seule forme (paire
CollisionShape / Visual Shape ), comme dans notre cas, ou de plusieurs.
En plus des formes qui composent le corps, il est nécessaire de déterminer sa masse, sa position et son orientation dans l'espace.
Quelques mots sur les corps multi-objets.En règle générale, dans des cas réels, pour simuler divers mécanismes, des corps composés de nombreuses formes sont utilisés. Lors de la création du corps, en plus de la forme de base des collisions et de la visualisation, le corps est transféré des chaînes de formes d'objets enfants (
Liens ), leur position et leur orientation par rapport à l'objet précédent, ainsi que les types de connexions (articulations) d'objets entre eux (
Articulation ). Les types de connexions peuvent être fixes, prismatiques (glissant sur le même axe) ou rotatifs (tournant sur un axe). Les 2 derniers types de connexions vous permettent de définir les paramètres des types de moteurs correspondants (
JointMotor ), tels que la force agissante, la vitesse ou le couple, simulant ainsi les moteurs des "articulations" du robot. Plus de détails dans la
documentation .
Nous allons créer 3 corps: Ball, Plane (Earth) et Target Pointer. Le dernier objet n'aura qu'une forme de visualisation et une masse nulle, il ne participera donc pas à l'interaction physique entre les corps:
Définissez la gravité et le temps de l'étape de simulation.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
Pour empêcher la balle de tomber immédiatement après le début de la simulation, nous équilibrons la gravité.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
pas
L'agent sélectionne des actions en fonction de l'état actuel de l'environnement, après quoi il appelle la méthode
step et reçoit un nouvel état.
2 types d'action sont définis: augmentation et diminution de la force agissant sur le ballon. Les limites de force sont limitées.
Après avoir modifié la force agissant sur la balle, une nouvelle étape de simulation physique
pb.stepSimulation () est lancée et les paramètres suivants sont renvoyés à l'agent:
observation - observations (état de l'environnement)
récompense - récompense pour une action parfaite
fait - le drapeau de la fin de l'expérience
info - informations supplémentaires
Comme l'état de l'environnement, 3 valeurs sont renvoyées: la distance à la cible, la force actuelle appliquée à la balle et la vitesse de la balle. Les valeurs sont retournées normalisées (0..1), car les paramètres environnementaux qui déterminent ces valeurs peuvent varier en fonction de notre désir.
La récompense pour l'action parfaite est 1 si le ballon est proche de la cible (hauteur cible plus / moins la valeur de roulement acceptable
TARGET_DELTA ) et 0 dans les autres cas.
L'expérience est terminée si le ballon sort de la zone (tombe au sol ou vole haut). Si le ballon atteint le but, l'expérience se termine également, mais seulement après un certain temps (étapes
STEPS_AFTER_TARGET de l'expérience). Ainsi, notre agent est formé non seulement pour avancer vers le but, mais aussi pour s'arrêter et en est proche. Étant donné que la récompense lorsque vous êtes proche de l'objectif est de 1, une expérience pleinement réussie devrait avoir une récompense totale égale à
STEPS_AFTER_TARGET .
En tant qu'informations supplémentaires pour l'affichage des statistiques, le nombre total d'étapes effectuées dans l'expérience, ainsi que le nombre d'étapes effectuées par seconde, est renvoyé.
rendre
PyBullet dispose de 2 options de rendu d'image - le rendu GPU basé sur OpenGL et le processeur basé sur TinyRenderer. Dans notre cas, seule une implémentation CPU est possible.
Pour obtenir la trame actuelle de la simulation, il est nécessaire de déterminer la
matrice des espèces et la
matrice de projection , puis d'obtenir l'image
rgb de la taille donnée à partir de la caméra.
camTargetPos = [0,0,5]
À la fin de chaque expérience, une vidéo est générée sur la base des images collectées.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
Agent
Le code utilisateur GitHub
jaara a été pris comme base pour l'agent, comme un exemple simple et compréhensible de mise en œuvre de l'entraînement de renforcement pour l'environnement Gym.
L'agent contient 2 objets: la
mémoire - un stockage pour la formation d'exemples d'entraînement et le
cerveau lui-même est le réseau neuronal qu'il forme.
Le réseau neuronal formé a été créé sur TensorFlow à l'aide de la bibliothèque Keras, qui a récemment été entièrement
incluse dans TensorFlow.
Le réseau neuronal a une structure simple - 3 couches, c'est-à-dire Seulement 1 couche cachée.
La première couche contient 512 neurones et possède un nombre d'entrées égal au nombre de paramètres de l'état du milieu (3 paramètres: distance à la cible, force et vitesse de la balle). La couche cachée a une dimension égale à la première couche - 512 neurones, en sortie elle est connectée à la couche de sortie. Le nombre de neurones de la couche de sortie correspond au nombre d'actions effectuées par l'agent (2 actions: diminution et augmentation de la force agissante).
Ainsi, l'état du système est fourni à l'entrée du réseau, et à la sortie, nous avons un avantage pour chacune des actions.
Pour les deux premières couches,
ReLU (unité linéaire rectifiée) est utilisée comme fonctions d'activation, pour la dernière - une
fonction linéaire (la somme des valeurs d'entrée est simple).
En fonction de l'erreur,
MSE (erreur standard), comme algorithme d'optimisation -
RMSprop (Root Mean Square Propagation).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
Après chaque étape de simulation, l'agent enregistre les résultats de cette étape sous forme de liste
(s, a, r, s_) :
s - observation précédente (état de l'environnement)
a - action terminée
r - récompense reçue pour l'action effectuée
s_ - observation finale après l'action
Après cela, l'agent reçoit de la mémoire un ensemble aléatoire d'exemples pour les périodes précédentes et forme un package de formation (
batch ).
L'état initial
s des étapes aléatoires sélectionnées dans la mémoire est pris comme valeurs d'entrée (
X ) du paquet.
Les valeurs réelles de la sortie d'apprentissage (
Y ' ) sont calculées comme suit: À la sortie (
Y ) du réseau neuronal pour s, il y aura des valeurs de la
fonction Q pour chacune des actions
Q (s) . Dans cet ensemble, l'agent a sélectionné l'action avec la valeur la plus élevée
Q (s, a) = MAX (Q (s)) , l'a terminée et a reçu le prix
r . La nouvelle valeur
Q pour l'action sélectionnée
a sera
Q (s, a) = Q (s, a) + DF * r , où
DF est le facteur d'actualisation. Les valeurs de sortie restantes resteront les mêmes.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
La formation réseau a lieu sur le pack formé
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
Une fois l'expérience terminée, une vidéo est générée
et les statistiques sont affichées
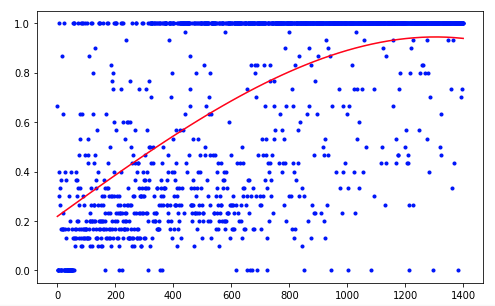
L'agent a eu besoin de 1 200 essais pour obtenir un résultat d'environ 95% (nombre d'étapes réussies). Et à la 50e expérience, l'agent avait appris à déplacer la balle vers la cible (les expériences infructueuses disparaissent).
Pour améliorer les résultats, vous pouvez essayer de modifier la taille des couches réseau (LAYER_SIZE), le paramètre du facteur d'actualisation (GAMMA) ou le taux de diminution de la probabilité de choisir une action aléatoire (LAMBDA).
Notre agent a l'architecture la plus simple - DQN (Deep Q-Network). Sur une tâche aussi simple, il suffit d'obtenir un résultat acceptable.
L'utilisation, par exemple, de l'architecture DDQN (Double DQN) devrait fournir une formation plus fluide et plus précise. Et le réseau RDQN (DQN récurrent) sera en mesure de suivre les modèles de changement environnemental au fil du temps, ce qui permettra de se débarrasser du paramètre de vitesse de balle, réduisant le nombre de paramètres d'entrée du réseau.
Vous pouvez également étendre notre simulation en ajoutant une masse de balle variable ou l'angle d'inclinaison de son mouvement.
Mais c'est la prochaine fois.