Il y a un an, nous avons ajouté à notre agent une collection de métriques à partir des attributs de disque SMART sur les serveurs clients. À ce moment, nous ne les avons pas ajoutés à l'interface et ne les avons pas montrés aux clients. Le fait est que nous ne prenons pas les métriques via smartctl, mais nous tirons ioctl directement du code pour que cette fonctionnalité fonctionne sans installer smartmontools sur les serveurs clients.
L'agent ne supprime pas tous les attributs disponibles, mais uniquement les plus importants à notre avis et les moins spécifiques au fournisseur (sinon, vous devrez conserver une base de disques similaire à smartmontools).
Maintenant, les mains ont enfin atteint le point de vérifier ce que nous avons filmé là-bas. Et il a été décidé de commencer par l'attribut "indicateur d'usure des supports", qui indique le pourcentage de ressource d'enregistrement SSD restante. Sous la coupe, quelques histoires en images sur la façon dont cette ressource est dépensée dans la vie réelle sur les serveurs.
Y a-t-il des SSD tués?
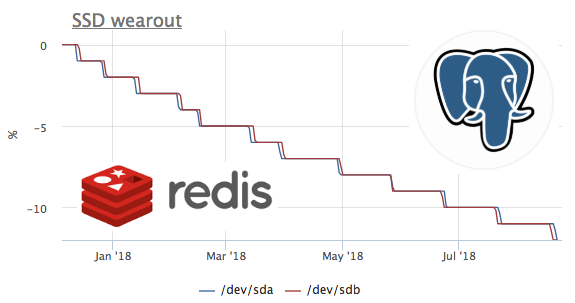
On pense que de nouveaux ssds plus productifs sont publiés plus souvent que les anciens parviennent à se faire tuer. Par conséquent, la première chose qu'il était intéressant de regarder les plus tués en termes d'enregistrement de disque de ressources. La valeur minimale pour tous les ssd de tous les clients est de 1%.
Nous avons immédiatement écrit au client à ce sujet, il s'est avéré être un Dedik chez hetzner. Le support d'hébergement a immédiatement remplacé ssd:

Il serait très intéressant de voir à quoi ressemble la situation du point de vue du système d'exploitation lorsque ssd arrête de gérer un enregistrement (nous recherchons maintenant la possibilité de se moquer délibérément de ssd afin d'examiner les métriques de ce scénario :)
À quelle vitesse les SSD sont-ils tués?
Depuis que nous avons commencé à collecter des métriques il y a un an et que nous ne supprimons pas les métriques, il est possible d'examiner cette métrique à temps. Malheureusement, le serveur avec le débit le plus élevé a été connecté à l'okmètre il y a seulement 2 mois.

Dans ce graphique, nous voyons comment en 2 mois, ils ont brûlé 8% de la ressource d'enregistrement. Autrement dit, avec le même profil d'enregistrement, ces ssd seront suffisants pour 100 / (8/2) = 25 mois. Je ne sais pas grand-chose ou peu, mais voyons quel genre de charge il y a?

Nous voyons que seul ceph fonctionne avec le disque, mais nous comprenons que ceph n'est qu'une couche. Dans ce cas, le client ceph agit comme un référentiel pour le cluster kubernetes sur plusieurs nœuds, voyons ce qui à l'intérieur de k8s génère le plus d'écritures sur disque:

Les valeurs absolues ne correspondent pas très probablement en raison du fait que ceph fonctionne dans le cluster et que l'enregistrement de redis augmente en raison de la réplication des données. Mais le profil de charge vous permet de dire en toute confiance que l'enregistrement démarre exactement redis. Voyons ce qui se passe sur le radis:

ici, vous pouvez voir qu'en moyenne moins de 100 requêtes par seconde sont exécutées, ce qui peut modifier les données. Rappelons que redis a 2 façons d'écrire des données sur le disque :
- RDB - instantanés périodiques de la base de données entière sur le disque, lors du démarrage de redis, nous lisons le dernier vidage en mémoire et nous perdons des données entre les vidages
- AOF - nous écrivons un journal de toutes les modifications, au début, redis perd ce journal et toutes les données apparaissent en mémoire, nous ne perdons que les données entre fsync de ce journal
Comme tout le monde l'a probablement déjà deviné dans ce cas, RDB est utilisé avec une fréquence de vidage de 1 minute:

SSD + RAID
Selon nos observations, il existe trois configurations principales du sous-système de disques des serveurs avec présence de SSD:
- dans le serveur 2 SSD collectés en raid-1 et tout y vit
- le serveur a HDD + raid-10 de ssd, il est généralement utilisé pour les SGBDR classiques (système, WAL et une partie des données sur le disque dur, et sur le SSD les données les plus chaudes en termes de lecture)
- le serveur dispose d'un SSD autonome (JBOD), généralement utilisé pour les cassandra de type nosql
Si les ssd sont collectés dans le raid-1, l'enregistrement va aux deux disques, donc l'usure se poursuit à la même vitesse:
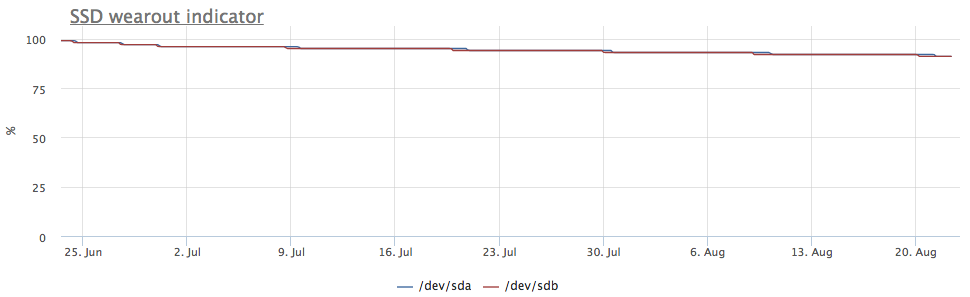
Mais le serveur a attiré mon attention, dans lequel l'image est différente:

Dans ce cas, seules les partitions mdraid sont montées (toutes les baies raid-1):

Les métriques d'enregistrement montrent également qu'il y a plus d'entrées sur / dev / sda:

Il s'est avéré qu'une des partitions sur / dev / sda est utilisée comme swap, et les swap i / o sur ce serveur sont assez visibles:

Amortissement des SSD et PostgreSQL
En fait, je voulais voir le taux d'usure ssd à diverses charges d'écriture dans Postgres, mais en règle générale, ils sont utilisés très soigneusement sur les bases de données ssd chargées et un enregistrement massif va sur le disque dur. En cherchant un cas approprié, je suis tombé sur un serveur très intéressant:

L'usure de deux ssd en raid-1 pendant 3 mois était de 4%, mais à en juger par la vitesse d'enregistrement WAL, ce postgres écrit moins de 100 Kb / s:
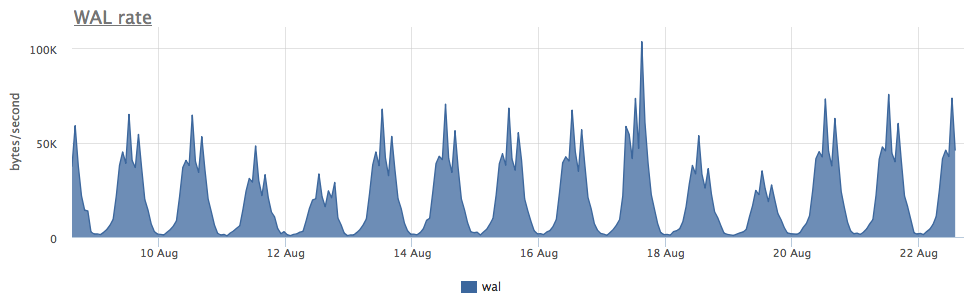
Il s'est avéré que postgres utilise activement des fichiers temporaires, ce qui crée un flux constant d'écriture sur le disque:

Étant donné que postgresql avec diagnostics est assez bon, nous pouvons, jusqu'à la demande, savoir exactement ce que nous devons corriger:

Comme vous pouvez le voir ici, ce SELECT particulier génère un tas de fichiers temporaires. En général, dans SELECT postgres, ils génèrent parfois un enregistrement sans aucun fichier temporaire - nous en avons déjà parlé ici.
Total
- La quantité d'écriture sur disque créée par Redis + RDB ne dépend pas du nombre de modifications dans la base de données, mais de la taille de la base de données + intervalle de vidage (et en général, c'est le plus haut niveau d'amplification d'écriture dans les magasins de données que je connais)
- L'échange activement utilisé sur ssd est mauvais, mais si vous avez besoin d'ajouter de la gigue à l'usure ssd (pour la fiabilité du raid-1), cela pourrait être une option :)
- En plus du WAL et des fichiers de données, les bases de données peuvent toujours écrire toutes sortes de données temporaires sur le disque.
Chez okmeter.io, nous pensons que pour aller au fond de la cause du problème, l'ingénieur a besoin de beaucoup de métriques sur toutes les couches de l'infrastructure. Nous faisons de notre mieux pour vous aider :)