
Nous avons deux approches de la récupération après sinistre: un cluster «étiré» (installation active-active) et une plate-forme avec des machines virtuelles (répliques) désactivées. Ils ont plusieurs points pour enregistrer des instantanés.
Il y a une demande de tolérance aux catastrophes, et beaucoup de nos clients en ont vraiment besoin. Par conséquent, nous avons commencé à élaborer les deux schémas dans le cadre de notre production.
Les méthodes ont des avantages et des inconvénients, maintenant je vais vous en parler.
Cluster étiré
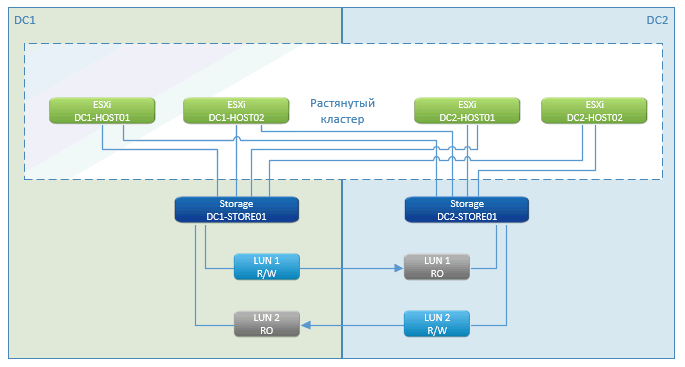
Comme vous pouvez le voir, il s'agit d'une histoire de cluster de métro standard. Chez les pros - temps d'arrêt quasi nul, une pause uniquement au moment du démarrage des machines virtuelles. Cette fonctionnalité fonctionne - VMware High Availability (HA). Elle voit que les hôtes sont perdus et redémarre immédiatement la machine virtuelle sur le site distant.
Le lancement se fait immédiatement à partir du stockage, qui se trouve dans le cluster.
Le stockage avec un cluster géo-distribué est une fonctionnalité marketing de NetApp. D'autres fabricants ont quelque chose avec un nom similaire. Il s'agit essentiellement d'une réplication asynchrone réfléchie d'un côté à l'autre. Nous écrivons sur un nœud du réseau local et nous synchronisons via des canaux de communication spécialisés avec un autre.
En cas de panne de l'un des systèmes de stockage, le reste (sur un autre site) présente le chemin d'accès aux disques vers les hôtes restants. Les machines virtuelles mortes sont redémarrées sur elles. Tout se passe automatiquement - le centre de données est tombé en panne, tout a redémarré, le stockage a fonctionné, VMware a fonctionné. Le client a vu que tout clignait des yeux et recommençait.
Le seul cache de la RAM de la VM peut être perdu. Mais si la base de données l'a supprimée, la perte est nulle dans le temps.
Si nous perdons la communication entre les sites, alors tout continue à fonctionner à sa place et, dès que la connexion est rétablie, elle commence à se synchroniser.
L'inconvénient est le prix élevé. Parce que vous avez réellement besoin d'un double SHD (de plus, de type, de vitesse et de volume de disques du premier SHD similaire sur le site principal), qui ne peut pas être utilisé d'une manière ou d'une autre, sauf comme réserve. De plus, la liaison au stockage pour le cluster de métro, ce sont les ponts FC, le réseau FC et plus encore.
Nous avons deux DPC, entre eux un faisceau FC le long de deux faisceaux (quatre lignes optiques sombres et DWDM). Ce sont deux morceaux de fer, chacun fournit une bande passante de 200 Gbit / s pour FC et Ethernet.
Alternative avec DR

Il existe un logiciel avec un nom intuitivement mémorable - VMware vCloud Availability for Cloud-to-Cloud DR.
Il s'agit d'un système permettant de créer une VM identique sur un site distant une fois, relativement parlant, en 15 minutes. Un système permettant de présenter tout cela correctement aux mécanismes de contrôle du cloud lui est attaché sur du ruban électrique.
Autrement dit, la technologie de réplication VMware est dans le backend. En cas d'échec, nous lançons manuellement le plan DR sur le deuxième site, il arrête automatiquement d'essayer de répliquer, puis enregistre la machine virtuelle dans vCloud Director, personnalise les adresses IP (afin qu'il ne doive pas être changé en machine virtuelle) et démarre la machine virtuelle dans l'ordre nécessaire. Dans notre solution, il n'est pas nécessaire de modifier l'adressage, nous étendons les réseaux aux deux centres de données.
Les machines sont constamment répliquées, mais pas l'intégralité du centre de données, mais seules celles sélectionnées sont des processus critiques. Il est répliqué de temps en temps, l'intervalle minimum est de 15 minutes (c'est un cas idéal lorsque tout vole et qu'il y a un serveur de réplication dédié et un minimum de changements sur la VM). En pratique, vous en avez une copie il y a une demi-heure ou une heure. En cas de problème, les données tombées dans l'intervalle étaient perdues. 15 minutes est la question de l'agent qui collecte la nouvelle réplication. Veeam dit qu'ils peuvent prendre moins de 15 minutes, mais en fait, c'est aussi plus long en pratique s'ils n'utilisent pas les fonctionnalités de stockage. Je n'ai pas vu sur une machine industrielle (pas sur un test) qu'il en serait autrement.
Pendant longtemps, NetApp, comme de nombreux autres fabricants de systèmes de stockage, dispose de la technologie SnapMirror, qui vous permet de déplacer le travail de réplication des hyperviseurs vers les systèmes de stockage, et VMware Replication peut l'utiliser.
Alors que le service de réplication fonctionne, le train va loin. Mais c'est bon marché.
Pourquoi est-il toujours bon marché - parce que vous pouvez utiliser n'importe quel stockage de n'importe quel côté (de différents fabricants, de différentes classes), vous n'avez pas besoin d'allouer un grand volume de disques à l'avance.
Pas besoin d'allouer un grand groupe de disques, à l'intérieur duquel les lunes sont coupées. Il prend juste une place sur le stockage local et est appliqué sur le fait de la disponibilité de l'enregistrement à partir de la machine virtuelle. Pour cette raison, la place sur le système de stockage est occupée de manière optimale, si elle est utilisée pour d'autres tâches. Et il est utilisé, car nous ne proposons pas un tel service à tous les clients.
Moins - vous devez configurer la réplication au niveau de la machine virtuelle, c'est-à-dire contrôler que tout est correctement configuré, qu'il s'agit de la machine, assurez-vous que la réplication réussit, qu'il n'y a pas d'erreur. Créez des plans DR pour chaque client, effectuez leurs tests.
Dans le premier cas, le stockage est pris, conditionnellement, infrastructurellement, presque par secteurs (plus précisément, par objets). Et puis une machine peut tomber en raison d'une tâche qui tombe pour des raisons logicielles liées à un bogue à des niveaux élevés ou à des problèmes d'accessibilité. Cela se produit un peu plus souvent que si vous ne prenez que des niveaux faibles.
En plus - DR enregistre plusieurs points. Vous pouvez restaurer quelques instantanés.
En dehors du système d'exploitation invité, vous avez besoin de logiciels supplémentaires.
Afin d'obtenir tous les réseaux nécessaires à Vcloud Director, nous avons besoin du travail de notre administrateur. En général, toute la connectivité réseau dans cette version reste avec notre administrateur. Pour un client cloud, cela signifie une application, ce qui prend également du temps.
La réplication est également configurée via l'application. VM ajoutée - vous devez envoyer une demande dont vous avez besoin pour la répliquer. Il ne tombe pas automatiquement dans les tâches de réplication. Il faut faire attention à l'administrateur.
La différence
Par conséquent, le prix peut différer de plus de deux fois. La réplication multipliera le coût de l'espace disque par deux ou plus (deux copies complètes + historique des modifications), plus quelque chose pour le service et la réservation des ressources informatiques. Dans le cas du cluster de métro, le coût de l'espace sera multiplié par deux, mais l'espace lui-même coûtera beaucoup plus, et vous devrez réserver fermement des nœuds sur un site distant. Autrement dit, les ressources informatiques doivent être multipliées par deux, nous ne pouvons pas les utiliser pour autre chose.
Dans le cas du cluster metro, nous ne pouvons utiliser que les mêmes types de disques pour qu'il y ait un miroir complet. Si sur le centre de données principal certains des disques sont rapides, certains lents à 10 000 tours par minute, alors une configuration identique est nécessaire. Dans le cas d'une réplique, des disques plus lents sur le site de sauvegarde sont possibles, ce qui est moins cher en raison du stockage. Mais lors du passage à une réserve, ses performances seront moindres. Autrement dit, s'il stocke quelque chose sur le SSD dans le cluster principal et est répliqué sur des disques ordinaires, le stockage sera beaucoup moins cher au prix d'un ralentissement de l'infrastructure de réserve.
En ce moment, nous choisissons ce qui sera inclus dans une version antérieure, nous voulons donc consulter: pouvez-vous nous dire brièvement comment vous organisez vos sites de DR et que souhaiteriez-vous qu'ils fassent en général?