
J'ai pu récupérer mon poste de travail en tant qu'étudiant. Assez logiquement, j'ai préféré les solutions informatiques AMD. parce que ça pas cher rentable en termes de rapport qualité / prix. J'ai ramassé les composants pendant longtemps, à la fin je suis entré avec 40k avec un ensemble de FX-8320 et RX-460 2GB. Au début, ce kit semblait parfait! Mon colocataire et moi avons légèrement exploité Monero et mon set affichait 650h / s contre 550h / s sur un set de i5-85xx et Nvidia 1050Ti. Certes, de mon ensemble dans la pièce, il faisait un peu chaud la nuit, mais cela a été décidé lorsque j'ai acheté un refroidisseur de tour pour le processeur.
L'histoire est finie
Tout était exactement comme dans un conte de fées jusqu'à ce que je m'intéresse à l'apprentissage automatique dans le domaine de la vision par ordinateur. Encore plus précisément - jusqu'à ce que je devais travailler avec des images d'entrée avec une résolution de plus de 100x100px (jusqu'à présent, mon FX à 8 cœurs s'est copieusement adapté). La première difficulté était la tâche de déterminer les émotions. 4 couches ResNet, image d'entrée 100x100 et 3000 images dans le jeu de formation. Et maintenant - 9 heures de formation 150 époques sur le CPU.
Bien sûr, en raison de ce retard, le processus de développement itératif en souffre. Au travail, nous avions Nvidia 1060 6 Go et nous nous entraînions pour une structure similaire (bien que la régression y ait été formée pour localiser des objets), il volait en 15-20 minutes - 8 secondes pour une ère d'images de 3,5k. Lorsque vous avez un tel contraste sous votre nez, la respiration devient encore plus difficile.
Eh bien, devinez mon premier coup après tout ça? Oui, je suis allé négocier 1050Ti avec mon voisin. Avec des arguments sur l'inutilité de CUDA pour lui, avec une offre pour échanger ma carte contre un supplément. Mais en vain. Et maintenant, je poste mon RX 460 sur Avito et j'examine le 1050Ti chéri sur les sites de Citylink et TechnoPoint. Même en cas de vente réussie de la carte, je devrais trouver 10 000 autres (je suis étudiant, bien que professionnel).
Google
Ok Je vais google comment utiliser Radeon sous Tensorflow. Sachant qu'il s'agissait d'une tâche exotique, je n'espérais pas particulièrement trouver quoi que ce soit de sensé. Collectez sous Ubuntu, qu'il démarre ou non, obtenez une brique - phrases arrachées sur les forums.
Et donc je suis allé dans l'autre sens - je n'ai pas google Tensorflow AMD Radeon, mais Keras AMD Radeon. Il me renvoie instantanément sur la page de PlaidML . Je le démarre en 15 minutes (même si j'ai dû rétrograder Keras à 2.0.5) et configurer le réseau pour apprendre. Première observation - l'ère est de 35 secondes au lieu de 200.
Grimpez pour explorer
Les auteurs de PlaidML sont vertex.ai , qui fait partie du groupe de projet Intel (!). L'objectif de développement est un maximum multiplateforme. Bien sûr, cela ajoute de la confiance au produit. Leur article dit que PlaidML est compétitif avec Tensorflow 1.3 + cuDNN 6 en raison d'une "optimisation approfondie".
Cependant, nous continuons. L'article suivant nous révèle dans une certaine mesure la structure interne de la bibliothèque. La principale différence avec tous les autres cadres est la génération automatique de noyaux de calcul (dans la notation Tensorflow, le «noyau» est le processus complet d'exécution d'une certaine opération dans un graphique). Pour la génération automatique de noyau dans PlaidML, les dimensions exactes de tous les tenseurs, constantes, étapes, tailles de convolution et valeurs limites avec lesquelles vous devrez travailler plus tard sont très importantes. Par exemple, il est avancé que la création ultérieure de noyaux efficaces diffère pour les tailles de patch 1 et 32 ou pour les convolutions 3x3 et 7x7. Ayant ces données, le framework lui-même générera le moyen le plus efficace de paralléliser et d'exécuter toutes les opérations pour un appareil particulier avec des caractéristiques spécifiques. Si vous regardez Tensorflow, lorsque vous créez de nouvelles opérations, nous devons également implémenter le noyau pour elles - et les implémentations sont très différentes pour les noyaux à un seul thread, à plusieurs threads ou compatibles CUDA. C'est-à-dire PlaidML est clairement plus flexible.
Nous allons plus loin. L'implémentation est écrite dans le langage auto-écrit Tile . Ce langage présente les principaux avantages suivants - la proximité de la syntaxe avec les notations mathématiques (mais devenez fou!):
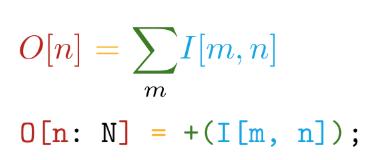
Et différenciation automatique de toutes les opérations déclarées. Par exemple, dans TensorFlow, lors de la création d'une nouvelle opération personnalisée, il est fortement recommandé d'écrire une fonction pour calculer les dégradés. Ainsi, lors de la création de nos propres opérations dans le langage Tile, nous n'avons qu'à dire CE QUE nous voulons calculer sans penser à COMMENT considérer cela par rapport aux périphériques matériels.
De plus, l'optimisation du travail avec la DRAM et un analogue du cache L1 dans le GPU est effectuée. Rappelez le dispositif schématique:
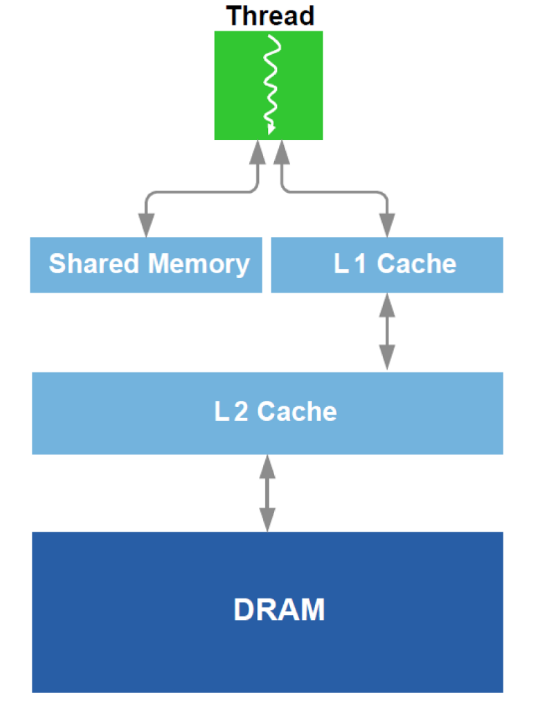
Pour l'optimisation, toutes les données disponibles sur l'équipement sont utilisées - taille du cache, largeur de ligne du cache, bande passante DRAM, etc. Les principales méthodes sont la lecture simultanée de blocs suffisamment grands à partir de la DRAM (une tentative pour éviter l'adressage à différentes zones) et la réalisation que les données chargées dans le cache sont utilisées plusieurs fois (une tentative pour éviter de recharger les mêmes données plusieurs fois).
Toutes les optimisations ont lieu au cours de la première période d'entraînement, tout en augmentant considérablement le temps de la première manche:
De plus, il convient de noter que ce cadre est lié à OpenCL . Le principal avantage d'OpenCL est qu'il est un standard pour les systèmes hétérogènes et rien ne vous empêche d'exécuter le noyau sur le CPU . Oui, c'est là que réside l'un des principaux secrets de la plateforme multiplateforme PlaidML.
Conclusion
Bien sûr, la formation sur le RX 460 est encore 5 à 6 fois plus lente que sur le 1060, mais vous pouvez comparer les catégories de prix des cartes vidéo! Ensuite, j'ai eu un RX 580 8 Go (ils m'ont prêté!) Et le temps qu'il a fallu pour exécuter l'ère a été réduit à 20 secondes, ce qui est presque comparable.
Le blog vertex.ai a des graphiques honnêtes (plus c'est mieux):
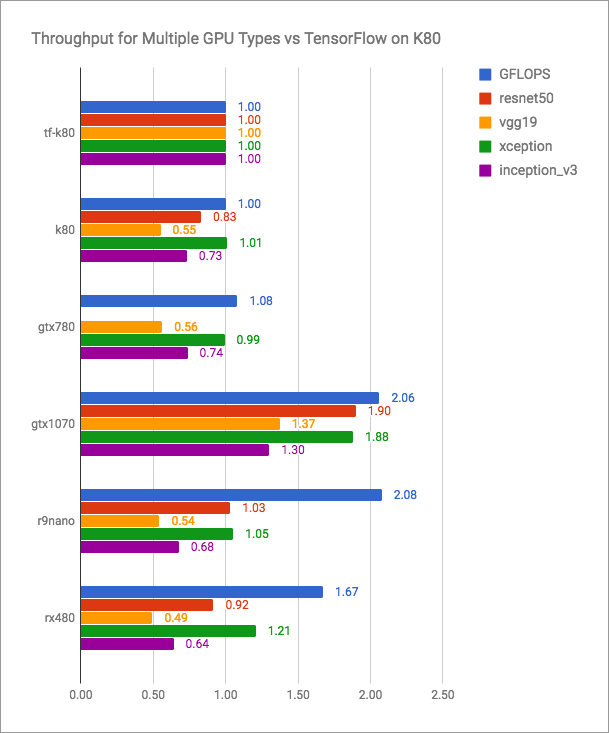
On peut voir que PlaidML est compétitif avec Tensorflow + CUDA, mais certainement pas plus rapide pour les versions actuelles. Mais les développeurs de PlaidML ne prévoient probablement pas d'entrer dans une telle bataille ouverte. Leur objectif est l'universalité, multiplateforme.
Je vais laisser ici un tableau pas tout à fait comparatif avec mes mesures de performances:
| Appareil informatique | Temps d'exécution de l'ère (lot - 16), s |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB plaid | 35 |
| RX 580 8 GB plaid | 20 |
| 1060 6GB TF | 8 |
| 1060 6GB plaid | 10 |
| Intel i7-2600 tf | 185 |
| Plaid Intel i7-2600 | 240 |
| Plaqué GT 640 | 46 |
Le dernier article du blog vertex.ai et les dernières modifications apportées au référentiel datent de mai 2018. Il semble que si les développeurs de cet outil n'arrêtent pas de publier de nouvelles versions et que de plus en plus de personnes offensées par Nvidia connaissent PlaidML, alors ils parleront beaucoup plus souvent de vertex.ai.
Découvrez vos radeons!