
Le deuxième jour du programme KDD principal. Sous la coupe à nouveau, beaucoup de choses intéressantes: de l'apprentissage automatique sur Pinterest à diverses façons de creuser dans les tuyaux d'eau. Y compris le discours du lauréat du prix Nobel d'économie - une histoire sur le fonctionnement de la NASA avec la télémétrie et de nombreux incorporations de graphiques :)
Conception du marché et marché informatisé
Une bonne performance du
lauréat du prix Nobel qui a travaillé avec Shapley sur les marchés. Le marché est une chose artificielle dont les gens inventent l'appareil. Il y a ce qu'on appelle les marchés de matières premières, lorsque vous achetez un certain produit et que vous ne vous souciez pas de qui, cela n'a d'importance qu'à quel prix (par exemple, le marché boursier). Et il y a des marchés assortis lorsque le prix n'est pas le seul facteur (et parfois pas du tout).
Par exemple, la répartition des enfants dans les écoles. Auparavant, aux États-Unis, le système fonctionnait comme ceci: les parents notent la liste des écoles par priorité (1, 2, 3, etc.), les écoles considèrent d'abord celles qui les ont indiquées comme numéro 1, les trient selon leurs critères scolaires et en prennent autant qu'elles peuvent. . Pour ceux qui n'ont pas frappé, nous prenons la deuxième école et répétons la procédure. Du point de vue de la théorie des jeux, le schéma est très mauvais: les parents doivent se comporter «stratégiquement», il n'est pas pratique de dire honnêtement leurs préférences - si vous n'entrez pas à l'école 1, au deuxième tour, l'école 2 peut déjà être pleine et vous n'y entrerez pas, même si vos caractéristiques sont supérieures à celles qui ont été acceptées au premier tour. Dans la pratique, le non-respect de la théorie des jeux se traduit par de la corruption et des accords internes entre les parents et les écoles. Les mathématiciens ont proposé un autre algorithme - «l'acceptation différée». L'idée principale est que l'école ne donne pas son consentement immédiatement, mais conserve simplement une liste classée des candidats «en mémoire», et si quelqu'un va au-delà de la queue, il obtient immédiatement un refus. Dans ce cas, il y a une stratégie dominante pour les parents: d'abord on va à l'école 1, si à un moment on obtient un refus, puis on va à l'école 2 et on n'a peur de rien perdre - les chances d'aller à l'école 2 sont les mêmes que si on y allait tout de suite. Ce schéma a cependant été mis en œuvre «en production». Les résultats du test A / B n'ont pas été rapportés.
Un autre exemple est la transplantation rénale. Contrairement à de nombreux autres organes, vous pouvez vivre avec un rein, de sorte qu'une situation se présente souvent: quelqu'un est prêt à donner un rein à une autre personne, mais pas abstrait, mais spécifique (en raison de relations personnelles). Cependant, la probabilité que le donneur et le receveur soient compatibles est très faible, et vous devez attendre un autre organe. Il existe une alternative - l'échange de reins. Si deux paires sont donneuses et receveuses et sont incompatibles à l'intérieur, mais compatibles entre les paires, alors vous pouvez échanger: 4 opérations simultanées d'extraction / implantation. Le système fonctionne déjà pour cela. Et s'il existe un organe «libre» qui n'est pas lié à une paire spécifique, alors il peut donner lieu à toute une chaîne d'échanges (en pratique, il y avait des chaînes de jusqu'à 30 transplantations).
Il existe actuellement de nombreux marchés de correspondance similaires: d'Uber au marché de la publicité en ligne, et tout change très rapidement en raison de l'informatisation. Entre autres choses, la «vie privée» change beaucoup: à titre d'exemple, l'orateur a cité une étude d'un étudiant qui a montré qu'aux États-Unis après l'élection, le nombre de voyages à visiter sur l'Action de grâces a diminué en raison de voyages entre États ayant des opinions politiques différentes. L'étude a été menée sur un ensemble de données anonyme de coordonnées téléphoniques, mais l'auteur a assez facilement identifié le «domicile» du propriétaire du téléphone, c'est-à-dire ensemble de données deanonymized.
Par ailleurs, l'orateur a évoqué le chômage technologique. Oui, les voitures sans pilote en priveront bon nombre (6% des emplois aux États-Unis sont à risque), mais ils créeront de nouveaux emplois (pour les mécaniciens automobiles). Bien sûr, le conducteur âgé ne pourra plus se recycler et ce sera pour lui un coup dur. À de tels moments, vous devez vous concentrer non pas sur la façon de prévenir les changements (cela ne fonctionnera pas), mais sur la façon d'aider les gens à les surmonter le plus indolore possible. Au milieu du siècle dernier, lors de la mécanisation de l'agriculture, beaucoup de gens ont perdu leur emploi, mais nous sommes heureux que maintenant la moitié de la population n'ait pas à aller travailler dans les champs? Malheureusement, il ne s'agit que des options d'atténuation mises en œuvre pour ceux qui sont confrontés au chômage technologique, l'orateur n'a pas suggéré ...
Et oui, encore une fois sur l'équité. Il est impossible de rendre la distribution du modèle de prévision la même dans tous les groupes, le modèle perdra son sens. Que peut-on faire, en théorie, pour que la répartition des ERREURS du premier et du deuxième type soit la même pour tous les groupes? Cela semble déjà beaucoup plus sensé, mais la manière d'y parvenir dans la pratique n'est pas claire. Il a donné un lien vers un article intéressant sur la pratique juridique - aux États-Unis, un juge décide de libérer ou non sous caution
sur la base des prévisions de ML .
Recommandateurs I
Je suis devenu confus dans le calendrier et suis venu au mauvais discours, mais toujours dans le sujet - le premier bloc sur les systèmes de recommandation.
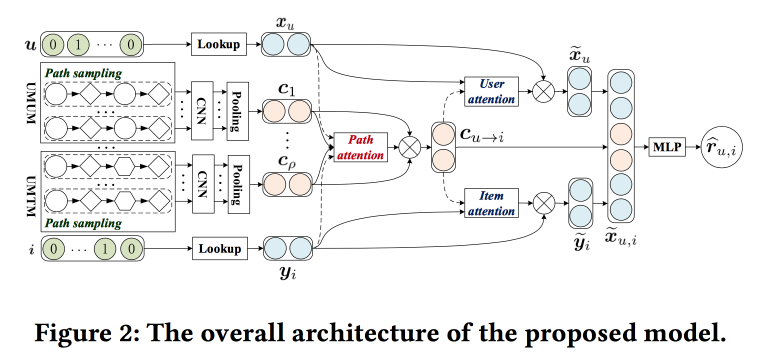
Tirer parti du contexte basé sur le méta-chemin pour la recommandation Top N avec un mécanisme de co-attention
Les gars essaient d'améliorer les recommandations en analysant les chemins dans le graphique. L'idée est assez simple. Il existe un recommandeur de réseau neuronal «classique» avec des incorporations pour les objets et les utilisateurs et une partie entièrement connectée sur le dessus. Il y a des recommandations sur le graphique, y compris celles avec des balises de réseau neuronal. Essayons de combiner tout cela en un seul mécanisme. Commençons par construire un «méta-graphique» qui unit les utilisateurs, les films et les attributs (acteur / réalisateur / genre, etc.), sur le graphique de marche aléatoire, nous échantillonnons un certain nombre de chemins, le transmettons au réseau de convolution, ajoutons des intégrations d'utilisateurs sur le côté et objet, et au-dessus nous mettons l'attention (ici un peu délicat, avec ses propres caractéristiques pour différentes branches). Pour obtenir la réponse finale, placez un perceptron avec deux couches cachées sur le dessus.
Applications Internet grand public
Dans la pause entre les rapports, je passe à la présentation où je voulais à l'origine: des conférenciers invités de LinkedIn, Pinterest et Amazon parlent ici. Toutes les filles et tous les chefs des départements DS.
Neraline Recommandations contextuelles pour les communautés actives LinkedIn
L'essentiel est de stimuler le développement et l'activation de la communauté sur LinkedIn. J'ai raté la moitié du développement, dernière recommandation: exploiter les schémas locaux. Par exemple, en Inde, les étudiants, souvent après l'obtention du diplôme, tentent de contacter les diplômés de la même université des cours passés avec une carrière établie. LinkedIn en tient compte lors de la création et lors de la formulation de recommandations.
Mais il ne suffit pas de créer une communauté, il faut qu'il y ait de l'activité: les utilisateurs publient du contenu, reçoivent et donnent leur avis. Montrez la corrélation des commentaires reçus avec le nombre de publications futures. Montrez comment les informations sont réparties en cascade dans le graphique. Mais que faire si un nœud n'est pas impliqué dans la cascade? Envoyez un avis!
Ensuite, il y a eu beaucoup de conversations avec l'histoire d'hier sur l'utilisation des notifications et de la bande. Ici, ils utilisent également l'approche d'optimisation polyvalente de «maximiser l'une des mesures tout en gardant les autres dans certaines limites». Pour contrôler la charge, nous avons introduit notre système de contrôle du trafic aérien, qui limite la charge sur les notifications par utilisateur (ils ont pu réduire les désabonnements et les plaintes de 20%, sans perdre l'engagement). L'ATC décide si le push peut être envoyé à l'utilisateur ou non, et ce push est préparé par un autre système appelé Concourse, qui fonctionne en mode streaming (comme le nôtre, sur
Samza !). C'est à son sujet que beaucoup a été dit hier. Concourse a également un partenaire hors ligne du nom de Beehive, mais progressivement, il est de plus en plus diffusé.
A noté quelques points supplémentaires:
- La déduplication est importante et de haute qualité, compte tenu de la présence de nombreux canaux et contenus.
- Il est important d'avoir une plateforme. Et ils ont une équipe de plate-forme dédiée, et les programmeurs y travaillent.
Approche Pinterest de l'apprentissage automatique
Un
porte-parole de Pinterest parle et parle maintenant de deux grandes tâches qui utilisent ML-feed (homefeed) et la recherche. L'orateur dit immédiatement que le produit final est le résultat du travail non seulement des scientifiques des données, mais aussi des ingénieurs et programmeurs ML - des personnes ont été affectées à chacun d'eux.
La bande (la situation où il n'y a aucune intention de l'utilisateur) est construite selon le modèle suivant:
- Nous comprenons l'utilisateur - nous utilisons les informations du profil, du graphique, de l'interaction avec les broches (que j'ai vu que j'ai lancées), nous construisons des incorporations en fonction du comportement et des attributs.
- Nous comprenons le contenu - nous le regardons sous tous ses aspects: visuel, textuel, qui est l'auteur, quels conseils participent, qui réagit. Il est très important de se rappeler que les gens sur une image voient souvent des choses différentes: quelqu'un a un accent bleu dans la conception, quelqu'un a une cheminée et quelqu'un a une cuisine.
- Mettre tout cela ensemble - une procédure en trois étapes: nous générons des candidats (recommandations + abonnements), personnalisons (en utilisant le modèle de classement) et mélangeons selon les politiques et les règles métier.
Pour les recommandations, ils utilisent une marche aléatoire sous le graphique des broches de la carte utilisateur, ils présentent PinSage, dont ils ont parlé
hier . La personnalisation a évolué du tri temporel, à travers un modèle linéaire et le GBDT vers un réseau neuronal (depuis 2017). Lors de la collecte de la liste finale, il est important de ne pas oublier les règles métier: fraîcheur, variété, filtres supplémentaires. Nous avons commencé avec l'heuristique, nous nous dirigeons maintenant vers le modèle d'optimisation du contexte dans son ensemble en ce qui concerne les objectifs.
Dans une situation de recherche (quand il y a une intention), ils se déplacent un peu différemment: ils essaient de mieux comprendre l'intention. Pour ce faire, utilisez les techniques de compréhension et d'expansion des requêtes, et l'extension est effectuée non seulement par auto-complétion, mais via une belle navigation visuelle. Ils utilisent différentes techniques pour travailler avec des images et des textes. Nous avons commencé en 2014 sans apprentissage en profondeur, lancé la recherche visuelle avec apprentissage en profondeur en 2015, ajouté en 2016 la détection d'objets avec l'analyse sémantique et la recherche, récemment lancé le service Lens - vous pointez la caméra du smartphone vers le sujet et obtenez des épingles. Dans l'apprentissage en profondeur, ils utilisent activement plusieurs tâches: il existe un bloc commun qui construit l'intégration de l'image. et d'autres réseaux pour résoudre différents problèmes.
En plus de ces tâches, ML est beaucoup plus utilisé où: notifications / publicité / spam / prévisions, etc.
Un peu sur les leçons apprises:
- Nous devons nous souvenir des biais, l'un des «riches s'enrichissant» les plus dangereux (la tendance de l'apprentissage automatique à transférer le trafic vers des objets déjà populaires).
- Il est obligatoire de tester et de surveiller: l'implémentation de la grille a d'abord fortement effondré tous les indicateurs, puis il s'est avéré qu'en raison de la distribution des bogues, les fonctionnalités avaient longtemps dérivé et des vides sont apparus en ligne.
- L'infrastructure et la plate-forme sont très importantes, avec un accent particulier sur la commodité et la parallélisation des expériences, mais vous devez pouvoir interrompre les expériences hors ligne.
- Métriques et compréhension: hors ligne ne garantit pas en ligne, mais pour l'interprétation des modèles, nous faisons des outils.
- Construire un écosystème durable: à propos du filtre à ordures et des appâts cliquables, assurez-vous d'ajouter des commentaires négatifs à l'interface utilisateur et au modèle.
- N'oubliez pas d'avoir une couche pour incorporer des règles métier.
Graphique de connaissances étendues d'Amazon
Maintenant, une
fille d'Amazon joue.
Il existe des graphiques de connaissances - nœuds d'entité, bords d'attributs, etc. - qui sont créés automatiquement, par exemple, sur Wikipédia. Ils aident à résoudre de nombreux problèmes. Nous aimerions obtenir une chose similaire pour les produits, mais il y a beaucoup de problèmes avec cela: il n'y a pas de données d'entrée structurées, les produits sont dynamiques, il y a beaucoup d'aspects qui ne correspondent pas au modèle de graphique des connaissances (c'est discutable, à mon avis, plutôt "ne mentez pas sans une complication sérieuse de la structure "), Beaucoup de verticales et" entités sans nom. " Lorsque le concept a été "vendu" à la direction et a reçu le feu vert, les développeurs ont déclaré qu'il s'agissait d'un "projet de cent ans" et, par conséquent, ils ont réussi en 15 mois-hommes.
Nous avons commencé par extraire des entités du répertoire Amazon: il y a une sorte de structure ici, bien qu'elle soit externalisée et sale. Ensuite, ils ont connecté OpenTag (décrit plus en détail hier) pour le traitement de texte. Et le troisième composant était Ceres - un outil d'analyse syntaxique à partir du Web, prenant en compte l'arborescence DOM. L'idée est qu'en annotant l'une des pages du site, vous pouvez facilement analyser le reste - après tout, tous sont générés par un modèle (mais il existe de nombreuses nuances). Pour ce faire, nous avons utilisé le système de balisage Vertex (acheté par Amazon en 2011) - ils y font du balisage, basé sur lui, un ensemble de xpath est créé pour isoler les attributs, et la régression logistique détermine ceux qui sont applicables dans une page particulière. Pour fusionner les informations de différents sites, utilisez une forêt aléatoire. Ils utilisent également une formation active, des pages complexes sont envoyées pour un nouveau marquage manuel. En fin de compte, ils effectuent un nettoyage supervisé des connaissances - un simple classificateur, par exemple, une marque / pas une marque.
Ensuite, un peu pour la vie. Ils distinguent deux types d'objectifs. Roofshots sont les objectifs à court terme que nous atteignons en déplaçant le produit, et Moonshots sont les objectifs que nous repoussons les limites et le leadership mondial.
Intégrations et représentants
Après le déjeuner, je suis allé à la section sur la façon de construire des intégrations, principalement pour les graphiques.
Trouver des exercices similaires avec une représentation sémantique unifiée
Les gars
résolvent le problème de trouver des tâches similaires dans un système d'apprentissage en ligne chinois. Les affectations sont décrites par du texte, des images et un ensemble de cônes associés. La contribution des développeurs est de rassembler les informations de ces sources. Les circonvolutions sont faites pour les images, les encastrements sont formés pour les concepts, et les mots aussi. Les incorporations de mots sont transmises au LSTM basé sur l'attention avec des informations sur les concepts et les images. Obtenez une représentation du travail.

Le bloc décrit ci-dessus est transformé en un réseau siamois, dans lequel l'attention est également ajoutée et en sortie un score de similitude.
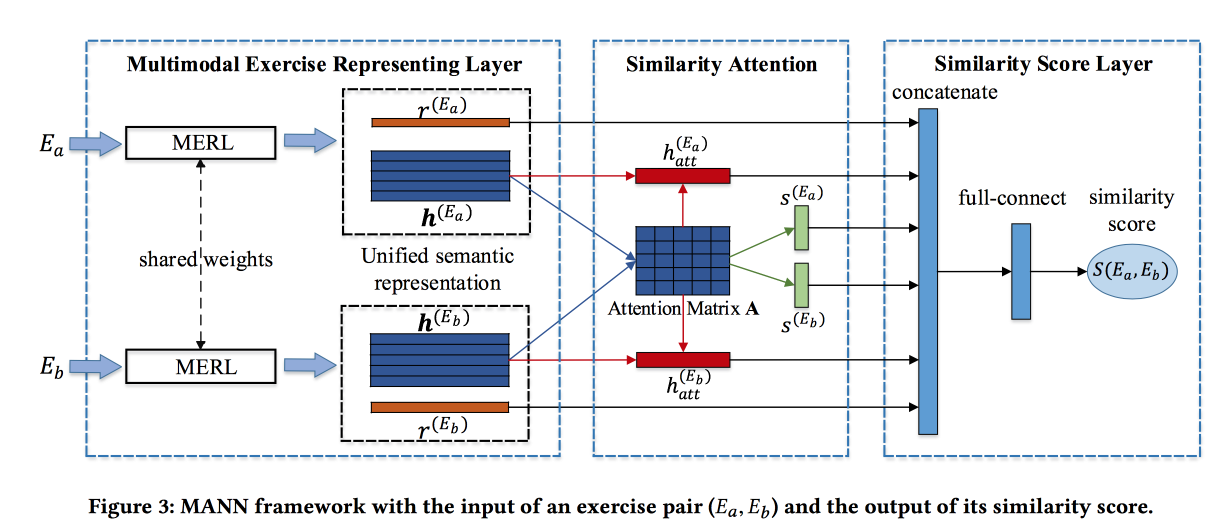
Ils enseignent sur un ensemble de données marqué de 100 000 exercices et 400 000 paires (un total de 1,5 million d'exercices). Ajoutez un négatif dur en échantillonnant des exercices avec les mêmes concepts. Les matrices d'attention peuvent ensuite être utilisées pour interpréter la similitude.
Incorporation de réseau préservé de proximité d'ordre arbitraire
Les gars
construisent une variante très intéressante des plongements pour les graphiques. Premièrement, les méthodes basées sur les marches et sur la base des voisins sont critiquées pour se focaliser sur la «proximité» d'un certain niveau (correspondant à la durée de la marche). Ils proposent une méthode qui prend en compte la proximité de l'ordre souhaité, et avec des poids contrôlés.
L'idée est très simple. Prenons une fonction polynomiale et appliquons-la à la matrice d'adjacence du graphe, et nous factorisons le résultat par SVD. Dans ce cas, le degré d'un membre particulier du polynôme est le niveau de proximité, et le poids de ce membre est l'influence de ce niveau sur le résultat. Naturellement, cette idée folle n'est pas réalisable: après avoir élevé la matrice d'adjacence à une puissance, elle devient plus dense, ne rentre pas dans la mémoire et vous factorisez une telle fig.
Sans mathématiques, ce sont des déchets, car si vous appliquez la fonction polynomiale au résultat APRÈS l'expansion, nous obtenons exactement la même chose que si l'expansion était appliquée à une grande matrice. En fait, pas vraiment. Nous considérons SVD approximativement et ne laissons que les valeurs propres les plus élevées, mais après avoir appliqué le polynôme, l'ordre des valeurs propres peut changer, vous devez donc prendre des nombres avec une marge.

L'algorithme séduit par sa simplicité et montre des résultats étonnants dans la tâche de prédiction de lien.

NetWalk: une approche flexible d'enrobage profond pour la détection d'anomalies dans les réseaux dynamiques
Comme son nom l'indique,
nous construirons les intégrations
du graphique en fonction des promenades. Mais pas seulement, mais en mode streaming, puisque nous résolvons le problème de la recherche d'anomalies dans les réseaux dynamiques (il y avait du travail sur ce sujet hier). Afin de lire et de mettre à jour rapidement les encastrements, ils utilisent le concept de «
réservoir », dans lequel se trouve un échantillon du graphique et est mis à jour stochastiquement lorsque des modifications sont reçues.
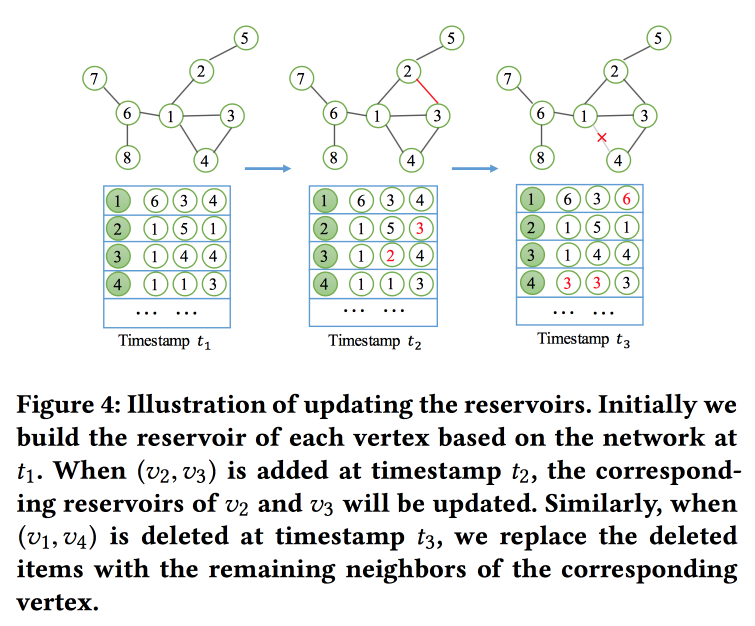
Pour la formation, ils formulent une tâche assez compliquée avec plusieurs objectifs, les principaux étant la proximité des intégrations pour les nœuds dans un chemin et les erreurs minimales lors de la restauration du réseau avec un auto-encodeur.
Incorporation d'un réseau conscient de la taxonomie hiérarchique
Une autre
option pour construire des incorporations pour un graphique, cette fois basée sur un modèle de génération probabiliste. La qualité des plongements est améliorée en utilisant des informations provenant d'une taxonomie hiérarchique (par exemple, un domaine de connaissances pour les réseaux de citation ou une catégorie de produits pour les produits dans e-tail). Le processus de génération est construit sur certains "sujets", dont certains sont liés à des nœuds dans une taxonomie, et certains à un nœud spécifique.
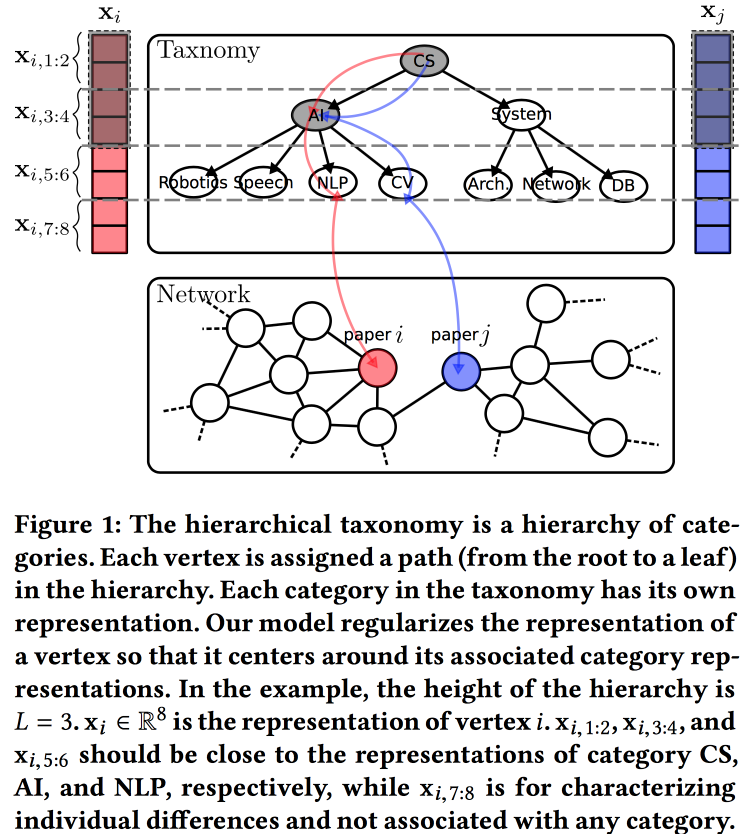
Nous associons la distribution normale a priori à une moyenne nulle aux paramètres de la taxonomie, aux paramètres d'un sommet particulier dans la taxonomie - la distribution normale à la moyenne égale au paramètre de taxonomie, et la distribution normale à la moyenne nulle et à la dispersion infinie pour les paramètres libres du sommet. Nous générons l'environnement du sommet en utilisant la distribution de Bernoulli, où la probabilité de succès est proportionnelle à la proximité des paramètres des nœuds. Nous optimisons l'ensemble de ce colosse avec l'
algorithme EM .
Intégration réseau récursive profonde avec équivalence régulière
Les techniques d'intégration courantes ne fonctionnent pas pour toutes les tâches. Par exemple, considérez le rôle d'une tâche de nœud. Pour déterminer le rôle, ce ne sont pas les voisins spécifiques (qui sont généralement examinés) qui sont importants, mais la structure du graphe au voisinage du sommet et certains motifs qui s'y trouvent. Dans le même temps, il est très difficile de rechercher algorithmiquement directement ces modèles (équivalence régulière), mais pour les grands graphiques, cela n'est pas réaliste.
Par conséquent, nous irons dans l'
autre sens . Pour chaque nœud, nous calculons les paramètres associés à son graphe: degré, densité, différentes centralités, etc. Les incorporations ne peuvent pas être construites uniquement sur elles, mais la récursivité peut être utilisée, car la présence du même modèle implique que les attributs des voisins de deux nœuds avec le même rôle doivent être similaires. Ce qui signifie que vous pouvez empiler plus de couches.
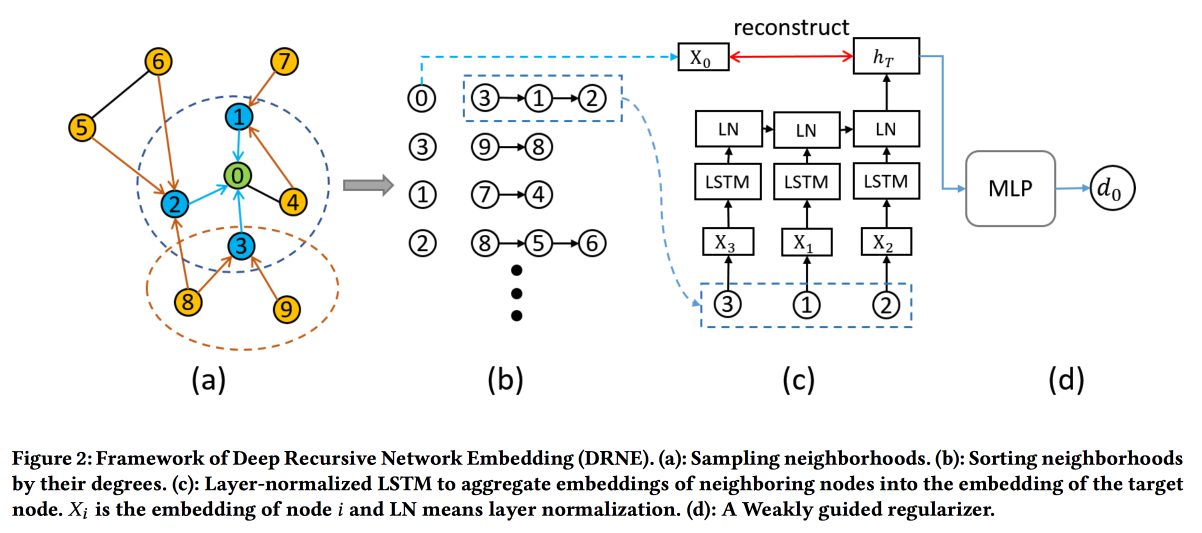
Les validations montrent qu'ils contournent les lignes de base standard de DeepWalk et node2wek sur de nombreuses tâches.
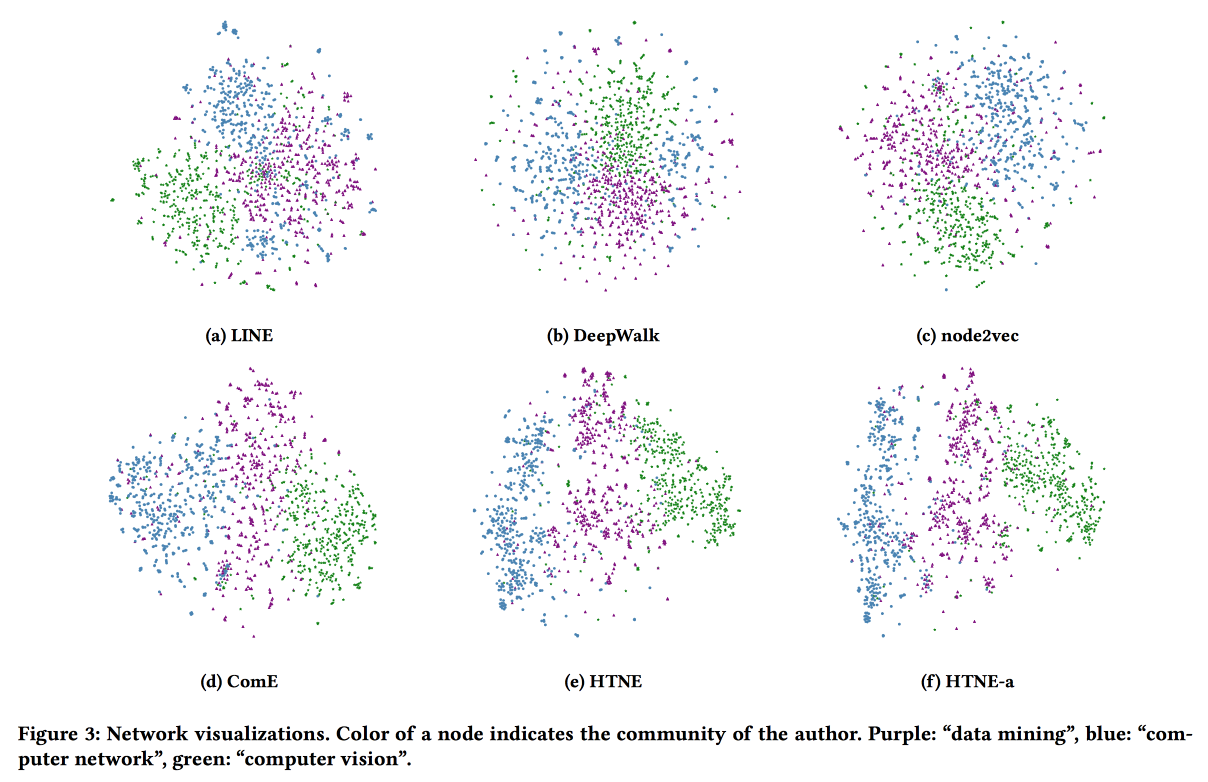
Intégration du réseau temporel via la formation de quartier
Le dernier travail d'intégration de graphique pour aujourd'hui. Cette fois, nous examinerons la dynamique: nous évaluerons à la fois le moment de la connexion et tous les faits d'interaction dans le temps. Prenons l'exemple du réseau de citation, où l'interaction est une publication conjointe.
Nous utilisons le processus de Hawkes pour modéliser comment les interactions des vertex passées affectent leurs interactions futures. HP . attention . log likelihood . .
Safety
. , . , ML , , .
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
: , , — . , . , ( - , ), 1-2 % . ,
.
data miner-
Data Science for Social Good . , , :

, . : , GBDT. -1 % .
base line-: « » , , « , » . ML, , .
27 32- , , , ( , — ). , $1,2 .
, , , 1940-, , ( ) .
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
NASA
( ). — . , . , .
ML . LSTM , . ( , ). , , . , . , .
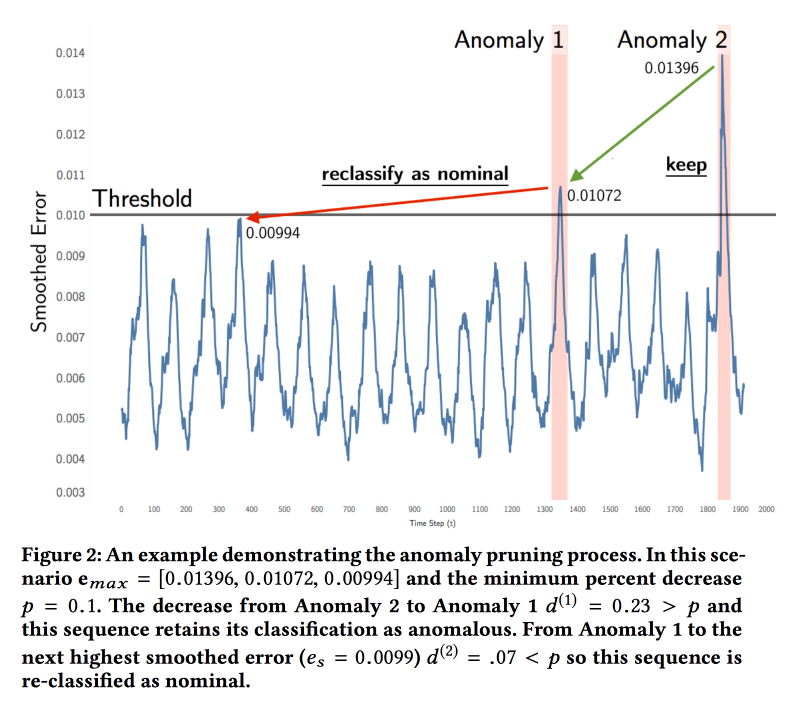
:
soil moisture active passive Curiosity c Mars Science Laboratory. 122 , 80 %. , , . , , .
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
, , . Safety Incidents, , . , . .
, - , . «», .. , . , , . , , .
GRU ,
Multiple Instances Learning . , «» — , . « , , — » ( = ). max pooling .

cross entropy loss . base line
MI-SVM ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
, ,
.
. 120 . , 2013 , : . , 2014-. 2015- — . , . , …
— , . , . .
. «», . : , , , . , , — , …
6 . , 20 %. data scientist-.
, 19 , , , . , « ». , , XGBoost - . ( 7 % , ).
Les autorités n'ont pas osé creuser de modèles selon les prévisions, mais elles ont donné aux gars une pompe à impuretés, qui pouvait atteindre les tuyaux avec relativement peu de dommages afin de vérifier s'il y avait du cuivre ou du plomb. Avec cette machine, les gars ont commencé à pratiquer "l'apprentissage actif" et étaient convaincus de l'efficacité du modèle. Après avoir analysé les données rétrospectivement, nous avons considéré que l'utilisation du modèle dans un format d'apprentissage actif réduirait le dépassement des coûts de 16% à 3%. En outre, ils ont noté que dans le processus d'interaction avec les scientifiques, les autorités avaient considérablement amélioré leur attitude envers les données - au lieu de dépliants et de comprimés dispersés, un portail normal est apparu dans Excel pour surveiller le processus de remplacement du système d'approvisionnement en eau.
Après avoir analysé les données rétrospectivement, nous avons considéré que l'utilisation du modèle dans un format d'apprentissage actif réduirait le dépassement des coûts de 16% à 3%. En outre, ils ont noté que dans le processus d'interaction avec les scientifiques, les autorités avaient considérablement amélioré leur attitude envers les données - au lieu de dépliants et de comprimés dispersés, un portail normal est apparu dans Excel pour surveiller le processus de remplacement du système d'approvisionnement en eau.Un pipeline dynamique pour la prévision des risques d'incendie spatio-temporels
En conclusion, un autre point sensible est l'inspection incendie. À propos de ce qui se passe si elles ne sont pas réalisées, nous avons appris en mars 2018. Aux États-Unis, de tels cas ne sont pas rares non plus. En même temps, les ressources pour l'inspection des pompiers sont limitées, elles doivent être dirigées vers les endroits les plus à risque.
Il existe des modèles ouverts pour évaluer le risque d'incendie, mais ils sont conçus pour les incendies de forêt et ne conviennent pas à la ville. Il existe une sorte de système à New York, mais il est fermé. Donc, vous devez essayer
de créer le vôtre .
En collaboration avec les pompiers de Pittsburgh, les garçons ont collecté des données sur les incendies sur plusieurs années, ajouté des informations sur la démographie, les revenus, les formes d'entreprise, etc., ainsi que d'autres appels au service d'incendie qui ne sont pas liés aux incendies. Et ils ont essayé d'évaluer le risque d'incendie sur la base de ces données.
Deux modèles XGBoost différents sont enseignés: pour les ménages et l'immobilier commercial. La qualité du travail a été évaluée, tout d'abord, selon
Kappa compte tenu du fort déséquilibre des classes.
L'ajout de facteurs dynamiques (appels au service d'incendie, déclenchement de détecteurs / alarmes) au modèle a considérablement amélioré la qualité, mais pour les utiliser, le modèle a dû être recompté chaque semaine. Sur la base des prévisions, les modèles ont créé une muselière Web agréable pour les inspecteurs des incendies montrant où se trouvent les objets les plus à risque.
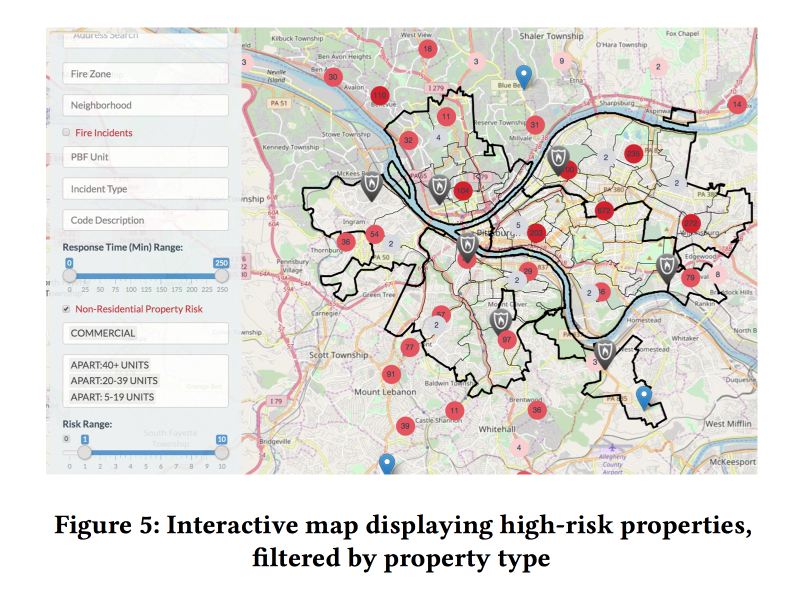
L'importance des symptômes a été analysée. Parmi les caractéristiques importantes pour le commerce, il y avait les fausses alarmes (apparemment, l'arrêt va plus loin). Mais pour les ménages - le montant des impôts payés (Hi Fairness, les inspections incendie dans les zones pauvres iront plus souvent).