Il y a quelque temps, j'ai activé un essai gratuit sous Google pour leur cloud, je n'ai pas résolu mon problème, il s'est avéré que Google donne 300 $ pour 12 mois dans le cadre de l'essai, mais contrairement à mes attentes, d'autres limites sont imposées en plus de la limite budgétaire. Par exemple, je n'ai pas autorisé l'utilisation de machines virtuelles avec plus de 8 processeurs virtuels dans une région. Après six mois, j'ai décidé d'utiliser le budget d'essai pour me familiariser avec dataproc, un cluster hadup préinstallé de Google. La tâche consiste à essayer d'évaluer à quel point il serait facile pour moi de lancer un projet sur l'accès de Google, qu'il soit logique ou préférable de se concentrer immédiatement sur mon matériel et de réfléchir à l'administration. J'ai le vague sentiment que le matériel moderne et la pile de bigdata devraient facilement s'adapter à de petites bases de données de dizaines ou de centaines de Go, chargeant brutalement, sinon l'ensemble complet de données, puis la grande majorité dans la mémoire du cluster. Certaines sous-données distinctes pour les data marts peuvent ne plus être nécessaires.
En bref, dataproc a été impressionné par la facilité de lancement et de paramétrage, par rapport à Oracle et Cloudera. À la première étape, j'ai joué avec un cluster de nœuds sur 8 vCpu, dont le maximum permet un essai totalement gratuit. Si vous regardez la simplicité, leurs technologies permettent déjà à un hindou de démarrer un cluster en 15 minutes, de charger des exemples de données et de préparer des rapports à l'aide d'un outil de BI classique, sans sous-fenêtres intermédiaires. Une connaissance approfondie de Hadoup n'est plus du tout requise.
En principe, j'ai vu que la chose est merveilleuse pour un démarrage rapide et pour un argent raisonnable, vous pouvez exécuter un prototype, évaluer le type de matériel dont vous avez besoin pour une tâche. Cependant, un cluster plus important, dans des dizaines de nœuds, mangera évidemment beaucoup plus qu'une location + quelques administrateurs qui regardent le cluster. Loin du fait que le cloud sera économiquement viable. La première étape, j'ai essayé d'évaluer une option entièrement micro avec un cluster de nœuds 8 vCpu et 0,5 To de données brutes. En principe, les tests spark + hadoop sur des clusters plus importants sont déjà complets sur Internet, mais je prévois de tester l'option un peu plus tard.
En seulement une heure, j'ai googlé des scripts pour créer une sauvegarde de cluster, configurer son pare-feu et configurer un serveur d'épargne, ce qui a permis à jdbc de se connecter à spark sql à partir de Windows domestique. J'ai passé encore deux ou trois heures à optimiser les paramètres d'allumage par défaut et à charger quelques petites tables d'environ 10 Go (la taille des fichiers de données dans Oracle). J'ai poussé toutes les tables en mémoire (alter table cache;) et il était possible de travailler avec elles depuis ma machine Windows depuis Dbeaver et Tableau (via le connecteur spark sql).
Par défaut, spark n'a utilisé qu'un seul exécuteur sur 4 vCpu, j'ai édité spark-defaults.conf, installé 3 exécuteurs, 2 vCpu chacun et pendant longtemps je ne pouvais pas comprendre pourquoi je n'avais vraiment qu'un seul exécuteur dans mon travail. Il s'est avéré que je n'ai pas édité la mémoire, les deux autres fils n'ont tout simplement pas pu allouer de mémoire. J'ai mis 6,5 Go sur l'exécuteur, après quoi les trois ont commencé à augmenter comme prévu.
Ensuite, j'ai décidé de jouer avec un volume légèrement plus sérieux et une tâche plus proche de DWH à partir des tests TPC-DS. Pour commencer, j'ai généré officiellement des tableaux avec un facteur d'échelle 500 de l'outil officiel. J'ai obtenu quelque chose comme 480 Go de données brutes (texte délimité). Le test TPC-DS est un DWH typique, avec des faits et des dimensions. Je ne comprenais pas comment générer des données directement sur le stockage google, je devais générer des machines virtuelles sur le disque puis les copier sur le stockage google. Google, si je comprends bien, estime que le capot fonctionne parfaitement avec le stockage Google et que la vitesse y est un peu meilleure que si les données étaient à l'intérieur du cluster sur HDFS. Dans ce cas, une partie de la charge passe de HDFS au stockage Google.
Une fois connecté via Dbeaver, j'ai converti les fichiers texte en tablettes à base de parquet avec un emballage accrocheur à l'aide de commandes SQL. 480 Go de données texte regroupées dans des fichiers parquet de 187 Go. Le processus a pris environ deux heures, la plus grande table du texte occupait 188 Go, 3 exécuteurs d'étincelles les ont transformés en parquet en 74 minutes, la taille du SUV était de 66,8 Go. Sur mon bureau avec environ le même 8 vCpu (i7-3770k), je pense que "insérer dans la table select * ..." dans une table Oracle avec un bloc de 8k prendrait une journée, et combien le fichier de données prendrait est même effrayant à imaginer.
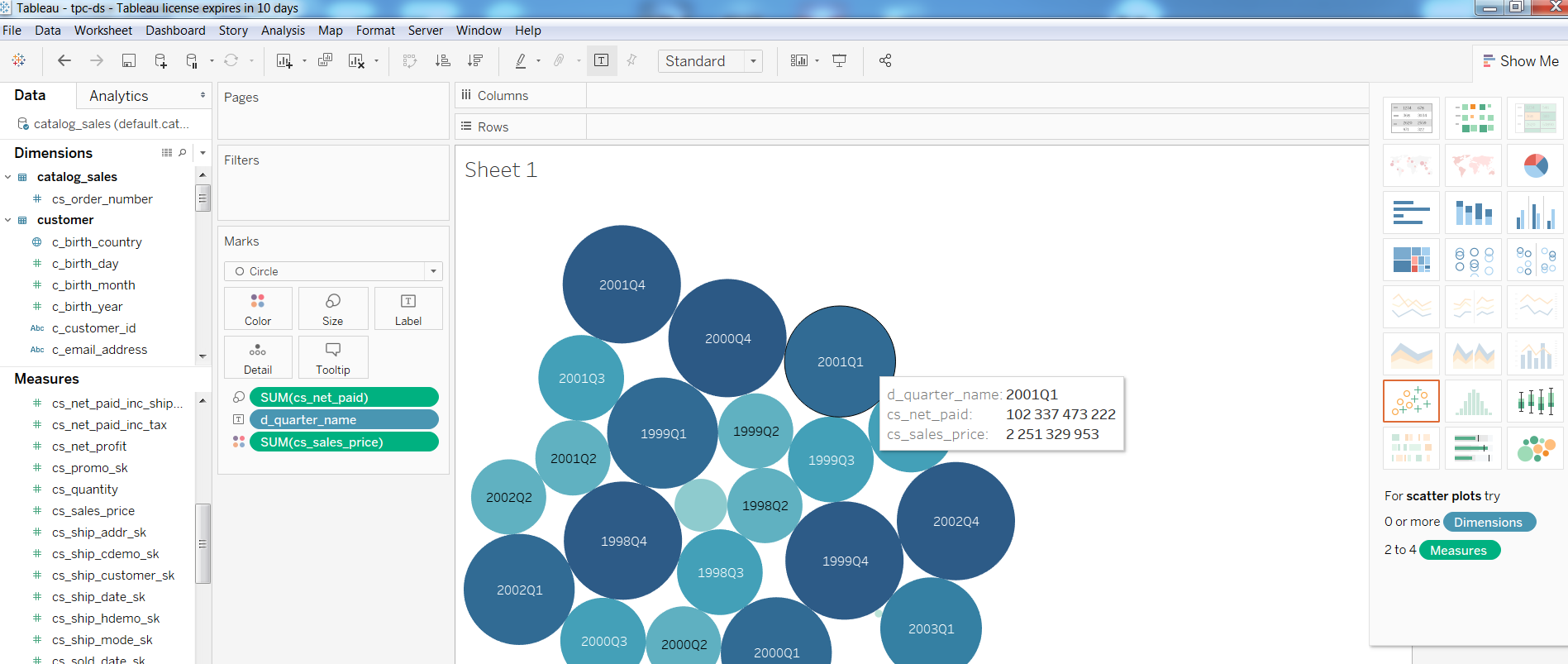
Ensuite, j'ai vérifié les performances des outils de BI sur une telle configuration, construit un rapport simple dans Tableua
Quant aux requêtes, Query1 du test TPC-DS
Requête1WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;
complété en 1:08, Query2 avec la participation des plus grandes tables (catalog_sales, web_sales)
Requête2 WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1;
terminé en 4:33 minutes, Query3 en 3.6, Query4 en 32 minutes.
Si quelqu'un est intéressé par les paramètres, sous la coupe mes notes sur la création d'un cluster. En principe, il n'y a que quelques commandes gcloud et le paramètre HIVE_SERVER2_THRIFT_PORT.
Remarquesune option de cluster de nœuds:
gcloud dataproc - les clusters region europe-north1 créent test1 \
--sous-réseau par défaut \
- ruban de seau1 \
--zone europe-nord1-a \
--single-node \
--master-machine-type n1-highmem-8 \
--master-boot-disk-size 500 \
--image-version 1.3 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projet 123
option pour 3 nœuds:
gcloud dataproc - clusters région europe-nord1 \
create cluster-test1 --bucket tape1 \
--subnet default --zone europe-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-workers 2 \
--worker-machine-type n1-standard-1 --worker-boot-disk-size 10 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projet 123
gcloud compute --project = 123 \
les règles de pare-feu créent allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--source-gammes = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
au nœud maître:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
changement: exportation HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
À suivre ...