
Le cinquième, dernier jour de KDD s'est donc terminé. J'ai réussi à entendre des rapports intéressants de Facebook et de Google AI, à me souvenir des tactiques du football et à générer des produits chimiques. À ce sujet et pas seulement - sous la coupe. Rendez-vous dans un an à Anchorage, la capitale de l'Alaska!
Sur l'apprentissage du Big Data pour les problèmes de petites données
Le rapport du matin du
professeur chinois était difficile. L'orateur a été clairement chargé pendant la préparation, s'est souvent égaré, a commencé à sauter des diapositives et, au lieu de parler pour la vie, a essayé de charger le cerveau endormi de mathématiques.
Le contour général de l'histoire tournait autour de l'idée qu'il y a loin de toujours beaucoup de données. Il y a, par exemple, une longue queue dans laquelle il existe de nombreux exemples divers. Il existe des ensembles de données avec un grand nombre de classes qui, bien que grandes en elles-mêmes, n'ont que quelques enregistrements pour chaque classe. Comme exemple d'un tel ensemble de données, il a cité
Omniglot - des caractères manuscrits de 50 alphabets, 1623 classes et 20 images par classe en moyenne. Mais en fait, dans cette perspective, vous pouvez également considérer des ensembles de données de tâches de recommandation, lorsque nous avons beaucoup d'utilisateurs et pas tellement de notes pour chacun d'eux individuellement.
Que peut-on faire pour faciliter la vie de ML dans une telle situation? Tout d'abord. essayez d'y apporter des connaissances de la matière. Cela peut se faire sous différentes formes: il s'agit de l'ingénierie des fonctionnalités, de la régularisation spécifique et du raffinement de l'architecture du réseau. Une autre solution courante est l'apprentissage par transfert, je pense que presque tous ceux qui ont travaillé avec des images ont commencé par mettre à niveau ImageNet à partir de leurs données. Dans le cas d'Omniglot, le donneur naturel pour le transfert sera le
MNIST .
Une forme de transfert peut être l'
apprentissage multi-tâches , dont KDD a été évoqué à plusieurs reprises. Le développement de MTL peut être considéré comme l'approche du
méta-apprentissage - en entraînant l'algorithme sur des échantillons de diverses tâches, nous pouvons APPRENDRE non seulement des paramètres, mais aussi des hyperparamètres (bien sûr, seulement si notre procédure est différenciable).
Poursuivant le sujet du multitâche, nous pouvons arriver au concept d'apprentissage continu tout au long de la vie, qui peut être le plus clairement illustré par l'exemple de la robotique. Le robot doit être capable de résoudre différents problèmes et, lorsqu'il apprend une nouvelle tâche, d'utiliser l'expérience précédente. Mais vous pouvez envisager cette approche avec l'exemple d'Omniglot: après avoir appris l'un des personnages, vous pouvez passer à l'apprentissage du suivant, en utilisant l'expérience accumulée. Certes, un dangereux problème d'
oubli catastrophique nous attend sur cette voie, lorsque l'algorithme commence à oublier ce qu'il a appris auparavant (conseille de régulariser le
CEE pour lutter contre cela).
En outre, l'orateur a évoqué plusieurs de ses travaux dans ce sens.
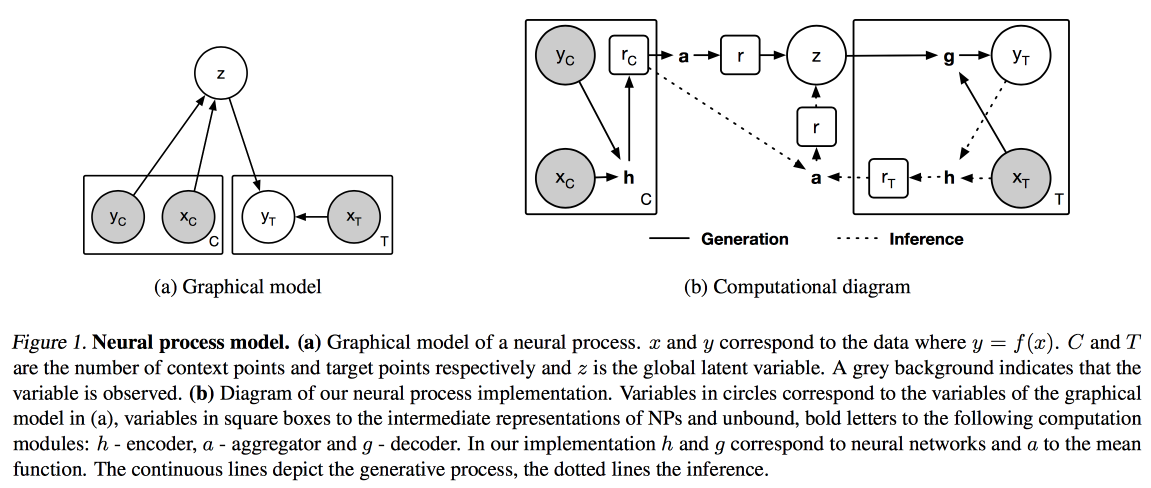
Processus neuronaux (une analogie du processus gaussien pour les réseaux de neurones) et
apprentissage par distillation et transfert (optimisation de l'apprentissage par transfert dans le cas où nous ne prenons pas comme modèle un modèle préalablement formé, mais formons le nôtre en mode multitâche).
Images et textes
Aujourd'hui, j'ai décidé de marcher sur des rapports appliqués, le matin sur le travail avec des textes, des images et des vidéos.
Service de conversion de corpus
La fréquence des publications augmente très rapidement, il est difficile de travailler avec cela, surtout compte tenu du fait que presque toute la recherche est effectuée dans le texte. IBM
propose ses services de marquage des boîtiers Scientific Knowledge 3.0. Le flux de travail principal ressemble à ceci:
- Parsim PDF, reconnaître le texte dans les images.
- On vérifie s'il existe un modèle pour cette forme de texte, si c'est le cas, on en fait un extrait sémantique.
- S'il n'y a pas de modèle, nous envoyons pour annotation et train.
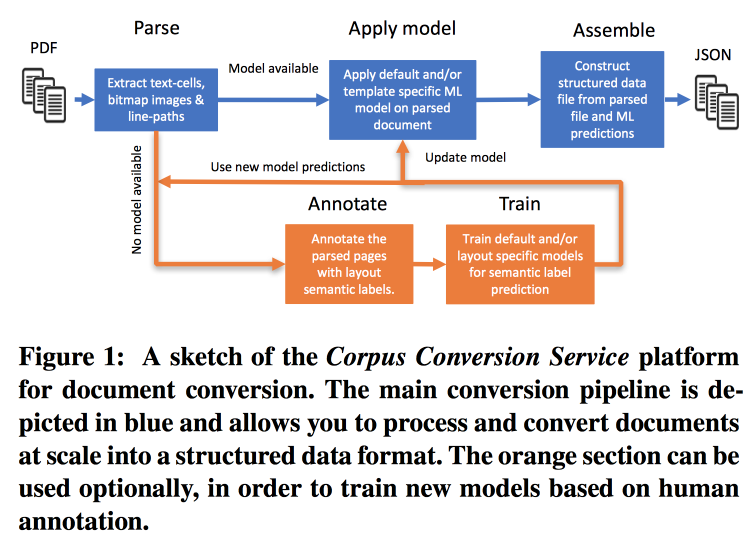
Pour former des modèles, nous commençons par regrouper par structure. Au sein d'un cluster utilisant le crowdsourcing, nous mettons en page plusieurs pages. Il s'avère atteindre une précision> 98% lors de la formation sur le marquage de 200 à 300 documents. Il y a un fort déséquilibre de classe dans le balisage (presque tout est marqué comme du texte), vous devez donc regarder la précision de toutes les classes et la matrice de confusion.
Les modèles ont une structure hiérarchique. Par exemple, un modèle reconnaît un tableau et les autres découpent en lignes / colonnes / en-têtes (et oui, un tableau peut être imbriqué dans un tableau). Comme modèle, un réseau convolutionnel est utilisé.
Pour tout cela, ils ont assemblé un convoyeur sur Docker avec Kubernetes et sont prêts à télécharger votre corpus de texte pour un prix raisonnable. Ils peuvent fonctionner non seulement avec du texte PDF, mais aussi avec des numérisations; ils prennent en charge les langues orientales. En plus de simplement extraire le texte, ils travaillent à l'extraction du graphe de connaissances, ils promettent de donner les détails sur le prochain KDD.
Expansion de requêtes rares par le biais de réseaux contradictoires génératifs dans la publicité de recherche
Les moteurs de recherche tirent le plus d'argent de la publicité, et la publicité est affichée en fonction de ce que recherche l'utilisateur. Mais la comparaison n'est pas toujours évidente. Par exemple, à la demande de billets d'avion, afficher des publicités de billets de bus bon marché n'est pas très correct, mais Expedia fera bien l'affaire, mais vous ne pouvez pas le comprendre par mots clés. Les modèles d'apprentissage automatique peuvent aider, mais ils ne fonctionnent pas bien avec des requêtes rares.
Pour résoudre ce problème, pour développer la requête de recherche,
nous allons former le GAN conditionnel selon le modèle de séquence à séquence. Nous utilisons des réseaux récurrents (GRU 2 couches) comme architecture. Nous modifions min-max de GAN, en essayant de l'ajouter à des mots clés pour lesquels il y a eu des clics sur les annonces.
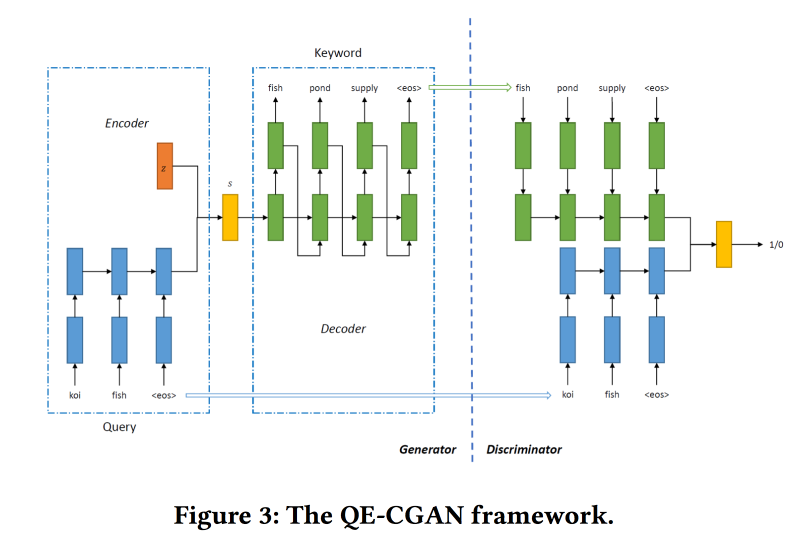
Ensemble de données pour la formation sur 14 millions de requêtes et 4 millions de mots clés publicitaires. Le modèle proposé fonctionne mieux sur la longue queue de la demande, pour laquelle il a été fait. Mais dans la tête, les performances ne sont pas plus élevées.
Apprentissage collaboratif des métriques approfondies pour la compréhension de la vidéo
Le travail est présenté par les gars de Google AI. Ils veulent créer de bonnes intégrations vidéo, puis les utiliser dans des vidéos similaires, des recommandations, des annotations automatiques, etc. Cela fonctionne comme suit:
- À partir de la vidéo, nous échantillonnons des images - une image et un morceau de la piste audio.
- Nous extrayons des fonctionnalités des images que Inception a précédemment apprises.
- Nous faisons de même avec le fragment audio (l'architecture réseau spécifique n'a pas été montrée). Sur les signes obtenus, nous accrochons des mailles entièrement connectées en tirant par des cadres. Nous normalisons par L2.
- Ensuite, un point intéressant - nous essayons de nous assurer que des vidéos similaires sont proches en termes de similitude collaborative. Pour ce faire, nous utilisons la perte de triplets dans la formation (nous prenons un objet, l'échantillonnons de manière similaire et dissemblable, nous nous assurons que les plongements du dissemblable sont plus éloignés de l'original que du similaire). N'oubliez pas que vous devez utiliser un minage négatif.

Ils sont utilisés pour un démarrage à froid dans des vidéos similaires, mais il y a quelques problèmes: par similitude visuelle, ils peuvent trouver des vidéos dans une autre langue ou des vidéos sur un sujet différent (particulièrement pertinent pour le format vidéo «tableau et conférencier»). Vous conseille d'utiliser des méta-informations supplémentaires sur la vidéo.
Il y a un problème avec les recommandations: vous devez faire correspondre l'historique de navigation et 5 milliards de vidéos de Youtube. Pour accélérer le travail, nous calculons pour l'utilisateur le vecteur de l'incorporation moyenne des vidéos regardées. Vérifié sur
movielens , pompé les remorques de Youtube pour analyse. Ils ont montré que pour les utilisateurs avec un petit nombre de notes, cela fonctionne mieux.
Dans le problème des annotations vidéo, l'approche du
mélange d'experts est utilisée: ils s'entraînent sur logreg pour l'incorporation pour chaque annotation possible. Vérifié sur
Youtube-8 et a montré un très bon résultat.
Désambiguïsation des noms dans AMiner: regroupement, maintenance et humain dans la boucle
AMiner - un graphique pour l'académie, fournissant divers services pour travailler avec la littérature. Un des problèmes: les collisions de noms d'auteurs et d'entités. Un algorithme automatique avec une certaine forme d'apprentissage actif est
proposé pour la solution.
Le processus se compose de trois étapes: à l'aide d'une recherche de texte, nous collectons des candidats (documents avec des noms d'auteurs similaires), un cluster (avec détermination automatique du nombre de clusters) et construisons des profils.

Pour considérer la similitude dans le clustering, vous avez besoin d'une sorte de présentation (emeding). Il peut être obtenu en utilisant le modèle global (tout au long du graphique) ou local (pour les candidats qui ont échantillonné). Des schémas de captures globaux qui peuvent être transférés dans de nouveaux documents et des aides locales pour prendre en compte les caractéristiques individuelles - nous combinerons. Pour obtenir des intégrations globales, ils utilisent également le réseau siamois formé à la perte de triplets, et pour les réseaux locaux - un encodeur automatique de graphique (j'ai laissé les images dans l'article pour économiser de l'espace).
La question la plus douloureuse est de savoir combien de clusters ai-je? L'approche
X-means ne s'adapte pas à un grand nombre de grappes; RNN est utilisé pour prédire leur nombre: K grappes sont échantillonnées à partir d'un ensemble marqué, puis N exemples de ces grappes. Ils forment le réseau pour révéler le nombre initial de clusters.

Les données arrivent assez rapidement, 500 000 par mois, mais il faut des semaines pour exécuter l'ensemble du modèle. Pour une initialisation rapide, ils utilisent la sélection de candidats pour la recherche de texte et l'IPN pour les intégrations globales. Un point important: les personnes qui marquent ce qui devrait ou ne devrait pas être dans le cluster sont incluses dans le processus d'apprentissage. Sur ces données, le modèle est recyclé.
Rosetta: système à grande échelle pour la détection et la reconnaissance de texte dans les images
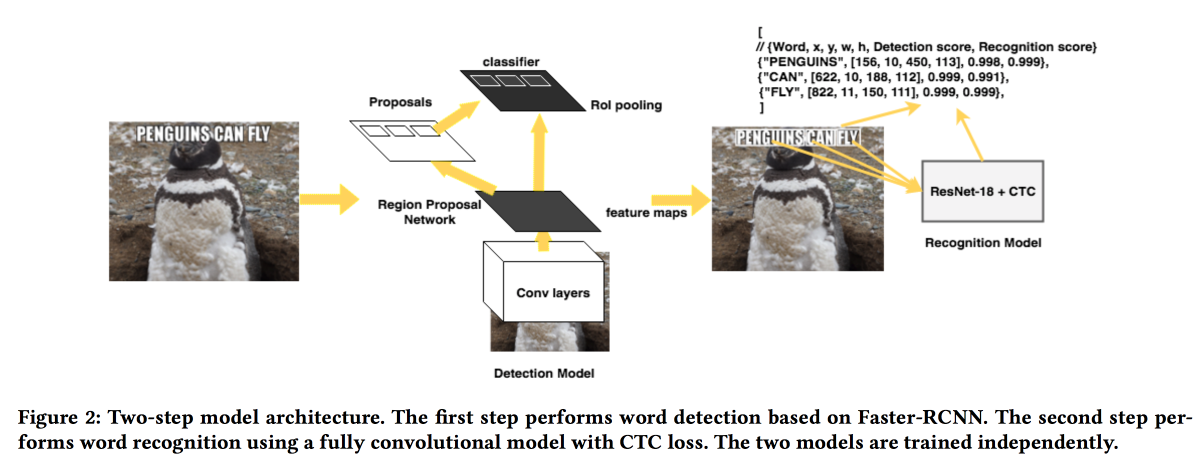
Les gars de FB
présenteront leur solution pour extraire les textes des images. Le modèle fonctionne en deux temps: le premier réseau détermine le texte, le second le reconnaît.
Faster-RCNN a été utilisé comme détecteur avec le remplacement de ResNet par
SuffleNet pour accélérer le travail. Pour la reconnaissance, ils ont utilisé ResNet18 et ont été formés à
la perte de CTC .
Pour améliorer la convergence, nous avons utilisé plusieurs astuces:
- Pendant l'entraînement, un petit bruit a été introduit dans le résultat du détecteur.
- Les textes ont été étirés horizontalement de 20%.
- Utilisation du curriculum utilisé - exemples progressivement compliqués (par le nombre de caractères).
Sciences naturelles
La dernière section de contenu de la conférence était consacrée aux «sciences naturelles». Un peu de chimie, de football et plus encore.
Détection d'effet de traitement hétérogène contrôlée par taux de fausse découverte pour une expérience contrôlée en ligne
Travail très intéressant sur l'analyse des tests A / B. Le problème avec la plupart des systèmes d'analyse est qu'ils examinent l'effet moyen, alors qu'en réalité, le plus souvent, certains utilisateurs réagissent positivement et négativement au changement, et il est possible d'obtenir davantage si vous comprenez à qui s'adresse la fonctionnalité et qui non.

Vous pouvez diviser les utilisateurs en cohortes à l'avance et évaluer l'effet par eux, mais avec une augmentation du nombre de cohortes, le nombre de faux positifs augmente (vous pouvez essayer de les réduire en utilisant la méthode
Bonferoni , mais c'est trop conservateur). De plus, vous devez connaître les cohortes à l'avance. Les gars suggèrent d'utiliser une combinaison de plusieurs approches: combiner le mécanisme de détection d'effet hétérogène (HTE) avec des méthodes de filtrage des faux positifs.
Pour détecter un effet hétérogène, une matrice avec
x=0/1 0/1 (dans le groupe ou non) et l'effet est transformé en une matrice dans laquelle au lieu de
0/1 se trouve le nombre
(x — p)/p(1-p) , où
p est la probabilité d'inclusion dans le test. Ensuite, un modèle pour prédire l'effet de
x (régression linéaire ou lasso) est enseigné. Les utilisateurs pour lesquels le résultat est significativement différent de la prévision sont candidats à la séparation en un effet «hétérogène».
Ensuite, nous avons essayé deux méthodes pour le filtre des faux positifs:
Benjamini-Hochberg et
Knockoffs . Le premier est beaucoup plus facile à mettre en œuvre, mais le second est plus flexible et a montré des résultats plus intéressants.
La malédiction du gagnant: estimation du biais pour les effets totaux des fonctionnalités dans les expériences contrôlées en ligne
Les gars d'AirBnB ont parlé un peu de la façon dont ils ont amélioré le système d'analyse expérimentale. Le principal problème est que lors de l'expérimentation de nombreux biais, nous avons considéré le biais de sélection dans ce travail - nous sélectionnons des expériences avec le meilleur résultat
observé , mais cela signifie que nous sélectionnerons plus souvent des expériences dans lesquelles le résultat observé est trop élevé par rapport au réel.
Par conséquent, lors de la combinaison d'expériences, l'effet final est inférieur à la somme des effets des expériences. Mais connaissant ce biais, vous pouvez essayer de l'évaluer et de le soustraire à l'aide de l'appareil statistique (en supposant que la différence entre les effets réels et observés est distribuée normalement). En bref, quelque chose comme ça:

Et si vous ajoutez du
bootstrap , vous pouvez même créer des intervalles de confiance pour une estimation impartiale de l'effet.
Découverte automatique des tactiques dans les données de matchs de football spatio-temporels
Travail intéressant sur la divulgation des tactiques des équipes de football. Les données de match sont disponibles sous forme de séquences d'actions (passe / toucher / coup, etc.), environ 2000 actions par match. Combinez des attributs continus (coordonnées / temps) et discrets (joueur). Il est important d'élargir les données en utilisant la connaissance du sujet (ajoutez le rôle du joueur et le type de passe, par exemple), mais cela ne fonctionne pas toujours. En outre, différents types d'utilisateurs sont intéressés par différents types de modèles: entraîneurs - réussis, attaquant - défensif, journaliste - unique.
La méthode proposée est la suivante:
- Divisez le flux en phases pour la transition du ballon entre les équipes.
- Phases de cluster utilisant la distorsion temporelle dynamique comme distance. Comment déterminer le nombre de clusters, pas dit.
- Nous classons les clusters par objectif (pour lesquels nous recherchons des tactiques).
- Minimisez les motifs à l'intérieur du cluster (extraction séquentielle de motifs CM-SPADE ), nous désertons les coordonnées en fonction des segments de champ (flanc gauche / droit, milieu, pénalité).
- Classez à nouveau les motifs.
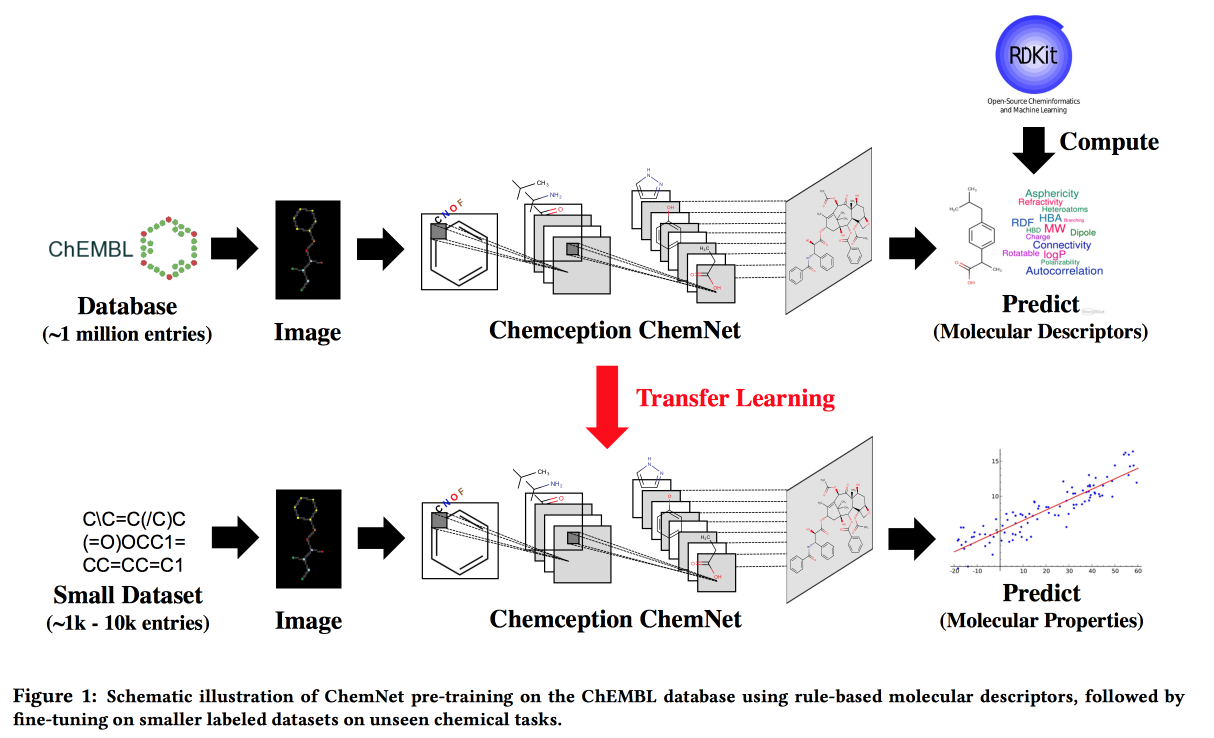
Utilisation d'étiquettes basées sur des règles pour un apprentissage supervisé faible: un ChemNet pour la propriété chimique transférable P
Travaillez dans des situations où il n'y a pas de big data, mais il existe des modèles théoriques avec des règles hiérarchiques. En utilisant la théorie, nous construisons un réseau neuronal «expert». Applicable à la tâche de développer des composés chimiques avec les propriétés souhaitées.
Je voudrais, par analogie avec les images, obtenir un réseau dans lequel les couches correspondront à différents niveaux d'abstraction: atomes / groupes fonctionnels / fragments / molécules. Dans le passé, il existait des approches pour les grands ensembles de données étiquetés, par exemple, SMILE2Vect: utilisez
SMILE pour traduire une formule en texte, puis appliquez des techniques pour créer des incorporations pour les textes.
Mais que faire s'il n'y a pas de grand ensemble de données marqué? Nous enseignons ChemNet en utilisant
RDKit pour les objectifs qu'il peut prédire, puis nous transférons l'apprentissage pour résoudre le problème. Nous montrons que nous pouvons rivaliser avec des modèles formés sur des données étiquetées. Vous pouvez apprendre en couches, ce qui signifie atteindre l'objectif - décomposer les couches par niveau d'abstraction.
PrePeP - Un outil pour l'identification et la caractérisation des composés d'interférence Pan Assay
Nous développons des médicaments et utilisons la science des données pour sélectionner les candidats. Il existe des molécules qui réagissent avec de nombreuses substances. Ils ne peuvent pas être utilisés comme médicaments, mais apparaissent souvent dans les premières étapes du test. Ce sont les molécules de
DOULEUR que nous filtrerons.
Il y a des difficultés: les données sont déchargées et arrogantes (107 000), les classes sont déséquilibrées (0,5% positif) et les chimistes veulent obtenir un modèle interprété. Combinez les données de la structure graphique (
gSpan ) de la molécule et les empreintes chimiques. Ils ont lutté avec l'équilibre en ensachant le sous-échantillonnage négatif, ont enseigné les arbres, les prévisions agrégées par vote majoritaire.