 Pour rendre la surveillance utile, nous devons élaborer différents scénarios de problèmes probables et concevoir des tableaux de bord et des déclencheurs de manière à ce qu'ils comprennent immédiatement la cause de l'incident.
Pour rendre la surveillance utile, nous devons élaborer différents scénarios de problèmes probables et concevoir des tableaux de bord et des déclencheurs de manière à ce qu'ils comprennent immédiatement la cause de l'incident.
Dans certains cas, nous comprenons bien comment fonctionne telle ou telle composante de l'infrastructure, et nous savons alors à l'avance quelles mesures seront utiles. Et parfois, nous supprimons presque toutes les mesures possibles avec un maximum de détails, puis examinons comment certains problèmes sont visibles sur elles.
Aujourd'hui, nous allons voir comment et pourquoi les postgres WAL (Write-Ahead Log) peuvent gonfler. Comme d'habitude - des exemples de la vie réelle en images.
Un peu de théorie WAL en postgresql
Tout changement dans la base de données est d'abord enregistré dans le WAL, et ce n'est qu'après que les données de la page dans le cache de tampon sont modifiées et marquées comme sales - qui doivent être enregistrées sur le disque. En outre, le processus CHECKPOINT est périodiquement démarré, ce qui enregistre toutes les pages encrassées sur le disque et enregistre le numéro de segment WAL, jusqu'à ce que toutes les pages modifiées soient déjà écrites sur le disque.
Si soudainement postgresql pour une raison quelconque se bloque et redémarre, tous les segments WAL du dernier point de contrôle seront lus pendant le processus de récupération.
Les segments WAL précédant le point de contrôle ne nous seront plus utiles pour la récupération de base de données post-crash, mais dans le postgres, WAL participe également au processus de réplication, et la sauvegarde de tous les segments pour Point In Time Recovery - PITR peut également être configurée.
Un ingénieur expérimenté a probablement déjà tout compris, comment ça se casse dans la vraie vie :)
Regardons les graphiques!
Gonflement WAL # 1
Notre agent de surveillance pour chaque instance trouvée de postgres calcule le chemin sur le disque vers le répertoire avec wal et supprime à la fois la taille totale et le nombre de fichiers (segments):
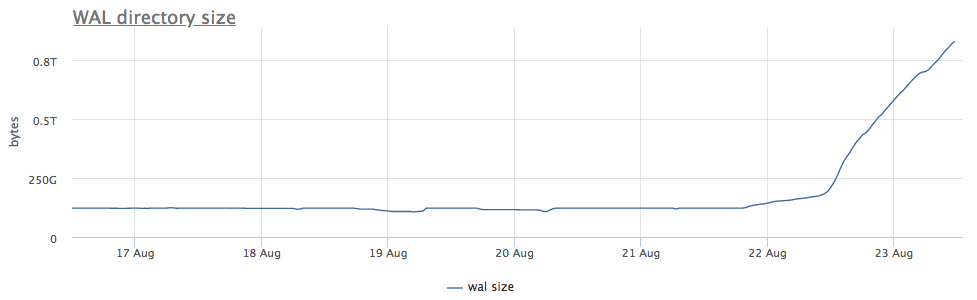
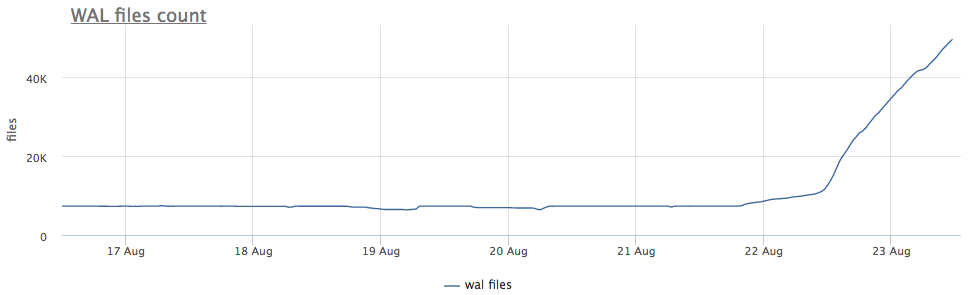
Tout d'abord, nous regardons depuis combien de temps nous exécutons CHECKPOINT.
Nous prenons les métriques de pg_stat_bgwriter:
- checkpoints_timed - compteur de lancements de points de contrôle qui se sont produits à condition que l'heure du dernier point de contrôle ait été dépassée de plus de pg_settings.checkpoint_timeout
- checkpoints_req - compteur de débuts du point de contrôle par la condition que la taille wal est dépassée depuis le dernier point de contrôle
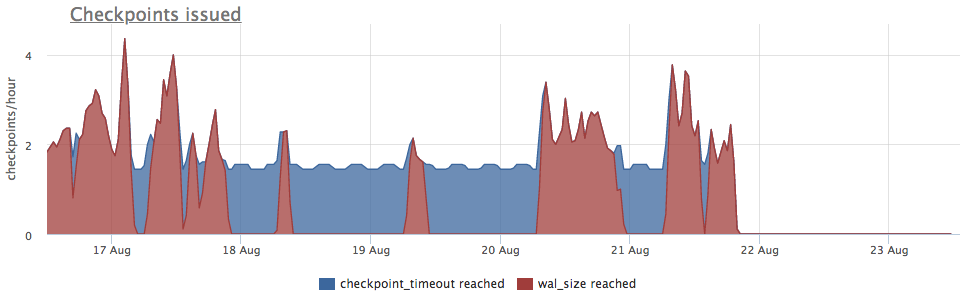
Nous voyons que le point de contrôle n'a pas été lancé depuis longtemps. Dans ce cas, il est impossible de comprendre directement la raison de NE PAS démarrer ce processus (mais ce serait bien sûr cool), mais nous savons que dans les postgres, de nombreux problèmes surviennent en raison de longues transactions!
Nous vérifions:

De plus, il est clair que faire:
- tuer une transaction
- traiter les raisons pour lesquelles il est long
- attendez, mais vérifiez qu'il y a assez d'espace
Autre point important: sur les répliques connectées à ce serveur, wal est également gonflé !
Archiveur WAL
Je vous le rappelle à l'occasion: la réplication n'est pas une sauvegarde!
Une bonne sauvegarde devrait vous permettre de récupérer à tout moment. Par exemple, si quelqu'un a «accidentellement» exécuté
DELETE FROM very_important_tbl;
Ensuite, nous devrions être en mesure de restaurer la base de données à l'état exactement avant cette transaction. Cela s'appelle PITR (récupération ponctuelle) et est implémenté en postgresql avec des sauvegardes complètes périodiques de la base de données + sauvegarde de tous les segments WAL après le vidage.
Le paramètre archive_command est responsable de la sauvegarde de wal, postgres démarre simplement la commande que vous avez spécifiée et s'il se termine sans erreur, le segment est considéré comme ayant été correctement copié. Si une erreur se produit, il tentera jusqu'à la victoire, le segment reposera sur le disque.
Eh bien, et à titre d'illustration - graphiques de l'archivage cassé wal:
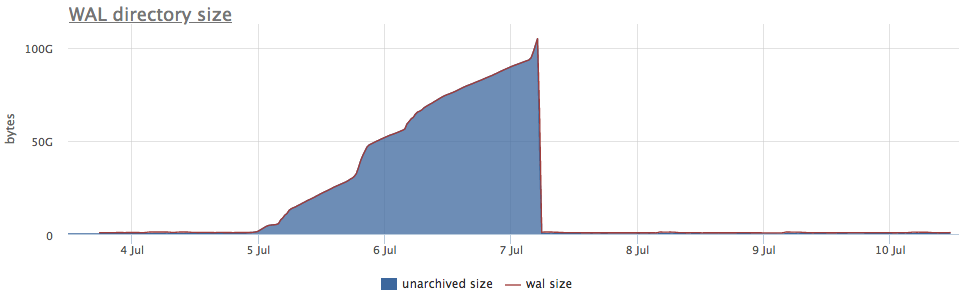
Ici, en plus de la taille de tous les segments wal, il existe une taille non archivée - c'est la taille des segments qui ne sont pas encore considérés comme enregistrés avec succès.
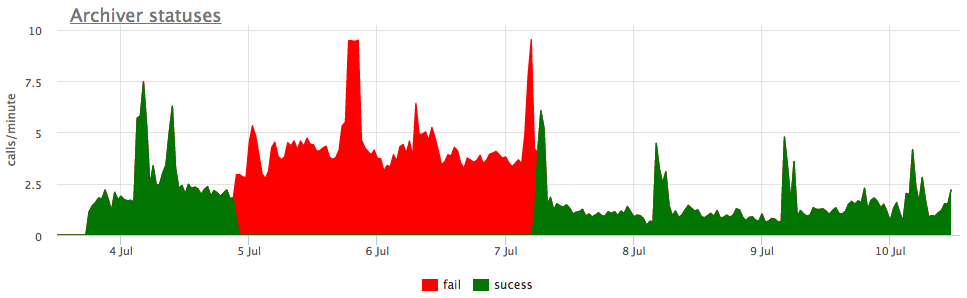
Nous considérons les statuts en fonction des compteurs de pg_stat_archiver. Pour le nombre de fichiers, nous avons fait un déclenchement automatique pour tous les clients, car il tombe souvent en panne, en particulier lorsque du stockage cloud est utilisé comme destination (S3, par exemple).
Retard de réplication
La réplication en continu fonctionne en transférant et en jouant à Wal sur les répliques. Si, pour une raison quelconque, la réplique est derrière et n'a pas perdu un certain nombre de segments, l'assistant stockera les segments pg_settings.wal_keep_segments pour elle. Si la réplique prend du retard sur un plus grand nombre de segments, elle ne pourra plus se connecter au maître (elle devra être redistribuée).
Afin de garantir la préservation du nombre souhaité de segments, la fonctionnalité des emplacements de réplication est apparue en 9.4, qui sera discutée plus loin.
Emplacements de réplication
Si la réplication est configurée à l'aide de l'emplacement de réplication et qu'il y a eu au moins une connexion de réplique réussie à l'emplacement, alors dans le cas où la réplique disparaît, les postgres stockent tous les nouveaux segments wal jusqu'à épuisement de l'emplacement.
C'est-à-dire qu'un emplacement de réplication oublié peut provoquer un gonflement de Wal. Mais heureusement, nous pouvons surveiller l'état des emplacements via pg_replication_slots.
Voici à quoi cela ressemble dans un exemple en direct:
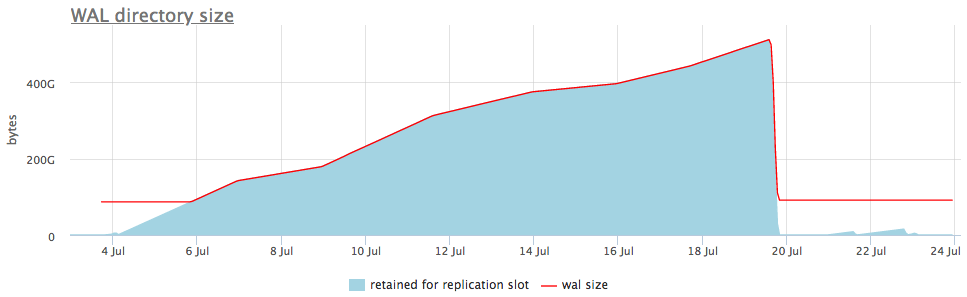

Dans le graphique supérieur, à côté de la taille wal, nous affichons toujours soit une fente avec le nombre maximum de segments accumulés, mais il y a aussi un graphique détaillé qui montrera quelle fente est gonflée.
Une fois que nous savons quel type de slot collecte les données, nous pouvons soit réparer les répliques qui lui sont associées, soit simplement les supprimer.
J'ai cité les cas les plus courants de gonflement du wal, mais je suis sûr qu'il y en a d'autres (des bugs dans les postgres sont aussi parfois trouvés). Par conséquent, il est important de surveiller la taille du wal et de répondre aux problèmes avant que l'espace disque ne soit épuisé et que la base de données cesse de traiter les demandes.
Notre service de surveillance sait déjà collecter tout cela, visualiser et alerter correctement. Et nous avons également une option de livraison sur site pour ceux à qui le cloud ne convient pas.