À ma connaissance, l'un des programmes les plus utiles sur PC et smartphone est un dictionnaire électronique. Dans ces temps anciens, lorsque j'apprenais une langue étrangère, je devais chercher chaque mot dans un dictionnaire papier. J'ai fait cette opération triviale des centaines de fois, et certains mots malveillants ont dû être regardés encore et encore, car j'ai réussi à oublier leur signification. Comme c'était insultant! Que ce soit le cas maintenant, rapidement et traduisez devant vos yeux sur l'écran du moniteur. Historique de recherche, au cas où le mot recherché ne serait pas passé du domaine de la mémoire à court terme à celui à long terme.
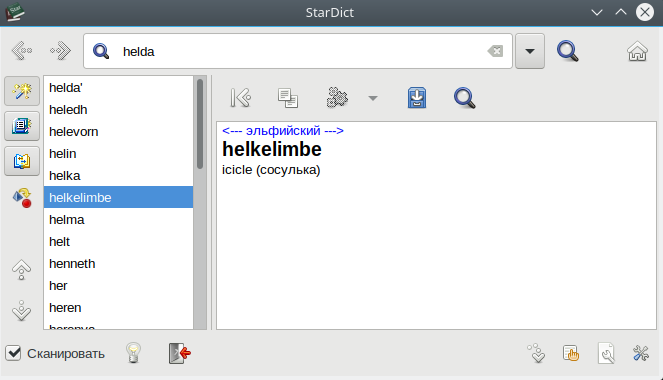
Créons nous-mêmes un dictionnaire électronique pour les programmes StarDict / GoldenDict. Pour cela, vous pouvez avoir besoin de plusieurs, voire quelques heures-homme, selon la qualité du matériel source.
Première étape: OCR
Contrairement à l'alpinisme, l'étape la plus difficile à numériser un dictionnaire n'est pas la dernière mais la première. Si vous devez exécuter une OCR d'un dictionnaire papier avec des pages fanées imprimées trop finement, avec divers artefacts d'une utilisation imprudente, ou dans une langue exotique, même FineReader n'aidera pas beaucoup. Sur certaines pages, la différence de temps entre la saisie manuelle et l'OCR avec correction d'erreur est négligeable.
Je vous conseille de tout sauvegarder dans des fichiers texte simples , car la recherche avancée et la correction d'erreurs, le balisage, la conversion de tri et d'autres opérations avec un tableau de texte sont inimaginables à effectuer avec un fichier binaire .
À cette étape, il est important de déterminer la structure des entrées du dictionnaire. Dans le cas le plus simple, il n'y aura que deux champs: une clé et une valeur . Cela suffit, mais si vous avez besoin de mettre en évidence divers éléments d'articles, vous devrez étiqueter tous ces éléments d'une certaine manière.
Il est temps de parler un peu des formats. Il existe de nombreux formats de dictionnaires électroniques, en voici une liste.
Nous n'analyserons pas tous les formats ici, car la plupart d'entre eux sont propriétaires. Nous nous intéressons aux standards ouverts et aux logiciels open source.
Dictd
Né à une époque où les protocoles réseau TCP / IP librement multipliés et multipliés dictd est désormais uniquement d'intérêt archéologique. Il s'agit d'un protocole client-serveur qui utilise le port TCP 2628, défini dans RFC 2229 .
Le fichier source du dictionnaire est formaté comme suit.
::
Par exemple, un tel dictionnaire
:catalysis: "increase in the rate of a chemical reaction due to the participation of an additional substance called a catalyst, which is not consumed in the catalyzed reaction and can continue to act repeatedly. " <a href="is.gd/v6a22Q">ref</a>. :deconstruction: :rendered: eg. "rendered irrelevant." :reading: cf. 'reading of' :minor: a minor reading.
Le fichier terminé pour le dictionnaire est créé par la commande dictfmt .
dictfmt --utf8 -s " " -j dict-name < mydict.txt
En conséquence, 2 fichiers sont formés: dict-name.index et dict-name.dict . Parmi ceux-ci, le premier est évidemment un fichier d'index, vous n'avez rien à faire avec lui, et le second peut être compressé avec la commande dictzip . Cette commande compresse le fichier * .dict à l'aide de l'utilitaire gzip . La question se pose immédiatement: pourquoi alors est-il nécessaire s'il y a un gzip régulier?
Le fait est que dictzip utilise des octets supplémentaires dans l'en-tête du fichier d'archive pour fournir un accès pseudo-aléatoire au fichier.
Enfin, les fichiers sont placés dans les répertoires de profil, /usr/lib/dict , nous redémarrons le service dictd et le tour est joué. La syntaxe de recherche est simple, il suffit de taper
dict WORD.
Faire du jogging via des liens dictd ressemble à un safari sur le réseau Internet des années 90, est vivant et continue!
Sdict
Une tentative audacieuse d' Alexei Semenov de changer le monde pour le mieux avec l'aide de la magie Perl à une époque où Microsoft n'avait pas encore tordu Linux et la communauté open-source, et la principale source de dictionnaires était les pirates ABBYY Lingvo.
En-tête du fichier de dictionnaire source.
<header> title = Sample 1 test dictionary - dictionary name; copyright = GNU Public License - copyright information; version = 0.1 - version; w_lang = en - language for words; a_lang = fi - language for articles. For further information about language codes refer 'C:\Sdict\share\doc\iso639.htm' file; # charset = ... - use if your source file is not in UTF-8 encoding. </header>
Le corps est formaté comme suit:
word___article
Le cas échéant, vous pouvez télécharger la version pour le système d'exploitation Symbian. Le projet n'est plus en vie et même les dictionnaires eux-mêmes ne peuvent être appris qu'à partir de Time Machine .
Xdxf
Eh bien, tout, nous sommes liés à l'archéologie et passons aux formats de dictionnaire et aux programmes adaptés à l'utilisation de l'IRL.
XDXF possède tous les avantages et inconvénients du format XML, ce qu'il est. Toutes les syntaxes et exemples de format peuvent être consultés ici .
Le squelette du fichier dictionnaire ressemble à ceci, se compose de 2 parties: meta_info et lexicon .
<xdxf ...> <meta_info> : , . </meta_info> <lexicon> <ar> 1</ar> <ar> 2</ar> <ar> 3</ar> <ar> 4</ar> ... </lexicon> </xdxf>
Il existe un grand nombre de dictionnaires dans ce format. Le grand avantage du format est qu'il n'est pas nécessaire de convertir quoi que ce soit. GoldenDict reconnaît les fichiers XDXF ainsi qu'un grand nombre d'autres formats pris en charge.
TSV / StarDict
StarDict et ses clones ne concernent pas tant le format de dictionnaire électronique que des logiciels de haute qualité pour les visualiser, les convertir et les créer.
Pour créer un dictionnaire électronique à l'aide de StarDict, un fichier TSV suffit, que j'ai choisi pour une copie numérique du dictionnaire arménien-russe .
Néanmoins, une mise en forme et un balisage du fichier de dictionnaire sont possibles, mais ils ne peuvent pas être comparés à XDXF .
a 1\n2\n3 b 4\\5\n6 c 789
Le format définit le caractère de saut de ligne \n , dans le cas où l'article est divisé en paragraphes.
Deuxième étape: ajustement
Après la première étape, il y aura très probablement des dizaines, voire des centaines d'orthographe, de grammaire et toutes sortes d'autres erreurs, caractères étranges et autres artefacts OCR.
La particularité des dictionnaires est que l'orthographe est nécessaire simultanément dans deux langues. Même maintenant en 2018, étonnamment peu d'éditeurs de texte et même de suites bureautiques sont capables d'effectuer cette action simple.
Pas un holivar pour, je recommande de traiter teska pour produire avec Vim . Si votre éditeur de texte préféré ne fait pas pire, c'est bien. Avec Vim, une équipe suffit.
:setlocal spell spelllang=en,ru
pour vérifier l'orthographe dans deux dictionnaires, en l'occurrence russe et anglais. Voici une liste de râteaux.
- Le tri de texte fonctionne de toute façon pour les paramètres régionaux non latins, en particulier lorsque l'écriture d'une lettre nécessite plus d'un caractère, comme l'arménien
ու = ո + ւ . Il est nécessaire dans de tels cas de trier vous-même la liste des mots à l'aide d'un simple Perl ou d'un autre script. - La correspondance de modèles peut également fonctionner de manière inattendue pour certains paramètres régionaux, même si le texte lui-même et la console sont en UTF-8.
- Lors de la numérisation d'un dictionnaire imprimé, il faut être prêt non seulement aux erreurs de numérisation, mais également aux erreurs du dictionnaire imprimé lui-même. Ils peuvent en contenir beaucoup!
- Si le titre de l'article est écrit en majuscules, il doit peut-être être converti en minuscules lors de la numérisation. Toutes les lettres n'ont pas de caractères majuscules; en fait, tous les paramètres régionaux n'ont même pas de lettres majuscules.
Troisième étape: compilation du dictionnaire
Pour le format XDXF , comme déjà mentionné, cette étape n'est pas requise. /usr/share/goldendict simplement le fichier dans le dossier /usr/share/goldendict , où le programme le /usr/share/goldendict .
Pour le fichier TSV, l' stardict-editor , fourni avec la boîte à outils StarDict , est utilisé.

En sortie, le programme crée les fichiers suivants, comme l'ancien Dict.
- somedict.ifo
- somedict.idx ou somedict.idx.gz
- somedict.dict ou somedict.dict.dz
- somedict.syn (facultatif)
Les fichiers sont copiés dans le /ysr/share/stardict/dic et c'est tout.
PS Pour la plate-forme mobile Android, GoldenDict est soudainement devenu payant, mais vous pouvez toujours trouver la dernière version gratuite sur Internet.