Chaque jour, les utilisateurs engagent des millions d'activités en ligne. Le projet FACETz DMP doit structurer ces données et les segmenter pour identifier les préférences des utilisateurs. Dans l'article, nous expliquerons comment l'équipe a segmenté un public de 600 millions de personnes, traité 5 milliards d'événements par jour et travaillé avec des statistiques à l'aide de Kafka et HBase.
Le matériel est basé sur une transcription d'un
rapport par Artyom Marinov , spécialiste du Big Data chez Directual, de la conférence SmartData 2017.
Je m'appelle Artyom Marinov, je veux parler de la façon dont nous avons repensé l'architecture du projet FACETz DMP lorsque je travaillais chez Data Centric Alliance. Pourquoi nous l'avons fait, à quoi cela a conduit, dans quelle direction nous sommes allés et quels problèmes nous avons rencontrés.
DMP (Data Management Platform) est une plateforme de collecte, de traitement et d'agrégation de données utilisateur. Les données sont beaucoup de choses différentes. La plateforme compte environ 600 millions d'utilisateurs. Ce sont des millions de cookies qui vont sur Internet et font divers événements. En général, une journée ressemble en moyenne à quelque chose comme ceci: nous voyons environ 5,5 milliards d'événements par jour, ils sont en quelque sorte répartis sur la journée et, au pic, ils atteignent environ 100 000 événements par seconde.

Les événements sont différents signaux utilisateur. Par exemple, une visite sur un site: nous voyons à partir de quel navigateur l'utilisateur va, son agent utilisateur et tout ce que nous pouvons extraire. Parfois, nous voyons comment et pour quelles requêtes de recherche il est venu sur le site. Il peut également s'agir de diverses données du monde hors ligne, par exemple, ce qu'il paie avec des coupons de réduction, etc.
Nous devons enregistrer ces données et marquer l'utilisateur dans les soi-disant groupes de segments d'audience. Par exemple, les segments peuvent être une «femme» qui «aime les chats» et qui recherche un «service de voiture», elle «a une voiture de plus de trois ans».
Pourquoi segmenter un utilisateur? Il existe de nombreuses applications pour cela, par exemple la publicité. Divers réseaux publicitaires peuvent optimiser les algorithmes de diffusion d'annonces. Si vous faites la publicité de votre service de voiture, vous pouvez mettre en place une campagne de telle sorte que seules les personnes qui ont une vieille voiture affichent des informations, à l'exclusion des propriétaires de nouvelles. Vous pouvez modifier dynamiquement le contenu du site, vous pouvez utiliser les données pour la notation - il existe de nombreuses applications.
Les données sont obtenues à partir de nombreux endroits complètement différents. Il peut s'agir de paramètres de pixels directs - c'est-à-dire que si le client veut analyser son public, il place le pixel sur le site, une image invisible qui est téléchargée depuis notre serveur. L'essentiel est que nous voyons la visite de l'utilisateur sur ce site: vous pouvez l'enregistrer, commencer à analyser et comprendre le portrait de l'utilisateur, toutes ces informations sont à la disposition de notre client.

Les données peuvent être obtenues auprès de différents partenaires qui voient beaucoup de données et souhaitent les monétiser de différentes manières. Les partenaires peuvent fournir des données en temps réel et effectuer des téléchargements périodiques sous forme de fichiers.
Exigences clés:
- Évolutivité horizontale;
- Évaluation du volume de l'audience;
- Commodité du suivi et du développement;
- Bonne vitesse de réaction aux événements.
L'une des principales exigences du système est l'évolutivité horizontale. Il y a un tel moment que lorsque vous développez un portail ou une boutique en ligne, vous pouvez estimer le nombre de vos utilisateurs (comment il va croître, comment cela va changer) et comprendre approximativement combien de ressources sont nécessaires, et comment la boutique va vivre et se développer au fil du temps.
Lorsque vous développez une plate-forme similaire à DMP, vous devez être préparé au fait que tout grand site - l'Amazonie conditionnelle - peut y mettre votre pixel, et vous devrez travailler avec le trafic de l'ensemble de ce site, alors que vous ne devriez pas tomber, et les indicateurs les systèmes ne devraient pas en quelque sorte changer de cela.
Il est également très important de pouvoir comprendre le volume d'une certaine audience afin qu'un annonceur potentiel ou quelqu'un d'autre puisse élaborer un plan média. Par exemple, une personne vient à vous et vous demande de savoir combien de femmes enceintes de Novossibirsk recherchent un prêt hypothécaire afin d'évaluer s'il est logique de les cibler ou non.
Du point de vue du développement, vous devez pouvoir surveiller froidement tout ce qui se passe dans votre système, déboguer une partie du trafic réel, etc.
L'une des exigences système les plus importantes est une bonne vitesse de réaction aux événements. Plus les systèmes répondent rapidement aux événements, mieux c'est, c'est évident. Si vous cherchez des billets de théâtre, alors si vous voyez une sorte d'offre de réduction après une journée, deux jours ou même une heure - cela peut ne pas être pertinent, car vous pourriez déjà acheter des billets ou aller à une représentation. Lorsque vous cherchez une perceuse - vous la recherchez, trouvez, achetez, accrochez une étagère, et après quelques jours, le bombardement commence: "Achetez une perceuse!".
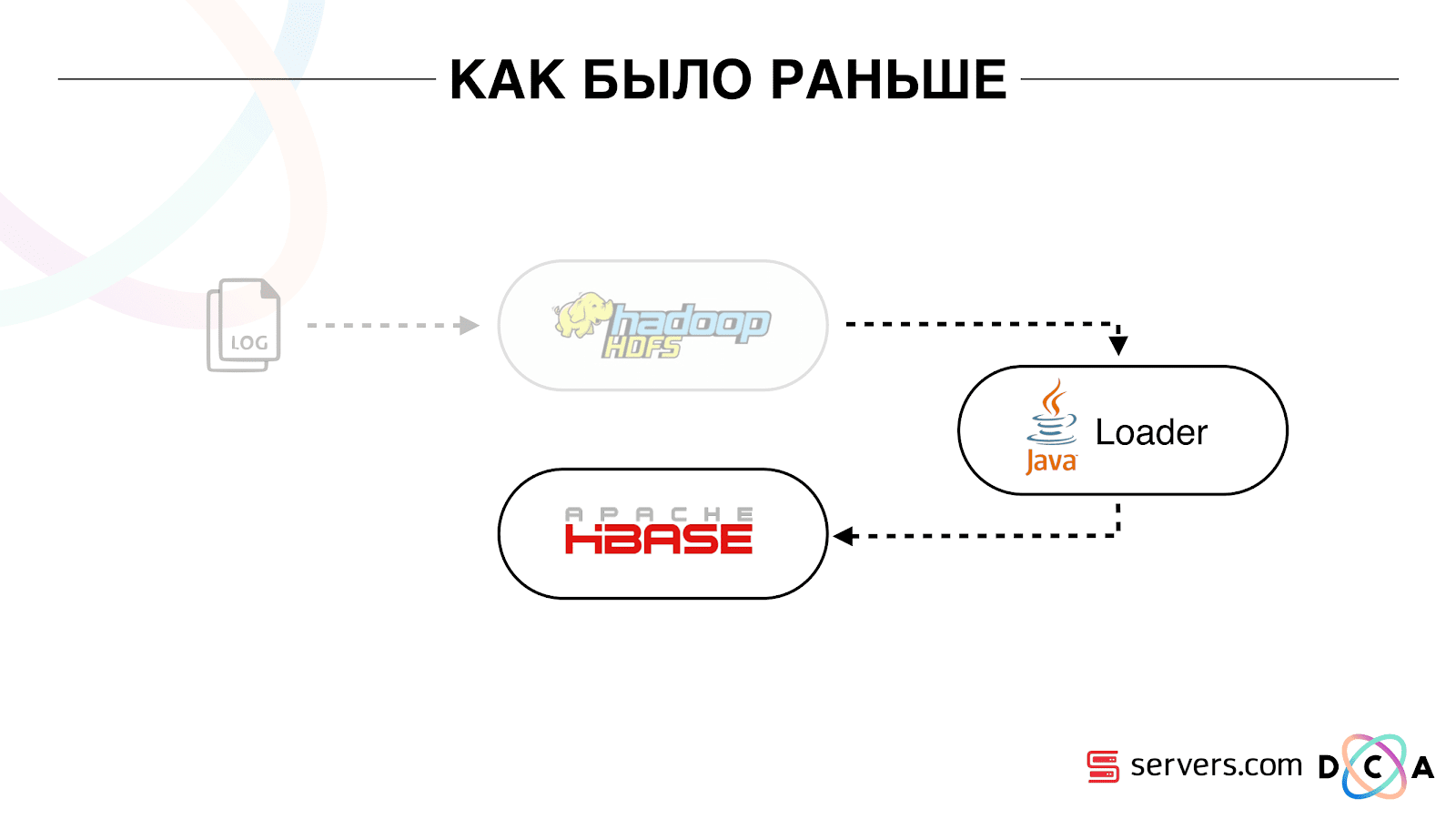
Comme avant
L'article dans son ensemble porte sur le recyclage de l'architecture. Je voudrais vous dire quel était notre point de départ, comment tout fonctionnait avant les changements.
Toutes les données que nous avions, qu'il s'agisse d'un flux de données direct ou de journaux, étaient stockées sur un stockage de fichiers distribué HDFS. Ensuite, il y avait un certain processus qui était périodiquement lancé, prenait tous les fichiers non traités de HDFS et les convertissait en demandes d'enrichissement de données dans HBase («demandes PUT»).
Comment stockons-nous les données dans HBase
Il s'agit d'une base de données chronologique en colonnes. Elle a le concept d'une clé de ligne - c'est la clé sous laquelle vous stockez vos données. Nous utilisons l'ID utilisateur comme clé, l'ID utilisateur, que nous générons lorsque nous voyons l'utilisateur pour la première fois. À l'intérieur de chaque clé, les données sont divisées en famille de colonnes - entités au niveau desquelles vous pouvez gérer les méta-informations de vos données. Par exemple, vous pouvez stocker un millier de versions d'enregistrements pour les «données» de la famille de colonnes et les stocker pendant deux mois, et pour la famille de colonnes «brutes» - un an, en option.
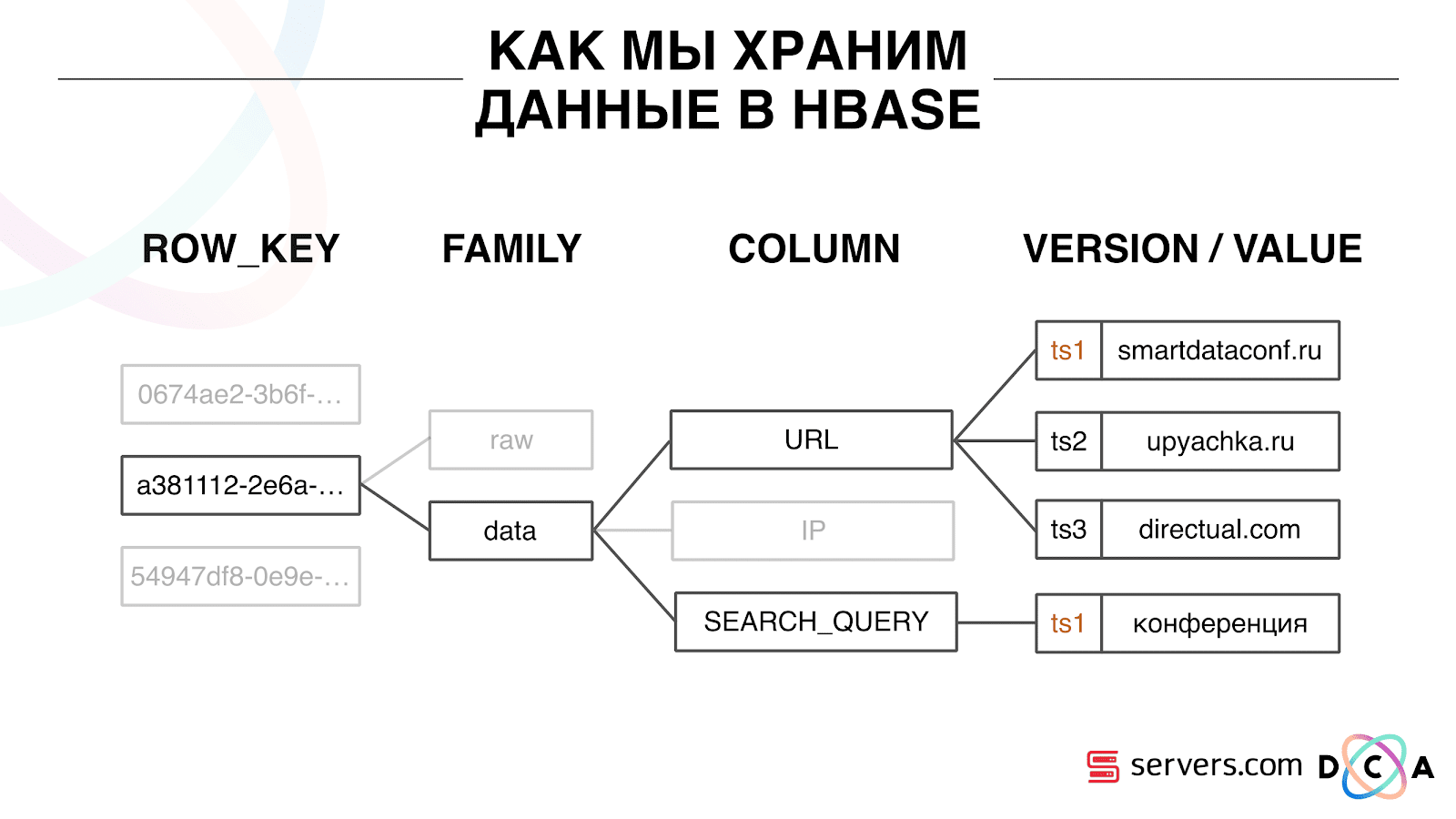
Au sein de la famille de colonnes, il existe de nombreux qualificateurs de colonne (colonne ci-après). Nous utilisons divers attributs utilisateur comme colonne. Il peut s'agir de l'URL vers laquelle il est allé, de l'adresse IP, de la requête de recherche. Et surtout, beaucoup d'informations sont stockées dans chaque colonne. À l'intérieur de l'URL de la colonne, il peut être indiqué que l'utilisateur est allé sur smartdataconf.ru, puis sur d'autres sites. Et l'horodatage est utilisé comme version - vous voyez un historique ordonné des visites des utilisateurs. Dans notre cas, nous pouvons déterminer que l'utilisateur est venu sur le site Web de smartdataconf avec le mot-clé «conférence», car il a le même horodatage.
Travailler avec HBase
Il existe plusieurs options pour travailler avec HBase. Il peut s'agir de demandes PUT (demande de changement de données), de demande GET ("donnez-moi toutes les données sur l'utilisateur Vasya", etc.). Vous pouvez exécuter des requêtes SCAN - analyse séquentielle multithread de toutes les données dans HBase. Nous l'avons utilisé plus tôt pour baliser dans les segments d'audience.
Il y avait une tâche appelée Analytics Engine, qui s'exécutait une fois par jour et analysait HBase dans plusieurs threads. Pour chaque utilisateur, elle a extrait toute l'histoire de HBase et l'a exécutée à travers un ensemble de scripts analytiques.

Qu'est-ce qu'un script analytique? Il s'agit d'une sorte de boîte noire (classe java), qui reçoit toutes les données utilisateur en entrée et donne un ensemble de segments qu'il considère comme approprié en sortie. Nous donnons tout au script que nous voyons - IP, visites, UserAgent, etc., et sur la sortie les scripts donnent: «c'est une femme, aime les chats, n'aime pas les chiens».
Ces données ont été transmises aux partenaires, des statistiques ont été prises en compte. Il était important pour nous de comprendre combien de femmes en général, combien d'hommes, combien de gens aiment les chats, combien ont ou n'ont pas de voiture, etc.
Nous avons stocké des statistiques dans MongoDB et écrit en incrémentant un compteur de segment spécifique pour chaque jour. Nous avions un graphique du volume de chaque segment pour chaque jour.
Ce système était bon pour l'époque. Il permettait de se redimensionner horizontalement, de grandir, permettait d'estimer le volume de l'audience, mais il avait un certain nombre d'inconvénients.
Il n'était pas toujours possible de comprendre ce qui se passait dans le système, de consulter les journaux. Pendant que nous étions à l'hébergeur précédent, la tâche a souvent échoué pour diverses raisons. Il y avait un cluster Hadoop de 20+ serveurs, une fois par jour, l'un des serveurs se bloquait de manière stable. Cela a conduit au fait que la tâche pouvait partiellement tomber et ne pas calculer les données. Il fallait avoir le temps de le redémarrer et, étant donné qu'il fonctionnait pendant plusieurs heures, il y avait un certain nombre de nuances.
La chose la plus fondamentale que l'architecture existante ne remplissait pas était que le temps de réaction à l'événement était trop long. Il y a même une histoire à ce sujet. Il y avait une entreprise qui accordait des microcrédits à la population des régions et nous nous sommes associés à elle. Leur client vient sur le site, remplit une demande de microcrédit, l'entreprise doit donner une réponse en 15 minutes: sont-ils prêts à accorder ou non un prêt. Si vous êtes prêt, ils ont immédiatement transféré de l'argent sur la carte.
Tout fonctionnait plutôt bien. Le client a décidé de vérifier comment cela se passe généralement: il a pris un ordinateur portable séparé, installé un système propre, visité de nombreuses pages sur Internet et s'est rendu sur son site. Ils voient qu'il y a une demande, et en réponse, nous disons qu'il n'y a pas encore de données. Le client demande: "Pourquoi n'y a-t-il pas de données?"
Nous expliquons: il y a un certain décalage avant que l'utilisateur n'agisse. Les données sont envoyées à HBase, traitées et ce n'est qu'alors que le client reçoit le résultat. Il semblerait que si l'utilisateur n'a pas vu la publicité - tout est en ordre, il ne se passera rien de mal. Mais dans cette situation, l'utilisateur pourrait ne pas obtenir de prêt en raison du décalage.
Ce n'est pas un cas isolé et il a fallu passer à un système temps réel. Que voulons-nous d'elle?

Nous voulons écrire des données dans HBase dès que nous les voyons. Nous avons vu une visite, enrichi tout ce que nous savons et envoyé à Storage. Dès que les données du stockage ont changé, vous devez exécuter immédiatement l'ensemble complet des scripts analytiques dont nous disposons. Nous voulons la commodité de la surveillance et du développement, la possibilité d'écrire de nouveaux scripts, de les déboguer en morceaux de trafic réel. Nous voulons comprendre ce que le système est actuellement occupé.
La première chose avec laquelle nous avons commencé est de résoudre le deuxième problème: segmenter l'utilisateur immédiatement après avoir modifié les données le concernant dans HBase. Initialement, nous avions des nœuds de travail (des tâches de réduction de carte ont été lancées sur eux) situés au même endroit que HBase. Dans un certain nombre de cas, c'était très bien - les calculs sont effectués à côté des données, les tâches fonctionnent assez rapidement, peu de trafic passe par le réseau. Il est clair que la tâche consomme certaines ressources, car elle exécute des scripts analytiques complexes.
Lorsque nous allons travailler en temps réel, la nature de la charge sur HBase change. Nous passons à des lectures aléatoires au lieu de lectures séquentielles. Il est important que la charge sur HBase soit attendue - nous ne pouvons pas permettre à quelqu'un d'exécuter la tâche sur le cluster Hadoop et de gâcher les performances de HBase.
La première chose que nous avons faite a été de déplacer HBase sur des serveurs séparés. A également modifié BlockCache et BloomFilter. Ensuite, nous avons fait un bon travail sur la façon de stocker les données dans HBase. Ils ont à peu près retravaillé le système dont j'ai parlé au début et ont récolté les données elles-mêmes.

De l'évidence: nous avons stocké IP sous forme de chaîne et sommes devenus longs en nombre. Certaines données ont été classées, effectuées des choses de vocabulaire, etc. L'essentiel est qu'à cause de cela, nous avons pu secouer HBase environ deux fois - de 10 To à 5 To. HBase a un mécanisme similaire aux déclencheurs dans une base de données régulière. Il s'agit d'un mécanisme de coprocesseur. Nous avons écrit un coprocesseur qui, lorsqu'un utilisateur passe à HBase, envoie l'ID utilisateur à Kafka.
L'ID utilisateur est dans Kafka. En outre, il existe un certain «segmentateur» de services. Il lit le flux d'identifiants utilisateur et exécute sur eux tous les mêmes scripts qu'avant, demandant des données à HBase. Le processus a été lancé sur 10% du trafic, nous avons regardé comment cela fonctionne. Tout était plutôt bien.

Ensuite, nous avons commencé à augmenter la charge et avons constaté un certain nombre de problèmes. La première chose que nous avons vue est que le service fonctionne, se segmente, puis tombe de Kafka, se connecte et recommence à fonctionner. Plusieurs services - ils s'entraident. Puis le suivant tombe, un autre et ainsi de suite en cercle. Dans le même temps, la gamme d'utilisateurs pour la segmentation n'est presque pas ratissée.
Cela était dû à la particularité du mécanisme de battement de cœur dans Kafka, alors c'était toujours la version 0.8. Le battement de cœur, c'est quand les consommateurs disent au courtier s'ils sont vivants ou non, dans notre cas, rapporte le segmentateur. La chose suivante s'est produite: nous avons reçu un assez gros paquet de données, envoyé pour traitement. Pendant un certain temps, cela a fonctionné, pendant que cela a fonctionné - aucun battement de cœur n'a été envoyé. Les courtiers ont cru que le consommateur était mort et l'ont désactivé.
Le consommateur a travaillé jusqu'au bout, gaspillant de précieux processeurs, a essayé de dire que le pack de données avait été élaboré et que le suivant pouvait être pris, mais il a été refusé parce que l'autre avait emporté ce avec quoi il travaillait. Nous l'avons corrigé en faisant notre battement de chaleur en arrière-plan, puis la vérité est venue d'une nouvelle version de Kafka où nous avons résolu ce problème.
Puis la question s'est posée: sur quel type de matériel nos segmentateurs devraient-ils être installés? La segmentation est un processus gourmand en ressources (lié au processeur). Il est important que le service consomme non seulement beaucoup de CPU, mais charge également le réseau. Le trafic atteint désormais 5 Gbit / s. La question était: où mettre les services, sur de nombreux petits serveurs ou un peu gros.
À ce moment, nous avons déjà déménagé sur
servers.com sur du bare metal. Nous avons discuté avec les gars des serveurs, ils nous ont aidés, ont permis de tester le travail de notre solution à la fois sur un petit nombre de serveurs chers, et sur de nombreux serveurs peu coûteux avec des CPU puissants. Nous avons choisi l'option appropriée, en calculant le coût unitaire de traitement d'un événement par seconde. Soit dit en passant, le choix s'est porté sur un Dell R230 suffisamment puissant et en même temps extrêmement abordable, ils l'ont lancé - tout a fonctionné.
Il est important qu'après que le segmentateur ait marqué l'utilisateur en segments, le résultat de son analyse revienne à Kafka, dans un certain sujet Résultat de segmentation.
De plus, nous pouvons nous connecter indépendamment à ces données par différents consommateurs qui n'interféreront pas les uns avec les autres. Cela nous permet de fournir des données de manière indépendante à chaque partenaire, qu'il s'agisse de partenaires externes, DSP interne, Google, statistiques.
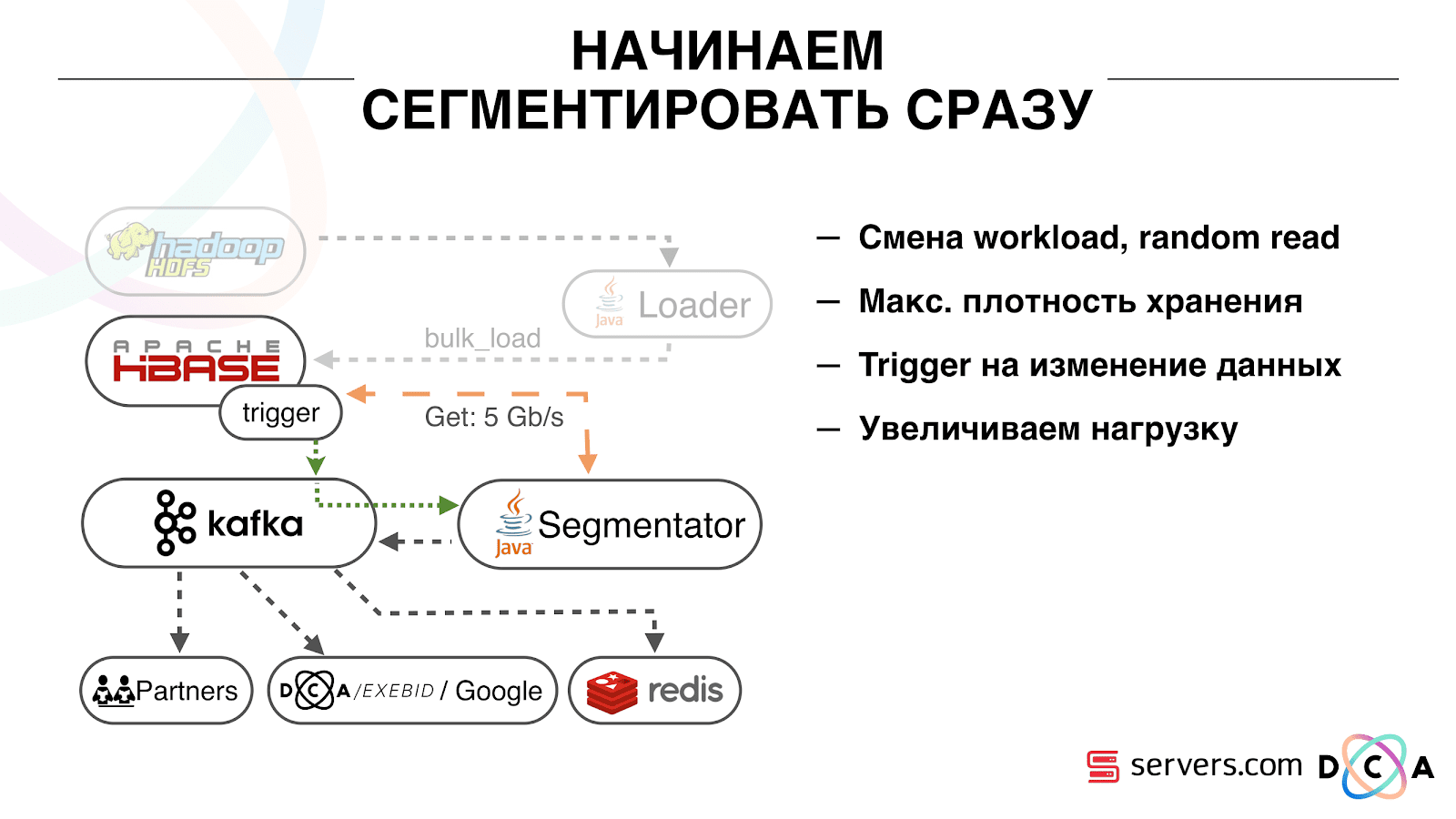
Avec les statistiques, il y a aussi un point intéressant: plus tôt, nous pourrions augmenter la valeur des compteurs dans MongoDB, combien d'utilisateurs étaient dans un certain segment pour un certain jour. Maintenant, cela ne peut pas être fait car nous analysons maintenant chaque utilisateur après avoir terminé un événement, c'est-à-dire plusieurs fois par jour.
Par conséquent, nous avons dû résoudre le problème du comptage du nombre unique d'utilisateurs dans le flux. Pour ce faire, nous avons utilisé la structure de données HyperLogLog et son implémentation dans Redis. La structure des données est probabiliste. Cela signifie que vous pouvez y ajouter des identifiants utilisateur, les identifiants eux-mêmes ne seront pas stockés, vous pouvez donc stocker des millions d'identifiants uniques dans HyperLogLog extrêmement compacts, et cela prendra jusqu'à 12 kilo-octets par clé.
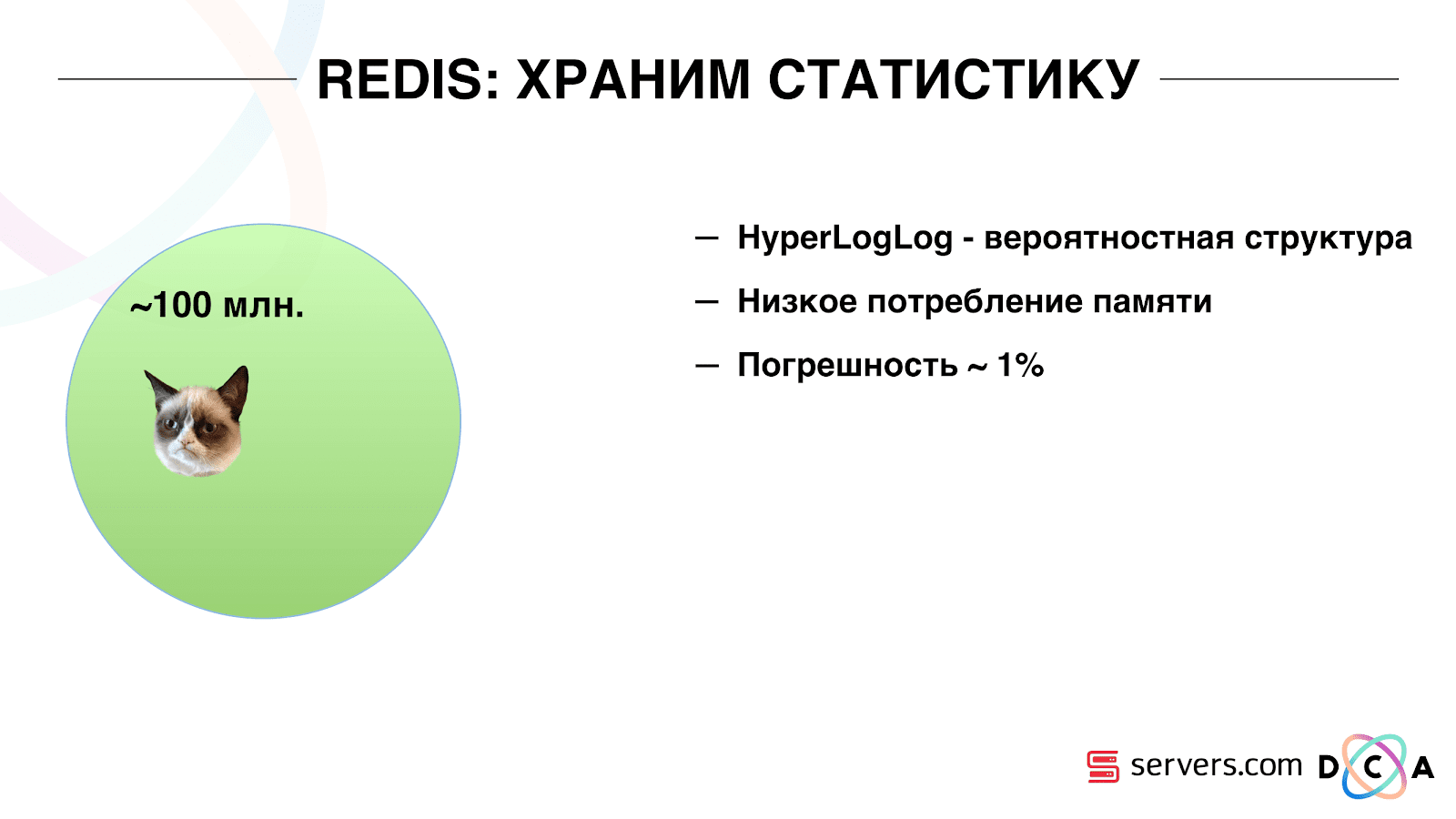
Vous ne pouvez pas obtenir les identifiants vous-même, mais vous pouvez connaître la taille de cet ensemble. Étant donné que la structure des données est probabiliste, il y a une erreur. Par exemple, si vous avez un segment «aime les chats», faisant une demande pour la taille de ce segment pour un certain jour, vous recevrez 99,2 millions et cela signifiera quelque chose comme «de 99 millions à 100 millions».
Également dans HyperLogLog, vous pouvez obtenir la taille de l'union de plusieurs ensembles. Disons que vous avez deux segments: «aime les phoques» et «aime les chiens». Disons les 100 premiers millions, le second 1 million. On peut se demander: "Combien d'animaux aiment-ils?" et obtenez la réponse "environ 101 millions" avec une erreur de 1%. Il serait intéressant de calculer combien les chats et les chiens sont aimés en même temps, mais cela est assez difficile.

D'une part, vous pouvez connaître la taille de chaque ensemble, connaître la taille de l'union, ajouter, soustraire l'un de l'autre et obtenir l'intersection. Mais du fait que la taille de l'erreur peut être supérieure à la taille de l'intersection finale, le résultat final peut être de la forme "de -50 à 50 000".

Nous avons beaucoup travaillé sur la façon d'augmenter les performances lors de l'écriture de données dans Redis. Initialement, nous avons atteint 200 000 opérations par seconde. Mais lorsque chaque utilisateur a plus de 50 segments - enregistrement d'informations sur chaque utilisateur - 50 opérations. Il s'avère que notre bande passante est assez limitée et, dans cet exemple, nous ne pouvons pas écrire d'informations sur plus de 4 000 utilisateurs par seconde, c'est plusieurs fois moins que ce dont nous avons besoin.
Nous avons créé une «procédure stockée» distincte dans Redis via Lua, nous l'avons chargée à cet endroit et avons commencé à lui passer une chaîne avec la liste complète des segments d'un utilisateur. La procédure à l'intérieur coupera la chaîne passée dans les mises à jour HyperLogLog nécessaires et enregistrera les données, nous avons donc atteint environ 1 million de mises à jour par seconde.
Un peu de hardcore: Redis est un thread unique, vous pouvez l'épingler à un cœur de processeur et une carte réseau à un autre et atteindre 15% de performances supplémentaires, en économisant sur le changement de contexte. En plus de cela, le point important est que vous ne pouvez pas simplement regrouper la structure de données, car les opérations d'obtention de la puissance des unions d'ensembles ne sont pas regroupées
Kafka est un excellent outil
Vous voyez que Kafka est notre principal outil de transport dans le système.
Il a l'essence du "sujet". C'est là que vous écrivez les données, mais essentiellement - la file d'attente. Dans notre cas, il y a plusieurs files d'attente. L'un d'eux est l'identifiant des utilisateurs qu'il faut segmenter. Le second est les résultats de segmentation.
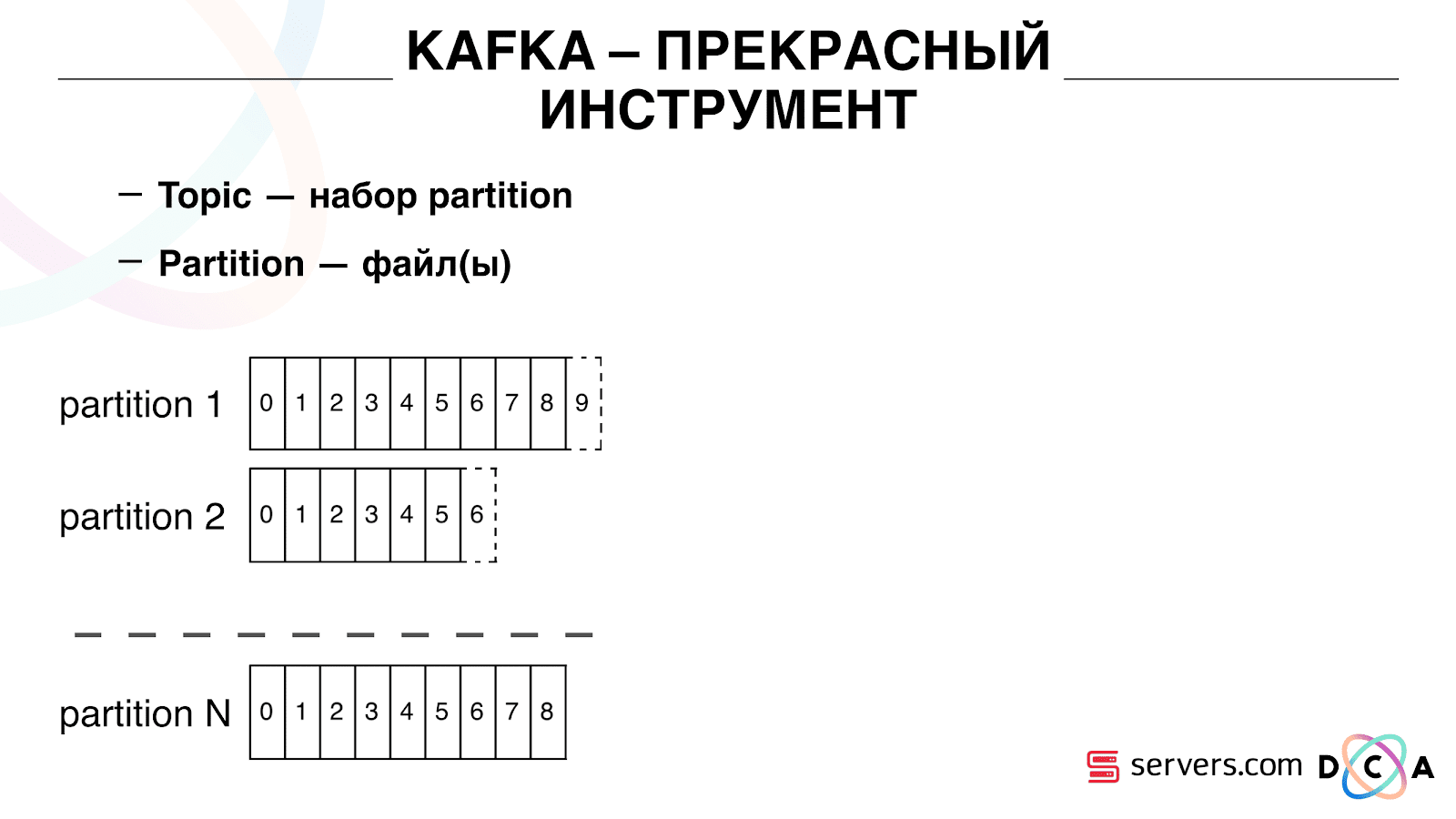
Un sujet est un ensemble de partitions. Il est divisé en quelques morceaux. Chaque partition est un fichier sur le disque dur. Lorsque vos producteurs écrivent des données, ils écrivent des morceaux de texte à la fin de la partition. Lorsque vos consommateurs lisent les données, ils lisent simplement à partir de ces partitions.
L'important est que vous puissiez connecter indépendamment plusieurs groupes de consommateurs, ils consommeront des données sans interférer les uns avec les autres. Ceci est déterminé par le nom du groupe de consommateurs et est obtenu comme suit.
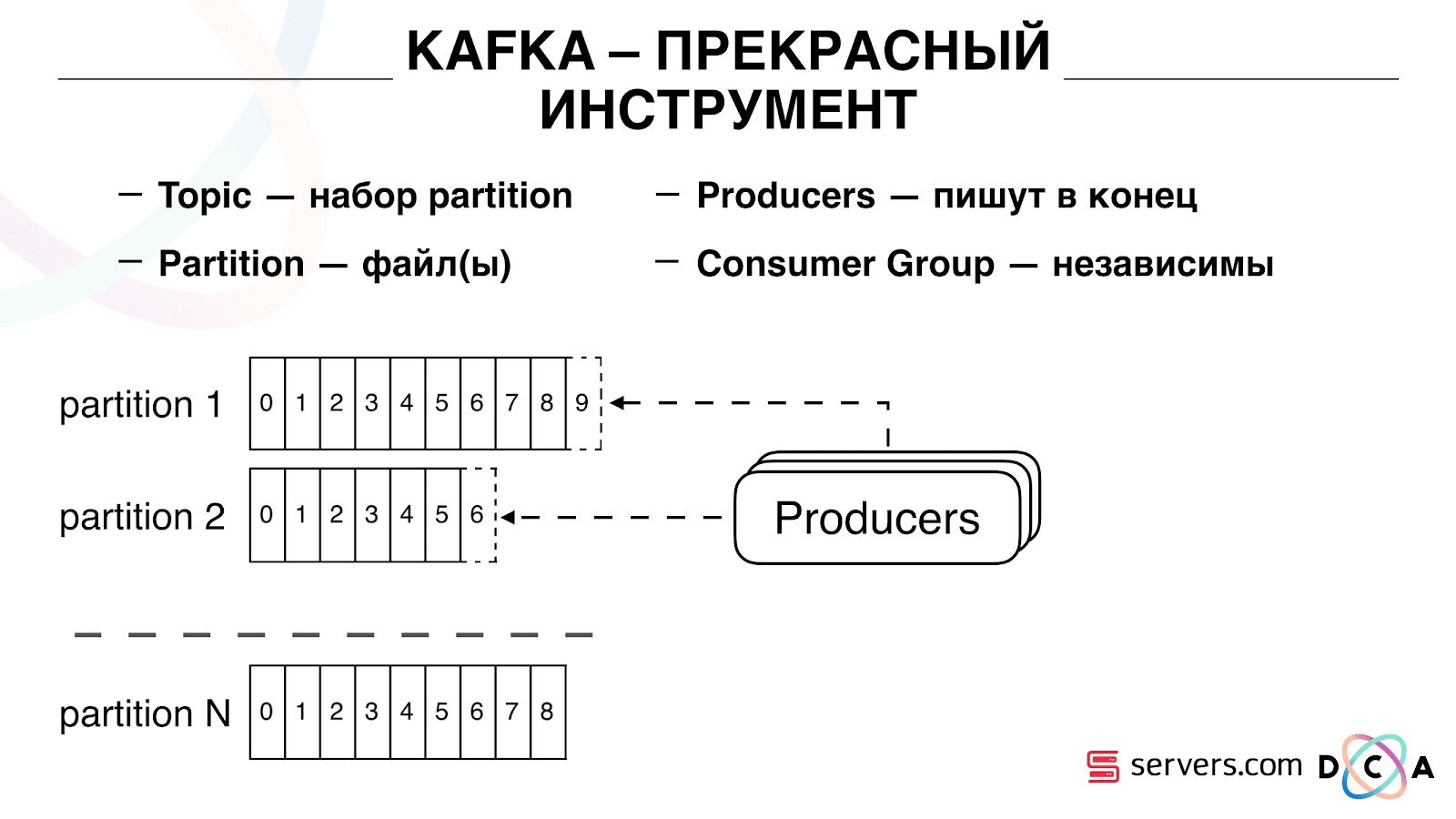
Il y a une telle chose comme décalage, la position où le groupe de consommateurs est maintenant situé sur chaque partition. Par exemple, le groupe A consomme le septième message de partition1 et le cinquième de partition2. Le groupe B, indépendant de A, a un autre décalage.
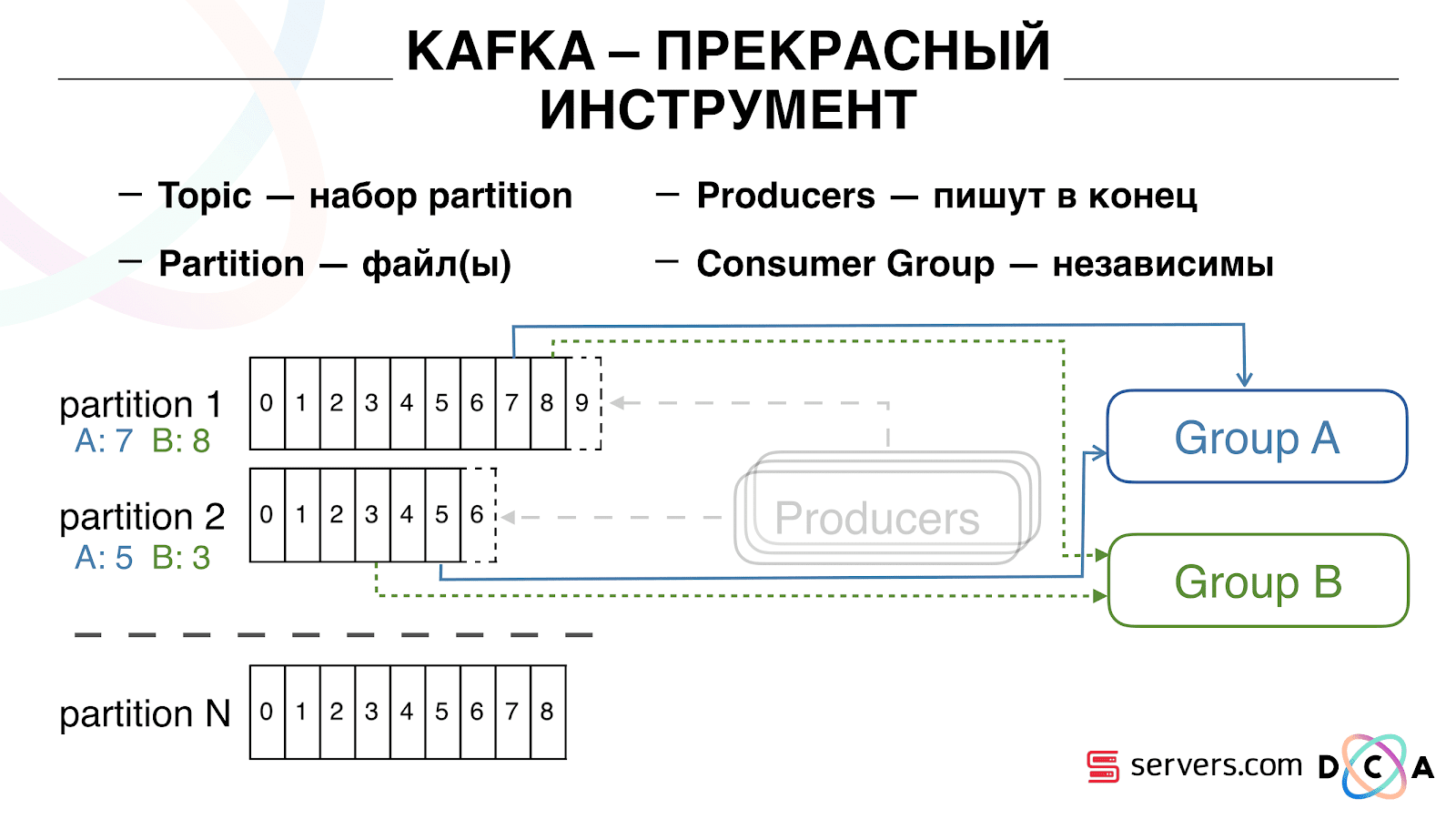 Vous pouvez faire évoluer votre groupe de consommateurs horizontalement, ajouter un autre processus ou serveur. Cela se produira une réaffectation de partition (le courtier Kafka attribuera à chaque consommateur une liste de partitions pour la consommation) Cela signifie que le premier groupe de consommateurs commencera à consommer uniquement la partition 1 et le second ne consommera que la partition 2. Si certains consommateurs meurent (par exemple, le battement de foyer ne vient pas), une nouvelle réaffectation se produit , chaque consommateur reçoit une liste de partition à jour pour traitement.
Vous pouvez faire évoluer votre groupe de consommateurs horizontalement, ajouter un autre processus ou serveur. Cela se produira une réaffectation de partition (le courtier Kafka attribuera à chaque consommateur une liste de partitions pour la consommation) Cela signifie que le premier groupe de consommateurs commencera à consommer uniquement la partition 1 et le second ne consommera que la partition 2. Si certains consommateurs meurent (par exemple, le battement de foyer ne vient pas), une nouvelle réaffectation se produit , chaque consommateur reçoit une liste de partition à jour pour traitement. C'est assez pratique. Tout d'abord, vous pouvez manipuler l'offset pour chaque groupe de consommateurs. Imaginez qu'il existe un partenaire auquel vous transférez des données de ce sujet avec les résultats de la segmentation. Il écrit qu'il a accidentellement perdu le dernier jour de données en raison d'un bogue. Et vous, pour le groupe de consommateurs de ce client, reculez simplement une journée et versez-y toute la journée de données. Nous pouvons également avoir notre propre groupe de consommateurs, nous connecter au trafic de production, regarder ce qui se passe et déboguer sur des données réelles.Ainsi, nous avons réalisé que nous avons commencé à segmenter les utilisateurs lors des changements, nous pouvons connecter indépendamment de nouveaux consommateurs, nous écrivons des statistiques et nous pouvons les regarder. Vous devez maintenant obtenir les données écrites dans HBase immédiatement après leur arrivée.
C'est assez pratique. Tout d'abord, vous pouvez manipuler l'offset pour chaque groupe de consommateurs. Imaginez qu'il existe un partenaire auquel vous transférez des données de ce sujet avec les résultats de la segmentation. Il écrit qu'il a accidentellement perdu le dernier jour de données en raison d'un bogue. Et vous, pour le groupe de consommateurs de ce client, reculez simplement une journée et versez-y toute la journée de données. Nous pouvons également avoir notre propre groupe de consommateurs, nous connecter au trafic de production, regarder ce qui se passe et déboguer sur des données réelles.Ainsi, nous avons réalisé que nous avons commencé à segmenter les utilisateurs lors des changements, nous pouvons connecter indépendamment de nouveaux consommateurs, nous écrivons des statistiques et nous pouvons les regarder. Vous devez maintenant obtenir les données écrites dans HBase immédiatement après leur arrivée.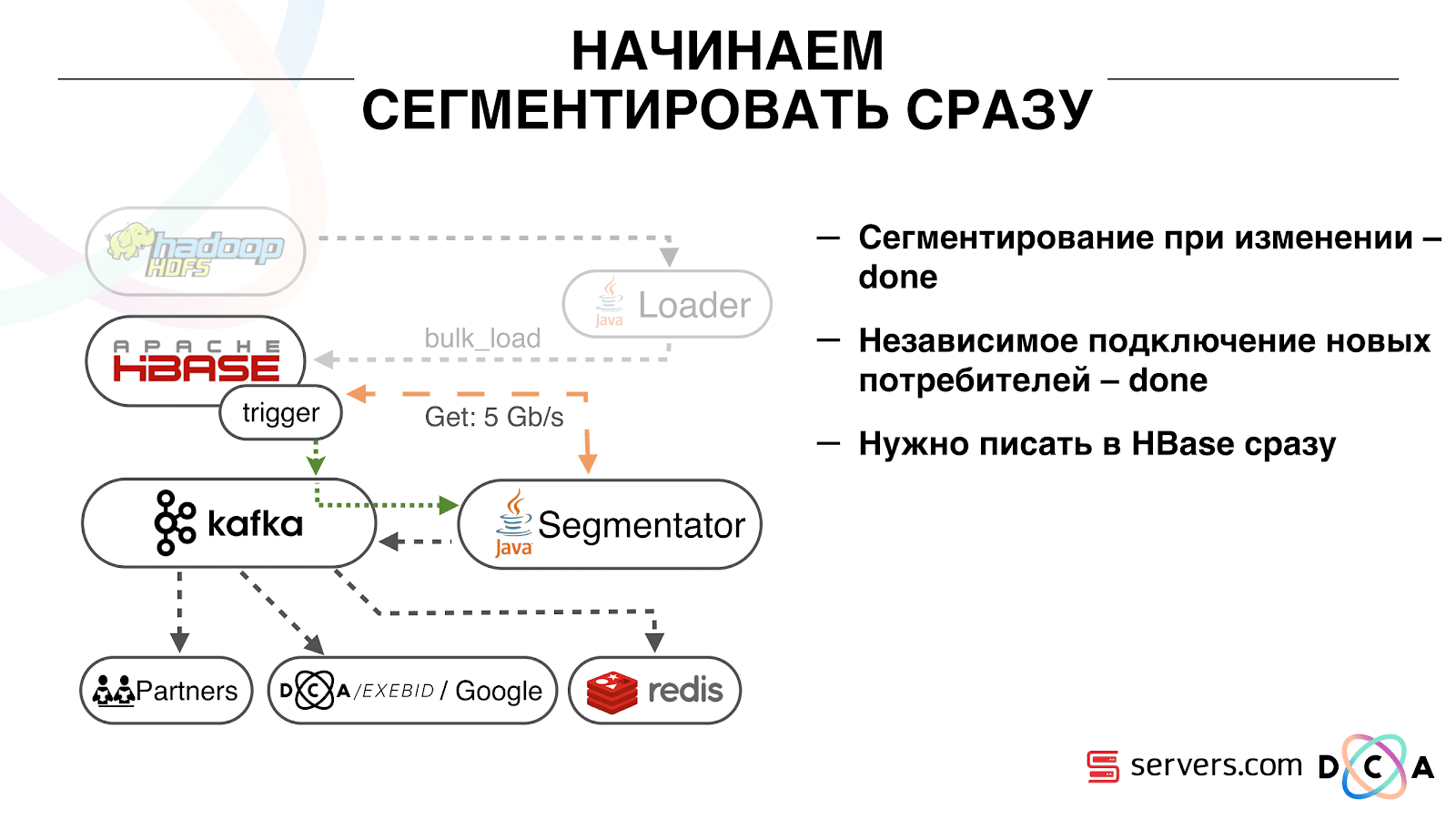 Comment nous l'avons fait. Il y avait autrefois un chargement de données par lots. Il y avait un chargeur par lots, il traitait les fichiers journaux d'activité de l'utilisateur: si l'utilisateur faisait 10 visites, le lot venait pour 10 événements, il était enregistré dans HBase en une seule opération. Il n'y avait qu'un seul événement par segmentation. Maintenant, nous voulons écrire chaque événement séparé dans le stockage. Nous augmenterons considérablement le flux d'écriture et le flux de lecture. Le nombre d'événements par segmentation augmentera également.
Comment nous l'avons fait. Il y avait autrefois un chargement de données par lots. Il y avait un chargeur par lots, il traitait les fichiers journaux d'activité de l'utilisateur: si l'utilisateur faisait 10 visites, le lot venait pour 10 événements, il était enregistré dans HBase en une seule opération. Il n'y avait qu'un seul événement par segmentation. Maintenant, nous voulons écrire chaque événement séparé dans le stockage. Nous augmenterons considérablement le flux d'écriture et le flux de lecture. Le nombre d'événements par segmentation augmentera également. La première chose que nous avons faite a été de porter HBase sur le SSD. Par des moyens standard, cela n'est pas particulièrement fait. Cela a été fait en utilisant HDFS. Vous pouvez dire qu'un répertoire spécifique sur HDFS doit se trouver sur un tel groupe de disques. Il y avait un problème cool avec le fait que lorsque nous avons amené HBase sur le SSD et l'avons doublé, tous les instantanés y sont arrivés aussi, et nos SSD se sont terminés assez rapidement.Ceci est également résolu, nous avons commencé à exporter périodiquement des instantanés vers un fichier, à écrire dans un autre répertoire HDFS et à supprimer toutes les méta-informations sur les instantanés. Si vous devez restaurer - prenez le fichier enregistré, importez et restaurez. Cette opération est très peu fréquente, heureusement.Également sur le SSD, ils ont sorti Write Ahead Log, torsadé MemStore, activé l'option de blocage de cache à l'écriture. Il vous permet de les mettre immédiatement dans le cache de bloc lors de l'enregistrement des données. C'est très pratique car dans notre cas, si nous avons enregistré les données, il est fort probable qu'elles soient immédiatement lues. Cela a également donné certains avantages.Ensuite, nous avons changé toutes nos sources de données pour écrire des données dans Kafka. Déjà à partir de Kafka, nous avons enregistré des données dans HDFS pour maintenir la compatibilité descendante, notamment pour que nos analystes puissent travailler avec des données, exécuter des tâches MapReduce et analyser leurs résultats.Nous avons connecté un groupe de consommateurs distinct qui écrit des données dans HBase. Il s'agit en fait d'un wrapper qui lit à partir de Kafka et forme les PUT dans HBase.
La première chose que nous avons faite a été de porter HBase sur le SSD. Par des moyens standard, cela n'est pas particulièrement fait. Cela a été fait en utilisant HDFS. Vous pouvez dire qu'un répertoire spécifique sur HDFS doit se trouver sur un tel groupe de disques. Il y avait un problème cool avec le fait que lorsque nous avons amené HBase sur le SSD et l'avons doublé, tous les instantanés y sont arrivés aussi, et nos SSD se sont terminés assez rapidement.Ceci est également résolu, nous avons commencé à exporter périodiquement des instantanés vers un fichier, à écrire dans un autre répertoire HDFS et à supprimer toutes les méta-informations sur les instantanés. Si vous devez restaurer - prenez le fichier enregistré, importez et restaurez. Cette opération est très peu fréquente, heureusement.Également sur le SSD, ils ont sorti Write Ahead Log, torsadé MemStore, activé l'option de blocage de cache à l'écriture. Il vous permet de les mettre immédiatement dans le cache de bloc lors de l'enregistrement des données. C'est très pratique car dans notre cas, si nous avons enregistré les données, il est fort probable qu'elles soient immédiatement lues. Cela a également donné certains avantages.Ensuite, nous avons changé toutes nos sources de données pour écrire des données dans Kafka. Déjà à partir de Kafka, nous avons enregistré des données dans HDFS pour maintenir la compatibilité descendante, notamment pour que nos analystes puissent travailler avec des données, exécuter des tâches MapReduce et analyser leurs résultats.Nous avons connecté un groupe de consommateurs distinct qui écrit des données dans HBase. Il s'agit en fait d'un wrapper qui lit à partir de Kafka et forme les PUT dans HBase.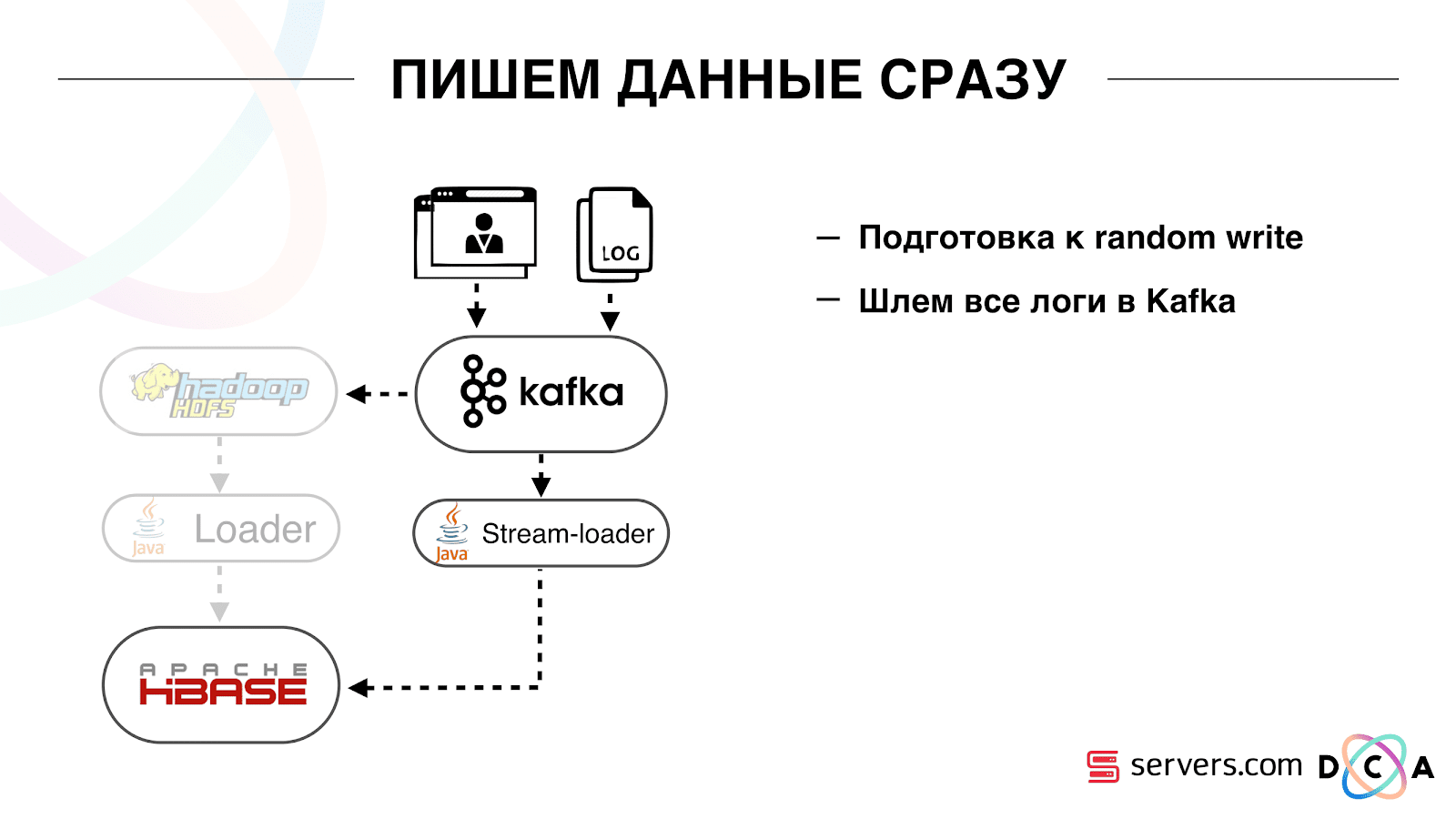 Nous avons lancé deux circuits en parallèle afin de ne pas rompre la compatibilité descendante et de ne pas dégrader les performances du système. Un nouveau schéma n'a été lancé que pour un certain pourcentage de trafic. À 10%, tout était plutôt cool. Mais à une plus grande charge, les segmenteurs ne pouvaient pas faire face au flux de segmentation.
Nous avons lancé deux circuits en parallèle afin de ne pas rompre la compatibilité descendante et de ne pas dégrader les performances du système. Un nouveau schéma n'a été lancé que pour un certain pourcentage de trafic. À 10%, tout était plutôt cool. Mais à une plus grande charge, les segmenteurs ne pouvaient pas faire face au flux de segmentation. Nous collectons la métrique "combien de messages se trouvaient dans Kafka avant sa lecture." C'est une bonne métrique. Initialement, nous avons collecté la métrique "combien de messages bruts sont maintenant", mais elle ne dit rien de spécial. Vous regardez: «J'ai un million de messages bruts», alors quoi? Pour interpréter ce million, vous devez savoir à quelle vitesse le segmentateur (consommateur) fonctionne, ce qui n'est pas toujours clair.Avec cette métrique, vous voyez immédiatement que les données sont écrites dans la file d'attente, extraites de celle-ci, et vous voyez combien elles s'attendent à être traitées. Nous avons vu que nous n'avions pas le temps de segmenter, et le message était dans la file d'attente plusieurs heures avant de le lire.Vous pourriez simplement ajouter de la capacité, mais ce serait trop
Nous collectons la métrique "combien de messages se trouvaient dans Kafka avant sa lecture." C'est une bonne métrique. Initialement, nous avons collecté la métrique "combien de messages bruts sont maintenant", mais elle ne dit rien de spécial. Vous regardez: «J'ai un million de messages bruts», alors quoi? Pour interpréter ce million, vous devez savoir à quelle vitesse le segmentateur (consommateur) fonctionne, ce qui n'est pas toujours clair.Avec cette métrique, vous voyez immédiatement que les données sont écrites dans la file d'attente, extraites de celle-ci, et vous voyez combien elles s'attendent à être traitées. Nous avons vu que nous n'avions pas le temps de segmenter, et le message était dans la file d'attente plusieurs heures avant de le lire.Vous pourriez simplement ajouter de la capacité, mais ce serait trop cher . Par conséquent, nous avons essayé d'optimiser.Auto-mise à l'échelle
Nous avons HBase. L'utilisateur change, son identifiant vole à Kafka. Le sujet est divisé en partitions, la partition cible est sélectionnée par ID utilisateur. Cela signifie que lorsque vous voyez l'utilisateur "Vasya" - il va à la partition 1. Lorsque vous voyez "Petya" - à la partition 2. C'est pratique - vous pouvez réaliser que vous verrez un consommateur sur une instance de votre service, et le second - de l'autre.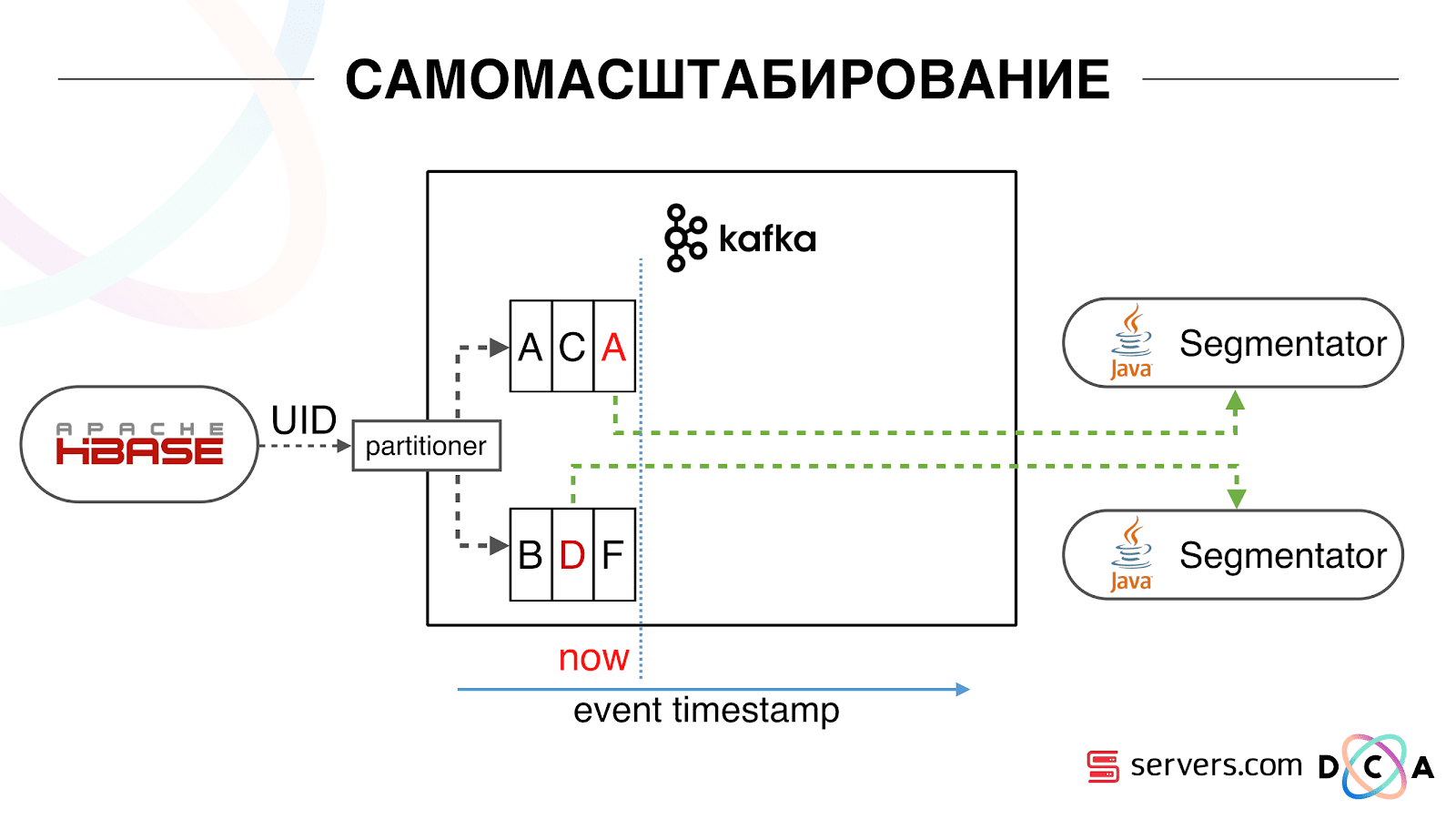 Nous avons commencé à regarder ce qui se passait. Un comportement utilisateur typique sur Internet consiste à accéder à un site Web et à ouvrir plusieurs onglets d'arrière-plan. La seconde consiste à se rendre sur le site et à faire quelques clics pour accéder à la page de destination.Nous regardons la file d'attente de segmentation et voyons ce qui suit: L'utilisateur A a visité la page. 5 autres événements viennent de cet utilisateur - chacun signifie une ouverture de page. Nous traitons chaque événement de l'utilisateur. Mais en fait, les données de HBase contiennent les 5 visites. Nous traitons les 5 visites pour la première fois, la deuxième fois, etc. - nous gaspillons les ressources du processeur.
Nous avons commencé à regarder ce qui se passait. Un comportement utilisateur typique sur Internet consiste à accéder à un site Web et à ouvrir plusieurs onglets d'arrière-plan. La seconde consiste à se rendre sur le site et à faire quelques clics pour accéder à la page de destination.Nous regardons la file d'attente de segmentation et voyons ce qui suit: L'utilisateur A a visité la page. 5 autres événements viennent de cet utilisateur - chacun signifie une ouverture de page. Nous traitons chaque événement de l'utilisateur. Mais en fait, les données de HBase contiennent les 5 visites. Nous traitons les 5 visites pour la première fois, la deuxième fois, etc. - nous gaspillons les ressources du processeur.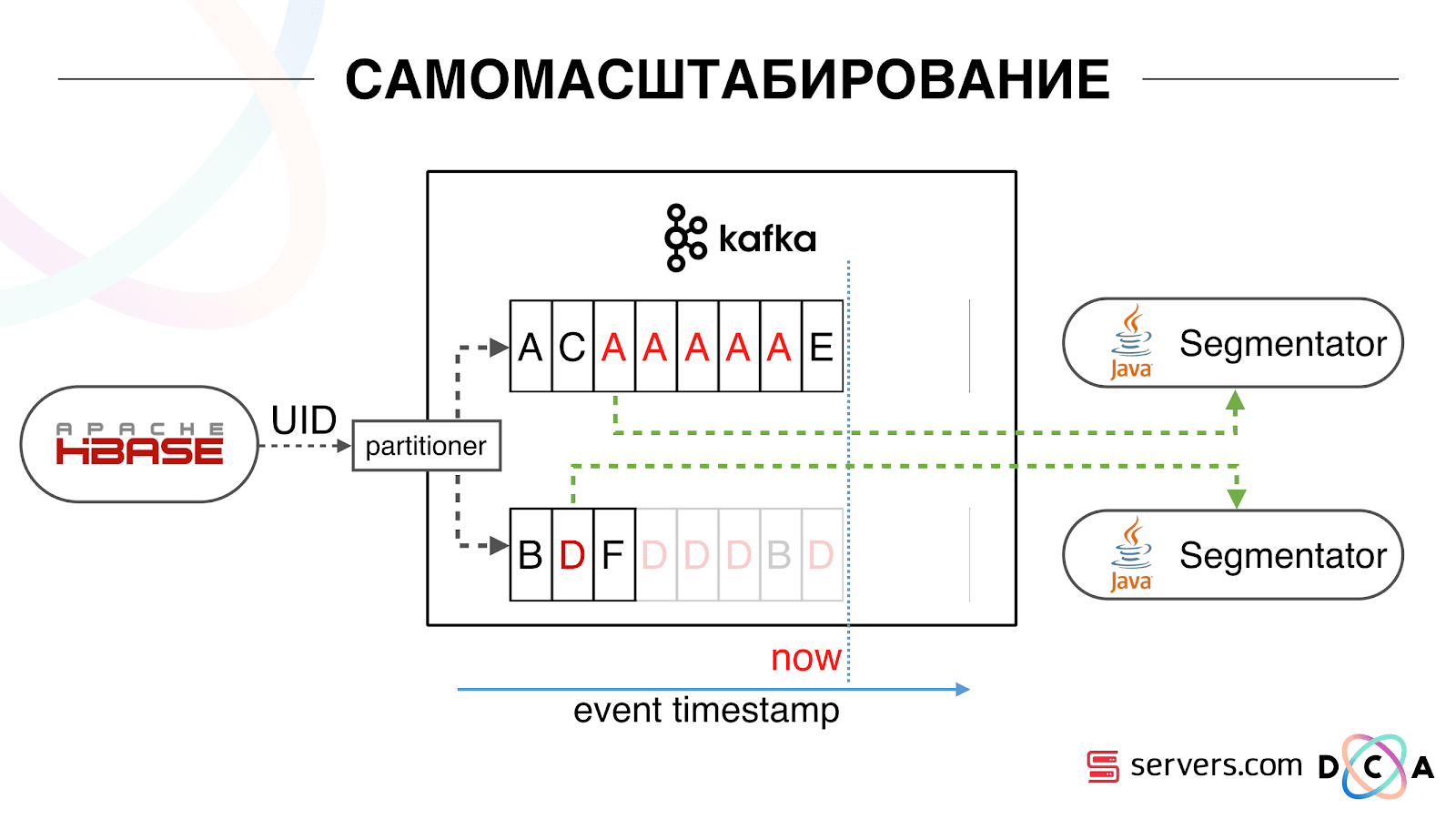 Par conséquent, nous avons commencé à stocker un certain cache local sur chacun des segmenteurs avec la date de la dernière analyse de cet utilisateur. Autrement dit, nous l'avons traité, écrit son ID utilisateur et son horodatage dans le cache. Chaque message kafka a également un horodatage - nous le comparons simplement: si l'horodatage dans la file d'attente est inférieur à la date de la dernière segmentation - nous avons déjà analysé l'utilisateur pour ces données, et vous pouvez simplement ignorer cet événement.Les événements utilisateur (Red A) peuvent être différents et ils ne fonctionnent plus. L'utilisateur peut ouvrir plusieurs onglets d'arrière-plan, ouvrir plusieurs liens d'affilée, peut-être que le site a plusieurs de nos partenaires à la fois, chacun envoyant ces données.Notre pixel peut voir la visite de l'utilisateur, puis une autre action - nous nous enverrons son casque. Cinq événements arrivent, nous traitons le premier A. rouge. Si l'événement est arrivé, il est déjà dans HBase. Nous voyons des événements, parcourons un ensemble de scripts. Nous voyons l'événement suivant, et là tous les mêmes événements, car ils sont déjà enregistrés. Nous l'exécutons à nouveau et enregistrons le cache avec la date, le comparons avec l'horodatage de l'événement.
Par conséquent, nous avons commencé à stocker un certain cache local sur chacun des segmenteurs avec la date de la dernière analyse de cet utilisateur. Autrement dit, nous l'avons traité, écrit son ID utilisateur et son horodatage dans le cache. Chaque message kafka a également un horodatage - nous le comparons simplement: si l'horodatage dans la file d'attente est inférieur à la date de la dernière segmentation - nous avons déjà analysé l'utilisateur pour ces données, et vous pouvez simplement ignorer cet événement.Les événements utilisateur (Red A) peuvent être différents et ils ne fonctionnent plus. L'utilisateur peut ouvrir plusieurs onglets d'arrière-plan, ouvrir plusieurs liens d'affilée, peut-être que le site a plusieurs de nos partenaires à la fois, chacun envoyant ces données.Notre pixel peut voir la visite de l'utilisateur, puis une autre action - nous nous enverrons son casque. Cinq événements arrivent, nous traitons le premier A. rouge. Si l'événement est arrivé, il est déjà dans HBase. Nous voyons des événements, parcourons un ensemble de scripts. Nous voyons l'événement suivant, et là tous les mêmes événements, car ils sont déjà enregistrés. Nous l'exécutons à nouveau et enregistrons le cache avec la date, le comparons avec l'horodatage de l'événement. Grâce à cela, le système a obtenu la propriété d'auto-évolutivité. L'axe des y est le pourcentage de ce que nous faisons avec les ID utilisateur lorsqu'ils nous parviennent. Vert - le travail que nous avons effectué a lancé le script de segmentation. Jaune - nous ne l'avons pas fait, car Déjà segmenté exactement ces données.
Grâce à cela, le système a obtenu la propriété d'auto-évolutivité. L'axe des y est le pourcentage de ce que nous faisons avec les ID utilisateur lorsqu'ils nous parviennent. Vert - le travail que nous avons effectué a lancé le script de segmentation. Jaune - nous ne l'avons pas fait, car Déjà segmenté exactement ces données.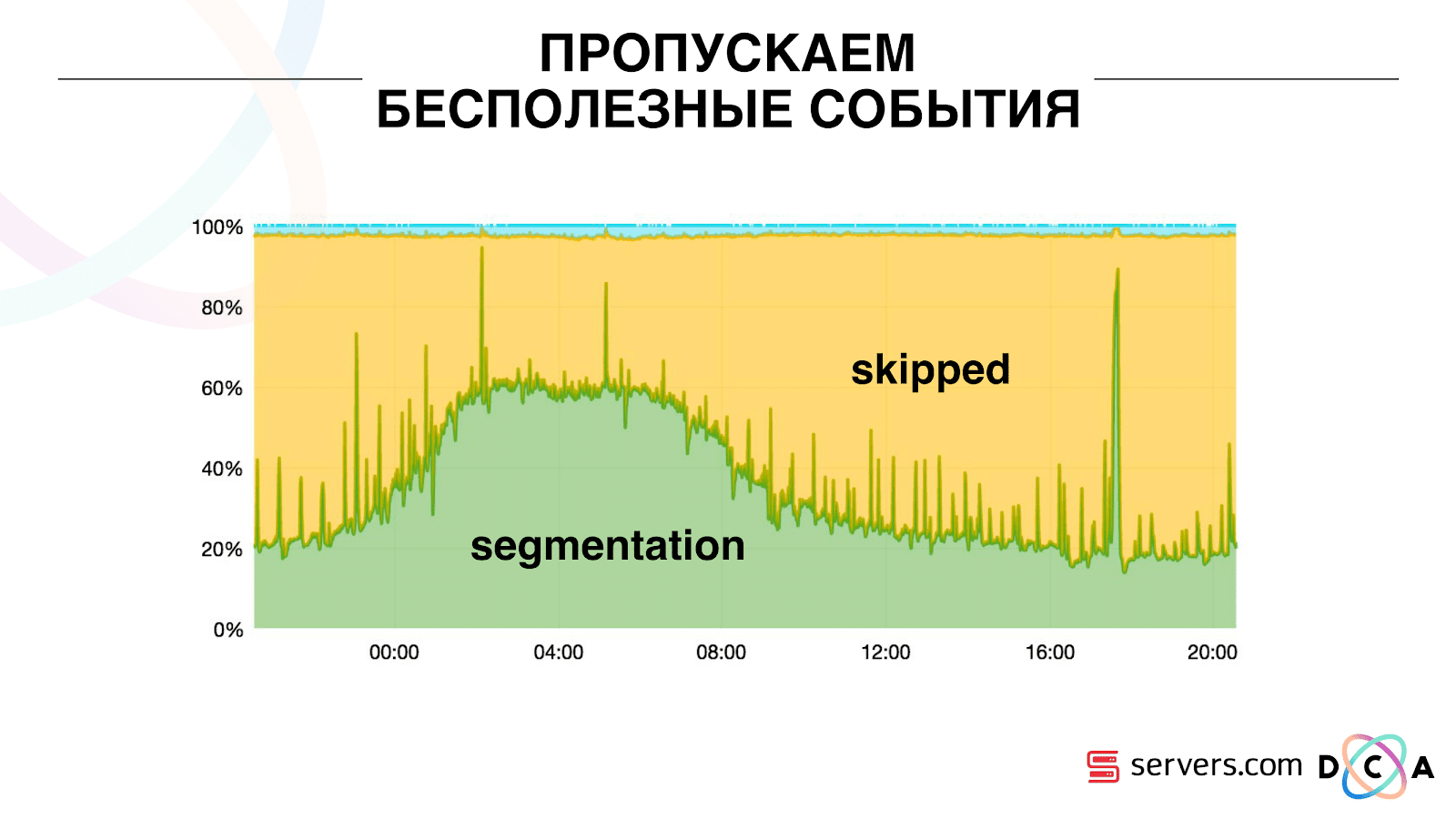 On peut voir qu'il y a des ressources la nuit, il y a moins de flux de données et vous pouvez segmenter chaque deuxième événement. Une journée de ressources plus petite et nous ne segmentons que 20% des événements. Un saut à la fin de la journée - le partenaire a téléchargé des fichiers de données que nous n'avions pas vus auparavant, et ils devaient être segmentés «honnêtement».Le système lui-même s'adapte à la croissance de la charge. Si nous avons un très gros partenaire, nous traitons les mêmes données mais un peu moins souvent. Dans ce cas, les caractéristiques du système se détérioreront le soir, la segmentation sera retardée non pas pendant 2-3 secondes, mais pendant une minute. Le matin, ajoutez les serveurs et revenez aux résultats souhaités.Ainsi, nous avons économisé environ 5 fois sur les serveurs. Maintenant, nous travaillons sur 10 serveurs, et cela prendrait donc 50 à 60.La petite chose bleue en haut, ce sont les bots. C'est la partie la plus difficile de la segmentation. Ils ont un grand nombre de visites, ils créent une très grande charge sur le fer. Nous voyons chaque bot sur un serveur séparé. Nous pouvons y collecter un cache local avec une liste noire de bots. Introduit un simple anti-fraude: si l'utilisateur fait trop de visites pendant un certain temps, alors quelque chose ne va pas avec lui, nous ajoutons à la liste noire pendant un certain temps. C'est une petite bande bleue, environ 5%. Ils nous ont permis d'économiser 30% supplémentaires sur le processeur.Ainsi, nous avons atteint ce que nous voyons l'ensemble du pipeline de traitement des données à chaque étape. Nous voyons des mesures de la quantité de message dans Kafka. Le soir, quelque chose s'estompe quelque part, le temps de traitement passe à une minute, puis il est relâché et revient à la normale.
On peut voir qu'il y a des ressources la nuit, il y a moins de flux de données et vous pouvez segmenter chaque deuxième événement. Une journée de ressources plus petite et nous ne segmentons que 20% des événements. Un saut à la fin de la journée - le partenaire a téléchargé des fichiers de données que nous n'avions pas vus auparavant, et ils devaient être segmentés «honnêtement».Le système lui-même s'adapte à la croissance de la charge. Si nous avons un très gros partenaire, nous traitons les mêmes données mais un peu moins souvent. Dans ce cas, les caractéristiques du système se détérioreront le soir, la segmentation sera retardée non pas pendant 2-3 secondes, mais pendant une minute. Le matin, ajoutez les serveurs et revenez aux résultats souhaités.Ainsi, nous avons économisé environ 5 fois sur les serveurs. Maintenant, nous travaillons sur 10 serveurs, et cela prendrait donc 50 à 60.La petite chose bleue en haut, ce sont les bots. C'est la partie la plus difficile de la segmentation. Ils ont un grand nombre de visites, ils créent une très grande charge sur le fer. Nous voyons chaque bot sur un serveur séparé. Nous pouvons y collecter un cache local avec une liste noire de bots. Introduit un simple anti-fraude: si l'utilisateur fait trop de visites pendant un certain temps, alors quelque chose ne va pas avec lui, nous ajoutons à la liste noire pendant un certain temps. C'est une petite bande bleue, environ 5%. Ils nous ont permis d'économiser 30% supplémentaires sur le processeur.Ainsi, nous avons atteint ce que nous voyons l'ensemble du pipeline de traitement des données à chaque étape. Nous voyons des mesures de la quantité de message dans Kafka. Le soir, quelque chose s'estompe quelque part, le temps de traitement passe à une minute, puis il est relâché et revient à la normale. Nous pouvons surveiller comment nos actions avec le système affectent son débit, nous pouvons voir combien le script s'exécute, où il est nécessaire d'optimiser et combien peut être enregistré. Nous pouvons voir la taille des segments, la dynamique de la taille des segments, évaluer leur association et leur intersection. Cela peut être fait pour plus ou moins les mêmes tailles de segment.
Nous pouvons surveiller comment nos actions avec le système affectent son débit, nous pouvons voir combien le script s'exécute, où il est nécessaire d'optimiser et combien peut être enregistré. Nous pouvons voir la taille des segments, la dynamique de la taille des segments, évaluer leur association et leur intersection. Cela peut être fait pour plus ou moins les mêmes tailles de segment.Qu'aimeriez-vous affiner?
Nous avons un cluster Hadoop avec quelques ressources informatiques. Il est occupé - les analystes y travaillent pendant la journée, mais la nuit, il est pratiquement libre. En général, nous pouvons conteneuriser et exécuter le segmenteur en tant que processus distinct au sein de notre cluster. Nous voulons stocker plus précisément les statistiques afin de calculer plus précisément le volume de l'intersection. Nous avons également besoin d'une optimisation sur le CPU. Cela affecte directement le coût de la décision.Pour résumer: Kafka est bon, mais, comme avec toute autre technologie, vous devez comprendre comment cela fonctionne à l'intérieur et ce qui lui arrive. Par exemple, la garantie de priorité des messages ne fonctionne qu'à l'intérieur de la partition. Si vous envoyez un message qui va à différentes partitions, il n'est pas clair dans quel ordre elles seront traitées.Les données réelles sont très importantes. Si nous n'avions pas testé sur le trafic réel, alors nous n'aurions probablement pas vu de problèmes avec les bots, avec les sessions utilisateur. Développerait quelque chose dans le vide, courrait et se coucherait. Il est important de surveiller ce que vous jugez nécessaire de surveiller et non de surveiller ce que vous ne pensez pas.Minute de publicité. Si vous avez aimé ce rapport de la conférence SmartData, veuillez noter que SmartData 2018 se tiendra à Saint-Pétersbourg le 15 octobre, une conférence pour ceux qui sont plongés dans le monde de l'apprentissage automatique, de l'analyse et du traitement des données. Le programme aura beaucoup de choses intéressantes, le site a déjà ses premiers intervenants et rapports.