Dans un
article précédent, j'ai promis de révéler plus en détail certains détails que j'avais omis lors de l'enquête [Gmail se bloque dans Chrome sur Windows - env. Per.], Y compris les tableaux de pages, les verrous, WMI et l'erreur vmmap. Maintenant, je comble ces lacunes avec des exemples de code mis à jour. Mais d'abord, décrivez brièvement l'essence.
Le fait était qu'un processus qui prend en charge
Control Flow Guard (CFG) alloue de la mémoire exécutable, tout en allouant également de la mémoire CFG que Windows ne libère jamais. Par conséquent, si vous continuez d'allouer et de libérer de la mémoire exécutable
à différentes adresses , le processus accumule une quantité arbitraire de mémoire CFG. Le navigateur Chrome fait cela, ce qui entraîne une fuite de mémoire presque illimitée et se bloque sur certaines machines.
Il convient de noter que les blocages sont difficiles à éviter si VirtualAlloc commence à s'exécuter plus d'un million de fois plus lentement que d'habitude.
En plus de CFG, il y a une autre mémoire perdue, bien que ce ne soit pas autant que le prétend vmmap.
CFG et pages
La mémoire du programme et la mémoire CFG sont finalement allouées avec des pages de 4 kilo-octets (plus à ce sujet plus tard). Étant donné que 4 Ko de mémoire CFG peuvent décrire 256 Ko de mémoire de programme (plus à ce sujet plus tard), cela signifie que si vous sélectionnez un bloc de mémoire de 256 Ko aligné sur 256 Ko, vous obtiendrez une page CFG de 4 Ko. Et si vous allouez un bloc exécutable de 4 Ko, vous obtiendrez toujours une page CFG de 4 Ko, mais la majeure partie ne sera pas utilisée.
Tout est plus compliqué si la mémoire exécutable est libérée. Si vous utilisez la fonction VirtualFree sur un bloc de mémoire exécutable qui n'est pas un multiple de 256 Ko ou non aligné à 256 Ko, le système d'exploitation doit effectuer une analyse et vérifier qu'une autre mémoire exécutable n'utilise pas une page CFG. Les auteurs de CFG ont décidé de ne pas déranger - et de simplement laisser pour toujours la mémoire CFG allouée. C’est très malheureux. Cela signifie que lorsque mon programme de test alloue puis libère 1 gigaoctet de mémoire exécutable alignée, il laisse 16 Mo de mémoire CFG.
En pratique, il s'avère que lorsque le moteur JavaScript Chrome alloue puis libère 128 Mo de mémoire exécutable alignée (pas tout a été utilisé, mais toute la plage a été allouée et immédiatement libérée), jusqu'à 2 Mo de mémoire CFG resteront alloués, bien qu'il soit trivial de la libérer entièrement . Étant donné que Chrome alloue et libère de la mémoire à plusieurs adresses aléatoires, cela entraîne le problème décrit ci-dessus.
Mémoire perdue supplémentaire
Dans tout système d'exploitation moderne, chaque processus obtient son propre espace d'adressage de mémoire virtuelle, de sorte que le système d'exploitation isole les processus et protège la mémoire. Cela se fait à l'aide d'
une unité de gestion de la mémoire (MMU) et de
tables de pages . La mémoire est divisée en pages de 4 Ko. Il s'agit de la quantité minimale de mémoire que le système d'exploitation vous offre. Chaque page est indiquée par un enregistrement de huit octets dans le tableau des pages, et les enregistrements eux-mêmes sont stockés dans des pages de 4 Ko. Chacun d'eux pointe vers un maximum de 512 pages de mémoire différentes, nous avons donc besoin d'une hiérarchie de tables de pages. Pour un espace d'adressage 48 bits dans un système d'exploitation 64 bits, le système est le suivant:
- Un tableau de niveau 1 couvre 256 To (48 bits), pointant vers 512 tableaux de niveau 2 de page différents
- Chaque table de niveau 2 couvre 512 Go, pointant vers 512 tables de niveau 3
- Chaque table de niveau 3 couvre 1 Go, pointant vers 512 tables de niveau 4
- Chaque table de niveau 4 s'étend sur 2 Mo, pointant vers 512 pages physiques
MMU indexe la table du 1er niveau dans les 9 premiers (sur 48) bits de l'adresse, les tables du 2e niveau dans les 9 bits suivants et les niveaux restants reçoivent 9 bits, c'est-à-dire seulement 36 bits. Les 12 bits restants sont utilisés pour indexer des pages de 4 kilo-octets à partir d'une table de 4e niveau. Et bien.
Si vous remplissez immédiatement tous les niveaux des tableaux, vous avez besoin de plus de 512 Go de RAM, ils sont donc remplis si nécessaire. Cela signifie que lors de l'allocation d'une page mémoire, le système d'exploitation sélectionne certaines tables de pages - de zéro à trois, selon que les adresses allouées se trouvent dans une zone précédemment inutilisée de 2 Mo, une zone précédemment inutilisée de 1 Go ou une zone précédemment inutilisée de 512 Go (tableau des pages de niveau 1). ressort toujours).
En bref, l'allocation à des adresses aléatoires est beaucoup plus coûteuse que l'allocation à des adresses proches, car dans le premier cas, les tables de pages ne peuvent pas être partagées. Les fuites de CFG sont rares, donc lorsque
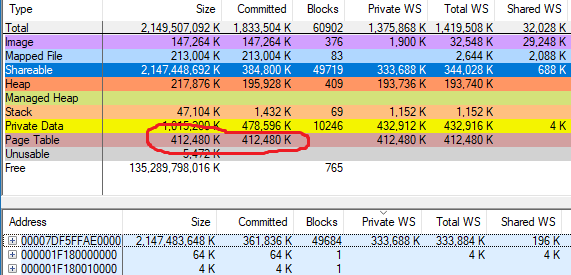
vmmap a montré
412 480 Ko de tableaux de pages utilisés dans Chrome, j'ai supposé que les chiffres étaient corrects. Voici une capture d'écran de vmmap avec la disposition de la mémoire chrome.exe de l'article précédent, mais avec la ligne Page Table:
Mais quelque chose semblait mal. J'ai décidé d'ajouter un simulateur de table de pages à mon outil
VirtualScan . Il calcule le nombre de pages de tables de pages nécessaires pour toute la mémoire allouée pendant le processus de numérisation. Il vous suffit de scanner la mémoire allouée, en ajoutant au compteur un chaque multiple de 2 Mo, 1 Go ou 512 Go.
Il a été rapidement découvert que les résultats du simulateur correspondaient à vmmap sur des processus normaux, mais pas sur des processus avec une grande quantité de mémoire CFG. La différence correspond approximativement à la mémoire CFG allouée. Pour le processus ci-dessus, où vmmap parle de 402,8 Mo (412 480 Ko) de tables de pages, mon outil affiche 67,7 Mo.
Temps d'analyse, validé, tables de pages, blocs validés
Total: 41,763 s, 1457,7 Mio, 67,7 Mio, 32112, 98 blocs de code
CFG: 41,759 s, 353,3 Mio, 59,2 Mio, 24866
J'ai vérifié l'erreur vmmap en exécutant
VAllocStress , ce qui, dans les paramètres par défaut, oblige Windows à allouer 2 gigaoctets de mémoire CFG. vmmap prétend avoir alloué 2 gigaoctets de tables de pages:
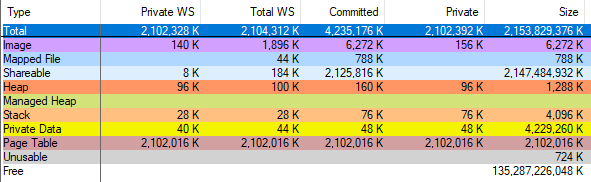
Et lorsque j'ai terminé le processus via le Gestionnaire des tâches, vmmap a montré que la quantité de mémoire allouée n'avait diminué que de 2 gigaoctets. Donc, vmmap est faux, mes calculs avec les tableaux de pages sont corrects, et après une
discussion fructueuse
sur Twitter, j'ai envoyé un rapport sur l'erreur vmmap, qui devrait être corrigé. La mémoire CFG consomme toujours beaucoup d'entrées de table de pages (59,2 Mo dans l'exemple ci-dessus), mais pas autant que le dit vmmap, et après correction, elle ne consommera rien du tout.
Qu'est-ce que CFG et CFG?
Je veux prendre un peu de recul et dire plus en détail ce qu'est le CFG.
CFG signifie Control Flow Guard. Il s'agit d'une méthode de protection contre les exploits en réécrivant les pointeurs de fonction. Lorsque CFG est activé, le compilateur et le système d'exploitation vérifient ensemble la validité de la cible de branche. Tout d'abord, l'octet de contrôle CFG correspondant est chargé à partir de la zone CFG réservée de 2 To. Le processus 64 bits dans Windows gère l'espace d'adressage de 128 To, donc la division de l'adresse par 64 vous permet de trouver l'octet CFG correspondant pour cet objet.
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];Nous avons maintenant un octet qui devrait décrire quelles adresses dans la plage de 64 octets sont des cibles de branche valides. Pour ce faire, le CFG traite l'octet comme quatre valeurs à deux bits, chacune correspondant à une plage de 16 octets. Ce nombre à deux bits (dont la valeur est de zéro à trois) est
interprété comme suit :
- 0 - toutes les cibles de ce bloc de 16 octets sont des cibles non valides de branches indirectes
- 1 - l'adresse de départ dans ce bloc de 16 octets est la cible valide de la branche indirecte
- 2 - associé aux appels CFG «supprimés» ; l'adresse est potentiellement invalide
- 3 - Les adresses non alignées dans ce bloc de 16 octets sont des cibles valides d'une branche indirecte, mais une adresse alignée de 16 octets est potentiellement invalide
Si la cible de la branche indirecte n'est pas valide, le processus se termine et l'exploit est empêché. Hourra!
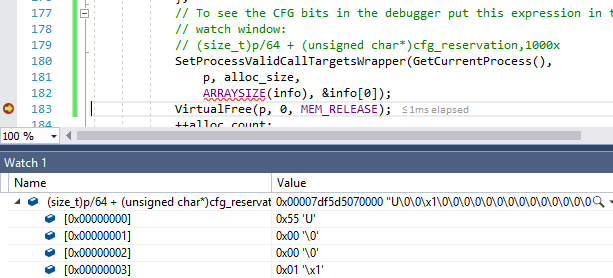
De cela, nous pouvons conclure que pour une sécurité maximale, les objectifs indirects de la branche doivent être alignés sur 16 octets, et nous pouvons comprendre pourquoi la mémoire CFG pour le processus est d'environ 1/64 de la mémoire du programme.
En fait, CFG charge 32 bits à la fois, mais ce sont des détails d'implémentation. De nombreuses sources décrivent la mémoire CFG comme un bit unique de 8 octets plutôt que comme un bit double de 16 octets. Mon explication est meilleure.
Voilà pourquoi tout va mal
Gmail se bloque pour deux raisons. Tout d'abord, l'analyse de la mémoire CFG sur Windows 10 16299 ou version antérieure est
douloureusement lente. J'ai vu comment l'analyse de l'espace d'adressage d'un processus prend 40 secondes ou plus, et littéralement 99,99% de ce temps, la mémoire CFG réservée est analysée, bien qu'elle ne représente qu'environ 75% des blocs de mémoire fixes. Je ne sais pas pourquoi l'analyse a été si lente, mais ils l'ont corrigée dans Windows 10 17134, il est donc inutile d'étudier le problème plus en détail.
Une analyse lente a provoqué un ralentissement car Gmail souhaitait une redondance CFG et WMI a maintenu le verrouillage pendant la durée de l'analyse. Mais le verrou de réservation de mémoire n'a pas été maintenu tout au long de l'analyse. Dans mon exemple, il y a environ 49 000 blocs dans la zone CFG et la fonction
NtQueryVirtualMemory , qui reçoit et libère le verrou, a été appelée une fois pour chacun d'eux. Par conséquent, le verrou a été obtenu et libéré ~ 49 000 fois et chaque fois a été maintenu pendant moins de 1 milliseconde.
Mais bien que le verrou ait été libéré 49 000 fois, le processus Chrome pour une raison quelconque n'a pas pu l'obtenir. C'est injuste!
Voilà l'essence du problème. Comme je l'ai écrit la dernière fois:
C'est parce que les verrous Windows sont intrinsèquement injustes - et si le thread libère le verrou et le demande immédiatement à nouveau, il peut l'obtenir pour toujours.
Un verrouillage équitable signifie que deux fils concurrents le recevront à leur tour. Mais cela signifie beaucoup de changements de contexte coûteux, donc pendant longtemps le verrou ne sera pas utilisé.

Les verrous injustes sont moins chers et ne font pas attendre les fils. Ils capturent simplement la serrure, comme mentionné dans
l'article de Joe Duffy . Il écrit également:
L'introduction de verrous injustes peut sans aucun doute entraîner la faim. Mais statistiquement, le temps dans les systèmes parallèles a tendance à être si variable que chaque thread recevra finalement un tour pour exécution, d'un point de vue probabiliste.
Comment corréler la déclaration de Joe de 2006 sur la rareté de la faim avec mon expérience sur un problème 100% reproductible et durable? Je pense que la principale raison est ce qui s'est passé en 2006. Intel a
publié Core Duo et les ordinateurs multicœurs sont omniprésents.
Après tout, il s'avère que ce problème de faim ne se produit que sur un système multicœur! Dans un tel système, le thread WMI libérera le verrou, signalera au thread Chrome de se réveiller et continuera. Étant donné que le flux WMI est déjà en cours d'exécution, il présente un «handicap» devant le flux Chrome, il peut donc facilement appeler à nouveau
NtQueryVirtualMemory et obtenir à nouveau le verrou avant que Chrome ait la possibilité de le faire.
De toute évidence, dans un système monocœur, un seul thread peut fonctionner à la fois. En règle générale, Windows augmente la priorité d'un nouveau thread, et l'augmentation de la priorité signifie que lorsque le verrou est libéré, le nouveau thread Chrome sera prêt et
devancera immédiatement
le thread WMI. Cela donne au thread Chrome beaucoup de temps pour se réveiller et obtenir un verrou, et la faim ne vient jamais.
Tu comprends? Dans un système multicœur, une augmentation de priorité dans la plupart des cas n'affecte pas le flux WMI, car il s'exécutera sur un noyau différent!
Cela signifie qu'un système avec des cœurs supplémentaires peut
répondre plus lentement qu'un système avec la même charge de travail et moins de cœurs. Une autre conclusion est curieuse: si mon ordinateur avait une lourde charge - des threads de la priorité correspondante, fonctionnant sur tous les cœurs de processeur - alors les blocages pourraient être évités (n'essayez pas de répéter cela à la maison).
Ainsi,
les verrous injustes augmentent la productivité, mais peuvent entraîner la faim. Je soupçonne que la solution pourrait être ce que j'appelle des verrous "parfois équitables". Disons que 99% du temps, ils seront injustes, mais dans 1%, ils verrouillent un autre processus. Cela permettra de préserver les avantages de la productivité avec plus, en évitant le problème de la faim. Auparavant, les verrous dans Windows étaient distribués équitablement et vous pouvez probablement y revenir partiellement, en trouvant l'équilibre parfait. Avertissement: je ne suis pas un expert des verrous ou un ingénieur du système d'exploitation, mais je suis intéressé à entendre des réflexions à ce sujet, et au moins je
ne suis
pas le premier à offrir quelque chose comme ça .
Linus Torvalds a récemment apprécié l'importance des serrures équitables:
ici et
ici . Il est peut-être temps de changer également Windows.
Pour résumer : le verrouillage pendant quelques secondes n'est pas bon, il limite la simultanéité. Mais sur les systèmes multicœurs avec des verrous injustes, le retrait puis la réception immédiate du verrou se comportent
exactement comme ça - les autres threads n'ont aucun moyen de fonctionner.
Presque un échec avec ETW
Pour toutes ces recherches, je me suis appuyé sur le traçage ETW, j'ai donc eu un peu peur quand il s'est avéré au début de l'enquête que Windows Performance Analyzer (WPA) ne pouvait pas charger les caractères Chrome. Je suis sûr que la semaine dernière, tout a fonctionné. Que s'est-il passé ...
Il est arrivé que Chrome M68 soit sorti, et il a été lié à l'aide de lld-link au lieu de l'éditeur de liens VC ++. Si vous exécutez
dumpbin et regardez les informations de débogage, vous verrez:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdbEh bien, WPA n'aime probablement pas ces barres obliques. Mais cela n'a toujours pas de sens, car j'ai changé l'éditeur de liens en lld-link, et je me souviens que j'ai testé WPA avant cela, alors qu'est-ce qui s'est passé ...
Il s'est avéré que la raison en était dans la nouvelle version WPA 17134. J'ai testé la disposition lld-Link - et cela a bien fonctionné dans WPA 16299. Quelle coïncidence! Le nouveau lieur et le nouveau WPA n'étaient pas compatibles.
J'ai installé l'ancienne version de WPA pour continuer l'enquête (xcopy à partir d'une machine avec l'ancienne version) et j'ai signalé un
bogue de lld-link , que les développeurs ont rapidement corrigé. Vous pouvez maintenant revenir au WPA 17134 lorsque le M69 est assemblé avec un linker fixe.
Wmi
Le déclencheur de gel WMI est un
composant logiciel enfichable Windows Management Instrumentation , et je ne suis pas bon dans ce domaine. J'ai trouvé qu'en
2014 ou avant, quelqu'un a rencontré le problème d'une utilisation importante du processeur dans
WmiPrvSE.exe dans
perfproc! GetProcessVaData , mais ils n'ont pas fourni suffisamment d'informations pour comprendre les causes du bogue. À un moment donné, j'ai fait une erreur et j'ai essayé de comprendre ce qu'une folle demande WMI pouvait bloquer Gmail pendant quelques secondes. J'ai connecté
quelques experts à l'enquête et j'ai passé beaucoup de temps à essayer de trouver cette requête magique. J'ai enregistré l'activité
Microsoft-Windows-WMI-Activity dans des traces ETW, expérimenté avec PowerShell pour trouver toutes les requêtes Win32_Perf, et me suis perdu dans quelques autres manières détournées qui sont trop ennuyeuses pour être discutées. À la fin, j'ai constaté qu'un blocage de Gmail a provoqué ce compteur,
Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly , déclenché par un PowerShell sur une seule ligne:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
Je suis alors devenu
encore plus confus à cause du nom du compteur ("cher"? Vraiment?) Et parce que ce compteur apparaît et disparaît en fonction de facteurs que je ne comprends pas.
Mais les détails de WMI n'ont pas d'importance. WMI n'a rien fait de mal - pas vraiment - il a juste scanné la mémoire. L'écriture de votre propre code de numérisation s'est avérée beaucoup plus utile pour étudier le problème.
Tracas pour Microsoft
Chrome a publié un patch, le reste est pour Microsoft.
Accélérez la numérisation de la région CFG - OK, c'est fait- Libérez de la mémoire CFG lorsque la mémoire exécutable est libérée - au moins dans le cas de l'alignement 256K, c'est facile
- Considérez un indicateur permettant d'allouer de la mémoire exécutable sans mémoire CFG, ou utilisez PAGE_TARGETS_INVALID à cet effet. Notez que le manuel Windows Internals Part 1 7th Edition dit que "vous devez sélectionner les pages [CFG] avec au moins un bit défini {1, X}" - si Windows 10 l'implémente, alors l'indicateur PAGE_TARGETS_INVALID (qui est actuellement utilisé par le moteur v8 ) évitera l'allocation de mémoire
- Correction du calcul des tables de pages dans vmmap pour les processus avec un grand nombre d'allocations CFG
Mises à jour du code
J'ai mis à jour les
exemples de code , en particulier VAllocStress. Il y a 20 lignes incluses pour montrer comment trouver une réservation CFG pour un processus. J'ai également ajouté du code de test qui utilise
SetProcessValidCallTargets pour vérifier la valeur des bits CFG et démontrer les astuces nécessaires pour les appeler avec succès (indice: appeler via GetProcAddress est susceptible de violer CFG!)