Bonjour chers collègues.
Nous venons de traduire un livre intéressant de Brendan Burns, qui parle des modèles de conception pour les systèmes distribués

En outre, la traduction du livre "
Mastering Kubernetes " (2e édition)
bat déjà son plein et le livre de l'auteur sur Docker est sur le point d'être publié en septembre, et il y aura un article séparé à ce sujet.
Nous pensons que le prochain arrêt sur ce chemin est un livre sur Prométhée, donc aujourd'hui nous attirons votre attention sur la traduction d'un court article de Björn Wenzel sur l'interaction étroite entre Prométhée et Kubernetes. N'oubliez pas de participer à l'enquête.
La surveillance du cluster Kubernetes est une activité très importante. Le cluster contient une tonne d'informations qui vous permet de répondre aux questions de la catégorie: combien de mémoire et d'espace disque sont disponibles maintenant, comment cpu est-il activement utilisé? Quel conteneur consomme combien de ressources? Cela inclut également des questions sur l'état des applications en cours d'exécution dans le cluster.
Un des outils tenus pour un tel travail s'appelle Prométhée. Il est pris en charge par la Cloud Native Computing Foundation, à l'origine Prometheus a été développé par SoundCloud. Conceptuellement, Prometheus est très simple:
L'architecture
Le serveur Prometheus peut fonctionner, par exemple, dans un cluster Kubernetes et recevoir la configuration via un fichier spécial. Cette configuration, en particulier, contient des informations sur l'emplacement du terminal à partir duquel collecter les données après l'intervalle spécifié. Ensuite, le serveur Prometheus demande des métriques à ces terminaux dans un format spécial (elles sont généralement disponibles sur
/metrics ) et les stocke dans une base de données de séries chronologiques. Voici un bref exemple: un petit fichier de configuration demandant des métriques à partir d'un module
node_exporter déployé en tant qu'agent sur chaque nœud:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
Nous définissons d'abord le nom du travail
job_name , puis ce nom peut être utilisé pour demander des mesures dans Prometheus, puis l'
scrape_interval données
scrape_interval et un groupe de serveurs exécutant
node_exporter . Maintenant, Prometheus demandera toutes les 15 secondes au serveur le
path /metrics d'
path /metrics aux métriques actuelles. Cela ressemble à ceci:
Tout d'abord, le nom de la métrique est donné, puis la signature (informations entre accolades) et, enfin, la valeur de la métrique. Le plus intéressant est la fonction de recherche de ces métriques. Prometheus dispose d'un
langage de requête très puissant à cet effet.
L'idée principale de Prometheus, déjà décrite ci-dessus, est la suivante: Prometheus à un intervalle donné interroge le port pour les métriques et les stocke dans une base de données de séries chronologiques. Si Prometheus ne peut pas supprimer les métriques lui-même, il existe une autre fonctionnalité appelée pushgateway. La passerelle pushgateway accepte les métriques envoyées par des travaux externes et Prometheus collecte les informations de cette passerelle à un intervalle spécifié.
Un autre composant facultatif de l'architecture Prometheus est le
alertmanager . Le composant
alertmanager permet de fixer des limites, et en cas de dépassement, d'envoyer des notifications par e-mail, slack ou opsgenie.
De plus, le serveur Prometheus contient de nombreuses
fonctionnalités intégrées , par exemple, il peut demander des instances ec2 sur l'API Amazon ou demander des pods, des nœuds et des services à Kubernetes. Il a également de nombreux
exportateurs , par exemple, le
node_exporter susmentionné. Ces exportateurs peuvent travailler, par exemple, sur le nœud où une application telle que MySQL est installée et à un intervalle donné pour interroger l'application pour les métriques et les fournir sur le terminal / métriques, et le serveur Prometheus peut collecter ces métriques à partir de là.
De plus, il n'est pas difficile d'écrire votre propre exportateur - par exemple, pour une application qui fournit des métriques telles que des informations jvm. Il existe, par exemple, une telle
bibliothèque développée par Prometheus pour exporter de telles métriques. Cette bibliothèque peut être utilisée conjointement avec Spring et vous permet également de définir vos propres métriques. Voici un exemple de la page
client_java :
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
Il s'agit d'une métrique décrivant la durée de la méthode, et d'autres métriques peuvent désormais être fournies via le terminal ou transmises via pushgateway.
Utilisation dans le cluster Kubernetes
Comme je l'ai mentionné, pour utiliser Prometheus dans le cluster Kubernetes, il existe des capacités intégrées pour supprimer des informations du foyer, du nœud et du service. Plus intéressant encore, Kubernetes est spécialement conçu pour fonctionner avec Prometheus. Par exemple,
kubelet et
kube-apiserver fournissent
kube-apiserver métriques
kube-apiserver dans Prometheus, donc la surveillance est très simple.
Dans cet exemple, pour commencer, j'utilise le tableau de barre officiel.
Pour moi, j'ai un peu changé la configuration du graphique de barre par défaut. Tout d'abord, j'avais besoin d'activer
rbac dans l'installation de Prometheus, sinon Prometheus n'était pas en mesure de collecter des informations à partir de
kube-apiserver . Par conséquent, j'ai écrit mon propre fichier values.yaml, qui décrit comment le graphique de barre doit être affiché.
J'ai fait les changements les plus simples:
alertmanager.enabled: false , c'est-à-dire annulé le déploiement d'alertemanager dans le cluster (je n'allais pas utiliser alertmanager, je pense qu'il est plus facile de configurer des alertes avec Grafana)kubeStateMetrics.enabled: false Je pense que ces mesures ne renvoient que quelques informations sur le nombre maximal de foyers. Lorsque vous démarrez le système pour la première fois, ces informations ne sont pas importantes pour moiserver.persistentVolume.enabled: false jusqu'à ce qu'un volume persistant soit configuré par défaut- J'ai changé la configuration de la collecte d'informations dans Prometheus, comme cela a été fait dans la demande de pull sur github . Le fait est que dans Kubernetes v1.7, les métriques cAdvisor fonctionnent sur un port différent.
Après cela, vous pouvez démarrer Prometheus à l'aide de Helm:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yamlNous installons donc le serveur Prometheus, et sur chaque nœud - installez-le sous node_exporter. Vous pouvez maintenant accéder à l'interface graphique Web de Prometheus et voir quelques informations:
kubectl port-forward <prometheus-server-pod> 9090La capture d'écran suivante montre à quelles fins Prometheus collecte des informations (état / cibles) et quand les informations ont été prises plusieurs fois au cours de la dernière:
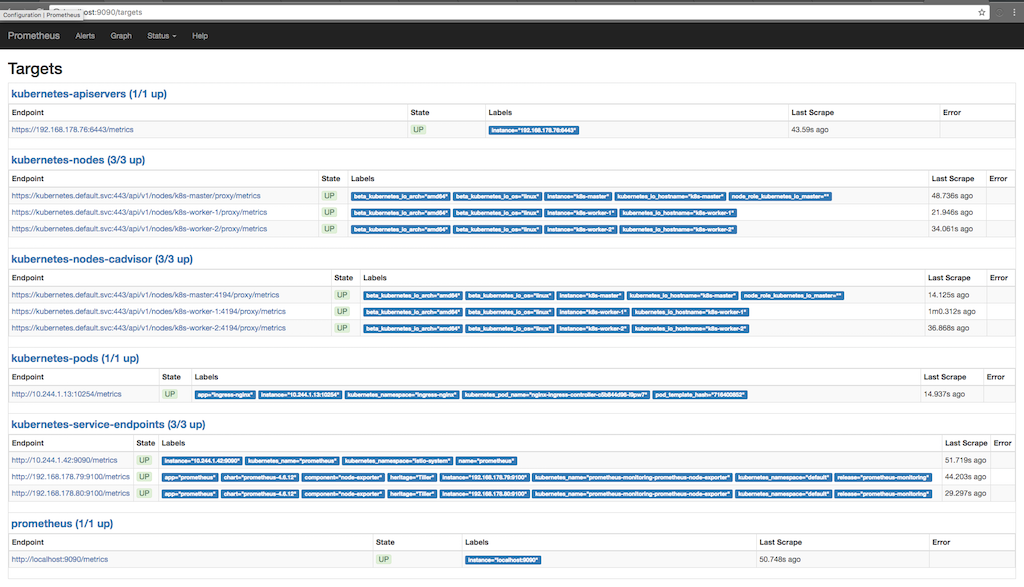
Ici, vous pouvez voir comment Prometheus demande des métriques à apiserver, à des nœuds, à un conseiller qui s'exécute sur des nœuds et des points de terminaison de service kubernetes. Vous pouvez voir les métriques en détail en allant dans Graph et en écrivant une requête pour afficher les informations qui nous intéressent:

Ici, par exemple, nous voyons du stockage gratuit au point de montage «/». En bas du diagramme, des signatures sont ajoutées qui sont ajoutées par Prometheus ou déjà disponibles sur node_exporter. Nous utilisons ces signatures pour demander uniquement le point de montage «/».
Mesures personnalisées avec annotations
Comme déjà montré dans la première capture d'écran, où les objectifs pour lesquels Prometheus demande des métriques sont dérivés, il existe également une métrique pour le foyer fonctionnant dans le cluster. L'une des fonctionnalités intéressantes de Prometheus est la capacité de prendre des informations de foyers entiers. Si le conteneur dans l'âtre fournit des métriques Prometheus, nous pouvons collecter ces métriques à l'aide de Prometheus automatiquement. La seule chose dont nous devons nous occuper est de fournir à l'installation deux annotations; dans mon cas,
nginx-ingress-controller fait hors de la boîte:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
Ici, nous voyons que le modèle de déploiement est livré avec deux annotations Prometheus. Le premier décrit le port par lequel Prometheus doit demander des mesures, et le second active la fonctionnalité de collecte de données. Désormais, Prometheus demande aux
Kubernetes Api-Server annotés de collecter des informations et essaie de collecter des informations à partir du terminal / des métriques.
Travail fédéré
Nous avons un projet dans lequel Prometheus est utilisé en mode fédéré. L'idée est la suivante: nous collectons uniquement les informations accessibles uniquement depuis le cluster (ou il est plus facile de collecter ces informations depuis le cluster), activons le mode fédéré et obtenons ces informations en utilisant le deuxième Prometheus installé en dehors du cluster. Ainsi, il est possible de collecter des informations à partir de plusieurs clusters Kubernetes à la fois, en capturant également d'autres composants qui ne sont pas accessibles depuis ce cluster ou qui ne sont pas liés à ce cluster. De plus, il n'est pas nécessaire de stocker les données collectées dans le cluster pendant une longue période, et si quelque chose ne va pas avec le cluster, nous pouvons collecter des informations, par exemple, node_exporter, de l'extérieur du cluster.