Bonjour, Habr! Aujourd'hui, je veux parler de la façon dont l'apprentissage en profondeur nous aide à mieux comprendre l'art. L'article est divisé en parties conformément aux tâches que nous avons résolues:
- rechercher une image dans la base de données à partir d'une photo prise par un téléphone mobile;
- détermination du style et du genre d'une image qui n'est pas dans la base de données.
Tout cela devait faire partie du service de base de données Arthive et de ses applications mobiles.
La tâche d'identifier les peintures était de trouver l'image correspondante à partir de l'image provenant de l'application mobile dans la base de données, en y consacrant moins d'une seconde. Le traitement entièrement dans l'appareil mobile a été exclu au stade de l'étude préalable à la conception. De plus, il s'est avéré qu'il est impossible d'effectuer de manière garantie sur un appareil mobile la séparation de l'image de l'arrière-plan dans des conditions de prise de vue réelles. Par conséquent, nous avons décidé que notre service accepterait la photo entière du téléphone mobile comme entrée, avec toutes les distorsions, le bruit et le chevauchement partiel possible.

Allons-nous aider Dasha à trouver ces peintures dans une base de données de plus de 200 000 images?
La base d' art d' Arthive comprend près de 250 000 images, ainsi que diverses métadonnées. La base est constamment mise à jour - de dizaines à des centaines d'images par jour. Même pompées avec une résolution limitée (pas plus de 1400 pixels sur la plupart des côtés), les images occupent plus de 80 gigaoctets. Malheureusement, la base de données est «sale»: il y a des fichiers cassés ou trop petits, des images non alignées et non traitées, des images en double. Cependant, dans l'ensemble, ce sont de bonnes données.
Comparaison de tableaux
Voyons à quoi ressemblent les images de la base de données:
Fondamentalement, les images de la base de données sont alignées, recadrées aux bordures de la toile, les couleurs sont préservées.
Et voici à quoi pourraient ressembler les demandes des appareils mobiles:

Les couleurs sont presque toujours déformées - un éclairage complexe est trouvé, des reflets sont présents, même des reflets d'autres peintures dans le verre sont trouvés. Les images elles-mêmes sont déformées en perspective, peuvent être partiellement recadrées ou, au contraire, occuper moins de la moitié de l'image, peuvent être partiellement fermées, par exemple, par des personnes.
Afin d'identifier les images, vous devez pouvoir comparer les images des requêtes avec les images de la base de données.
Pour comparer les images sujettes à la distorsion de perspective et à la distorsion des couleurs, nous utilisons la correspondance des points clés. Pour ce faire, nous trouvons des points clés avec des descripteurs sur les images, trouvons leur correspondance, puis affichons de manière homographique les points correspondants en utilisant la méthode RANSAC. Cela se fait généralement de la même manière que celle décrite dans l'exemple OpenCV . Si le nombre de points «antérieurs» trouvés par RANSAC est suffisamment grand et que la transformation homographique trouvée semble plausible (n'a pas de forte échelle ou de rotation), alors nous pouvons supposer que les images souhaitées sont une seule et même image sujette à des distorsions de perspective .
Un exemple de cartographie des points clés:

Exemple de correspondance négative Comparaison des peintures de l'exemple ci-dessus Bien sûr, la recherche de points clés est généralement un processus assez lent, mais pour rechercher dans la base de données, vous pouvez trouver à l'avance les points clés de toutes les images et en enregistrer certaines. Dans nos expériences, nous sommes arrivés à la conclusion que moins de 1000 points suffisent pour une recherche fiable de peintures. Lorsque vous utilisez 64 octets par point (coordonnées + descripteur AKAZE) pour stocker 1024 points, 64 Ko par image ou environ 15 Go par base suffisent.
La comparaison des images par points clés dans notre cas a pris environ 15 ms, c'est-à-dire que pour une énumération complète d'une base de données de 250 000 images, cela prend environ 1 heure. C’est beaucoup.
D'un autre côté, si nous apprenons à sélectionner rapidement dans l'ensemble de la base de données plusieurs (disons 100) des candidats les plus probables, nous atteindrons le délai cible de 1 seconde par demande.
Classement de similarité
Les réseaux de convolution profonds se sont imposés comme un bon moyen de rechercher des images similaires. Le réseau est utilisé pour extraire des entités et calculer sur leur base un descripteur qui a la propriété que la distance (euclidienne, cosinus ou autre) entre les descripteurs d'images similaires sera moindre que pour des images différentes.
Vous pouvez entraîner le réseau de telle sorte que pour l'image de l'image de la base et son image déformée de la photo, il produise des descripteurs proches et pour différentes images - plus éloignées. En outre, un tel réseau est utilisé pour calculer des descripteurs de toutes les images dans la base de données et des descripteurs de photos dans les requêtes. Vous pouvez sélectionner rapidement les images les plus proches et les organiser en fonction de la distance entre les descripteurs.
Le moyen de base pour former un réseau à calculer un descripteur est d'utiliser un réseau siamois.
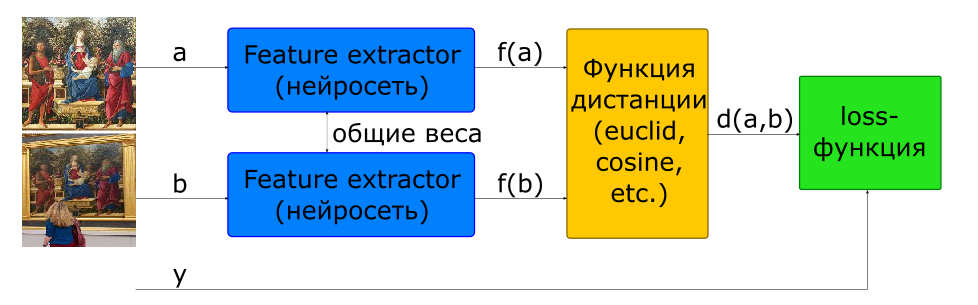
- images d'entrée
si et - une classe si différent
- descripteurs d'images
- distance entre une paire de vecteurs de caractéristiques
- fonction objective
Pour construire une telle architecture, un réseau qui calcule un descripteur (Feature Extractor) est utilisé dans le modèle 2 fois avec des poids communs. Deux images sont envoyées à l'entrée réseau. Le réseau Feature Extractor calcule les descripteurs d'image, puis le réseau calcule la distance en fonction de la métrique spécifiée (généralement la distance euclidienne ou cosinus est utilisée). La fonction cible de l'entraînement en réseau est construite de telle manière que pour les paires positives (images d'une image) la distance diminue et pour les négatifs (images d'images différentes) elle augmente. Pour réduire l'influence des paires négatives, la distance entre elles est limitée par la valeur de la marge.
Ainsi, nous pouvons dire que dans le processus d'apprentissage, le réseau cherche à calculer des descripteurs d'images similaires à l'intérieur d'une hypersphère avec un rayon de marge, et des descripteurs de différentes - à pousser hors de cette sphère.
Par exemple, cela pourrait ressembler à la formation d'un descripteur bidimensionnel à l'aide du réseau siamois sur l'ensemble de données MNIST.
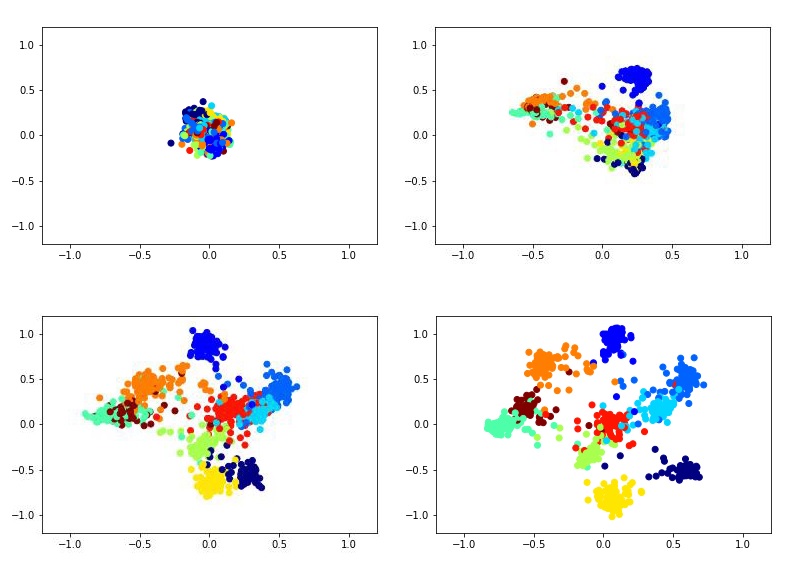
Pour former le réseau siamois, vous devez saisir des paires d'images et une étiquette égale à 1 si les images appartiennent à la même classe ou à 0 si différentes. Il y a le problème du choix de la proportion de paires positives et négatives. Idéalement, bien sûr, il faudrait soumettre au réseau de formation toutes les combinaisons possibles de paires de l'ensemble de formation, mais cela est techniquement impossible. Et le nombre de paires négatives dans ce cas dépasse considérablement le nombre de paires positives, ce qui n'aura pas non plus un très bon effet sur le processus d'apprentissage.
Une partie du problème avec le choix de la proportion de paires pour la formation est résolue en utilisant l'architecture triplet.
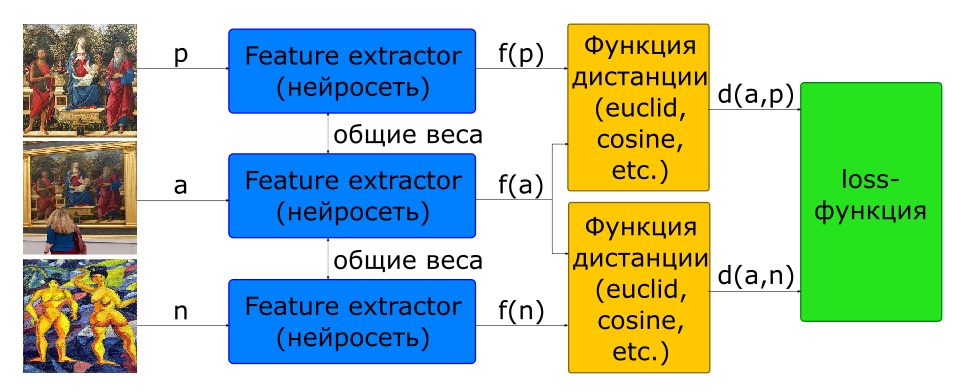
- images d'entrée: - une photo, - un autre
- fonction objective
A l'entrée d'un tel réseau, 3 images sont immédiatement formées, formant une paire positive et négative.
De plus, presque tous les chercheurs conviennent que le choix des paires négatives est essentiel à l'apprentissage en réseau. La fonction objective pour de nombreux échantillons (paires pour les siamois, triples pour les triplets) se révèle être 0 s'ils ne violent pas la limite de marge, par conséquent, ces échantillons ne participent pas à la formation du réseau. Au fil du temps, le processus d'apprentissage ralentit encore plus, car il y a de moins en moins d'échantillons avec une valeur non nulle de la fonction objectif. Pour résoudre ce problème, les paires négatives sont choisies non pas par hasard, mais en recherchant l'extraction de cas difficiles. En pratique, plusieurs candidats négatifs sont sélectionnés pour cela, pour chacun desquels un descripteur est calculé en utilisant la dernière version des pondérations du réseau (d'une époque précédente ou même de l'ère actuelle). Ayant un descripteur, vous pouvez sélectionner un négatif dans chacun des trois, ce qui produit une perte non nulle connue.
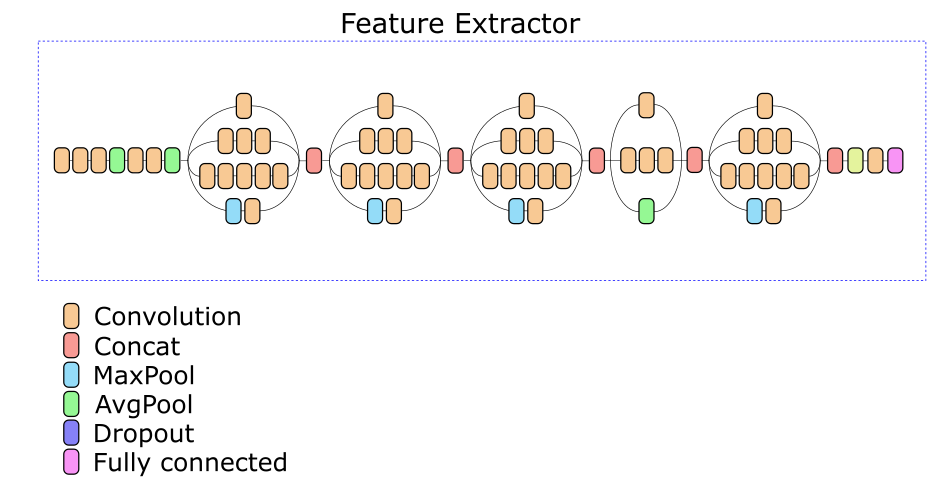
Pour rechercher des images similaires, Feature Extractor est séparé du réseau et utilisé pour calculer les descripteurs. Pour les images de la base de données, les descripteurs sont calculés à l'avance lorsqu'ils sont ajoutés. Ainsi, la tâche de trouver des images similaires consiste à calculer le descripteur d'image dans la requête et à rechercher les descripteurs les plus proches de la métrique donnée dans la base de données.
Notre extracteur de fonctionnalités réseau est basé sur l'architecture Inception v3. L'une des couches intermédiaires a été sélectionnée expérimentalement, sur la base de la sortie dont un descripteur de 512 nombres réels est calculé.
Augmentation des données
Ce serait bien si nous pouvions mettre chaque photo dans différents cadres, sur différents murs et prendre des photos à chaque fois sous un angle différent sur différents téléphones. En pratique, cela est bien sûr impossible. Par conséquent, il est nécessaire de générer des données d'entraînement.
Pour générer des données, environ 500 photographies de diverses peintures avec différents arrière-plans dans différentes conditions d'éclairage ont été collectées. Pour chaque photo, 4 points ont été sélectionnés correspondant aux coins de la toile de l'image. Pour quatre points, nous pouvons arbitrairement adapter n'importe quelle image dans le cadre, remplaçant ainsi l'image et obtenant une distorsion en perspective presque aléatoire de l'image à partir de la base de données. En complétant ce processus par une recadrage aléatoire, du bruit et une distorsion des couleurs, nous avons la possibilité de générer des images parfaitement adaptées qui imitent des photographies de peintures.

Séparation d'une image d'un arrière-plan
La qualité du travail et les modèles d'identification des peintures et les modèles de classification des genres / styles dépendent largement de la manière dont l'image est séparée de l'arrière-plan. Idéalement, avant d'insérer une image dans un modèle, vous devez trouver les 4 coins de sa toile et afficher la perspective dans un carré. En pratique, il s'est avéré très difficile de mettre en œuvre un algorithme qui garantirait cela. D'une part, il existe une grande variété d'arrière-plans, de cadres et d'objets qui peuvent tomber dans le cadre près de l'image. D'un autre côté, il y a des peintures à l'intérieur desquelles se dessinent des contours assez visibles de formes rectangulaires (fenêtres, façades de bâtiments, image dans l'image). Par conséquent, il est souvent très difficile de dire où l'image se termine et où commence son environnement.
Au final, nous avons opté pour une implémentation simple basée sur des méthodes classiques de vision par ordinateur (détection des frontières + filtrage morphologique + analyse des composants connectés), qui vous permet de couper en toute confiance les arrière-plans monophoniques, sans perdre une partie de l'image.
Vitesse de travail
L'algorithme de traitement des requêtes comprend les étapes principales suivantes:
- préparation - en fait, un simple détecteur de l'image est mis en œuvre, ce qui fonctionne bien si l'image contient un fond uni;
- calculer un descripteur d'image à l'aide d'un réseau profond;
- classement des images par distance aux descripteurs dans la base de données;
- rechercher des points clés dans l'image;
- vérifier les candidats dans l'ordre de classement.
Nous avons testé la vitesse du réseau sur 200 requêtes, le temps de traitement suivant a été obtenu pour chacune des étapes (temps en secondes):
| étape | min | max | moyenne |
|---|
| Préparation (recherche d'images) | 0,008 | 0,011 | 0,016 |
| Calcul de descripteur (GPU) | 0,082 | 0,092 | 0,088 |
| KNN (k <500, CPU, force brute) | 0,199 | 0,820 | 0,394 |
| Recherche de points clés | 0,031 | 0,432 | 0,156 |
| Vérifier les points clés | 0,007 | 9.844 | 2,585 |
| Temps total de demande | 0,358 | 10,386 | 3.239 |
La vérification des candidats s'arrêtant immédiatement, la photo étant trouvée avec suffisamment de confiance, on peut supposer que le temps de traitement minimum des demandes correspond aux photos trouvées parmi les premiers candidats. Le temps de demande maximum est obtenu pour les tableaux qui n'ont pas été trouvés du tout - le contrôle s'arrête après 500 candidats.
On constate que la plupart du temps est consacré à la sélection des candidats et à leur vérification. Il convient de noter que la mise en œuvre de ces étapes a été rendue très non optimale et présente un grand potentiel d'accélération.
Recherche en double
Après avoir construit l'index complet de la base des peintures, nous l'avons utilisé pour rechercher des doublons dans la base de données. Après environ 3 heures de visualisation de la base de données, il a été constaté qu'au moins 13657 images sont répétées deux fois (et environ trois) dans la base de données.
De plus, des cas très intéressants ont été trouvés qui ne sont pas des doublons.
 Un
Un ,
deux . Il semble que ce soient deux étapes du même travail.
 Un
Un ,
deux ,
trois . Ne faites pas attention au nom - les trois images sont différentes.
Ainsi qu'un exemple d'une identification faussement positive par des points clés.
 Un
Un ,
deux .
cartographie des points clés Au lieu d'une conclusion
En général, nous sommes satisfaits du résultat du service.
Sur les ensembles de test, une précision d'identification de plus de 80% est atteinte. En pratique, il s'avère souvent que si l'image n'est pas retrouvée la première fois, alors il suffit de la photographier sous un angle différent, et elle est localisée. Des erreurs lorsqu'une image incorrecte est trouvée ne se produisent presque jamais.
Dans l'ensemble, la solution a été emballée dans un conteneur docker et remise au client. Désormais, l'identification des peintures par des photos est disponible dans les applications utilisant le service Arthive, par exemple le Musée Pouchkine, disponible sur le Play Market (cependant, il détache la peinture de l'arrière-plan, exigeant que l'arrière-plan soit clair, ce qui rend parfois la photographie difficile).