La reconnaissance automatique d'images satellites ou aériennes est le moyen le plus prometteur pour obtenir des informations sur l'emplacement de divers objets au sol. Le rejet de la segmentation manuelle de l'image est particulièrement pertinent lorsqu'il s'agit de traiter de grandes surfaces de la surface de la terre en peu de temps.
Récemment, j'ai eu l'opportunité d'appliquer des compétences théoriques et de m'essayer dans le domaine de l'apprentissage automatique sur un projet de segmentation d'images réelles. L'objectif du projet est la reconnaissance des peuplements forestiers, à savoir les cimes des arbres dans les images satellites à haute résolution. Sous la coupe, je partagerai mon expérience et mes résultats.
En ce qui concerne le traitement d'image, la segmentation peut être donnée la définition suivante - c'est la présence sur l'image de zones caractéristiques qui sont également décrites dans cet espace de fonctionnalités.
Distinguer la luminosité, le contour, la texture et la segmentation sémantique.
La segmentation sémantique (ou sémantique) de l'image consiste à mettre en évidence des zones de l'image, chacune correspondant à un attribut spécifique. En termes généraux, les problèmes de segmentation sémantique sont difficiles à algorithmiser, de sorte que les réseaux de neurones convolutionnels qui montrent de bons résultats sont actuellement largement utilisés pour la segmentation d'images.
Énoncé du problème
Le problème de la segmentation binaire est en train d'être résolu - des images en couleur (images satellites à haute résolution) sont alimentées à l'entrée du réseau neuronal, sur lesquelles il est nécessaire de mettre en évidence les zones de pixels appartenant à la même classe - les arbres.
Données source
À ma disposition, il y avait un ensemble de tuiles d'images satellites d'une zone rectangulaire dans laquelle s'inscrit le polygone. À l'intérieur, vous devez chercher des arbres. Le polygone ou le multipolygone est présenté sous forme de fichier GeoJSON. Dans mon cas, les tuiles étaient au format png de taille 256 par 256 pixels en vraie couleur. (hélas, sans IR) Numérotation des tuiles sous la forme /zoom/x/y.png.
Il est garanti que toutes les tuiles de l'ensemble sont obtenues à partir d'images satellites prises à peu près au même moment de l'année (fin du printemps - début de l'automne, selon le climat d'une région particulière) et un jour à un angle similaire à la surface, où une légère couverture nuageuse était autorisée.
Préparation des données
Étant donné que la zone du polygone souhaité peut être inférieure à cette zone rectangulaire, la première chose à faire est d'exclure les tuiles qui dépassent les limites du polygone. Pour ce faire, un script simple a été écrit qui sélectionne les tuiles nécessaires dans le polygone du fichier GeoJSON. Cela fonctionne comme suit. Pour commencer, les coordonnées de tous les sommets du polygone sont
converties en nombres de tuiles et ajoutées à un tableau. Il existe également un décalage par rapport à l'origine. Pour l'inspection visuelle, une image est générée où un pixel est égal à une tuile. Le polygone dans l'image est déjà rempli en tenant compte du décalage à l'aide de PIL. Après cela, l'image est transférée dans un tableau, d'où les tuiles nécessaires sont sélectionnées, qui tombent à l'intérieur du polygone.
from PIL import Image, ImageDraw
 Résultat visuel de la conversion d'un polygone en un ensemble de tuiles
Résultat visuel de la conversion d'un polygone en un ensemble de tuilesModèle de réseau
Pour résoudre les problèmes de segmentation d'image,
il existe un certain nombre de modèles de réseaux de neurones convolutionnels. J'ai décidé d'utiliser
U-Net , qui a fait ses preuves dans les tâches de segmentation d'images binaires. L'architecture U-Net se compose de ce que l'on appelle les contrats et des chemins expansifs, qui sont connectés par des probros aux étapes de taille appropriées, et réduisent d'abord la résolution de l'image, puis l'augmentent, en la combinant auparavant avec les données d'image et en passant par d'autres couches convolution. Ainsi, le réseau agit comme une sorte de filtre. La compression et la décompression des blocs sont présentées comme un ensemble de blocs d'une certaine dimension. Et chaque bloc se compose d'opérations de base: convolution, ReLu et mise en commun maximale. Il existe des implémentations du modèle U-Net sur Keras, Tensorflow, Caffe et PyTorch. J'ai utilisé Keras.
Création d'un ensemble d'entraînement
Pour apprendre ce modèle Unet, vous avez besoin d'images. La première chose dans ma tête est venue avec l'idée de prendre des données OpenStreetMap et de générer des masques pour la formation basée sur eux. Mais comme il s'est avéré dans mon cas, la précision des polygones dont j'ai besoin laisse beaucoup à désirer. J'avais également besoin de la présence d'arbres isolés, qui ne sont pas toujours cartographiés. J'ai donc dû abandonner une telle entreprise. Mais il vaut la peine de dire que pour d'autres objets, comme les routes ou les bâtiments, cette approche peut être
efficace .

Étant donné que l'idée de générer automatiquement un échantillon d'entraînement basé sur les données OSM a dû être abandonnée, j'ai décidé de marquer manuellement une petite zone. Pour ce faire, j'ai utilisé l'éditeur JOSM, où j'ai utilisé des images de terrain disponibles comme substrat, que j'ai placées sur un serveur local. Puis un autre problème est apparu - je n'ai pas trouvé la possibilité d'activer l'affichage de la grille de tuiles à l'aide des outils JOSM habituels. Par conséquent, quelques lignes simples en .htaccess sur le même serveur à partir d'un répertoire différent ont commencé à émettre une tuile vide avec une bordure en pixels pour toute demande de la forme grille_tile / z / x / y.png et ont ajouté une telle couche impromptue à JOSM. Un tel vélo.
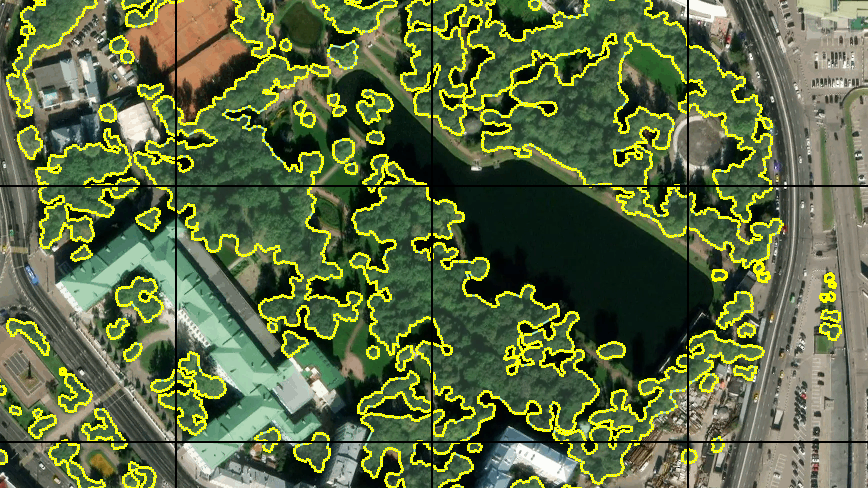
Tout d'abord, j'ai tracé environ 30 tuiles. Avec une tablette graphique et un «mode de dessin rapide» dans JOSM, cela n'a pas pris beaucoup de temps. J'ai compris qu'une telle quantité ne suffit pas pour une formation à part entière, mais j'ai décidé de commencer par cela. De plus, la formation sur autant de données sera assez rapide.
Entraînement et premier résultat
Le réseau a été formé pendant 15 époques sans augmentation préalable des données. Le graphique montre les valeurs des pertes et de la précision sur l'échantillon de test:
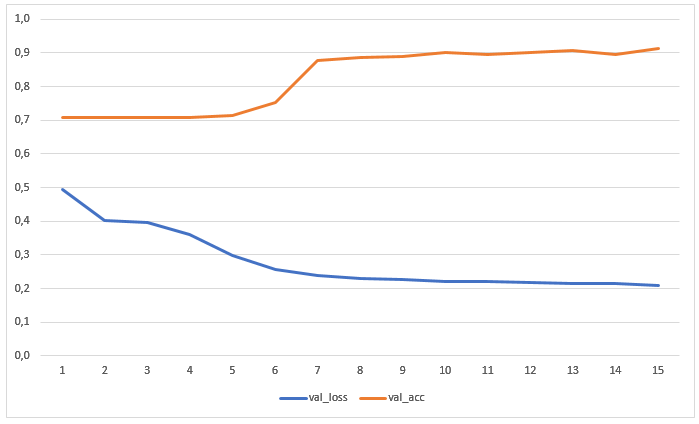
Le résultat de la reconnaissance d'images qui n'étaient ni dans la formation ni dans l'échantillon d'essai s'est avéré assez sain d'esprit:

Après une étude plus approfondie des résultats, certains problèmes sont devenus évidents. De nombreux ratés se trouvaient dans les zones d'ombre des images - le réseau a trouvé des arbres à l'ombre où ils n'étaient pas, ou exactement le contraire. Cela était attendu, car il y avait peu d'exemples de ce type dans l'ensemble de formation. Mais je ne m'attendais pas à ce que certains morceaux de la surface de l'eau et des toits sombres du profil métallique (vraisemblablement) soient reconnus comme des arbres. Il y avait également des inexactitudes avec les pelouses. Il a été décidé d'améliorer l'échantillon en y ajoutant un plus grand nombre d'images avec des sections controversées, ainsi l'échantillon de formation a presque doublé.
Augmentation des données
Pour augmenter encore la quantité de données, j'ai décidé de faire pivoter l'image à un angle arbitraire. Tout d'abord, j'ai essayé le module standard keras.preprocessing.image.ImageDataGenerator. Lorsque vous faites pivoter tout en préservant l'échelle, des zones vides restent sur les bords des images, dont le remplissage est défini par le paramètre
fill_mode . Vous pouvez simplement remplir ces zones de couleur en le spécifiant en
cval , mais je voulais une rotation complète, en espérant que la sélection serait plus complète, et j'ai implémenté le générateur moi-même. Cela a permis d'augmenter la taille de plus de dix fois.
 fill_mode = le plus proche
fill_mode = le plus procheMon générateur de données colle quatre tuiles voisines en une seule tuile source de 512 x 512 px. L'angle de rotation est choisi au hasard, en le prenant en compte, les intervalles admissibles de x et y sont calculés pour le centre de la tuile résultante, dans laquelle il ne dépasse pas la tuile d'origine. Les coordonnées du centre sont choisies au hasard en tenant compte des intervalles autorisés. Bien sûr, toutes ces transformations s'appliquent à la paire de masques de tuiles. Tout cela se répète pour différents groupes de tuiles voisines. À partir d'un groupe, vous pouvez obtenir plus d'une douzaine de tuiles avec différentes sections du terrain tournées à différents angles.
 Un exemple du résultat du générateur
Un exemple du résultat du générateurApprendre avec plus de données
En conséquence, la taille de l'échantillon d'apprentissage était de 1881 images, j'ai également augmenté le nombre d'époques à 30:
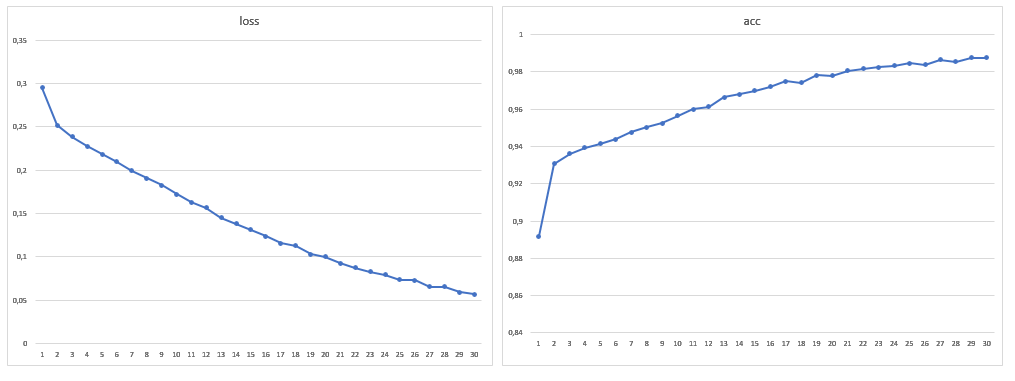
Après avoir entraîné le modèle sur un nouveau volume de données, les problèmes de segmentation erronée des toits et de l'eau n'étaient plus détectés. Il n'était pas du tout possible de se débarrasser des erreurs dans l'ombre, mais elles sont devenues moins nombreuses dans l'œil, ainsi que des erreurs avec les pelouses. Il convient de noter qu'en général la grande majorité des erreurs est que le réseau voit les arbres là où ils ne sont pas, et non l'inverse. La précision obtenue peut être améliorée en utilisant des images satellites avec un grand nombre de canaux et en modifiant l'architecture du réseau pour une tâche spécifique.

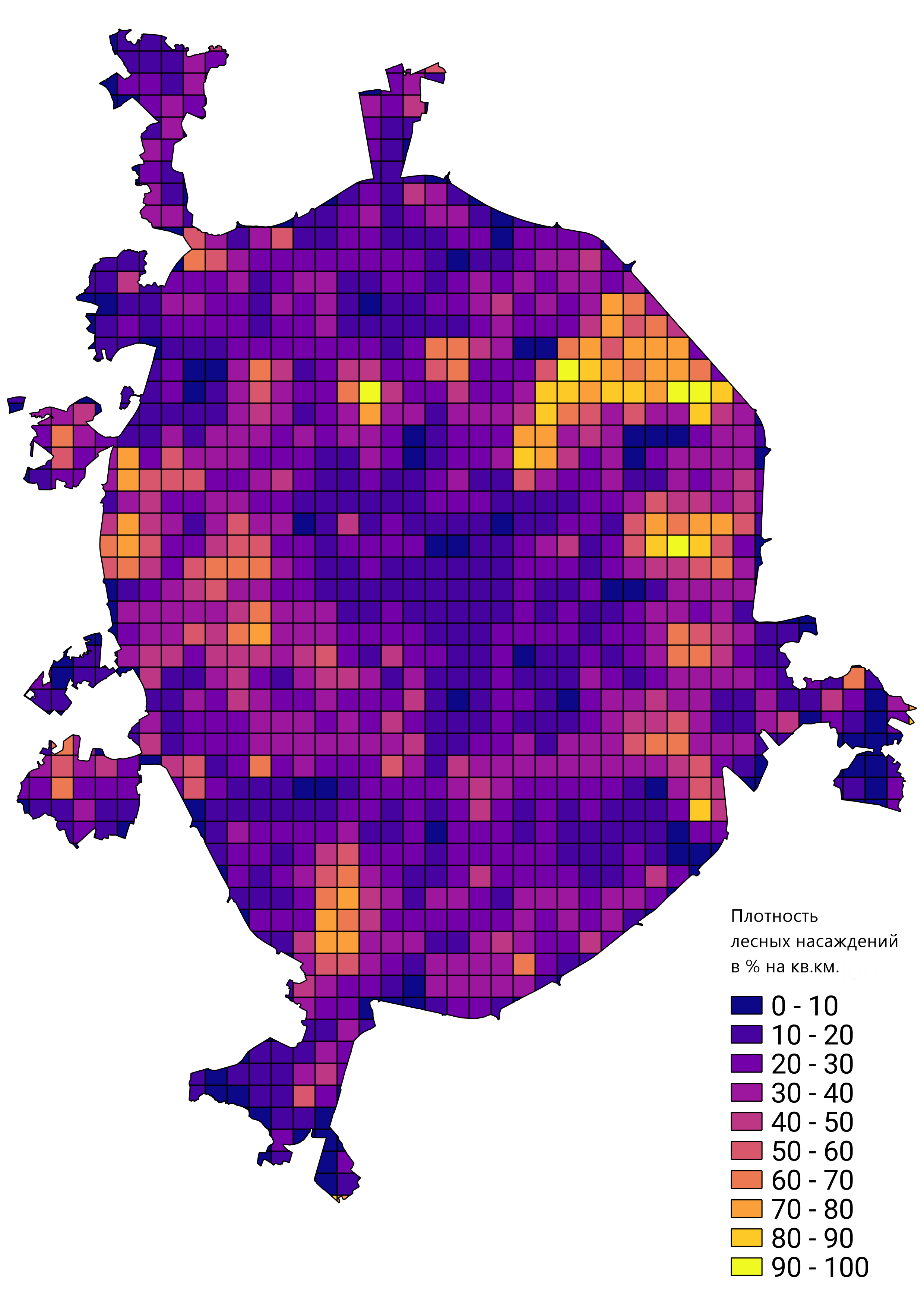
En général, j'étais satisfait du résultat du travail effectué et le prototype de réseau formé a été appliqué pour résoudre de vrais problèmes. Par exemple, calculer la densité des peuplements forestiers à Moscou: