
L'époque où l'une des tâches les plus urgentes de la vision par ordinateur était de pouvoir distinguer les photographies de chiens des photographies de chats, est déjà révolue. À l'heure actuelle, les réseaux de neurones sont capables d'effectuer des tâches beaucoup plus complexes et intéressantes pour le traitement d'images. En particulier, le réseau avec l'architecture Mask R-CNN vous permet de sélectionner les contours («masques») de différents objets dans les photographies, même s'il y en a plusieurs, ils ont des tailles différentes et se chevauchent partiellement. Le réseau est également capable de reconnaître les poses de personnes dans l'image.
Au début de cette année, j'ai eu l'occasion de participer au concours Data Science Bowl 2018 à Kaggle à des fins éducatives. À des fins éducatives, j'ai utilisé l'un de ces modèles que certains participants occupant des postes élevés présentent généreusement. Il s'agissait d'un réseau neuronal Mask R-CNN récemment développé par Facebook Research. (Il convient de noter que l'équipe gagnante utilisait toujours une architecture différente - U-Net. Apparemment, elle était plus adaptée aux tâches biomédicales, dont le Data Science Bowl 2018).
Le but étant de se familiariser avec les tâches du Deep Learning et de ne pas occuper une place de choix, après la fin de la compétition, il y avait un fort désir de comprendre comment fonctionne le réseau neuronal utilisé «sous le capot». Cet article est une compilation d'informations obtenues à partir de documents originaux d'arXiv.org et de plusieurs articles sur Medium. Le matériel est de nature purement théorique (bien qu'à la fin il y ait des liens sur l'application pratique), et il ne contient pas plus qu'il n'y en a dans les sources indiquées. Mais il y a peu d'informations sur le sujet en russe, donc l'article sera peut-être utile à quelqu'un.
Toutes les illustrations proviennent de sources d'autres personnes et appartiennent à leurs propriétaires légitimes.
Types de tâches de vision par ordinateur
Habituellement, les tâches modernes de vision par ordinateur sont divisées en quatre types (il n'était pas nécessaire de répondre aux traductions de leurs noms même dans les sources en russe, donc en anglais, afin de ne pas créer de confusion):
- Classification - classification de l'image par le type d'objet qu'elle contient;
- Segmentation sémantique - définition de tous les pixels d'objets d'une certaine classe ou d'un arrière-plan dans l'image. Si plusieurs objets de la même classe se chevauchent, leurs pixels ne peuvent pas être séparés les uns des autres;
- Détection d'objets - détection de tous les objets des classes spécifiées et détermination du cadre englobant pour chacune d'elles;
- Segmentation d'instance - définition des pixels appartenant à chaque objet de chaque classe séparément;
En utilisant l'exemple d'une image avec des ballons de
[9], cela peut être illustré comme suit:
Développement évolutif du masque R-CNN
Les concepts sous-jacents à Mask R-CNN ont connu un développement progressif à travers l'architecture de plusieurs réseaux de neurones intermédiaires qui ont résolu différentes tâches de la liste ci-dessus. La façon la plus simple de comprendre les principes de fonctionnement de ce réseau est probablement de considérer séquentiellement toutes ces étapes.
Sans s'attarder sur des choses de base comme la rétropropagation, la fonction d'activation non linéaire et ce qu'est un réseau neuronal multicouche en général, une brève explication du fonctionnement des couches de réseaux de neurones à convolution en vaut probablement la peine (R-CNN).
Convolution et MaxPooling
Une couche convolutionnelle vous permet de combiner les valeurs des pixels adjacents et de mettre en évidence des caractéristiques plus générales de l'image. Pour ce faire, l'image est séquentiellement glissée par une fenêtre carrée de petite taille (3x3, 5x5, 7x7 pixels, etc.) appelée noyau (noyau). Chaque élément central a son propre coefficient de poids multiplié par la valeur de ce pixel de l'image sur laquelle l'élément central est actuellement superposé. Ensuite, les nombres obtenus pour toute la fenêtre sont additionnés, et cette somme pondérée donne la valeur du signe suivant.
Pour obtenir une matrice («carte») d'attributs de l'image entière, le noyau est décalé séquentiellement horizontalement et verticalement. Dans les couches suivantes, l'opération de convolution est déjà appliquée aux cartes caractéristiques obtenues à partir des couches précédentes. Graphiquement, le processus peut être illustré comme suit:
Une image ou des cartes de caractéristiques dans une couche peuvent être numérisées non pas par un mais par plusieurs filtres indépendants, donnant ainsi non pas une carte, mais plusieurs (elles sont également appelées «canaux»). L'ajustement des poids de chaque filtre s'effectue en utilisant la même procédure de rétropropagation.
Évidemment, si le noyau du filtre pendant la numérisation ne dépasse pas l'image, la dimension de la carte d'entités sera inférieure à celle de l'image d'origine. Si vous souhaitez conserver la même taille, appliquez les soi-disant rembourrages - valeurs qui complètent l'image sur les bords et qui sont ensuite capturées par le filtre avec les vrais pixels de l'image.
En plus des rembourrages, les changements dimensionnels sont également affectés par les foulées - les valeurs de l'étape avec laquelle la fenêtre se déplace autour de l'image / de la carte.
La convolution n'est pas le seul moyen d'obtenir une caractéristique généralisée d'un groupe de pixels. La façon la plus simple de le faire est de sélectionner un pixel selon une règle donnée, par exemple le maximum. C'est exactement ce que fait la couche MaxPooling.
Contrairement à la convolution, le maxpool est généralement appliqué aux groupes de pixels disjoints.
R-CNN
L'architecture du réseau R-CNN (Regions With CNNs) a été développée par une équipe de UC Berkley pour appliquer les réseaux de neurones à convolution à une tâche de détection d'objets. Les approches de résolution de ces problèmes qui existaient à l'époque se rapprochaient au maximum de leurs capacités et leurs performances n'étaient pas significativement améliorées.
CNN a bien performé dans la classification des images, et dans le réseau donné, elles ont été essentiellement appliquées pour la même chose. Pour ce faire, non pas l'image entière a été envoyée à l'entrée CNN, mais les régions préalablement allouées d'une manière différente, sur lesquelles certains objets sont censés se trouver. À cette époque, il y avait plusieurs de ces approches, les auteurs ont choisi la
recherche sélective , bien qu'ils indiquent qu'il n'y a pas de raisons particulières de préférence.
Une architecture prête à l'emploi a également été utilisée comme réseau CNN -
CaffeNet (AlexNet). Ces réseaux de neurones, comme d'autres pour l'ensemble d'images ImageNet, se classent en 1000 classes. R-CNN a été conçu pour détecter des objets d'un plus petit nombre de classes (N = 20 ou 200), de sorte que la dernière couche de classification de CaffeNet a été remplacée par une couche avec N + 1 sorties (avec une classe supplémentaire pour l'arrière-plan).
La recherche sélective a renvoyé environ 2000 régions de tailles et de rapports d'aspect différents, mais CaffeNet accepte des images d'une taille fixe de 227x227 pixels en entrée, vous avez donc dû les modifier avant de soumettre des régions à l'entrée réseau. Pour cela, l'image de la région était enfermée dans le plus petit carré couvrant. Le long du côté (plus petit) le long duquel les champs ont été formés, plusieurs pixels «contextuels» (entourant la région) de l'image ont été ajoutés, le reste du champ n'était rempli de rien. Le carré résultant a été mis à l'échelle à une taille de 227x227 et alimenté à l'entrée de CaffeNet.

Malgré le fait que CNN s'est entraîné à reconnaître les classes N + 1, il n'a finalement été utilisé que pour extraire un vecteur caractéristique à 4096 dimensions fixes. N SVM linéaires ont été engagés dans la détermination directe de l'objet dans l'image, chacun d'eux a effectué une classification binaire en fonction de son type d'objets, déterminant s'il y avait une telle chose dans la région transférée ou non. Dans le document d'origine, l'ensemble de la procédure est illustré par le schéma suivant:
Les auteurs soutiennent que le processus de classification dans SVM est très productif, étant essentiellement de simples opérations matricielles. Les vecteurs de caractéristiques obtenus à partir de CNN sont combinés sur toutes les régions dans une matrice 2000x4096, qui est ensuite multipliée par une matrice 4096xN avec des poids SVM.
Il convient de noter que les régions obtenues à l'aide de la recherche sélective
ne peuvent contenir que certains objets, et non le fait qu'elles les contiennent dans leur intégralité. La prise en compte ou non d'une région contenant un objet a été déterminée par la
métrique Intersection over Union (IoU) . Cette métrique est le rapport de la zone d'intersection d'une région candidate rectangulaire avec un rectangle qui englobe réellement l'objet à la zone d'union de ces rectangles. Si le rapport dépasse une valeur de seuil prédéterminée, la région candidate est considérée comme contenant l'objet souhaité.
IoU a également été utilisé pour filtrer un nombre excessif de régions contenant un objet particulier (suppression non maximale). Si l'IoU d'une région avec une région qui a reçu le résultat maximum pour le même objet était au-dessus d'un seuil, la première région était simplement jetée.
Au cours de la procédure d’analyse des erreurs, les auteurs ont également développé une méthode qui permet de réduire l’erreur de sélection du cadre englobant de l’objet - régression du cadre de délimitation. Après avoir classifié le contenu de la région candidate, quatre paramètres ont été déterminés en utilisant une régression linéaire basée sur les attributs de CNN - (dx, dy, dw, dh). Ils ont décrit à quel point le centre du cadre de la région devait être décalé de x et y, et à quel point changer sa largeur et sa hauteur afin de couvrir plus précisément l’objet reconnu.
Ainsi, la procédure de détection d'objets par le réseau R-CNN peut être divisée en les étapes suivantes:
- Mettez en surbrillance les régions candidates à l'aide de la recherche sélective.
- Conversion d'une région à la taille acceptée par CNN CaffeNet.
- Obtention à l'aide d'un vecteur d'entités CNN 4096.
- Réalisation de N classifications binaires de chaque vecteur caractéristique à l'aide de N SVM linéaires.
- Régression linéaire des paramètres de trame de région pour une couverture d'objet plus précise
Les auteurs ont noté que l'architecture qu'ils avaient développée fonctionnait également bien dans le problème de segmentation sémantique.
R-cnn rapide
Malgré les bons résultats, les performances de R-CNN étaient encore faibles, en particulier pour les réseaux plus profonds que CaffeNet (tels que VGG16). De plus, la formation pour le régresseur de boîte englobante et SVM a nécessité la sauvegarde d'un grand nombre d'attributs sur le disque, ce qui a coûté cher en termes de taille de stockage.
Les auteurs de Fast R-CNN ont proposé d'accélérer le processus en raison de quelques modifications:
- Passer par CNN non pas chacune des 2000 régions candidates séparément, mais l'image entière. Les régions proposées sont ensuite superposées sur la carte des caractéristiques communes résultante;
- Au lieu d'une formation indépendante de trois modèles (CNN, SVM, régresseur bbox), combinez toutes les procédures de formation en une seule.
La conversion des signes qui sont tombés dans différentes régions en une taille fixe a été effectuée en utilisant la procédure
RoIPooling . Une fenêtre de région de largeur w et de hauteur h a été divisée en une grille ayant des cellules H × W de taille h / H × w / W. (Les auteurs du document ont utilisé W = H = 7). Pour chacune de ces cellules, Max Pooling a été effectué pour sélectionner une seule valeur, donnant ainsi la matrice de caractéristiques H × W résultante.
Les SVM binaires n'ont pas été utilisés, mais les entités sélectionnées ont été transférées vers une couche entièrement connectée, puis vers deux couches parallèles: softmax avec sorties K + 1 (une pour chaque classe + 1 pour l'arrière-plan) et régresseur de boîte englobante.
L'architecture générale du réseau ressemble à ceci:
Pour la formation conjointe du classificateur softmax et du régresseur bbox, la fonction de perte combinée a été utilisée:
Ici:
- la classe de l'objet effectivement représenté dans la région candidate;
- perte de log pour la classe u;
- de réels changements dans le cadre de la région pour une couverture plus précise de l'objet;
- changements prévus dans le cadre de la région;
- fonction de perte entre les changements de trame prévus et réels;
- fonction d'indicateur égale à 1 lorsque
et 0 quand vice versa. Classe
l'arrière-plan est indiqué (c'est-à-dire l'absence d'objets dans la région).
- coefficient conçu pour équilibrer la contribution des deux fonctions de perte au résultat global. Dans toutes les expériences des auteurs du document, cependant, il était égal à 1.
Les auteurs mentionnent également qu'ils ont utilisé la décomposition SVD tronquée de la matrice de poids pour accélérer les calculs dans une couche entièrement connectée.
R-cnn plus rapide
Après les améliorations apportées à Fast R-CNN, le goulot d'étranglement du réseau neuronal s'est avéré être le mécanisme pour générer des régions candidates. En 2015, une équipe de Microsoft Research a pu accélérer considérablement cette étape. Ils ont suggéré de calculer les régions non pas à partir de l'image d'origine, mais à nouveau à partir d'une carte de caractéristiques obtenue de CNN. Pour cela, un module appelé Region Proposition Network (RPN) a été ajouté. L'architecture entière est la suivante:
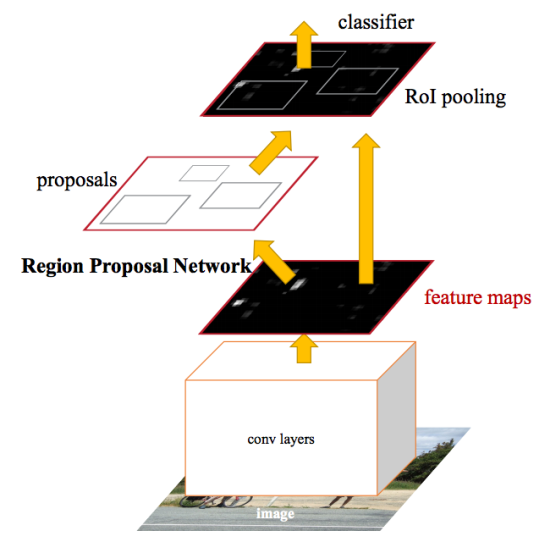
Dans le cadre du RPN, selon le CNN extrait, ils glissent dans un «mini réseau neuronal» avec une petite fenêtre (3x3). Les valeurs obtenues avec son aide sont transférées vers deux couches parallèles entièrement connectées: la couche de régression de boîte (reg) et la couche de classification de boîte (cls). Les sorties de ces couches sont basées sur les soi-disant ancres: k cadres pour chaque position de la fenêtre coulissante, qui ont des tailles et des rapports d'aspect différents. La couche Reg pour chacune de ces ancres produit 4 coordonnées, corrigeant la position du cadre englobant; La couche cls produit deux nombres chacun - la probabilité que la trame contienne au moins un objet ou non. Dans le document, cela est illustré par le schéma suivant:
Les couches reg et cls du processus d'apprentissage combinées; ils ont une fonction de perte en commun, qui est la somme des fonctions de perte de chacun d'eux, avec un coefficient d'équilibrage.
Les deux couches RPN ne proposent que des offres pour les régions candidates. Celles qui sont très susceptibles de contenir un objet sont transmises au module de détection et de raffinement d'objet, qui est toujours implémenté en tant que Fast R-CNN.
Afin de partager les fonctionnalités obtenues dans CNN entre le RPN et le module de détection, le processus de formation de l'ensemble du réseau est construit de manière itérative en plusieurs étapes:
- La partie RPN est initialisée et formée pour identifier les régions candidates.
- En utilisant les régions RPN proposées, la partie Fast R-CNN est recyclée.
- Un réseau de détection formé est utilisé pour initialiser les poids des RPN. Cependant, les couches de convolution générales sont fixes et seules les couches spécifiques au RPN sont réaccordées.
- Avec des couches de convolution fixes, Fast R-CNN est enfin réglé.
Le schéma proposé n'est pas le seul, et même dans sa forme actuelle, il peut être poursuivi par d'autres étapes itératives, mais les auteurs de l'étude originale ont mené des expériences précisément après une telle formation.
Masque r-cnn
Mask R-CNN développe l'architecture Faster R-CNN en ajoutant une autre branche qui prédit la position du masque couvrant l'objet trouvé, et résout ainsi le problème de segmentation d'instance. Le masque est juste une matrice rectangulaire, dans laquelle 1 à une certaine position signifie que le pixel correspondant appartient à un objet d'une classe donnée, 0 - que le pixel n'appartient pas à l'objet.

La visualisation de masques multicolores sur les images source peut donner des images colorées:

Les auteurs du document divisent conditionnellement l'architecture développée en un réseau CNN pour calculer les caractéristiques de l'image, appelé l'épine dorsale, et la tête - l'union des parties chargées de prédire le cadre enveloppant, de classer l'objet et de déterminer son masque. La fonction de perte est courante pour eux et comprend trois composants:
L'extraction des masques a lieu dans un style indépendant de la classe: les masques sont prédits séparément pour chaque classe, sans connaissance préalable de ce qui est représenté dans la région, puis le masque de la classe qui a remporté le classificateur indépendant est simplement sélectionné. On fait valoir qu'une telle approche est plus efficace que de s'appuyer sur une connaissance a priori de la classe.
L'une des principales modifications résultant de la nécessité de prédire le masque est un changement de la procédure
RoIPool (qui calcule la matrice de caractéristiques pour la région candidate) vers ce que l'on appelle
RoIAlign . Le fait est que la carte d'entités obtenue à partir de CNN a une taille plus petite que l'image d'origine, et la région couvrant le nombre entier de pixels dans l'image ne peut pas être affichée dans une région proportionnelle de la carte avec le nombre d'entités:
Dans RoIPool, le problème a été résolu simplement en arrondissant les valeurs fractionnaires aux nombres entiers. Cette approche fonctionne bien lors de la sélection du cadre englobant, mais le masque calculé sur la base de ces données est trop imprécis.
En revanche, RoIAlign n'utilise pas d'arrondi, tous les nombres restent valides et une interpolation bilinéaire sur les quatre points entiers les plus proches est utilisée pour calculer les valeurs d'attribut.
Dans le document d'origine, la différence est expliquée comme suit:
Ici, la carte hachurée dénote une carte d'entités, et continue - l'affichage sur la carte d'entités de la région candidate à partir de la photographie originale. Il devrait y avoir 4 groupes dans cette région pour la mise en commun maximale avec 4 attributs indiqués par des points sur la figure. Contrairement à la procédure RoIPool, qui, en raison de l'arrondi, alignerait simplement la région avec des coordonnées entières, RoIAlign laisse les points à leur emplacement actuel, mais calcule les valeurs de chacun d'eux en utilisant une interpolation bilinéaire selon les quatre signes les plus proches.
Interpolation bilinéaireL'interpolation bilinéaire de la fonction de deux variables est réalisée en appliquant une interpolation linéaire, d'abord dans le sens de l'une des coordonnées, puis dans l'autre.
Soit qu'il soit nécessaire d'interpoler la valeur de la fonction
au point P avec des valeurs connues de la fonction aux points environnants
(voir photo ci-dessous). Pour ce faire, les valeurs des points auxiliaires R1 et R2 sont d'abord interpolées, puis la valeur au point P est interpolée en fonction d'eux.
( — ,
)
En plus des résultats élevés dans les tâches de segmentation d'instance et de détection d'objets, le masque R-CNN s'est révélé approprié pour déterminer la pose de personnes en photographie (estimation de la pose humaine). Le point clé ici est la sélection de points clés (points clés), tels que l'épaule gauche, le coude droit, le genou droit, etc., par lesquels vous pouvez dessiner un cadre de la position d'une personne: Pour déterminer les points de référence, le réseau neuronal est entraîné de manière à ce qu'il délivre des masques, en dont un seul pixel (le même point) avait une valeur de 1, et le reste - 0 (masque un-chaud). Dans le même temps, le réseau s'entraîne à émettre K de tels masques à pixel unique, un pour chaque type de point de référence.
Pour déterminer les points de référence, le réseau neuronal est entraîné de manière à ce qu'il délivre des masques, en dont un seul pixel (le même point) avait une valeur de 1, et le reste - 0 (masque un-chaud). Dans le même temps, le réseau s'entraîne à émettre K de tels masques à pixel unique, un pour chaque type de point de référence.Réseaux de pyramides
Dans des expériences sur le masque R-CNN, ainsi que l'habituel CNN ResNet-50/101 comme colonne vertébrale, des études ont également été menées sur la faisabilité de l'utilisation de Feature Pyramid Network (FPN). Ils ont montré que l'utilisation du FPN dans le squelette donne au Mask R-CNN une augmentation à la fois de la précision et des performances. Il est donc utile de décrire l'amélioration de la même manière, malgré le fait qu'un document distinct lui soit dédié et ait peu à voir avec la série d'articles à l'étude.Les pyramides d'objets, comme les pyramides d'images, ont pour but d'améliorer la qualité de détection des objets, en tenant compte d'un large éventail de leurs tailles possibles.Dans Feature Pyramid Network, les cartes d'entités extraites par des couches CNN successives avec des dimensions décroissantes sont considérées comme une sorte de "pyramide" hiérarchique appelée la voie ascendante. De plus, les cartes des signes des niveaux inférieur et supérieur de la pyramide ont leurs avantages et leurs inconvénients: les premiers ont une capacité de généralisation haute résolution mais faible sémantique; le second - au contraire:L'architecture FPN vous permet de combiner les avantages des couches supérieures et inférieures en ajoutant un chemin descendant et des connexions latérales. Pour cela, la carte de chaque couche superposée est agrandie à la taille de la couche sous-jacente et leur contenu est ajouté élément par élément. Dans les prédictions finales, les cartes résultantes de tous les niveaux sont utilisées.Schématiquement, cela peut être représenté comme suit:L'augmentation de la taille de la carte de niveau supérieur (suréchantillonnage) se fait par la méthode la plus simple - le plus proche voisin, c'est-à-dire approximativement comme ceci:Liens utiles
Documents de recherche originaux sur arXiv.org:1. R-CNN: https://arxiv.org/abs/1311.25242. R-CNN rapide: https://arxiv.org/abs/1504.080833. R-CNN plus rapide : https://arxiv.org/abs/1506.014974. Masque R-CNN: https://arxiv.org/abs/1703.068705. Feature Pyramid Network: https://arxiv.org/abs/1612.03144Sur support moyen. com au sujet du Masque R-CNN il y a beaucoup d'articles, ils sont faciles à trouver. Comme références, je n'apporte que celles que j'ai lues:6. Compréhension simple du masque RCNN - un bref résumé des principes de l'architecture résultante.7. Une brève histoire des CNN dans la segmentation d'image: du R-CNN au masque R-CNN- L'histoire du développement du réseau dans le même ordre chronologique que dans cet article.8. Du R-CNN au masque R-CNN est une autre considération des stades de développement.9.
Splash of Color: Segmentation d'instance avec Mask R-CNN et TensorFlow - implémentation d'un réseau de neurones dans la bibliothèque opensource de Matterport.Le dernier article, en plus de décrire les principes du Masque R-CNN, offre la possibilité d'essayer le réseau en pratique: pour colorier des ballons de différentes couleurs sur des images en noir et blanc.De plus, vous pouvez vous entraîner avec le réseau neuronal sur le modèle que j'ai utilisé dans le concours de kaggle Data Science Bowl 2018 (mais pas seulement avec ce modèle, bien sûr; vous pouvez trouver beaucoup de choses intéressantes dans les sections Kernels et Discussions):10. Masque R- CNN dans PyTorch par Heng CherKeng. La mise en œuvre implique une série d'étapes de déploiement; l'auteur fournit des instructions. Le modèle nécessite PyTorch 0.4.0, la prise en charge de l'informatique GPU, NVIDIA CUDA. Si mon propre système ne répond pas aux exigences, je peux recommander des images Deep Learning AMI pour les machines virtuelles Amazon (les instances sont payantes, avec une facturation horaire, la taille minimale appropriée, apparemment, est p2.xlarge).Je suis également tombé sur le hub, un article sur l'utilisation du réseau de Matterport dans le traitement d'image avec des plats (bien que sans source). J'espère que l'auteur ne sera satisfait que de la mention supplémentaire:11. ConvNets. Prototype d'un projet à l'aide du masque R-CNN