Dans le film Mission Impossible 3, le processus de création des célèbres masques d'espionnage a été montré, grâce auquel certains personnages deviennent indiscernables des autres. Selon l'intrigue, il fallait d'abord photographier la personne que le héros voulait transformer sous plusieurs angles. En 2018, un simple modèle de visage 3D peut même ne pas être imprimé, mais au moins créé sous forme numérique - et basé sur une seule photo. Un chercheur de VisionLabs a décrit en détail le processus lors de l'événement Yandex «Le
monde à travers les yeux des robots » de la série Data & Science, avec des détails sur des méthodes et des formules spécifiques.
- Bonjour. Mon nom est Nikolai, je travaille pour VisionLabs, une société de vision par ordinateur. Notre profil principal est la reconnaissance faciale, mais nous disposons également de technologies applicables en réalité augmentée et virtuelle. En particulier, nous avons une technologie pour construire un visage 3D à partir d'une seule photo, et j'en parlerai aujourd'hui.

Commençons par une histoire sur ce que c'est. Sur la diapositive, vous voyez la photo originale de Jack Ma et un modèle 3D construit à partir de cette photo en deux variantes: avec et sans texture, juste la géométrie. C'est la tâche que nous résolvons.

Nous voulons également pouvoir animer ce modèle, changer la direction de notre regard, l'expression faciale, ajouter des expressions faciales, etc.
L'application est dans différents domaines. Les plus évidents sont les jeux, y compris la VR. Vous pouvez également faire des cabines d'essayage virtuelles - essayez des lunettes, des barbes et des coiffures. Vous pouvez faire de l'impression 3D, car certaines personnes sont intéressées par des accessoires personnalisés pour leur visage. Et vous pouvez faire des grimaces pour les robots: à la fois imprimer et afficher sur certains écrans du robot.

Je commencerai par vous expliquer comment générer des faces 3D en général, puis nous passerons à la tâche de reconstruction 3D en tant que tâche de génération inverse. Après cela, nous nous concentrerons sur l'animation et passerons aux défis qui se posent dans ce domaine.

Quelle est la tâche de générer des visages? Nous aimerions avoir un moyen de générer des visages tridimensionnels qui diffèrent par leur forme et leur expression. Voici deux lignes avec des exemples. La première rangée montre des visages de formes différentes, appartenant comme à des personnes différentes. Et ci-dessous est le même visage avec une expression différente.

Une façon de résoudre le problème de génération est les modèles déformables. La face la plus à gauche sur la diapositive est une sorte de modèle moyen auquel nous pouvons appliquer des déformations en ajustant les curseurs. Voici trois curseurs. Dans la rangée supérieure, il y a des faces dans le sens de l'augmentation de l'intensité du curseur, dans la rangée inférieure - dans le sens de la diminution. Ainsi, nous aurons plusieurs paramètres personnalisables. En les installant, vous pouvez donner aux gens différentes formes.

Un exemple de modèle déformable est le célèbre Basel Face Model, construit à partir de scans de visage. Pour construire un modèle déformable, vous devez d'abord prendre quelques personnes, les amener dans un laboratoire spécial et tirer sur leurs visages avec un équipement spécial, en les traduisant en 3D. Ensuite, sur cette base, vous pouvez faire de nouveaux visages.

Comment est-il organisé mathématiquement? Nous pouvons imaginer un modèle tridimensionnel d'un visage comme vecteur dans un espace tridimensionnel. Ici n est le nombre de sommets dans le modèle, chaque sommet correspond à trois coordonnées en 3D, et donc on obtient 3n coordonnées.

Si nous avons un ensemble de balayages, alors chaque balayage est représenté par un tel vecteur, et nous avons un ensemble de n tels vecteurs.
De plus, nous pouvons construire de nouvelles faces sous forme de combinaisons linéaires de vecteurs à partir de notre base de données. En même temps, nous aimerions que les coefficients soient significatifs. De toute évidence, ils ne peuvent pas être complètement arbitraires, et je montrerai bientôt pourquoi. L'une des restrictions peut être définie de sorte que tous les coefficients se situent dans la plage de 0 à 1. Cela doit être fait, car si les coefficients sont complètement arbitraires, les faces s'avéreront invraisemblables.

Ici, je voudrais donner aux paramètres une signification probabiliste. Autrement dit, nous voulons examiner un ensemble de paramètres et comprendre si une personne est susceptible de se révéler ou non. Par cela, nous voulons que de faibles distorsions correspondent à des visages déformés.

Voici comment procéder. Nous pouvons appliquer la méthode du composant principal à un ensemble d'analyses. En sortie, on obtient la face moyenne S0, on obtient la matrice V, un ensemble de composants principaux, et on obtient également des variations de données le long des composants principaux. Ensuite, nous pouvons jeter un regard neuf sur la génération de faces, nous représenterons les faces comme une face moyenne, plus la matrice des principaux composants, multipliée par le vecteur de paramètres.
La valeur des paramètres est l'intensité même des curseurs dont j'ai parlé dans l'une des diapositives précédentes. Et nous pouvons également attribuer une valeur probabiliste au vecteur de paramètres. En particulier, nous pouvons convenir que ce vecteur soit gaussien.

Ainsi, nous obtenons une méthode qui vous permet de générer des faces 3D, et cette génération est contrôlée par les paramètres suivants. Comme sur la diapositive précédente, nous avons deux ensembles de paramètres, deux vecteurs α id et α exp, ils sont les mêmes que sur la diapositive précédente, mais α id est responsable de la forme du visage, et α exp sera responsable de l'émotion.
Un nouveau vecteur T apparaît également - un vecteur de texture. Il a la même dimension que le vecteur de forme et chaque sommet de ce vecteur a trois valeurs RVB. De même, un vecteur de texture est généré à l'aide du vecteur de paramètres β. Ici les paramètres ne sont pas formalisés qui seront responsables de l'éclairage du visage et de sa position, mais ils existent également.

Voici des exemples de faces pouvant être générées à l'aide d'un modèle déformé. Veuillez noter qu'ils diffèrent par leur forme, leur couleur de peau et sont également dessinés dans différentes conditions d'éclairage.
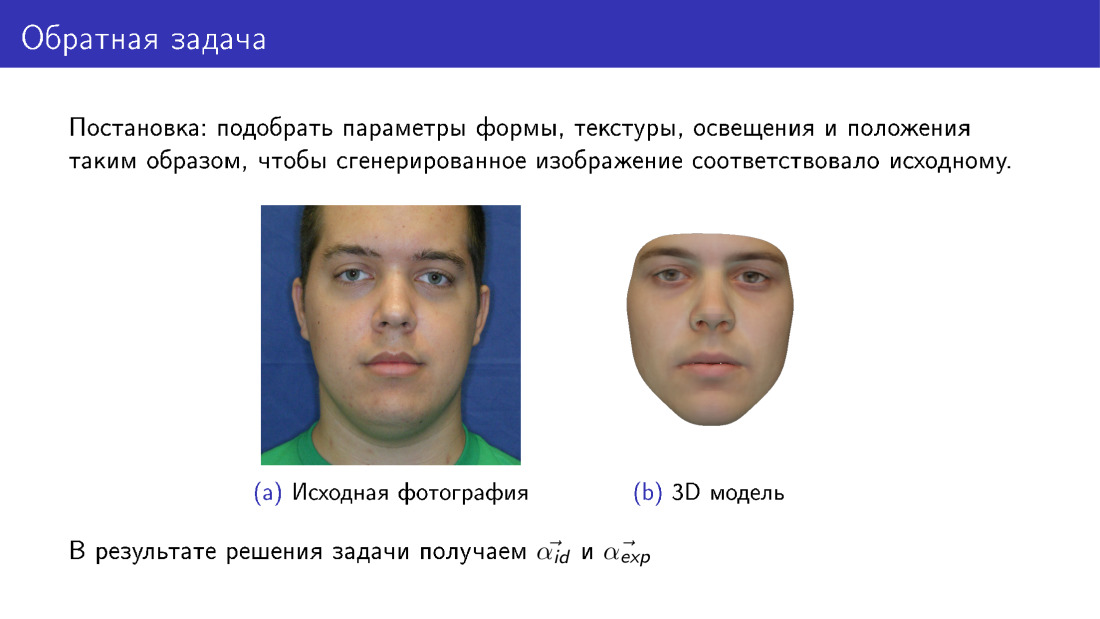
Nous pouvons maintenant passer à la reconstruction 3D. C'est ce qu'on appelle le problème inverse, car nous voulons sélectionner de tels paramètres pour le modèle déformable afin que la face que nous en tirons soit autant que possible similaire à l'original. Cette diapositive diffère de la première en ce qu'ici, à droite, le visage est entièrement synthétique. Si sur la première diapositive notre texture a été prise à partir d'une photographie, alors ici la texture a été prise à partir d'un modèle déformable.
À la sortie, nous aurons tous les paramètres, sur la diapositive α id et α exp sont présentés, et nous aurons également l'éclairage, les paramètres de texture, etc.

Nous avons dit que nous voulons nous assurer que le modèle généré ressemble à une photographie. Cette similitude est déterminée à l'aide de la fonction d'énergie. Ici, nous prenons simplement la différence pixel par pixel des images dans ces pixels où nous pensons que le visage est visible. Par exemple, si le visage est tourné, un chevauchement se produira. Par exemple, une partie de la pommette sera couverte par le nez. Et la matrice de visibilité M devrait afficher un tel chevauchement.
En substance, la reconstruction 3D vise à minimiser cette fonction énergétique. Mais pour résoudre ce problème de minimisation, ce serait bien d'avoir une initialisation et une régularisation. La régularisation est nécessaire pour une raison évidente, car nous avons dit que si nous ne régularisons pas les paramètres et les rendons complètement arbitraires, nous pouvons obtenir des visages déformés. L'initialisation est nécessaire car la tâche dans son ensemble est complexe, elle a des minima locaux et vous ne voulez pas les gérer.

Comment effectuer l'initialisation? Pour cela, vous pouvez utiliser 68 points clés du visage. Depuis 2013-2014, de nombreux algorithmes sont apparus qui permettent de détecter 68 points avec une assez bonne précision, et maintenant ils approchent d'une saturation de leur précision. Par conséquent, nous avons un moyen de détecter de manière fiable 68 points du visage.
Nous pouvons ajouter un nouveau terme à notre fonction énergétique, qui dira que nous voulons que les projections des mêmes 68 points du modèle coïncident avec les points clés du visage. Nous marquons ces points sur le modèle, puis nous déformons le modèle, le tordons, projetons les points et nous assurons que les positions des points coïncident. Sur la photo de gauche, il y a des points de deux couleurs, violet et jaune. Certains points ont été détectés par l'algorithme, tandis que d'autres ont été projetés à partir du modèle. Marquage des points sur le modèle à droite, mais pour les points le long du bord du visage, pas un point n'est marqué, mais une ligne entière. Cela est dû au fait que lorsque la face est tournée, les marques de ces points doivent changer et le point est sélectionné avec une ligne.

Voici le terme dont j'ai parlé, c'est la différence de coordonnées de deux vecteurs qui décrivent les points clés de la face et les points clés projetés à partir du modèle.

Revenons à la régularisation et considérons l'ensemble du problème du point de vue de la conclusion bayésienne. La probabilité que le vecteur α soit égal à quelque chose donné dans une image connue est proportionnelle au produit de la probabilité d'observer l'image pour un α donné, multiplié par la probabilité α. Si nous prenons le logarithme négatif de cette expression, que nous devrons minimiser, nous verrons que le terme responsable de la régularisation aura ici une forme concrète. Il s'agit en particulier du deuxième terme. Rappelant que nous avons précédemment fait l'hypothèse que le vecteur α est gaussien, nous voyons que le terme responsable de la régularisation est la somme des carrés des paramètres réduits aux variations le long des principales composantes.

Ainsi, nous pouvons écrire la fonction pleine énergie, qui contient trois termes. Le premier terme est responsable de la texture, de la différence de pixels entre l'image générée et l'image cible. Le deuxième terme est responsable des points clés, et le troisième est responsable de la régularisation.
Les coefficients des termes dans le processus de minimisation ne sont pas optimisés, ils sont simplement définis.
Ici, la fonction d'énergie est représentée en fonction de tous les paramètres. Paramètres de forme α id - face, paramètres α exp - expression, paramètres β - texture, p - autres paramètres dont nous avons parlé mais non formalisés, ce sont des paramètres de position et d 'éclairage.
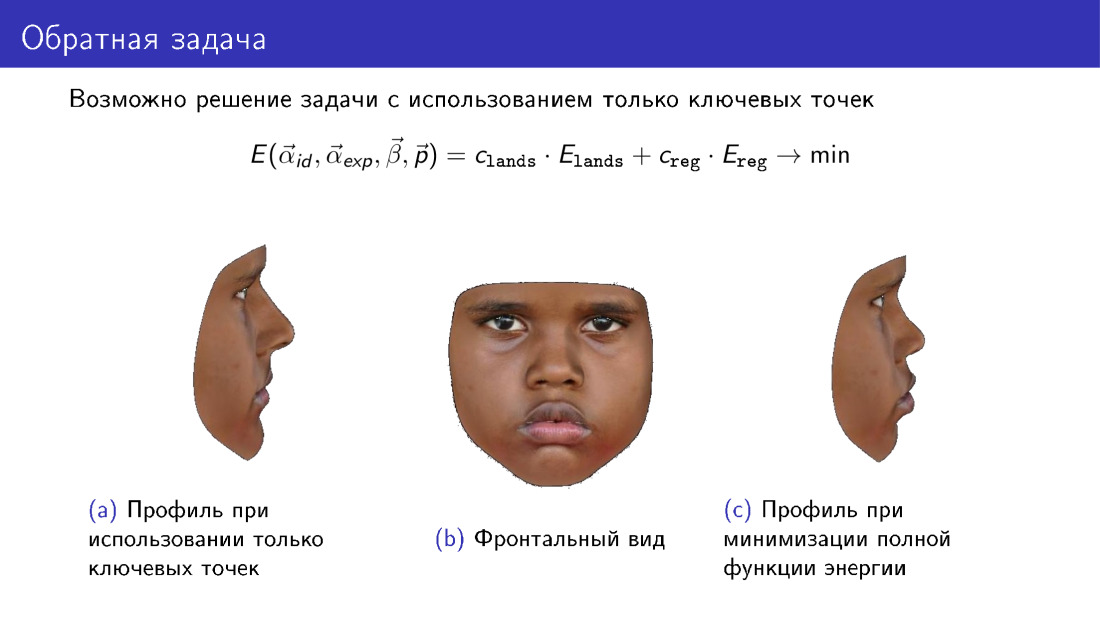
Arrêtons-nous sur cette remarque. Cette fonction énergétique peut être simplifiée. De là, vous pouvez jeter le terme qui est responsable de la texture, et utiliser uniquement les informations transmises par 68 points. Et cela vous permettra de construire une sorte de modèle 3D. Cependant, faites attention au profil du modèle. À gauche, un modèle construit uniquement aux points clés. À droite, un modèle utilisant une texture lors de la construction. Notez que le profil de droite est plus cohérent avec la photo centrale, qui représente la vue de face du visage.

L'animation avec l'algorithme existant pour construire un modèle 3D du visage fonctionne très simplement. Rappelons que lors de la construction d'un modèle 3D, nous obtenons deux vecteurs de paramètres, l'un responsable de la forme, l'autre de l'expression. Ces vecteurs de paramètres pour l'utilisateur et l'avatar auront toujours les leurs. L'utilisateur dispose d'un vecteur de paramètres de formulaire, l'avatar en a un autre. Cependant, nous pouvons faire en sorte que les vecteurs responsables de l'expression deviennent les mêmes pour eux. Nous prendrons les paramètres qui sont responsables de l'expression faciale de l'utilisateur, et nous les remplacerons simplement dans le modèle d'avatar. Ainsi, nous transférerons l'expression faciale de l'utilisateur vers l'avatar.
Parlons de deux défis dans ce domaine: la vitesse de travail et le modèle déformable limité.

La vitesse est vraiment un problème. Minimiser la fonction d'énergie totale est une tâche très exigeante en calcul. En particulier, cela peut prendre de 20 à 40, soit une moyenne de 30 secondes. C'est assez long. Si nous construisons un modèle tridimensionnel uniquement aux points clés, il se révélera beaucoup plus rapide, mais la qualité en souffrira.

Comment gérer ce problème? Vous pouvez utiliser plus de ressources, certaines personnes résolvent ce problème sur le GPU. Seuls les points clés peuvent être utilisés, mais la qualité en souffrira. Et vous pouvez utiliser des méthodes d'apprentissage automatique.

Voyons voir dans l'ordre. Voici le travail de 2016, dans lequel l'expression faciale de l'utilisateur est transférée vers une vidéo spécifique, vous pouvez contrôler la vidéo en utilisant votre visage. Ici, la construction du modèle 3D est réalisée en temps réel à l'aide du GPU.

Voici les méthodes qui utilisent l'apprentissage automatique. L'idée est que nous pouvons d'abord prendre une grande base de visages, pour chaque visage en utilisant un algorithme long mais précis pour construire des modèles 3D, présenter chaque modèle comme un ensemble de paramètres, puis former la grille pour prédire ces paramètres. En particulier, dans ce travail de 2016, ResNet est utilisé, qui prend une image à l'entrée et donne les paramètres du modèle à la sortie.

Le modèle tridimensionnel peut être représenté d'une autre manière. Dans ce travail de 2017, le modèle 3D n'est pas présenté comme un ensemble de paramètres, mais comme un ensemble de voxels. Le réseau prédit des voxels, transformant l'image en une représentation en trois dimensions. Il convient de noter que des options de formation en réseau sont possibles pour lesquelles les modèles 3D ne sont pas du tout nécessaires.

Cela fonctionne comme suit. Ici, la partie la plus importante est la couche, qui peut prendre les paramètres du modèle déformable en entrée et rendre l'image. Il a une telle propriété merveilleuse que vous pouvez faire la propagation arrière de l'erreur. Le réseau accepte une image en entrée, prédit les paramètres, envoie ces paramètres à une couche qui restitue l'image, compare cette image avec l'entrée, reçoit une erreur, propage l'erreur et continue d'apprendre. Ainsi, le réseau apprend à prédire les paramètres du modèle tridimensionnel, n'ayant que des images comme données d'apprentissage. Et c'est très intéressant.

Nous avons beaucoup parlé de précision - en particulier, qu'elle souffre si nous jetons certains termes de la fonction de l'énergie. Formalisons ce que cela signifie, comment vous pouvez évaluer la précision de la reconstruction du visage 3D. Pour ce faire, nous avons besoin d'une base de scans de vérité vérité obtenus à l'aide d'un équipement spécial, en utilisant des méthodes pour lesquelles il existe des garanties d'exactitude. Si une telle base existe, alors nous pouvons comparer nos modèles reconstruits avec la vérité du terrain. Cela se fait simplement: nous calculons la distance moyenne entre les sommets de notre modèle, que nous avons construit, aux sommets en vérité du sol, et normalisons à la taille du scan. Cela doit être fait parce que les faces sont différentes, certaines sont plus grandes, certaines sont plus petites et l'erreur sur la petite face serait plus petite, simplement parce que la face elle-même est plus petite. Par conséquent, une normalisation est nécessaire.

Je voudrais parler de notre travail, ce sera dans les ateliers, il y a l'ECCV. Nous faisons des choses similaires, nous enseignons à MobileNet à prédire les paramètres d'un modèle déformable. En tant que données d'entraînement, nous utilisons des modèles 3D conçus pour les photographies à partir du jeu de données 300W. Évaluez la précision en fonction des analyses BU4DFE.
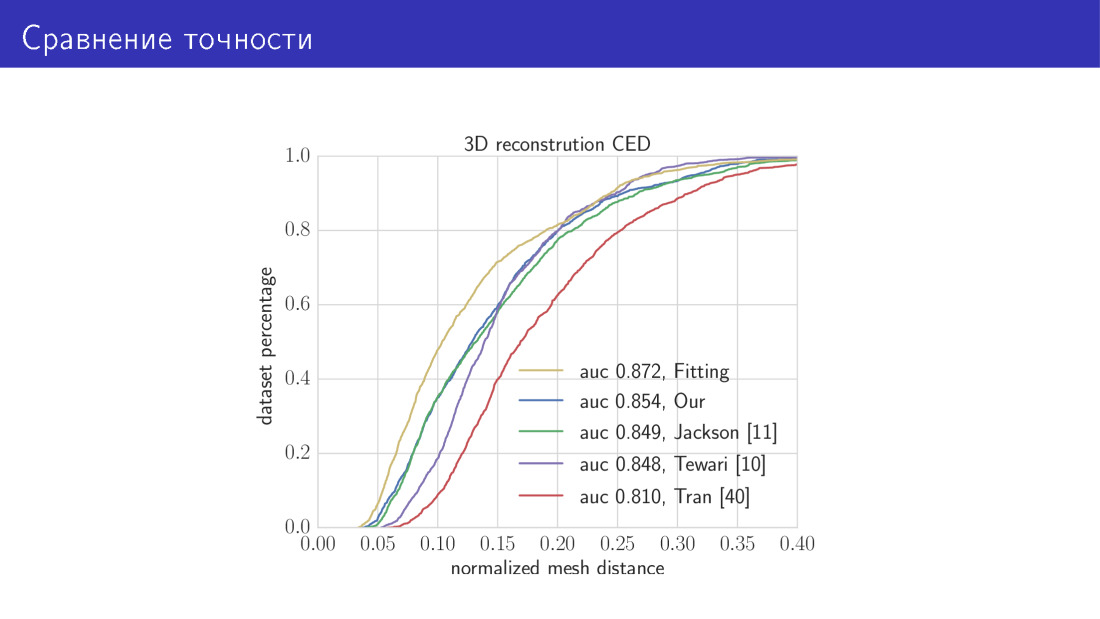
Voici le résultat. Nous comparons nos deux algorithmes avec l'état de l'art. La courbe jaune de ce graphique est un algorithme qui prend 30 secondes et consiste à minimiser la fonction d'énergie totale. Ici le long de l'axe X se trouve l'erreur dont nous venons de parler, la distance moyenne entre les sommets. L'axe Y est la fraction d'images dans laquelle cette erreur est plus petite que celle sur l'axe X. Dans ce graphique, plus la courbe est élevée, mieux c'est. La courbe suivante est notre réseau MobileNet. Ensuite, les trois œuvres dont nous avons parlé. Réseau prédictif de paramètres et réseau prédictif de voxels.
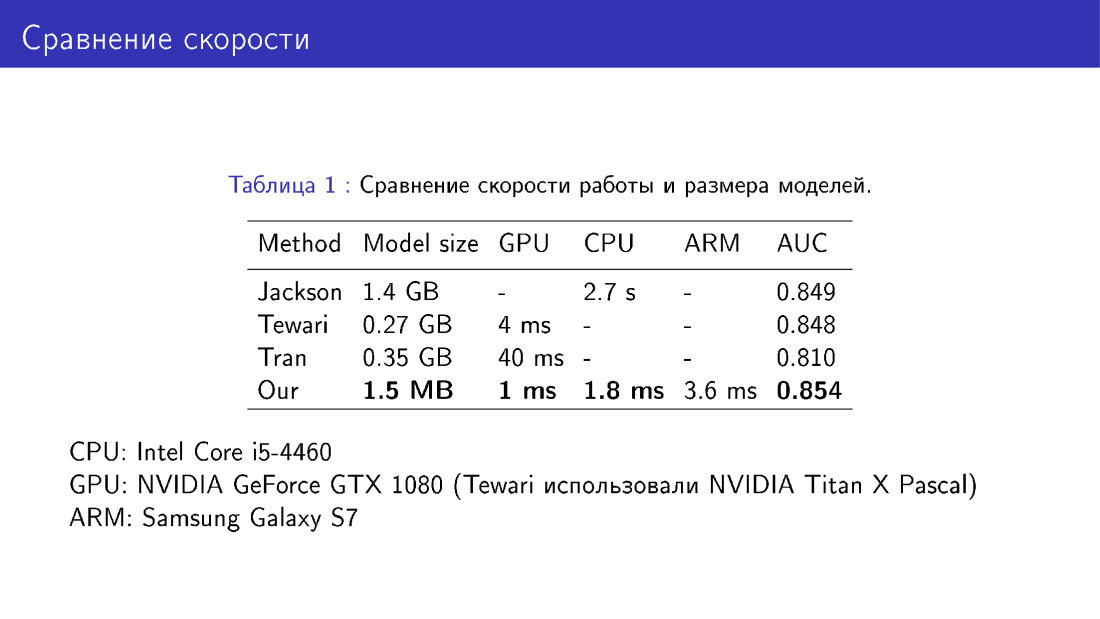
Nous avons également comparé notre réseau avec ses pairs en termes de taille et de vitesse du modèle. C'est une victoire car nous utilisons MobileNet, ce qui est assez simple.
Le deuxième défi est le caractère limité du modèle déformable.

Faites attention à la face gauche, regardez les ailes du nez. Il y a des ombres sur les ailes du nez. Les bords des ombres ne coïncident pas avec les bords du nez sur la photo, ainsi un défaut est obtenu. La raison en est peut-être que le modèle déformable, en principe, n'est pas en mesure de construire le nez de la forme requise, car ce modèle déformable a été obtenu à partir de scans de seulement 200 faces. Nous aimerions que le nez soit correct, comme sur la photo de droite. Il nous faut donc en quelque sorte dépasser le cadre du modèle déformable.

Cela peut être fait en utilisant une déformation non paramétrique du maillage. Voici trois tâches que nous aimerions résoudre: modifier la partie locale du visage, par exemple le nez, puis l'intégrer dans le modèle d'origine du visage, et même pour que tout le reste reste inchangé.

Cela peut être fait comme suit. Revenons à la désignation du maillage comme vecteur dans l'espace tridimensionnel et regardons l'opérateur de moyenne. Il s'agit d'un opérateur qui en S avec un en-tête remplace chaque sommet par la moyenne de ses voisins. Les voisins du pic sont ceux qui lui sont reliés par un bord.
Nous définirons une certaine fonction énergétique qui décrit la position du sommet par rapport à ses voisins. Nous voulons que la position du pic par rapport à ses voisins reste inchangée, ou du moins ne change pas grand-chose. Mais en même temps, nous modifierons en quelque sorte S. Cette fonction d'énergie est appelée interne, car il y aura également un terme externe, qui dira que, par exemple, le nez devrait prendre une forme donnée.
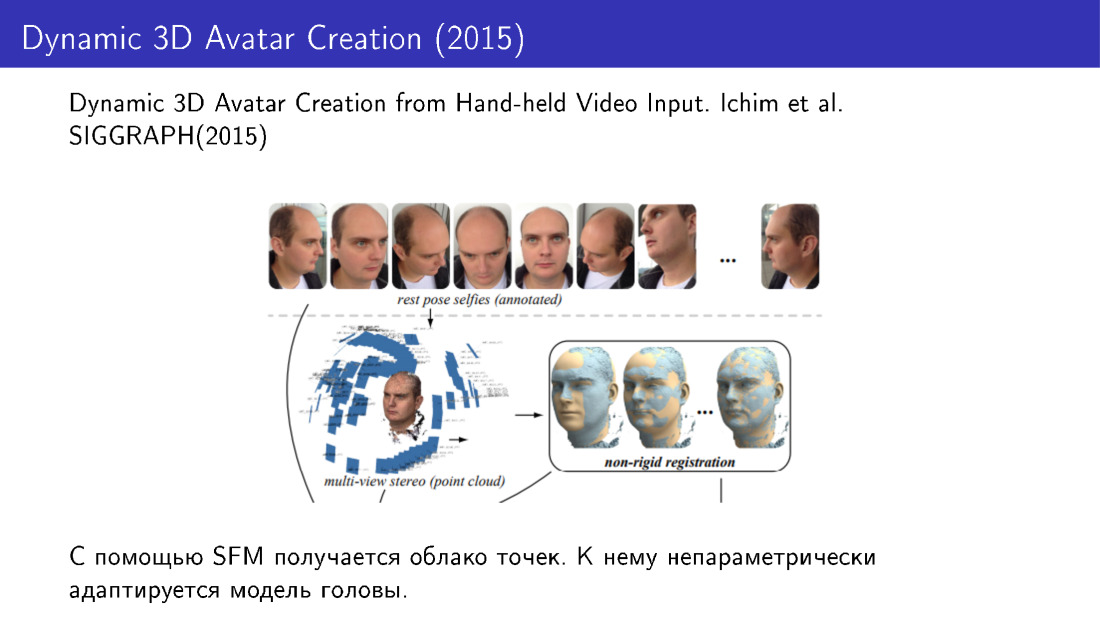
De telles techniques ont été utilisées, par exemple, dans les travaux de 2015. Ils ont fait la reconstruction du visage en 3D à partir de plusieurs photographies. Nous avons pris plusieurs photos du téléphone, reçu un nuage de points, puis adapté le modèle de visage à ce nuage en utilisant des modifications non paramétriques.
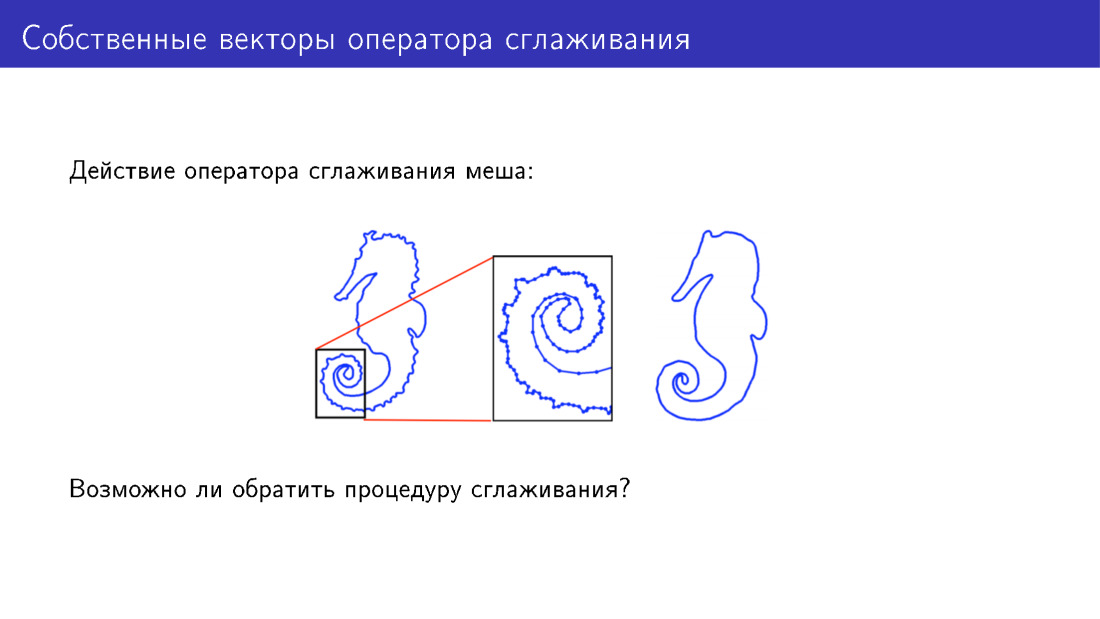
Vous pouvez aller au-delà du modèle déformable d'une autre manière. Arrêtons-nous sur l'action de l'opérateur de lissage. Ici, pour plus de simplicité, un maillage bidimensionnel est présenté auquel cet opérateur a été appliqué. Il y a beaucoup de détails sur le modèle à gauche; sur le modèle à droite, ces détails ont été lissés. Mais pouvons-nous faire quelque chose pour ajouter des détails plutôt que de les supprimer?

. .
? -: - . . , 2016 . , .