Bonjour à tous!
Netracker développe et fournit des applications d'entreprise pour le marché mondial des opérateurs de télécommunications depuis de nombreuses années. Le développement de telles solutions est assez compliqué: des centaines de personnes participent à des projets, et le nombre de projets actifs par dizaines.
Auparavant, les produits étaient monolithiques, mais nous nous dirigeons maintenant en toute confiance vers des applications de microservices. DevOps a été confronté à une tâche plutôt ambitieuse: fournir ce saut technologique.
En conséquence, nous avons obtenu un concept d'assemblage réussi, que nous voulons partager comme meilleure pratique. La description de l'implémentation avec les détails techniques sera assez volumineuse; nous ne le ferons pas dans le cadre de cet article.
Dans le cas général, l'assemblage est la transformation de certains artefacts en d'autres.
Qui sera intéressé
Les entreprises qui fournissent des logiciels prêts à l'emploi à une organisation entièrement tierce et sont rémunérées pour cela.
Voici à quoi pourrait ressembler un développement sans livraison externe:
- Le service informatique de l'usine développe des logiciels pour son entreprise.
- L'entreprise est engagée dans l'externalisation pour un client étranger. Le client compile et exploite indépendamment ce code sur son propre serveur Web.
- L'entreprise fournit des logiciels à des clients externes, mais sous licence open source. La majeure partie de la responsabilité est ainsi déchargée.
Si vous n'êtes pas confronté à une offre externe, une grande partie de ce qui est écrit ci-dessous vous semblera redondante, voire paranoïaque.
Dans la pratique, tout doit être fait conformément aux exigences internationales pour les licences et le cryptage utilisés, sinon des conséquences juridiques au moins se produiront.
Un exemple de violation consiste à prendre le code d'une bibliothèque avec une licence GPL3 et à l'intégrer dans une application commerciale.
L'émergence des microservices nécessite un changement
Nous avons acquis une vaste expérience dans l'assemblage et la livraison d'applications monolithiques.
Plusieurs serveurs Jenkins, des milliers de travaux CI, plusieurs chaînes de montage entièrement automatisées basées sur Jenkins, des dizaines d'ingénieurs de version dédiés, son propre groupe d'experts sur la gestion de la configuration.
Historiquement, l'approche dans l'entreprise était la suivante: les développeurs écrivent le code source, et DevOps inventent et écrivent la configuration du système d'assemblage.
En conséquence, nous avions deux ou trois configurations d'assemblage typiques conçues pour fonctionner dans l'écosystème de l'entreprise. Schématiquement, cela ressemble à ceci:
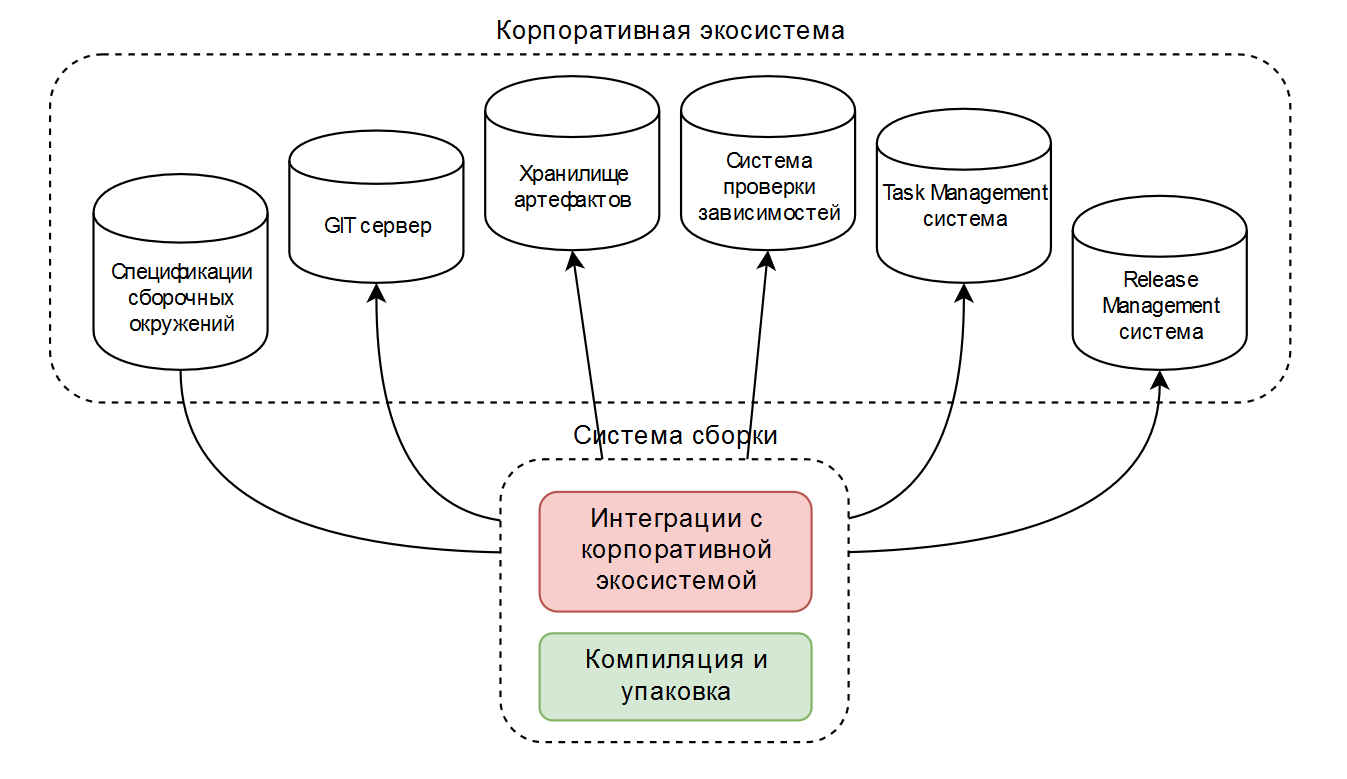
L'outil de construction est généralement ant ou maven, et quelque chose est implémenté par des plug-ins disponibles publiquement, quelque chose est écrit de lui-même. Cela fonctionne bien lorsqu'une entreprise utilise un ensemble restreint de technologies.
Les microservices diffèrent des applications monolithiques principalement par la variété des technologies.
Il s'avère que de nombreuses configurations d'assemblage pour au moins chaque langage de programmation. Le contrôle centralisé devient impossible.
Il est nécessaire de simplifier autant que possible les scripts d'assemblage et de permettre aux développeurs de les modifier indépendamment.
En plus d'une simple compilation et packaging (dans le diagramme en vert ), ces scripts contiennent beaucoup de code pour l'intégration avec l'écosystème de l'entreprise (dans le diagramme en rouge ).
Par conséquent, il a été décidé de percevoir l'assemblage comme une "boîte noire", dans laquelle un environnement d'assemblage "intelligent" peut résoudre tous les problèmes, à l'exception de la compilation et du conditionnement lui-même.
Au début des travaux, il n'était pas clair comment obtenir un tel système. Prendre des décisions architecturales pour les tâches DevOps nécessite de l'expérience et des connaissances. Comment les obtenir? Les options possibles sont ci-dessous:
- Recherchez des informations sur Internet.
- Propre expérience et connaissance de l'équipe DevOps. Pour ce faire, il est bon de faire de cette équipe de programmeurs une expérience polyvalente.
- Expérience et connaissances acquises en dehors de l'équipe DevOps. De nombreux développeurs de l'entreprise ont de bonnes idées - vous devez les entendre. La communication est utile.
- Nous inventons et expérimentons!
Ai-je besoin d'automatisation?
Pour répondre à cette question, vous devez comprendre à quel stade d'évolution sont nos approches d'assemblage. En général, une tâche passe par les niveaux suivants.
- Niveau inconscient

Nous devons sortir un assemblage par semaine, nos gars vont bien. C'est naturel, pourquoi en parler?
- Le niveau de «l'artisan», se transformant finalement en niveau de «l'escroc»

Il est nécessaire de produire deux assemblages par jour de manière stable et sans erreur. Nous avons Vasya, il le fait cool, et personne d'autre que lui ne passe ce temps.
- Niveau manufacture

Les choses sont allées loin. Vous avez besoin de 20 assemblées par jour, Vasya ne peut pas faire face, et maintenant une équipe de dix personnes est déjà assise. Ils ont un patron, des plans, des vacances, des congés de maladie, de la motivation, du team building, des formations, des traditions et des règles. Il s'agit d'une spécialisation, leur travail doit être étudié.
À ce niveau, la tâche est séparée de l'exécuteur testamentaire concret et devient ainsi un processus.
Le résultat sera une description claire, élaborée, rodée et corrigée des centaines de fois du processus avec du texte.
- Le niveau de «production automatisée»

Les exigences modernes pour les assemblages augmentent: tout doit être rapide, fiable, 800 assemblages doivent être fournis par jour. Cela est essentiel, car sans ces volumes, l'entreprise perdra ses avantages concurrentiels.
Une automatisation coûteuse est en cours et quelques DevOps qualifiés peuvent maintenir le processus en cours. Une mise à l'échelle supplémentaire n'est plus un problème.
Toutes les tâches ne doivent pas atteindre la dernière étape de l'automatisation.
Souvent, un artisan possédant une ligne de commande résout les problèmes facilement et efficacement.
L'automatisation «fige» le processus, réduit le coût de fonctionnement et augmente le coût du changement.
Vous pouvez vous rendre directement à l'assemblage de la voiture, mais le système sera gênant, ne suivra pas les exigences de l'entreprise et, par conséquent, deviendra obsolète.
Quels sont les assemblages et pourquoi le problème n'est pas résolu par des systèmes d'assemblage prêts à l'emploi

Nous utilisons la classification suivante pour déterminer les niveaux d'agrégation d'assemblage.
L1. Une petite partie indépendante d'une grande application. Il peut s'agir d'un composant, d'un microservice ou d'une bibliothèque auxiliaire. L'assemblage L1 est une solution aux problèmes techniques linéaires: compilation, packaging, travail avec les dépendances. Maven, gradle, npm, grunt et d'autres systèmes de construction font un excellent travail. Il y en a des centaines.
L'assemblage L1 doit être effectué à l'aide d'outils tiers prêts à l'emploi.
L2 +. Entités d'intégration. Les entités L1 sont combinées en formations plus grandes, par exemple, en applications de microservices à part entière. Plusieurs de ces applications peuvent être regroupées en une seule solution. Nous utilisons le signe «+», car en fonction du niveau d'agrégation d'assemblage, un niveau L3 ou même L4 peut être attribué.
Un exemple de tels assemblages dans le monde des tiers est la préparation des distributions Linux. Méta-packages là-bas.
En plus de tâches techniques assez complexes (comme celle-ci: ru.wikipedia.org/wiki/Dependency_hell ). Les assemblages L2 + sont souvent le produit final et ont donc de nombreuses exigences de processus: un système de droits, la fixation de personnes responsables, l'absence d'erreurs légales, la fourniture de divers documents.
Chez L2 +, les exigences de processus sont hiérarchisées par l'automatisation.
Si la solution automatique ne fonctionne pas car elle convient aux personnes intéressées, elle ne sera pas mise en œuvre.
Les assemblages L2 + seront très probablement réalisés par un outil propriétaire spécifiquement adapté aux processus de l'entreprise. Pensez-vous que les gestionnaires de packages Linux viennent juste avec ça?
Nos bonnes pratiques
L'infrastructure
Disponibilité permanente de fer
L'ensemble de l'infrastructure d'assemblage se trouve sur des serveurs fermés à l'intérieur du réseau d'entreprise. Dans certains cas, des services cloud commerciaux sont possibles.
Autonomie
Dans tous les processus CI, Internet n'est pas disponible. Toutes les ressources nécessaires sont mises en miroir et mises en cache en interne. Partiellement même github.com (merci, npm!) La plupart de ces problèmes sont résolus par Artifactory.
Par conséquent, nous sommes calmes lors de la suppression d'artefacts de maven central ou de la fermeture de référentiels populaires. Il y a un exemple: community.oracle.com/community/java/javanet-forge-sunset .
La mise en miroir réduit considérablement le temps d'assemblage et libère le canal Internet d'entreprise. Moins de ressources réseau critiques augmentent la stabilité de la construction.
Trois référentiels pour chaque type d'artefact
- Dev est un référentiel où n'importe qui peut publier des artefacts de toute origine. Ici, vous pouvez expérimenter des approches fondamentalement nouvelles sans les adapter aux normes de l'entreprise dès le premier jour.
- Le staging est un référentiel rempli uniquement avec un pipeline d'assemblage.
- Libération - assemblages simples, prêts pour une livraison externe. Il est rempli d'une opération de transfert spéciale avec confirmation manuelle.
Règle des 30 jours
Dans les référentiels Dev et Staging, nous supprimons tout ce qui date de plus de 30 jours. Cela permet de garantir à tous des opportunités de publication égales en dépensant une quantité limitée d'espace disque sur le serveur.
La version est stockée pour toujours, l'archivage est effectué si nécessaire.
Environnement d'assemblage propre
Souvent, après les assemblages, les fichiers auxiliaires restent dans le système, ce qui peut affecter d'autres processus d'assemblage. Exemples typiques:
- le problème le plus courant est un cache endommagé par un assemblage incorrect (comment traiter les caches, décrit ci-dessous);
- certains utilitaires, tels que npm, laissent des fichiers de service dans le répertoire $ HOME qui affectent tous les lancements ultérieurs de ces utilitaires;
- un assembly particulier peut dépenser tout l'espace disque d'une partition / tmp, ce qui entraînera une indisponibilité générale de l'environnement.
Par conséquent, il vaut mieux abandonner l'environnement unifié au profit des conteneurs dockers. Les conteneurs ne doivent contenir que le logiciel nécessaire pour un assemblage spécifique avec des versions fixes.
DevOps gère une collection d'images Docker d'assemblage, qui est constamment mise à jour. Au début, il y en avait environ six, puis c'était moins de 30, puis nous avons mis en place une génération automatique d'images à partir de la liste des logiciels. Maintenant, spécifiez simplement des exigences telles que require ('maven 3.3.9', 'python') - et l'environnement est prêt.
Auto-diagnostic
Il n'est pas seulement nécessaire d'organiser le support utilisateur pour les demandes, nous devons analyser nous-mêmes le comportement de notre propre système. Nous collectons constamment des journaux, recherchons dans ceux-ci des mots clés montrant des problèmes.
Sur un système "live", il suffit d'écrire 20 à 30 expressions régulières pour que pour chaque assemblage vous puissiez dire la raison de sa chute au niveau:
- Crash du serveur Git
- l'espace disque est épuisé;
- erreur de construction due à la faute du développeur;
- Bug connu dans Docker.
Si quelque chose est tombé, mais qu'aucun problème connu n'a été détecté, c'est l'occasion de reconstituer la collection de masques.
Ensuite, nous allons à l'utilisateur et disons qu'il a une version et cela peut être corrigé de cette façon.
Vous serez surpris du nombre de problèmes que les utilisateurs ne signalent pas à l'appui. Il est préférable de les réparer à l'avance et à un moment opportun. Souvent, une erreur de publication mineure est ignorée pendant deux semaines, et vendredi soir, il s'avère que cela bloque la sortie externe.
Nous choisissons soigneusement les systèmes dont dépend l'assemblage
Idéalement, en général, pour assurer une autonomie complète de l'ensemble, mais le plus souvent cela est impossible. Pour les assemblys basés sur java, vous avez besoin d'au moins Artifactory pour la mise en miroir - voir ci-dessus pour l'autonomie. Chaque système intégré augmente le risque de défaillance. Il est souhaitable que tous les systèmes fonctionnent en mode HA décent.
Interface de ligne d'assemblage
Interface unique pour appeler l'assembly
Nous réalisons tout type d'assemblage avec un seul système. Les assemblages de tous les niveaux (L1, L2 +) sont décrits par code de programme et sont appelés via un travail Jenkins.
Cependant, cette approche n'est pas idéale. Il est préférable d'utiliser les mécanismes de génération automatique de travaux Jenkins: par exemple, 1 travail = 1 référentiel git ou 1 travail = 1 branche git. Cela permettra d'atteindre les objectifs suivants:
- les journaux d'assemblages hétérogènes ne sont pas confondus dans une seule histoire sur la page de travail Jenkins;
- en fait, vous obtenez des emplois attribués confortables pour une équipe ou pour un développeur; la sensation de confort peut être améliorée en ajustant les graphiques des résultats de junit, cobertura, sonar.
Liberté de choisir la technologie
Le démarrage de la construction est un appel au script bash "./build.sh". Et puis - tous les systèmes d'assemblage, les langages de programmation et tout ce qui sera nécessaire pour effectuer une tâche commerciale. Cela fournit une approche de l'assemblage sous forme de boîte noire.
Message intelligent
La chaîne de montage intercepte les publications de la boîte noire et les place déjà dans le stockage de l'entreprise. Pour cela, les problèmes ennuyeux tels que la génération de noms d'images Docker et le choix du bon référentiel pour la publication sont automatiquement résolus.
Les référentiels de staging et de release ont toujours de l'ordre. Il est nécessaire pour prendre en charge les spécificités des publications de différents types: maven, npm, file, docker.
Descripteur d'assemblage
Build.sh décrit comment compiler du code, mais cela ne suffit pas pour un conteneur d'assembly.
Vous devez également savoir:
- quel environnement d'assemblage utiliser;
- variables d'environnement disponibles dans build.sh;
- quelles publications seront effectuées;
- d'autres options spécifiques.
Nous avons choisi un moyen pratique de décrire ces informations sous la forme d'un fichier yaml ressemblant à distance à .gitlab-ci.yaml.
Paramétrage de l'assemblage
L'utilisateur peut spécifier des paramètres arbitraires sans exécuter la commande git commit dès le début de l'assembly.
Nous l'avons implémenté en définissant des variables d'environnement directement à partir de l'interface de travail Jenkins.
Par exemple, nous transférons la version de la bibliothèque dépendante vers un tel paramètre d'assembly et, dans certains cas, redéfinissons cette version en une version expérimentale. Sans un tel mécanisme, l'utilisateur devrait exécuter la commande «git commit» à chaque fois.
Portabilité du système
Vous devez être en mesure de reproduire le processus d'assemblage non seulement sur le serveur CI principal, mais également sur l'ordinateur du développeur. Cela aide à déboguer des scripts de construction complexes. De plus, au lieu de Jenkins, il sera parfois plus pratique d'utiliser Gitlab CI. Par conséquent, le système de génération doit être une application java indépendante. Nous l'avons implémenté comme un plugin gradle.
Un artefact peut être publié sous différents noms.
Il existe deux exigences opposées pour la publication qui peuvent survenir simultanément.
D'une part, pour le stockage à long terme et la gestion des versions, il est nécessaire de garantir l'unicité des noms des artefacts publiés. Cela protégera au moins les artefacts contre l'écrasement.
D'un autre côté, il est parfois pratique d'avoir un artefact réel avec un nom fixe comme le plus récent. Par exemple, le développeur n'a pas besoin de connaître la version exacte de la dépendance à chaque fois, vous pouvez simplement travailler avec la dernière version.
L'artefact dans ce cas est publié sous deux noms ou plus, car il convient à tout le monde.
Par exemple:
- un nom unique avec horodatage ou UUID - pour ceux qui ont besoin de précision;
- le nom «dernier» - pour leurs développeurs, qui récupèrent toujours le dernier code;
- le nom "<major version> .x-latest" est pour une équipe voisine qui est prête à récupérer les dernières versions, mais uniquement dans le cadre d'une certaine majeure.
Maven fait quelque chose de similaire dans son approche de SNAPSHOT.
Moins de restrictions de sécurité
Tout le monde peut commencer l'assemblage. Cela ne nuira à personne, car l'assemblage crée uniquement des artefacts.
Conformité légale
Contrôle des interactions externes du processus d'assemblage
L'assemblée ne peut utiliser aucun élément interdit dans le cadre de ses travaux.
Pour cela, l'enregistrement du trafic réseau et l'accès aux caches de fichiers sont implémentés. Nous obtenons le journal d'activité réseau de l'assemblage sous la forme d'une liste d'url avec sha256 hachages des données reçues. De plus, chaque URL est validée:
- liste blanche statique;
- base de données dynamique des artefacts autorisés (par exemple, pour les dépendances maven-, rpm-, npm-). Chaque dépendance est considérée individuellement. Un permis automatique ou une interdiction d'utilisation peut fonctionner, et une longue discussion avec les avocats peut également commencer.
Contenu transparent des artefacts publiés
Parfois, la tâche consiste à fournir une liste de logiciels tiers dans n'importe quel assemblage. Pour ce faire, ils ont réalisé un analyseur de composition simple qui analyse tous les fichiers et archives de l'assemblage, reconnaît le tiers par hachage et fait un rapport.
Le code source émis ne peut pas être supprimé de GIT
Parfois, vous devrez peut-être trouver le code source en consultant l'artefact binaire compilé il y a deux ans. Pour ce faire, il est nécessaire d'allouer automatiquement des balises dans Git avec une sortie externe, ainsi que d'interdire leur suppression.
Logistique et comptabilité
Tous les assemblages sont stockés dans la base de données.
Nous utilisons le référentiel de fichiers dans Artifactory à ces fins. Il contient toutes les informations à l'appui: qui l'a lancé, quels ont été les résultats des vérifications, quels artefacts ont été publiés, quel git hash a été utilisé, etc.
Nous savons reproduire le montage le plus fidèlement possible
Selon les résultats de l'assemblage, nous stockons les informations suivantes:
- l'état exact du code qui a été collecté;
- avec quels paramètres le lancement a été effectué;
- quelles commandes ont été appelées;
- quel accès aux ressources externes a eu lieu;
- environnement d'assemblage utilisé.
Si nécessaire, nous pouvons répondre avec précision à la question de savoir comment il a été assemblé.
Communication bidirectionnelle de l'assemblée avec le ticket JIRA
Assurez-vous de pouvoir résoudre les problèmes suivants:
- pour l'assemblage, créez une liste des tickets JIRA qui y sont inclus;
- écrire dans le ticket JIRA dans quels assemblages il est inclus.
Une communication bidirectionnelle étroite entre l'assembly et git commit est fournie. Et puis, à partir du texte des commentaires, vous pouvez déjà découvrir tous les liens vers JIRA.
La vitesse
Caches de système d'assemblage
L'absence de cache Maven peut augmenter le temps de génération d'une heure.
Le cache viole l'isolement de l'environnement d'assemblage et la propreté de l'assemblage. Ce problème peut être résolu en déterminant son origine pour chaque artefact mis en cache. Nous avons chaque fichier cache associé à un lien https à partir duquel il a été téléchargé une fois. De plus, nous traitons la lecture d'un cache en tant qu'adresse réseau.
Caches de ressources réseau
La croissance géographique de l'entreprise conduit à la nécessité de transférer des fichiers de 300 Mo entre les continents. Beaucoup de temps est consacré, surtout si vous devez le faire souvent.
Référentiels Git, images docker des environnements d'assemblage, stockages de fichiers - tout doit être soigneusement mis en cache. Eh bien, bien sûr, périodiquement propre.
Assemblage - aussi vite que possible, tout le reste - puis
La première étape: nous faisons le montage et immédiatement, sans gestes inutiles, nous donnons le résultat.
La deuxième étape: validation, analyse, comptabilité et autre bureaucratie. Cela peut déjà être fait dans un travail Jenkins séparé et sans limites de temps strictes.
Quel est le résultat
- L'essentiel est que l' assemblage soit devenu clair pour les développeurs , eux-mêmes peuvent le développer et l'optimiser.
- La fondation a été créée pour construire des processus métier qui dépendent de l'assemblage: installation, gestion des problèmes, tests, gestion des versions, etc.
- L'équipe DevOps n'écrit plus de scripts d'assemblage: les développeurs le font.
- Les exigences complexes de l'entreprise se sont transformées en un rapport transparent avec une liste finale de contrôles.
- Tout le monde peut créer n'importe quel référentiel simplement en appelant build.sh via une seule interface. Il lui suffit de spécifier simplement les coordonnées git du code source. Cette personne peut être chef d'équipe, ingénieur QA / IT, etc.
Et quelques chiffres
- Coûts de temps. 15 Jenkins job build.sh. 15 docker-, , . . .
- . . 2200 . — on-commit-.
- 300 git-, .
- 30 , (25 ) — docker.
- , :
- glide, golang, promu;
- maven, gradle;
- python & pip;
- ruby;
- nodejs & npm;
- docker;
- rpm build tools & gcc;
- Android ADT;
- ;
- legacy-;
- .