Plus tôt, nous avons
parlé du supercalculateur japonais le plus puissant pour la recherche en physique nucléaire. Un superordinateur exaflops Post-K est en cours de création au Japon - les Japonais seront parmi les premiers à lancer une machine avec une telle puissance de calcul.
La mise en service est prévue pour 2021.
La semaine dernière, Fujitsu a parlé des caractéristiques techniques de la puce A64FX, qui constituera la base de la nouvelle "machine". Nous vous en dirons plus sur la puce et ses capacités.
 / photo Toshihiro Matsui CC / Supercalculateur japonais K
/ photo Toshihiro Matsui CC / Supercalculateur japonais KSpécifications A64FX
Il est prévu que les capacités informatiques de Post-K seront presque dix fois
supérieures aux performances du plus puissant des supercalculateurs
IBM Summit existants (
en juin 2018 ).
Le supercalculateur doit des performances similaires à celles de la puce basée sur le bras A64FX. Cette puce se
compose de 48 cœurs pour les opérations de calcul et de quatre cœurs pour les contrôler. Tous sont également répartis en quatre groupes - les groupes de mémoire de base (CMG).
Chaque groupe dispose de 8 Mo de cache L2. Il est connecté au contrôleur mémoire et à l'interface NoC ("
network on a chip "). NoC connecte différents CMG aux contrôleurs PCIe et Tofu. Ce dernier est responsable de la communication entre le processeur et le reste du système. Le contrôleur Tofu possède dix ports avec un débit de 12,5 Go / s.
La disposition des puces est la suivante:
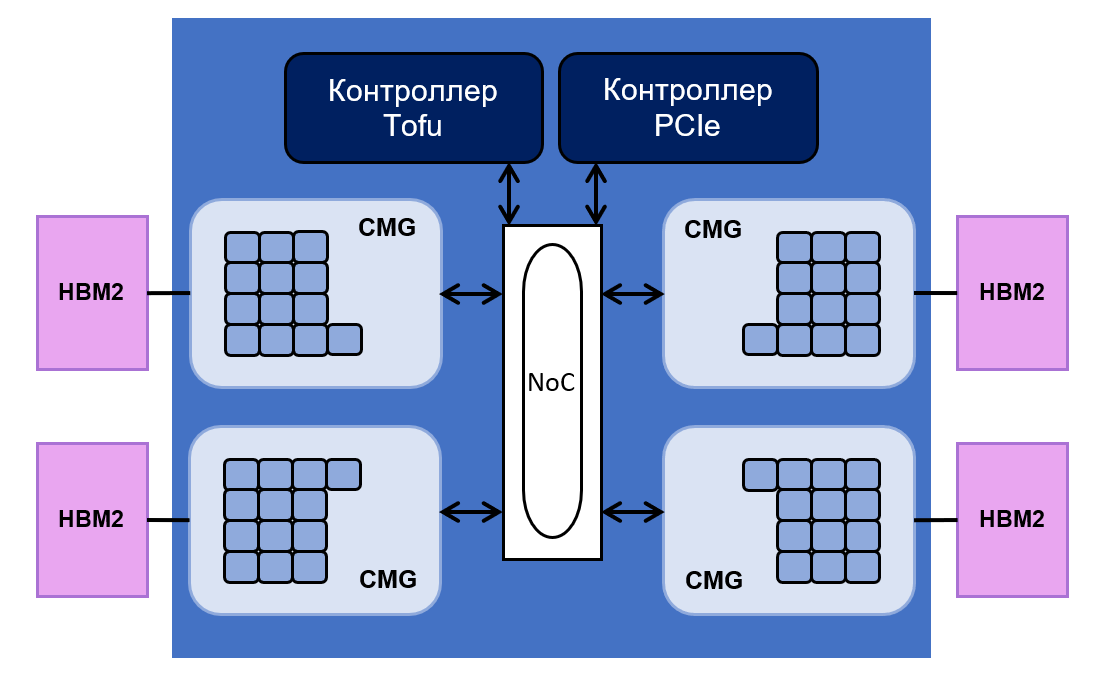
La mémoire totale
HBM2 du processeur est de 32 gigaoctets et son débit est égal à 1024 Go / s. Fujitsu affirme que les performances du processeur sur les opérations en virgule flottante atteignent 2,7 téraflops pour les opérations 64 bits, 5,4 téraflops pour 32 bits et 10,8 téraflops pour 16 bits.
La création de Post-K est surveillée par les éditeurs de ressources Top500, qui compilent une liste des systèmes informatiques les plus puissants. Selon eux, afin d'atteindre des performances dans un exaflops, le supercalculateur utilise plus de 370 000 processeurs A64FX.
L'appareil utilisera d'abord la technologie d'extension vectorielle appelée Scalable Vector Extension (SVE). Il diffère des autres
architectures SIMD en ce qu'il ne
limite pas
la longueur des registres vectoriels, mais définit une plage valide pour eux. SVE prend en charge des vecteurs de 128 à 2048 bits. Ainsi, n'importe quel programme peut être exécuté sur d'autres processeurs qui prennent en charge SVE, sans avoir besoin de recompilation.
En utilisant SVE (car il s'agit d'une fonction SIMD), le processeur peut effectuer simultanément des calculs avec plusieurs tableaux de données. Voici un exemple de l'une de ces instructions pour la fonction NEON, qui a été utilisée pour le calcul vectoriel dans d'autres architectures de processeur Arm:
vadd.i32 q1, q2, q3
Il ajoute quatre entiers 32 bits du registre 128 bits q2 avec les nombres correspondants dans le registre 128 bits q3 et écrit le tableau résultant dans q1. L'équivalent de cette opération en C ressemble à ceci:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
De plus, SVE prend en charge la vectorisation automatique. Un vectoriseur automatique analyse les cycles dans le code et, si possible, utilise des registres vectoriels pour les exécuter. Cela améliore les performances du code.
Par exemple, une fonction en C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
Il sera compilé comme suit (pour un processeur Arm 32 bits):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
Si vous utilisez la vectorisation automatique, cela ressemblera à ceci:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
Ici, les registres SIMD q8 et q9 sont chargés avec des données provenant de tableaux pointés par r5 et r4. Après cela, l'instruction vadd ajoute quatre valeurs entières de 32 bits à la fois. Cela augmente la quantité de code, mais de cette façon, beaucoup plus de données sont traitées pour chaque itération de la boucle.
Qui d'autre crée des superordinateurs exaflops
Les superordinateurs Exaflops ne sont pas uniquement créés au Japon. Par exemple, des travaux sont également en cours en Chine et aux États-Unis.
En Chine, créez Tianhe-3 (Tianhe-3). Son prototype est déjà en
cours de test au National Supercomputing Center de Tianjin. La version finale de l'ordinateur devrait être achevée en 2020.
 / photo O01326 CC / Tianhe-2 Supercomputer - prédécesseur de Tianhe-3
/ photo O01326 CC / Tianhe-2 Supercomputer - prédécesseur de Tianhe-3Au cœur de Tianhe-3 se
trouvent des processeurs chinois Phytium. L'appareil contient 64 cœurs,
a une performance de 512 gigaflops et une bande passante mémoire de 204,8 Go / s.
Un prototype fonctionnel a également été créé pour une machine de la série
Sunway . Il est actuellement testé au National Supercomputer Center de Jinan. Selon les développeurs, environ 35 applications fonctionnent actuellement sur l'ordinateur - ce sont des simulateurs biomédicaux, des applications de traitement des mégadonnées et des programmes d'étude du changement climatique. Les travaux sur l'ordinateur devraient être achevés au cours du premier semestre 2021.
Quant aux États-Unis, les Américains
prévoient de créer leur ordinateur exaflops d'ici 2021. Le projet s'appelle Aurora A21, et le
laboratoire national d'Argonne du département américain de l'Énergie , ainsi qu'Intel et Cray y travaillent.
Cette année, les chercheurs ont déjà
sélectionné dix projets pour le programme Aurora Early Science, dont les participants seront les premiers à utiliser le nouveau système haute performance. Parmi eux se trouvaient des programmes pour créer une
carte des neurones du cerveau, étudier la matière noire et développer un simulateur d'accélérateur de particules.
Les ordinateurs Exaflops permettront de construire des modèles de recherche complexes, de nombreux projets scientifiques attendent la création de telles machines. L'un des plus ambitieux est le Human Brain Project (HBP), dont l'objectif est de créer un modèle complet du cerveau humain et d'étudier les calculs neuromorphiques. Selon
les scientifiques de HBP, l'utilisation de nouveaux systèmes d'exaflops peut être trouvée dès les premiers jours de leur existence.
Ce que nous faisons dans IT-GRAD: • IaaS • Hébergement PCI DSS • Cloud -152
Contenu de notre blog d'entreprise IaaS: