Ce printemps, un important concours rétro OpenAI a eu lieu, consacré à l'apprentissage par renforcement, au méta-apprentissage et, bien sûr, à Sonic. Notre équipe a pris la 4e place sur 900+ équipes. Le domaine de la formation avec renforcement est légèrement différent de l'apprentissage automatique standard, et ce concours était différent d'une compétition RL typique. Je demande des détails sous chat.
TL; DR
Une ligne de base correctement réglée n'a pas besoin de trucs supplémentaires ... pratiquement.
Introduction à la formation de renforcement
L'apprentissage renforcé est un domaine qui combine la théorie du contrôle optimal, la théorie des jeux, la psychologie et la neurobiologie. Dans la pratique, l'apprentissage par renforcement est utilisé pour résoudre des problèmes de prise de décision et rechercher des stratégies comportementales optimales ou des politiques trop complexes pour une programmation «directe». Dans ce cas, l'agent est formé sur l'historique des interactions avec l'environnement. L'environnement, à son tour, évaluant les actions de l'agent, lui fournit une récompense (scalaire) - meilleur est le comportement de l'agent, meilleure est la récompense. En conséquence, la meilleure politique est apprise de l'agent qui a appris à maximiser la récompense totale pendant toute la durée de l'interaction avec l'environnement.
À titre d'exemple simple, vous pouvez jouer à BreakOut. Dans ce bon vieux jeu de la série Atari, une personne / un agent doit contrôler la plate-forme horizontale inférieure, frapper la balle et casser progressivement tous les blocs supérieurs avec elle. Le plus renversé - plus la récompense est grande. En conséquence, ce qu'une personne / un agent voit est une image d'écran et il est nécessaire de décider dans quelle direction déplacer la plate-forme inférieure.
Si vous êtes intéressé par le sujet de la formation de renforcement, je vous conseille un cours d'introduction sympa de HSE , ainsi que son homologue open source plus détaillé. Si vous voulez quelque chose que vous pouvez lire, mais avec des exemples - un livre inspiré de ces deux cours. J'ai révisé / terminé / aidé à créer tous ces cours, et par conséquent, je sais par ma propre expérience qu'ils fournissent une excellente base.
À propos de la tâche
L'objectif principal de cette compétition était de trouver un agent capable de bien jouer dans la série de jeux SEGA - Sonic The Hedgehog. OpenAI commençait tout juste à importer des jeux de SEGA dans sa plateforme de formation d'agents RL, et a donc décidé de promouvoir un peu ce moment. Même l' article a été publié avec l'appareil de tout et une description détaillée des méthodes de base.
Les 3 jeux Sonic ont été pris en charge, chacun avec 9 niveaux, auxquels, en jetant une larme en larmes, vous pouvez même jouer, en vous souvenant de votre enfance (après les avoir achetés sur Steam en premier).
L'état de l'environnement (ce que l'agent a vu) était l'image du simulateur - une image RVB, et en tant qu'action, l'agent a été invité à choisir le bouton du joystick virtuel sur lequel appuyer - sauter / gauche / droite et ainsi de suite. L'agent a reçu des points de récompense ainsi que dans le jeu original, c'est-à-dire pour la collecte des anneaux, ainsi que pour la vitesse de passage du niveau. En fait, nous avions une sonique originale devant nous, seulement il fallait la passer avec l'aide de notre agent.
Le concours s'est déroulé du 5 avril au 5 juin, soit seulement 2 mois, ce qui semble assez petit. Notre équipe n'a pu se réunir et participer à la compétition qu'en mai, ce qui nous a fait beaucoup apprendre en déplacement.
Baselines
À titre de référence, des guides de formation complets pour la formation Rainbow (approche DQN) et PPO (approche Gradient politique) à l'un des niveaux possibles dans Sonic et la soumission de l'agent résultant ont été fournis.
La version Rainbow était basée sur le projet anyrl peu connu, mais PPO utilisait les bonnes vieilles lignes de base d'OpenAI et nous semblait beaucoup plus préférable.
Les lignes de base publiées diffèrent des approches décrites dans l'article par leur plus grande simplicité et leurs petits ensembles de «hacks» pour accélérer l'apprentissage. Ainsi, les organisateurs ont lancé des idées et fixé la direction, mais la décision sur l'utilisation et la mise en œuvre de ces idées a été laissée au participant au concours.
En ce qui concerne les idées, je voudrais remercier OpenAI pour son ouverture et individuellement John Schulman pour les conseils, idées et suggestions qu'il a exprimés au tout début de ce concours. Nous, comme de nombreux participants (et plus encore les nouveaux arrivants dans le monde RL), cela nous a permis de mieux nous concentrer sur l'objectif principal de la compétition - le méta-apprentissage et l'amélioration de la généralisation des agents, dont nous parlerons maintenant.
Caractéristiques de l'évaluation des décisions
La chose la plus intéressante a commencé au moment de l'évaluation des agents. Dans les compétitions / benchmarks RL typiques, les algorithmes sont testés dans le même environnement où ils ont été formés, ce qui contribue à des algorithmes qui se souviennent bien et qui ont de nombreux hyperparamètres. Dans le même concours, le test de l'algorithme a été réalisé aux nouveaux niveaux Sonic (qui n'ont jamais été montrés à personne), développés par l'équipe OpenAI spécifiquement pour ce concours. La cerise sur le gâteau était le fait que dans le processus de test, l'agent a également reçu une récompense lors du passage du niveau, ce qui a permis de se recycler directement dans le processus de test. Cependant, dans ce cas, il valait la peine de se rappeler que les tests étaient limités à la fois dans le temps - 24 heures et dans les ticks de jeu - 1 million. Dans le même temps, OpenAI a fortement soutenu la création d'agents qui pourraient rapidement se recycler à de nouveaux niveaux. Comme déjà mentionné, l'obtention et l'étude de telles solutions étaient le principal objectif d'OpenAI lors de ce concours.
Dans le milieu universitaire, la direction de l'étude des politiques qui peuvent s'adapter rapidement à de nouvelles conditions est appelée méta-apprentissage et, ces dernières années, elle s'est activement développée.
De plus, contrairement aux compétitions kaggle habituelles, où toute la soumission se résume à l'envoi de votre fichier de réponses, dans cette compétition (et en effet dans les compétitions RL), l'équipe devait emballer sa solution dans un conteneur docker avec l'API donnée, la collecter et l'envoyer image de docker. Cela a augmenté le seuil d'entrée dans la compétition, mais a rendu le processus de décision beaucoup plus honnête - les ressources et le temps pour l'image de docker étaient respectivement limités, des algorithmes trop lourds et / ou lents n'ont tout simplement pas réussi la sélection. Il me semble que cette approche de l'évaluation est beaucoup plus préférable, car elle permet aux chercheurs sans «cluster maison de DGX et AWS» de rivaliser avec les amateurs de modèles en verre 50000. J'espère voir plus de ce genre de compétition à l'avenir.
L'équipe
Kolesnikov Sergey ( scitateur )
Passionné de RL. Au moment du concours, un étudiant de l'Institut de physique et de technologie de Moscou, MIPT, a écrit et défendu un diplôme du concours NIPS: Learning to Run de l'année dernière (un article sur lequel devrait également être écrit).
Senior Data Scientist @ Dbrain - Nous proposons des concours prêts à la production avec docker et des ressources limitées dans le monde réel.
Pavlov Mikhail ( fgvbrt )
Développeur principal de recherche DiphakLab . A participé à plusieurs reprises et remporté des prix dans des hackathons et des compétitions d'entraînement renforcées.
Sergeev Ilya ( sergeevii123 )
Passionné de RL. J'ai frappé l'un des hackathons RL de Deephack et tout a commencé. Data Scientist @ Avito.ru - vision par ordinateur pour divers projets internes.
Sorokin Ivan ( 1ytique )
Engagé dans la reconnaissance vocale dans speechpro.ru .
Approches et solutions
Après avoir testé rapidement les bases de référence proposées, notre choix s'est porté sur l'approche OpenAI - PPO, comme une option plus formée et intéressante pour développer notre solution. De plus, à en juger par leur article pour ce concours, l'agent PPO a fait face à la tâche un peu mieux. À partir du même article, les premières améliorations que nous avons utilisées dans notre solution sont nées, mais d'abord:
Formation PPO collaborative à tous les niveaux disponibles
La ligne de base présentée a été formée à un seul des 27 niveaux Sonic disponibles. Cependant, à l'aide de petites modifications, il a été possible de paralléliser la formation à la fois à tous les 27 niveaux. En raison de la plus grande diversité dans la formation, l'agent résultant avait une généralisation beaucoup plus grande et une meilleure compréhension de l'appareil du monde sonique, et a donc mieux géré un ordre de grandeur.
Formation supplémentaire pendant les tests
Revenant à l'idée principale de la compétition, le méta-apprentissage, il fallait trouver une approche qui aurait la généralisation maximale et pourrait facilement s'adapter à de nouveaux environnements. Et pour l'adaptation, il a fallu recycler l'agent existant pour l'environnement de test, ce qui a en fait été fait (à chaque niveau de test, l'agent a pris 1 million de pas, ce qui a suffi pour s'adapter à un niveau spécifique). À la fin de chacun des jeux de test, l'agent a évalué le prix reçu et optimisé sa politique en utilisant l'histoire qui vient d'être reçue. Il est important de noter ici qu'avec cette approche, il est important de ne pas oublier toute votre expérience antérieure et de ne pas se dégrader dans des conditions spécifiques, ce qui, en substance, est le principal intérêt du méta-apprentissage, car un tel agent perd immédiatement toute sa capacité existante à généraliser.
Bonus d'exploration
En approfondissant les conditions de rémunération d'un niveau, l'agent a reçu une récompense pour avoir progressé le long de la coordonnée x, respectivement, il pouvait rester bloqué à certains niveaux, lorsque vous deviez d'abord avancer puis reculer. Il a été décidé de faire un ajout à la récompense de l'agent, la soi-disant exploration basée sur le nombre , lorsque l'agent a reçu une petite récompense s'il était dans un état où il n'était pas encore. Deux types de bonus d'exploration ont été mis en œuvre: basé sur l'image et basé sur la coordonnée x de l'agent. Une récompense basée sur une image a été calculée comme suit: pour chaque emplacement de pixel dans l'image, il a été compté combien de fois chaque valeur s'est produite pour un épisode, la récompense était inversement proportionnelle au produit pour tous les emplacements de pixel et combien de fois les valeurs de ces emplacements se sont rencontrées pour un épisode. La récompense basée sur la coordonnée x a été considérée de la même manière: pour chaque coordonnée x (avec une certaine précision), il a été compté combien de fois l'agent était dans cette coordonnée pour l'épisode, la récompense est inversement proportionnelle à ce montant pour la coordonnée x actuelle.
Expériences mixtes
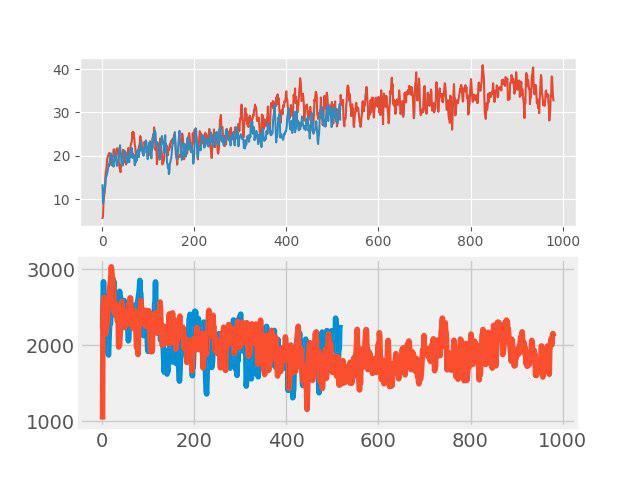
Dans «l'enseignement avec un enseignant» récemment, une méthode simple mais efficace d'augmentation des données, mélange. L'idée est très simple: l'ajout de deux images d'entrée arbitraires est effectué et une somme pondérée des étiquettes correspondantes est affectée à cette nouvelle image (par exemple, 0,7 chien + 0,3 chat). Dans des tâches telles que la classification d'images et la reconnaissance vocale, le mixage montre de bons résultats. Par conséquent, il était intéressant de tester cette méthode pour RL. L'augmentation a été effectuée dans chaque gros lot, composé de plusieurs épisodes. Les images d'entrée étaient mélangées en pixels, mais avec des balises, tout n'était pas si simple. Les valeurs return, values et neglogpacs ont été mélangées par une somme pondérée, mais l'action (actions) a été choisie dans l'exemple avec le coefficient maximum. Une telle solution n'a pas montré d'augmentation tangible (bien qu'il semblerait qu'il aurait dû y avoir une augmentation de la généralisation), mais elle n'a pas aggravé la ligne de base. Les graphiques ci-dessous comparent l'algorithme PPO avec mixup (rouge) et sans mixup (bleu): en haut se trouve la récompense pendant l'entraînement, en bas se trouve la durée de l'épisode.
Sélection de la meilleure politique initiale
Cette amélioration a été l'une des dernières et a apporté une contribution très significative au résultat final. Au niveau de la formation, plusieurs politiques différentes avec différents hyperparamètres ont été formées. Au niveau du test, pour les premiers épisodes, chacun d'eux a été testé, et pour une formation complémentaire, la politique qui a donné la récompense maximale au test pour son épisode a été choisie.
Bloopers
Et maintenant sur la question de ce qui a été essayé, mais "n'a pas volé." Après tout, ce n'est pas un nouvel article SOTA pour cacher quelque chose.
- Modification de l'architecture du réseau: activation SELU , auto-attention, blocs SE
- Neuroévolution
- Création de vos propres niveaux Sonic - tout était préparé, mais il n'y avait pas assez de temps
- Méta-formation via MAML et REPTILE
- Ensemble de plusieurs modèles et formation continue lors du test de chaque modèle à l'aide d'un échantillonnage d'importance
Résumé
3 semaines après la fin de la compétition, OpenAI a publié les résultats . À 11 niveaux supplémentaires supplémentaires, notre équipe a reçu une honorable 4ème place, après avoir sauté du 8ème lors d'un test public et dépassé les lignes de base obscures d'OpenAI.
Les principaux points distinctifs qui ont «volé» dans le premier 3ki:
- Système d'actions amélioré (est venu avec leurs propres boutons, supprimé les supplémentaires);
- Investigation des états par hachage à partir de l'image d'entrée;
- Plus de niveaux de formation;
De plus, je tiens à noter que dans ce concours, en plus de gagner, la description de leurs décisions, ainsi que le matériel qui a aidé les autres participants ont été activement encouragés - il y avait aussi une nomination séparée pour cela. Ce qui, encore une fois, a augmenté le concours de lampes.
Postface
Personnellement, j'ai vraiment aimé ce concours, ainsi que le thème du méta apprentissage. Pendant la participation, j'ai pris connaissance d'une longue liste d'articles (je n'ai même pas oublié certains d'entre eux) et j'ai appris un grand nombre d'approches différentes que j'espère appliquer à l'avenir.
Dans la meilleure tradition de participation au concours, tout le code est disponible et affiché sur github .