Article écrit en septembre 2017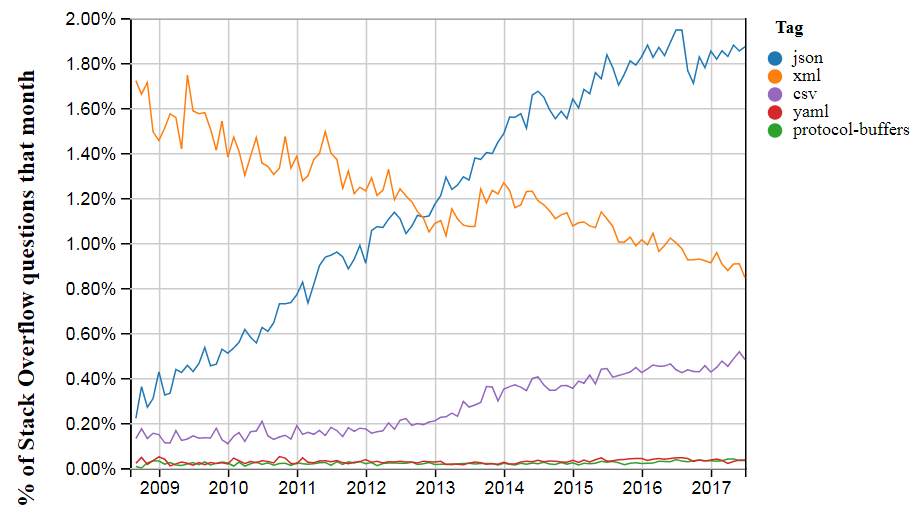
JSON a conquis le monde. Si aujourd'hui deux applications communiquent entre elles via Internet, il est fort probable qu'elles le fassent en utilisant JSON. La norme est acceptée par tous les principaux acteurs: sur les dix API Web les plus populaires, qui sont développées principalement par de grandes entreprises telles que Google, Facebook et Twitter,
une seule API transfère des données en XML, pas JSON. Par exemple, Twitter a pris en charge XML jusqu'en 2013, date à laquelle il a publié une nouvelle version de l'API exclusivement en JSON. Parmi les autres développeurs, JSON est également populaire: selon Stack Overflow,
plus de questions sont posées sur JSON que sur tout autre format d'échange de données .
XML est toujours vivant et utilisé beaucoup. Par exemple, dans les formats Web SVG, RSS et Atom. Si l'auteur de l'application Android souhaite déclarer qu'il a besoin de l'autorisation de l'utilisateur, il le fait dans le manifeste de l'application écrit en XML. Et XML n'est pas la seule alternative JSON: certains développeurs optent pour le YAML ou les tampons de protocole de Google. Mais ces formats sont loin d'être aussi populaires que JSON, qui est maintenant devenu presque la norme de facto pour l'échange de données entre programmes sur Internet.
La domination de JSON est étonnante, car en 2005, tout le monde discutait du potentiel de «JavaScript et XML asynchrone» plutôt que de «JavaScript et JSON asynchrone». Bien sûr, il est possible que cela ne dise rien sur la popularité relative des deux formats, juste AJAX semblait être une abréviation plus attrayante que AJAJ. Mais bien qu'en 2005, certaines personnes utilisaient déjà JSON au lieu de XML (en fait peu de gens), on se demande encore comment XML pourrait tomber si brutalement qu'une décennie plus tard, l'expression «JavaScript et XML asynchrone» provoque un sourire ironique. Que s'est-il passé pendant cette décennie? Comment JSON a-t-il remplacé XML dans de nombreuses applications? Et qui a inventé ce format de données, dont dépendent désormais les ingénieurs et les systèmes du monde entier?
La naissance de JSON
Le premier message JSON a été envoyé en avril 2001 depuis un ordinateur dans un garage près de San Francisco. L'histoire a conservé les noms des personnes impliquées dans l'événement: Douglas Crockford et Chip Morningstar, co-fondateurs de la société de conseil en technologie State Software.
Ces deux-là développaient des applications AJAX bien avant l'apparition du terme AJAX. Mais le support des applications dans les navigateurs n'était pas très bon. Ils voulaient transférer des données vers leur application après le chargement initial de la page, mais n'ont pas trouvé de moyen qui fonctionnerait dans tous les navigateurs.
C'est difficile à croire aujourd'hui, mais Internet Explorer était le navigateur le plus avancé en 2001. Depuis 1999, Internet Explorer 5 prend en charge la première forme de XMLHttpRequest via ActiveX. Crockford et Morningstar pouvaient utiliser cette technologie pour récupérer des données dans l'application, mais cela ne fonctionnait pas dans Netscape 4. J'ai donc dû chercher un format différent qui fonctionnait dans les deux navigateurs.
Le premier message JSON ressemblait à ceci:
<html><head><script> document.domain = 'fudco'; parent.session.receive( { to: "session", do: "test", text: "Hello world" } ) </script></head></html>
Seule une petite partie du message ressemble au JSON tel que nous le connaissons aujourd'hui. Le message lui-même est en fait un document HTML avec quelques lignes de JavaScript. La partie de type JSON n'est qu'un littéral JavaScript pour la fonction
receive() .
Crockford et Morningstar ont décidé d'abuser du cadre HTML pour envoyer des données. Pour un cadre, vous pouvez spécifier une URL qui renvoie un document HTML similaire à celui ci-dessus. Lorsque le code HTML est reçu, JavaScript est lancé et retransmet le littéral à l'application. Cela fonctionnait à condition que la protection du navigateur soit soigneusement contournée pour empêcher l'enfant d'accéder à la fenêtre parent: comme vous pouvez le voir, Crockford et Morningstar définissent explicitement le domaine du document. Cette technique est parfois appelée un cadre caché; elle était
souvent utilisée à la fin des années 90 avant le XMLHttpRequest normal .
Ce qui est surprenant dans le premier article JSON, c'est qu'il n'est pas du tout évident qu'il s'agit de la première utilisation d'un nouveau type de format de données. C'est juste du JavaScript! En fait, l'idée d'utiliser JavaScript de cette manière est si simple que Crockford lui-même pense qu'il n'était pas le premier à le faire - il prétend que quelqu'un dans Netscape a utilisé des littéraux de tableau JavaScript pour transmettre des informations
en 1996 . La publication en JavaScript simple ne nécessite aucune analyse particulière. Tout est fait par l'interpréteur JavaScript.
En fait, le premier message JSON de l'histoire a rencontré des problèmes avec l'interpréteur. JavaScript réserve un grand nombre de mots - 64 mots sont réservés dans ECMAScript 6 - et Crockford et Morningstar les ont involontairement utilisés dans leur message: à savoir, le mot réservé
do la clé. Étant donné que JavaScript a tant de mots réservés, Crockford a décidé de ne pas les éviter, mais simplement de citer toutes les clés JSON. La clé entre guillemets est considérée par l'interpréteur JavaScript comme une chaîne, vous pouvez donc utiliser en toute sécurité les mots réservés. C'est pourquoi les clés JSON sont toujours entre guillemets.
Crockford et Morningstar ont réalisé que la nouvelle méthode peut être utilisée dans toutes sortes d'applications. Ils voulaient appeler le format JSML (JavaScript Markup Language), mais il s'est avéré que l'abréviation était déjà occupée par quelque chose appelé Java Speech Markup Language. Par conséquent, nous avons choisi la notation d'objet Javascript, c'est-à-dire JSON. Ils ont commencé à offrir le format à leurs clients, mais il est vite devenu évident qu'ils ne risquaient pas d'utiliser une technologie inconnue sans spécification officielle. Crockford a donc décidé de l'écrire.
En 2002, Crockford a acheté le domaine
JSON.org , publié la syntaxe JSON et un exemple d'implémentation de l'analyseur. Le site Web fonctionne toujours, bien qu'il affiche désormais un lien vers la norme JSON ECMA adoptée en 2013. En plus de lancer le site, Crockford n'a pratiquement rien fait pour promouvoir JSON, mais bientôt il y a eu des implémentations de l'analyseur JSON dans une variété de langages de programmation. Initialement, JSON était clairement associé à JavaScript, mais il est devenu clair qu'il convenait bien à l'échange de données entre des paires de langues arbitraires.
Mauvais AJAX
JSON a obtenu un gros coup de pouce en 2005. Puis un concepteur et développeur nommé Jesse James Garrett a inventé le terme AJAX dans son
article . Il a essayé de souligner que AJAX n'est pas seulement une nouvelle technologie, mais plutôt «plusieurs à sa manière de bonnes technologies combinées de nouvelles façons puissantes». Garrett a appelé AJAX une nouvelle approche pour le développement d'applications Web. Dans un article de blog, il a décrit comment les développeurs peuvent utiliser JavaScript et XMLHttpRequest pour créer des applications plus interactives. Il a appelé Gmail et Flickr des exemples de sites qui s'appuient sur les méthodes AJAX.
Bien sûr, "X" dans AJAX signifiait XML. Mais dans les questions et réponses ultérieures, Garrett a qualifié le JSON d'alternative parfaitement acceptable. Il a écrit que "XML est l'outil d'échange de données le plus fonctionnel pour le client AJAX, mais le même effet peut être obtenu en utilisant Javascript Object Notation ou tout autre format de structuration de données similaire."
Les développeurs ont vraiment découvert qu'ils pouvaient facilement utiliser JSON pour créer des applications AJAX, et beaucoup l'ont choisi au lieu de XML. Ironiquement, l'intérêt pour AJAX a conduit à une explosion de la popularité de JSON. À cette époque, JSON a attiré l'attention de la blogosphère.
En 2006, Dave Weiner, un blogueur prolifique et créateur d'un certain nombre de technologies XML, telles que RSS et XML-RPC,
s'est plaint que JSON réinventait XML sans raison valable:
«Bien sûr, je peux écrire une procédure pour analyser [JSON], mais regardez jusqu'où ils sont allés pour réinventer la technologie: pour une raison quelconque, XML n'est pas assez bon pour eux (je me demande pourquoi). Qui a créé cette parodie? Trouvons un arbre et pendons un gars. Maintenant. "
Il est facile de comprendre la déception de Weiner. XML n'a jamais été particulièrement apprécié. Même Weiner lui-même a
dit qu'il n'aimait pas XML . Mais XML a été conçu comme un système universel pour toutes les applications imaginables. XML est en fait un métalangage qui vous permet de définir des langues de domaine pour des applications individuelles - par exemple, RSS et SOAP. Weiner estime qu'il est important de dégager un consensus pour tous les avantages que le format d'échange commun apporte. À son avis, la flexibilité de XML est capable de satisfaire tous les besoins. Pourtant, JSON est un format qui n'offre aucun avantage sur XML, à l'exception de la suppression des fichiers indésirables, qui a rendu XML si flexible.
Crockford a vu le blog de Weiner et a commenté. En réponse à l'accusation selon laquelle JSON réinvente XML, Crockford a écrit:
" Réinventer la
roue est bon parce que vous pouvez la faire tourner .
"JSON vs XML
En 2014, JSON a été officiellement reconnu comme une norme ECMA et RFC. Il a obtenu son type MIME. JSON est entré dans les grandes ligues.
Pourquoi JSON est-il devenu beaucoup plus populaire que XML?
Sur
JSON.org, Crockford répertorie certains des
avantages de JSON sur XML . Il écrit que JSON est plus facile à comprendre par les personnes et les machines, car sa syntaxe est minimale et sa structure est prévisible. D'autres blogueurs
mentionnent la verbosité XML et la «taxe sur les balises». Chaque balise d'ouverture en XML doit avoir une balise de fermeture, ce qui signifie beaucoup d'informations redondantes. Cela rend XML beaucoup plus volumineux que le document JSON équivalent, mais plus important encore, pour cette raison, le document XML est plus difficile à lire.
Crockford a
appelé un autre grand avantage de JSON: qu'il a été initialement conçu comme un format pour l'échange d'informations structurées entre les programmes. Bien que XML ait été utilisé dans le même but, il a été initialement développé comme langage de balisage de document. Il est né du SGML (Standard Generalized Markup Language), qui, à son tour, a évolué à partir du langage de balisage Scribe, destiné au texte de balisage, comme LaTeX. En XML, à l'intérieur d'une balise, il peut y avoir ce que l'on appelle du «contenu mixte», c'est-à-dire du texte avec des balises intégrées entourant des mots ou des phrases. Il ressemble à un éditeur marquant un manuscrit avec un marqueur rouge ou bleu, une sorte de métaphore du langage de balisage. JSON, en revanche, ne prend pas en charge un analogue exact de contenu mixte, ce qui signifie simplifier la structure. Le document est mieux représenté sous la forme d'une arborescence, mais abandonnant l'idée du document, Crockford a pu limiter JSON aux dictionnaires et aux tableaux d'éléments familiers que tous les programmeurs utilisent pour créer leurs programmes.
Enfin, ma propre supposition est que les gens n'aimaient pas la complexité de XML, et c'était vraiment à cause de sa diversité. À première vue, il est difficile de faire la distinction entre le XML lui-même et ses sous-langues, telles que RSS, ATOM, SOAP ou SVG. Les premières lignes d'un document XML type établissent la version de XML, puis le sous-langage spécifique auquel le document XML doit correspondre. Il s'agit de nombreuses options par rapport à JSON, qui est si simple qu'aucune nouvelle version de la spécification JSON ne sera jamais écrite. Les développeurs XML, dans une tentative de créer un format d'échange de données unique pour tout, ont été victimes du piège du programmeur classique: une complication technique excessive. XML est si général qu'il est difficile de l'utiliser pour quelque chose de simple.
En 2000, une campagne a commencé à aligner le HTML sur la norme XML. Publication d'une spécification pour HTML conforme à XML, connue plus tard sous le nom de XHTML. Certains fabricants de navigateurs ont immédiatement commencé à prendre en charge la nouvelle norme, mais il est rapidement devenu évident que le grand public travaillant avec HTML ne voulait pas changer ses habitudes. La nouvelle norme exigeait une validation XHTML plus stricte que ce qui était habituel pour HTML, mais trop de sites dépendaient de règles HTML gratuites. En 2009, les militants avaient cessé d'essayer d'écrire une deuxième version de XHTML quand il est devenu clair que l'avenir reposait sur la norme HTML5, qui ne nécessitait pas la conformité XML.
Si les efforts de XHTML réussissaient, alors peut-être que XML deviendrait un format de données commun, comme l'espéraient ses développeurs. Imaginez un monde dans lequel les documents HTML et les réponses API ont exactement la même structure. Dans un tel monde, JSON n'est peut-être pas devenu aussi populaire qu'aujourd'hui. Mais je considère l'échec de XHTML comme une sorte de défaite morale pour le camp XML. Si XML n'a pas aidé HTML, il pourrait y avoir de meilleurs outils pour d'autres applications. Dans le monde réel, il est facile de comprendre pourquoi le format JSON simple et hautement spécialisé a connu un tel succès.