
Dans l'
article précédent sur le thème de la gestion des risques par l'État, nous sommes passés par les bases: pourquoi les autorités étatiques devraient-elles gérer les risques, où les rechercher et quelles sont les approches d'évaluation. Aujourd'hui, nous allons parler du processus d'analyse des risques: comment identifier les causes de leur occurrence et identifier les contrevenants.
Évaluation des risques
Pour évaluer le risque - même dans le cadre d'une approche statique, bien que dynamique - vous devez trouver ses causes, ses conditions d'occurrence et déterminer les principales caractéristiques: la probabilité et les dommages potentiels de la mise en œuvre.
Prenons, par exemple, le dédouanement: lors de l'importation d'un produit dans le pays, à l'exception d'une variété d'informations différentes (coût, poids, emballage, expéditeur, destinataire, etc.), une déclaration doit être faite dans la déclaration selon un classificateur spécial - la nomenclature des produits de l'activité économique étrangère (FEA). Ce code pour les marchandises détermine ensuite le droit conformément au tarif douanier (TN FEA + taux).
Le tarif douanier est un classificateur complexe: à première vue, certaines marchandises peuvent être attribuées à des codes différents avec des taux de droits différents. Par exemple, vous pouvez gérer un équipement minier complexe uniquement en plongeant dans ses dessins. D'où la tentation de l'importateur de déclarer un code erroné (mais similaire à la vérité) afin de payer moins d'argent au budget.
Nous avons donc
identifié le risque - la déclaration d'un code de produit non fiable dans la déclaration afin de sous-estimer les paiements en douane. La raison en est la présence dans le classificateur de postes «limites» avec des taux de droits différents.
Il est plus difficile de détecter les conditions de survenance d'un tel risque - quand et avec quels biens il se produit dans la pratique. Pour ce faire, vous devez effectuer
une analyse des risques : étudier l'historique des observations des objets de contrôle, savoir quand et qui a déclaré le mauvais code produit et identifier certaines caractéristiques générales de ces cas. Cela permettra de formuler des
règles pour la future gestion des risques: quels objets nous attribuerons au risque et quel audit soumettre.
Le moyen le plus simple d'obtenir ces règles est de faire confiance au jugement expert de vos employés.
Règles d'experts
Ces règles d'identification des risques sont des spécialistes en la matière. Ils sont guidés par leur expérience de travail ou résument les opinions de collègues qui rencontrent chaque jour des contrevenants. Il en résulte des jugements simples de la forme «si ... alors ...».
La probabilité d'occurrence du risque et les dommages potentiels de la menace dans ce cas sont déterminés «à l'œil nu» ou par des estimations approximatives.
L'avantage des règles expertes est la facilité de leur compilation et interprétation par l'homme. L'inconvénient est qu'un grand nombre de personnes, à la fois des contrevenants et des sujets respectables de l'activité économique, peuvent simultanément tomber sous le coup de la règle. Par conséquent, l'efficacité du contrôle sera faible. Dans le même temps, certains contrevenants passeront, sur lesquels l'expert n'a pas pu détecter et prendre en compte les modèles.
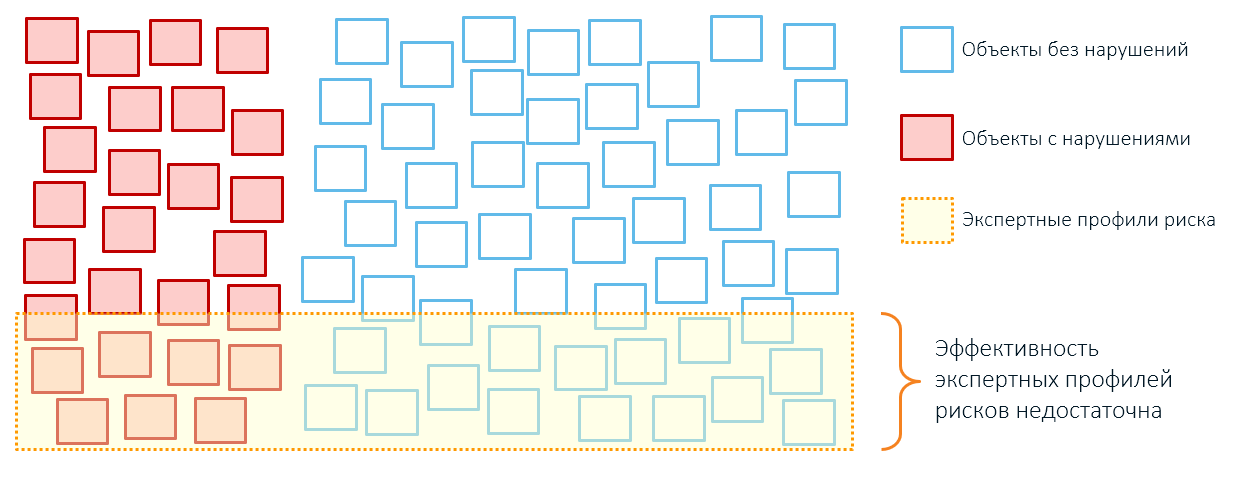
Par exemple, une règle d'expert en matière de contrôle douanier nous dit que tous les lots de pommes d'une valeur inférieure à un certain seuil sont liés à des livraisons de risques:

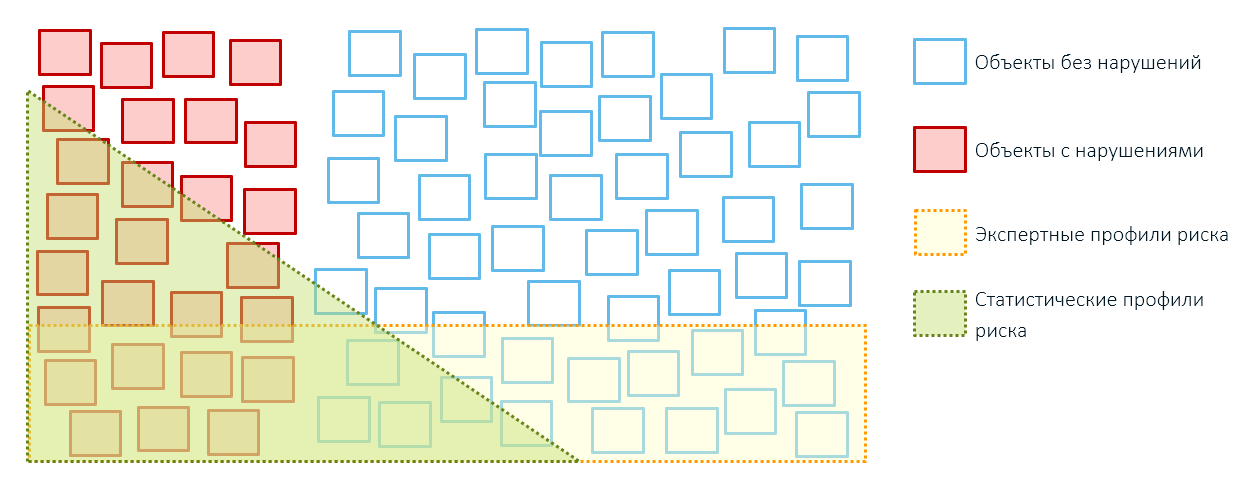
Lorsque nous effectuons le contrôle, nous trouvons à la fois des marchandises avec des irrégularités (rouge) et des livraisons tout à fait normales (vert), dont le faible coût s'explique par des remises individuelles, la lutte de l'expéditeur avec le surstock ou le modèle économique des entreprises.
Tout ce qui dépasse ce seuil de valeur conditionnelle (ligne rouge) sera hors de contrôle (cercles gris). Mais si nous les vérifions également, nous trouverons à la fois des livraisons véritablement légitimes et des livraisons dont la valeur réelle est encore plus élevée que ce qui était indiqué dans la déclaration (cercles gris avec un contour en pointillé rouge) et pour lesquelles les paiements en douane ne sont pas payés en totalité.
Par conséquent, l'application de règles expertes conduit généralement à une couverture excessive des objets de contrôle et à de faibles performances (rappelez-vous, nos encadrés du premier article?):
Il ne faut pas blâmer les experts: la conscience humaine est limitée dans les objets avec lesquels elle peut opérer (un article curieux a été publié une fois sur Habr, dont l'auteur suggère que leur nombre est limité à sept). D'où les grands coups au lieu des détails exacts: disons, le risque d'incendie n'est déterminé que par l'année de construction du bâtiment, la zone de localisation et la catégorie de résidents. Toutes ces caractéristiques une fois «jouées»: un incendie s'est déclaré dans une vieille maison, une pièce a pris feu dans une zone dysfonctionnelle. Par conséquent, les experts s'attendent précisément aux menaces futures provenant d'objets de ce type.
Mais tous ces bâtiments «dangereux» ne vont pas réellement brûler, même s'ils relèvent de la règle des experts: de nombreuses maisons anciennes et en bois se tiennent comme si de rien n'était. Certaines maisons dysfonctionnelles sont sans feu depuis des années. C'est juste que l'expert ne pouvait pas prendre en compte certaines caractéristiques individuelles subtiles des objets dangereux.
C'est là qu'intervient l'apprentissage automatique qui permet de créer
des profils de risque statistiques . Ils sont formés lorsque nous appliquons des technologies d'analyse de données à l'historique des violations et des informations sur les objets contrôlés.
Profils de risques statistiques
Dans ce cas, nous résolvons le problème de classification binaire: un algorithme analytique spécialisé détermine par lui-même quelles caractéristiques des objets permettent de les attribuer à «mauvais» ou «bon». Si tout est fait correctement, à la fin, nous obtiendrons des évaluations des risques assez précises: des conditions détaillées et une probabilité calculée automatiquement plus des dommages potentiels (qui, avec une approche experte, sont également déterminés d'une manière ou d'une autre «expert»). Ces caractéristiques définissent un «profil de risque» - quoi, où, quand et comment effrayant.
Les profils de risque statistiques sont créés de différentes manières. Il peut être basé sur un arbre de décision ou une forêt aléatoire. Vous pouvez appliquer un réseau de neurones délicat avec un grand nombre de couches cachées.
Mais chez SAS, nous pensons qu'aux fins du contrôle de l'État, il est préférable de créer des profils de risque statistiques basés sur des algorithmes interprétés, par exemple, la
régression ou l'
arbre de décision . La pratique a montré qu'il est difficile pour un organisme d'État de s'orienter même s'il s'agit d'une prévision précise mais incompréhensible d'une machine, si elle n'explique pas pourquoi cette personne respectée est marquée comme un méchant.
L'agence d'État doit comprendre exactement quels facteurs indiquent une menace et lequel des contrevenants a les mêmes caractéristiques, car il existe des procédures d'approbation des décisions de gestion (dont un cas particulier est le profil de risque). L'officiel doit comprendre ce qu'il lance exactement «au combat», car il est responsable du résultat du profil de risque.
Toute vérification doit être justifiée et cette justification doit être exprimée par des mots. Sinon, vous devez rougir devant le procureur et expliquer comment il s'est avéré que l'agence d'État «pince» les affaires intérieures sur la base des instructions mystérieuses de deus ex machina.
Par conséquent, le profil de risque statistique ressemble également à une règle qui peut être lue et comprise. Seule la liste des caractéristiques décrivant les contrevenants possibles est plus longue et plus complexe que celle des profils d'experts:
 * les valeurs des paramètres de profil sont modifiées et ne correspondent pas aux valeurs réelles
* les valeurs des paramètres de profil sont modifiées et ne correspondent pas aux valeurs réellesUn ensemble d'
indicateurs de
risque (conditions) peut sembler un peu bizarre. Mais ce n'est pas une «grande sorcellerie» - simplement à l'aide des technologies d'apprentissage automatique et des informations limitées dont nous disposons, nous décrivons un modèle caché de comportement humain qui conduit à des perturbations.
Il en va de même pour le contrôle fiscal - les contrevenants peuvent distinguer de la masse totale des contribuables certaines fourchettes de montants de certaines transactions, les délais de dépôt des déclarations, le nombre d'employés dans le personnel de l'entreprise, le nombre de comptes et un autre ensemble de 30 paramètres différents qui décrivent collectivement les entrepreneurs sans scrupules qui sous-estiment la TVA.
Une personne ne pourra pas comparer toutes ces caractéristiques, elle s'en sortira avec trois ou cinq, plus faciles à comprendre. Et le programme peut. Aussi détaillé que nécessaire. Lors de la construction d'un modèle, l'algorithme itère automatiquement sur une masse de données et trouve ce que les délinquants ont en commun - même s'il s'agit d'un amour des liens rouges dans un filet jaune.
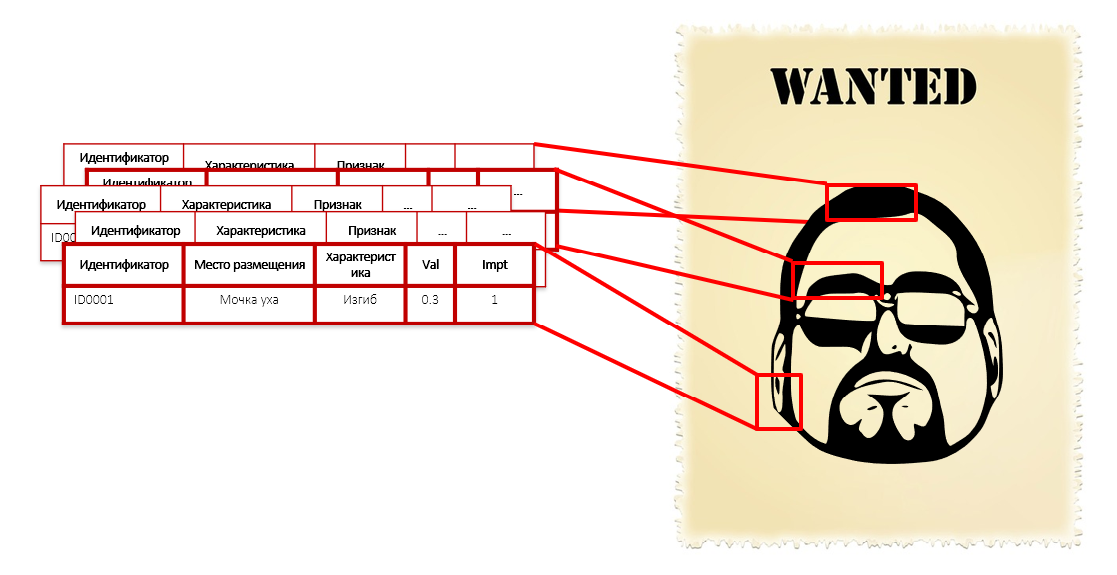
Cela est similaire à la description du criminel dans ses caractéristiques individuelles: la forme du nez, des oreilles, la courbure des sourcils, les couleurs des chemises et la longueur du pied. Nous ne connaissons pas son visage, sa taille et son poids, mais nous avons mille caractéristiques, dont la longueur des poils sur la phalange de l'auriculaire gauche. Chacun de ces paramètres ne donne pas individuellement des intentions criminelles - vous n'avez pas besoin de menotter une personne uniquement pour le rayon de courbure de ses oreillettes. Mais l'ensemble de ces caractéristiques constitue un portrait assez précis de l'intrus:
Lorsque nous passons de l'application de règles expertes à un profilage statistique basé sur une analyse des modèles cachés, nous nous débarrassons des contrôles délibérément inefficaces. L'énorme champ de contrôle continu se rétrécit jusqu'à un impact ponctuel sur les objets qui relèvent du
modèle révélé
de comportement déloyal .
Rappelez-vous des pommes de l'exemple des douanes ci-dessus. En soumettant l'historique des contrôles à l'entrée du modèle statistique, nous obtenons un profil de risque qui prend en compte les caractéristiques comportementales des importateurs-contrevenants, quel que soit le prix auquel ils déclarent les marchandises:
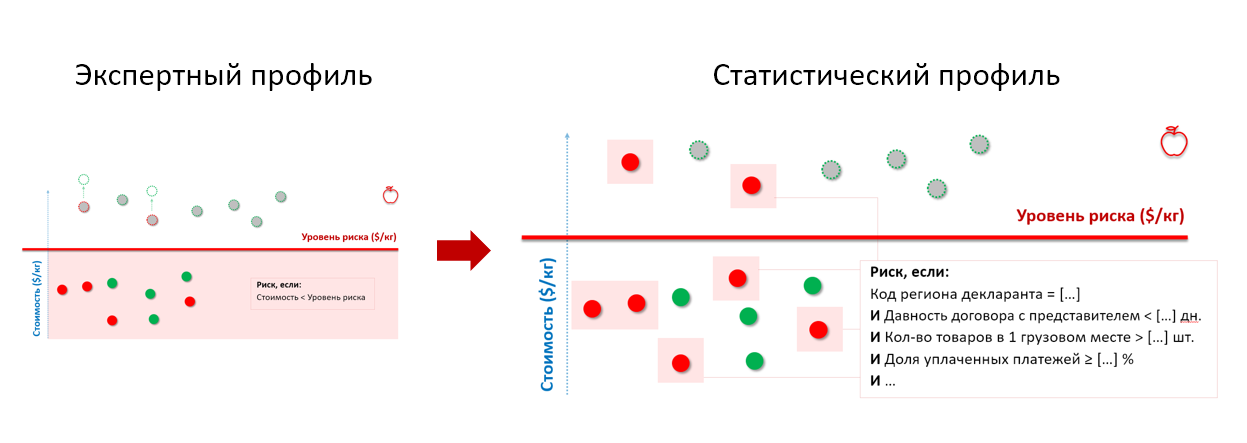 * l'ensemble des paramètres du profil de risque a été modifié et ne correspond pas au réel
* l'ensemble des paramètres du profil de risque a été modifié et ne correspond pas au réelC'est ainsi que le profil de risque statistique est construit à l'aide des algorithmes de la classe «arbre de décision» - chaque niveau de celui-ci sépare de plus en plus l'ensemble des entités testées en «bon» et «mauvais» et montre quelle caractéristique de séparation s'est avérée être la plus significative (dans la capture d'écran de SAS Visual Statistics):
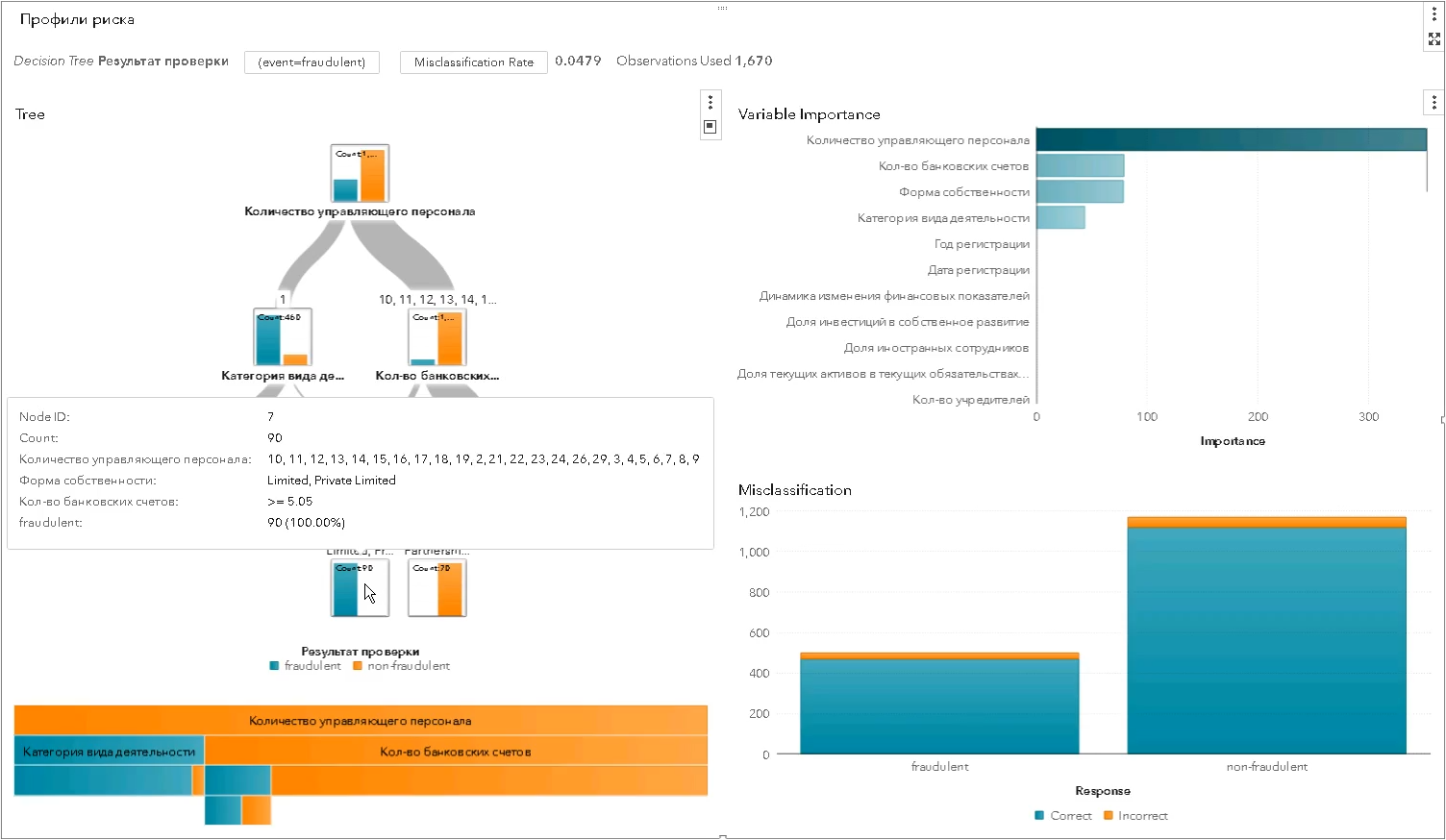
Les profils statistiques sont meilleurs que ceux des experts - plus précisément, plus sélectifs, impartiaux. Ils contribuent à accroître l'efficacité des inspections en réduisant le nombre de «séances d'entraînement» inactives:
L'inconvénient des profils statistiques est qu'ils sont guidés par l'expérience passée dans l'identification des violations. Aux schémas bien connus.
Si, dans l'histoire du contrôle douanier, il y a eu des cas de sous-estimation lors de l'importation de marchandises, l'algorithme trouvera des signes de contrevenants et formera un profil de risque statistique. Si nous recherchons une nouvelle violation qui n'a pas encore été portée à l'attention de l'agence d'État et que nous ne connaissons pas ses caractéristiques, nous devons agir «par contact» - par essais et erreurs.
Recherche inconnue
Vous pouvez ressentir l'inconnu de plusieurs manières.
Le premier est
l'échantillonnage aléatoire . Nous prenons un objet arbitraire (en notre pouvoir) - un produit, une entreprise, un bâtiment ou un citoyen - et nous l'examinons attentivement. L'approche est assez impartiale, mais pas trop efficace - un sujet respectable peut tout aussi bien relever du «débriefing». La force de l'agence d'État et l'argent du budget seront dépensés en vain.
Le second est l'
identification des anomalies . Dans ce cas, un objet est pris pour vérification, dont les paramètres se distinguent des autres. Lorsque nous analysons des événements anormaux, et pas seulement «poussons» au hasard un tas d'objets, la probabilité de trouver une violation est plus élevée.
Par exemple, lors d'une surveillance environnementale, il s'avère que l'usine consomme de façon inattendue beaucoup d'électricité:
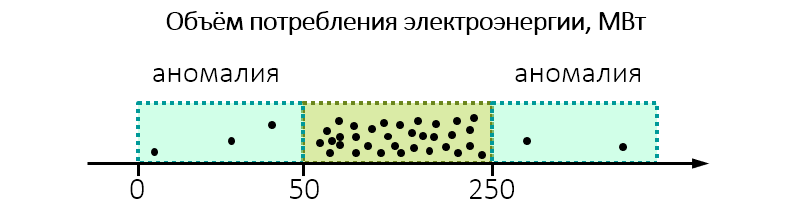
Peut-être que cela vaut la peine de l'examiner de plus près et de vérifier si la plante ne se décharge pas dans l'eau ou dans l'air plus que ce qui est permis.
Ou les marchandises à la douane ont un rapport inhabituel du poids des marchandises et de l'emballage:
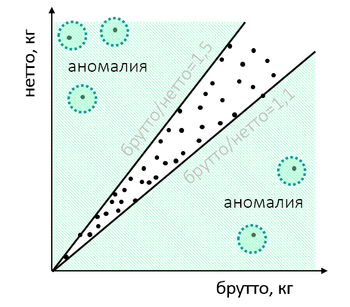
Après vérification, il peut s'avérer que l'importateur a «joué» avec poids afin de couvrir certaines violations: sous-estimé le coût et a donc voulu resserrer l'une des valeurs du test ou émettre certaines marchandises sous le couvert d'autres. Les caractéristiques de poids «naturelles», si vous creusez bien, diffèrent des caractéristiques fictives.
Cependant, ce sont les exemples les plus simples qu'une personne peut voir. En réalité, la recherche d'anomalies se produit dans un espace multidimensionnel d'attributs - il peut y en avoir des centaines. L'algorithme fait ce que l'humain ne peut pas faire - il trouve des objets qui diffèrent considérablement des autres en même temps dans un grand nombre de signes, et détermine les soi-disant valeurs aberrantes multidimensionnelles (dans la capture d'écran de SAS Visual Statistics):
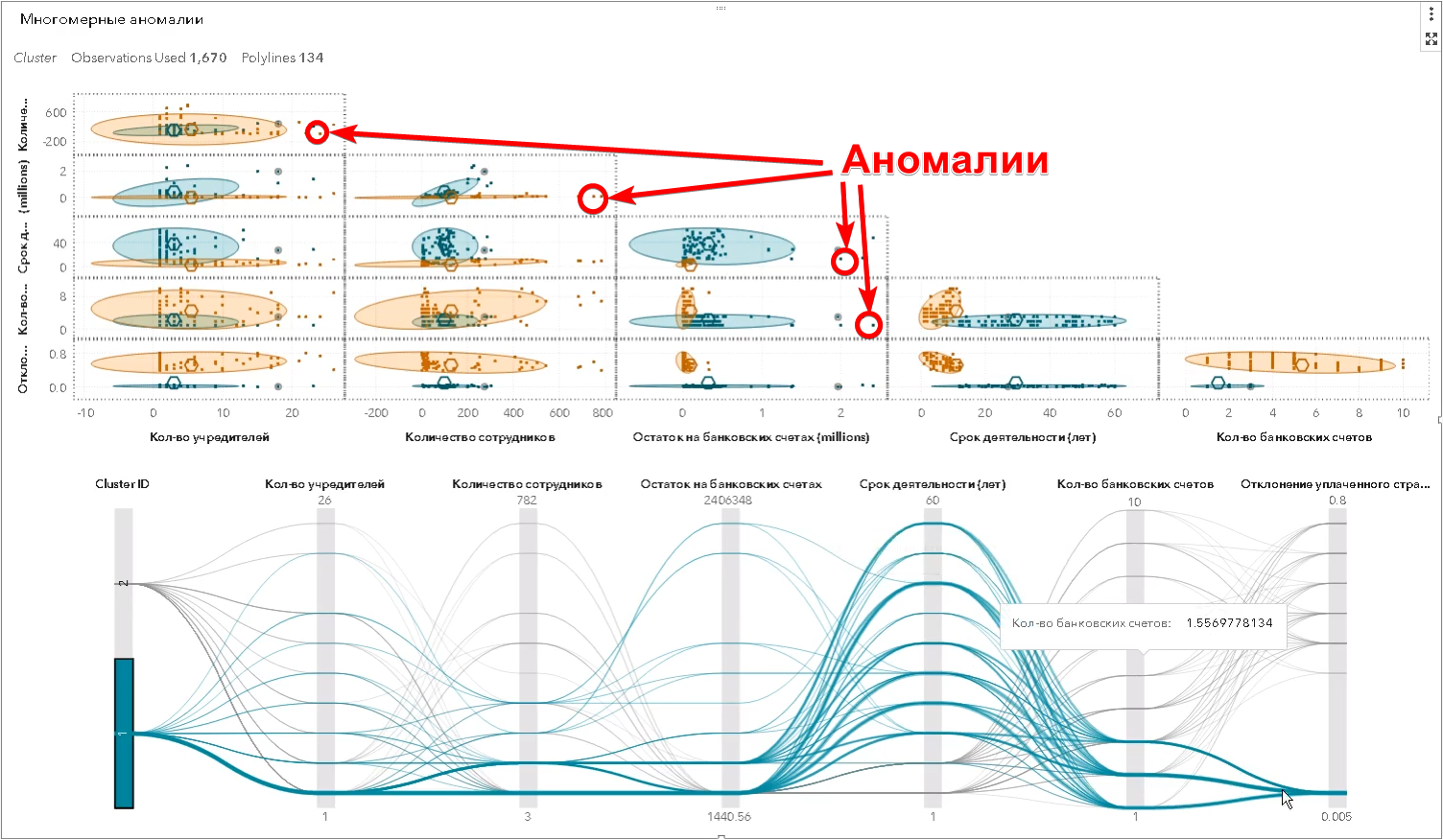
De plus, au-delà des limites de la perception humaine, il existe une variété de relations juridiques entre différentes entreprises qui sont visualisées à l'aide d'un graphique (dans la capture d'écran de SAS Social Network Analysis):
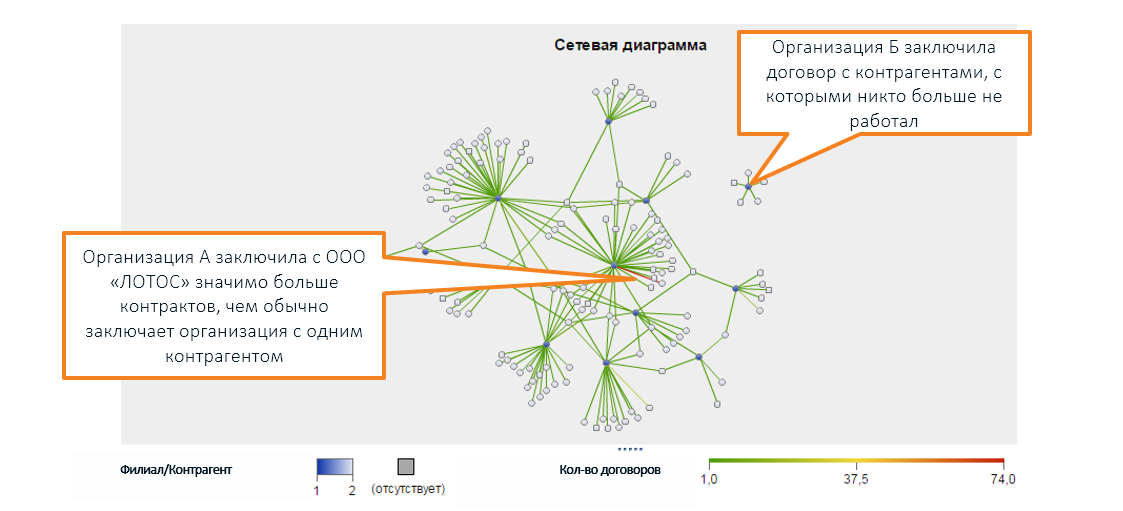 * les noms des organisations sont inventés, les coïncidences avec de vraies entreprises sont aléatoires
* les noms des organisations sont inventés, les coïncidences avec de vraies entreprises sont aléatoiresDes caractéristiques inhabituelles n'indiquent pas nécessairement un problème. La vérification peut ne rien montrer: oui, les indicateurs sont étranges, mais il n'y a pas de violation.
Une anomalie n'est pas un risque, c'est juste «quelque chose d'inhabituel». Des profils d'anomalies sont nécessaires pour fournir de nouvelles «matières premières» pour la construction de profils d'experts ou statistiques, car le résultat de la vérification des anomalies est inclus dans l'historique des observations des objets sous contrôle.
Approche hybride
Les meilleurs résultats dans les activités de contrôle et de supervision des organismes publics (et pas seulement) peuvent être obtenus en combinant les trois méthodes d'identification des risques: règles d'experts, profils statistiques de risque basés sur les technologies d'apprentissage automatique et profils d'anomalies. Dans le même temps, il est préférable de réduire la couverture des objets avec des règles d'experts, en ne les laissant que pour des influences administratives ciblées (par exemple, des sanctions imposées - nous bloquons les marchandises de ces pays):
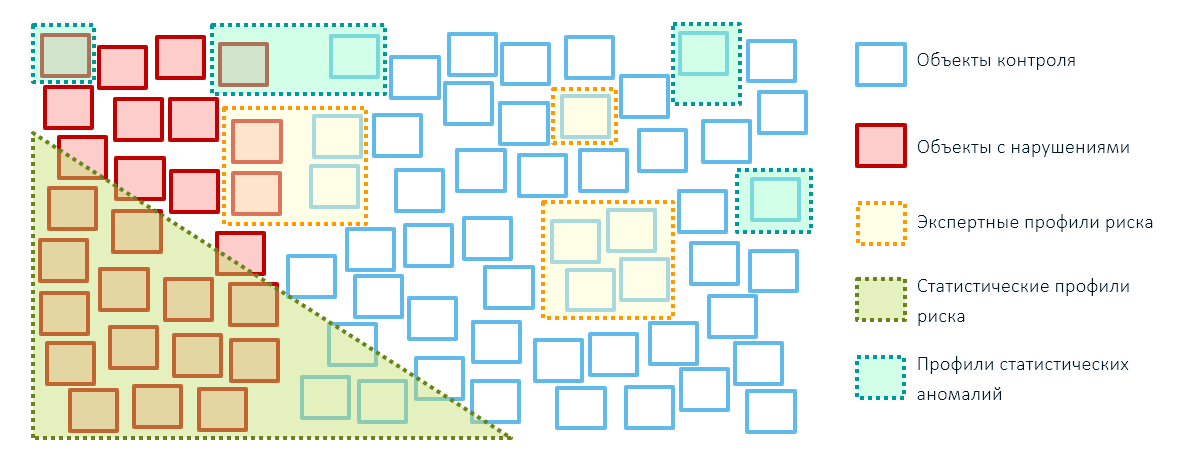
Vous ne pouvez pas vous passer de règles expertes au stade initial de la construction d'un système de gestion des risques, car une base précédente est nécessaire pour créer des modèles analytiques. Pour le créer, il sera nécessaire de procéder à des vérifications sur la base de profils de risque d'experts et de passer ensuite à des modèles mathématiques.
Chez SAS, nous pensons que l’avenir de l’activité de contrôle et de surveillance de l’État repose sur une approche hybride qui combinera l’expérience des organes de l’État et l’expertise de ses employés avec les technologies modernes d’apprentissage automatique. Dans ce cas, nous réduisons les résultats des trois modules en une seule évaluation des risques intégrée:
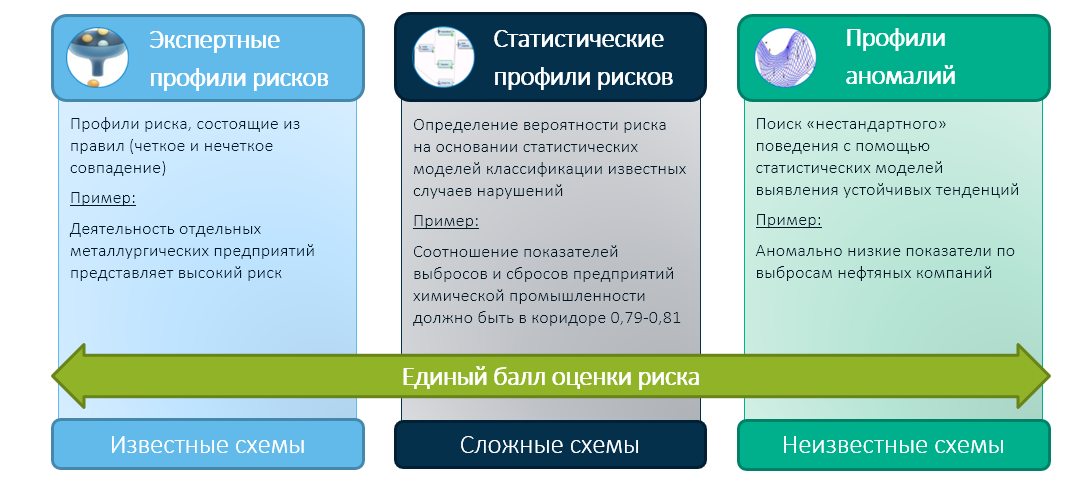
Et déjà une évaluation intégrée (par exemple, basée sur une matrice de décision d'experts) détermine le choix de l'organisme de contrôle - à qui vérifier et à qui faire confiance.
Dans le prochain article, nous analyserons les méthodes pour minimiser les menaces identifiées et réfléchirons à l'importance du feedback et de la réévaluation dynamique des risques.