Dans le cadre du support produit, nous répondons en permanence aux demandes des utilisateurs. Il s'agit d'un processus standard. Et comme tout processus, il doit être régulièrement évalué et amélioré de manière critique.
Nous connaissons certains problèmes systématiques qu'il serait bon de résoudre et, si possible, sans attirer de ressources supplémentaires:
- Erreurs lors de la répartition des applications: nous obtenons quelque chose d '«étranger», d'autres équipes obtiennent parfois quelque chose de «nôtre».
- il est difficile d'évaluer la "complexité" de la demande. Si l'application est complexe, elle peut être transmise à un analyste fort, et avec une simple, le débutant s'en sortira.
La solution à l'un de ces problèmes affectera positivement la vitesse de traitement des demandes.
L'application du machine learning, appliquée à l'analyse du contenu de l'application, apparaît comme une réelle opportunité d'améliorer le processus de répartition.
Dans notre cas, le problème peut être formulé par les problèmes de classification suivants:
- Assurez-vous que la demande est correctement affectée à:
- unité de configuration (l'une des 5 dans l'application ou «autres»)
- catégories de services (incident, demande d'informations, demande de service)
- Estimer le temps prévu pour clôturer la demande (comme indicateur de haut niveau de "complexité").
Quoi et comment nous travaillerons
Pour créer l'algorithme, nous utiliserons le "jeu standard": Python avec la bibliothèque scikit-learn.
Pour une application réelle, 2 scénarios seront mis en œuvre:
Formation:
- obtenir des données de "formation" à partir du traqueur d'application
- exécuter un algorithme pour former un modèle, enregistrer un modèle
Utilisation:
- recevoir des données de l'outil de suivi des applications pour la classification
- chargement du modèle, classification de l'application, sauvegarde des résultats
- mise à jour des applications dans le tracker en fonction de la classification
Tout ce qui concerne le pipeline (interaction avec le tracker) peut être implémenté sur n'importe quoi. Dans ce cas, des scripts PowerShell ont été écrits, bien qu'il soit possible de continuer en python.
L'algorithme d'apprentissage automatique recevra les données de classification / formation sous la forme d'un fichier .csv. Les résultats traités seront également affichés dans un fichier .csv.
Entrer les données
Afin de rendre l'algorithme le plus indépendant possible de l'avis des équipes de service, nous ne prendrons en compte que les données reçues du créateur de l'application comme paramètres d'entrée du modèle:
- Brève description / titre (texte)
- Une description détaillée du problème, le cas échéant (texte). Il s'agit du premier message du flux de communication de l'application.
- Nom du client (employé, catégorie)
- Noms d'autres employés inclus dans la liste de surveillance sur demande (liste des employés)
- Heure de dépôt de la demande (date / heure).
Ensemble de données de formation
Pour la formation des algorithmes, des données sur les appels clôturés au cours des 3 dernières années ont été utilisées - ~ 3 500 enregistrements.
De plus, afin d'enseigner au classificateur la reconnaissance des «autres» unités de configuration, des applications fermées traitées par d'autres départements pour d'autres unités de configuration ont été ajoutées à l'ensemble de formation. Total des enregistrements supplémentaires - environ 17 000.
Pour toutes ces demandes supplémentaires, l'unité de configuration sera définie sur "autre"
Prétraitement
Texte
Le prétraitement du texte est extrêmement simple:
- Nous traduisons tout en minuscules
- Ne laissez que des chiffres et des lettres - remplacez le reste par des espaces
Liste des notifications (liste de surveillance)
La liste est disponible pour analyse sous la forme d'une chaîne dans laquelle les noms sont présentés sous la forme Nom, Prénom et sont séparés par un point-virgule. Pour l'analyse, nous allons le convertir en une liste de chaînes.
En combinant les listes, nous obtenons un ensemble de noms uniques basés sur toutes les applications de l'ensemble de formation. Cette liste générale formera un vecteur de noms.
Durée de traitement des demandes
Pour nos besoins (gestion des priorités, planification des versions), il suffit d'attribuer l'application à une certaine classe par la durée du service. Il vous permet également de transférer la tâche de la régression à la classification avec un petit nombre de classes.
Texte
- Combinez le «titre» et la «description du problème».
- Passez à TfidfVectoriser pour former un vecteur de mots
Nom du demandeur
Puisqu'on s'attend à ce que la personne qui a créé l'application soit un attribut important d'une classification supplémentaire - nous le traduirons en un codage individuel à l'aide de DictionaryVectorisor
Noms des personnes incluses dans la liste de notification
La liste des personnes incluses dans les applications de la liste de surveillance sera convertie en un vecteur sur la base de tous les noms préparés précédemment: si la personne était dans la liste, le composant correspondant sera défini sur 1, sinon - sur 0. Une application peut avoir plusieurs personnes dans la liste de surveillance - respectivement, plusieurs composants aura une seule valeur.
Date de création
La date de création sera présentée comme un ensemble d'attributs numériques - année, mois, jour du mois, jour de la semaine.
Cela se fait en supposant que:
- La vitesse de traitement des demandes varie au fil du temps
- La vitesse de traitement a un facteur saisonnier
- Le jour de la semaine (en particulier les applications de week-end) peut aider à identifier l'unité de configuration et la catégorie de service
Modèle de formation
Algorithme de classification
Pour les trois tâches de classification, une régression logistique a été utilisée. Il prend en charge la classification multiclasse (dans le modèle One-vs-All), apprend assez rapidement.
Pour former des modèles qui définissent la catégorie de service et la durée de traitement des applications, nous n'utiliserons que des applications appartenant évidemment à nos unités de configuration.
Résultats d'apprentissage
Définition des unités de configuration
Le modèle montre des indicateurs élevés d'exhaustivité et de précision lors de l'affectation d'applications aux unités de configuration. De plus, le modèle définit bien les événements lorsque les applications font référence à des unités de configuration étrangères.
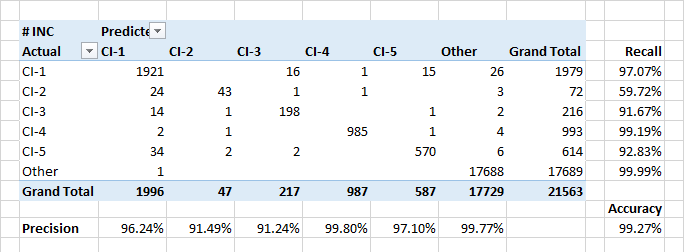
L'exhaustivité relativement faible de la classe CI-2 est en partie due à de réelles erreurs de classification dans les données. De plus, les CI-2 présentent des applications «techniques» exécutées pour d'autres CI. Ainsi, en termes de description et d'utilisateurs impliqués, ces applications peuvent être similaires aux applications d'autres classes.
Les attributs les plus importants pour classer les applications en CI-? les noms des clients des applications et des personnes figuraient sur la feuille d’alerte. Mais il y avait quelques mots-clés qui étaient dans la première tranche de 30 ke. La date de création de l'application n'a pas d'importance.
Définition de la catégorie d'application
La qualité du classement par catégories s'est avérée quelque peu inférieure.
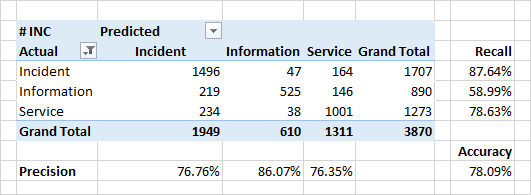
Une très grave raison de la non-concordance des catégories et catégories prévues dans les données source est de réelles erreurs dans les données source. Pour un certain nombre de raisons organisationnelles, la classification peut être incorrecte. Par exemple, au lieu d'un «incident» (un défaut du système, un comportement inattendu du système), l'application peut être marquée comme «information» («ce n'est pas un bogue - c'est une fonctionnalité») ou «service» («oui, il est cassé, mais nous le redémarrons simplement - et tout ira bien ").
L'identification de telles incohérences est l'une des tâches du classificateur.
Les attributs importants pour la classification dans le cas des catégories sont les mots du contenu des applications. Pour les incidents, ce sont les mots "erreur", "correction", "quand". Il y a aussi des mots désignant certains modules du système - ce sont les modules avec lesquels les utilisateurs travaillent directement et observent l'apparition d'erreurs directes ou indirectes.
Fait intéressant, pour les applications qui sont définies comme «service» - les premiers mots définissent également certains modules du système. Une occasion de réfléchir, de vérifier et enfin de les réparer.
Déterminer le temps de traitement de la demande
Le plus faible était de prévoir la durée du traitement des demandes.
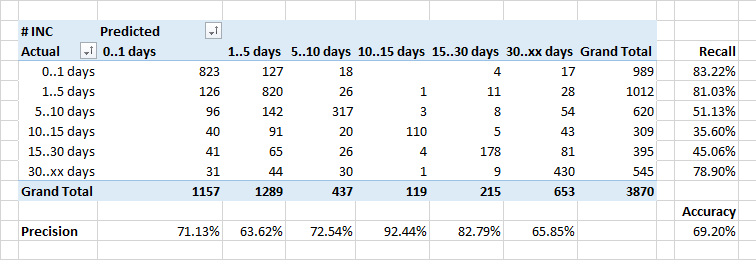
En général, la dépendance du nombre d'applications fermées pendant un certain temps devrait idéalement ressembler à l'inverse de l'exposant. Mais compte tenu du fait que certains incidents nécessitent des corrections dans le système, et cela se fait dans le cadre de versions régulières, la durée d'exécution de certaines applications augmente artificiellement.
Par conséquent, le classificateur classe peut-être certaines applications «longues» comme «plus rapides» - il ne connaît pas le calendrier des versions prévues et estime que l'application doit être fermée plus rapidement.
C'est aussi une bonne raison de penser ...
Implémentation du modèle en classe
Le modèle est implémenté en tant que classe encapsulant toutes les classes standard de scikit-learn utilisées - mise à l'échelle, vectorisation, classificateur et paramètres significatifs.
La préparation, la formation et l'utilisation ultérieure du modèle sont implémentées comme des méthodes de classe, basées sur des objets auxiliaires.
L'implémentation d'objet vous permet de générer facilement des versions dérivées du modèle qui utilisent d'autres classes de classificateurs et / ou de prédire les valeurs d'autres attributs de l'ensemble de données d'origine. Tout cela se fait en remplaçant les méthodes virtuelles.
Cependant, toutes les procédures de préparation des données peuvent rester communes à toutes les options.
De plus, l'implémentation du modèle sous forme d'objet a permis de résoudre naturellement le problème de stockage intermédiaire du modèle formé entre les sessions d'utilisation - par la sérialisation / désérialisation.
Pour sérialiser le modèle, le mécanisme Python standard, pickle / unpickle, a été utilisé.
Puisqu'il vous permet de sérialiser plusieurs objets dans le même fichier, cela aidera à enregistrer de manière cohérente la récupération de plusieurs modèles inclus dans le flux de traitement général.
Conclusion
Les modèles résultants, même relativement simples, donnent des résultats très intéressants:
- identifié des "omissions" systématiques dans la classification par catégorie
- il est devenu clair quelles parties du système sont associées à des problèmes (apparemment - non sans raison)
- Les délais de traitement des demandes dépendent clairement de facteurs externes qui doivent être améliorés séparément.
Nous n'avons pas encore reconstruit les processus internes sur la base des «conseils» reçus. Mais même cette petite expérience a permis d'évaluer la puissance des méthodes d'apprentissage automatique. Et aussi, suscité un intérêt supplémentaire de l'équipe dans l'analyse de leur propre processus et son amélioration.