À l'aube de ma carrière, j'ai travaillé pour une entreprise qui a sorti un système de gestion de contenu. Ce CMS a aidé les départements marketing à gérer leurs sites par eux-mêmes, plutôt que de compter sur les développeurs pour chaque changement. Le système a aidé les clients à réduire leurs coûts d'exploitation et, pour moi, à apprendre à créer des applications Web.
Bien que le produit lui-même ait un objectif très général, les clients l'utilisent généralement pour des tâches spécifiques. Ces tâches ont tiré le maximum du CMS, et les développeurs ont dû chercher une solution aux problèmes. Après dix ans de travail dans un tel environnement, j'ai appris un grand nombre de façons dont une application web en production peut se casser. Certains d'entre eux seront discutés dans cet article.
L'une des leçons apprises au fil des ans est que les ingénieurs individuels se plongent généralement très profondément dans le domaine qui les intéresse et étudient le reste superficiellement. Le programme fonctionne normalement dans une équipe d'ingénieurs avec une bonne communication, où les connaissances se chevauchent et comblent les lacunes individuelles pour chacun d'eux. Mais dans les équipes avec peu d'expérience ou pour des ingénieurs individuels, un échec se produit.
Si vous avez commencé à travailler dans un tel environnement, puis avez commencé à créer et à déployer une application Web à partir de zéro, vous découvrirez rapidement ce qu'est la «connaissance des surfaces dangereuses».
Il existe un certain nombre de solutions dans l'industrie pour résoudre ce problème: les applications Web gérées (Beanstalk, AppEngine, etc.), la gestion des conteneurs (Kubernetes, ECS, etc.) et bien d'autres. Ils fonctionnent bien hors de la boîte et peuvent parfaitement résoudre le problème. Mais c'est une complexité inutile lors du lancement d'une application Web, et généralement de telles solutions «fonctionnent tout simplement».
Malheureusement, ils ne «travaillent pas» toujours. S'il y a une nuance, je veux en savoir un peu plus sur cette sinistre boîte noire.
Dans l'article, nous prenons un système peu fiable et le modifions à un niveau de fiabilité raisonnable. À chaque étape, un véritable problème est utilisé, dont la solution nous amène à l'étape suivante. Je pense qu'il est plus efficace de ne pas analyser toutes les parties de la conception finale, mais d'utiliser une telle approche en plusieurs phases. Il montre mieux quand et dans quel ordre prendre certaines décisions. En fin de compte, nous allons construire à partir de zéro la structure de base du service d'hébergement pour les applications Web gérées, et j'espère que nous expliquerons en détail les raisons de l'existence de chacune de ses parties.
Commencer
Imaginez que votre budget d'hébergement soit de 500 $ par an, vous avez donc décidé de louer un serveur t2.medium sur Amazon AWS. Au moment de la rédaction de ce document, cela représente environ 400 $ par an.
Vous savez à l'avance que vous disposerez d'un système d'autorisation et que vous devrez stocker des informations sur les utilisateurs, vous avez donc besoin d'une base de données. En raison du budget limité, nous le placerons sur notre seul serveur. Au final, nous obtenons l'infrastructure suivante:
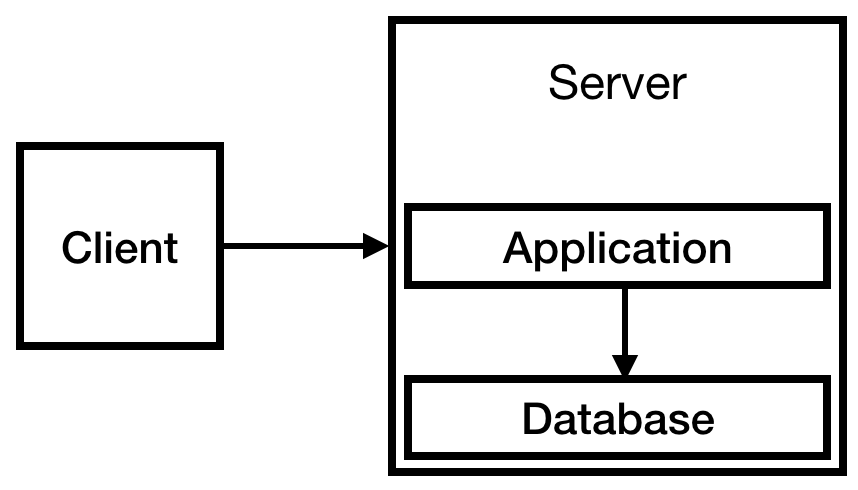 Fig. 1
Fig. 1C'est assez pour l'instant. En fait, un tel système peut fonctionner pendant un certain temps. Le service est petit, moins de 10 visites par jour. Un petit exemple suffit peut-être, mais nous sommes optimistes quant à la croissance de l'entreprise, nous avons donc prudemment pris t2.medium.
La valeur de l'entreprise est dans la base de données, c'est donc très important. Vous devez vous assurer que si le serveur tombe en panne, vous ne perdrez pas de données. Vous devez probablement vous assurer que le contenu de la base de données n'est pas stocké sur un disque temporaire. Après tout, si l'instance est supprimée, vous perdrez vos données. C'est une pensée très effrayante.
Vous devez également vous assurer que vous disposez de sauvegardes sur le stockage externe. S3 semble être un bon endroit pour eux, et relativement peu coûteux, alors configurons-le également. Et vous devez absolument vérifier que la sauvegarde fonctionne, en restaurant périodiquement la sauvegarde.
Maintenant, le système ressemble à ceci:
 Fig. 2
Fig. 2Vous avez augmenté la fiabilité de la base de données et il est temps de vous préparer à «l'habraeffet» en exécutant un test de charge sur le serveur. Tout se passe très bien jusqu'à ce que 500 erreurs apparaissent, puis un flux d'erreurs 404, donc vous étudiez ce qui s'est passé.
Il s'avère que vous n'avez aucune idée de ce qui s'est passé car vous avez écrit des journaux dans la console et n'avez pas dirigé la sortie vers un fichier. Vous voyez également que le processus ne fonctionne pas, vous pouvez donc très probablement supposer que c'est la raison pour laquelle des erreurs 404 apparaissent. Une vague de soulagement vient du fait que vous avez correctement exécuté le test de charge local et n'avez pas provoqué le véritable effet Habra en tant que charge de test.
Vous résolvez le problème du redémarrage automatique en créant le service
systemd , démarrez le serveur Web, ce qui résout simultanément le problème de la journalisation. Exécutez ensuite un autre test de charge pour vérifier.
Et encore une fois, nous voyons des erreurs 500 (heureusement, sans 404). Vous vérifiez les journaux. Il est détecté que le pool de connexions à la base de données est plein car une petite limite de 10 connexions a été définie. Mettez à jour la restriction, redémarrez la base de données et relancez le test de charge. Tout se passe bien, vous décidez donc de parler de votre site sur Habré.
Jour de lancement
Mère de Dieu! Votre service devient instantanément un succès. Vous êtes arrivé à la page principale et obtenez 5000 vues dans les 30 premières minutes - et vous voyez les commentaires. Qu'est-ce qu'ils y écrivent?
J'ai une erreur 404, j'ai donc dû ouvrir une version en cache de la page. Voici le lien, si quelqu'un en a besoin: ...
...
Rien ne s'ouvre. De plus, j'ai désactivé Javascript. Pourquoi les gens pensent que je veux charger leur Javascript de 2 Mo ...
...
Le téléchargement de la page d'accueil prend 4 secondes. Traceroute d'Australie montre que le serveur est situé quelque part au Texas. Aussi, pourquoi la première page charge-t-elle 2 mégaoctets de Javascript?
Dans une course folle, vous configurez Nginx en tant que serveur proxy inverse pour votre application et y configurez une page statique 404. Vous modifiez également la procédure de déploiement pour envoyer des fichiers statiques à S3: cela est nécessaire pour que CloudFront CDN fonctionne afin de réduire le temps de chargement en Australie.
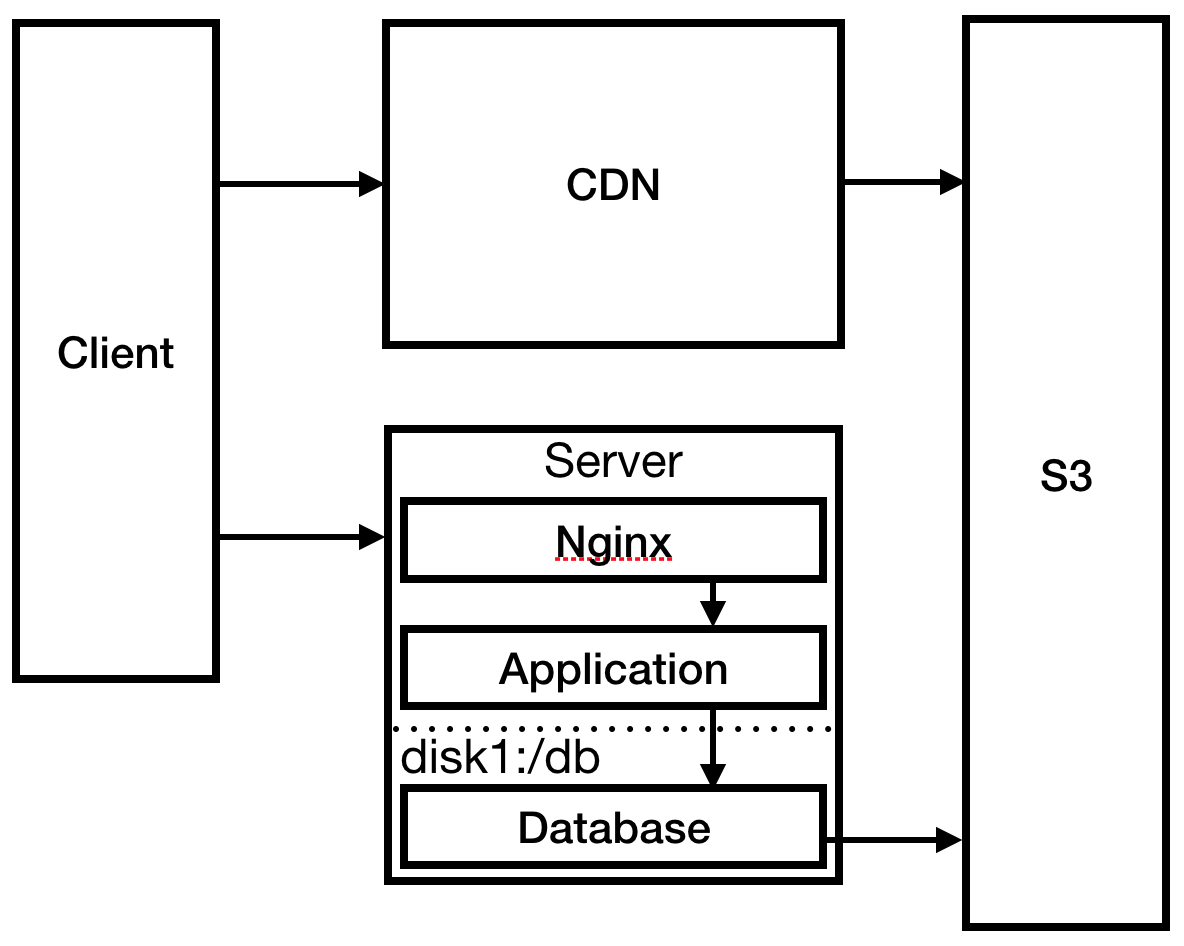 Fig. 3
Fig. 3Vous avez résolu le problème le plus urgent, allez sur le serveur et consultez les journaux. Votre connexion SSH est inhabituellement en retard. Après une étude, vous voyez que les fichiers journaux ont complètement utilisé l'espace disque, ce qui a entraîné le blocage du processus et l'empêche de redémarrer. Créez un disque beaucoup plus grand et montez-y les journaux. Configurez
logrotate pour que les fichiers journaux
logrotate plus ces tailles.
Problèmes de performances
Les mois passent. Le public augmente. Le site commence à ralentir. Vous avez remarqué dans la surveillance CloudWatch que cela ne se produit qu'entre 00:00 et 12:00 UTC. En raison des mêmes délais de début et de fin, vous vous rendez compte que cela est dû à une tâche planifiée sur le serveur. Vérifiez crontab et réalisez qu'une tâche est prévue pour minuit: la sauvegarde. Bien sûr, la sauvegarde prend douze heures et entraîne une surcharge de la base de données, provoquant un ralentissement important du site.
Vous avez lu à ce sujet avant - et décidez d'exécuter des sauvegardes dans une base de données esclave. N'oubliez pas: vous n'avez pas de base de données subordonnée, vous devez donc la créer. Cela n'a pas beaucoup de sens d'exécuter la base de données esclave sur le même serveur, vous décidez donc de l'étendre. Créez deux nouveaux serveurs: un pour la base de données maître et un pour la base de données esclave. Modifiez la sauvegarde pour qu'elle fonctionne avec une base de données subordonnée.
 Fig. 4
Fig. 4Croissance d'équipe
Pendant un moment, tout se passe bien. Les mois passent. Vous embauchez des développeurs. L'un des nouveaux venus introduit un bogue qui fait tomber le serveur de production. Le développeur accuse l'environnement de développement, qui est différent de la production. Il y a du vrai dans ses paroles. Puisque vous êtes une personne rationnelle avec un bon caractère, vous percevez cet événement comme une leçon.
Il est temps de créer des environnements supplémentaires: staging, QA et production. Heureusement, dès le premier jour, vous avez automatisé la création de l'infrastructure, pour que tout se passe bien et simplement. Vous avez également établi de bonnes pratiques de livraison continue dès le premier jour, vous pouvez donc facilement assembler un convoyeur à partir de nouvelles succursales.
Le département marketing fait pression pour la version 2.0. Vous ne comprenez pas bien ce que signifie 2.0, mais vous êtes d'accord. Il est temps de se préparer à la prochaine augmentation du trafic. Vous êtes déjà proche du pic sur le serveur actuel, le temps est donc venu pour l'équilibrage de charge. Amazon ELB vous facilite la tâche. À cette époque, vous remarquez que les diagrammes en couches de cet article doivent montrer les calques de haut en bas et non de gauche à droite.
 Fig. 5
Fig. 5Confiant que vous allez faire face à la charge, vous mentionnez à nouveau votre site sur Habré. Oh miracle, il peut supporter le trafic. Grand succès!
Tout semblait bien se passer jusqu'à ce que vous alliez vérifier les journaux. Il a fallu une heure pour tester 12 serveurs (quatre serveurs dans chaque environnement). Un vrai tracas. Heureusement, il y a suffisamment d'argent pour acheter une pile ELK (ElasticSearch, LogStash, Kibana). Vous le déployez et y dirigez les serveurs de tous les environnements.
 Fig. 6
Fig. 6Maintenant, vous pouvez à nouveau consulter les journaux, les regarder - et remarquer quelque chose d'étrange. Ils sont pleins de telles entrées:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
Vous n'utilisez pas PHP ou WordPress, c'est donc plutôt étrange. Vous remarquez des entrées suspectes similaires dans les journaux des serveurs de base de données et vous vous demandez comment ils se sont même connectés à Internet. Il est temps de mettre en œuvre des sous-réseaux publics et privés.
 Fig. 7
Fig. 7Vérifiez à nouveau les journaux. Les tentatives de piratage sont restées, mais elles sont maintenant limitées au port 80 sur l'équilibreur de charge, ce qui est un peu réconfortant, car les serveurs d'applications, les serveurs de base de données et la pile ELK ne sont plus dans le domaine public.
Malgré les journaux centralisés, vous en avez assez de chercher des temps d'arrêt, de vérifier les journaux manuellement. Grâce à Amazon CloudWatch, vous configurez des alertes par e-mail lorsque le lecteur, le processeur et le réseau atteignent 80% d'utilisation. Super!
Fonctionnement en douceur
Je plaisante! Le bon fonctionnement d'un logiciel n'existe pas. Quelque chose va définitivement se casser. Heureusement, vous disposez désormais de nombreux outils pour gérer la situation.
Nous avons créé une application web évolutive avec des sauvegardes, des rollbacks (en utilisant des déploiements bleu / vert entre la production et la phase intermédiaire), des journaux centralisés, la surveillance et la notification. Une mise à l'échelle supplémentaire, en règle générale, dépend des besoins spécifiques de l'application.
Il existe de nombreuses options d'hébergement sur le marché qui prennent en charge la plupart des tâches mentionnées. Au lieu de développer par vous-même, vous pouvez compter sur Beanstalk, AppEngine, GKE, ECS, etc. La plupart de ces services configurent automatiquement des autorisations raisonnables, des sous-systèmes d'équilibrage de charge, des sous-réseaux, etc. Cela élimine une partie importante des tracas liés à l'exécution d'une application Web sur un backend fiable qui fonctionne depuis longtemps.
Malgré cela, je trouve utile de comprendre quelles fonctionnalités chacune de ces plateformes fournit et pourquoi elles la fournissent. Cela facilite le choix d'une plate-forme en fonction de vos propres besoins. En hébergeant l'application sur une telle plateforme, vous saurez déjà comment fonctionnent ces modules. En cas de problème, il est utile de connaître les outils pour résoudre le problème.
Conclusion
Cet article omet de nombreux détails. Il ne décrit pas comment automatiser la création d'une infrastructure, comment préparer et configurer des serveurs. Il ne couvre pas la création d'environnements de développement, la mise en place de pipelines de livraison continue, le déploiement et la restauration. Nous n'avons pas abordé la sécurité du réseau, le partage de clés et le principe des privilèges minimaux. Ils n'ont pas parlé de l'importance d'une infrastructure immuable, de serveurs sans état et de migrations. Chaque sujet nécessite un article distinct.
Le but de cet article est un aperçu général de ce à quoi devrait ressembler une application web raisonnable en production. Les futurs articles peuvent créer un lien ici et développer le sujet.
C'est tout pour l'instant.
Merci pour la lecture et le bon codage!
Remarque: ne prenez pas littéralement la séquence de cet article illustratif. Séparément, tous ces événements m'ont vraiment arrivé, mais à des moments différents, dans des environnements complètement différents et sur des tâches différentes.