Nikolai Ryzhikov a proposé sa version de la réponse à la question de savoir pourquoi il est si difficile de développer une interface utilisateur. Sur l'exemple de son projet, il montrera que l'application sur le frontend de certaines idées du backend affecte à la fois la réduction de la complexité de développement et la testabilité du frontend.
Le matériel a été préparé sur la base d'un rapport de Nikolai Ryzhikov lors de la
conférence de printemps
HolyJS 2018 Piter .
Actuellement, Nikolai Ryzhikov travaille dans le secteur Santé-TI pour créer des systèmes d'information médicale. Membre de la communauté des programmeurs fonctionnels FPROG de Saint-Pétersbourg. Membre actif de la communauté Online Clojure, membre de la norme d'échange d'informations médicales HL7 FHIR. Programmation depuis 15 ans.
- J'ai toujours été tourmenté par la question: pourquoi l'interface graphique était-elle toujours difficile à faire? Pourquoi cela a-t-il toujours soulevé de nombreuses questions?
Aujourd'hui, je vais essayer de spéculer sur la possibilité de développer efficacement une interface utilisateur. Pouvons-nous réduire la complexité de son développement.
Qu'est-ce que l'efficacité?
Définissons ce qu'est l'efficacité. Du point de vue du développement d'une interface utilisateur, l'efficacité signifie:
- vitesse de développement
- nombre de bugs
- montant d'argent dépensé ...
Il y a une très bonne définition:
L'efficacité, c'est faire plus avec moins
Après cette détermination, vous pouvez mettre tout ce que vous voulez - passer moins de temps, moins d'efforts. Par exemple, «si vous écrivez moins de code, autorisez moins de bogues» et atteignez le même objectif. En général, nous dépensons beaucoup d'efforts en vain. Et l'efficacité est un objectif plutôt élevé - se débarrasser de ces pertes et ne faire que ce qui est nécessaire.
Qu'est-ce que la complexité?
À mon avis, la complexité est le principal problème du développement.
Fred Brooks a écrit un article en 1986 intitulé No silver bullet. Il y réfléchit sur les logiciels. Dans le matériel, les progrès sont des sauts et des limites, et avec les logiciels, tout est bien pire. La question principale de Fred Brooks - peut-il y avoir une telle technologie qui nous accélère immédiatement d'un ordre de grandeur? Et lui-même donne une réponse pessimiste, déclarant que dans le logiciel, il n'est pas possible d'y parvenir, expliquant sa position. Je recommande fortement de lire cet article.
Un de mes amis a dit que la programmation de l'interface utilisateur est un tel "sale problème". Vous ne pouvez pas vous asseoir une seule fois et trouver la bonne option pour que le problème soit résolu pour toujours. De plus, au cours des 10 dernières années, la complexité du développement n'a fait qu'augmenter.
Il y a 12 ans ...
Nous avons commencé à développer un système d'information médicale il y a 12 ans. D'abord avec flash. Nous avons ensuite examiné ce que Gmail avait commencé à faire. Nous l'avons aimé et nous voulions passer au JavaScript avec HTML.
En fait, nous étions alors bien en avance. Nous avons pris un dojo, et en fait, nous avions tout de même que nous avons maintenant. Il y avait des composants qui étaient assez bons dans les widgets dojo, il y avait un système de construction modulaire et exigeait que le compilateur Google Clojure soit construit et minimisé (RequireJS et CommonJS ne sentaient même pas alors).
Tout a fonctionné. Nous avons regardé Gmail, avons été inspirés, avons pensé que tout allait bien. Au début, nous n'avions écrit qu'un lecteur de carte patient. Ensuite, ils sont progressivement passés à l'automatisation d'autres flux de travail à l'hôpital. Et tout est devenu compliqué. L'équipe semble être des professionnels - mais chaque fonctionnalité a commencé à grincer. Cette sensation est apparue il y a 12 ans - et ne me quitte toujours pas.
Voie Rails + jQuery
Nous avons fait la certification du système et il a fallu rédiger un portail patient. C'est un tel système où le patient peut aller voir ses données médicales.
Notre backend a ensuite été écrit en Ruby on Rails. Bien que la communauté Ruby on Rails ne soit pas très grande, elle a eu un impact énorme sur l'industrie. De votre petite communauté passionnée, tous vos gestionnaires de packages, GitHub, Git, maquillages automatiques, etc. sont venus.
L'essence du défi auquel nous avons été confrontés était que nous devions mettre en œuvre le portail des patients en deux semaines. Et nous avons décidé d'essayer la méthode Rails - pour tout faire sur le serveur. Un tel web 2.0 classique. Et ils l'ont fait - ils l'ont vraiment fait en deux semaines.
Nous étions en avance sur la planète entière: nous avons fait du SPA, nous avions une API REST, mais pour une raison quelconque, elle était inefficace. Certaines fonctionnalités pouvaient déjà faire des unités, car seules elles étaient capables de gérer toute cette complexité des composants, la relation du backend avec le frontend. Et quand nous avons pris la voie Rails - un peu dépassée par rapport à nos normes, les fonctionnalités ont soudainement commencé à riveter. Le développeur moyen a commencé à déployer la fonctionnalité en quelques jours. Et nous avons même commencé à écrire des tests simples.
Sur cette base, j'ai toujours une blessure: il y avait des questions. Lorsque nous sommes passés de Java à Rails sur le backend, l'efficacité du développement a été multipliée par 10 environ. Mais lorsque nous avons marqué sur le SPA, l'efficacité du développement a également augmenté de manière significative. Comment ça?
Pourquoi le Web 2.0 a-t-il été efficace?
Commençons par une autre question: pourquoi faisons-nous une application d'une seule page, pourquoi y croyons-nous?
Ils nous disent simplement: nous devons le faire - et nous le faisons. Et très rarement le remettre en question. L'architecture REST API et SPA est-elle correcte? Est-il vraiment adapté au cas où nous l'utilisons? Nous ne pensons pas.
D'un autre côté, il existe des exemples inverses remarquables. Tout le monde utilise GitHub. Savez-vous que GitHub n'est pas une application d'une seule page? GitHub est une application "rail" classique qui est rendue sur le serveur et où il y a peu de widgets. Quelqu'un en a-t-il fait l'expérience? Je pense qu'il y a trois personnes. Les autres n'ont même pas remarqué. Cela n'a pas affecté l'utilisateur en aucune façon, mais en même temps, pour une raison quelconque, nous devons payer 10 fois plus pour le développement d'autres applications (à la fois la force, la complexité, etc.). Un autre exemple est Basecamp. Twitter n'était autrefois qu'une application Rails.
En fait, il y a tellement d'applications Rails. Cela a été partiellement déterminé par le génie DHH (David Heinemeier Hansson, créateur de Ruby on Rails). Il a su créer un outil axé sur les affaires, qui vous permet de faire immédiatement ce dont vous avez besoin, sans être distrait par des problèmes techniques.
Lorsque nous avons utilisé la méthode Rails, bien sûr, il y avait beaucoup de magie noire. Au fur et à mesure de notre développement, nous sommes passés de Ruby à Clojure, en conservant pratiquement la même efficacité, mais en simplifiant tout un ordre de grandeur. Et c'était merveilleux.
12 ans se sont écoulés
Au fil du temps, de nouvelles tendances ont commencé à apparaître dans le frontend.
Nous avons complètement ignoré Backbone, car l'application dojo que nous avons écrite auparavant était encore plus sophistiquée que ce que Backbone offrait.
Puis vint Angular. C'était un «rayon de lumière» assez intéressant - du point de vue de l'efficacité, Angular est très bon. Vous prenez le développeur moyen, et il rivalise avec la fonctionnalité. Mais du point de vue de la simplicité, Angular apporte un tas de problèmes - il est opaque, complexe, il y a la veille, l'optimisation, etc.
React est apparu, ce qui a apporté un peu de simplicité (au moins la simplicité du rendu, qui, grâce au Virtual DOM, nous permet à chaque fois comme pour simplement redessiner, comprendre et écrire). Mais en termes d'efficacité, pour être honnête, React nous a considérablement repoussés.
Le pire, c'est que rien n'a changé en 12 ans. Nous faisons toujours la même chose qu'alors. Il est temps de réfléchir - quelque chose ne va pas ici.
Fred Brooks dit qu'il y a deux problèmes avec le développement de logiciels. Bien sûr, il voit le problème principal de la complexité, mais il le divise en deux groupes:
- complexité importante qui vient de la tâche elle-même. Il ne peut tout simplement pas être jeté, car il fait partie de la tâche.
- la complexité aléatoire est celle que nous apportons en essayant de résoudre ce problème.
La question est, quel est l'équilibre entre eux. C'est précisément ce dont nous discutons actuellement.
Pourquoi est-ce si pénible de faire l'interface utilisateur?
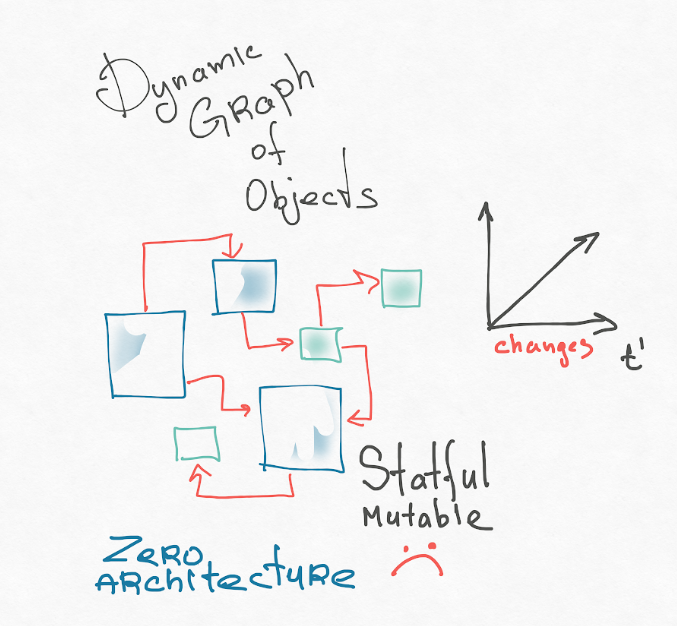
Il me semble que la première raison est notre modèle d'application mentale. Les composants React sont une approche purement OOP. Notre système est un graphe dynamique d'objets mutables interconnectés. Les types Turing-complete génèrent constamment des nœuds de ce graphe, certains nœuds disparaissent. Avez-vous déjà essayé d'imaginer votre application dans votre tête? C'est effrayant! Je présente généralement une application POO comme celle-ci:

Je recommande la lecture des thèses de Roy Fielding (auteur de l'architecture REST). Sa thèse s'intitule «Les styles architecturaux et la conception de logiciels en réseau». Au tout début, il y a une très bonne introduction, où il explique comment accéder à l'architecture en général, et présente les concepts: décompose le système en composants et les relations entre ces composants. Il a une architecture "zéro", où tous les composants peuvent potentiellement être associés à tous. C'est le chaos architectural. Il s'agit de notre représentation d'objet de l'interface utilisateur.
Roy Fielding recommande de rechercher et d'imposer un ensemble de contraintes, car c'est un ensemble de contraintes qui définit votre architecture.
La chose la plus importante est probablement que les restrictions sont des amis de l'architecte. Recherchez ces limitations réelles et concevez un système à partir de celles-ci. Parce que la liberté est mauvaise. La liberté signifie que vous avez un million d'options parmi lesquelles vous pouvez choisir, et non un seul critère par lequel vous pouvez déterminer si le choix était bon. Recherchez les contraintes et tirez parti de celles-ci.
Il y a un excellent article intitulé OUT OF THE TAR PIT («Plus facile qu'un puits de goudron»), dans lequel les gars après Brooks ont décidé d'analyser ce qui contribue exactement à la complexité de l'application. Ils en sont venus à la conclusion décevante qu'un système mutable à propagation étatique est la principale source de complexité. Ici, il est possible d'expliquer de manière purement combinatoire - si vous avez deux cellules, et dans chacune d'elles une balle peut mentir (ou ne pas mentir), combien d'états sont possibles? - Quatre.
Si trois cellules - 2
3 , si 100 cellules - 2
100 . Si vous présentez votre application et comprenez à quel point l'état est flou, vous vous rendez compte qu'il existe un nombre infini d'états possibles de votre système. Si en même temps vous n'êtes limité par rien, c'est trop difficile. Et le cerveau humain est faible, cela a déjà été prouvé par diverses études. Nous sommes capables de tenir jusqu'à trois éléments dans nos têtes en même temps. Certains disent sept, mais même pour cela, le cerveau utilise un hack. Par conséquent, la complexité est vraiment un problème pour nous.
Je recommande de lire cet article, où les gars arrivent à la conclusion que quelque chose doit être fait avec cet état mutable. Par exemple, il existe des bases de données relationnelles, vous pouvez y supprimer l'intégralité de l'état mutable. Et le reste se fait dans un style purement fonctionnel. Et ils viennent juste avec l'idée d'une telle programmation fonctionnelle-relationnelle.
Le problème vient donc du fait que:
- premièrement, nous n'avons pas un bon modèle d'interface utilisateur fixe. Les approches par composants nous conduisent à l'enfer existant. Nous n'imposons aucune restriction, nous répandons l'état mutable, en conséquence, la complexité du système à un moment donné nous écrase tout simplement;
- deuxièmement, si nous écrivons une application backend - frontend classique, c'est déjà un système distribué. Et la première règle des systèmes distribués est de ne pas créer de systèmes distribués (Première loi de la conception d'objets distribués: ne distribuez pas vos objets - par Martin Fowler), car vous augmentez immédiatement la complexité d'un ordre de grandeur. Quiconque a écrit une intégration comprend que dès que vous entrez dans l'interaction intersystèmes, toutes les estimations de projet peuvent être multipliées par 10. Mais nous l'oublions et passons aux systèmes distribués. C'était probablement la principale considération lorsque nous sommes passés à Rails, en retournant tout le contrôle au serveur.
Tout cela est trop dur pour un pauvre cerveau humain. Réfléchissons à ce que nous pouvons faire avec ces deux problèmes - le manque de restrictions en architecture (le graphique des objets mutables) et la transition vers des systèmes distribués qui sont si complexes que les universitaires se demandent encore comment les faire correctement (en même temps, nous nous condamner à ces tourments dans les applications commerciales les plus simples)?
Comment le backend a-t-il évolué?
Si nous écrivons le backend dans le même style que nous créons l'interface utilisateur maintenant, il y aura le même «bordel sanglant». Nous y consacrerons autant de temps. Donc vraiment une fois essayé de le faire. Puis, progressivement, ils ont commencé à imposer des restrictions.
La première grande invention de backend est la base de données.
Au début, dans le programme, l'État tout entier restait inexplicablement où, et il était difficile de le gérer. Au fil du temps, les développeurs ont créé une base de données et y ont supprimé tout l'état.
La première différence intéressante entre la base de données est que les données ne sont pas des objets avec leur propre comportement, ce sont des informations pures. Il existe des tables ou d'autres structures de données (par exemple, JSON). Ils n'ont aucun comportement, ce qui est également très important. Parce que le comportement est une interprétation de l'information, et il peut y avoir de nombreuses interprétations. Et les faits de base - ils restent fondamentaux.
Un autre point important est que sur cette base de données, nous avons un langage de requête tel que SQL. Du point de vue des limitations, dans la plupart des cas, SQL n'est pas un langage complet de Turing, il est plus simple. En revanche, il est déclaratif - plus expressif, car en SQL, vous dites «quoi», pas «comment». Par exemple, lorsque vous combinez deux étiquettes dans SQL, SQL décide comment effectuer cette opération efficacement. Lorsque vous cherchez quelque chose, il récupère un index pour vous. Vous ne le dites jamais explicitement. Si vous essayez de combiner quelque chose en JavaScript, vous devrez écrire un tas de code pour cela.
Ici encore, il est important que nous ayons imposé des restrictions et maintenant nous allons à cette base à travers un langage plus simple et plus expressif. Complexité redistribuée.
Une fois le backend entré dans la base, l'application est devenue apatride. Cela conduit à des effets intéressants - maintenant, par exemple, nous n'avons peut-être pas peur de mettre à jour l'application (l'état ne se bloque pas dans la couche application en mémoire, qui disparaîtra si l'application redémarre). Pour une couche d'application, l'apatridie est une bonne fonctionnalité et une excellente contrainte. Mettez-le si vous le pouvez. De plus, une nouvelle application peut être tirée sur l'ancienne base, car les faits et leur interprétation ne sont pas des choses liées.
De ce point de vue, les objets et les classes sont terribles car ils collent les comportements et les informations. L'information est plus riche, elle vit plus longtemps. Les bases de données et les faits survivent au code écrit en Delphi, Perl ou JavaScript.
Lorsque le backend est arrivé à une telle architecture, tout est devenu beaucoup plus simple. L'ère d'or du Web 2.0 est arrivée. Il était possible d'obtenir quelque chose de la base de données, de soumettre les données à des modèles (fonction pure) et de renvoyer le HTML-ku, qui est envoyé au navigateur.
Nous avons appris à écrire des applications assez complexes sur le backend. Et la plupart des applications sont écrites dans ce style. Mais dès que le backend fait un pas de côté - dans l'incertitude - les problèmes recommencent.
Les gens ont commencé à y penser et ont eu l'idée de jeter l'OLP et les rituels.
Que font réellement nos systèmes? Ils prennent des informations quelque part - de l'utilisateur, d'un autre système, etc. - les mettent dans la base de données, les transforment, les vérifient d'une manière ou d'une autre. De la base, ils le sortent avec des requêtes astucieuses (analytiques ou synthétiques) et le retournent. C’est tout. Et c'est important à comprendre. De ce point de vue, les simulations sont un concept très faux et mauvais.
Il me semble qu'en général, l'ensemble de la POO est né de l'interface utilisateur. Les gens ont essayé de simuler et de simuler une interface utilisateur. Ils ont vu un certain objet graphique sur le moniteur et ont pensé: ce serait bien de le stimuler dans notre runtime, avec ses propriétés, etc. Toute cette histoire est étroitement liée à la POO. Mais la simulation est le moyen le plus simple et le plus naïf de résoudre la tâche. Des choses intéressantes se font lorsque vous vous écartez. De ce point de vue, il est plus important de séparer les informations du comportement, de se débarrasser de ces objets étranges, et tout deviendra beaucoup plus facile: votre serveur web reçoit une chaîne HTTP, renvoie une chaîne de réponse HTTP. Si vous ajoutez une base à l'équation, vous obtenez une fonction généralement pure: le serveur accepte la base et demande, retourne une nouvelle base et une réponse (données entrées - données restantes).
Sur le chemin de cette simplification, les fonctionnaires ont jeté un autre ⅔ des bagages qui s'étaient accumulés sur le backend. Il n'était pas nécessaire, c'était juste un rituel. Nous ne sommes toujours pas un développeur de jeux - nous n'avons pas besoin que le patient et le médecin vivent en quelque sorte pendant l'exécution, se déplacent et suivent leurs coordonnées. Notre modèle d'information est autre chose. Nous ne prétendons pas être des médicaments, des ventes ou quoi que ce soit d'autre. Nous créons quelque chose de nouveau à la jonction. Par exemple, Uber ne simule pas le comportement des opérateurs et des machines - il introduit un nouveau modèle d'information. Dans notre domaine, nous créons également quelque chose de nouveau, pour que vous ressentiez la liberté.
Il n'est pas nécessaire d'essayer de simuler complètement - créer.
Clojure = JS--
Il est temps de vous dire exactement comment vous pouvez tout jeter. Et ici, je veux mentionner Clojure Script. En fait, si vous connaissez JavaScript, vous connaissez Clojure. Dans Clojure, nous n'ajoutons pas de fonctionnalités à JavaScript, mais nous les supprimons.
- Nous jetons la syntaxe - dans Clojure (en Lisp) il n'y a pas de syntaxe. Dans un langage ordinaire, nous écrivons du code, qui est ensuite analysé et un AST est obtenu, qui est compilé et exécuté. En Lisp, nous écrivons immédiatement un AST qui peut être exécuté - interprété ou compilé.
- Nous jetons la mutabilité. Il n'y a pas d'objets ou de tableaux modifiables dans Clojure. Chaque opération génère comme si une nouvelle copie. De plus, cette copie est très bon marché. C'est si intelligemment conçu pour être bon marché. Et cela nous permet de travailler, comme en mathématiques, avec des valeurs. Nous ne changeons rien - nous créons quelque chose de nouveau. Sûr, facile.
- Nous organisons des cours, des jeux avec des prototypes, etc. Ce n'est tout simplement pas là.
En conséquence, nous avons toujours des fonctions et des structures de données sur lesquelles nous opérons, ainsi que des primitives. Voici le Clojure entier. Et là-dessus, vous pouvez faire la même chose que vous faites dans d'autres langues, où il existe de nombreux outils supplémentaires que personne ne sait utiliser.
Des exemples
Comment arriver à Lisp via AST? Voici une expression classique:
(1 + 2) - 3
Si nous essayons d'écrire son AST, par exemple, sous la forme d'un tableau, où la tête est le type de nœud, et ce qui est ensuite un paramètre, nous obtiendrons quelque chose de similaire (nous essayons d'écrire ceci en Java Script):
['minus', ['plus', 1, 2], 3]
Jetez maintenant les guillemets supplémentaires, nous pouvons remplacer le moins par
- , et le plus par
+ . Jetez les virgules qui sont des espaces dans Lisp. Nous obtiendrons le même AST:
(- (+ 1 2) 3)
Et en Lisp, nous écrivons tous comme ça. Nous pouvons vérifier - c'est une fonction mathématique pure (mon emacs est connecté au navigateur; j'y laisse tomber le script, il y évalue la commande et le renvoie à emacs - vous voyez la valeur après le symbole
=> ):
(- (+ 1 2) 3) => 0
On peut aussi déclarer une fonction:
(defn xplus [ab] (+ ab)) ((fn [xy] (* xy)) 1 2) => 2
Ou une fonction anonyme. Cela semble peut-être un peu effrayant:
(type xplus)
Son type est une fonction JavaScript:
(type xplus) => #object[Function]
On peut l'appeler en lui passant le paramètre:
(xplus 1 2)
Autrement dit, tout ce que nous faisons est d'écrire AST, qui est ensuite soit compilé en JS ou en bytecode, soit interprété.
(defn mymin [ab] (if (a > b) ba))
Clojure est une langue hébergée. Par conséquent, il prend des primitives du runtime parent, c'est-à-dire que dans le cas de Clojure Script, nous aurons des types JavaScript:
(type 1) => #object[Number]
(type "string") => #object[String]
Donc, les expressions rationnelles sont écrites:
(type #"^Cl.*$") => #object[RegExp]
Les fonctions que nous avons sont des fonctions:
(type (fn [x] x)) => #object[Function]
Ensuite, nous avons besoin d'une sorte de types composites.
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} (type user)
Cela peut être lu comme si vous créiez un objet en JavaScript:
(def user {name: "niquola" …
Dans Clojure, cela s'appelle hashmap. Il s'agit d'un conteneur dans lequel se trouvent les valeurs. Si des crochets sont utilisés - alors cela s'appelle un vecteur - c'est votre tableau:
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} => #'intro/user (type user)
Nous enregistrons toute information avec des hashmaps et des vecteurs.
Les noms de deux-points étranges (
:name ) sont les soi-disant caractères: des chaînes constantes qui sont créées pour être utilisées comme clés dans les hashmaps. Dans différentes langues, ils sont appelés différemment - symboles, autre chose. Mais cela peut être pris simplement comme une chaîne constante. Ils sont assez efficaces - vous pouvez écrire des noms longs et ne pas y consacrer beaucoup de ressources, car ils sont connectés (c'est-à-dire qu'ils ne sont pas répétés).
Clojure fournit des centaines de fonctions pour gérer ces structures de données génériques et primitives. Nous pouvons ajouter, ajouter de nouvelles clés. De plus, nous avons toujours une sémantique de copie, c'est-à-dire chaque fois que nous obtenons une nouvelle copie. Vous devez d'abord vous y habituer, car vous ne pourrez plus enregistrer quelque chose, comme auparavant, quelque part dans la variable, puis modifier cette valeur. Votre calcul doit toujours être simple - tous les arguments doivent être passés explicitement à la fonction.
Cela mène à une chose importante. Dans les langages fonctionnels, une fonction est un composant idéal car elle reçoit tout explicitement à l'entrée. Pas de liens cachés divergents dans le système. Vous pouvez prendre une fonction d'un endroit, la transférer vers un autre et l'utiliser là-bas.
Dans Clojure, nous avons d'excellentes opérations d'égalité en valeur même pour les types composites complexes:
(= {:a 1} {:a 1}) => true
Et cette opération est bon marché du fait que des structures immuables rusées peuvent être comparées simplement par référence. Par conséquent, même une table de hachage avec des millions de clés, nous pouvons comparer en une seule opération.
Au fait, les gars de React ont simplement copié l'implémentation de Clojure et rendu JS immuable.
Clojure a également un tas d'opérations, par exemple, obtenir quelque chose à partir d'un chemin imbriqué dans hashmap:
(get-in user [:address :city])
Mettez quelque chose le long du chemin imbriqué dans hashmap:
(assoc-in user [:address :city] "LA") => {:name "niquola", :address {:city "LA"}, :profiles [{:type "github", :link "https://….."} {:type "twitter", :link "https://….."}], :age 37}
Mettre à jour une valeur:
(update-in user [:profiles 0 :link] (fn [old] (str old "+++++")))
Sélectionnez uniquement une clé spécifique:
(select-keys user [:name :address])
Même chose avec le vecteur:
(def clojurists [{:name "Rich"} {:name "Micael"}]) (first clojurists) (second clojurists) => {:name "Michael"}
Il existe des centaines d'opérations de la bibliothèque de base qui vous permettent d'opérer sur ces structures de données. Il y a une interopérabilité avec l'hôte. Vous devez vous y habituer un peu:
(js/alert "Hello!") => nil </csource> "". location window: <source lang="clojure"> (.-location js/window)
Il y a tous les sucres qui vont le long des chaînes:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
Je peux prendre la date JS et en retourner l'année:
(let [d (js/Date.)] (.getFullYear d)) => 2018
Rich Hickey, le créateur de Clojure, nous a sévèrement limités. Nous n'avons vraiment rien d'autre, nous faisons donc tout par le biais de structures de données génériques. Par exemple, lorsque nous écrivons SQL, nous l'écrivons généralement avec une structure de données. Si vous regardez attentivement, vous verrez que ce n'est qu'une carte de hachage dans laquelle quelque chose est intégré. Ensuite, il y a une fonction qui traduit tout cela en une chaîne SQL:
{select [:*] :from [:users] :where [:= :id "user-1"]} => {:select [:*], :from [:users], :where [:= :id "user-1"]}
Nous écrivons également des routages avec une structure de données et des structures de données composées:
{"users" {:get {:handler :users-list}} :get {:handler :welcome-page}}
[:div.row [:div {:on-click #(.log js/console "Hello")} "User "]]
DB dans l'interface utilisateur
Nous avons donc discuté de Clojure. Mais j'ai mentionné plus tôt qu'une grande réussite dans le backend était la base de données. Si vous regardez ce qui se passe dans le frontend maintenant, nous verrons que les gars utilisent le même modèle - ils entrent dans la base de données dans l'interface utilisateur (dans une application d'une seule page).
Les bases de données sont introduites dans elm-architecture, dans le re-frame scripté par Clojure et même sous une forme limitée dans flux et redux (des plugins supplémentaires doivent être définis ici pour lancer des requêtes). L'architecture, le recadrage et le flux de l'orme ont été lancés à peu près au même moment et empruntés les uns aux autres. Nous écrivons sur re-frame. Ensuite, je vais parler un peu de son fonctionnement.

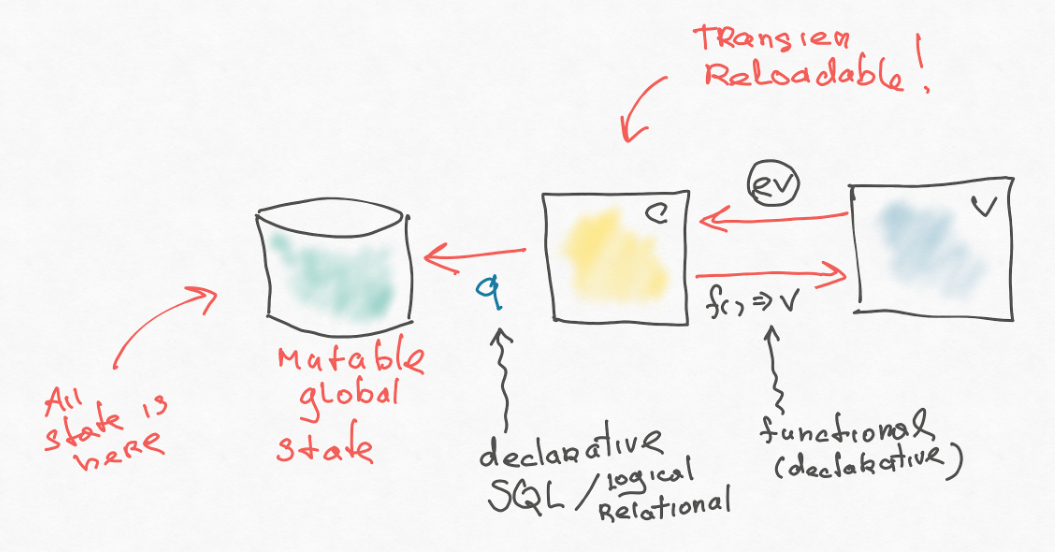
L'événement (c'est un peu comme redux) vole hors de la vue-chi, qui est capturée par un certain contrôleur. Le contrôleur que nous appelons gestionnaire d'événements. Le gestionnaire d'événements émet un effet, qui est également une personne interprétée par la structure de données.
Un type d'effet est la mise à jour de la base de données. Autrement dit, il prend la valeur de base de données actuelle et en renvoie une nouvelle. Nous avons également une chose telle que l'abonnement - un analogue des demandes sur le backend. Autrement dit, ce sont des requêtes réactives que nous pouvons lancer dans cette base de données. Ces demandes réactives, nous nous regroupons ensuite sur la vue. Dans le cas de réagir, nous semblons redessiner complètement, et si le résultat de cette demande a changé - c'est pratique.
React n'est présent à nos côtés que quelque part à la toute fin, et en général l'architecture n'y est en aucun cas liée. Cela ressemble à ceci:

Ici est ajouté ce qui manque, par exemple, dans redux-s.
Tout d'abord, nous séparons les effets. L'application frontale n'est pas autonome. Il a un certain backend - une sorte de «source de vrai». L'application doit constamment écrire quelque chose et lire quelque chose à partir de là. Pire encore, s'il a plusieurs backends vers lesquels il devrait aller. Dans la mise en œuvre la plus simple, cela pourrait être fait directement dans l'action creater - dans votre contrôleur, mais c'est mauvais. Par conséquent, les gars de re-frame introduisent un niveau supplémentaire d'indirection: une certaine structure de données sort du contrôleur, ce qui indique ce qui doit être fait. Et ce poste a son propre gestionnaire qui fait le sale boulot. Il s'agit d'une introduction très importante, dont nous discuterons un peu plus tard.
C'est également important (parfois ils l'oublient) - certains faits fondamentaux devraient être dans la base. Tout le reste peut être supprimé de la base de données - et les requêtes le font généralement, elles transforment les données - elles n'ajoutent pas de nouvelles informations, mais structurent correctement celles existantes. Nous avons besoin de cette requête. En redux, à mon avis, cela permet maintenant de resélectionner, et en recadrage nous l'avons sorti de la boîte (intégré).
Jetez un œil à notre schéma d'architecture. Nous avons reproduit un petit backend (dans le style du Web 2.0) avec une vue base, contrôleur,. La seule chose ajoutée est la réactivité. C'est très similaire à MVC, sauf que tout est au même endroit. Une fois que les premiers MVC pour chaque widget ont créé leur propre modèle, mais ici, tout est plié en une seule base. En principe, vous pouvez synchroniser avec le backend du contrôleur via l'effet, vous pouvez trouver un look plus générique pour que la base de données fonctionne comme un proxy pour le backend. Il existe même une sorte d'algorithme générique: vous écrivez dans votre base de données locale et elle se synchronise avec la principale.
Maintenant, dans la plupart des cas, la base est juste une sorte d'objet dans lequel nous écrivons quelque chose en redux. Mais en principe, on peut imaginer qu'il se développera plus loin en une base de données à part entière avec un langage de requête riche. Peut-être avec une sorte de synchronisation générique. Par exemple, il existe datomic - une base de données logique à trois magasins qui s'exécute directement dans le navigateur. Vous le ramassez et y mettez tout votre état. Datomic a un langage de requête assez riche, comparable en puissance à SQL, et même gagnant quelque part. Un autre exemple est Google a écrit lovefield. Tout ira quelque part là-bas.
Ensuite, je vais expliquer pourquoi nous avons besoin d'un abonnement réactif.
Nous obtenons maintenant la première perception naïve - nous avons obtenu l'utilisateur du backend, l'avons mis dans la base de données, puis nous devons le dessiner. Au moment du rendu, une certaine logique se produit, mais nous mélangeons cela au rendu, à la vue. Si nous commençons immédiatement à rendre cet utilisateur, nous obtenons un gros morceau délicat qui fait quelque chose avec le DOM virtuel et autre chose. Et il est mélangé avec le modèle logique de notre point de vue.
Un concept très important qui doit être compris: en raison de la complexité de l'interface utilisateur, il doit également être modélisé. Il est nécessaire de séparer la façon dont il est dessiné (tel qu'il apparaît) de son modèle logique. Le modèle logique sera alors plus stable. Vous ne pouvez pas le surcharger avec la dépendance à un cadre spécifique - Angular, React ou VueJS. Un modèle est le citoyen de première classe habituel dans votre runtime. Idéalement, s'il ne s'agit que de données et d'un ensemble de fonctions au-dessus.

Autrement dit, à partir du modèle backend (objet), nous pouvons obtenir un modèle de vue dans lequel, sans utiliser encore de rendu, nous pouvons recréer le modèle logique. S'il existe une sorte de menu ou quelque chose de similaire - tout cela peut être fait dans le modèle de vue.
Pourquoi?
Pourquoi faisons-nous tous cela?
Je n'ai vu de bons tests d'interface utilisateur que lorsqu'il y a une équipe de 10 testeurs.
Habituellement, il n'y a pas de test d'interface utilisateur. Par conséquent, nous essayons de pousser cette logique hors des composants du modèle de vue. L'absence de tests est un très mauvais signe, indiquant que quelque chose ne va pas là-bas, d'une manière ou d'une autre, tout est mal structuré.
Pourquoi l'interface utilisateur est-elle difficile à tester? Pourquoi les gars du backend ont-ils appris à tester leur code, ont fourni une couverture énorme et cela aide vraiment à vivre avec le code du backend? Pourquoi l'interface utilisateur est-elle incorrecte? Très probablement, nous faisons quelque chose de mal. Et tout ce que j'ai décrit ci-dessus nous a réellement orientés vers la testabilité.
Comment faisons-nous les tests?
Si vous regardez attentivement, la partie de notre architecture, contenant le contrôleur, l'abonnement et la base de données, n'est même pas liée à JS. Autrement dit, il s'agit d'une sorte de modèle qui fonctionne simplement sur les structures de données: nous les ajoutons quelque part, transformons en quelque sorte, supprimons la requête. Grâce aux effets, nous sommes déconnectés de l'interaction avec le monde extérieur. Et cette pièce est entièrement portable. Il peut être écrit dans le soi-disant cljc - c'est un sous-ensemble commun entre Clojure Script et Clojure, qui se comporte de la même manière ici et là. Nous pouvons simplement couper ce morceau du frontend et le mettre dans la JVM - où le backend vit. Ensuite, nous pouvons écrire un autre effet dans la JVM, qui atteint directement le point final - il tire le routeur sans aucune conversion de chaîne http, analyse, etc.
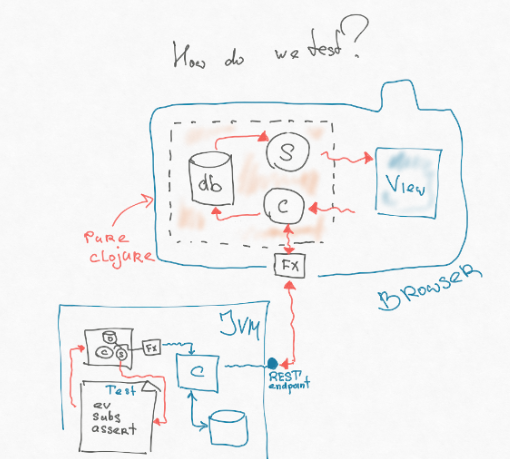
En conséquence, nous pouvons écrire un test très simple - le même test fonctionnel intégral que les gars écrivent sur le backend. Nous lançons un certain événement, il lance un effet qui frappe directement le point final sur le backend. Il nous renvoie quelque chose, le met dans la base de données, calcule l'abonnement, et dans l'abonnement se trouve une vue logique (nous y mettons la logique de l'interface utilisateur au maximum). Nous affirmons ce point de vue.
Ainsi, nous pouvons tester 80% du code sur le backend, tandis que tous les outils de développement du backend sont à notre disposition. À l'aide d'appareils fixes ou de certaines usines, nous pouvons recréer une situation spécifique dans la base de données.
Par exemple, nous avons un nouveau patient ou quelque chose n'est pas payé, etc. Nous pouvons passer par un tas de combinaisons possibles.
Ainsi, nous pouvons traiter le deuxième problème - avec un système distribué. Parce que le contrat entre les systèmes est précisément le principal point sensible, car ce sont deux temps d'exécution différents, deux systèmes différents: le backend a changé quelque chose et quelque chose s'est cassé sur notre frontend (vous ne pouvez pas être sûr que cela ne se produira pas).
Démonstration
Voici à quoi cela ressemble dans la pratique. C'est un assistant backend qui a nettoyé la base et y a écrit un petit monde:
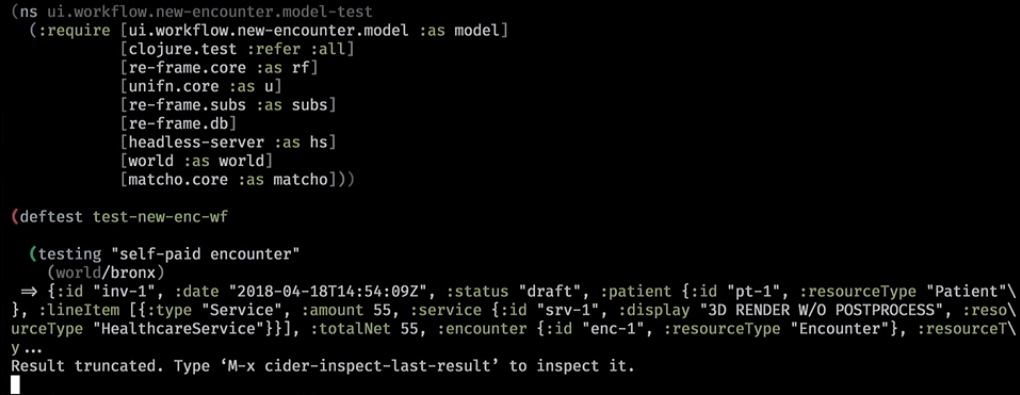
Ensuite, nous jetons l'abonnement:

Habituellement, l'URL définit complètement la page et un événement est déclenché - vous êtes maintenant sur telle ou telle page avec un ensemble de paramètres. Ici, nous sommes entrés dans un nouveau flux de travail et notre abonnement est revenu:

Derrière la scène, il est allé à la base, a obtenu quelque chose, l'a mis dans notre base d'interface utilisateur. L'abonnement a fonctionné et en a déduit le modèle de vue logique.
Nous l'avons initialisé. Et voici notre modèle logique:

Même sans regarder l'interface utilisateur, nous pouvons deviner ce qui sera dessiné selon ce modèle: un avertissement viendra, des informations sur le patient, des rencontres et un ensemble de liens se trouveront (c'est un widget de workflow qui dirige la réception à certaines étapes lorsque le patient arrive).
Ici, nous arrivons à un monde plus complexe. Ils ont effectué certains paiements et ont également testé après l'initialisation:
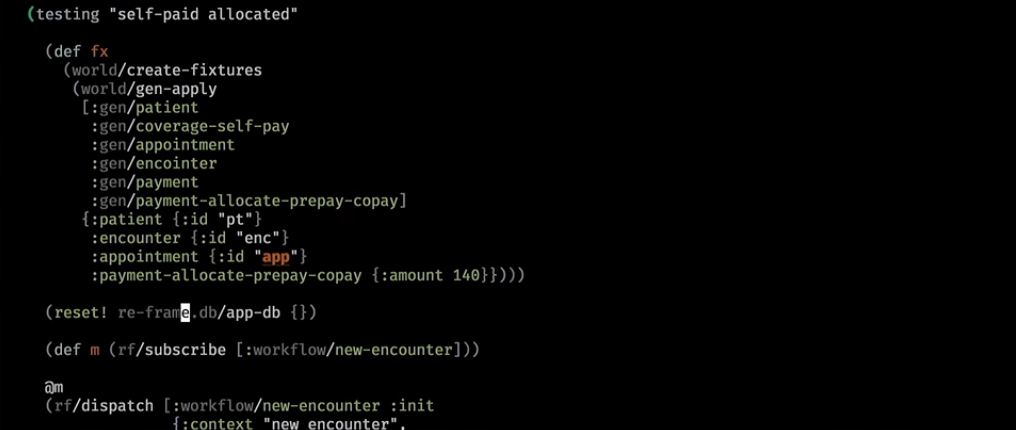
S'il a déjà payé la visite, il le verra dans l'interface utilisateur:

Exécutez les tests, définis sur CI. La synchronisation entre le backend et le frontend sera garantie par des tests, et pas honnêtement.
Retour au backend?
Nous avons introduit les tests il y a six mois et nous avons vraiment aimé. Le problème de la logique floue demeure. Plus une application métier est intelligente, plus elle a besoin d'informations pour certaines étapes. Si vous essayez d'exécuter une sorte de flux de travail à partir du monde réel, il y aura des dépendances sur tout: pour chaque interface utilisateur, vous devez obtenir quelque chose de différentes parties de la base de données sur le backend. Si nous écrivons des systèmes comptables, cela ne peut être évité. En conséquence, comme je l'ai dit, toute logique est tachée.
Avec l'aide de tels tests, nous pouvons créer l'illusion au moins en temps de développement - au moment du développement - que nous, comme dans l'ancien temps du Web 2.0, sommes assis sur le serveur en une seule exécution et que tout est confortable.
Une autre idée folle est venue (elle n'a pas encore été mise en œuvre). Pourquoi ne pas abaisser cette partie au backend? Pourquoi ne pas vous éloigner complètement de l'application distribuée maintenant? Que cet abonnement et notre modèle de vue soient générés sur le backend? Là, la base est disponible, tout est synchrone. Tout est simple et clair.
Le premier avantage que je vois dans cela est que nous aurons le contrôle en un seul endroit. Nous simplifions tout simplement tout de suite par rapport à notre application distribuée. Les tests deviennent simples, les doubles validations disparaissent. Le monde à la mode des systèmes multi-utilisateurs interactifs s'ouvre (si deux utilisateurs vont sur le même formulaire, nous leur en parlons; ils peuvent le modifier en même temps).
Une caractéristique intéressante apparaît: en allant au backend et à la perspective de la session, nous pouvons comprendre qui est actuellement dans le système et ce qu'il fait. C'est un peu comme le développement de jeu, où les serveurs fonctionnent comme ça. Là, le monde vit sur le serveur et le front-end ne s'affiche que. En conséquence, nous pouvons obtenir un certain client léger.
D'un autre côté, cela crée un défi. Nous devrons avoir un serveur d'état sur lequel ces sessions vivent. Si nous avons plusieurs serveurs d'applications, il faudra en quelque sorte équilibrer correctement la charge ou répliquer la session. Cependant, on soupçonne que ce problème est inférieur au nombre d'avantages que nous obtenons.
Par conséquent, je reviens au slogan principal: il existe de nombreux types d'applications qui peuvent être écrites non distribuées, pour en éliminer la complexité. Et vous pouvez obtenir une augmentation multiple de l'efficacité si vous révisez à nouveau les postulats de base sur lesquels nous nous sommes appuyés dans le développement.
Si vous avez aimé le rapport, faites attention: du 24 au 25 novembre, un nouveau HolyJS se tiendra à Moscou, et il y aura également beaucoup de choses intéressantes. Des informations déjà connues sur le programme sont sur le site , et des billets peuvent y être achetés.