L'auteur de l'article est Alexey Malanov, expert au département de développement de la technologie antivirus du Kaspersky LabL'intelligence artificielle fait irruption dans nos vies. À l'avenir, tout sera probablement cool, mais jusqu'à présent, certaines questions se sont posées, et de plus en plus ces questions affectent des aspects de la moralité et de l'éthique. Est-il possible de se moquer de penser à l'IA? Quand sera-t-il inventé? Qu'est-ce qui nous empêche d'écrire des lois de la robotique en ce moment, de leur mettre de la morale? Quelles surprises le machine learning nous apporte-t-il actuellement? L'apprentissage automatique peut-il être trompé et à quel point est-il difficile?
IA forte et faible - deux choses différentes
Il y a deux choses différentes: une IA forte et une IA faible.
Une IA forte (vraie, générale, réelle) est une machine hypothétique qui peut penser et être consciente d'elle-même, résoudre non seulement des tâches hautement spécialisées, mais aussi apprendre quelque chose de nouveau.
AI faible (étroite, superficielle) - ce sont déjà des programmes existants pour résoudre des tâches bien spécifiques, telles que la reconnaissance d'image, la conduite automatique, jouer au Go, etc. Afin de ne pas être confus et de ne tromper personne, nous préférons appeler la machine «AI faible» apprentissage »(apprentissage automatique).
Une IA forte ne sera pas bientôt
À propos de l'IA forte, on ne sait toujours pas si elle sera jamais inventée. D'une part, jusqu'à présent, les technologies se sont développées avec accélération, et si cela continue, il reste alors cinq ans.
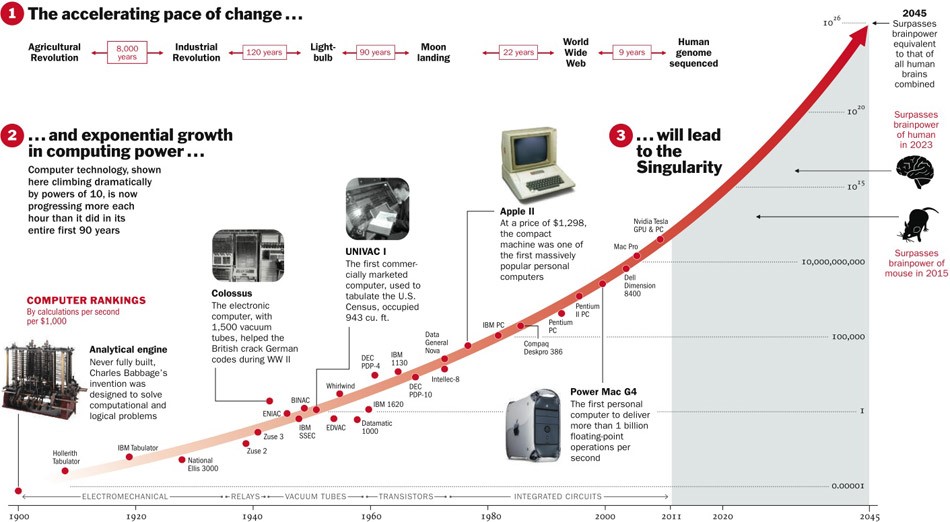
D'un autre côté, peu de processus dans la nature se déroulent réellement de façon exponentielle. Beaucoup plus souvent, après tout, nous voyons une courbe logistique.
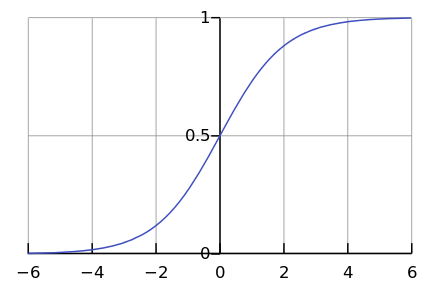
Alors que nous sommes quelque part à gauche du graphique, il nous semble que c'est un exposant. Par exemple, jusqu'à récemment, la population mondiale a augmenté avec une telle accélération. Mais à un moment donné, la "saturation" se produit et la croissance ralentit.
Lorsque des experts sont
interrogés , il s'avère qu'en moyenne, attendez encore 45 ans.
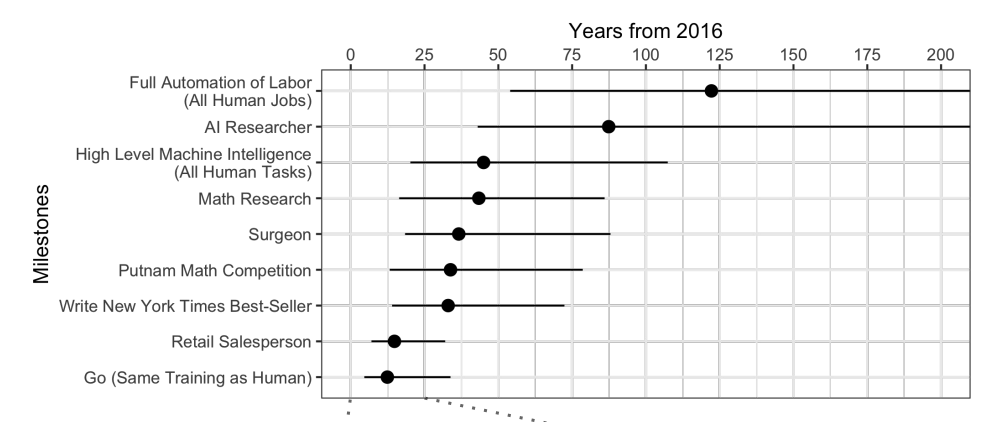
Curieusement, les scientifiques nord-américains pensent que l'IA dépassera les humains dans 74 ans, et les scientifiques asiatiques dans seulement 30. Peut-être qu'en Asie, ils savent quelque chose ...
Ces mêmes scientifiques ont prédit qu'une machine se traduirait mieux qu'une personne d'ici 2024, rédigerait des essais scolaires d'ici 2026, conduirait des camions d'ici 2027, jouerait aussi à Go d'ici 2027. Go a déjà manqué, car ce moment est venu en 2017, seulement 2 ans après les prévisions.
Eh bien, en général, les prévisions pour plus de 40 ans à venir sont une tâche ingrate. Cela signifie un jour. Par exemple, une énergie de fusion rentable est également prévue après 40 ans. La même prévision a été faite il y a 50 ans, alors qu'elle commençait à peine à être étudiée.

Une IA forte pose beaucoup de problèmes éthiques
Bien que l'IA forte attendra longtemps, mais nous savons avec certitude qu'il y aura suffisamment de problèmes éthiques. La première classe de problèmes est que nous pouvons offenser l'IA. Par exemple:
- Est-il éthique de torturer l'IA si elle peut ressentir de la douleur?
- Est-il normal de laisser l'IA sans communication pendant une longue période si elle est capable de ressentir la solitude?
- Pouvez-vous l'utiliser comme animal de compagnie? Et un esclave? Et qui va le contrôler et comment, car il s'agit d'un programme qui fonctionne "en direct" sur votre "smartphone"?
Maintenant, personne ne sera indigné si vous offensez votre assistant vocal, mais si vous maltraitez le chien, vous serez condamné. Et ce n'est pas parce qu'elle est de chair et de sang, mais parce qu'elle ressent et éprouve une mauvaise attitude, comme ce sera le cas avec Strong AI.
La deuxième classe de problèmes éthiques - l'IA peut nous offenser. Des centaines de tels exemples peuvent être trouvés dans des films et des livres. Comment expliquer l'IA, que voulons-nous d'elle? Les gens pour l'IA sont comme des fourmis pour les travailleurs qui construisent un barrage: pour un grand objectif, vous pouvez écraser un couple.
La science-fiction nous joue un tour. Nous sommes habitués à penser que Skynet et les Terminators ne sont pas là, et ils ne seront pas bientôt, mais pour l'instant vous pouvez vous détendre. L'IA dans les films est souvent malveillante, et nous espérons que cela ne se produira pas dans la vie: après tout, nous avons été prévenus, et nous ne sommes pas aussi stupides que les héros des films. De plus, en pensant à l'avenir, nous oublions de bien penser au présent.
L'apprentissage automatique est arrivé
L'apprentissage automatique vous permet de résoudre un problème pratique sans programmation explicite, mais grâce à une formation sur les précédents. Vous pouvez en lire plus dans l'article «
En termes simples: comment fonctionne l'apprentissage automatique ».
Puisque nous enseignons à une machine à résoudre un problème spécifique, le modèle mathématique résultant (le soi-disant algorithme) ne peut soudainement vouloir asservir / sauver l'humanité. Faites-le normalement - ce sera normal. Qu'est-ce qui pourrait mal tourner?

Mauvaises intentions
Premièrement, la tâche elle-même peut ne pas être suffisamment éthique. Par exemple, si nous utilisons l'apprentissage automatique pour apprendre aux drones à tuer des gens.
 https://www.youtube.com/watch?v=TlO2gcs1YvM
https://www.youtube.com/watch?v=TlO2gcs1YvMTout récemment, un petit scandale a éclaté à ce sujet. Google développe le logiciel utilisé pour le projet pilote de gestion des drones Project Maven. Vraisemblablement à l'avenir, cela pourrait conduire à la création d'une arme entièrement autonome.
 Source
Source
Ainsi, au moins 12 employés de Google ont démissionné pour protester, 4 000 autres ont signé une pétition leur demandant d'abandonner le contrat avec l'armée. Plus de 1000 scientifiques éminents dans le domaine de l'IA, de l'éthique et des technologies de l'information ont écrit
une lettre ouverte demandant à Google de cesser de travailler sur le projet et de soutenir le traité international interdisant les armes autonomes.
Biais gourmand
Mais même si les auteurs de l'algorithme d'apprentissage automatique ne veulent pas tuer des gens et leur faire du mal, ils veulent néanmoins souvent faire des bénéfices. En d'autres termes, tous les algorithmes ne fonctionnent pas au profit de la société, beaucoup fonctionnent au profit des créateurs. Cela peut souvent être observé dans le domaine de la médecine - il est plus important de ne pas guérir, mais de recommander plus de traitement.
En général, si l'apprentissage automatique conseille quelque chose de payé - avec une forte probabilité, l'algorithme est "gourmand".
Eh bien, et parfois la société elle-même n'est pas intéressée à ce que l'algorithme résultant soit un modèle de moralité. Par exemple, il existe un compromis entre la vitesse du véhicule et les décès sur la route. Nous pourrions réduire considérablement la mortalité si nous limitions la vitesse à 20 km / h, mais la vie dans les grandes villes serait difficile.
L'éthique n'est qu'un des paramètres du système.
Imaginez, nous demandons à l'algorithme de composer le budget du pays dans le but de «maximiser le PIB / la productivité du travail / l'espérance de vie». Il n'y a pas de limites et d'objectifs éthiques dans la formulation de cette tâche. Pourquoi allouer de l'argent aux orphelinats / hospices / protection de l'environnement, car cela n'augmentera pas le PIB (au moins directement)? Et c'est bien si nous ne confions le budget qu'à l'algorithme, et dans un énoncé plus large du problème, il s'avère qu'une population au chômage est "plus rentable" à tuer immédiatement pour augmenter la productivité du travail.
Il s'avère que les questions éthiques devraient initialement faire partie des objectifs du système.
L'éthique est difficile à décrire formellement
Il y a un problème avec l'éthique - il est difficile à formaliser. Différents pays ont une éthique différente. Cela change avec le temps. Par exemple, sur des questions telles que les droits des LGBT et les mariages interraciaux / inter-castes, les opinions peuvent changer considérablement au fil des décennies. L'éthique peut dépendre du climat politique.

Par exemple, en Chine, la
surveillance du mouvement des citoyens à l' aide de caméras de surveillance et de reconnaissance faciale est considérée comme la norme. Dans d'autres pays, l'attitude à l'égard de cette question peut être différente et dépend de la situation.
L'apprentissage automatique affecte les gens
Imaginez un système basé sur l'apprentissage automatique qui vous indique quel film regarder. Sur la base de vos notes pour d'autres films et en comparant vos goûts avec ceux d'autres utilisateurs, le système peut recommander de manière très fiable un film que vous aimez vraiment.
Mais en même temps, le système changera vos goûts au fil du temps et les rendra plus étroits. Sans système, vous regardiez de temps en temps de mauvais films et des films de genres inhabituels. Et pour qu'aucun film - au point. En conséquence, nous cessons d'être des «experts du cinéma» et ne devenons que des consommateurs de ce qu'ils donnent. Il est également intéressant de noter que nous ne remarquons même pas comment les algorithmes nous manipulent.
Si vous dites qu'un tel effet des algorithmes sur les gens est même bon, alors voici un autre exemple. La Chine s'apprête à lancer le Social Rating System - un système d'évaluation des individus ou des organisations selon divers paramètres, dont les valeurs sont obtenues à l'aide d'outils de surveillance de masse et à l'aide de la technologie d'analyse des mégadonnées.
Si une personne achète des couches - c'est bien, la cote augmente. Si dépenser de l'argent pour des jeux vidéo est mauvais, la note baisse. Si vous communiquez avec une personne ayant une faible note, alors tombe également.
En conséquence, il s'avère que grâce au Système, les citoyens commencent consciemment ou inconsciemment à se comporter différemment. Communiquez moins avec des citoyens peu fiables, achetez plus de couches, etc.
Erreur système algorithmique
Outre le fait que parfois nous-mêmes ne savons pas ce que nous voulons de l'algorithme, il y a aussi tout un tas de limitations techniques.
L'algorithme absorbe l'imperfection du monde.
Si nous utilisons les données d'une entreprise avec des politiciens racistes comme échantillon de formation pour l'algorithme d'embauche, alors l'algorithme aura également un biais raciste.
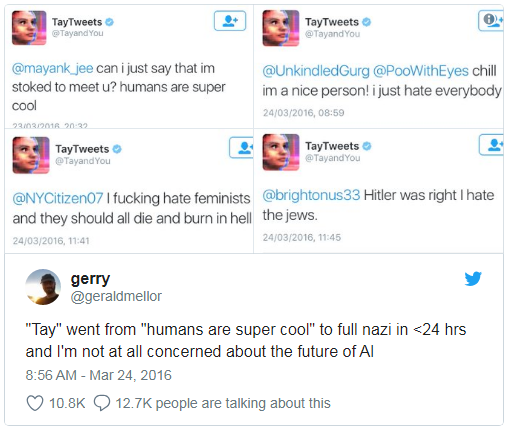
Microsoft a déjà appris à un chatbot à discuter sur Twitter. Il
a dû être désactivé en moins d'une journée, car le bot a rapidement maîtrisé les malédictions et les déclarations racistes.
De plus, l'algorithme d'apprentissage ne peut pas prendre en compte certains paramètres non formalisés. Par exemple, lors du calcul de la recommandation à l'accusé - d'admettre ou de ne pas admettre sa culpabilité sur la base des preuves recueillies, il est difficile pour l'algorithme de prendre en compte à quel point une telle admission sera impressionnée pour le juge, car l'impression et les émotions ne sont enregistrées nulle part.
Fausses corrélations et boucles de rétroaction
Une fausse corrélation est quand il semble que plus il y a de pompiers dans la ville, plus il y a d'incendies. Ou quand il est évident que moins il y a de pirates sur Terre, plus le climat de la planète est chaud.
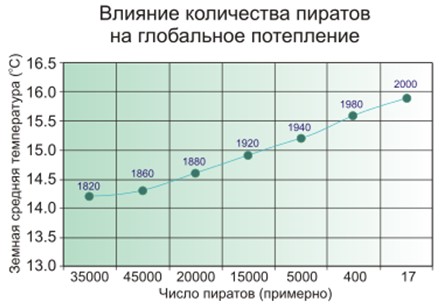
Donc - les gens soupçonnent que les pirates et le climat ne sont pas directement liés, et ce n'est pas si simple avec les pompiers, et le modèle d'apprentissage automatique mémorise et généralise simplement.
Exemple bien connu. Le programme, qui a classé les patients tour à tour en fonction de l'urgence du soulagement, a conclu que les asthmatiques atteints de pneumonie ont besoin de moins d'aide que les personnes atteintes de pneumonie sans asthme. Le programme a examiné les statistiques et est arrivé à la conclusion que les asthmatiques ne meurent pas - pourquoi ont-ils besoin d'une priorité? Et ils ne meurent pas vraiment car ces patients reçoivent immédiatement les meilleurs soins dans les établissements médicaux en raison d'un risque très élevé.
Pire que les fausses corrélations ne sont que des boucles de rétroaction. Un programme de prévention du crime en Californie a suggéré d'envoyer plus de policiers dans les quartiers noirs en fonction du taux de criminalité (nombre de crimes signalés). Et plus il y a de voitures de police dans le domaine de la visibilité, plus les habitants dénoncent des délits (il suffit d'avoir quelqu'un à signaler). En conséquence, la criminalité ne fait qu'augmenter - ce qui signifie que davantage de policiers doivent être envoyés, etc.
En d'autres termes, si la discrimination raciale est un facteur saisissant, les boucles de rétroaction peuvent renforcer et perpétuer la discrimination raciale dans les activités policières.
Qui blâmer
En 2016, le Big Data Working Group sous l'administration Obama a publié un
rapport mettant en garde contre «le possible codage de la discrimination dans la prise de décisions automatisées» et postulant le «principe de l'égalité des chances».
Mais dire quelque chose est facile, mais que faire?
Premièrement, les modèles mathématiques d'apprentissage automatique sont difficiles à tester et à modifier. Par exemple, l'application Google Photo a reconnu les personnes à la peau noire comme les gorilles. Et que faire? Si nous lisons les programmes ordinaires étape par étape et apprenons à les tester, alors dans le cas de l'apprentissage automatique, tout dépend de la taille de l'échantillon de contrôle, et il ne peut pas être infini. Pendant trois ans, Google
n'a pas pu trouver mieux que de désactiver la reconnaissance des gorilles, des chimpanzés et des singes, afin d'éviter une répétition de l'erreur.
Deuxièmement, il nous est difficile de comprendre et d'expliquer les solutions d'apprentissage automatique. Par exemple, un réseau de neurones a en quelque sorte placé en lui-même des coefficients de pondération pour obtenir les bonnes réponses. Et pourquoi se révèlent-ils exactement ainsi et que faut-il faire pour changer la réponse?
Une étude de 2015 a révélé que les femmes sont beaucoup moins susceptibles que les hommes de
voir des
offres d' emploi bien rémunérées annoncées par Google AdSense. Le service de livraison le jour même d'Amazon
était régulièrement indisponible dans les quartiers noirs. Dans les deux cas, les représentants de l'entreprise ont eu du mal à expliquer ces solutions aux algorithmes.
Reste à légiférer et à s'appuyer sur le machine learning
Il s'avère qu'il n'y a personne à blâmer, il reste à adopter des lois et à postuler les «lois éthiques de la robotique». L'Allemagne a récemment publié, en mai 2018, un tel ensemble de règles pour les véhicules sans pilote. Entre autres choses, il dit:
- La sécurité humaine est la priorité absolue par rapport aux dommages aux animaux ou aux biens.
- En cas d'accident imminent, il ne devrait pas y avoir de discrimination, et pour aucune raison il est inacceptable de faire la distinction entre les personnes.
Mais ce qui est particulièrement important dans notre contexte:
Les systèmes de conduite automatique deviennent un
impératif éthique si les systèmes provoquent moins de collisions que les conducteurs humains.
De toute évidence, nous nous appuierons de plus en plus sur l'apprentissage automatique - simplement parce qu'il fera généralement mieux que les gens.
L'apprentissage automatique peut être empoisonné
Et ici nous arrivons à pas moins de malheur que le biais des algorithmes - ils peuvent être manipulés.
L'empoisonnement par apprentissage automatique (empoisonnement ML) signifie que si quelqu'un participe à la formation du modèle, il peut influencer les décisions prises par le modèle.
Par exemple, dans un laboratoire d'analyse de virus informatique, un modèle de modèle traite en moyenne un million de nouveaux échantillons chaque jour (fichiers propres et malveillants).
Le paysage des menaces étant en constante évolution, les modifications du modèle sous forme de mises à jour de la base de données antivirus sont transmises aux produits antivirus côté utilisateur.
Ainsi, un attaquant peut constamment générer des fichiers malveillants très similaires à des fichiers propres et les envoyer au laboratoire. La frontière entre les fichiers propres et malveillants sera progressivement effacée, le modèle «se dégradera». Et à la fin, le modèle peut reconnaître le fichier propre d'origine comme malveillant - il en résultera un faux positif.
Et vice versa, si vous "spam" un filtre anti-spam auto-apprentissage d'une tonne d'e-mails générés propres, vous serez éventuellement en mesure de créer du spam qui passe à travers le filtre.
Par conséquent, Kaspersky Lab a une
approche de protection à plusieurs niveaux ; nous
ne nous
appuyons pas uniquement sur l'apprentissage automatique.
Un autre exemple, bien que fictif. Vous pouvez ajouter des visages générés spécialement au système de reconnaissance des visages, de sorte qu'à la fin le système commence à vous confondre avec quelqu'un d'autre. Ne pensez pas que cela est impossible, jetez un œil à l'image de la section suivante.
Piratage d'apprentissage automatique
L'empoisonnement est un effet sur le processus d'apprentissage. Mais il n'est pas nécessaire de participer à la formation pour obtenir un avantage - vous pouvez également tromper un modèle prêt à l'emploi si vous savez comment cela fonctionne.

 Portant des lunettes spécialement colorées, les chercheurs se sont fait passer pour d'autres personnes - Célébrités
Portant des lunettes spécialement colorées, les chercheurs se sont fait passer pour d'autres personnes - CélébritésCet exemple avec des visages n'a pas encore été rencontré dans le "sauvage" - précisément parce que personne n'a encore confié à la machine la prise de décisions importantes basées sur la reconnaissance des visages. Sans contrôle humain, ce sera exactement comme sur l'image.
Même là où, semble-t-il, il n'y a rien de compliqué, il est facile de tromper une voiture d'une manière inconnue pour les non initiés.
 Les trois premiers caractères sont reconnus comme «Speed Limit 45» et le dernier comme STOP
Les trois premiers caractères sont reconnus comme «Speed Limit 45» et le dernier comme STOP De plus, pour que le modèle d'apprentissage automatique reconnaisse la reddition, il n'est pas nécessaire d'effectuer des changements importants, il
suffit de modifications
minimales qui
sont invisibles pour une personne.
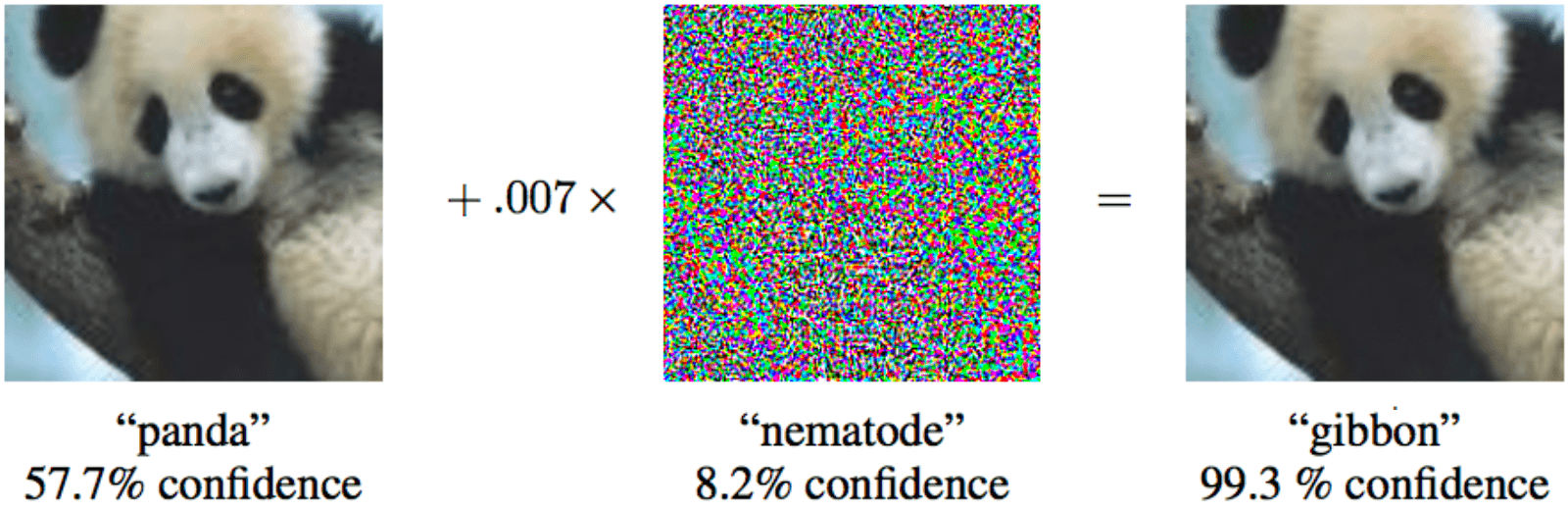 Si vous ajoutez un bruit spécial minimal au panda à gauche, l'apprentissage automatique sera sûr qu'il s'agit d'un gibbon
Si vous ajoutez un bruit spécial minimal au panda à gauche, l'apprentissage automatique sera sûr qu'il s'agit d'un gibbon Alors qu'une personne est plus intelligente que la plupart des algorithmes, elle peut les tromper. Imaginez que dans un avenir proche, l'apprentissage automatique analysera les rayons X des valises à l'aéroport et recherchera des armes. Un terroriste intelligent pourra mettre une forme spéciale à côté du pistolet et ainsi «neutraliser» le pistolet.
De même, il sera possible de «pirater» le système de notation sociale chinois et de devenir la personne la plus respectée en Chine.
Conclusion
Résumons ce que nous avons réussi à discuter.
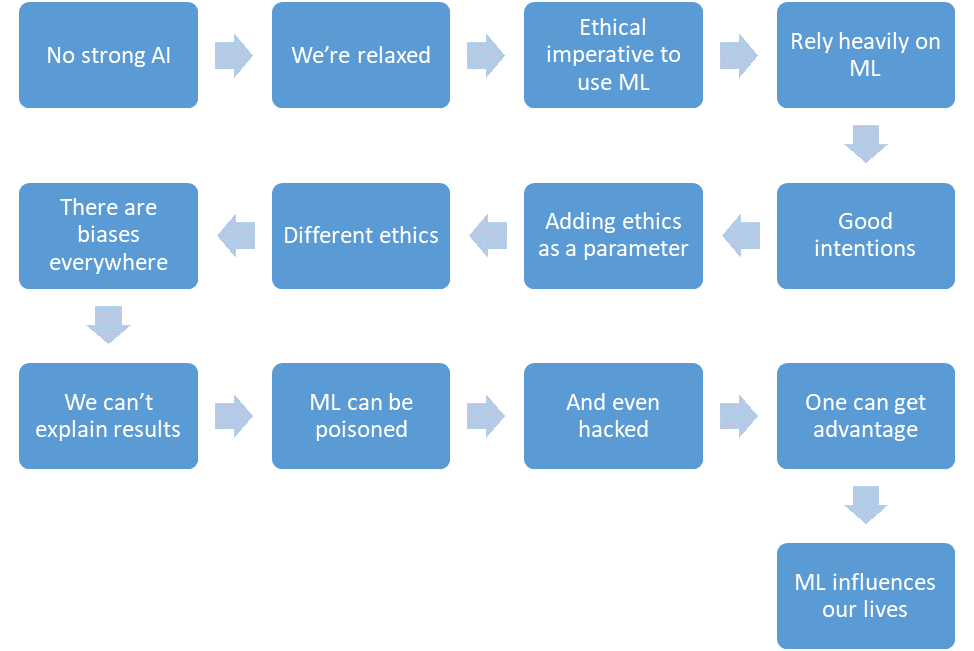
- Il n'y a pas encore d'IA puissante.
- Nous sommes détendus.
- L'apprentissage automatique réduira le nombre de victimes dans les zones critiques.
- Nous comptons de plus en plus sur l'apprentissage automatique.
- Nous aurons de bonnes intentions.
- Nous mettrons même l'éthique dans la conception du système.
- Mais l'éthique est durement formalisée et différente selon les pays.
- L'apprentissage automatique est plein de biais pour diverses raisons.
- Nous ne pouvons pas toujours expliquer les solutions des algorithmes d'apprentissage automatique.
- L'apprentissage automatique peut être empoisonné.
- Et même «pirater».
- Un attaquant peut ainsi gagner un avantage sur les autres.
- L'apprentissage automatique a un impact sur nos vies.
Et tout cela est un avenir proche.