En fait, l'article est consacré au développement d'un programme de reconditionnement de vidéo DVR d'un conteneur à un autre, si cela peut être appelé conversion. Bien que, toute ma vie, j'ai pensé que le convertisseur est engagé dans la conversion (transcodage) du format vidéo. Cet article est la deuxième partie de ma dernière publication, où j'ai parlé en détail de l'accès à tous les enregistrements vidéo du DVR. Mais au tout début de la publication, je me suis fixé une autre tâche: étudier l'algorithme par lequel fonctionne le programme standard 264-avi repacker et créer le même programme qui effectuerait les mêmes opérations, mais pas sur un, mais sur tout un groupe de fichiers, d'ailleurs "Un clic".
Je vais expliquer une fois de plus l'essence de toutes choses dans un langage simple.
L'utilisateur dispose d'un enregistreur vidéo, par exemple, le modèle populaire QCM-08DL. Il a besoin d'une vidéo pour une date et une heure spécifiques. Il peut le retirer sur une clé USB ou via une interface Web d'un DVR vers un ordinateur. Le fichier vidéo extrait (extension .264) ne s'ouvrira que dans le programme du lecteur fourni avec le DVR. Le joueur est très mal à l'aise. Vous pouvez toujours l'ouvrir dans le lecteur VLC en définissant le mode RAW H264 dans les paramètres de démultiplexage (paramètres pour les utilisateurs avancés). Mais en même temps, apparemment, des blocs de flux audio, qui sont interprétés comme de la vidéo, et il n'y a pas de son, interfèrent avec la lecture normale. Et pour ouvrir la vidéo dans n'importe quel lecteur, le fichier .264 doit d'abord être converti en un format populaire, par exemple, avi. Un programme de conversion est également inclus avec le DVR. Mais elle est également très mal à l'aise. En ce qui concerne un ou plusieurs fichiers, il n'y a aucun problème. Cependant, lorsque la tâche consiste à accéder à toutes les vidéos sur le disque dur, et plus encore à les convertir toutes au format populaire, les outils standard ne conviennent pratiquement pas.

Le problème d'accès à tous les fichiers a été résolu. C'était le sujet de la dernière publication. Nous procédons à la résolution du deuxième problème. On m'a déjà donné des "conseils pratiques": il suffit de renommer l'extension de "264" en "avi" dans le nom du fichier, et tout ira mal, disent-ils, il n'y a rien à déranger. Mais c'est l'erreur la plus courante de tout utilisateur ordinaire, qui, en règle générale, ne comprend pas les problèmes pertinents.
Dans une publication précédente, j'ai déjà brièvement écrit sur la structure du fichier source .264. Permettez-moi de vous le rappeler.
Les informations principales concernant les flux audio et vidéo proviennent d'un décalage de 65 536 octets. Les blocs de flux vidéo commencent par un en-tête de 8 octets «01dcH264» (également trouvé «00dcH264»). Les 4 octets suivants décrivent la taille du bloc actuel du flux vidéo en octets. Après 4 octets de zéros (00 00 00 00), le bloc de flux vidéo commence lui-même. Les blocs de flux audio ont le titre «03wb» (bien que, selon mes observations, le premier caractère du titre dans certains cas était éventuellement «0»). Après - 12 octets d'informations que je n'ai pas encore compris. Et en commençant par le 17e octet - un flux audio d'une longueur fixe de 160 octets. Il n'y a pas de balises à la fin du fichier.Je commenterai ce qui précède. Tout ce qui peut atteindre un décalage de 65 536 octets s'est avéré non résolu et inutile. D'un décalage de 65536 octets au premier en-tête du flux, il y a un petit écart, dont le contenu n'est pas non plus résolu, et, de plus, comme je l'ai vérifié, il n'apparaît pas dans le fichier avi de sortie après conversion par un programme normal.
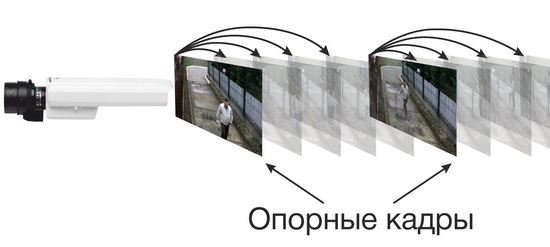
Chaque bloc du flux vidéo représente une image. Le premier caractère de l'en-tête des blocs du flux vidéo est éventuellement «0». Je n'ai pas compris son but, car, comme je l'ai découvert, ce n'est pas la clé pour résoudre la tâche. Le deuxième caractère de l'en-tête du flux vidéo peut être «1» ou «0». Dans le second cas, le contenu du bloc de flux vidéo est ce que l'on appelle la trame de référence. Et dans le premier cas, le contenu du bloc de flux vidéo est une trame compressée codée, qui dépend de la trame de référence. La taille du contenu de la trame de référence est significativement plus grande que la taille du contenu de la sous-trame compressée. La période de répétition de l'image de référence dépend très probablement des paramètres de taux de compression dans le DVR. Mais dans mon cas, la période de répétition était de 1 image / sec.
Le programme régulier de reconditionnement des vidéos du conteneur «264» vers le conteneur «avi» a donné des résultats différents concernant la fréquence d'images. Dans le cas de vidéos enregistrées en mode haute résolution (704 * 576), la fréquence d'images était de 20 images / s. Et dans le cas de basse résolution (352 * 288) - 25 images / sec. Ces informations sont fournies par l'utilitaire MediaInfo. Elles indiquent également que la taille de la vidéo est la même dans tous les cas: 720 * 576, et la taille du flux vidéo (cet utilitaire rapporte) est 704 * 576 ou 352 * 288. La plupart des lecteurs sont déployés spécifiquement pour la taille du flux vidéo. Cependant, j'ai rencontré un joueur qui n'a pas affiché correctement le mode demi-écran lors de la lecture d'un fichier 352 * 288. Je voulais corriger cette faille mineure dans le reconditionneur à temps plein en regardant les octets du contenu du flux vidéo et en extrayant des informations sur la taille de l'image à partir de là. Mais pressé, je ne pouvais pas faire ça. Ce qui précède est illustré dans la figure ci-dessous.

Maintenant sur la fréquence d'images. Comme je l'ai découvert, le reconditionneur normal n'accède à aucun champ d'en-tête du conteneur «264». Il juge la fréquence d'images en calculant le rapport du nombre de blocs vidéo et de flux audio. Et cette valeur dans le calcul n'est même pas arrondie à la valeur entière la plus proche, comme le montre la figure ci-dessus (encerclée en vert). Comme je l'ai découvert, le nombre de blocs de flux audio par unité de temps est toujours et partout (dans n'importe quel fichier) fixe, à savoir 25 blocs par seconde. Si vous examinez le fichier vidéo avec une fréquence de 20 images / sec., Alors l'image de référence (bloc) se produit toutes les 19 images compressées, et dans le cas de 25 images / sec. - toutes les 24 images compressées.
Nous continuons à étudier la structure de l'en-tête du flux vidéo. Nous avons compris les huit premiers octets: c'est l'étiquette de la trame de référence ou compressée plus le mot-clé "H264". Les quatre octets suivants décrivent, comme je l'ai découvert, non pas la taille exacte, mais approximative du contenu du flux vidéo. Un reconditionneur régulier jette complètement tous les octets de ce contenu, puis écrit la taille résultante dans les champs correspondants du conteneur avi. Et cette valeur est différente de la valeur spécifiée dans le champ correspondant du fichier .264 source.
En partie, j'ai deviné douze octets d'informations après l'en-tête du bloc de flux audio. Dans tous les cas, les éléments clés sont les 4 derniers octets, après quoi le flux audio commence. Ce sont deux nombres de 16 bits qui décrivent les paramètres initiaux du schéma de décodage itératif d'ADPCM à PCM. Le décodage augmente la taille du flux audio de 4 fois. Lorsque j'ai examiné les fichiers à l'avance, j'ai découvert que le reconditionneur à temps plein décode l'audio, mais laisse le contenu de la vidéo inchangé.
Sans connaissances approfondies, j'ai longtemps essayé de comprendre quel algorithme de décodage était utilisé dans mon cas. Intuitivement déjà deviné que la méthode de compression ADPCM était appliquée. Plus précisément, pas intuitivement, mais avec une approche compétente, basée sur le fait que le flux audio est compressé exactement 4 fois. Et lorsque j'ouvre un fragment dans Adobe Audition en tant que RAW dans divers formats (et que je compare le même fragment après reconditionnement avec un programme normal), un résultat sonore très similaire (mais pas précis) m'a été donné par ADPCM. Pour analyser l'algorithme de compression, les informations sur le site
wiki.multimedia.cx/index.php/IMA_ADPCM m'ont aidé. Ici, j'ai appris les deux paramètres de décodage initiaux, puis, en utilisant la «méthode poke», j'ai réalisé que ces paramètres initiaux étaient enregistrés sur 4 octets avant le début du flux audio. Je décrirai le fonctionnement de l'algorithme et donnerai une interprétation mathématique approximative (sous le spoiler).
Détails de l'algorithme de décodage ADPCMIl y a une séquence d'échantillons
De plus, comme déjà mentionné, il existe deux paramètres initiaux
et
. Besoin d'obtenir une nouvelle séquence d'échantillons
. Comme vous pouvez déjà le deviner, le premier échantillon de sortie est déjà connu: il coïncide avec l'un des paramètres initiaux
. C'est autre chose qu'un «déplacement initial». Il convient de noter que les échantillons d'entrée (source) sont codés sur quatre bits. Pour les types signés, les entiers de -8 à 7, inclus, relèvent du codage. Le bit le plus significatif, en fait, est responsable du signe du nombre. Les échantillons PCM en sortie, qui sont obtenus après décodage, ont un format standard 16 bits signé.
En analysant le code de l'algorithme en C, vous pouvez voir deux tableaux. Ils sont listés ci-dessous.
int ima_index_table[] = { -1, -1, -1, -1, 2, 4, 6, 8 };
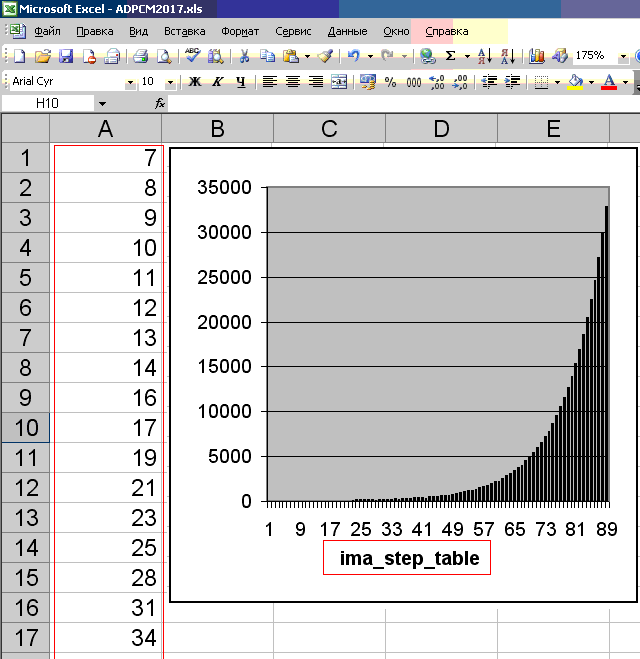
int ima_step_table[] = { 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 19, 21, 23, 25, 28, 31, 34, 37, 41, 45, 50, 55, 60, 66, 73, 80, 88, 97, 107, 118, 130, 143, 157, 173, 190, 209, 230, 253, 279, 307, 337, 371, 408, 449, 494, 544, 598, 658, 724, 796, 876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899, 15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767 };
Ces deux tableaux «magiques» peuvent être considérés comme des fonctions tabulaires, dans les arguments desquels les deux mêmes paramètres initiaux sont substitués. Pendant l'itération, à chaque étape, les paramètres sont recalculés et substitués à nouveau dans ces tables. Voyons d'abord comment cela est implémenté dans le code.
Nous déclarons les variables nécessaires, y compris auxiliaires.
int current1; int step; int stepindex1; int diff; int current; int stepindex; int value;
Avant de commencer l'itération, vous devez affecter le paramètre initial à la variable actuelle
et la variable stepindex est
. Cela se fait en dehors de l'algorithme en question, donc je ne reflète pas cela avec du code. Voici les transformations qui sont effectuées dans un cercle (dans une boucle).
value = read(input_sample);
Dans l'étape de variable auxiliaire du tableau ima_step_table, la valeur à l'index stepindex1 est écrite. Pour la première itération, il s'agit du paramètre initial
, pour d'autres itérations, il s'agit d'un paramètre recalculé
. Ensuite, la valeur de ce tableau est divisée par 8 (apparemment, complètement) par une opération de décalage de bit vers la droite, et la variable diff est initialisée à la suite de cette division. Ensuite, les trois bits les moins significatifs de la valeur de l'échantillon d'entrée sont analysés et, en fonction de leurs états, la variable diff peut être ajustée de trois termes. Les termes sont une division entière similaire de la valeur diff par 4 (>> 2), 2 (>> 1) ou diff sans changements (que ce soit une division par 1 pour la généralisation). Ensuite, le bit le plus significatif (signé) de la valeur de l'échantillon d'entrée est analysé. Selon son état, la variable diff qui a été générée avant celle-ci est ajoutée ou soustraite à la variable courant1. Ce sera la valeur de l'échantillon de sortie. Par souci d'exactitude, les valeurs sont limitées au haut et au bas. Ensuite, stepindex1 est ajusté en ajoutant la valeur du tableau ima_index_table par l'index de la valeur de l'échantillon d'entrée avec le bit de signe remis à zéro. Les valeurs de Stepindex1 sont également soumises à une limite. À la toute fin, avant de répéter cet algorithme, les valeurs actuelles et stepindex reçoivent les valeurs juste recomptées de current1 et stepindex1, et l'algorithme est répété à nouveau.
Vous pouvez essayer de le comprendre afin de comprendre approximativement comment la variable diff est formée. Soit
. Ce sont les valeurs de la variable step à chaque i-ème étape de l'itération, comme les valeurs de la fonction (tableau) de l'argument
où
. Pour plus de commodité, nous désignons la variable diff comme
. Suivant la logique du raisonnement décrit ci-dessus, nous avons:
où
- faible 3 bits d'un nombre
. Menant à un dénominateur commun, nous transformons cette expression en une forme plus pratique:
La dernière conversion est basée sur le fait que, dans un sens, les trois bits au moins (0 ou 1) d'un nombre
avec les coefficients présentés, il y a autre chose que d'écrire la valeur absolue de ce nombre et le bit le plus significatif du nombre
correspondra au signe de l'expression entière. Toujours selon la formule
une nouvelle valeur d'échantillon est calculée sur la base de l'ancienne. De plus, une nouvelle valeur de variable est calculée.
:
Le module de la formule indique que la variable
entre en fonction
à l'exclusion du bit de signe le plus significatif, qui se reflète dans le code. Une fonction
Valeur du tableau ima_index_table avec l'index correspondant à l'argument.
Dans la description des formules, j'ai négligé les opérations de restriction ci-dessus et ci-dessous. Le schéma itératif total ressemble à ceci:
Très profondément dans la théorie de l'encodage / décodage ADPCM, je ne me suis pas plongé dans. Cependant, les valeurs du tableau du tableau ima_step_table (de 89 pièces), à en juger par leur réflexion sur le graphique (voir la figure ci-dessous), décrivent la distribution probabiliste des échantillons par rapport à la ligne zéro. En pratique, c'est généralement le cas: plus l'échantillon est proche de la ligne zéro, plus il se produit. Par conséquent, ADPCM est basé sur un modèle probabiliste et aucun ensemble source d'échantillons PCM 16 bits ne peut être correctement converti en échantillons ADPCM 4 bits. De manière générale, ADPCM est un PCM avec un pas de quantification variable. Apparemment, ce graphique reflète cette étape très variable. Il est choisi correctement, sur la base de la loi de distribution des données audio en pratique.
Passons maintenant à la description de la structure du conteneur avi. En fait, c'est une structure hiérarchique complexe.
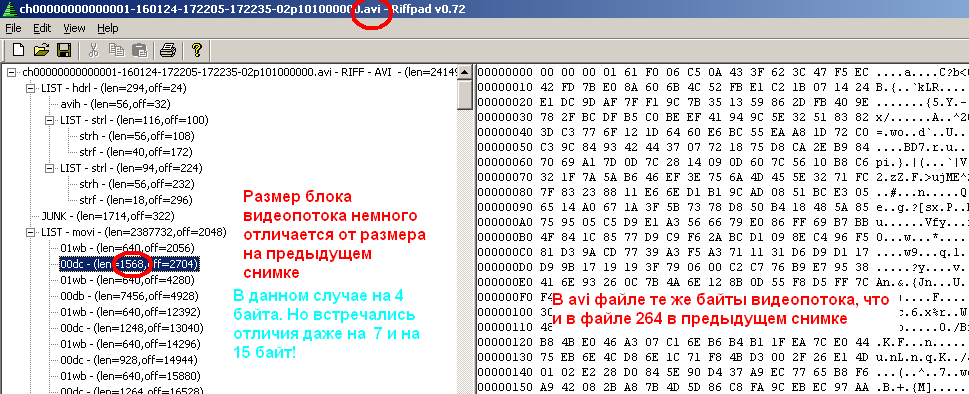
Mais, après avoir simplifié la tâche pour un cas spécial, j'ai présenté la structure avi sous une forme linéaire. Le résultat est le suivant: le fichier avi comprend un grand en-tête, zéro octet de saut (JUNK), une zone de flux audio et vidéo (avec leurs en-têtes et tailles de contenu) et une liste d'index. Ce dernier sert notamment à faire défiler la vidéo dans le lecteur. Sans cette liste, le défilement ne fonctionnera pas (coché). Il s'agit uniquement d'une table des matières, qui répertorie les noms de clé des blocs de flux (correspondant aux noms dans les en-têtes de bloc), les tailles correspondantes du contenu et les valeurs des décalages (adresses) par rapport au début de la zone de flux.
Vous pouvez maintenant procéder au développement du programme. Une description spécifique du problème est la suivante.
A la racine de la section X: il y a un répertoire «DVR». Ce répertoire contient de nombreux sous-répertoires non vides (et uniquement des sous-répertoires) avec des noms qui correspondent à certaines dates. Dans chacun de ces sous-répertoires, il existe de nombreux fichiers avec des noms différents et l'extension "264". Obligatoire dans la section Y: créez le répertoire «DVR», et dans celui-ci les mêmes sous-répertoires que dans la section X:. Remplissez chacun de ces sous-répertoires avec des fichiers portant les mêmes noms correspondants, mais avec des extensions non pas «264», mais «avi». Ces fichiers avi doivent être obtenus à partir des 264 fichiers d'origine en les traitant, ce qui, d'une manière ou d'une autre, répète l'algorithme d'un programme existant. Le traitement consiste à reconditionner directement les flux vidéo, à reconditionner avec décoder les flux audio, à formater le fichier avi. Le programme doit être lancé à partir de la ligne de commande comme suit: "264toavi.exe X: Y:", où "264toavi.exe" est le nom du programme, "X:" est la section source, "Y:" est la section destination.En effet, pour simplifier la tâche, il a été possible d'écrire un programme qui ne traiterait que la conversion (reconditionnement) d'un fichier, soit deux jours: le nom du fichier d'entrée et le nom du fichier de sortie. Et puis, pour implémenter uniquement le reconditionnement de groupe, vous pouvez écrire un fichier de commandes (bat) en utilisant d'autres outils, par exemple Excel. Mais j'ai mis en place un programme complet, très lourd. Il est peu probable que le code source mérite l'attention des lecteurs. Je décrirai la structure du code du programme.
Le programme est écrit en C dans l'environnement de développement Dev-C ++ avec des éléments WinAPI. Le programme met en œuvre trois grandes fonctions auxiliaires: la fonction de génération de l'en-tête avi initial, la fonction de décodage d'un échantillon audio et la fonction de numérisation du fichier source "264" par des mots. En termes, j'appelle une portion de 4 octets. Il a été observé que la taille des en-têtes et le contenu de tous les flux sont un multiple de quatre octets. La fonction de numérisation peut renvoyer cinq valeurs: 0 - s'il s'agit des 4 octets habituels du flux vidéo à reconditionner, 1 - s'il s'agit de l'en-tête du bloc du flux vidéo de la trame de référence, 2 - s'il s'agit du titre du bloc du flux vidéo de la trame compressée, 3 - s'il s'agit de l'en-tête du bloc de flux audio, 4 - si c'est Bloc «corrompu» à ignorer lors du reconditionnement. Très, très rare, mais c'est arrivé. Le bloc endommagé (comme je l'ai appelé) est un en-tête comme "\ 0 \ 0 \ 0 \ 0H264", où "\ 0" est l'octet zéro. Le reconditionneur normal ignore les blocs de ce type. Bien sûr, le contenu d'un tel bloc peut s'avérer tout à fait fonctionner, mais j'ignore ces blocs pour rapprocher mon programme du programme standard.
Dans la fonction principale, en plus d'organiser les répertoires, le fichier d'entrée est lu par la fonction scan. Selon ce que cette fonction a renvoyé, d'autres actions se produisent. S'il s'agit des en-têtes des flux vidéo, les en-têtes correspondants sont formés dans le fichier avi de sortie. Là, ils sont appelés différemment: "00db" est le titre du bloc du flux vidéo de la trame de référence, et "00dc" est pour la trame compressée. Après l'opération de reconditionnement (réécriture des mots) avant le nouvel en-tête nouvellement rencontré, la taille du contenu reconditionné est calculée et cette valeur est écrite dans le champ qui suit immédiatement l'en-tête du flux qui vient d'être traité. Si un en-tête de flux audio est rencontré pendant le balayage, le nom d'en-tête «03wb» est généré dans le fichier avi de sortie et le flux audio est décodé d'ADPCM vers PCM dans la boucle en même temps que le contenu décodé est écrit dans le fichier avi. Parallèlement à tout ce qui précède, une brève information (table des matières) est enregistrée dans un fichier d'index temporaire «index». Vous ne pouviez pas faire de fonction de numérisation, mais écrivez tout dans la fonction principale. Mais alors le programme serait très lourd et presque difficile à lire.
A la fin de toute l'opération, lorsque le fichier d'entrée "264" est terminé, avant de passer à un nouveau fichier, le programme termine avec compétence toutes les opérations. Tout d'abord, certains champs de l'en-tête du fichier avi sont ajustés, dont les valeurs dépendent de la taille et du nombre de flux de lecture, puis le contenu du fichier "index" temporaire est attaché au fichier avi presque terminé, qui est ensuite supprimé. Après ces opérations, le fichier avi de sortie est prêt pour la lecture.
Pendant l'exécution du programme, une visualisation de texte a lieu sur la ligne de commande, qui affiche le répertoire actuel, le fichier, ainsi que le numéro de bloc du flux vidéo par trame de référence et le point temporel correspondant de la vidéo en minutes et secondes. Et si le fichier d'entrée n'a pas de nom arbitraire, mais celui d'origine (contenant le numéro de canal, la date et l'heure de début de l'enregistrement), une visualisation plus interactive basée sur l'arithmétique date-heure se produit.
Lors du test et du débogage du programme, les principaux problèmes que j'ai rencontrés lors du travail de décodage du son. L'arithmétique simple ne fonctionnait pas correctement si, lors de la déclaration de variables dans la fonction de décodage, je ne saisissais pas correctement les types. Pour cette raison, certains blocs de flux audio ont été rompus et il y a eu des clics à l'oreille. Quelques champs d'en-tête incompréhensibles du fichier 264 d'origine que je ne pouvais pas comprendre se sont révélés insensibles au résultat. Contrairement à un programme normal, mon programme ne jette pas le dernier bloc de flux incomplet de l'opération de reconditionnement. Cependant, son absence ne jouera aucun rôle pratique. Un autre programme régulier, contrairement au mien, laisse une petite quantité de «déchets» (c'est le contenu du dernier flux) à la toute fin du fichier avi après les index. Pour tout cela, la vidéo joue presque la même chose. Et le programme effectue le remballage pour la même période de temps que le programme régulier.
En conclusion, je donnerai des illustrations démontrant la structure de l'organisation des flux dans le fichier .264 (dans l'éditeur hexadécimal WinHex) en utilisant l'un des fichiers à titre d'exemple et l'apparence du programme RiffPad avec le fichier avi reconditionné ouvert. Ce programme a grandement simplifié le processus d'étude de la structure d'un fichier avi. Il montre clairement la structure hiérarchique, montre le contenu en octets de chaque membre de la structure et interprète même intelligemment le contenu des en-têtes sous la forme d'une liste de paramètres. L'image, en particulier, démontre le fait que le contenu du flux vidéo est écrasé sans modifications.