Bon à tous! Eh bien, le moment est venu pour
notre prochain
cours Devops . C'est probablement l'un des cours les plus stables et de référence, mais en même temps le plus diversifié en termes d'étudiants, car aucun groupe n'a jamais ressemblé à l'autre: dans l'un, les développeurs sont presque complètement, puis dans les ingénieurs suivants, puis les administrateurs, etc. Et cela signifie également que le moment est venu de disposer de documents intéressants et utiles, ainsi que de réunions en ligne.

Cet article contient des recommandations sur le lancement d'un cluster Kubernetes de production dans un centre de données sur site ou un emplacement périphérique (emplacement périphérique).
Que signifie qualité de production?
- Installation sûre
- La gestion du déploiement est effectuée à l'aide d'un processus répétitif et enregistré;
- Le travail est prévisible et cohérent;
- Il est sûr d'effectuer des mises à jour et des réglages;
- Pour détecter et diagnostiquer les erreurs et le manque de ressources, il existe une journalisation et une surveillance;
- Le service a une «haute disponibilité» suffisante compte tenu des ressources disponibles, y compris les restrictions d'argent, d'espace physique, d'alimentation, etc.
- Le processus de récupération est disponible, documenté et testé pour une utilisation en cas de panne.
Bref, la production signifie anticiper les erreurs et préparer la reprise avec un minimum de problèmes et de retards.

Cet article concerne le déploiement sur site de Kubernetes sur un hyperviseur ou une plate-forme bare-metal, compte tenu de la quantité limitée de ressources de support par rapport à l'augmentation des principaux clouds publics. Néanmoins, certaines de ces recommandations peuvent être utiles pour le cloud public si le budget limite les ressources sélectionnées.
Le déploiement d'un Minikube métal nu simple métal nu peut être un processus simple et bon marché, mais il n'est pas de qualité production. À l'inverse, vous ne pourrez pas atteindre le niveau de Google avec Borg dans un magasin hors ligne, une succursale ou un emplacement périphérique, bien qu'il soit peu probable que vous en ayez besoin.
Cet article décrit des conseils pour réaliser un déploiement Kubernetes au niveau de la production, même dans des situations de ressources limitées.
Composants importants du cluster KubernetesAvant de plonger dans les détails, il est important de comprendre l'architecture globale de Kubernetes.
Le cluster Kubernetes est un système hautement distribué basé sur le plan de contrôle et l'architecture des nœuds de travail en cluster, comme indiqué ci-dessous:
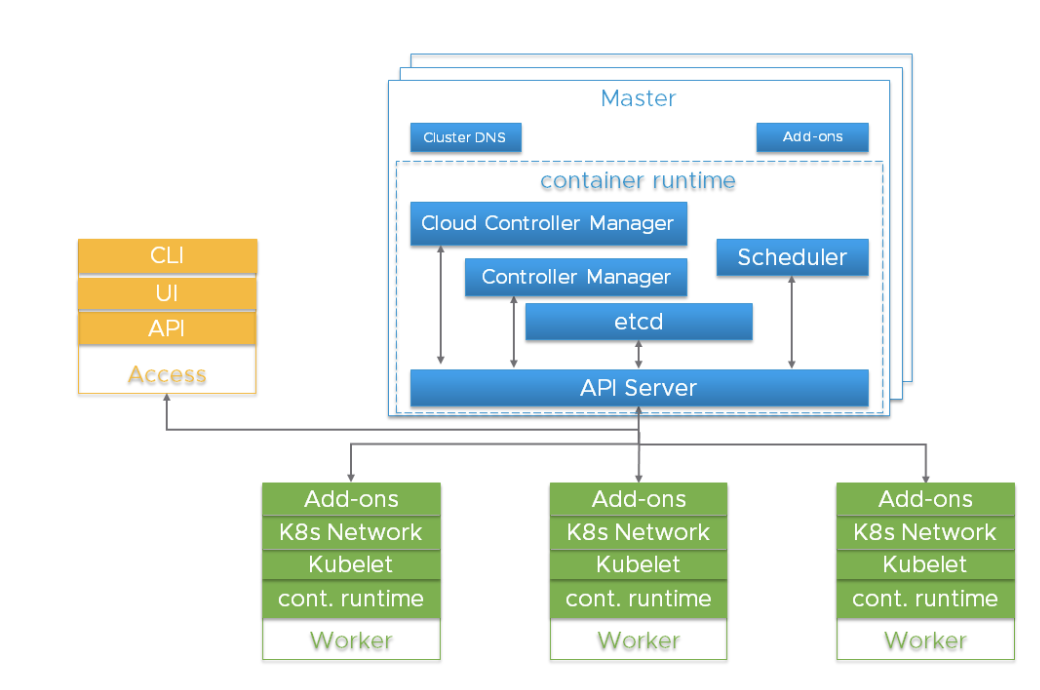
En règle générale, les composants du serveur API, du gestionnaire de contrôleur et du planificateur sont situés dans plusieurs instances de nœuds de niveau de contrôle (appelés maîtres). Les nœuds maîtres incluent également etcd, mais il existe des scripts volumineux et hautement accessibles qui nécessitent d'exécuter etcd sur des hôtes indépendants. Les composants peuvent être exécutés comme des conteneurs et, éventuellement, sous la supervision de Kubernetes, c'est-à-dire fonctionner comme des foyers statiques.
Des instances redondantes de ces composants sont utilisées pour la haute disponibilité. L'importance et le niveau de redondance requis peuvent varier.
| Composant | Rôles | Conséquences de la perte | Instances recommandées |
|---|
| etcd | Maintient l'état de tous les objets Kubernetes | Perte catastrophique de stockage. Perte de la plupart = Kubernetes perd le niveau de contrôle, le serveur API dépend de etcd, les appels d'API en lecture seule qui n'ont pas besoin de quorum, comme les charges de travail déjà créées, peuvent continuer à fonctionner. | nombre impair, 3+ |
| Serveur API | Fournit une API pour une utilisation externe et interne | Impossible d'arrêter, de démarrer et de mettre à jour de nouveaux pods. Scheduler et Controller Manager dépendent du serveur API. Les chargements se poursuivent s'ils ne dépendent pas des appels d'API (opérateurs, contrôleurs personnalisés, CRD, etc.) | 2+ |
| kube-scheduler | Place les pods sur les nœuds | Les pods ne peuvent pas être placés, priorisés ou déplacés entre eux. | 2+ |
| kube-controller-manager | Contrôle de nombreux contrôleurs | Les principales boucles de contrôle responsables de l'état cessent de fonctionner. L'intégration dans l'arborescence du fournisseur de cloud est interrompue. | 2+ |
| cloud-controller-manager (CCM) | Intégration de fournisseurs de cloud hors arborescence | Pauses d'intégration des fournisseurs de cloud | 1 |
| Ajouts (par exemple DNS) | Différent | Différent | Dépend de l'add-on (par exemple 2+ pour DNS) |
Les risques de ces composants incluent les pannes matérielles, les bogues logiciels, les mauvaises mises à jour, les erreurs humaines, les interruptions du réseau et la surcharge du système entraînant l'épuisement des ressources. La redondance peut réduire l'impact de ces dangers. De plus, grâce aux fonctionnalités de la plate-forme hyperviseur (planification des ressources, haute disponibilité), vous pouvez multiplier les résultats en utilisant le système d'exploitation Linux, Kubernetes et le runtime du conteneur.
Le serveur API utilise plusieurs instances d'équilibreur de charge pour atteindre l'évolutivité et la disponibilité. Un équilibreur de charge est un composant essentiel pour une haute disponibilité. Plusieurs enregistrements A du serveur API DNS peuvent servir d'alternative en l'absence d'un équilibreur.
kube-scheduler et kube-controller-manager sont impliqués dans le processus de sélection d'un leader au lieu d'utiliser un équilibreur de charge. Étant donné que le
cloud-controller-manager est utilisé pour certains types d'infrastructure d'hébergement, dont la mise en œuvre peut varier, nous n'en discuterons pas - nous indiquons seulement qu'ils font partie du niveau de gestion.
Les pods exécutés sur Kubernetes sont gérés par l'agent kubelet. Chaque instance du travailleur exécute un agent kubelet et un environnement de lancement de conteneur compatible
CRI . Kubernetes lui-même est conçu pour surveiller et récupérer des défaillances des nœuds de travail. Mais pour les fonctions de charge critiques, la gestion des ressources de l'hyperviseur et l'isolation de la charge, il peut être utilisé pour améliorer l'accessibilité et augmenter la prévisibilité de leur travail.
etcdetcd est un stockage persistant pour tous les objets Kubernetes. La disponibilité et la récupérabilité du cluster etcd devraient être une priorité absolue lors du déploiement de Kubernetes de niveau production.
Le cluster etcd composé de cinq nœuds est la meilleure option si vous pouvez l'autoriser. Pourquoi? Parce que vous pouvez en entretenir un et en même temps résister à une panne. Un cluster de trois nœuds est le minimum que nous pouvons recommander pour un service de qualité production, même si un seul hyperviseur hôte est disponible. Plus de sept nœuds sont également déconseillés, à l'exception des
très grandes installations couvrant plusieurs zones d'accès.
Les recommandations minimales pour l'hébergement d'un nœud de cluster etcd sont 2 Go de RAM et un disque dur SSD de 8 Go. En règle générale, 8 Go de RAM et 20 Go d'espace disque dur sont suffisants. Les performances du disque affectent le temps de récupération d'un nœud après une panne.
Consultez pour plus de détails.
Dans des cas particuliers, pensez à plusieurs clusters etcdPour les très grands clusters Kubernetes, envisagez d'utiliser un cluster etcd distinct pour les événements Kubernetes afin que trop d'événements n'affectent pas le service principal de l'API Kubernetes. Lorsque vous utilisez le réseau Flannel, la configuration est enregistrée dans etcd, et les exigences de version peuvent différer de Kubernetes. Cela peut compliquer la sauvegarde de etcd, nous vous recommandons donc d'utiliser un cluster etcd distinct spécifiquement pour la flanelle.
Déploiement sur un seul hôteLa liste des risques d'accessibilité comprend le matériel, les logiciels et le facteur humain. Si vous êtes limité à un seul hôte, l'utilisation d'un stockage redondant, d'une mémoire de correction d'erreurs et d'une double alimentation peut améliorer la protection contre les pannes matérielles. L'exécution d'un hyperviseur sur un hôte physique vous permet d'utiliser des composants logiciels redondants et ajoute des avantages opérationnels associés au déploiement, à la mise à jour et à la surveillance de l'utilisation des ressources. Même dans des situations stressantes, le comportement reste reproductible et prévisible. Par exemple, même si vous ne pouvez autoriser le lancement que de singletones à partir de services principaux, ils doivent être protégés contre la surcharge et l'épuisement des ressources, en concurrence avec la charge de travail de votre application. Un hyperviseur peut être plus efficace et plus facile à utiliser que la priorisation dans le planificateur Linux, les cgroups, les drapeaux Kubernetes, etc.
Vous pouvez déployer trois machines virtuelles etcd si les ressources de l'hôte le permettent. Chaque machine virtuelle doit être prise en charge par un périphérique de stockage physique distinct ou utiliser des parties distinctes du stockage à l'aide de la redondance (mise en miroir, RAID, etc.).
Les doubles instances redondantes de l'API du serveur, du planificateur et du gestionnaire de contrôleur sont la prochaine mise à niveau si votre seul hôte dispose de suffisamment de ressources pour cela.
Options de déploiement sur un seul hôte, du moins adapté à la production à la plupart| Tapez | CARACTÉRISTIQUES | Résultat |
|---|
| Équipement minimum | Singleton etcd et composants principaux. | Laboratoire à domicile, pas du tout de production. Multiple Single Point of Failure (SPOF). La récupération est lente et lorsque le stockage est perdu, il est complètement absent. |
| Amélioration de la redondance du stockage | etcd singleton et composants maîtres, le stockage etcd est redondant. | Au minimum, vous pouvez récupérer d'une panne de périphérique de stockage. |
| Redondance de niveau gérée | Il n'y a pas d'hyperviseur, plusieurs instances de composants de niveau géré dans des modules statiques. | La protection contre les bogues logiciels est apparue, mais le système d'exploitation et l'environnement de lancement du conteneur sont toujours le même point d'échec avec des mises à jour dévastatrices. |
| Ajout d'un hyperviseur | Exécution de trois instances redondantes de niveau géré dans la machine virtuelle. | Il y a une protection contre les bogues logiciels et les erreurs humaines et un avantage opérationnel dans l'installation, la gestion des ressources, la surveillance et la sécurité. Les mises à jour du système d'exploitation et les environnements de lancement de conteneurs sont moins perturbateurs. L'hyperviseur est le seul point de défaillance unique. |
Déploiement sur deux hôtesAvec deux hôtes, les problèmes de stockage etcd sont similaires à l'option d'hôte unique - vous avez besoin de redondance. Il est préférable d'exécuter trois instances d'encd. Cela peut sembler peu intuitif, mais il est préférable de concentrer tous les nœuds etcd sur un seul hôte. Vous n'augmenterez pas la fiabilité en les divisant par 2 + 1 entre deux hôtes - la perte d'un nœud avec la plupart des instances d'encd entraînera un échec, qu'il s'agisse d'une majorité de 2 ou de 3. Si les hôtes ne sont pas les mêmes, placez l'ensemble du cluster etcd sur le plus fiable.
Il est recommandé d'exécuter des serveurs d'API redondants, des planificateurs de kube et des gestionnaires de contrôleur de kube. Ils doivent être partagés entre les hôtes pour minimiser les risques d'échecs dans l'environnement de lancement de conteneur, le système d'exploitation et le matériel.
Le lancement d'une couche d'hyperviseur sur des hôtes physiques vous permettra de travailler avec des composants de programme redondants, offrant une gestion des ressources. Il présente également l'avantage opérationnel d'une maintenance planifiée.
Options de déploiement pour deux hôtes, du moins adapté à la production au plus| Tapez | CARACTÉRISTIQUES | Résultat |
|---|
| Équipement minimum | Deux hôtes, sans stockage redondant. Singleton etcd et composants principaux sur le même hôte. | etcd - un seul point de défaillance, cela n'a aucun sens d'en exécuter deux sur d'autres services maîtres. Le partage entre deux hôtes augmente le risque de défaillance de la couche gérée. L'avantage potentiel d'isoler les ressources en exécutant une couche gérée sur un hôte et des charges de travail d'application sur un autre. Si le stockage est perdu, il n'y a pas de récupération. |
| Amélioration de la redondance du stockage | Singleton etcd et composants maîtres sur le même hôte, stockage etcd redondant. | Au minimum, vous pouvez récupérer d'une panne de périphérique de stockage. |
| Redondance de niveau gérée | Il n'y a pas d'hyperviseur, plusieurs instances de composants de niveau géré dans des modules statiques. cluster etcd sur un hôte, les autres composants de niveau géré sont séparés. | Une panne matérielle, la mise à jour du micrologiciel, du système d'exploitation et de l'environnement de lancement de conteneur sur un hôte sans etcd sont moins dommageables. |
| Ajout d'un hyperviseur aux deux hôtes | Trois composants redondants de niveau géré s'exécutent sur des machines virtuelles, etcd cluster sur un hôte, et les composants de niveau géré sont séparés. Les charges de travail d'application peuvent résider sur les deux nœuds de machine virtuelle. | Amélioration de l'isolation de la charge des applications. Les mises à jour du système d'exploitation et de l'environnement de lancement de conteneur sont moins perturbatrices. La maintenance planifiée du matériel / micrologiciel devient non destructive si l'hyperviseur prend en charge la migration des machines virtuelles. |
Déploiement sur trois hôtes (ou plus)Transition vers un service de qualité sans compromis. Nous vous recommandons de diviser etcd entre les trois hôtes. Une défaillance matérielle réduira la quantité de charges de travail d'application possibles, mais n'entraînera pas une interruption complète du service.
Les très grands clusters nécessiteront plus d'instances.
Le lancement d'une couche d'hyperviseur offre des avantages opérationnels et une meilleure isolation des charges de travail des applications. Cela dépasse le cadre de l'article, mais au niveau de trois hôtes ou plus, des fonctions améliorées peuvent être disponibles (stockage partagé redondant en cluster, gestion des ressources avec un équilibreur de charge dynamique, surveillance d'état automatisée avec migration en direct et basculement).
Options de déploiement pour trois hôtes (ou plus), du moins adapté à la production au plus| Tapez | CARACTÉRISTIQUES | Résultat |
|---|
| Minimum | Trois hôtes. Instance etcd sur chaque nœud. Composants principaux sur chaque nœud. | La perte d'un nœud réduit les performances, mais n'entraîne pas de chute de Kubernetes. La possibilité de récupération demeure. |
| Ajout d'un hyperviseur aux hôtes | Dans les machines virtuelles sur trois hôtes, etcd, un serveur API, des planificateurs et un gestionnaire de contrôleurs sont en cours d'exécution. Les charges de travail s'exécutent dans la machine virtuelle sur chaque hôte. | Protection supplémentaire contre les bogues du système d'exploitation / l'environnement de lancement du conteneur / logiciel et les erreurs humaines. Avantages opérationnels de l'installation, de la mise à niveau, de la gestion des ressources, de la surveillance et de la sécurité. |
Configurer KubernetesLes nœuds maître et travailleur doivent être protégés contre la surcharge et l'épuisement des ressources. Les fonctions d'hyperviseur peuvent être utilisées pour isoler les composants critiques et réserver les ressources. Il existe également des paramètres de configuration de Kubernetes qui peuvent ralentir des choses comme la vitesse des appels d'API. Certains kits d'installation et distributions commerciales s'en chargent, mais si vous déployez Kubernetes vous-même, les paramètres par défaut peuvent ne pas convenir, en particulier pour les petites ressources ou pour un cluster trop volumineux.
La consommation des ressources au niveau géré est en corrélation avec le nombre de foyers et le taux de sortie des foyers. Les clusters très grands et très petits bénéficieront de la modification de la requête kube-apiserver et des
paramètres de ralentissement de la mémoire.
Les nœuds allouables doivent être configurés sur les
nœuds de travail en fonction de la densité de charge prise en charge raisonnable pour chaque nœud. Des espaces de noms peuvent être créés pour diviser un cluster de nœuds de travail en plusieurs clusters virtuels avec des
quotas de CPU et de mémoire.
La sécuritéChaque cluster Kubernetes possède une autorité de certification (CA) racine. Les certificats Controller Manager, API Server, Scheduler, kubelet client, kube-proxy et administrateur doivent être générés et installés. Si vous utilisez un outil d'installation ou une distribution, vous n'aurez peut-être pas à vous en occuper vous-même. Le processus manuel est décrit
ici . Vous devez être prêt à réinstaller les certificats si vous développez ou remplacez les nœuds.
Étant donné que Kubernetes est entièrement géré par l'API, il est impératif de contrôler et de limiter la liste de ceux qui ont accès au cluster. Les options de chiffrement et d'authentification sont décrites dans cette documentation.
Les charges de travail des applications Kubernetes sont basées sur des images de conteneur. Vous avez besoin de la source et du contenu de ces images pour être fiables. Presque toujours, cela signifie que vous hébergerez l'image du conteneur dans le référentiel local. L'utilisation d'images provenant d'Internet public peut entraîner des problèmes de fiabilité et de sécurité. Vous devez sélectionner un référentiel prenant en charge la signature de l'image, la sécurité de la numérisation, le contrôle de l'accès pour envoyer et télécharger des images et l'activité de consignation.
Les processus doivent être configurés pour prendre en charge l'utilisation de l'hôte, de l'hyperviseur, d'OS6, de Kubernetes et d'autres mises à jour du micrologiciel de dépendance. La surveillance des versions est nécessaire pour prendre en charge l'audit.
Recommandations:
- Renforcez les paramètres de sécurité par défaut pour les composants de niveau géré (par exemple, blocage des nœuds de travail );
- Utiliser la politique de sécurité du foyer ;
- Pensez à l'intégration NetworkPolicy disponible pour votre solution réseau, y compris le suivi, la surveillance et le dépannage;
- Utilisez RBAC pour prendre des décisions d'autorisation;
- Pensez à la sécurité physique, en particulier lors du déploiement sur des emplacements périphériques ou distants qui pourraient être négligés. Ajoutez un chiffrement de stockage pour limiter les conséquences du vol d'appareils et une protection contre la connexion d'appareils malveillants, tels que des clés USB;
- Protégez les informations d'identification textuelles du fournisseur de cloud (clés d'accès, jetons, mots de passe, etc.).
Les objets
secrets Kubernetes conviennent pour stocker de petites quantités de données sensibles. Ils sont stockés dans etcd. Ils peuvent être utilisés en toute sécurité pour stocker les informations d'identification de l'API Kubernetes, mais il arrive parfois qu'une charge de travail ou l'expansion du cluster lui-même nécessite une solution plus complète. Le projet HashiCorp Vault est une solution populaire si vous avez besoin de plus que ce que les objets secrets intégrés peuvent fournir.
Récupération après sinistre et sauvegarde
La mise en œuvre de la redondance via l'utilisation de plusieurs hôtes et machines virtuelles permet de réduire le nombre de certains types de pannes. Mais des scénarios tels qu'une catastrophe naturelle, une mauvaise mise à jour, une attaque de pirate, des bogues logiciels ou une erreur humaine peuvent toujours entraîner des plantages.
Un élément critique d'un déploiement en production est l'attente d'une future récupération.
Il convient également de noter qu'une partie de votre investissement dans la conception, la documentation et l'automatisation du processus de récupération peut être réutilisée si vous avez besoin de déploiements répliqués à grande échelle sur plusieurs sites.
Parmi les éléments de la reprise après sinistre, les sauvegardes (et éventuellement les répliques), les remplacements, le processus planifié, les personnes qui exécuteront ce processus et la formation régulière méritent d'être notés.
Les exercices et principes de test fréquents de
Chaos Engineering peuvent être utilisés pour tester votre état de préparation.
En raison des exigences de disponibilité, vous devrez peut-être stocker des copies locales du système d'exploitation, des composants Kubernetes et des images de conteneur pour permettre la récupération même si Internet se bloque. La possibilité de déployer des hôtes et des nœuds de remplacement dans une situation d '«isolation physique» améliore la sécurité et augmente la vitesse de déploiement.
Tous les objets Kubernetes sont stockés dans etcd. La sauvegarde périodique des données de cluster etcd est un élément important dans la restauration des clusters Kubernetes pendant les scénarios d'urgence, par exemple, lorsque tous les nœuds maîtres sont perdus.
etcd
etcd . Kubernetes . , Kubernetes.
, Kubernetes etcd , - . , .
etcd. , , , , /. , . :
- : CA, API Server, Apiserver-kubelet-client, ServiceAccount, “Front proxy”, Front proxy;
- DNS;
- IP/;
- ;
- kubeconfig;
- LDAP ;
- .
Anti-affinity . , . , Kubernetes , . , , - .
, .
stateful-, — Kubernetes (, SQL ). , , Kubernetes,
roadmap feature request , , , Container Storage Interface (CSI). , - , , . , Kubernetes , , , Kubernetes .
stateful- (, Cassandra) , , . - Kubernetes ( -) .
( ) , , . , , .
, (,
Ansible ,
BOSH ,
Chef ,
Juju ,
kubeadm ,
Puppet .). , .
, , , , , , . , Git, .
, , — . 2 , — . — , .

— . - , Airbus A320 — . , . , .
, . , , , . Kubernetes , - , , (, FedEx, Amazon).
production-grade Kubernetes . . , , , , . , (, Kubernetes
self-hosting, pas de foyers statiques). Peut-être devraient-elles être discutées dans les articles suivants, si l'intérêt est suffisant. De plus, en raison de la vitesse élevée de l'amélioration de Kubernetes, si votre moteur de recherche a trouvé cet article après 2019, certains de ses documents pourraient déjà être très obsolètes.LA FIN
Comme toujours, nous attendons vos questions et commentaires ici, et vous pouvez vous rendre à la journée portes ouvertes d' Alexander Titov .