Considérez un scénario où votre modèle d'apprentissage automatique pourrait être sans valeur.
Il y a un dicton:
"Ne comparez pas les pommes avec les oranges" . Mais que se passe-t-il si vous devez comparer un ensemble de pommes avec des oranges avec un autre, mais la distribution des fruits dans les deux ensembles est différente? Pouvez-vous travailler avec des données? Et comment allez-vous le faire?
Dans les cas réels, cette situation est courante. Lors du développement de modèles d'apprentissage automatique, nous sommes confrontés à une situation où notre modèle fonctionne bien avec un ensemble de formation, mais la qualité du modèle diminue fortement sur les données de test.
Et il ne s'agit pas de se recycler. Disons que nous avons construit un modèle qui donne un excellent résultat sur la validation croisée, mais montre un mauvais résultat sur le test. Ainsi, dans l'échantillon de test, il y a des informations que nous ne prenons pas en compte.
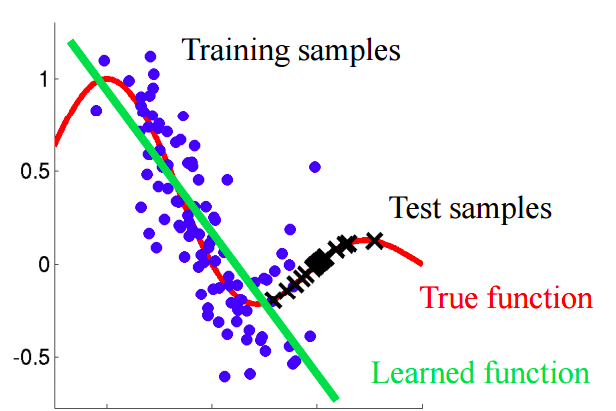
Imaginez une situation dans laquelle nous prédisons le comportement des clients dans un magasin. Si les exemples de formation et de test ressemblent à l'image ci-dessous, c'est un problème clair:
Dans cet exemple, le modèle est formé sur des données avec une valeur moyenne de l'attribut «âge du client» inférieure à la valeur moyenne d'un attribut similaire sur le test. Dans le processus d'apprentissage, le modèle n'a jamais «vu» les valeurs plus importantes de l'attribut «âge». Si l'âge est une caractéristique importante du modèle, il ne faut pas s'attendre à de bons résultats sur l'échantillon de test.Dans ce texte, nous parlerons d'approches «naïves» qui nous permettent d'identifier de tels phénomènes et d'essayer de les éliminer.
Décalage covariant
Donnons une définition plus précise de ce concept.
La covariance fait référence aux valeurs des caractéristiques, et le
décalage covariant fait référence à une situation où la distribution des valeurs des caractéristiques dans les échantillons d'apprentissage et d'essai a des caractéristiques (paramètres) différentes.
Dans les problèmes du monde réel avec un grand nombre de variables, le décalage covariant est difficile à détecter. L'article traite de la méthode d'identification et de prise en compte de la variation covariante des données.
Idée principale
S'il y a un changement dans les données, alors lors du mélange des deux échantillons, nous pouvons construire un classificateur qui peut déterminer si l'objet appartient à un échantillon d'apprentissage ou de test.Voyons pourquoi il en est ainsi. Revenons à l'exemple avec les clients, où l'âge était un signe «décalé» des échantillons de formation et de test. Si nous prenons un classificateur (par exemple, basé sur une forêt aléatoire) et essayons de diviser l'échantillon mixte en formation et test, alors l'âge sera un signe très important pour une telle classification.
Implémentation
Essayons d'appliquer l'idée décrite à un ensemble de données réel. Utilisez l'
ensemble de
données du concours Kaggle.
Étape 1: préparation des données
Tout d'abord, nous suivrons une série d'étapes standard: nettoyer, remplir les blancs, effectuer le codage des étiquettes pour les signes catégoriels. Aucune étape n'a été requise pour l'ensemble de données en question, alors ignorez sa description.
import pandas as pd
Étape 2: ajout d'un indicateur de source de données
Il est nécessaire d'ajouter un nouvel indicateur indicateur aux deux parties de l'ensemble de données - formation et test. Pour l'échantillon d'apprentissage avec la valeur «1», pour le test, respectivement, «0».
Étape 3: Combinaison des échantillons d'apprentissage et de test
Vous devez maintenant combiner les deux jeux de données. Étant donné que l'ensemble de données d'apprentissage contient une colonne de valeurs cibles «cible», qui ne se trouve pas dans l'ensemble de données de test, cette colonne doit être supprimée.
Étape 4: construction et test du classificateur
À des fins de classification, nous utiliserons le classificateur de forêt aléatoire, que nous configurerons pour prédire les étiquettes de la source de données dans l'ensemble de données combiné. Vous pouvez utiliser n'importe quel autre classificateur.
from sklearn.ensemble import RandomForestClassifier import numpy as np rfc = RandomForestClassifier(n_jobs=-1, max_depth=5, min_samples_leaf = 5) predictions = np.zeros(y.shape)
Nous utilisons une répartition aléatoire stratifiée de 4 plis. De cette façon, nous conserverons le rapport des étiquettes «is_train» dans chaque pli comme dans l'échantillon combiné d'origine. Pour chaque partition, nous formons le classificateur sur la majorité de la partition et prédisons l'étiquette de classe pour la plus petite partie différée.
from sklearn.model_selection import StratifiedKFold, cross_val_score skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=100) for fold, (train_idx, test_idx) in enumerate(skf.split(x, y)): X_train, X_test = x[train_idx], x[test_idx] y_train, y_test = y[train_idx], y[test_idx] rfc.fit(X_train, y_train) probs = rfc.predict_proba(X_test)[:, 1]
Étape 5: interpréter les résultats
Nous calculons la valeur de la métrique ROC AUC pour notre classificateur. Sur la base de cette valeur, nous concluons à quel point notre classifieur révèle un changement covariant dans les données.
Si le classificateur c sépare bien les objets dans les ensembles de données d'apprentissage et de test, alors la valeur de la métrique ROC AUC devrait être significativement supérieure à 0,5, idéalement proche de 1. Cette image indique un fort changement covariant dans les données.Trouvez la valeur de ROC AUC:
from sklearn.metrics import roc_auc_score print('ROC-AUC:', roc_auc_score(y_true=y, y_score=predictions))
La valeur résultante est proche de 0,5. Et cela signifie que notre classificateur de qualité est le même qu'un prédicteur d'étiquette aléatoire. Il n'y a aucune preuve d'un changement covariant dans les données.
Étant donné que l'ensemble de données provient de Kaggle, le résultat est assez prévisible. Comme dans les autres compétitions d'apprentissage automatique, les données sont soigneusement vérifiées pour s'assurer qu'il n'y a pas de changements.
Mais cette approche peut être appliquée à d'autres problèmes de science des données pour vérifier la présence d'un décalage covariant juste avant le début de la solution.
Etapes supplémentaires
Donc, soit nous observons un décalage covariant ou non. Que faire pour améliorer la qualité du modèle dans le test?
- Supprimer les fonctionnalités biaisées
- Utiliser des poids d'importance d'objet basés sur des estimations de coefficient de densité
Suppression des fonctionnalités biaisées:
Remarque: la méthode est applicable en cas de décalage covariant des données.- Extrayez l'importance des attributs du Random Forest Classifier, que nous avons construit et formé plus tôt.
- Les signes les plus importants sont précisément ceux qui sont biaisés et provoquent un changement dans les données.
- En commençant par le plus important, supprimez sur une base, construisez le modèle cible et examinez sa qualité. Recueillez tous les signes pour lesquels la qualité du modèle ne diminue pas.
- Ignorez les caractéristiques collectées des données et construisez le modèle final.
 Cet algorithme vous permet de supprimer les signes du panier rouge dans le diagramme.
Cet algorithme vous permet de supprimer les signes du panier rouge dans le diagramme.Utilisation de poids d'importance des objets basés sur des estimations de coefficient de densité
Remarque: la méthode est applicable qu'il y ait ou non un décalage covariant dans les données.Regardons les prédictions que nous avons reçues dans la section précédente. Pour chaque objet, la prédiction contient la probabilité que cet objet fasse partie de l'ensemble d'apprentissage pour notre classifieur.
predictions[:10]
Par exemple, pour le premier objet, notre classificateur de forêt aléatoire pense qu'il appartient à l'ensemble d'apprentissage avec une probabilité de 0,397. Appelez cette valeur
. Ou nous pouvons dire que la probabilité d'appartenance aux données de test est de 0,603. De même, nous appelons la probabilité
.
Maintenant une petite astuce: pour chaque objet du jeu de données d'apprentissage, nous calculons le coefficient
.
Coefficient
nous indique à quel point un objet de l'ensemble d'apprentissage est proche des données de test. L'idée principale:
Nous pouvons utiliser comme les poids dans l'un des modèles pour augmenter le poids des observations qui ressemblent à l'échantillon de test. Intuitivement, cela a du sens, car notre modèle sera plus orienté données que dans une suite de tests.Ces poids peuvent être calculés à l'aide du code:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(20,10)) predictions_train = predictions[:len(trn)] weights = (1./predictions_train) - 1. weights /= np.mean(weights)
Les coefficients obtenus peuvent être transférés au modèle, par exemple, comme suit:
rfc = RandomForestClassifier(n_jobs=-1,max_depth=5) m.fit(X_train, y_train, sample_weight=weights)

Quelques mots sur l'histogramme résultant:
- Des valeurs de poids plus élevées correspondent à des observations plus similaires à l'échantillon d'essai.
- Près de 70% des objets de l'ensemble d'entraînement ont un poids proche de 1 et, par conséquent, se trouvent dans un sous-espace qui est également similaire à l'ensemble d'entraînement et à l'ensemble de test. Cela correspond à la valeur ASC que nous avons calculée précédemment.
Conclusion
Nous espérons que ce billet vous aidera à identifier le «changement covariant» dans les données et à le combattre.
Les références
[1] Shimodaira, H. (2000). Amélioration de l'inférence prédictive sous décalage covariable en pondérant la fonction log-vraisemblance. Journal of Statistical Planning and Inference, 90, 227-244.
[2] Bickel, S. et al. (2009). Apprentissage discriminatoire sous décalage covariable. Journal of Machine Learning Research, 10, 2137–2155
[3]
github.com/erlendd/covariate-shift-adaption[4]
Lien vers l'ensemble de données utiliséPS L'ordinateur portable avec le code de l'article peut être consulté
ici .