 Processeur tenseur de 3e générationLe processeur Google Tensor
Processeur tenseur de 3e générationLe processeur Google Tensor est un circuit intégré à usage spécial (
ASIC ) développé à partir de zéro par Google pour effectuer des tâches d'apprentissage automatique. Il travaille sur plusieurs produits Google majeurs, notamment Translate, Photos, Search Assistant et Gmail. Cloud TPU offre les avantages de l'évolutivité et de la facilité d'utilisation à tous les développeurs et scientifiques des données qui lancent des modèles d'apprentissage automatique de pointe dans Google Cloud. Lors de Google Next '18, nous avons annoncé que Cloud TPU v2 est désormais disponible pour tous les utilisateurs, y compris
les comptes d'essai gratuits , et Cloud TPU v3 est disponible pour les tests alpha.

Mais beaucoup de gens demandent - quelle est la différence entre CPU, GPU et TPU? Nous avons réalisé un
site de démonstration où
se trouvent la présentation et l'animation qui répondent à cette question. Dans cet article, je voudrais m'attarder sur certaines caractéristiques du contenu de ce site.
Comment fonctionnent les réseaux de neurones?
Avant de commencer à comparer le CPU, le GPU et le TPU, voyons quels types de calculs sont nécessaires pour l'apprentissage automatique - et en particulier, pour les réseaux de neurones.
Imaginez, par exemple, que nous utilisons un réseau neuronal monocouche pour reconnaître les nombres manuscrits, comme le montre le diagramme suivant:
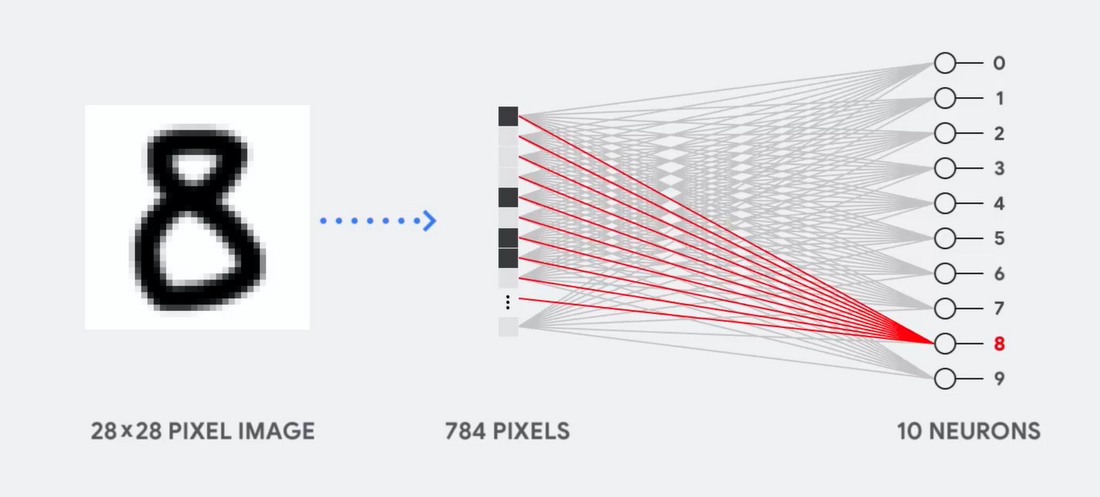
Si l'image est une grille de 28x28 pixels en échelle de gris, elle peut être convertie en un vecteur de 784 valeurs (mesures). Un neurone qui reconnaît le nombre 8 prend ces valeurs et les multiplie par les valeurs des paramètres (lignes rouges dans le diagramme).
Le paramètre fonctionne comme un filtre, extrayant les caractéristiques des données qui indiquent la similitude de l'image et de la forme 8:

C'est l'explication la plus simple de la classification des données par les réseaux de neurones. Multiplication des données avec les paramètres qui leur correspondent (coloration des points) et leur addition (somme des points à droite). Le résultat le plus élevé indique la meilleure correspondance entre les données saisies et le paramètre correspondant, qui, très probablement, sera la bonne réponse.
En termes simples, les réseaux de neurones doivent effectuer un grand nombre de multiplications et d'ajouts de données et de paramètres. Nous les organisons souvent sous forme de
multiplication matricielle , que vous pourriez rencontrer en algèbre à l'école. Par conséquent, le problème est d'effectuer un grand nombre de multiplications matricielles aussi rapidement que possible, en dépensant le moins d'énergie possible.
Comment fonctionne un CPU?
Comment le CPU aborde-t-il cette tâche? Le CPU est un processeur polyvalent basé sur l'
architecture von Neumann . Cela signifie que le CPU fonctionne avec le logiciel et la mémoire comme suit:
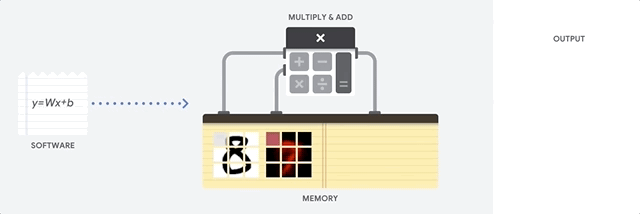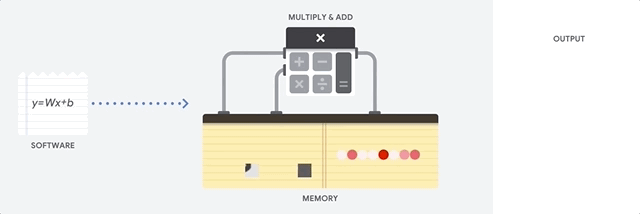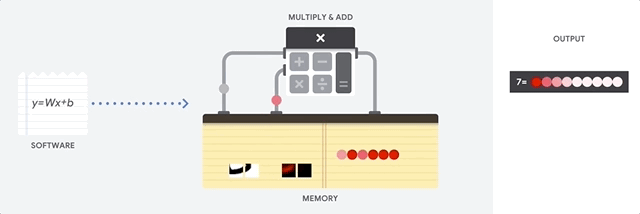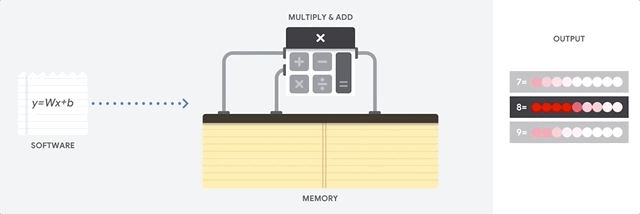
Le principal avantage du CPU est sa flexibilité. Grâce à l'architecture von Neumann, vous pouvez télécharger des logiciels complètement différents pour des millions de fins différentes. Le CPU peut être utilisé pour le traitement de texte, le contrôle du moteur de fusée, les transactions bancaires, la classification d'images à l'aide d'un réseau de neurones.
Mais comme le CPU est si flexible, l'équipement ne sait pas toujours à l'avance quelle sera la prochaine opération jusqu'à ce qu'il lise la prochaine instruction du logiciel. Le CPU a besoin de stocker les résultats de chaque calcul dans la mémoire située à l'intérieur du CPU (les soi-disant registres, ou
cache L1 ). L'accès à cette mémoire devient un inconvénient de l'architecture CPU, connue sous le nom de goulot d'étranglement de l'architecture von Neumann. Et bien qu'une énorme quantité de calculs pour les réseaux de neurones rend les étapes futures prévisibles, chaque
périphérique logique arithmétique du CPU (ALU, un composant qui stocke et contrôle les multiplicateurs et les additionneurs) effectue des opérations séquentiellement, accédant à la mémoire à chaque fois, ce qui limite le débit global et consomme une quantité importante d'énergie .
Comment fonctionne le GPU
Pour augmenter le débit par rapport au CPU, le GPU utilise une stratégie simple: pourquoi ne pas intégrer des milliers d'ALU dans le processeur? Le GPU moderne contient environ 2500 à 5000 ALU sur le processeur, ce qui permet d'effectuer des milliers de multiplications et d'ajouts à la fois.

Une telle architecture fonctionne bien avec des applications nécessitant une parallélisation massive, comme par exemple la multiplication matricielle dans un réseau neuronal. Avec une charge de formation typique d'apprentissage en profondeur (GO), le débit dans ce cas augmente d'un ordre de grandeur par rapport au CPU. Par conséquent, le GPU est aujourd'hui l'architecture de processeur la plus populaire pour GO.
Mais le GPU reste un processeur polyvalent qui doit prendre en charge un million d'applications et de logiciels différents. Et cela nous ramène au problème fondamental du goulot d'étranglement de l'architecture von Neumann. Pour chaque calcul en milliers d'ALU, GPU, il est nécessaire de se référer aux registres ou à la mémoire partagée afin de lire et sauvegarder les résultats de calcul intermédiaires. Étant donné que le GPU effectue plus de calcul parallèle sur des milliers de ses ALU, il dépense également proportionnellement plus d'énergie pour accéder à la mémoire et occupe une grande surface.
Comment fonctionne le TPU?
Lorsque nous avons développé TPU chez Google, nous avons construit une architecture conçue pour une tâche spécifique. Au lieu de développer un processeur polyvalent, nous avons développé un processeur matriciel spécialisé pour travailler avec les réseaux de neurones. Le TPU ne pourra pas fonctionner avec un traitement de texte, contrôler des moteurs de fusée ou effectuer des transactions bancaires, mais il peut traiter un grand nombre de multiplications et d'ajouts pour les réseaux de neurones à une vitesse incroyable, tout en consommant beaucoup moins d'énergie et en s'adaptant à un volume physique plus petit.
La principale chose qui lui permet de le faire est l'élimination radicale du goulot d'étranglement de l'architecture von Neumann. Étant donné que la tâche principale du TPU est le traitement matriciel, les développeurs de circuits connaissaient toutes les étapes de calcul nécessaires. Par conséquent, ils ont pu placer des milliers de multiplicateurs et d'additionneurs et les connecter physiquement, formant une grande matrice physique. C'est ce qu'on appelle l'
architecture de réseau en pipeline . Dans le cas de Cloud TPU v2, deux matrices de pipeline de 128 x 128 sont utilisées, ce qui donne au total 32 768 ALU pour des valeurs à virgule flottante 16 bits sur un processeur.
Voyons comment un tableau en pipeline effectue des calculs pour un réseau de neurones. Tout d'abord, le TPU charge les paramètres de la mémoire dans une matrice de multiplicateurs et d'additionneurs.

Le TPU charge ensuite les données de la mémoire. À la fin de chaque multiplication, le résultat est transmis aux facteurs suivants, tout en effectuant des ajouts. Par conséquent, la sortie sera la somme de toutes les multiplications des données et des paramètres. Tout au long du processus de calcul volumétrique et de transfert de données, l'accès à la mémoire est totalement inutile.
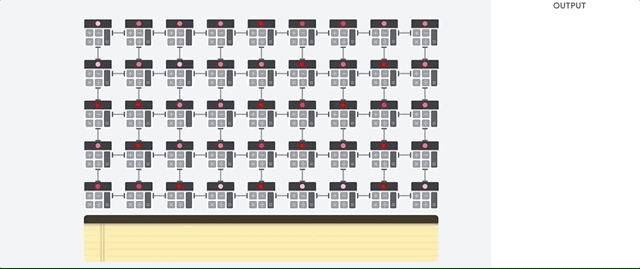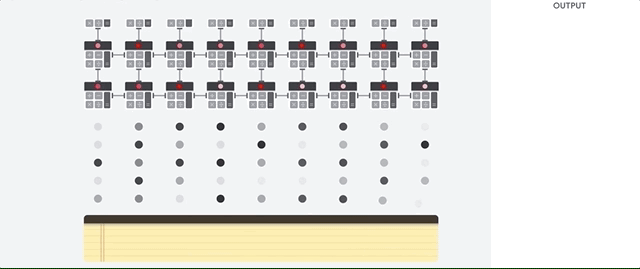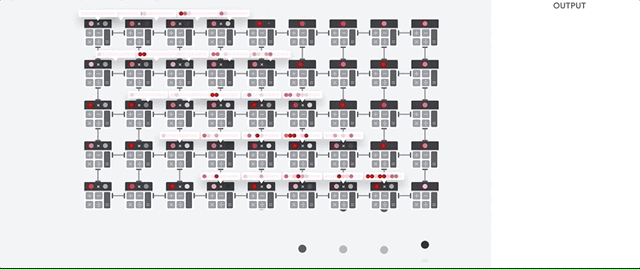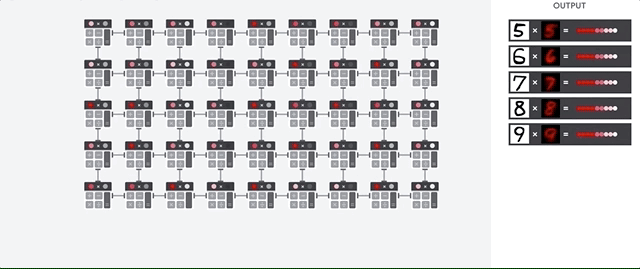
Par conséquent, TPU démontre un débit supérieur lors du calcul pour les réseaux de neurones, consommant beaucoup moins d'énergie et occupant moins d'espace.
Avantage: 5 fois moins cher
Quels sont les avantages de l'architecture TPU? Coût. Voici le coût de Cloud TPU v2 pour août 2018, au moment de la rédaction:
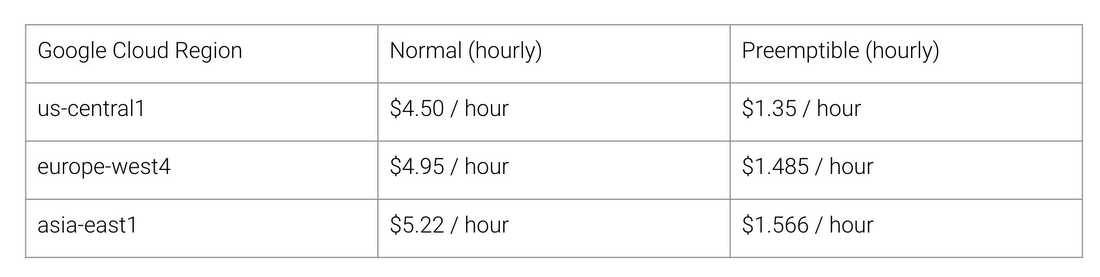
Coût de travail normal et TPU pour différentes régions de Google Cloud
L'Université de Stanford distribue un ensemble de tests
DAWNBench qui mesurent les performances des systèmes d'apprentissage en profondeur. Vous pouvez y voir différentes combinaisons de tâches, modèles et plates-formes informatiques, ainsi que les résultats des tests correspondants.
Au moment de la fin du concours en avril 2018, le coût minimum de formation sur les processeurs avec une architecture autre que TPU était de 72,40 $ (pour la formation ResNet-50 avec une précision de 93% sur ImageNet sur
des instances ponctuelles ). Avec Cloud TPU v2, cette formation peut être effectuée pour 12,87 $. C'est moins de 1/5 du coût. Telle est la puissance de l'architecture conçue spécifiquement pour les réseaux de neurones.