
Malheureusement, sur Internet, il n'y a pas suffisamment d'informations sur la migration des applications réelles et le fonctionnement de production du Percona XtraDB Cluster (ci-après PXC). Je vais essayer de corriger cette situation et raconter notre expérience avec mon histoire. Il n'y aura pas d'instructions d'installation étape par étape et l'article ne doit pas être considéré comme un remplacement de la documentation hors site, mais comme un ensemble de recommandations.
Le problème
Je travaille en tant qu'administrateur système sur
ultimate-guitar.com . Puisque nous fournissons un service Web, nous avons naturellement des backends et une base de données, qui est le cœur du service. La disponibilité du service dépend directement des performances de la base de données.
Percona MySQL 5.7 a été utilisé comme base de données. La réservation a été implémentée à l'aide du maître du schéma de réplication maître. Les esclaves ont été utilisés pour lire certaines données.
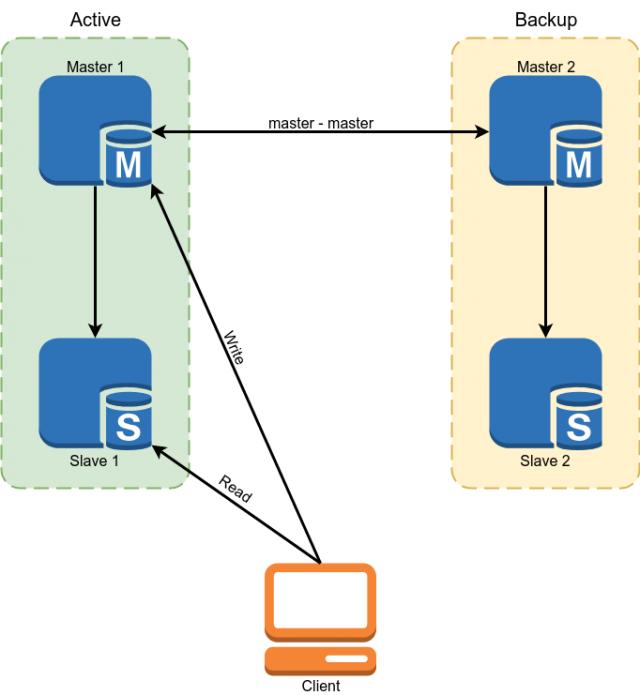
Mais ce schéma ne nous convenait pas avec les inconvénients suivants:
- En raison du fait que dans la réplication MySQL, les esclaves asynchrones peuvent être indéfiniment en retard. Toutes les données critiques devaient être lues par le maître.
- Du paragraphe précédent suit la complexité du développement. Le développeur ne pouvait pas simplement faire une demande à la base de données, mais était obligé de se demander s'il était prêt dans chaque cas particulier à l'arriéré de l'esclave et sinon, lire les données de l'assistant.
- Commutation manuelle en cas d'accident. L'implémentation de la commutation automatique était problématique en raison du fait que l'architecture MySQL n'a pas de protection intégrée contre le split brain. Il faudrait nous écrire un arbitre avec une logique complexe de choix d'un maître. Lorsque vous écrivez aux deux maîtres, des conflits peuvent survenir en même temps, brisant la réplication du maître et conduisant au split brain classique.
Quelques chiffres secs, pour que vous compreniez avec quoi nous avons travaillé:
Taille de la base de données: 300 Go
QPS: ~ 10k
Rapport RW: 96/4%
Configuration du serveur maître:
CPU: 2x E5-2620 v3
RAM: 128 Go
SSD: Intel Optane 905p 960 Go
Réseau: 1 Gbit / s
Nous avons une charge OLTP classique avec beaucoup de lecture, ce qui doit être fait très rapidement et avec une petite quantité d'écriture. La charge sur la base de données est assez faible en raison du fait que la mise en cache est activement utilisée dans Redis et Memcached.
Sélection de décision
Comme vous l'avez peut-être deviné à partir du titre, nous avons choisi PXC, mais ici je vais expliquer pourquoi nous l'avons choisi.
Nous avions 4 options:
- Changer de SGBD
- Réplication de groupe MySQL
- Vissez nous-mêmes les fonctionnalités nécessaires à l'aide de scripts sur le maître de réplication maître.
- Cluster MySQL Galera (ou ses fourches, par exemple PXC)
L'option de modification de la base de données n'a pratiquement pas été envisagée, car l'application est grande, dans de nombreux endroits, elle est liée à la fonctionnalité ou à la syntaxe mysql, et la migration vers PostgreSQL, par exemple, prendra beaucoup de temps et de ressources.
La deuxième option était la réplication de groupe MySQL. Un avantage incontestable est qu'il se développe dans la branche vanille de MySQL, ce qui signifie qu'à l'avenir il se généralisera et aura un large pool d'utilisateurs actifs.
Mais il a quelques inconvénients. Premièrement, il impose plus de restrictions sur le schéma d'application et de base de données, ce qui signifie qu'il sera plus difficile de migrer. Deuxièmement, la réplication de groupe résout le problème de la tolérance aux pannes et du fractionnement du cerveau, mais la réplication dans le cluster est toujours asynchrone.
Nous n'avons pas non plus aimé la troisième option pour trop de vélos, que nous devons inévitablement mettre en œuvre pour résoudre le problème de cette manière.
Galera a permis de résoudre complètement le problème de basculement MySQL et de résoudre partiellement le problème avec la pertinence des données sur les esclaves. En partie parce que l'asynchronie de réplication est maintenue. Une fois qu'une transaction est validée sur un nœud local, les modifications sont transmises aux nœuds restants de manière asynchrone, mais le cluster s'assure que les nœuds ne traînent pas trop et s'ils commencent à ralentir, cela ralentit artificiellement le travail. Le cluster garantit qu'après avoir validé la transaction, personne ne peut valider les modifications conflictuelles, même sur le nœud qui n'a pas encore répliqué les modifications.
Après la migration, le schéma de fonctionnement de la base de données devrait ressembler à ceci:
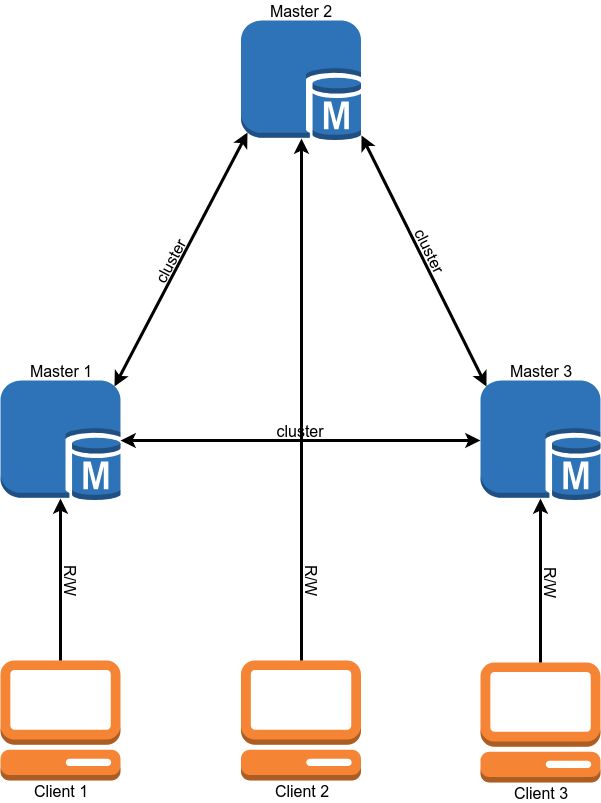
La migration
Pourquoi la migration est-elle le deuxième élément après avoir choisi une solution? C'est simple - le cluster contient un certain nombre d'exigences que l'application et la base de données doivent suivre, et nous devons les remplir avant la migration.
- Moteur InnoDB pour toutes les tables. MyISAM, Memory et autres backends ne sont pas pris en charge. Il est corrigé assez simplement - nous convertissons toutes les tables en InnoDB.
- Binlog au format ROW. Le cluster n'a pas besoin d'un binlog pour fonctionner, et si vous n'avez pas besoin d'esclaves classiques, vous pouvez le désactiver, mais le format binlog doit être ROW.
- Toutes les tables doivent avoir une CLÉ PRIMAIRE / ÉTRANGÈRE. Cela est nécessaire pour une écriture simultanée correcte dans la même table à partir de différents nœuds. Pour les tables qui ne contiennent pas de clé unique, vous pouvez utiliser la clé primaire composite ou l'incrémentation automatique.
- N'utilisez pas 'LOCK TABLES', 'GET_LOCK () / RELEASE_LOCK ()', 'FLUSH TABLES {{table}} WITH READ LOCK' ou le niveau d'isolement 'SERIALIZABLE' pour les transactions.
- N'utilisez pas les requêtes 'CREATE TABLE ... AS SELECT' , car ils combinent le schéma et le changement de données. Il est facilement divisé en 2 requêtes, la première crée une table et la seconde remplit de données.
- N'utilisez pas 'DISCARD TABLESPACE' et 'IMPORT TABLESPACE' , car ils ne sont pas répliqués
- Définissez les options «innodb_autoinc_lock_mode» sur «2». Cette option peut corrompre les données lorsque vous travaillez avec la réplication STATEMENT, mais comme seule la réplication ROW est autorisée dans le cluster, il n'y aura aucun problème.
- Comme «log_output», seul «FILE» est pris en charge. Si vous avez une entrée de journal dans le tableau, vous devrez la supprimer.
- Les transactions XA ne sont pas prises en charge. S'ils ont été utilisés, vous devrez réécrire le code sans eux.
Je dois noter que presque toutes ces restrictions peuvent être supprimées si vous définissez la variable 'pxc_strict_mode = PERMISSIVE', mais si vos données sont importantes pour vous, il est préférable de ne pas le faire. Si vous avez défini «pxc_strict_mode = ENFORCING», alors MySQL ne vous permettra pas d'effectuer les opérations ci-dessus ni d'empêcher le nœud de démarrer.
Après avoir rempli toutes les exigences de la base de données et testé minutieusement le fonctionnement de notre application dans l'environnement de développement, nous pouvons passer à l'étape suivante.
Déploiement et configuration de cluster
Nous avons plusieurs bases de données en cours d'exécution sur nos serveurs de bases de données et d'autres bases de données n'ont pas besoin de migrer vers le cluster. Mais un package avec un cluster MySQL remplace le mysql classique. Nous avions plusieurs solutions à ce problème:
- Utilisez la virtualisation et démarrez le cluster dans VM. Nous n'avons pas aimé cette option en raison des frais généraux élevés (par rapport au reste) et de l'apparition d'une autre entité qui doit être desservie
- Construisez votre version du paquet, qui mettra mysql dans un endroit non standard. Ainsi, il sera possible d'avoir plusieurs versions de mysql sur un même serveur. Une bonne option si vous avez de nombreux serveurs, mais le support constant de votre package, qui doit être mis à jour régulièrement, peut prendre beaucoup de temps.
- Utilisez Docker.
Nous avons choisi Docker, mais nous l'utilisons dans l'option minimale. Pour le stockage de données, le volume local est utilisé. Le mode de fonctionnement «--net host» est utilisé pour réduire la latence du réseau et la charge du processeur.
Nous avons également dû créer notre propre version de l'image Docker. La raison en est que l'image standard de Percona ne prend pas en charge la position de restauration au démarrage. Cela signifie que chaque fois que l'instance est redémarrée, elle n'effectue pas de synchronisation IST rapide, qui télécharge uniquement les modifications nécessaires, mais un SST lent, qui recharge complètement la base de données.
Un autre problème est la taille du cluster. Dans un cluster, chaque nœud stocke l'intégralité de l'ensemble de données. Par conséquent, la lecture évolue parfaitement avec l'augmentation de la taille du cluster. Avec l'enregistrement, la situation est inverse - lors de la validation, chaque transaction est validée pour l'absence de conflits sur tous les nœuds. Naturellement, plus il y a de nœuds, plus la validation prendra de temps.
Ici, nous avons également plusieurs options:
- 2 nœuds + arbitre. 2 nœuds + arbitre. Une bonne option pour les tests. Pendant le déploiement du deuxième nœud, le maître ne doit pas enregistrer.
- 3 nœuds. La version classique. Équilibre entre vitesse et fiabilité. Veuillez noter que dans cette configuration, un nœud doit étirer la charge entière, car au moment de l'ajout du 3e noeud, le second sera le donneur.
- 4+ nœuds. Avec un nombre pair de nœuds, il est nécessaire d'ajouter un arbitre pour éviter le split-brain. Une option qui fonctionne bien pour une très grande quantité de lecture. La fiabilité du cluster augmente également.
Nous avons jusqu'à présent opté pour l'option à 3 nœuds.
La configuration du cluster copie presque complètement la configuration MySQL autonome et ne diffère que par quelques options:
"Wsrep_sst_method = xtrabackup-v2" Cette option définit la méthode de copie des nœuds. Les autres options sont mysqldump et rsync, mais elles bloquent le nœud pendant la durée de la copie. Je ne vois aucune raison d'utiliser la méthode de copie non xtrabackup-v2.
«Gcache» est un analogue du binlog de cluster. Il s'agit d'un tampon circulaire (dans un fichier) de taille fixe dans lequel toutes les modifications sont écrites. Si vous désactivez l'un des nœuds du cluster, puis le rallumez, il essaiera de lire les modifications manquantes de Gcache (synchronisation IST). S'il ne comporte pas les modifications requises par le nœud, un rechargement complet du nœud (synchronisation SST) sera nécessaire. La taille de gcache est définie comme suit: wsrep_provider_options = 'gcache.size = 20G;'.
wsrep_slave_threads Contrairement à la réplication classique dans un cluster, il est possible d'appliquer plusieurs "sets d'écriture" à la même base de données en parallèle. Cette option indique le nombre de travailleurs appliquant les modifications. Il vaut mieux ne pas laisser la valeur par défaut de 1, car lors de l'application par le travailleur d'un grand ensemble d'écriture, le reste attendra dans la file d'attente et la réplication du nœud commencera à être en retard. Certains conseillent de définir ce paramètre sur 2 * CPU THREADS, mais je pense que vous devez examiner le nombre d'opérations d'écriture simultanées que vous avez.
Nous avons opté pour la valeur 64. À une valeur inférieure, le cluster n'a parfois pas réussi à appliquer tous les jeux d'écriture de la file d'attente lors des rafales de charge (par exemple, lors du démarrage de couronnes lourdes).
wsrep_max_ws_size La taille d'une seule transaction dans un cluster est limitée à 2 Go. Mais les transactions importantes ne correspondent pas bien au concept PXC. Il est préférable d'effectuer 100 transactions de 20 Mo chacune plutôt qu'une par 2 Go. Par conséquent, nous avons d'abord limité la taille des transactions dans le cluster à 100 Mo, puis réduit la limite à 50 Mo.
Si le mode strict est activé, vous pouvez définir la variable "
binlog_row_image " sur "minimal". Cela réduira la taille des entrées dans le binlog de plusieurs fois (10 fois dans le test de Percona). Cela permettra d'économiser de l'espace disque et d'autoriser les transactions qui ne correspondent pas à la limite avec "binlog_row_image = full".
Limites pour SST. Pour Xtrabackup, qui est utilisé pour remplir les nœuds, vous pouvez définir une limite sur l'utilisation du réseau, le nombre de threads et la méthode de compression. Cela est nécessaire pour que lorsque le nœud est rempli, le serveur donneur ne commence pas à ralentir. Pour ce faire, la section «sst» est ajoutée au fichier my.cnf:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
Nous limitons la vitesse de copie à 80 Mb / s. Nous utilisons pigz pour la compression, c'est une version multi-thread de gzip.
GTID Si vous utilisez des esclaves classiques, je recommande d'activer GTID sur le cluster. Cela vous permettra de connecter l'esclave à n'importe quel nœud du cluster sans recharger l'esclave.
De plus, je veux parler de 2 mécanismes de cluster, leur signification et leur configuration.
Contrôle de flux
Le contrôle de flux est un moyen de gérer la charge d'écriture dans un cluster. Il ne permet pas aux nœuds de trop tarder dans la réplication. De cette façon, la réplication «presque synchrone» est obtenue. Le mécanisme de fonctionnement est assez simple - dès que la longueur de la file d'attente de réception atteint la valeur définie, il envoie le message «Flow control pause» aux autres nœuds, qui leur dit de faire une pause avec la validation de nouvelles transactions jusqu'à ce que le nœud en retard finisse de ratisser la file d'attente .
Plusieurs choses en découlent:
- L'enregistrement dans le cluster se fera à la vitesse du nœud le plus lent. (Mais il peut être resserré.)
- Si vous rencontrez de nombreux conflits lors de la validation des transactions, vous pouvez configurer Flow Control de manière plus agressive, ce qui devrait réduire leur nombre.
- Le décalage maximal d'un nœud dans un cluster est une constante, mais pas par le temps, mais par le nombre de transactions dans la file d'attente. Le délai dépend de la taille moyenne des transactions et du nombre de wsrep_slave_threads.
Vous pouvez afficher les paramètres de contrôle de flux comme ceci:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
Tout d'abord, nous nous intéressons au paramètre wsrep_flow_control_interval_high. Il contrôle la longueur de la file d'attente, après quoi la pause FC est activée. Ce paramètre est calculé par la formule: gcs.fc_limit * √N (où N = le nombre de nœuds dans le cluster.).
Le deuxième paramètre est wsrep_flow_control_interval_low. Il est responsable de la valeur de la longueur de la file d'attente, lorsqu'il atteint quel FC est désactivé. Calculé par la formule: wsrep_flow_control_interval_high * gcs.fc_factor. Par défaut, gcs.fc_factor = 1.
Ainsi, en modifiant la longueur de la file d'attente, nous pouvons contrôler le retard de réplication. La réduction de la longueur de la file d'attente augmentera le temps que le cluster passe en pause FC, mais réduira le décalage des nœuds.
Vous pouvez définir la variable de session "
wsrep_sync_wait = 7". Cela forcera le PXC à exécuter des requêtes de lecture ou d'écriture uniquement après avoir appliqué tous les ensembles d'écriture dans la file d'attente actuelle. Naturellement, cela augmentera la latence des requêtes. L'augmentation de la latence est directement proportionnelle à la longueur de la file d'attente.
Il est également souhaitable de réduire la taille maximale des transactions au minimum possible, afin que les transactions longues ne passent pas accidentellement.
EVS ou Auto Evict
Ce mécanisme vous permet de rejeter des nœuds instables (par exemple, perte de paquets ou longs retards) ou qui répondent lentement. Grâce à cela, les problèmes de communication avec un nœud ne mettront pas l'ensemble du cluster, mais laisseront le nœud désactivé et continuer à fonctionner en mode normal. Ce mécanisme est particulièrement utile lorsque le cluster fonctionne via le WAN ou des parties du réseau qui ne sont pas sous votre contrôle. Par défaut, EVS est désactivé.
Pour l'activer, ajoutez l'option «evs.version = 1;» au paramètre
wsrep_provider_options et "evs.auto_evict = 5;" (le nombre d'opérations après lesquelles le nœud s'éteint. Une valeur de 0 désactive EVS.) Il existe également plusieurs paramètres qui vous permettent d'affiner EVS:
- evs.delayed_margin Le temps nécessaire à un nœud pour répondre. Par défaut, 1 seconde, mais lorsque vous travaillez sur un réseau local, il peut être réduit à 0,05-0,1 seconde ou moins.
- evs.inactive_check_period Période de vérifications. Par défaut 0,5 sec
En fait, le temps pendant lequel un nœud peut fonctionner en cas de problème avant le déclenchement d'EVS est evs.inactive_check_period * evs.auto_evict. Vous pouvez également définir "evs.inactive_timeout" et un nœud qui ne répond pas sera immédiatement supprimé, par défaut 15 secondes.
Une nuance importante est que ce mécanisme lui-même ne renverra pas le nœud lors de la restauration de la communication. Il doit être redémarré à la main.
Nous avons installé EVS à la maison, mais nous n'avons pas eu l'occasion de le tester au combat.
Équilibrage de charge
Pour que les clients utilisent les ressources de chaque nœud de manière uniforme et exécutent les demandes uniquement sur les nœuds de cluster actifs, nous avons besoin d'un équilibreur de charge. Percona propose 2 solutions:
- ProxySQL. Il s'agit du proxy L7 pour MySQL.
- Haproxy. Mais Haproxy ne sait pas comment vérifier l'état d'un nœud de cluster et déterminer s'il est prêt à exécuter des requêtes. Pour résoudre ce problème, il est proposé d'utiliser un script percona-clustercheck supplémentaire
Au début, nous voulions utiliser ProxySQL, mais après l'analyse comparative, il s'est avéré que la latence perdait à Haproxy d'environ 15 à 20% même en utilisant le mode fast_forward (les réécrivains de requêtes, le routage et de nombreuses autres fonctions ProxySQL ne fonctionnent pas dans ce mode, les demandes sont mandatées en l'état) .
Haproxy est plus rapide, mais le script Percona a quelques inconvénients.
Tout d'abord, il est écrit en bash, ce qui ne contribue pas à sa personnalisation. Un problème plus grave est qu'il ne met pas en cache le résultat de la vérification MySQL. Ainsi, si nous avons 100 clients, chacun vérifiant l'état du nœud une fois toutes les 1 seconde, le script fera une requête à MySQL toutes les 10 ms. Si pour une raison quelconque MySQL commence à fonctionner lentement, le script de validation commencera à créer un grand nombre de processus, ce qui n'améliorera certainement pas la situation.
Il a été décidé d'écrire
une solution dans laquelle la vérification d'état MySQL et la réponse Haproxy ne sont pas liées. Le script vérifie régulièrement l'état du nœud en arrière-plan et met le résultat en cache. Le serveur Web donne à Haproxy le résultat mis en cache.
Exemple de configuration haproxylisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
Cet exemple montre une configuration d'assistant unique. Les serveurs de cluster restants agissent comme des esclaves.
Suivi
Pour surveiller l'état du cluster, nous avons utilisé Prometheus + mysqld_exporter et Grafana pour visualiser les données. Parce que mysqld_exporter recueille un tas de métriques pour créer vous-même des tableaux de bord est assez fastidieux. Vous pouvez prendre des
tableaux de bord prêts
à l'emploi de Percona et les personnaliser pour vous-même.
Nous utilisons également Zabbix pour collecter des mesures et alertes de cluster de base.
Les principales mesures de cluster que vous souhaitez surveiller:
- wsrep_cluster_status Doit être défini sur Primary sur tous les nœuds. Si la valeur est «non primaire», ce nœud a perdu le contact avec le quorum du cluster.
- wsrep_cluster_size Le nombre de nœuds dans le cluster. Cela inclut également les nœuds «perdus», qui doivent être dans le cluster, mais pour une raison quelconque, ils ne sont pas disponibles. Lorsque le nœud est désactivé doucement, la valeur de cette variable diminue.
- wsrep_local_state Indique si le nœud est un membre actif du cluster et est prêt à fonctionner.
- wsrep_evs_state Un paramètre important si vous avez Auto Eviction activé (désactivé par défaut). Cette variable indique qu'EVS considère ce nœud sain.
- wsrep_evs_evict_list La liste des nœuds qui ont été lancés par EVS à partir du cluster. Dans une situation normale, la liste doit être vide.
- wsrep_evs_delayed Liste des candidats à la suppression d'EVS. Doit également être vide.
Mesures de performance clés:
- wsrep_evs_repl_latency Affiche ( délai minimum / moyen / maximum / écart senior / taille de paquet) le délai de communication au sein du cluster. Autrement dit, il mesure la latence du réseau. Des valeurs croissantes peuvent indiquer une surcharge du réseau ou des nœuds de cluster. Cette métrique est enregistrée même lorsque l'EVS est éteint.
- wsrep_flow_control_paused_ns Le temps (en ns) depuis le démarrage du noeud qu'il a passé dans la pause du contrôle de flux. Idéalement, il devrait être 0. La croissance de ce paramètre indique des problèmes avec les performances du cluster ou le manque de "wsrep_slave_threads". Vous pouvez déterminer quel nœud ralentit par le paramètre " wsrep_flow_control_sent ".
- wsrep_flow_control_paused Pourcentage de temps écoulé depuis la dernière exécution de «FLUSH STATUS;» que le nœud a passé dans la pause du contrôle de flux. En plus de la variable précédente, elle devrait tendre vers zéro.
- wsrep_flow_control_status Indique si Flow Control est en cours d'exécution. Sur le nœud initiateur de pause FC, la valeur de cette variable sera ON.
- wsrep_local_recv_queue_avg Longueur moyenne de la file d'attente de réception. La croissance de ce paramètre indique des problèmes avec les performances du nœud.
- wsrep_local_send_queue_avg La longueur moyenne de la file d'attente d'envoi. La croissance de ce paramètre indique des problèmes de performances réseau.
Il n'y a pas de recommandations universelles sur les valeurs de ces paramètres. Il est clair qu'ils devraient tendre à zéro, mais à charge réelle, ce ne sera probablement pas le cas et vous devrez déterminer par vous-même où passe la limite de l'état normal du cluster.
Sauvegarde
La sauvegarde de cluster n'est pratiquement pas différente de mysql autonome. Pour une utilisation en production, nous avons plusieurs options.
- Supprimez la sauvegarde de l'un des nœuds "de gain" à l'aide de xtrabackup. L'option la plus simple, mais pendant la performance du cluster de sauvegarde sera gaspillée.
- Utilisez des esclaves classiques et sauvegardez à partir de répliques.
Les sauvegardes autonomes et avec la version de cluster créée à l'aide de xtrabackup sont portables entre elles. Autrement dit, la sauvegarde prise à partir du cluster peut être déployée sur mysql autonome et vice versa. Naturellement, la version principale de MySQL doit correspondre, de préférence la mineure. Les sauvegardes effectuées à l'aide de mysqldump sont naturellement portables également.
La seule mise en garde est qu'après avoir déployé la sauvegarde, vous devez exécuter le script mysql_upgrade, qui vérifiera et corrigera la structure de certaines tables système.
Migration de données
Maintenant que nous avons compris la configuration, la surveillance et d'autres choses, nous pouvons commencer la migration vers le prod.
La migration des données dans notre schéma était assez simple, mais nous avons un peu gâché;).
Légende - le maître 1 et le maître 2 sont connectés par le maître de réplication maître. L'enregistrement va uniquement au master 1. Master 3 est un serveur propre.
Notre plan de migration (dans le plan je vais omettre les opérations avec des esclaves pour plus de simplicité et ne parlerai que des serveurs maîtres).
Tentative 1
- Supprimez la sauvegarde de la base de données du maître 1 à l'aide de xtrabackup.
- Copiez la sauvegarde sur le maître 3 et exécutez le cluster en mode nœud unique.
- Configurez la réplication principale entre les maîtres 3 et 1.
- Basculez la lecture et l'écriture sur le maître 3. Vérifiez l'application.
- Sur le maître 2, désactivez la réplication et démarrez MySQL en cluster. Nous attendons qu'il copie la base de données du maître 3. Lors de la copie, nous avions un cluster d'un nœud à l'état «Donateur» et un nœud toujours non fonctionnel. Pendant la copie, nous avons obtenu un tas de verrous et, à la fin, les deux nœuds sont tombés avec une erreur (la création d'un nouveau nœud ne peut pas être terminée en raison de verrous morts). Cette petite expérience nous a coûté quatre minutes de temps d'arrêt.
- Basculez la lecture et l'écriture sur le maître 1.
La migration n'a pas fonctionné du fait que lors du test du circuit dans l'environnement de développement sur la base de données, il n'y avait pratiquement pas de trafic d'écriture, et lors de la répétition du même circuit sous charge, des problèmes étaient survenus.
Nous avons légèrement modifié le schéma de migration pour éviter ces problèmes et réessayé, pour la deuxième fois avec succès;).
Tentative 2
- Nous redémarrons le maître 3 pour qu'il fonctionne à nouveau en mode nœud unique.
- Nous remontons le cluster MySQL sur le maître 2. Pour le moment, le trafic provenant de la réplication n'est allé qu'au cluster, il n'y a donc pas eu de problèmes répétés avec les verrous et le deuxième nœud a été ajouté avec succès au cluster.
- Encore une fois, passez la lecture et l'écriture au maître 3. Nous vérifions le fonctionnement de l'application.
- Désactivez la réplication maître avec maître 1. Activez le cluster mysql sur maître 1 et attendez qu'il démarre. Afin de ne pas marcher sur le même râteau, il est important que l'application n'écrive pas sur le nœud Donateur (pour plus de détails, voir la section sur l'équilibrage de charge). Après avoir démarré le troisième nœud, nous aurons un cluster entièrement fonctionnel de trois nœuds.
- Vous pouvez supprimer une sauvegarde de l'un des nœuds du cluster et créer le nombre d'esclaves classiques dont vous avez besoin.
La différence entre le deuxième schéma et le premier est que nous avons commuté le trafic vers le cluster uniquement après avoir élevé le deuxième nœud du cluster.
Cette procédure nous a pris environ 6 heures.
Multi-maître
Après la migration, notre cluster a fonctionné en mode maître unique, c'est-à-dire que la totalité de l'enregistrement est allée sur l'un des serveurs, et seules les données ont été lues à partir du reste.
Après avoir fait passer la production en mode multi-maître, nous avons rencontré un problème - les conflits de transaction sont survenus plus souvent que prévu. Cela était particulièrement mauvais avec les requêtes qui modifient de nombreux enregistrements, par exemple, en mettant à jour la valeur de tous les enregistrements d'une table. Les transactions qui ont été exécutées avec succès sur le même nœud de manière séquentielle sur le cluster sont exécutées en parallèle et une transaction plus longue reçoit une erreur de blocage. Je ne tarderai pas, après plusieurs tentatives pour résoudre ce problème au niveau de l'application, nous avons abandonné l'idée du multi-maître.
Autres nuances
- Un cluster peut être un esclave. Lors de l'utilisation de cette fonction, je recommande d'ajouter à la config tous les nœuds sauf celui qui est l'option esclave "skip_slave_start = 1". Sinon, chaque nouveau nœud démarrera la réplication à partir du maître, ce qui entraînera des erreurs de réplication ou une corruption des données sur la réplique.
- Comme je l'ai dit Donor, un nœud ne peut pas servir correctement les clients. Il ne faut pas oublier que dans un cluster de trois nœuds, des situations sont possibles lorsqu'un nœud s'est envolé, que le second est un donneur et qu'il ne reste qu'un nœud pour le service client.
Conclusions
Après la migration et un certain temps de fonctionnement, nous sommes arrivés aux conclusions suivantes.
- Le cluster Galera fonctionne et est assez stable (au moins tant qu'il n'y a pas eu de gouttes anormales de nœuds ou de leur comportement anormal). En termes de tolérance aux pannes, nous avons obtenu exactement ce que nous voulions.
- Les relevés multimaîtres de Percona sont principalement marketing. Oui, il est possible d'utiliser le cluster dans ce mode, mais cela nécessitera une profonde modification de l'application pour ce modèle d'utilisation.
- Il n'y a pas de réplication synchrone, mais maintenant nous contrôlons le retard maximum des nœuds (dans les transactions). Avec la limitation de la taille maximale des transactions de 50 Mo, nous pouvons prédire assez précisément le temps de latence maximal des nœuds. Il est devenu plus facile pour les développeurs d'écrire du code.
- Lors de la surveillance, nous observons des pics à court terme dans la croissance de la file d'attente de réplication. La raison en est dans notre réseau à 1 Gbit / s. Il est possible de faire fonctionner un cluster sur un tel réseau, mais des problèmes apparaissent lors des rafales de charge. Nous prévoyons maintenant de mettre à niveau le réseau à 10 Gbit / s.
Au total, trois «Wishlist» que nous avons reçues environ un an et demi. L'exigence la plus importante est la tolérance aux pannes.
Notre fichier de configuration PXC pour les personnes intéressées:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
Sources et liens utiles
→
Notre image Docker→
Documentation Percona XtraDB Cluster 5.7→
Surveillance de l'état du cluster - Documentation du cluster Galera→
Variables d'état Galera - Documentation du cluster Galera