En Python, vous pouvez travailler avec des données et les visualiser. Non seulement les programmeurs en profitent, mais aussi les scientifiques: biologistes, physiciens et sociologues. Aujourd'hui, avec
Shwars , le conservateur de notre cours
Python Jumpstart for AI , nous nous transformerons brièvement en météorologues et étudierons le climat des villes russes. Depuis les bibliothèques de visualisation et de travail avec les données, nous utilisons Pandas, Matplotlib et Bokeh.

Nous effectuons des recherches sur
Azure Notebooks , la version cloud de Jupyther Notebook. Ainsi, pour commencer avec Python, nous n'avons pas besoin d'installer quoi que ce soit sur notre ordinateur et nous pouvons travailler directement à partir du navigateur. Il vous suffit de vous connecter avec votre compte Microsoft, de créer une bibliothèque et le nouvel ordinateur portable Python 3. Ensuite, vous pouvez prendre les extraits de code de cet article et expérimenter!
Nous obtenons les données
Tout d'abord, nous importons les principales bibliothèques dont nous avons besoin.
Pandas est une bibliothèque pour travailler avec des données tabulaires, ou soi-disant trames de données, et
pyplot nous permettra de construire des graphiques.
import pandas as pd import matplotlib.pyplot as plt
Les données source sont faciles à trouver sur Internet, mais nous avons déjà préparé les données pour vous dans un format CSV pratique. CSV est un format de texte dans lequel toutes les colonnes sont séparées par des virgules. D'où le nom - Valeurs séparées par des virgules.
Les pandas peuvent ouvrir des fichiers CSV à partir d'un disque local ainsi que directement depuis Internet. Les données elles-mêmes se trouvent dans notre
référentiel sur GitHub , nous avons donc juste besoin de spécifier l'URL correcte.
data = pd.read_csv("https://raw.githubusercontent.com/shwars/PythonJump/master/Data/climat_russia_cities.csv") data

Renommez les colonnes du tableau afin qu'il soit plus pratique d'y accéder par leur nom. Nous devons également convertir les chaînes en valeurs numériques afin de pouvoir les utiliser. Lorsque nous essayons de le faire en utilisant la fonction
pd.to_numeric , nous constatons qu'une étrange erreur se produit. Cela est dû au fait qu'au lieu d'un moins, un long tiret est utilisé dans le texte.
data.columns=["City","Lat","Long","TempMin","TempColdest","AvgAnnual","TempWarmest","AbsMax","Precipitation"] data["TempMin"] = pd.to_numeric(data["TempMin"])
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) pandas/_libs/src/inference.pyx in pandas._libs.lib.maybe_convert_numeric() ValueError: Unable to parse string "−38.0" ... ... ... ValueError: Unable to parse string "−38.0" at position 0
Une moralité importante découle de ce problème: les données se présentent généralement sous une forme «sale», ce qui n'est pas pratique à utiliser, et la tâche d'un scientifique des données est de les présenter correctement.
Vous pouvez voir que certaines des colonnes de notre tableau sont de type
object , plutôt que de type numérique
float64 . Dans de telles colonnes, nous remplacerons le tiret par un moins, puis convertirons l'ensemble du tableau en format numérique. Les colonnes qui ne peuvent pas être converties (noms de villes) resteront inchangées (pour cela, nous avons utilisé les
errors='ignore' clés
errors='ignore' ).
print(data.dtypes) for x in ["TempMin","TempColdest","AvgAnnual"]: data[x] = data[x].str.replace('−','-') data = data.apply(pd.to_numeric,errors='ignore') print(data.dtypes)
City object Lat float64 Long float64 TempMin object TempColdest object AvgAnnual object TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object City object Lat float64 Long float64 TempMin float64 TempColdest float64 AvgAnnual float64 TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object
Nous recherchons des données
Maintenant que nous avons des données propres, nous pouvons essayer de construire des graphiques intéressants.
Température annuelle moyenne
Par exemple, voyons comment la température moyenne dépend de la latitude.
ax = data.plot(x="Lat",y="AvgAnnual",kind="Scatter") ax.set_xlabel("") ax.set_ylabel(" ")

Le graphique montre que le plus proche de l'équateur, le plus chaud.
Enregistrer des villes
Jetons maintenant un coup d'œil aux villes qui sont des champions de la température et voyons s'il existe une corrélation entre les températures minimales et maximales dans la ville.
ax=data.plot(x="TempMin",y="AbsMax",kind="scatter") ax.set_xlabel(" ") ax.set_ylabel(" ") ax.invert_xaxis()
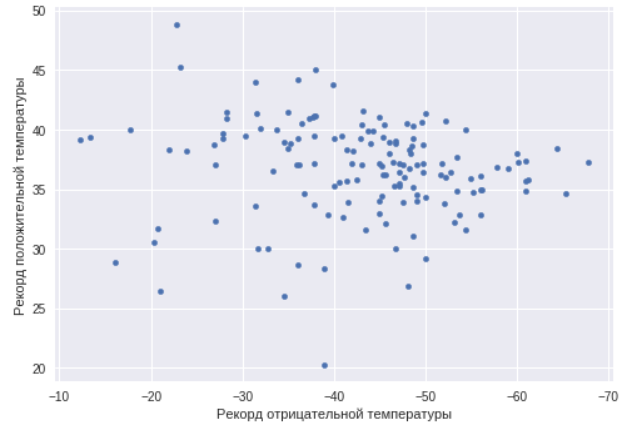
Comme vous pouvez le voir, dans ce cas, il n'y a pas une telle corrélation. Il y a des villes avec un climat fortement continental, et juste des villes chaudes et froides. Nous trouvons des villes avec un écart de température maximum, c'est-à-dire des villes au climat fortement continental.
data['spread'] = data['TempWarmest'] - data['TempColdest'] data.nlargest(3,'spread')

Cette fois, nous n'avons pas enregistré de records, mais les moyennes des mois les plus chauds et les plus froids. Comme prévu, la plus grande dispersion parmi les villes de la République de Sakha (Yakoutie).
Hiver et été
Pour de plus amples recherches, considérez les villes dans un rayon de 300 km de Moscou. Pour calculer la distance entre les points de latitude et de longitude, nous utilisons la bibliothèque
geopy , qui doit d'abord être installée à l'aide de
pip install .
!pip install geopy import geopy.distance
Ajoutez une colonne de plus au tableau - la distance jusqu'à Moscou.
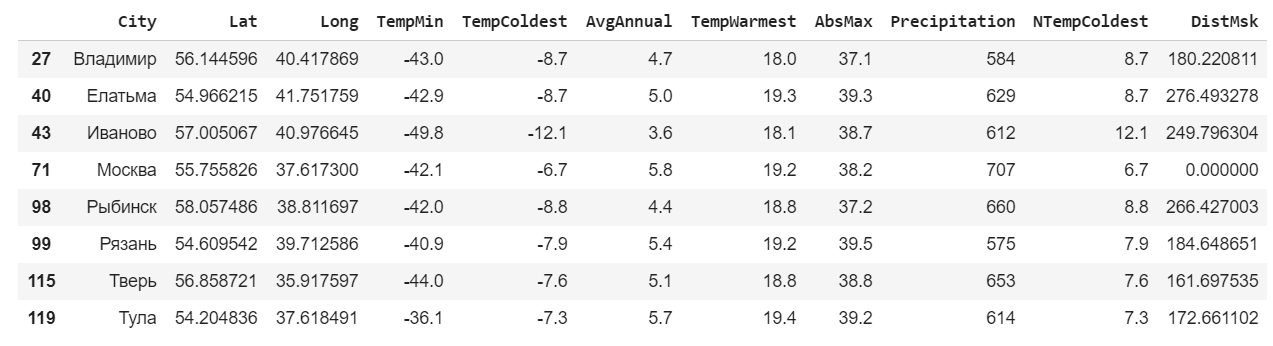
msk_coords = tuple(data.loc[data["City"]==""][["Lat","Long"]].iloc[0]) data["DistMsk"] = data.apply(lambda row : geopy.distance.distance(msk_coords,(row["Lat"],row["Long"])).km,axis=1) data.head()

Nous utilisons l'expression pour sélectionner uniquement les lignes qui nous intéressent.
msk = data.loc[data['DistMsk']<300] msk
Pour ces villes, nous construisons un programme de températures minimales, moyennes annuelles et maximales.
ax=msk.plot(x="City",y=["TempColdest","AvgAnnual","TempWarmest"],kind="bar",stacked="true") ax.legend(["","",""],loc='lower right')
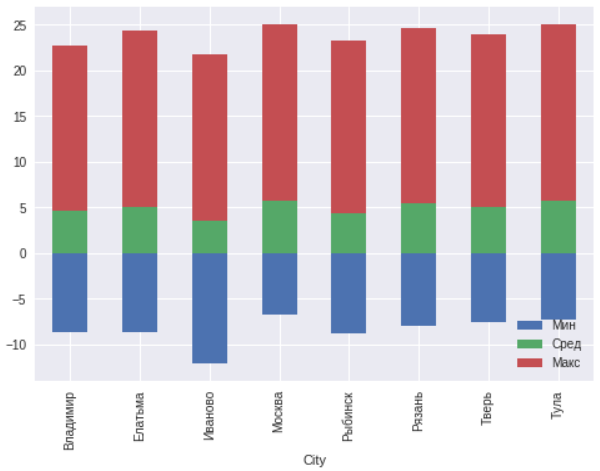
En général, aucune anomalie n'est observée dans un rayon de 300 kilomètres autour de Moscou. Ivanovo est situé au nord du reste des villes, et donc les températures y sont plusieurs degrés plus basses.
Travailler avec des géo-données
Essayons maintenant d'afficher sur la carte les précipitations annuelles moyennes par rapport aux villes et de voir comment les précipitations dépendent de la situation géographique. Pour cela, nous utilisons une autre bibliothèque de visualisation -
Bokeh . Il doit également être installé.
Ensuite, nous calculons une autre colonne - la taille du cercle, qui montrera la quantité de précipitations. Le coefficient est choisi empiriquement.
!pip install bokeh from bokeh.io import output_file, output_notebook, show from bokeh.models import ( GMapPlot, GMapOptions, ColumnDataSource, Circle, LogColorMapper, BasicTicker, ColorBar, DataRange1d, PanTool, WheelZoomTool, BoxSelectTool, HoverTool ) from bokeh.models.mappers import ColorMapper, LinearColorMapper from bokeh.palettes import Viridis5 from bokeh.plotting import gmap
Pour travailler avec la carte, vous avez besoin de la clé API Google Maps. Il doit être obtenu indépendamment
sur le site .
Des instructions plus détaillées sur l'utilisation de Bokeh pour tracer des graphiques sur des cartes peuvent être trouvées
ici et
ici .
google_key = "<INSERT YOUR KEY HERE>" data["PrecipSize"] = data["Precipitation"] / 50.0 map_options = GMapOptions(lat=msk_coords[0], lng=msk_coords[1], map_type="roadmap", zoom=4) plot = gmap(google_key,map_options=map_options) plot.title.text = " " source = ColumnDataSource(data=data) my_hover = HoverTool() my_hover.tooltips = [('', '@City'),('','@Precipitation')] plot.circle(x="Long", y="Lat", size="PrecipSize", fill_color="blue", fill_alpha=0.8, source=source) plot.add_tools(PanTool(), WheelZoomTool(), BoxSelectTool(), my_hover) output_notebook() show(plot)
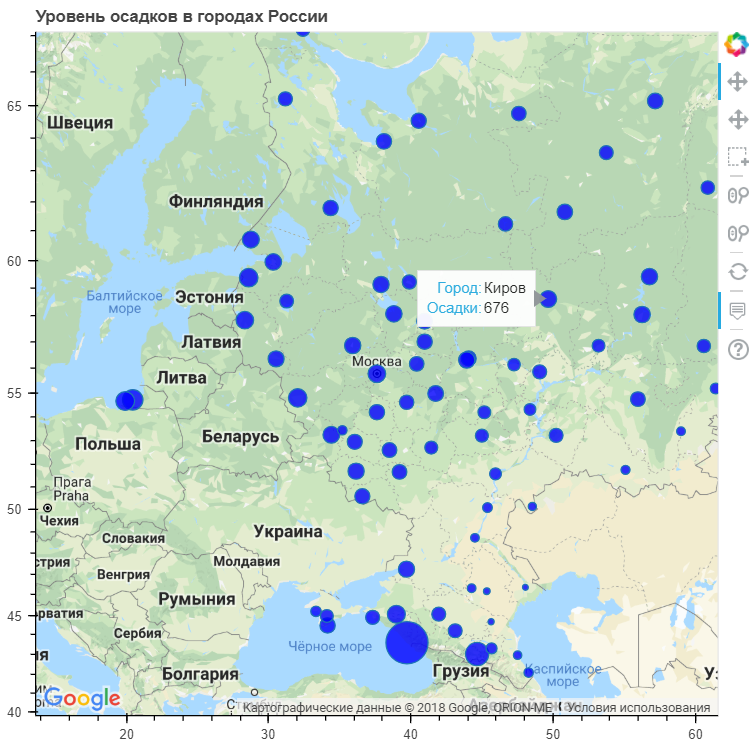
Comme vous pouvez le voir, la plus grande quantité de précipitations se produit dans les villes côtières. Bien qu'il existe un nombre assez important de villes où les précipitations sont moyennes voire inférieures au niveau national.
Le code entier avec des commentaires écrits par Dmitry Soshnikov, vous pouvez le voir et l'exécuter de manière indépendante
ici .
Résumé
Nous avons montré les capacités du langage sans utiliser d'algorithmes complexes, de bibliothèques spécifiques ou d'écrire des centaines de lignes de code. Cependant, même armé d'outils standard, vous pouvez analyser vos données et tirer des conclusions.
Les ensembles de données sont loin d'être toujours parfaitement composés, donc avant de commencer à travailler avec la visualisation, vous devez les mettre en ordre. La qualité de la visualisation dépendra largement de la qualité des données utilisées.
Il existe un grand nombre de différents types de tableaux et de graphiques, et il n'est pas nécessaire de se limiter aux seules bibliothèques standard.
Il y a
Geoplotlib ,
Plotly ,
cuir minimaliste et autres.
Si vous souhaitez en savoir plus sur l'utilisation des données en Python, ainsi que vous familiariser avec l'intelligence artificielle, nous vous invitons à une journée intensive du Binary District -
Python jumpstart pour l'IA .